机器学习 —— 浅析
一、概念
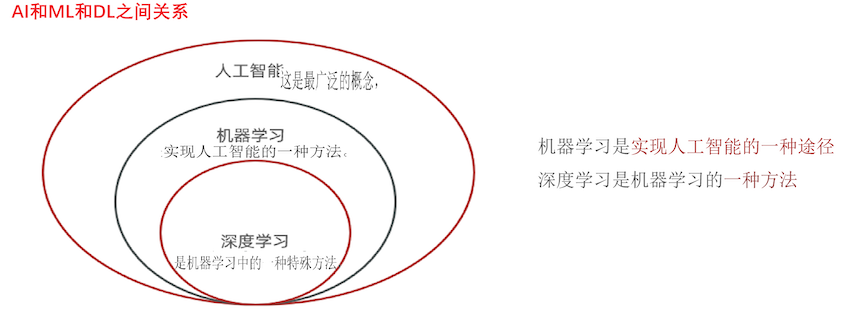
AI: 人工智能 (像人一样模拟代替人类)
ML:机器学习 (从数据中获取规律,来了一个新的数据,产生一个新的预测)
小结:1.提供数据(历史数据)
2.训练模型(公式)
3.提供测试数据
4.对测试数据进行预测
DL: 深度学习 (大脑仿生,一层一层的神经元模拟万事万物)
发展史:
1.1956年提出“人工智能”这一术语
2.1962. 跳棋
3.1997 国际象棋
4.2016 AlphaGo 围棋
==== 大模型预训练模型 ====
5.2017年,自然语音处理NLP的Transformer框架出现
6.2022,chatGPT的出现,进入到大模型AIGC发展阶段
AI 发展三要素:
数据、算法、算力
二、机器学习常用术语:
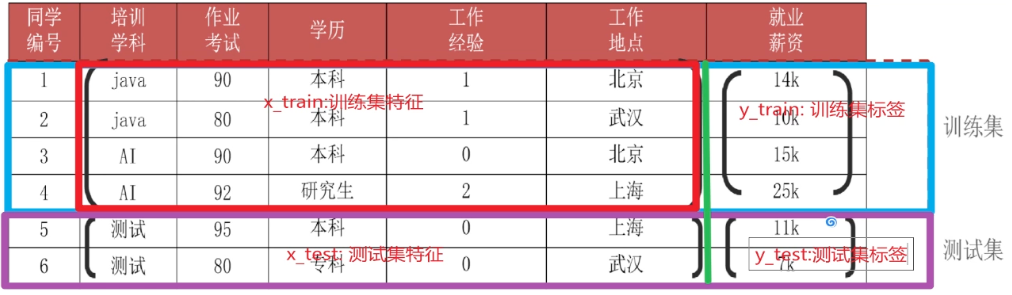
样本(sample):一行数据就是一个样本:多个样本组成数据集:有时一条样本被叫成一条记录
特征(feature):一列数据一个特征,有时也被称为属性
标签/目标(label/target):模型要预测的那一列数据。
特征是从数据中抽取出来的,对结果预测有用信息。。
训练集:用来训练模型的数据集
测试集:用来测试模型的数据集
x_train:训练集特征 x_test:测试集特征
y_train:训练集标签 预测-> y_test:测试集标签
一般划分比例7:3, 8:2
训练集和测试集
三、机器学习算法分类
1.监督学习
(有特征、有标签) 即 (有训练数据 x_train + 有标签 y_train)
(预测结果) -> 案例:“猫狗分类/房价预测”
有监督问题&回归问题
如果标签是连续的 即回归
如果标签是离散的 即分类
🔹 离散 vs 连续(看输出空间)
|
类型 |
特点 |
典型例子 |
|---|---|---|
|
离散(Discrete) |
取值有限或可数,值之间没有“中间状态”,强调“种类”或“状态” |
猫/狗、是/否、手写数字0~9、用户等级A/B/C |
|
连续(Continuous) |
取值在某个区间内可以是任意实数,理论上无限可分,强调“大小”和“度量” |
房价(350.2万)、温度(23.5℃)、点击率(0.037)、身高 |
🔹 分类 vs 回归(看任务目标)
|
任务 |
对应目标类型 |
预测本质 |
典型算法 |
评估指标 |
|---|---|---|---|---|
|
分类(Classification) |
离散 |
“是什么”(定性) |
逻辑回归、SVM、决策树分类、随机森林、XGBoost分类、神经网络分类 |
准确率、精确率、召回率、F1、ROC-AUC |
|
回归(Regression) |
连续 |
“是多少”(定量) |
线性回归、岭/Lasso回归、决策树回归、SVR、XGBoost回归 |
MSE、RMSE、MAE、R² |
2.无监督学习.
(有特征、无标签) 即 聚类分析,发现事务内部的关系
(发现潜在结构) 案例: “物以类聚人以群分”
3.半监督
(有特征、部分有标签,部分无标签)
(降低数据标记的难度)
大大降低标记成本
拿部分有标签的数据进行训练 训练出来的模型,让他去给没有标签的数据进行预测标签!!
4.强化学习
(长期利益最大化) -> 案例: 学下棋
让机器自己学习,然后给机器奖励,让机器自己学习。
得到更多奖励,强化去做能得到奖励的事情
agent 根据环境状态进行行动获得最多的累计奖励。
四、机器学习建模流程
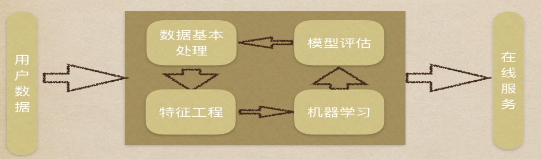
在整个建模流程中,数据基本处理、特征工程一般是耗时、耗精力最多的。
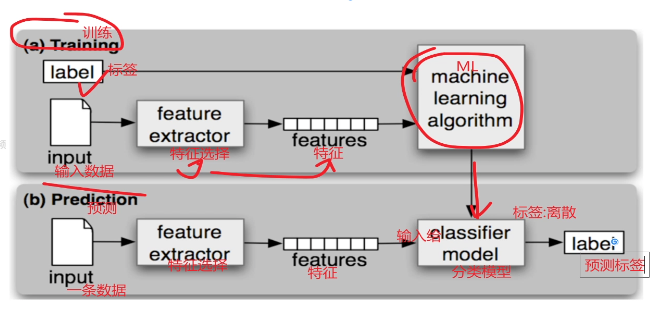
1.获取数据
获取经验数据、图像数据、文本数据......
2.数据基本处理
数据缺失值处理、异常值处理......
3.特征工程
利用专业背景知识和技巧处理数据,让机器学习算法效果最好。
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已
<1> 特征提取
从原始数据提取和任务相关特征
<2>特征预处理
解决量纲问题:比如身高,体重 单位不统一 (归一化,标准化)
( 比如有些特征对模型影响很大,比如房价有朝向,楼层,面积等等特征,其中面积影响就比较大,涉及到权重问题。)
<3>特征降维
原始特征:[x₁, x₂, x₃, ..., xₙ] (n维)
↓ 降维处理
新特征:[z₁, z₂, ..., zₖ] (k维,k << n)
<4>特征选择
从已经有的特征中,找出子集
比如原来10个特征,选择其中6个来用
<5> 特征组合
利用已有的特征,组合成新的特征
比如房子的 (朝向+面积)-> (新特征)
把多个特征合并成一个特征,利用乘法或者加法来完成
4.机器学习(模型训练)
<1> 线性回归
<2> 逻辑回归
<3> 决策数
<4> GBDT
5.模型评估
<1> 回归评测指标
<2> 分类评测指标
<3> 聚类评测指标
五、拟合
1.拟合 fitting 用在机器学习领域,用来表示模型对样本点的拟合情况
2.欠拟合 under-fitting 模型在训练集上表现很差、在测试集表现也很差
3.过拟合 over-fitting 模型在训练集表现很好、在测试集表现很差
泛化 Generalization: 模型在新数据集(非训练数据)上的表现好坏能力。
奥卡姆剃刀原则:给定两个具有相同泛化误差的模型,较简单的模型的优先选取。
这里可以理解为:
开发过程:
过拟合和欠拟合:模型在训练集和测试集效果
上线:
泛化:评估模型在新数据集上的效果

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)