OpsPilot:面向企业业务系统的智能运维 Agent 平台(1)
开始
在运维工作中,我们管理的系统会越来越复杂,比如说数十个微服务、多种中间件(Redis、Nginx、RabbitMQ、Elasticsearch)、跨云多节点的容器集群,这些组件每天产生海量日志和指标。传统的监控方式——登录机器观察或者依赖几个固定面板可能早已力不从心,所以我们需要一个能统一采集、存储、查询、告警的监控体系。我们团队希望以Prometheus为基础,结合AI agent,做出一款智能运维平台以辅助运维人员的日常决策。
以下是我对于此项目的前期准备与思考。
Prometheus的介绍
Prometheus 是一个开源的系统监控与警报工具包。它以多维数据模型(指标名称+键值对标签)存储时间序列数据,提供灵活的 PromQL 查询语言,采用 HTTP 拉取模型采集指标,并可通过 Pushgateway 支持短期任务推送。核心组件包括 Prometheus Server、客户端库、Exporter、Alertmanager 等,具有单节点自治、服务发现、多图形化等特点,广泛应用于云原生环境的监控。
架构
其架构图如下所示:
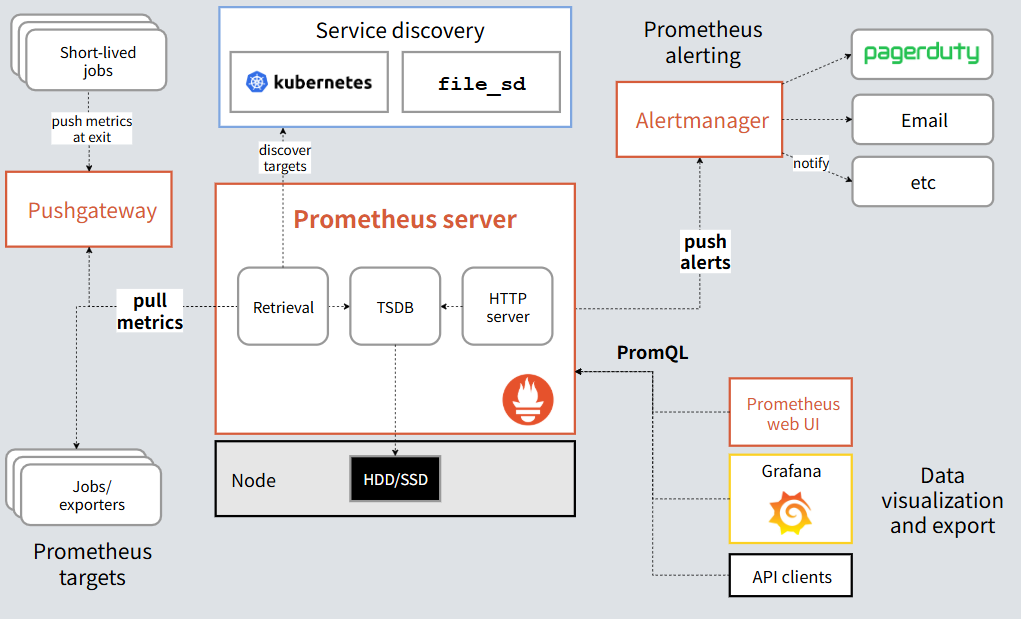
其中我详细探究了Prometheus中的pull模式和pushgateway:
| 类型 | pull | pushgateway |
| 数据流向 | Prometheus → 目标服务 | 任务 → Pushgateway → Prometheus |
| 适用对象 | 长期运行的服务 | 短期批处理任务 |
| 典型场景 | API 服务、数据库、Node Exporter | 每日备份、数据清洗、定时报表 |
有关于pushgateway的代码示例如下:
push_to_gateway(
pushgateway_url,
job=job_name,
registry=registry
)这行代码位于 push_metrics 函数内,作用是将定义好的指标(records_total、task_status、task_duration)通过 Pushgateway 推送到 Prometheus。
代码示例
from prometheus_client import start_http_server, Summary
import random
import time
# Create a metric to track time spent and requests made.
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
# Decorate function with metric.
@REQUEST_TIME.time()
def process_request(t):
"""A dummy function that takes some time."""
time.sleep(t)
if __name__ == '__main__':
# Start up the server to expose the metrics.
start_http_server(8000)
# Generate some requests.
while True:
process_request(random.random())这段代码是一个使用 Prometheus 客户端库的 Python 示例,用于暴露应用程序的性能指标(如请求处理时间)供 Prometheus 监控系统抓取。
1. 导入模块
prometheus_client 是官方 Python 客户端,用于生成和暴露 Prometheus 指标。
Summary 是一种指标类型,用于统计事件(如请求)的持续时间和数量,可以计算分位数(如 0.5、0.9、0.99)。
random 和 time 用于模拟随机处理时间。
2. 定义 Summary 指标
创建一个名为 request_processing_seconds 的 Summary 指标,描述为“处理请求所花费的时间”。
该指标将自动记录每次被装饰函数调用的耗时,并统计总数、总和以及分位数。
3. 使用装饰器监控函数耗时
@REQUEST_TIME.time() 装饰器会自动记录函数 process_request 的执行时间(以秒为单位)。
每次调用该函数时,指标会记录一次观测值(即执行耗时)。
4. 主程序
start_http_server(8000) 启动一个 HTTP 服务,监听 8000 端口。Prometheus 通过访问 http://localhost:8000/metrics 获取指标数据。
进入无限循环,每次生成一个随机浮点数(0~1 之间)作为模拟的处理时间,调用 process_request,从而不断产生指标数据。
代码运行结果
代码运行结果如图:
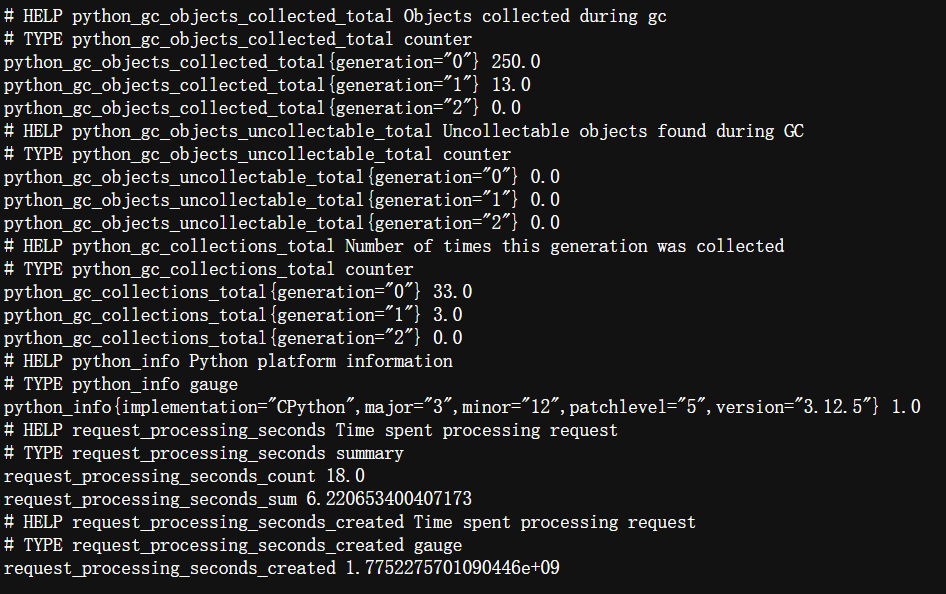
main.py 通过 prometheus_client 暴露了两类指标:Python 运行时指标(如垃圾回收次数 python_gc_collections_total、回收对象数 python_gc_objects_collected_total、环境信息 python_info)和你自定义的 Summary 指标 request_processing_seconds。其中,request_processing_seconds_count 表示 process_request 被调用了18次,_sum 为总耗时约 6.22秒,平均每次约 0.35 秒,与代码中 random.random() 的 0~1 秒随机 sleep 相符;GC 指标显示年轻代回收了 33 次、250 个对象,无内存泄漏。这些数据证明了 Prometheus 客户端正常工作,能够持续收集并暴露服务的行为指标。
其他技术需求
除了核心的Prometheus之外,我还需要掌握其他与AI相关的工具以完成开发。
| 组件 | 类型 | 核心作用 | 具体职责 | 关键特性 |
| FastAPI | Web框架 | 提高高性能异步API服务 | 作为监控系统的统一入口:接收用户查询请求、接收 Prometheus Alertmanager 的告警回调、对外暴露 /metrics 端点供 Prometheus 拉取自身健康指标 |
自动生成 OpenAPI 文档、依赖注入、异步支持、与 Prometheus 客户端集成方便 |
| MCP | 协议/工具集成层 | 标准化 AI Agent 与外部工具/数据源的交互 | 封装运维动作为可调用的工具集:query_prometheus(执行 PromQL)、get_logs(查询日志)、run_playbook(执行运维脚本)、send_notification(发送告警) |
支持 stdio/HTTP 传输、工具自动发现、类型安全、与 LangGraph 无缝集成 |
| LangChain | 开发框架 | 构建LLM应用的基础组件(模型、提示、链记忆) | 提供基础能力:格式化提示词、管理对话记忆、定义工具调用模式、连接不同 LLM。在监控系统中用于构建可重用的分析链(如“异常检测 → 根因分析 → 建议生成”) | 模块化设计、大量内置工具/链、与 LangGraph 互补使用 |
| LangGraph | 编排框架 | 基于图结构的状态机agent编排 | 实现智能监控 Agent 的决策流程:定义分析步骤的 DAG(计划 → 调用 MCP 工具 → 推理 → 决策)、支持循环与分支、持久化状态。用于自动化执行多步运维分析(如 CPU 飙升根因分析) | 图结构状态机、支持人机回环、可观测性、与 LangChain 组件兼容 |
工作流
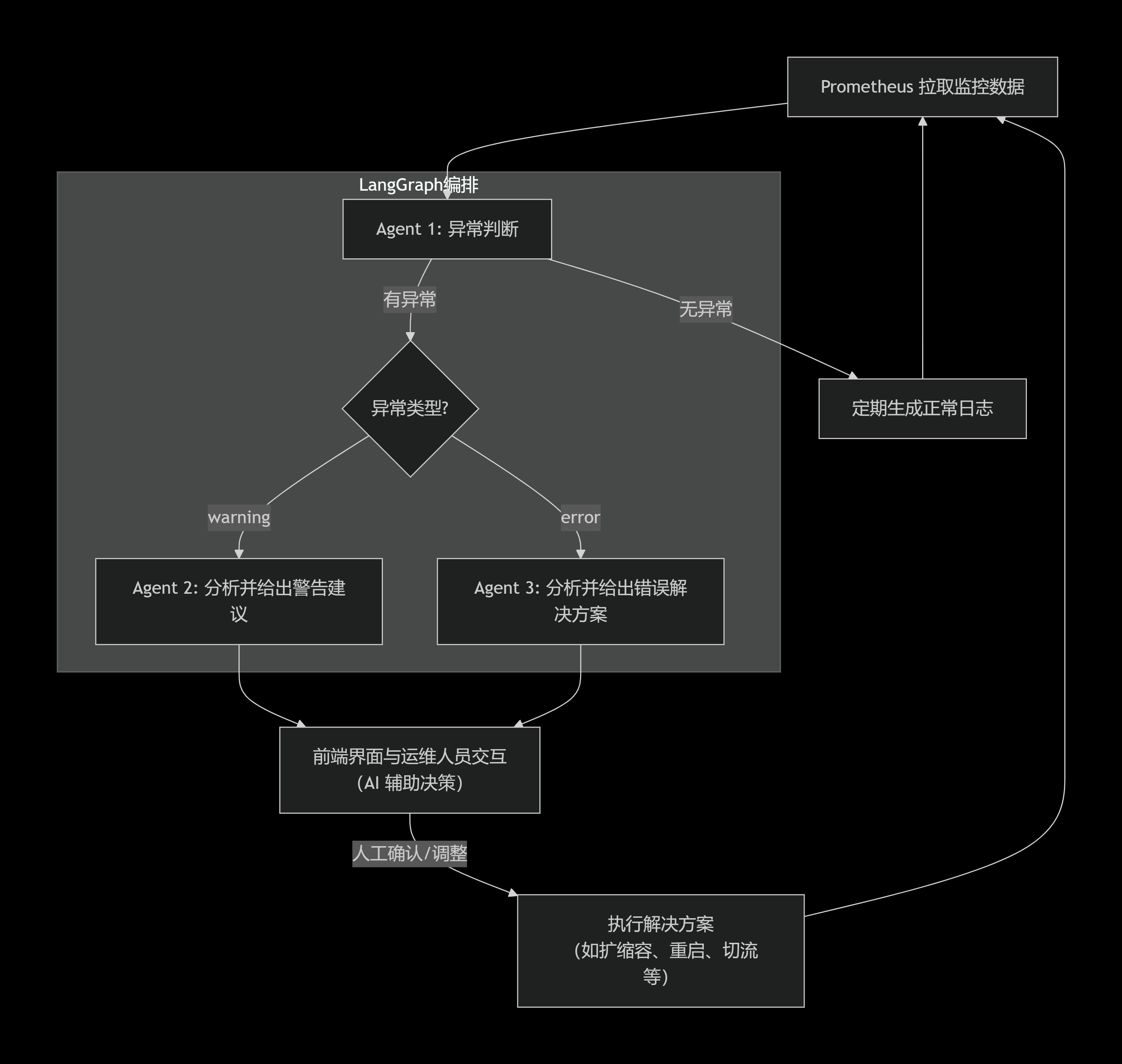
关于此项目,我们团队初定的工作流大致为:先通过Prometheus拉取监控数据,在交由第一个agent进行判断,如果无异常就每隔一段时间生成日志,否则交由下一个agent(或多个agent共同)决定warning或error的解决方法(此时运维人员可通过前端界面与AI进行交互)。不同agent之间使用langgragh进行编排。
流程图大致如下:
总结与展望
初步探索后,我已初步搭建起以 Prometheus 为数据源、LangGraph 编排多智能体的监控分析原型,实现了从指标采集、查询到异常判断的基础链路。下一步我将将继续学习前端界面开发,提供与智能体交互的可视化界面,并且我们团队持续优化工作流,如丰富 MCP 工具集、完善状态路由、引入人工反馈(我们试想可以找到一位真正的运维人员进行咨询),最终实现分析、决策与执行的闭环,打造真正辅助运维的智能体系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)