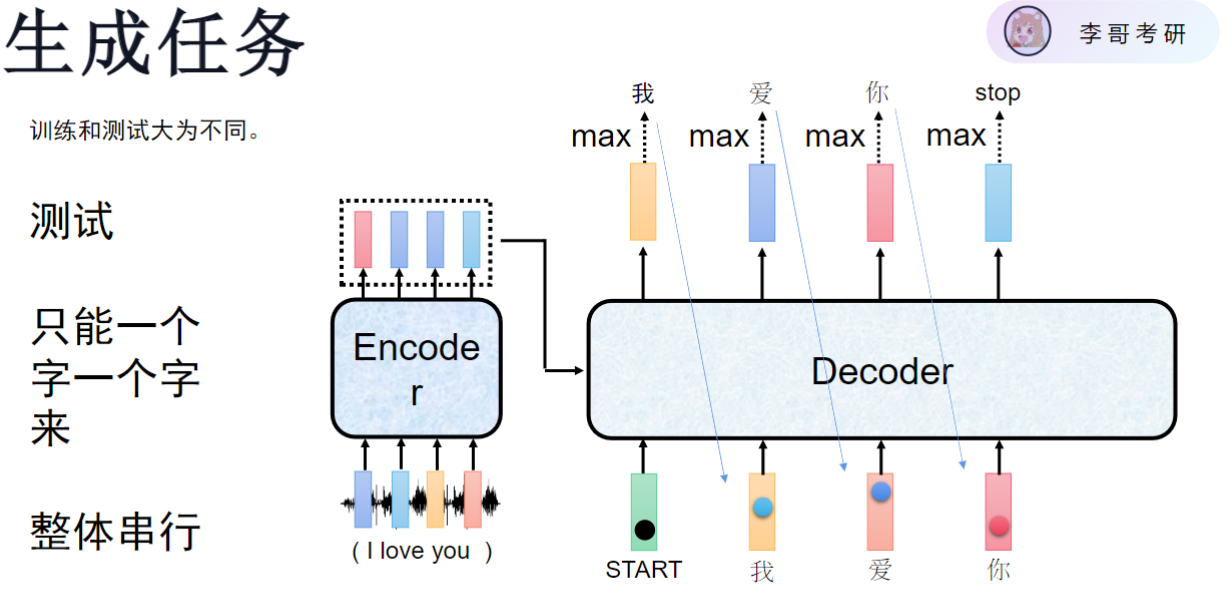
文字生成任务,大模型基础

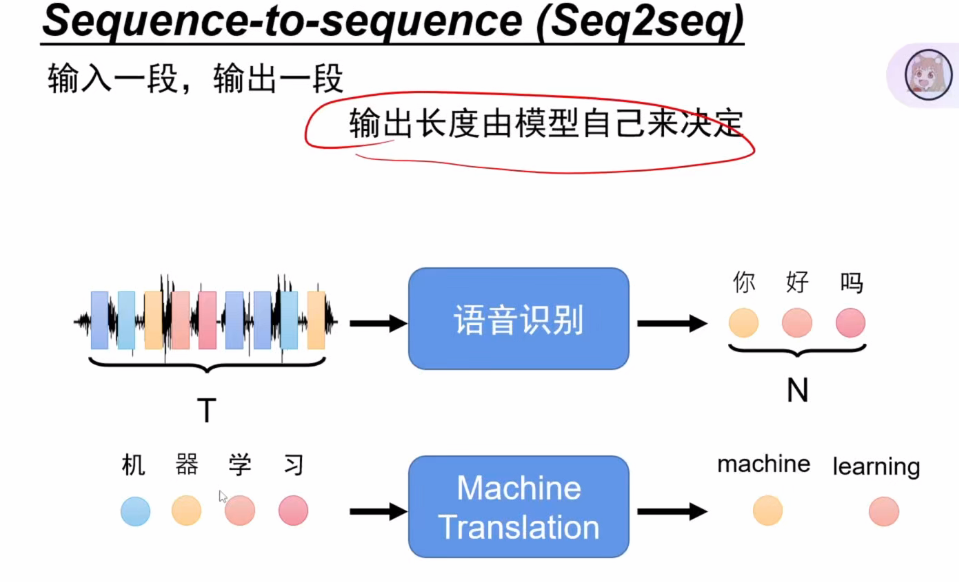
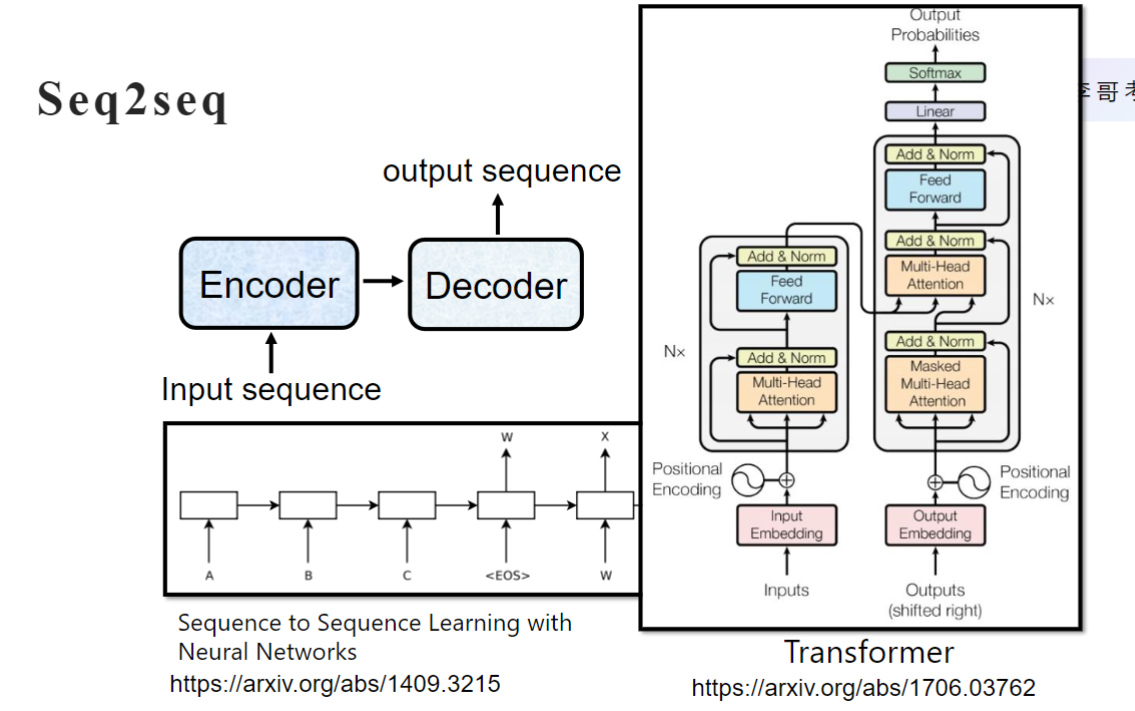
Seq2seq模型同Transformer架构一样分为Encoder和Decoder,Transformer出现后,Transformer成为主流架构
- 两大组件:
- Encoder(编码器): 处理输入序列
- Decoder(解码器): 生成输出序列
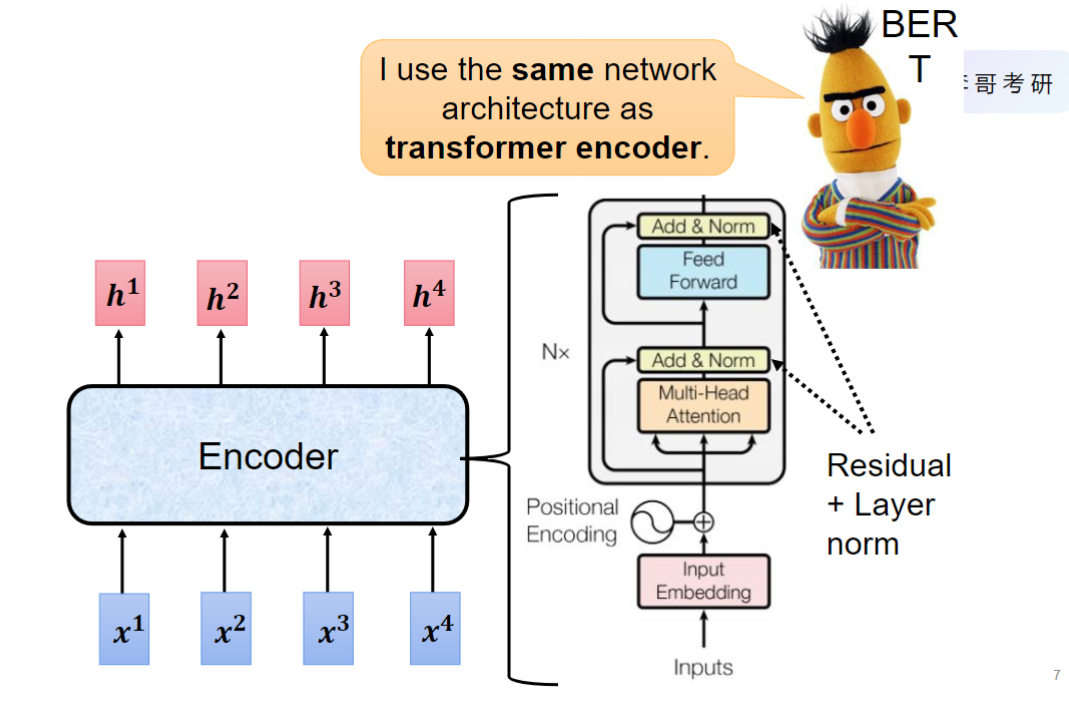
Encoder(编码器)与BERT几乎完全相同,主要区别在于输入处理部分,仅需将输入ID和位置编码相加,不需要额外的句子编码(规定只输入一句话)
-
- 文字生成
- 基本原理:通过分类任务实现文字生成,从21128个汉字中选择一个
- 核心思想:每个字的生成都是一道选择题,模型预测概率最高的字
- 文字生成
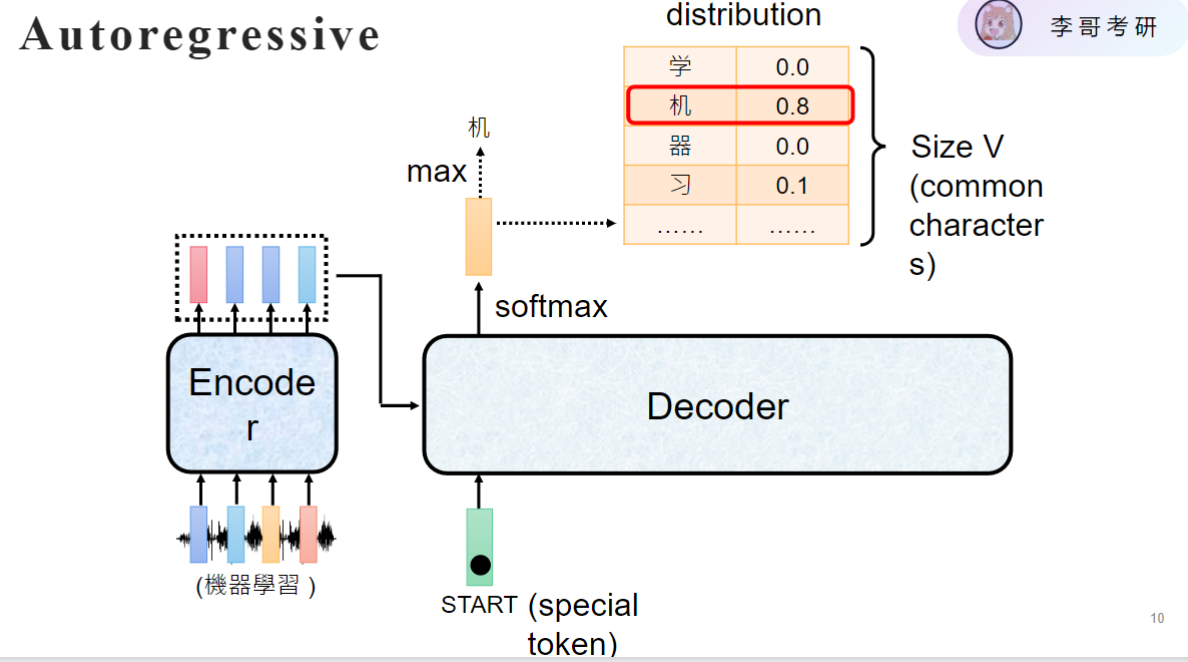
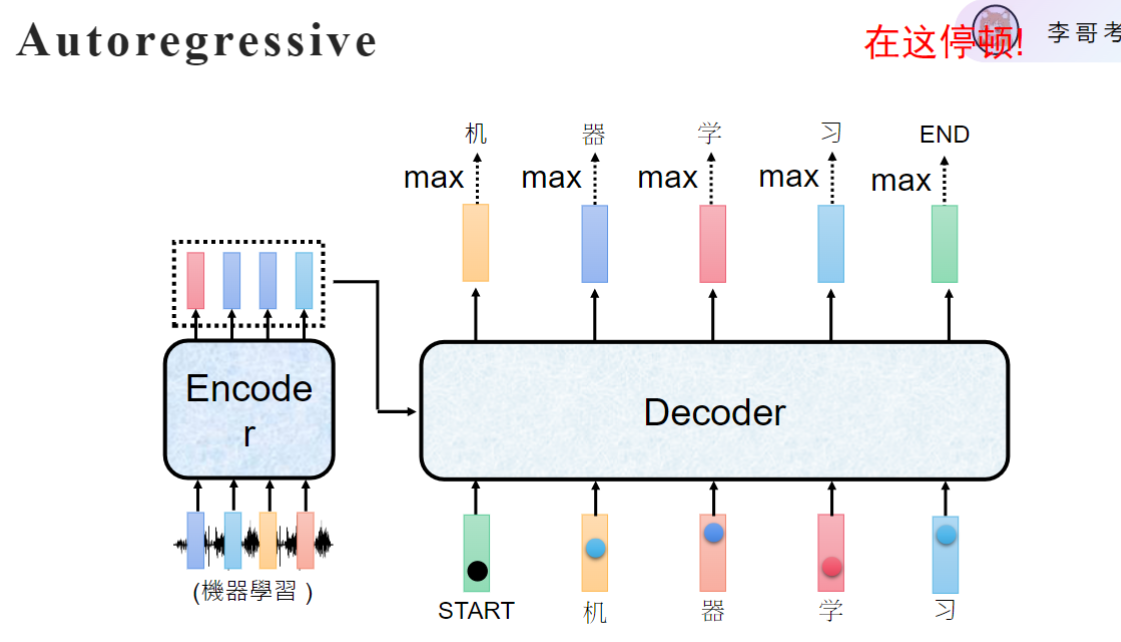
这种方法称为自回归。
- 工作流程:
- 输入START token开始推理
- 每次生成一个字后,将该字作为下一步输入
- 重复直到生成结束
- 存在问题:
- 错误累积:前一步错误会导致后续连续错误
- 串行处理:无法并行计算,速度受限(最重要的一点)
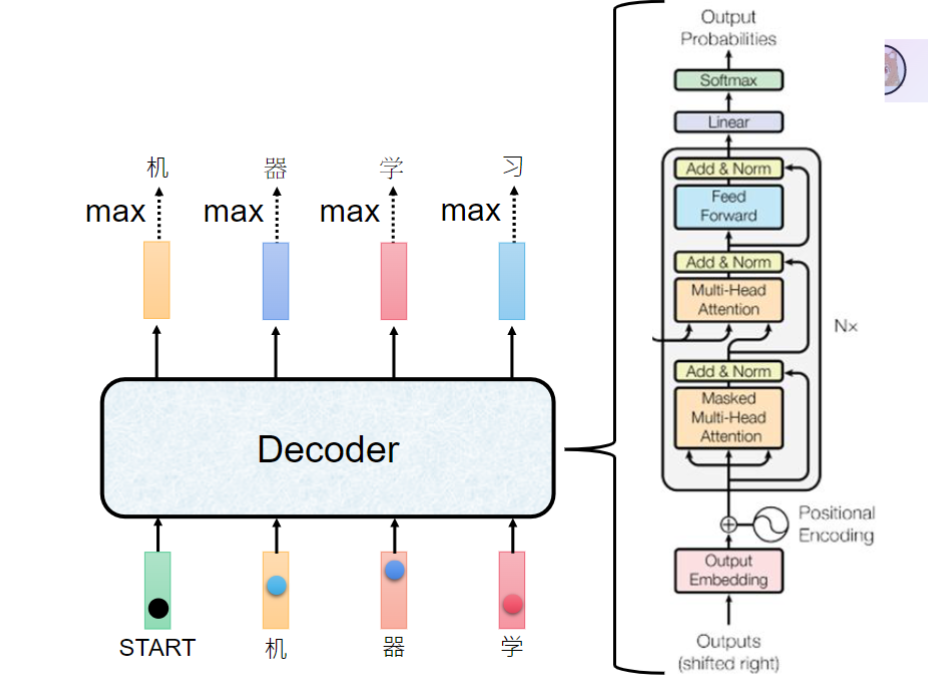
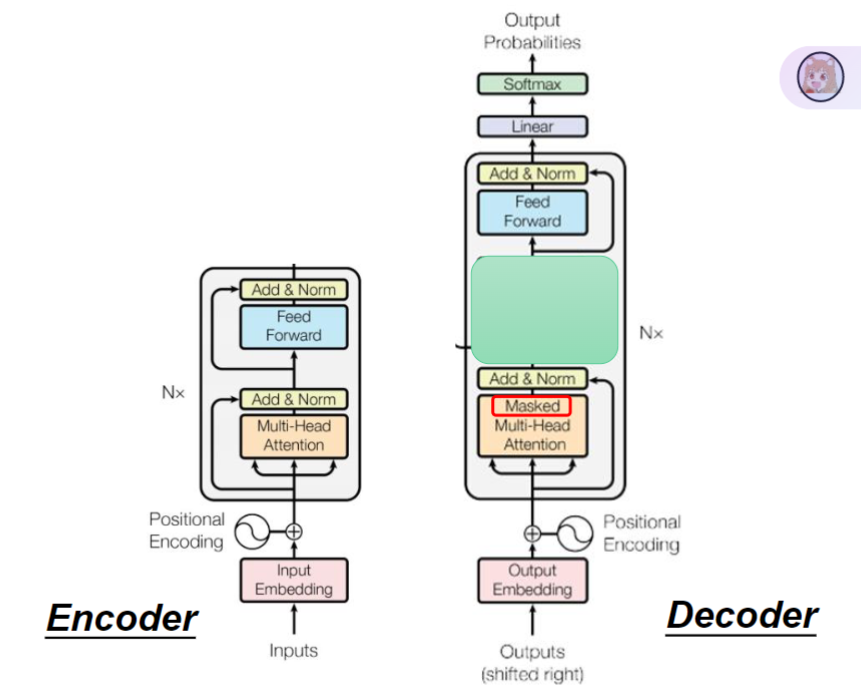
Decoder(解码器)与Encoder(编码器)很像,主要区别在于掩盖自我注意力
为了实现并行输入,我们是有x有y进行训练的(繁体转简体任务)。那你的y是一定正确的,那我把y当做抵扣的输入
可以实现并行,我直接把label全部拿过来,机器学三个字,前面加个start就可以当做decoder的输入,直接输入进去,得到所有的输出。直接并行。但有人作弊,对于self attention来说,
他是要去看别人所有人的特征的,他看了这个机字,看了气字,看了学字,然后。出来一个特征,得到一个结果。
这个机字我是希望你通过这个encoder的,这输出的特征来推出来的,它通过self attention架构的时候,它本身就可以看到这个第二个字是鸡字,他直接把这个字输出就行了,他不需要看其他任何东西,准确率100%。但是这种是我们想要的吗?显然不是我们想要的
我们不能让我的start第一个token看见后边的字,我这个机字输入的时候。所以怎么做?
就是mask。
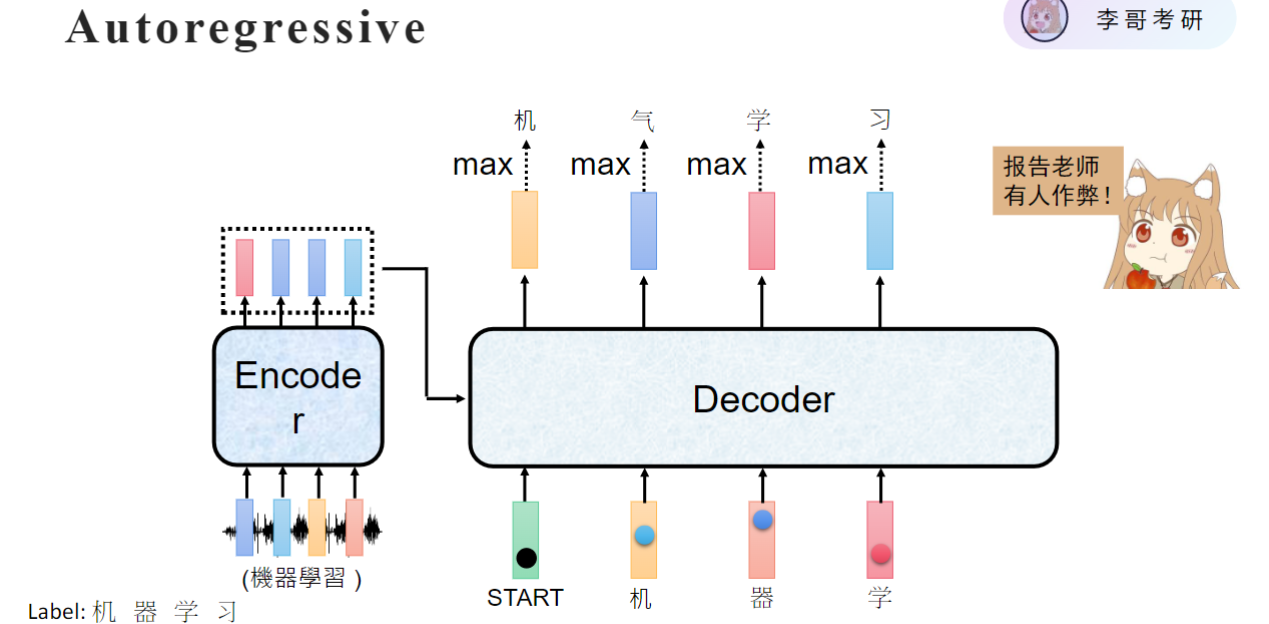
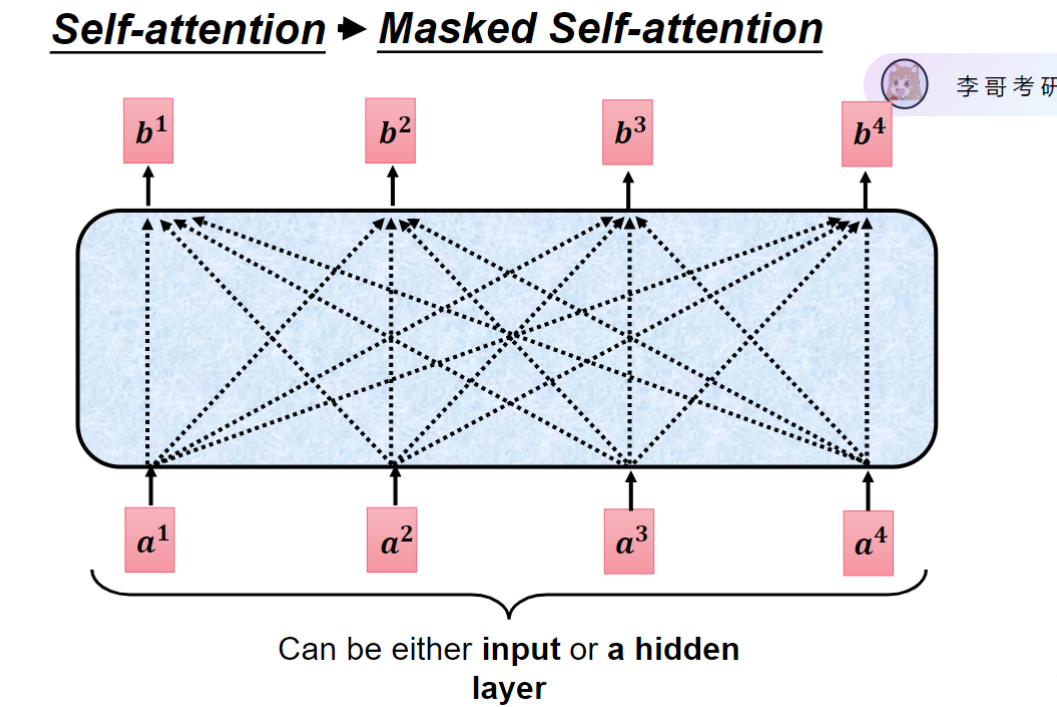
它是看了a1a2a3a4全部得到一个结果才输出。其实我很简单,我就让它只看a1不就行了吗?进化成mask的self attention就是把后面的全部mask把a1输入的时候,把a1后面的全部mask
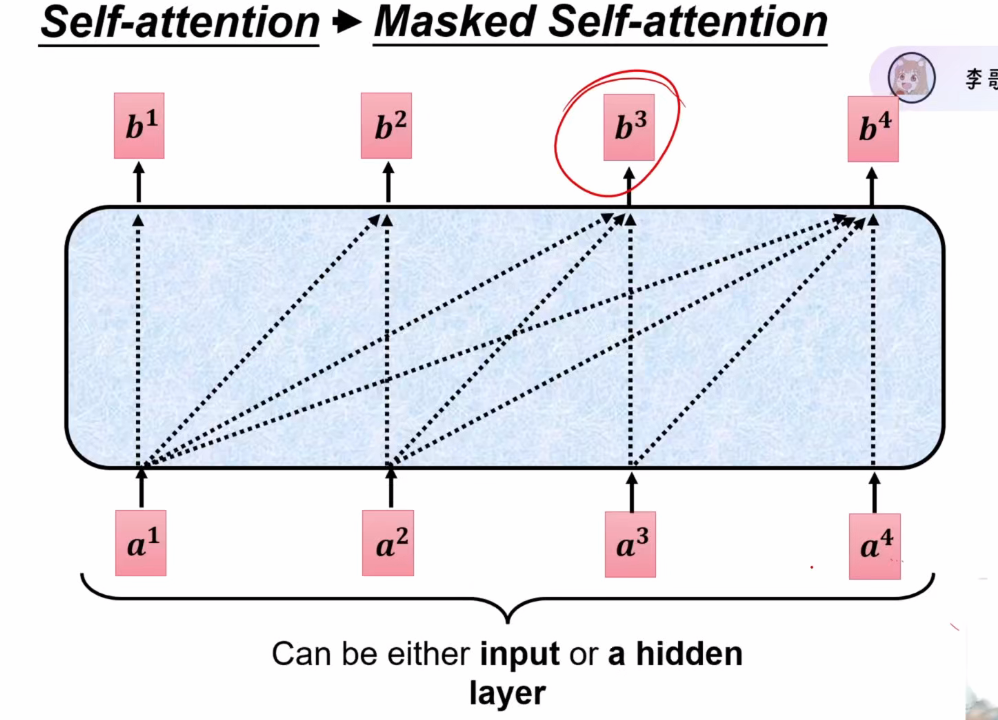
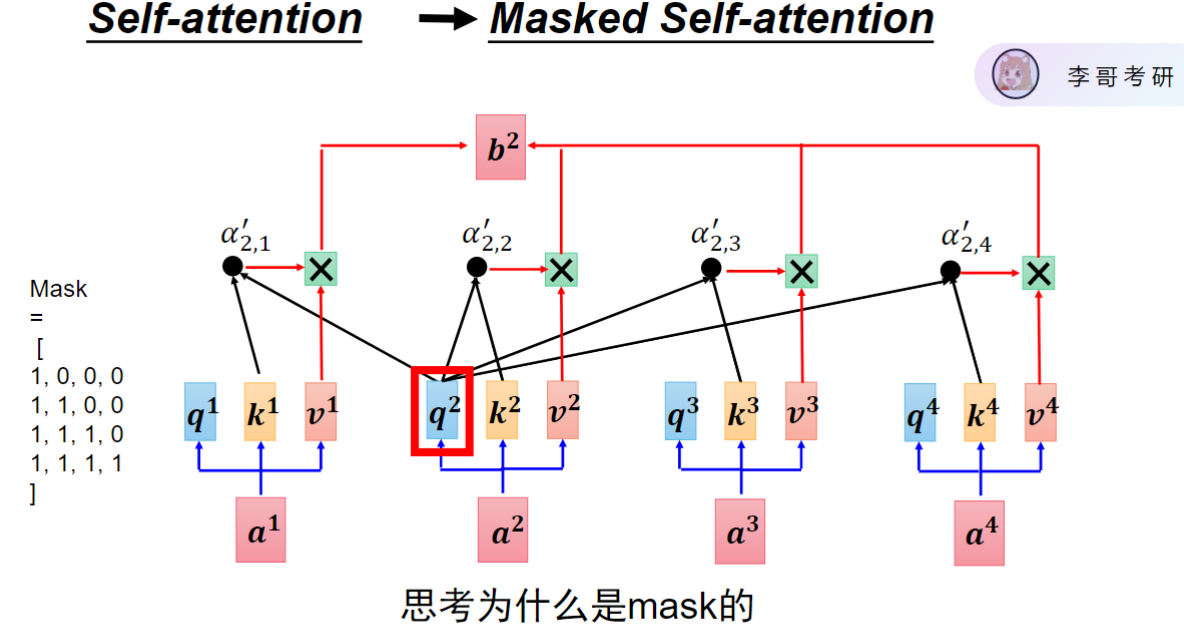
- 实现方式:使用上三角矩阵将未来位置的信息mask为0
- 优势:
- 防止模型"作弊"看到正确答案
- 允许使用标签作为训练输入
- 实现并行训练
- 作用原理:每个token只能看到自身及之前的token信息
- 优势:
-
-
-
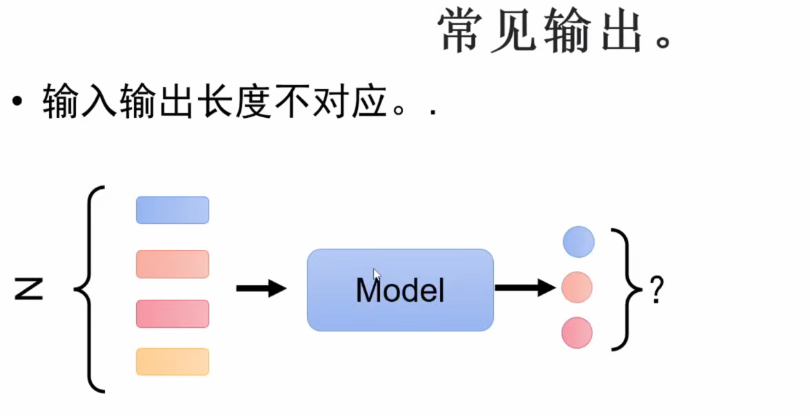
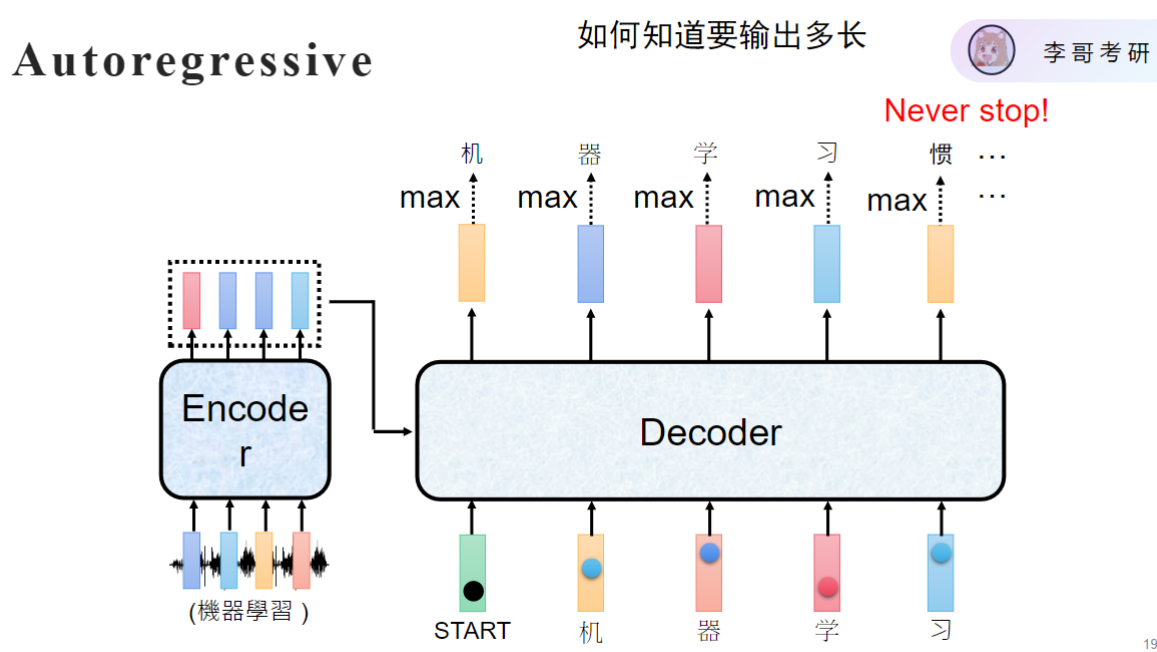
- 长度问题:输入输出长度可能不对应
- 解决方案:在词表中添加特殊END token(21128→21129)结束标记
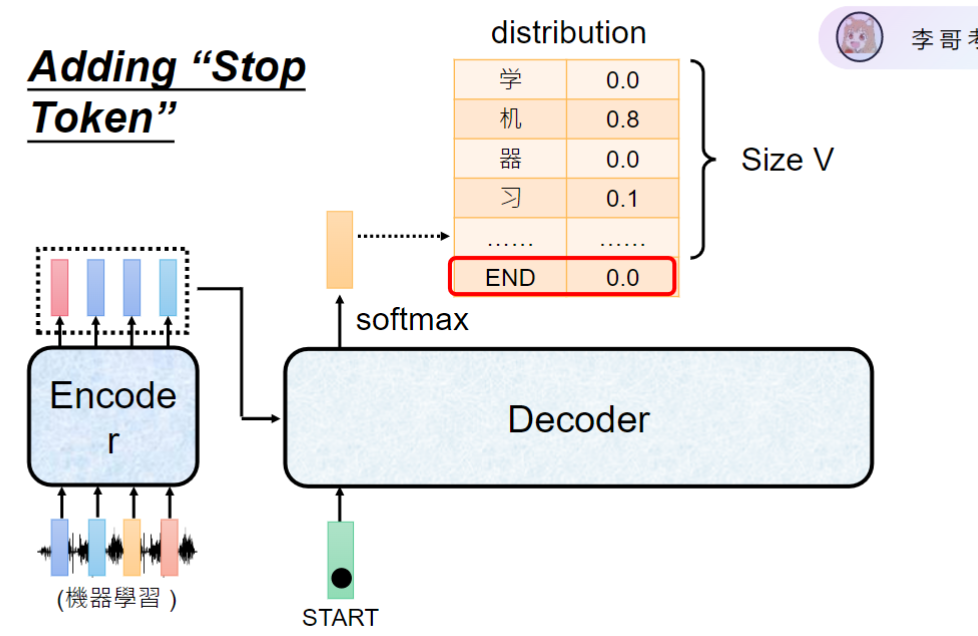
- 工作机制:当模型输出END token时终止生成
- 应用示例:生成"机器学习"后输出END停止
- 优势:灵活控制输出长度,不受输入长度限制
-
-
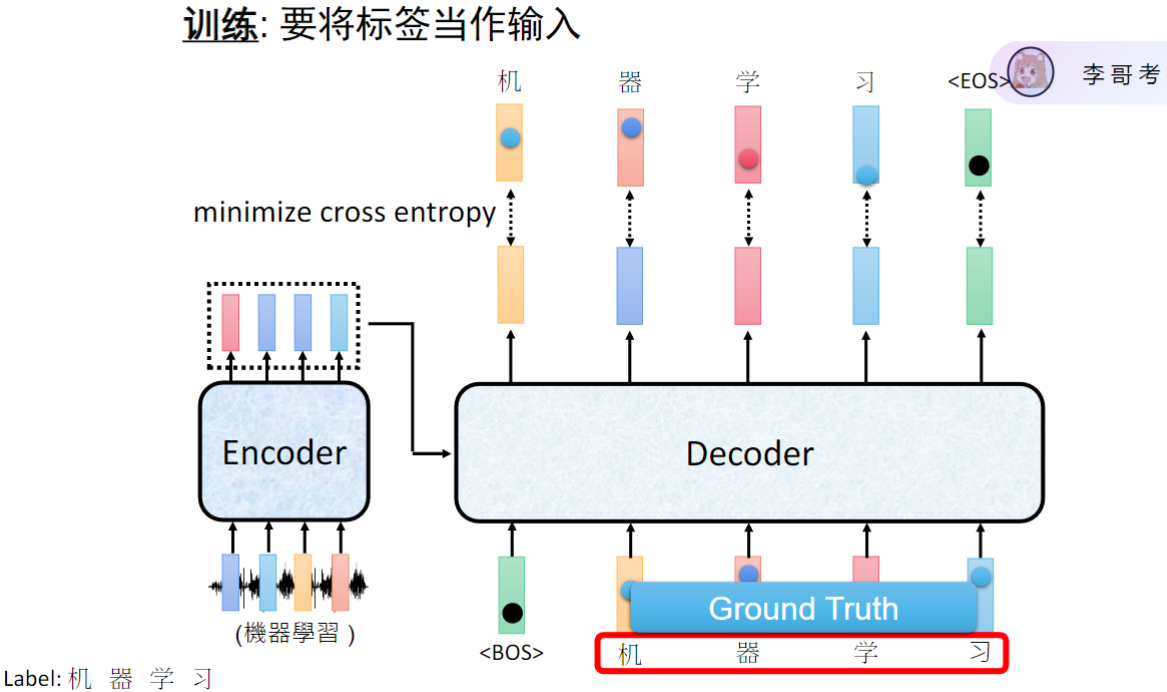
序列到序列任务训练的基本流程
- 训练机制:采用Encoder-Decoder架构,输入序列经过编码器处理后,由解码器生成输出序列
- 输出生成:每个时间步输出一个字,经过softmax得到概率分布,选择概率最高的字作为输出
- 标签使用:训练时使用真实标签(ground truth)作为监督信号,通过交叉熵损失计算预测值与真实值的差异
2. 序列到序列任务的输入输出长度关系
- 输入构成:输入为<BOS>(开始标记)拼接真实标签,例如输入"<BOS>机器学习"
- 输出构成:输出为真实标签拼接<EOS>(结束标记),例如输出"机器学习<EOS>"
- 长度关系:输入输出长度始终保持一致,等于标签长度加1(开始/结束标记各占1位)
- 并行处理:训练时由于已知完整标签,可以并行计算所有时间步的损失
3. 序列到序列任务的loss计算与模型训练
- 损失计算:每个时间步计算预测分布与真实标签的交叉熵损失,对所有时间步求平均
- 标签定义:真实标签y为完整输出序列(含<EOS>),预测值为y_pred
- 训练过程:通过最小化交叉熵损失来更新模型参数
- 术语说明:ground truth即真实标签,在生成任务中特指完整的目标序列
三、序列到序列任务的推断
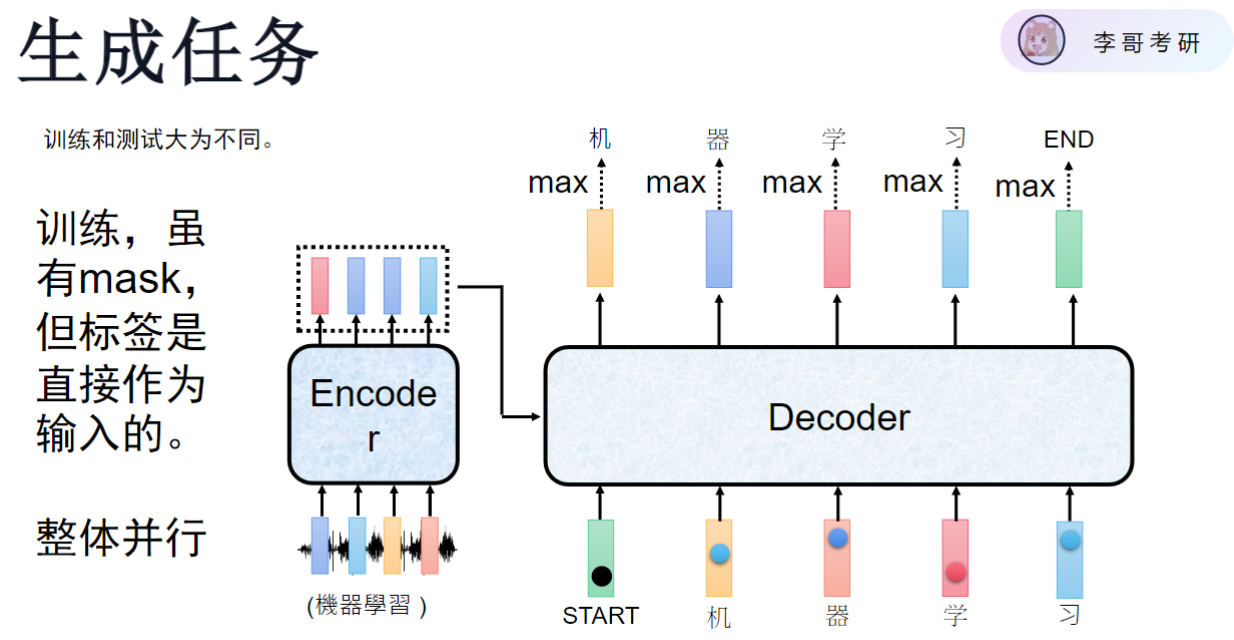
1. 训练与推断的区别
- 训练特点:使用完整标签作为解码器输入,采用mask实现并行计算
- 推断特点:没有真实标签可用,只能串行生成,前一步输出作为下一步输入
- 速度差异:推断速度远慢于训练,可能慢数百倍,因无法并行计算
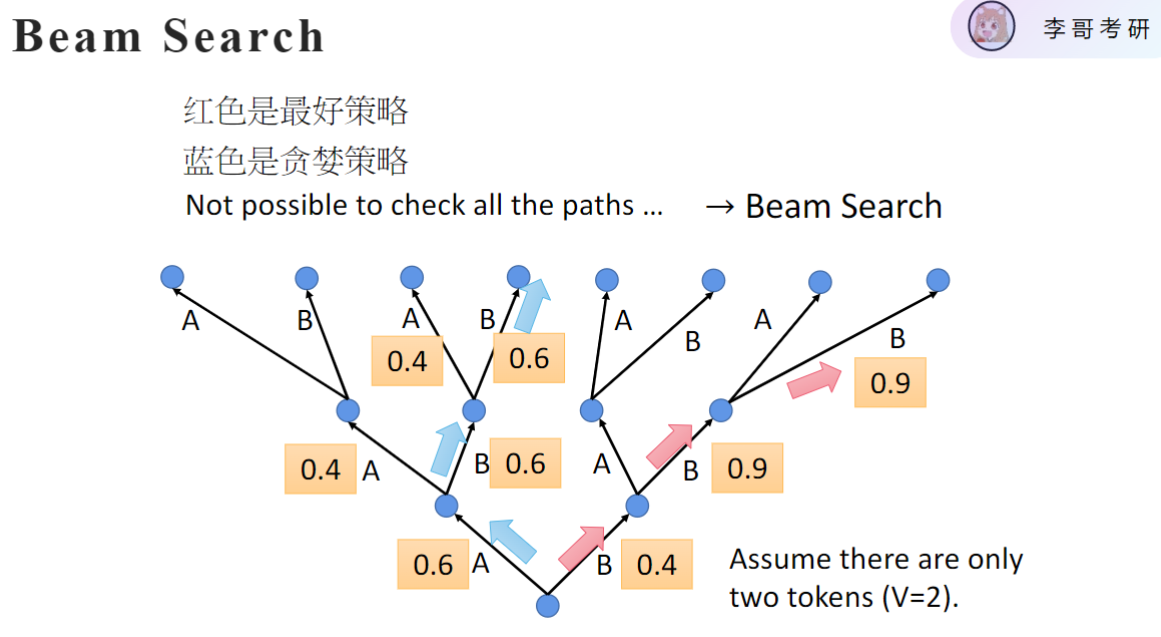
2. beam搜索(规定你每次看的步数)
- 基本概念:在生成每个词时保留多个候选序列(beam width),而非仅选择当前最优
- 贪婪策略:beam width=1时退化为贪婪搜索,每步只选概率最高的词
- 全局优化:通过增大beam width可以考虑更优的全局序列,但计算量指数增长
- 计算代价:beam width为k时,每步需计算k×V个候选(V为词表大小),显存消耗大
- 应用建议:根据硬件条件选择适当beam width,通常2-5之间
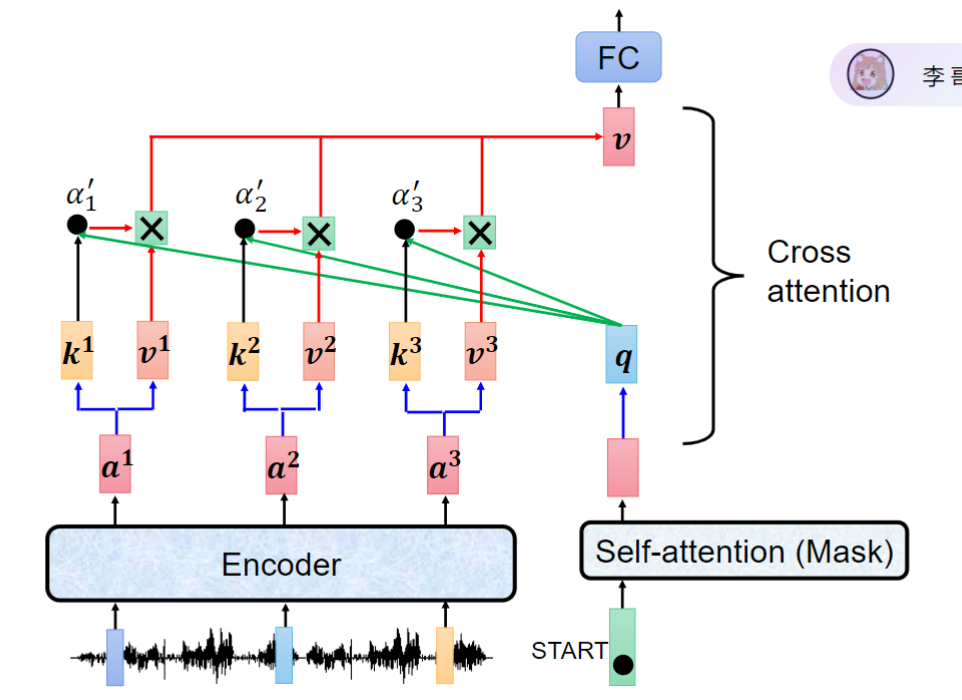
3. 交叉自注意力机制
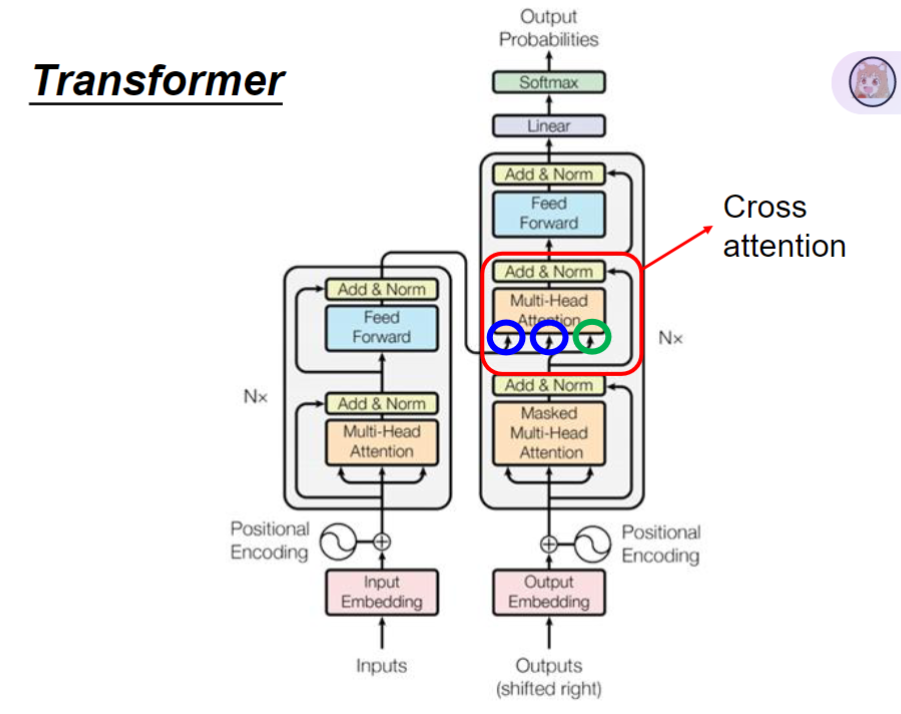
- 机制特点:解码器decoder的q向量来自自身输入,k和v向量来自编码器encoder输出
- 物理意义:解码器作为"扫码器"评估编码器输出的重要性
- 实现方式:self-attention处理解码器输入,cross-attention融合编码器信息
- 设计合理性:输出主要依赖输入内容而非起始标记,故k/v来自编码器

- 处理词表
18:09
- 词表是什么
- 本质:字/词与ID的映射关系表
- 功能:输入字词返回对应ID(如输入"猜"返回5)
- 规模特点:
- 英文词表约5万词项
- 中文词表约2万词项
- 关键要求:输入字符必须存在于词表中才能获取有效ID
- 为什么需要处理词表
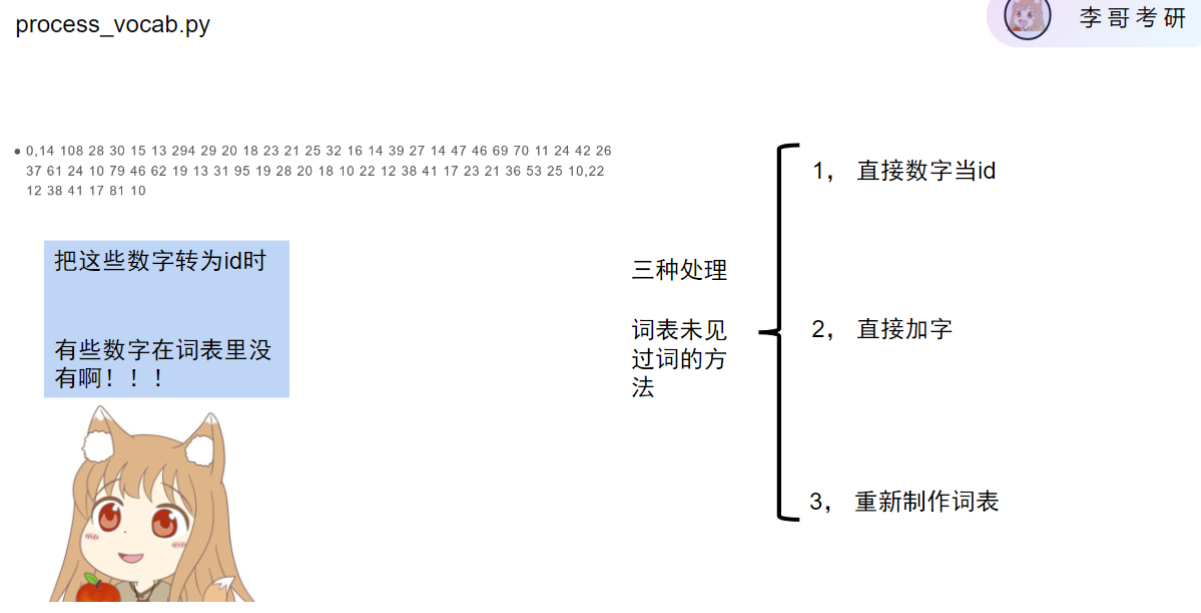
- 数字处理问题
- 核心矛盾:
- 数字组合无限性(如1019)与词表有限容量(2万项)的矛盾
- 医疗数据特有现象:医院生成ID可能超出预训练词表范围
- 后果:
- 无法查询到ID时导致数据无法输入模型
- 影响模型训练和预测流程完整性
- 核心矛盾:
- 数字处理问题
-
- 三种解决方案对比
- 方案1-直接数字当ID:
- 优点:实现简单
- 缺点:部分数字在词表中不存在会导致问题
- 方案2-直接加字:
- 方法:将未见数字添加到现有词表
- 缺点:无法解决原始词表噪声问题
- 方案3-重新制作词表:
- 核心思想:仅保留数据集中出现的数字
- 优势:完全消除噪声,词表精简(最终仅1297个数字)
- 实施步骤:统计数据集数字→构建纯数字词表→添加特殊token
- 方案1-直接数字当ID:
- 词表重构实现细节
- 关键操作:
- 直接使用数据集统计出的数字作为新词表基础
- 移除原有词表处理逻辑(如new_vocabs相关代码)
- 特殊token添加:
- 必要性:模型运行必需的基础功能token
- 6个关键token:
- [PAD]:填充token
- [UNK]:未知字符
- [CLS]:分类标记
- [SEP]:分隔符
- [MASK]:掩码标记
- [EOS]:结束标记
- 添加方式:通过vocab.insert()方法按指定位置插入
- 关键操作:
- 技术验证与项目应用
- 验证过程:
- 运行生成新词表文件(vocab.txt)
- 确认词表内容:仅包含数字+6个特殊token
- 项目价值:
- 测试结果:第三种方案效果最优
- 面试应答:可系统阐述问题发现→方案对比→决策依据→验证过程的技术思考链条
- 模型适配:
- 需要同步调整config.json中的vocab_size参数为1297
- 确保特殊token的ID与模型预期一致
- 验证过程:
- 三种解决方案对比
- 词表是什么
- 自监督预训练
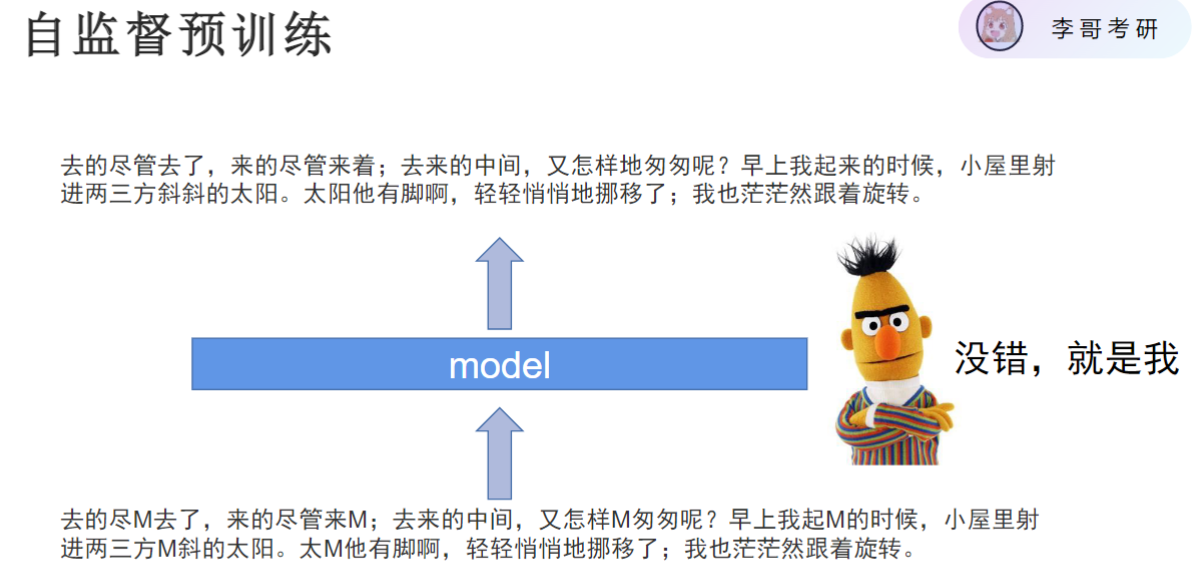
- 本质区别:与传统微调训练没有本质区别,都需要数据、模型、loss、梯度回传和模型更新,唯一区别在于loss的来源方式不同。
- 核心思想:将原始数据作为y,遮住部分数据作为x,让模型预测被遮住的内容。
- BART模型
- 模型优势:在摘要生成任务上达到最佳效果,特别适合从大段文本中提取关键信息的任务场景。
- 架构特点:由编码器(encoder)和解码器(decoder)组成,属于生成式模型。
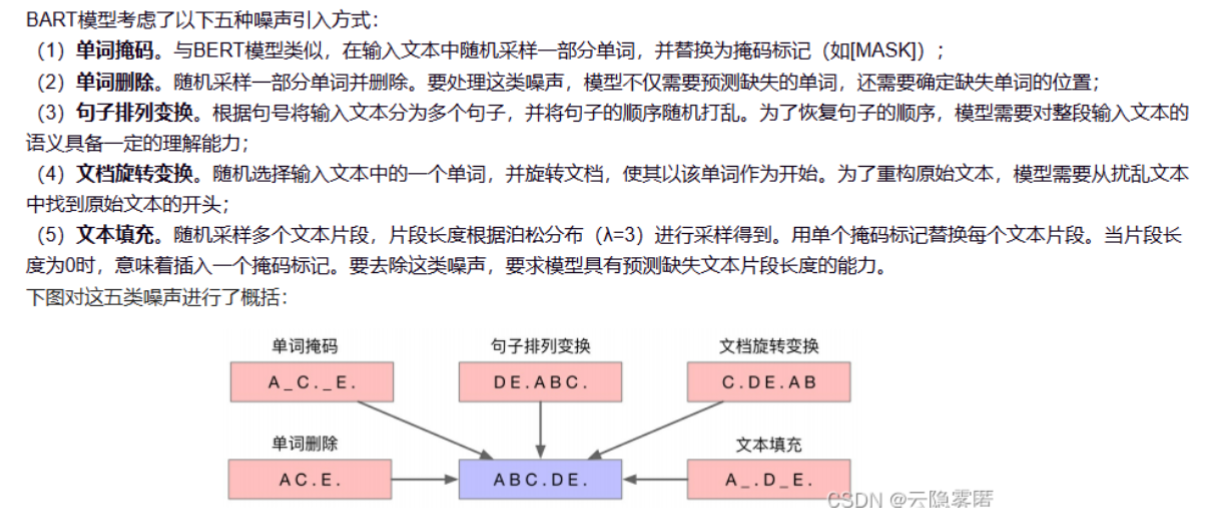
- 噪声处理:
- 单词掩码:随机替换为[MASK]标记(类似BERT)
- 单词删除:随机删除单词,需预测缺失内容及位置
- 句子重排:打乱句子顺序,需恢复原始语义
- 文档旋转:以随机词开头旋转文本
- 文本填充:用泊松分布(
λ=3\lambda=3λ=3
)采样片段替换为单个[MASK]
- 预训练过程
46:41
- 训练机制:
- 采用masked language modeling(MLM)方式
- 输入是被mask的文本,输出是完整原文
- 通过生成式预测(非BERT的一对一预测)
- 数据准备:
- 可使用训练集(x,y)、验证集x、测试集x
- 禁止使用验证集y(避免测试作弊)
- 标签设计:
- 被mask位置对应真实token id
- 未变化位置标记为-100(计算loss时自动忽略)
- 实验证明:输出张量与-100计算cross entropy loss结果为0
- 训练机制:
- BART模型详解
- 参数设置:
- 基础设置:随机种子(如2025)、dropout率(0.2-0.3)
- 训练参数:学习率3e-5
- 生成设置:beam search宽度、长度惩罚等
- 训练流程:
- 数据加载:通过PreTrainDataset处理MLM数据
- 模型初始化:preModel加载BART基础模型
- 优化器构建:使用build_optimizer配置
- 训练循环:计算mask位置的预测loss
- 关键差异:
- BART是生成模型(编码器+解码器)
- 预训练时采用更丰富的噪声引入方式
- 通过自回归方式生成文本(非BERT的填空式预测)
- 参数设置:
2. 典型训练循环结构
- 标准步骤:
- 前向传播计算损失
- 反向传播更新梯度
- 优化器执行参数更新
- 学习率调度器调整学习率
- 梯度清零准备下一轮迭代
13. 模型训练与loss计算
- loss获取:模型直接返回计算好的loss值(outputs.loss)
- 多卡适应:对loss求均值处理多卡训练情况
- 训练简化:无需手动计算loss,模型内置MLM损失函数
14. 优化器更新与学习率调整
- 优化器类型:使用AdamW优化器(torch.optim.AdamW)
- 参数配置:
- 学习率3e-5
- beta=(0.9,0.99)
- 权重衰减0.0
- 学习率调度:采用LambdaLR策略
CiderD_scorer计算得分

- 评分机制:
- refs包含每个样本的多个参考描述
- cand包含生成的候选描述
- 使用CiderD计算两者相似度得分
- 参数说明:
- df='corpus'表示使用语料库频率
- 返回总score和各样本的scores
- 应用场景:常用于文本生成任务的自动评估

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)