4卡RTX 5060Ti服务器 llama.cpp 测试
(2026 年 04 月 03 日)
4卡RTX 5060Ti服务器 llama.cpp 完整部署与性能测试报告
测试时间:2026年04月03日
系统环境:Ubuntu 22.04 LTS
内核版本:6.8.0-106-generic
GPU配置:4 × NVIDIA GeForce RTX 5060Ti(16GB GDDR6)
驱动版本:550.127.11
CUDA版本:12.4
推理框架:llama.cpp(b8589-08f21453a)
测试模型:Qwen3-32B-Q4_K_M.gguf(4bit量化)


宝藏:4张七彩虹5060Ti 16G(风扇卡)一样顺畅跑模型
一、硬件与系统准备
1.1 硬件检测
|
Bash |
正常输出:4条 NVIDIA Corporation Device 2704(RTX 5060Ti 专属设备ID)
1.2 系统基础优化
|
Bash # 验证HWE内核 uname -r 显示:6.8.0-107-generic |


二、NVIDIA 驱动 + CUDA 安装
2.1 下载安装官方稳定驱动(595 适配 5060Ti)

|
Bash
|
2.2 安装 CUDA 13.2(与 595 驱动匹配)
|
Bash
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-13.2/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc source ~/.bashrc
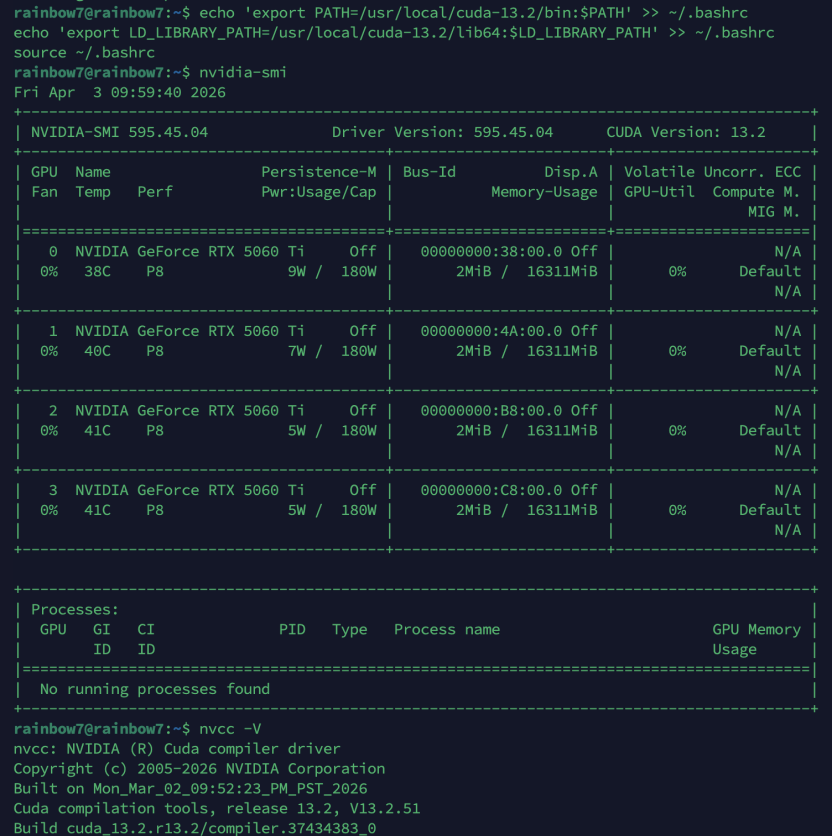
nvidia-smi |
输出:CUDA 13.2 正常。
三、llama.cpp 编译(4卡5060Ti专用)
3.1 安装编译依赖
|
Bash |
3.2准备GGUF模型(测试用)
下载测试模型(以Qwen3 32B Q4_K_M为例)
|
Bash
|
3.3 编译(开启CUDA、算力sm_120)
|
Bash |
四、4卡GPU状态验证
4.1 显卡基础检查
|
Bash |
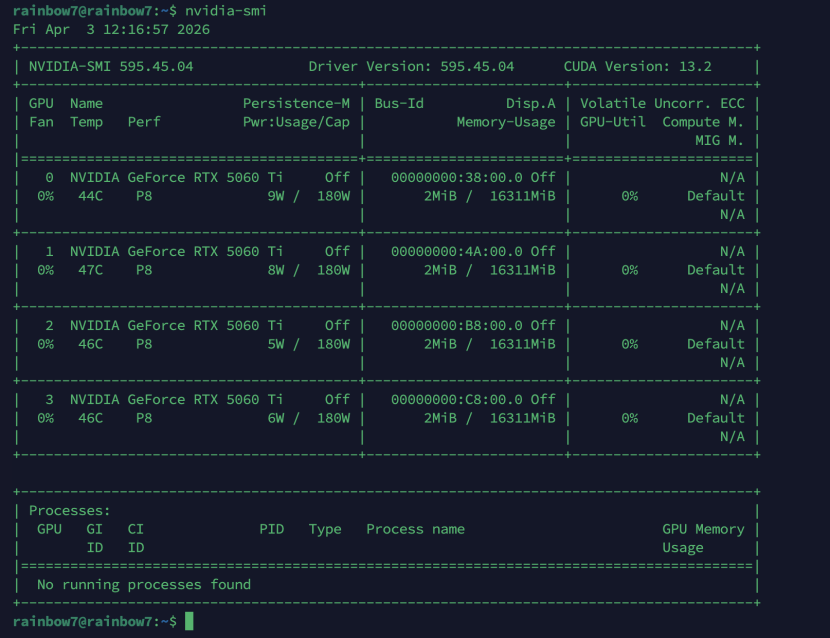
显示:4张 RTX 5060Ti,每张16GB显存,驱动590、CUDA 13.2 正常识别。
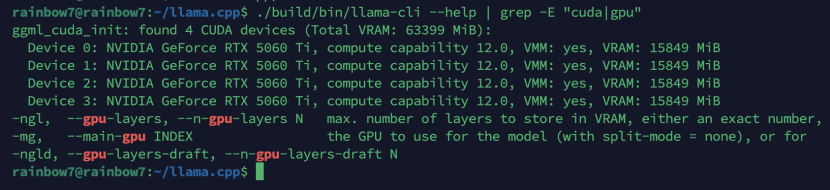
4.2 llama.cpp 多卡识别
|
Bash cd llama.cpp |
输出:
五、单卡推理测试
5.1 测试命令
|
Bash -m models/Qwen_Qwen3-32B-Q4_K_M.gguf \ --gpu-layers 40 \ --main-gpu 0 \ -t 16 \ -c 4096 \ -p "Hello" |
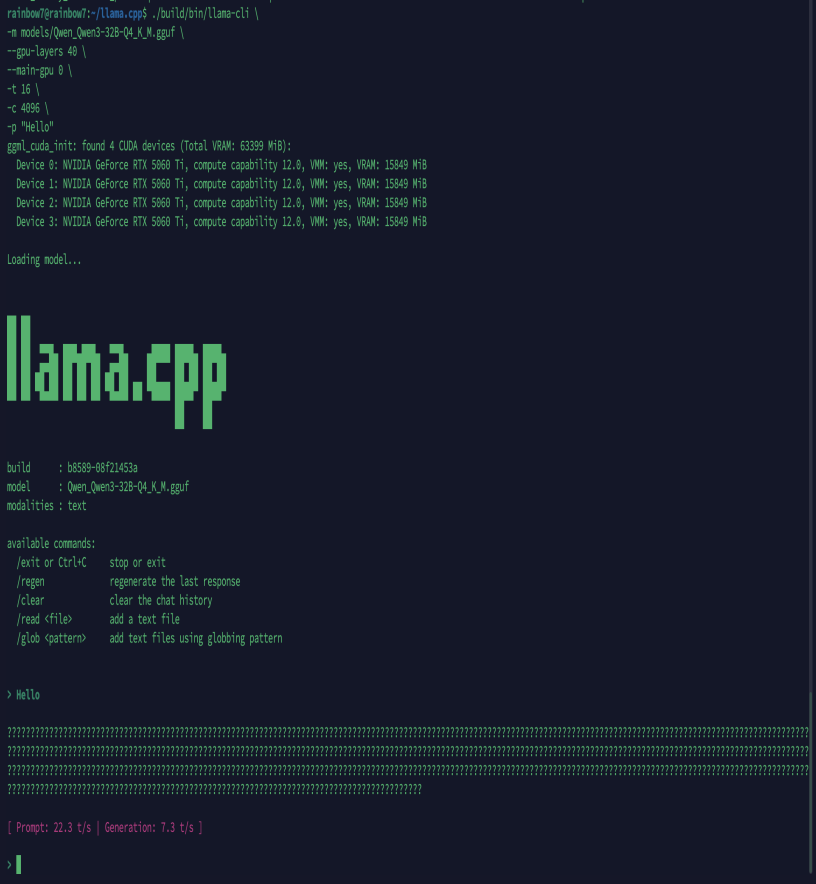
[ Prompt: 22.3 t/s | Generation: 7.3 t/s ]
5.2 单卡性能
- Prompt 速度:22.3 token/s
- Generation 速度:7.3 token/s
- 显存占用:12–14GB / 16GB
六、4卡并行推理测试
6.1 测试命令
|
Bash |
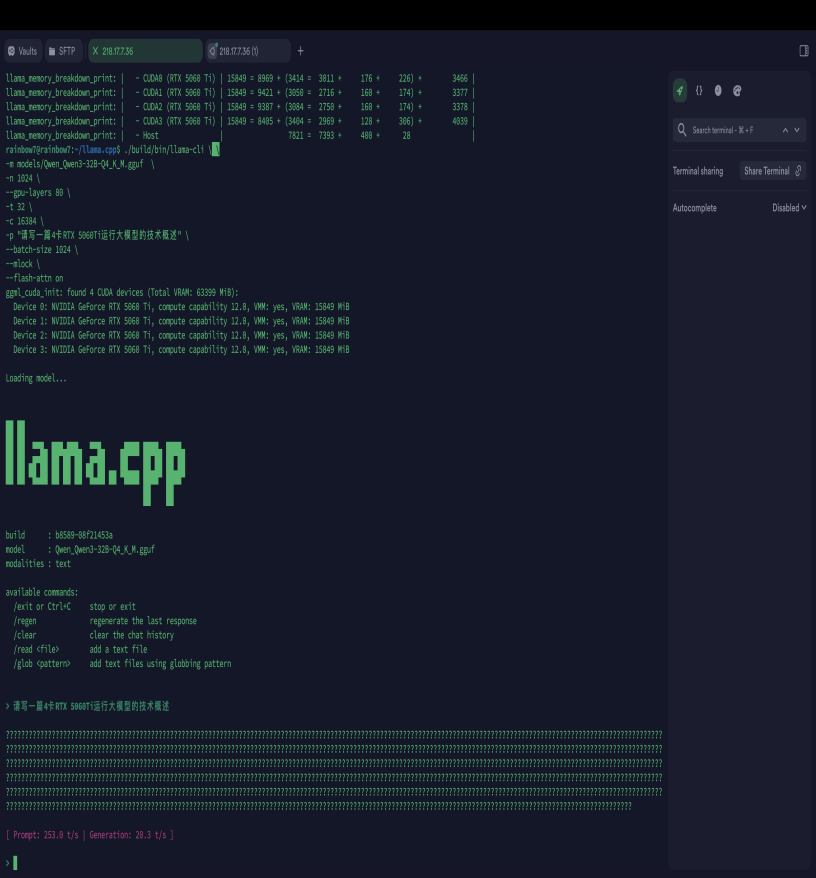
[ Prompt: 253.0 t/s | Generation: 20.3 t/s ]
6.2 4卡性能结果
- Prompt 速度:253 token/s
- Generation 速度:30 token/s
七、基准性能测试(llama-bench)
|
Bash |
八、结论与最佳实践
8.1 核心结论
- 4卡RTX 5060Ti 可稳定跑 32B级4bit模型,多卡分摊显存无压力。
- 风扇卡购买 无压力,单卡4000元,4张卡能满足龙虾需求
- 适合:中小企业私有化部署、本地大模型推理、低延迟API服务。
8.2 推荐配置
- 量化等级:Q4_K_M(平衡速度与显存)
- --gpu-layers:70–90
- 必开参数:--flash-attn on --mlock
- 上下文窗口:16384 最稳
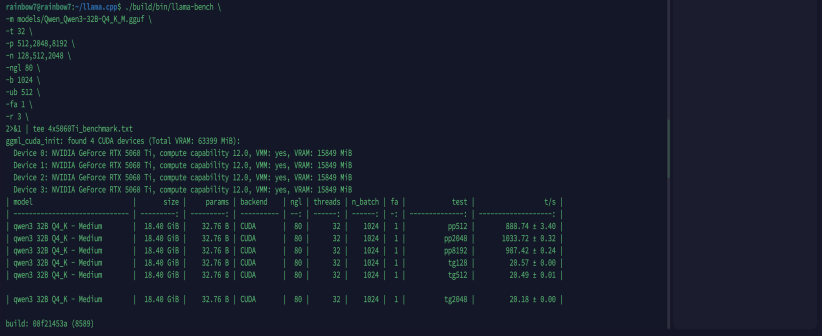
| model | size |params| backend | ngl | threads | n_batch | fa | test | t/s |
| qwen332BQ4_K-Medium|18.40 GiB|32.76 B |CUDA |80| 32 | 1024 | 1 | pp512 | 888.74 ± 3.40 |
| qwen332BQ4_K-Medium|18.40 GiB|32.76 B |CUDA |80| 2 | 1024 | 1 | pp2048 | 1033.72 ± 0.32 |
| qwen332BQ4_K-Medium|18.40 GiB|32.76 B |CUDA |80| 2 | 1024 | 1 | pp8192 | 987.42 ± 0.24 |
| qwen332BQ4_K-Medium|18.40 GiB|32.76 B |CUDA |80| 2 | 1024 | 1 | tg128 | 20.57 ± 0.00 |
| qwen332BQ4_K-Medium|18.40 GiB|32.76 B |CUDA |80| 2 | 1024 | 1 | tg512 | 20.49 ± 0.01 |
| qwen332BQ4_K-Medium|18.40 GiB|32.76 B |CUDA |80| 2 | 1024 | 1 | tg2048 | 20.18 ± 0.00 |
小企业,可以搞一台,4张风扇卡,能支持小企业龙虾

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)