人话版AI词典 | 第10期:什么是Embedding?AI大脑里的变形记
你有没有想过一个问题:AI是怎么理解"苹果"这两个字的?
它知道苹果是一种水果吗?知道苹果和香蕉都是水果、而不是蔬菜吗?知道苹果公司是卖手机的那家公司、跟真正的苹果有关系但又不太一样吗?
更重要的问题是——它是怎么知道这些的?
计算机本质上是处理数字的机器。它看到的永远是0和1。那"苹果"这两个汉字,在AI的"脑子"里,到底是怎么变成它能理解、处理、计算的东西的?
答案就是今天要讲的Embedding。
Embedding到底是什么?
Embedding,中文翻译是"嵌入"或"向量化"。听起来挺玄乎,但核心思想不复杂。
简单说,它就是一个"翻译官"——把人类语言翻译成AI能看懂的语言。
具体怎么翻译?就是之前RAG那期提到的"数字指纹"。
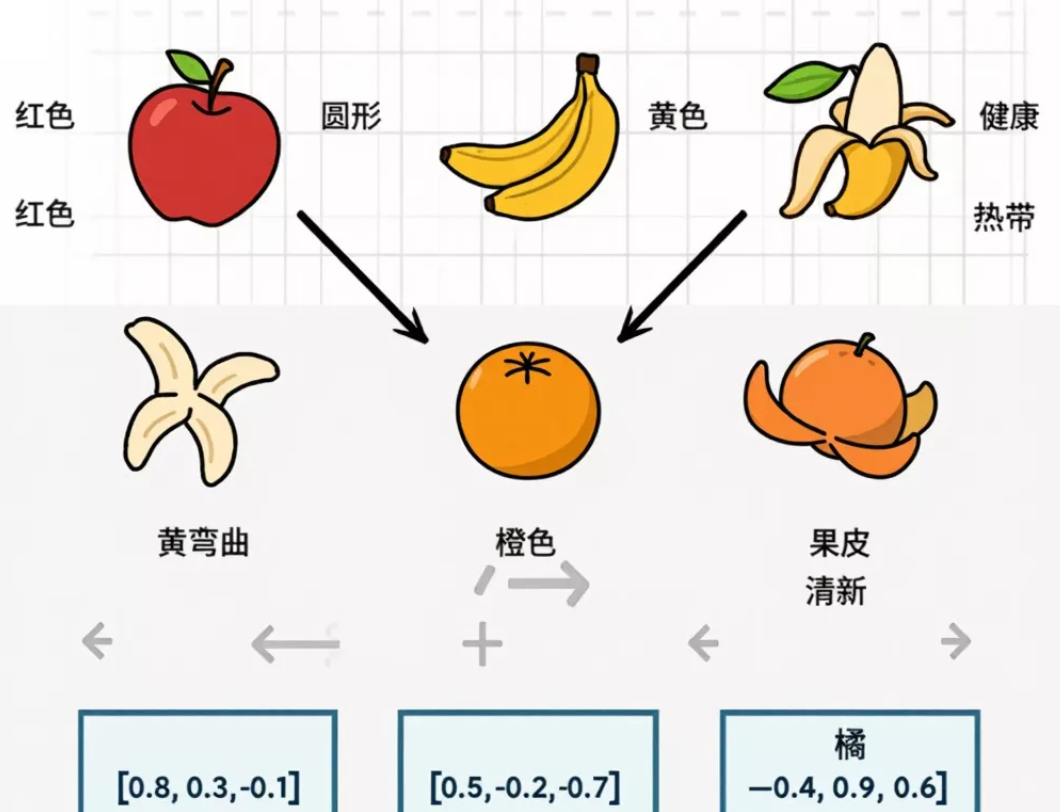
当AI看到"苹果"这两个字,它会把这两个字转换成一长串数字,比如:
[0.23, -0.45, 0.87, 0.12, -0.33, …]
这串数字有几百甚至上千位,每一位都是0到1之间的小数。

这些数字是怎么确定的?随便编一串不行吗?
还真不行。这些数字是AI在海量文本里"学习"出来的。学习的目标只有一个:意思相近的词,数字也要"长得像"。
比如"苹果"和"香蕉"的数字会比较接近,因为它们都是水果,日常生活中经常一起出现。而"苹果"和"手机"的数字差异就大一些——虽然苹果公司挺有名,但水果苹果和手机毕竟是两码事。
为什么要用Embedding?
你可能想问了,为什么非要转换成数字?让AI直接看文字不行吗?
还真不行,有几个原因。
处理速度。计算机天生就是做数字计算的。比较两个数字大小、判断两个数字序列是否相似,这些都是它最擅长的事。但如果让它直接理解两个中文词语的意思——这就太强人所难了。
能做数学运算。这是关键。"苹果"转换成了数字之后,AI就能做各种运算了。比如:
苹果 - 水果 + 蔬菜 = ?
听起来莫名其妙对吧?但如果"苹果"的数字是A,"水果"的数字是B,"蔬菜"的数字是C,那A - B + C的结果,可能就接近"萝卜"或"白菜"这些蔬菜的数字。
这不是开玩笑。Google当年训练的一个Embedding模型,真的能做这种"词语类比"游戏。“国王” - “男人” + “女人” ≈ “女王”,就这么神奇。

表达语义关系。"苹果"和"iPhone"在文字上一点都不像,但意思上有关系。Embedding能让这两个词的数字表示变得相似。"很好"和"超棒"文字不同,但意思相近,Embedding也能让它们的数字表示接近。
说白了,Embedding捕捉的是词语之间的"语义关系",不只是"字面相似度"。
Embedding是怎么工作的?
原理说起来有点"暴力"。
早期的Embedding方法叫Word2Vec,核心思路是:看一个词周围会出现什么词,就能知道这个词是什么意思。
语言学上有句话叫"语义由上下文决定"——你认识一个词,不是因为有人给你定义过,而是因为你见过它在不同语境下是怎么用的。“苹果"总是和"吃”、“水果”、“红色”、"多少钱一斤"这些词一起出现,所以你知道它是一种水果。
Word2Vec就是这么干的。它用一个大神经网络,看海量文本里每个词周围都有什么词,然后自动学习出每个词应该对应什么样的数字。训练完成后,神经网络里的那些数字,就是这个词的Embedding。
现在有更复杂的Embedding方法,比如基于Transformer的大模型产生的上下文Embedding。但基本思路是一样的——用数字来表示词语的意思,而且"意思相近的词,数字也要相近"。
Embedding用在哪?
Embedding是AI世界里的"基础设施",到处都能见到它。
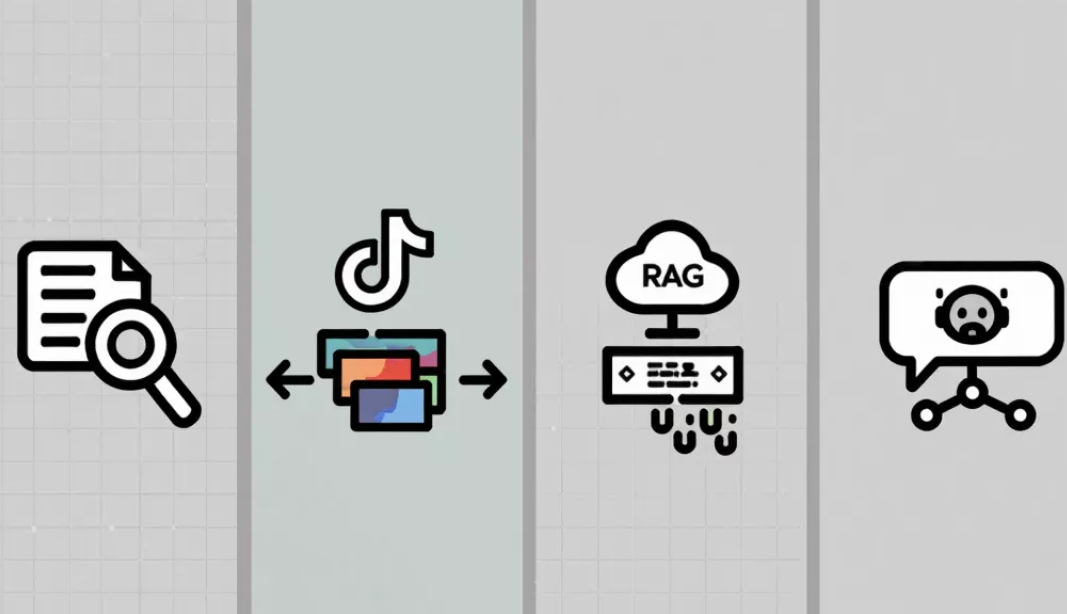
搜索引擎。当你在Google或百度搜索时,你的query会被转换成Embedding,然后在数据库里找和你query的Embedding最接近的文档。比你搜的什么词更重要。
推荐系统。抖音为什么知道你喜欢看什么视频?因为它把你的兴趣转成了Embedding,把视频内容也转成了Embedding,然后找最"接近"的推给你。
RAG。RAG里的向量数据库,存的就是文档片段的Embedding。检索的时候,把你的问题转成Embedding,然后找数据库里最相似的那些段落。
大模型的思考过程。大模型处理每一个词语的时候,都会先把它转换成Embedding,然后再做后续计算。Embedding就是大模型理解语言的"第一关"。
补充一下:中文Embedding更复杂
刚才的例子用的是中文词语,但中文的Embedding比英文更复杂一点。
英文单词之间有空格分隔,计算机很容易知道哪些是一个词。中文没有空格,“我今天很开心"这几个字连在一起,计算机得先做"分词”,才能知道"今天"是一个词、"开心"是一个词。
所以中文的Embedding通常要先经过分词这一步。不过现在很多大模型都是直接在字的级别做Embedding,不用显式分词,背后的原理类似。
总结
Embedding的本质:用一串数字来表示词语的意思,让计算机能够处理和计算语言。
核心规律是:意思相近的词,数字也要相近。
有了Embedding,AI能够理解词语之间的语义关系、做词语的数学运算、在海量信息中快速找到相关内容。
Embedding是AI理解人类语言的"第一关",也是RAG、搜索引擎、推荐系统等无数AI应用的基石。

本文是「人话版AI词典」第10期,旨在用最通俗的人话,让每个人都能听懂AI。关注我,一起了解一些AI相关的有意思的东西。
下期预告:第11期——什么是向量数据库?AI的"记忆宫"到底长什么样?
这期我们讲了Embedding是把文字变成数字。那这么多数字存在哪?怎么快速找到相似的?答案就是向量数据库。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)