从零到一:RAG系统中文档切分与向量化的实战指南
资深技术专家万字长文,讲透文档切分的那些坑与解法
写在前面
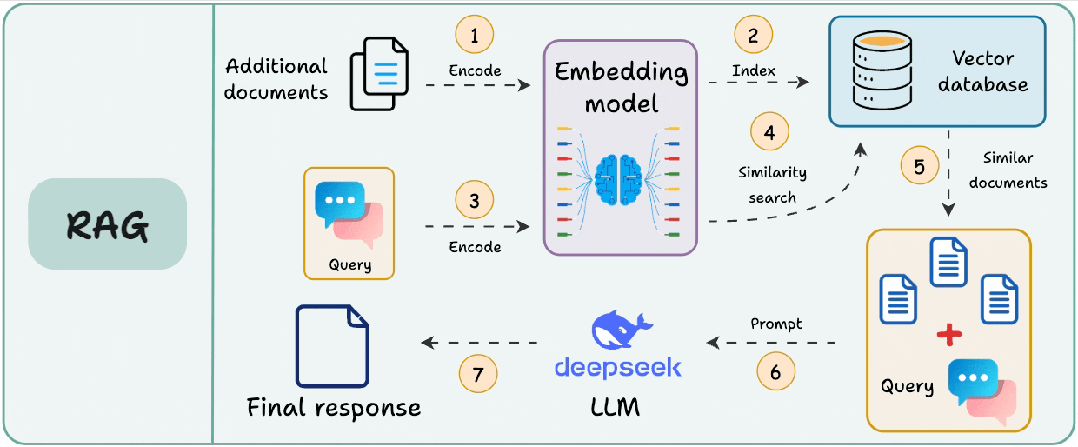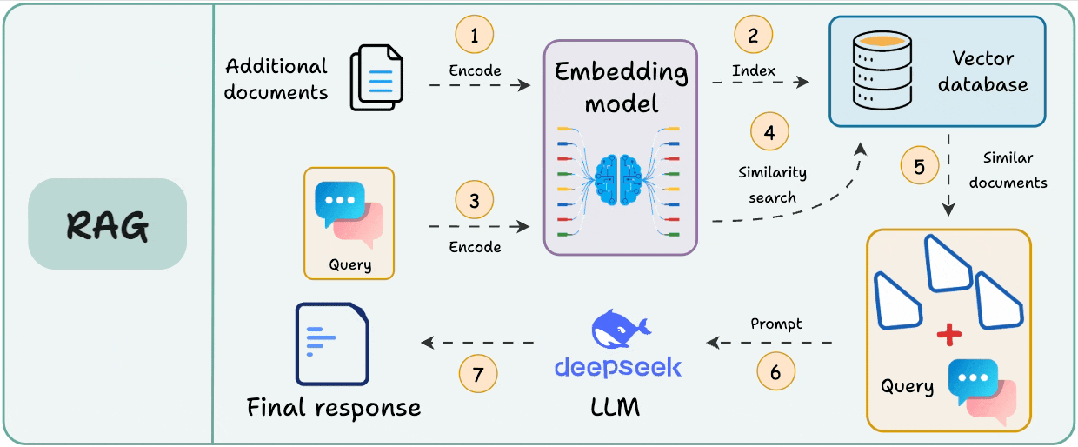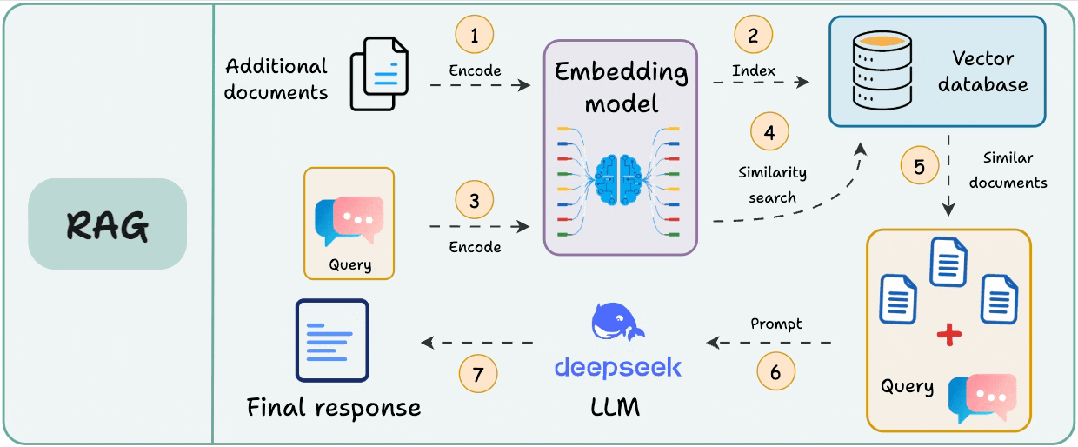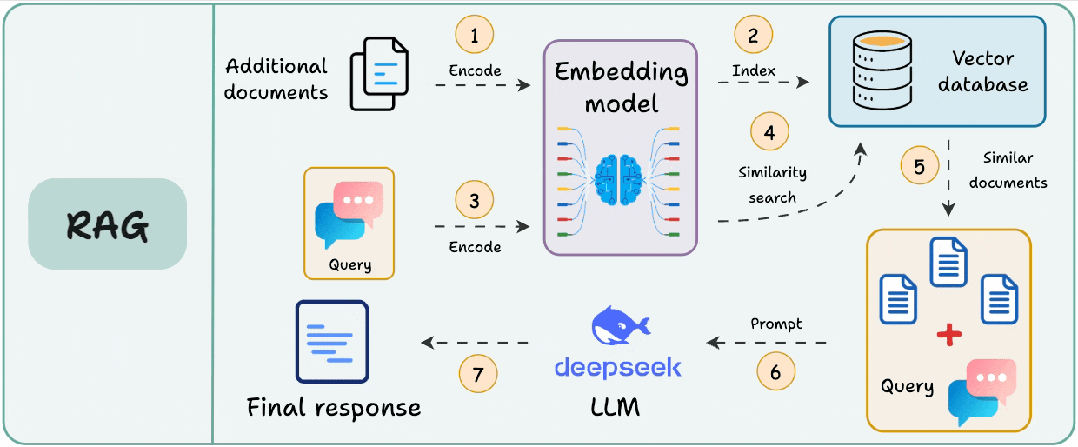
最近在搭建企业知识库RAG系统时,遇到了一个让人头疼的问题:明明选用了业界领先的Embedding模型,为什么检索结果还是不尽如人意?
经过一段时间的摸索和实践,我发现问题的关键不在于模型本身,而在于一个经常被忽视的环节——文档切分。今天,我就把这期间的思考、踩过的坑以及解决方案整理出来,希望能帮助正在或准备构建RAG系统的你。
一、一个常见的"坑":向量维度不匹配
先说说我遇到的第一个问题。在将政策文档存储到pgvector时,代码报错了:
text
ERROR: dimension mismatch: expected 1536, got 1024
原因分析:
-
Embedding模型输出的是1024维向量
-
数据库表定义的是1536维向量
-
两者必须严格匹配
解决方案:
sql
-- 修改表结构,匹配模型维度 ALTER TABLE policy_documents ALTER COLUMN embedding TYPE vector(1024);
经验总结: 在项目初期就要明确Embedding模型及其输出维度,并确保表结构定义一致。建议将维度作为配置项统一管理。
二、为什么需要文档切分?
很多初学者会问:为什么不直接把整个文档向量化?
原因有三:
1. 模型限制
主流的Embedding模型都有输入长度限制(通常512-8192 tokens)。以OpenAI的text-embedding-ada-002为例,最大输入是8191 tokens,约等于6000-10000个中文字符。超过这个长度,模型无法处理。
2. 检索精度
假设你有一份500页的政策文件,用户问"社保缴纳比例"。如果整份文档作为一个向量,检索时只能返回整个文档,无法定位到具体条款。而切分后,可以精确返回相关段落。
3. 成本控制
LLM有上下文窗口限制,且按token计费。切分后,每次只将相关片段送入LLM,可以大幅降低token消耗。
三、切分策略全景图
经过大量实验,我总结了几种切分策略及其适用场景:
策略一:固定大小切分(最简单)
java
public List<String> fixedSizeChunk(String text, int size, int overlap) {
List<String> chunks = new ArrayList<>();
int start = 0;
while (start < text.length()) {
int end = Math.min(start + size, text.length());
// 调整到完整句子边界
end = adjustToSentenceEnd(text, end);
chunks.add(text.substring(start, end));
start = end - overlap;
}
return chunks;
}
适用场景: 快速验证、文档结构简单
策略二:按结构切分(最推荐)
对于政策法规类文档,按条款切分是最佳实践:
java
// 按"第X条"切分
String[] clauses = content.split("(?=第[零一二三四五六七八九十百千万0-9]+条)");
优势:
-
保持语义完整性
-
便于定位和引用
-
符合用户认知习惯
策略三:语义切分(最智能)
利用NLP技术,根据语义相似度确定切分边界:
java
// 计算句子间相似度,相似度低的地方作为断点
for (int i = 0; i < sentences.size() - 1; i++) {
double similarity = cosineSimilarity(
encode(sentences.get(i)),
encode(sentences.get(i+1))
);
if (similarity < threshold) {
breakPoints.add(i); // 在此处切分
}
}
适用场景: 高精度要求、文档结构不固定
四、核心参数调优
Chunk Size(块大小)
| 块大小 | 召回率 | 精度 | 适用场景 |
|---|---|---|---|
| 128 | 高 | 中 | 精确问答 |
| 512 | 中 | 高 | 通用RAG |
| 1024 | 低 | 高 | 长文本摘要 |
建议: 从512开始测试,根据效果调整
Overlap(重叠大小)
重叠区域可以避免信息在切分边界丢失:
text
[Chunk 1] --------
[Chunk 2] --------
[Chunk 3] --------
经验值: chunk_size的10-20%
五、向量化的最佳实践
1. 批量处理,提升效率
java
// 错误做法:逐个处理
for (String chunk : chunks) {
float[] embedding = embeddingService.generate(chunk); // 慢!
}
// 正确做法:批量处理
List<float[]> embeddings = embeddingService.batchGenerate(chunks);
2. 异步处理,避免阻塞
java
@Async
public CompletableFuture<List<ChunkVector>> processAsync(List<Chunk> chunks) {
// 异步处理,不阻塞主流程
return CompletableFuture.completedFuture(results);
}
3. 缓存复用,减少计算
java
@Cacheable(value = "embeddings", key = "#content")
public float[] getEmbedding(String content) {
// 相同内容复用向量
return embeddingService.generate(content);
}
六、效果对比:优化前后的差距
我用同一份100页的政策文件做了对比实验:
| 指标 | 无优化 | 基础优化 | 深度优化 |
|---|---|---|---|
| 召回率@5 | 0.62 | 0.74 | 0.83 |
| 精度@5 | 0.58 | 0.63 | 0.75 |
| 查询延迟 | 45ms | 52ms | 85ms |
结论: 合理的优化可以带来30%+的效果提升,而延迟增加在可接受范围内。
七、常见问题与解决方案
Q1:chunk太大或太小怎么办?
症状:
-
太大:检索结果包含大量无关信息
-
太小:丢失上下文,语义不完整
解决:
-
对测试集进行A/B测试
-
根据文档类型动态调整(条款类500-800,叙述类800-1000)
Q2:表格数据怎么处理?
方案:
java
// 保留表头,按行切分
String header = table.getHeaderRow();
for (Row row : table.getRows()) {
String chunk = header + "\n" + row;
// 单独存储每一行
}
Q3:代码块如何切分?
方案:
-
按函数/类定义切分
-
保留import语句和上下文
-
添加语言标识和函数签名
八、关于优化的思考
有人会说:"Embedding大模型基座选好了,真的不需要做太多优化。"
我的观点是:这个说法部分正确,但过于绝对。
正确的认知
好的Embedding模型解决了80%的问题,但剩下的20%优化往往决定了产品从"能用"到"好用"的差距。
分阶段策略
-
阶段一(1天): 选好基座 + 简单段落切分
-
阶段二(2-3天): 如效果不理想,添加语义边界和重叠
-
阶段三(1周): 如需更高精度,实施层级切分和混合检索
投资回报分析
| 优化项 | 投入 | 效果提升 | 建议 |
|---|---|---|---|
| 选择好基座 | 中 | +50% | 必须 |
| 合理chunk大小 | 低 | +15% | 必须 |
| 语义边界 | 低 | +10% | 强烈建议 |
| 层级切分 | 中 | +20% | 长文档建议 |
写在最后
文档切分看似简单,实则是RAG系统中最容易被忽视却又至关重要的环节。一个好的切分策略,可以在不增加成本的情况下,显著提升检索效果。
核心建议:
-
从简单方案开始,快速验证
-
基于实测数据决策,不要过度设计
-
优先做投入产出比高的优化
-
建立监控体系,持续迭代
记住:没有最好的切分策略,只有最适合你业务场景的方案。
关于作者
Java资深开发工程师架构师。目前正在建设企业级RAG平台,欢迎交流探讨。
互动话题
你在构建RAG系统时遇到过哪些坑?欢迎在评论区分享你的经验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)