计算机毕业设计:Python汽车销量智能分析与预测系统 Flask框架 scikit-learn 可视化 requests爬虫 AI 大模型(建议收藏)✅
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:Python语言、Flask框架、scikit-learn机器学习库、ECharts可视化库、requests爬虫、车主之家数据源
功能模块:
· 首页——注册登录
· 汽车销量分析
· 汽车不同品牌销量对比分析
· 汽车销量预测——3种预测算法
· 后台数据管理
· 数据采集
项目介绍:本项目为汽车销量分析与可视化系统,基于Python爬虫从车主之家定向采集汽车销量及品牌数据,经清洗后存入MySQL数据库。后端采用Flask框架搭建服务接口,前端结合ECharts生成销量趋势图、品牌对比图等可视化图表。系统集成ARIMA时间序列算法、决策树回归与岭回归三种预测模型,用户可选择算法对指定品牌下月销量进行预测。同时配备注册登录验证与后台数据管理模块,支持数据的增删改查及导入导出,形成从数据采集、分析展示到销量预测的完整闭环。
2、项目界面
(1)首页–注册登录
这是汽车销量分析与可视化系统的首页,页面顶部设有导航栏,包含首页、汽车总体销量分析、汽车品牌销量对比分析、汽车销量预测、后台数据管理等功能入口,页面中部展示系统介绍与登录注册区域,下方介绍了汽车销量数据采集、品牌销量对比分析、销量预测、可视化分析平台等核心功能模块。
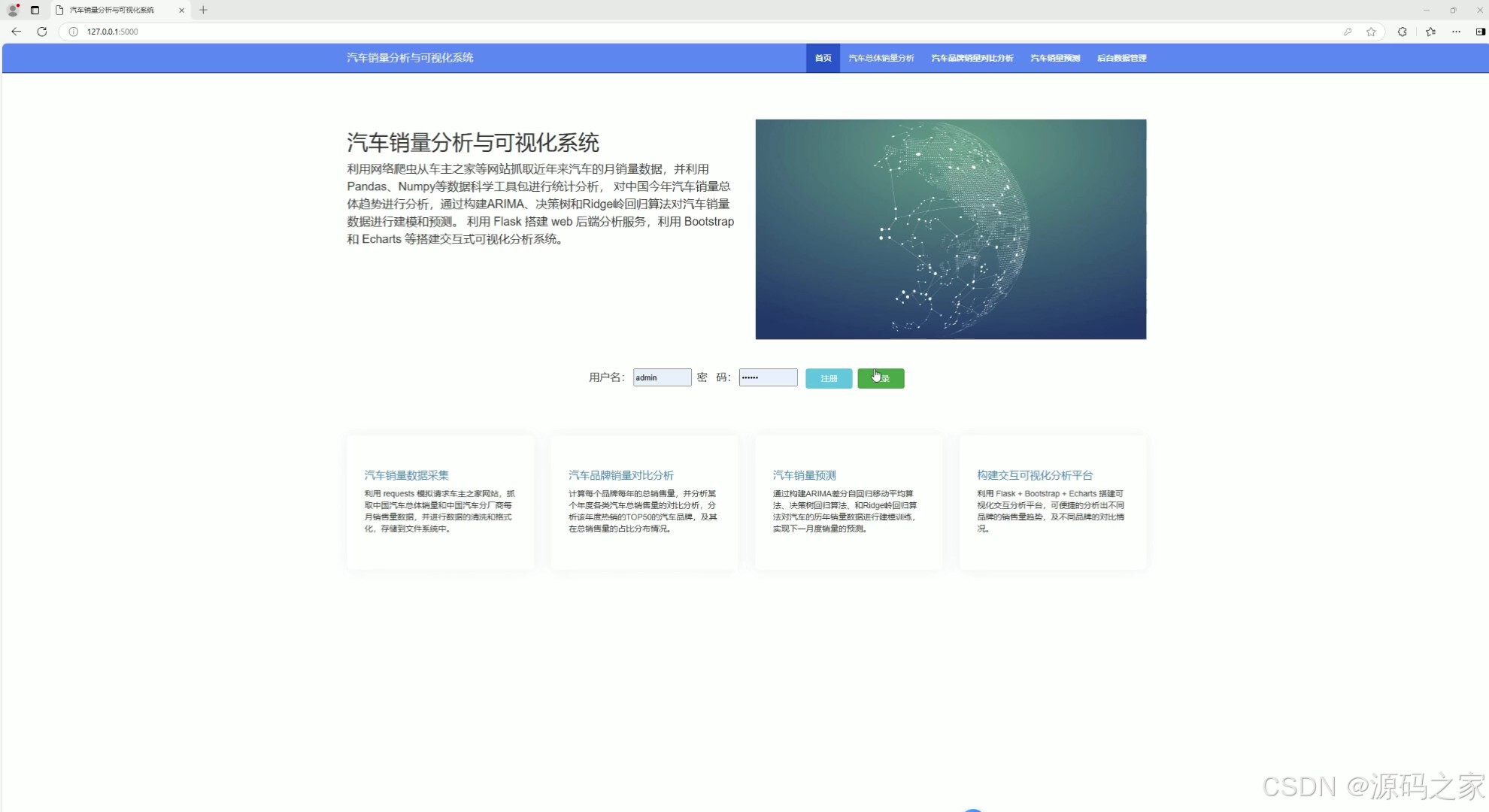
(2)汽车销量分析
这是汽车销量分析与可视化系统的汽车总体销量分析页面,页面通过折线图展示中国汽车总体月销量走势,通过柱状图展示中国汽车总体年销量走势,直观呈现不同时间维度下汽车销量的变化趋势,帮助用户把握汽车市场的整体销售情况。
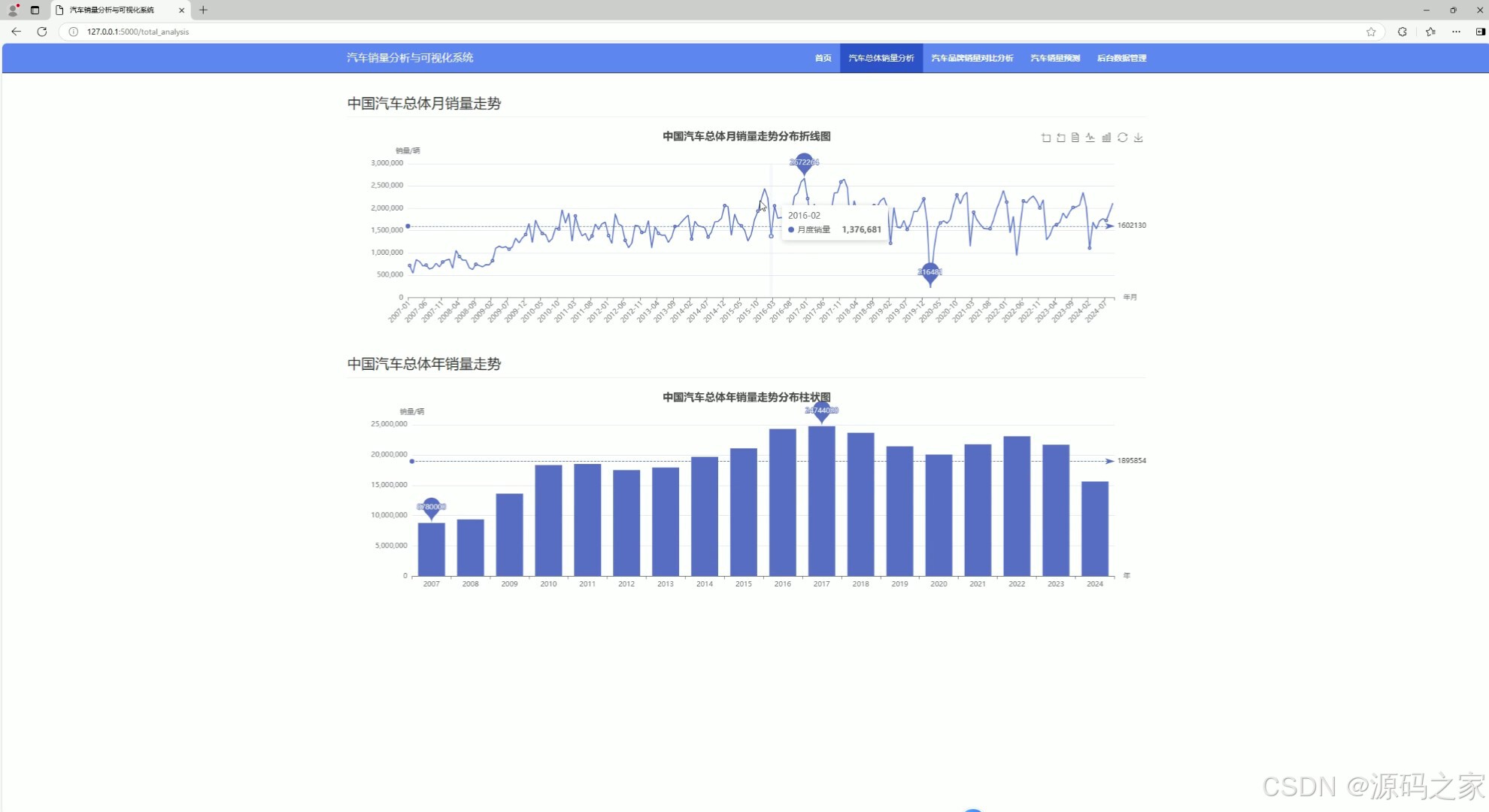
(3)汽车不同品牌销量对比分析
这是汽车销量分析与可视化系统的汽车品牌销量对比分析页面,页面支持选择年份,通过条形图展示各汽车品牌年度总销量的对比情况,通过环形饼图呈现热销TOP10汽车品牌的销量占比,直观呈现不同品牌的市场销售表现。
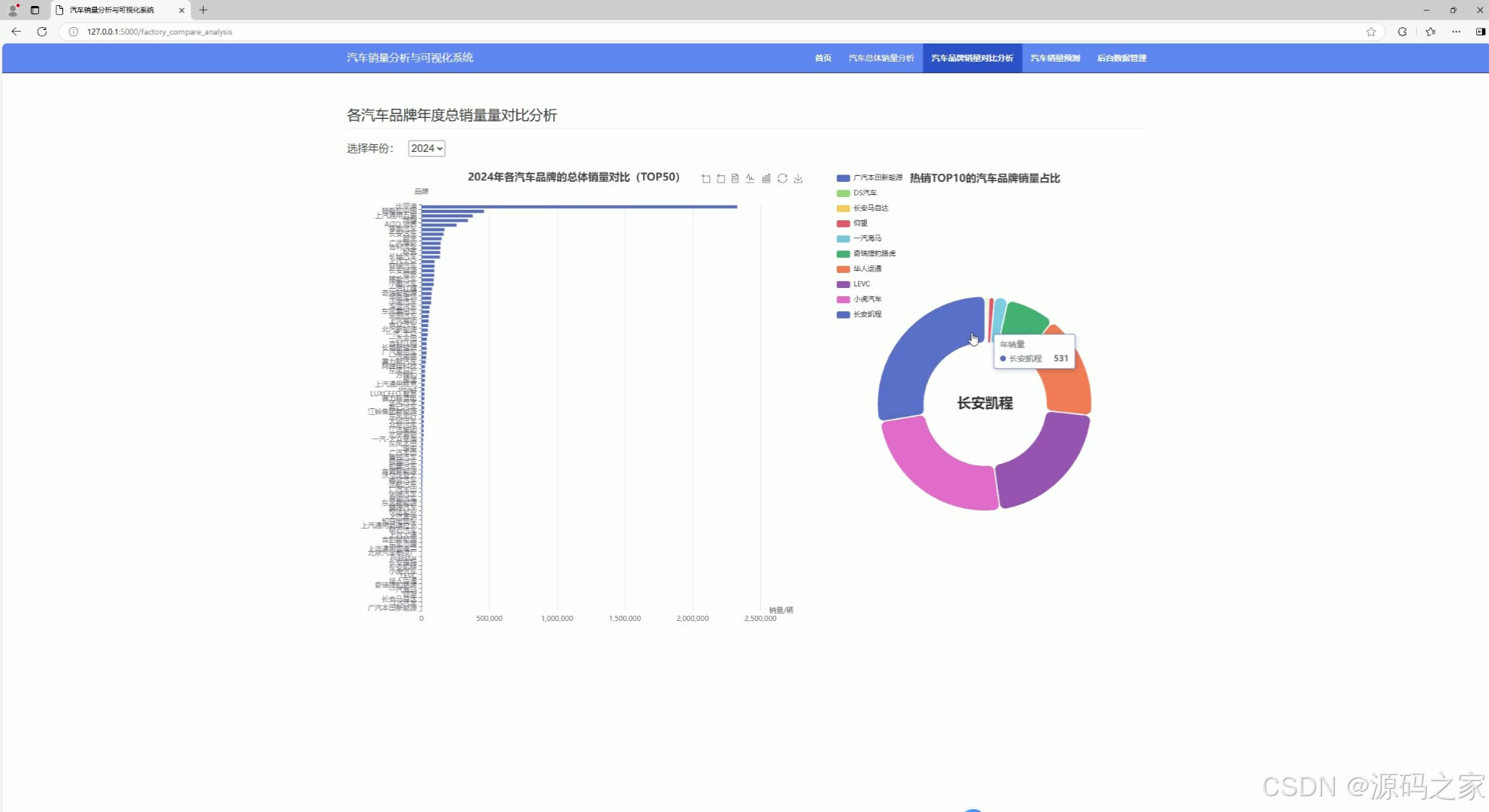
(4)汽车销量预测—3种预测算法
这是汽车销量分析与可视化系统的汽车销量预测页面,页面提供汽车品牌和预测算法的选择功能,结合折线图呈现品牌月度销量走势,并基于所选算法对该品牌下一个月度的销量进行预测,直观展示销量趋势与预测结果。
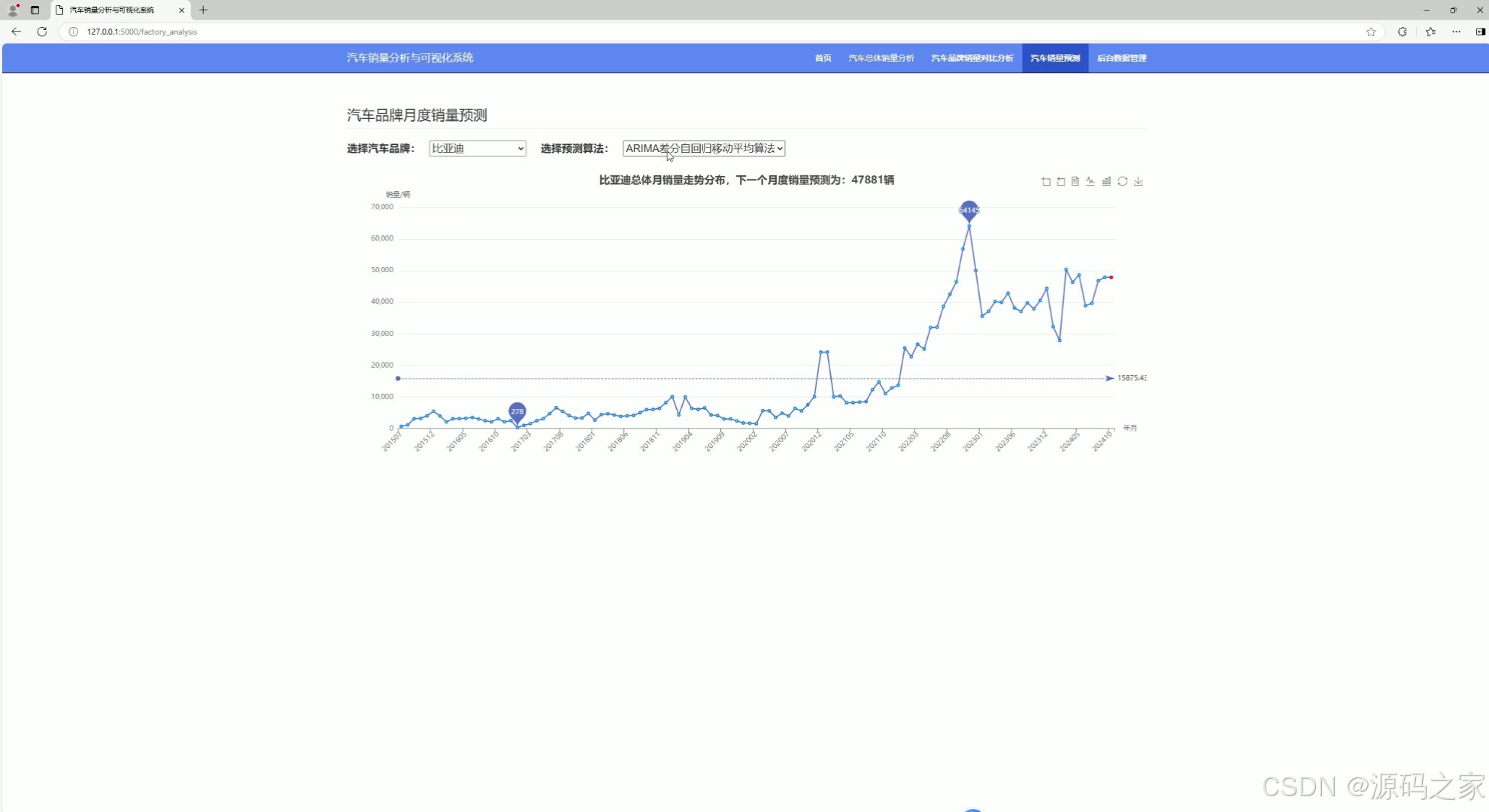
这是汽车销量分析与可视化系统的汽车销量预测页面,页面支持选择汽车品牌与多种预测算法,通过柱状图展示所选品牌的月度销量走势,并基于选定算法对该品牌下一个月度的销量进行预测,直观呈现销量趋势与预测结果。
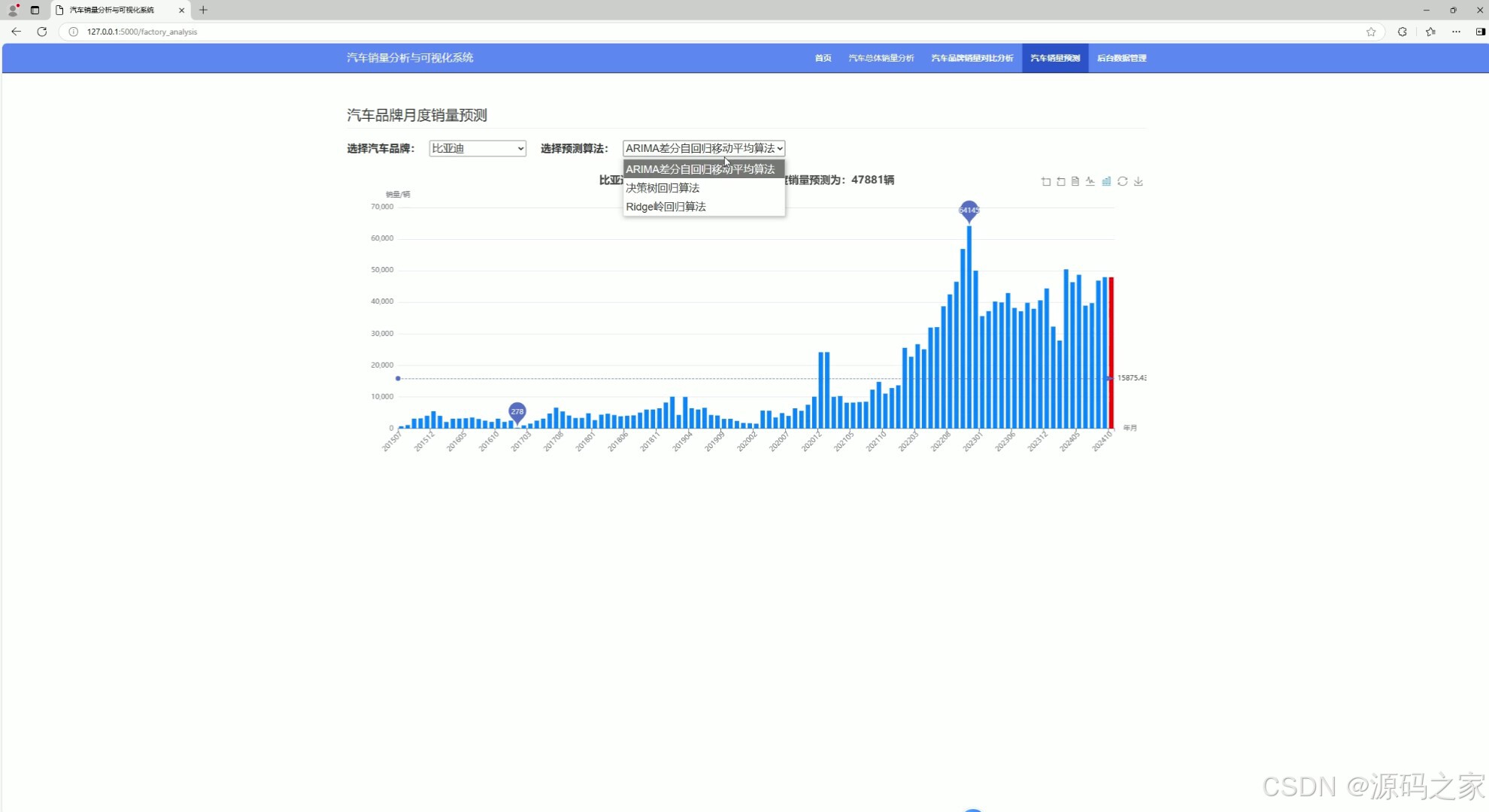
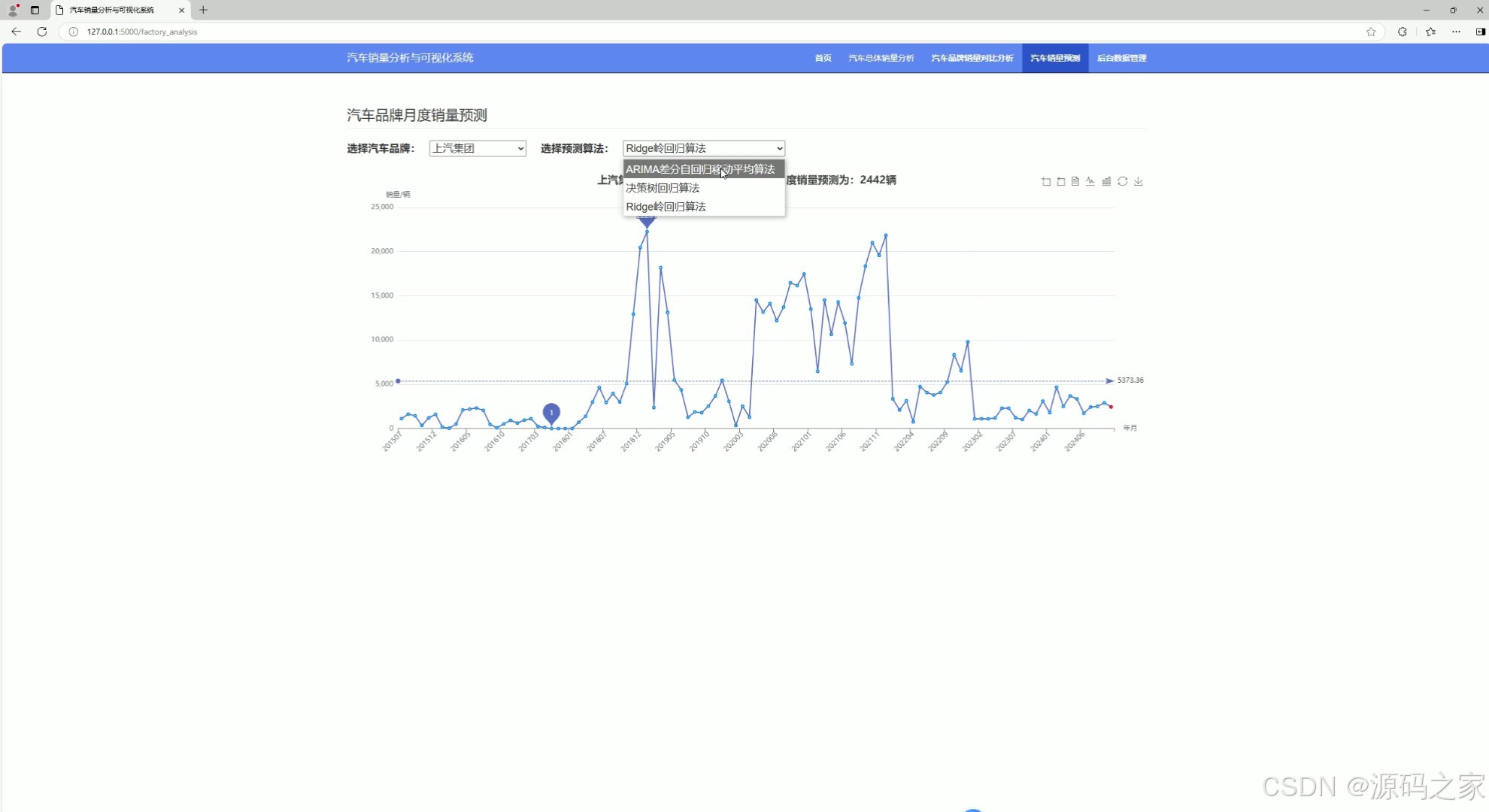
这是汽车销量分析与可视化系统的汽车销量预测页面,页面支持选择不同汽车品牌与多种预测算法,通过折线图展示所选品牌的月度销量走势,并基于选定算法对该品牌下一个月度的销量进行预测,直观呈现销量趋势与预测结果。
(5)后台数据管理
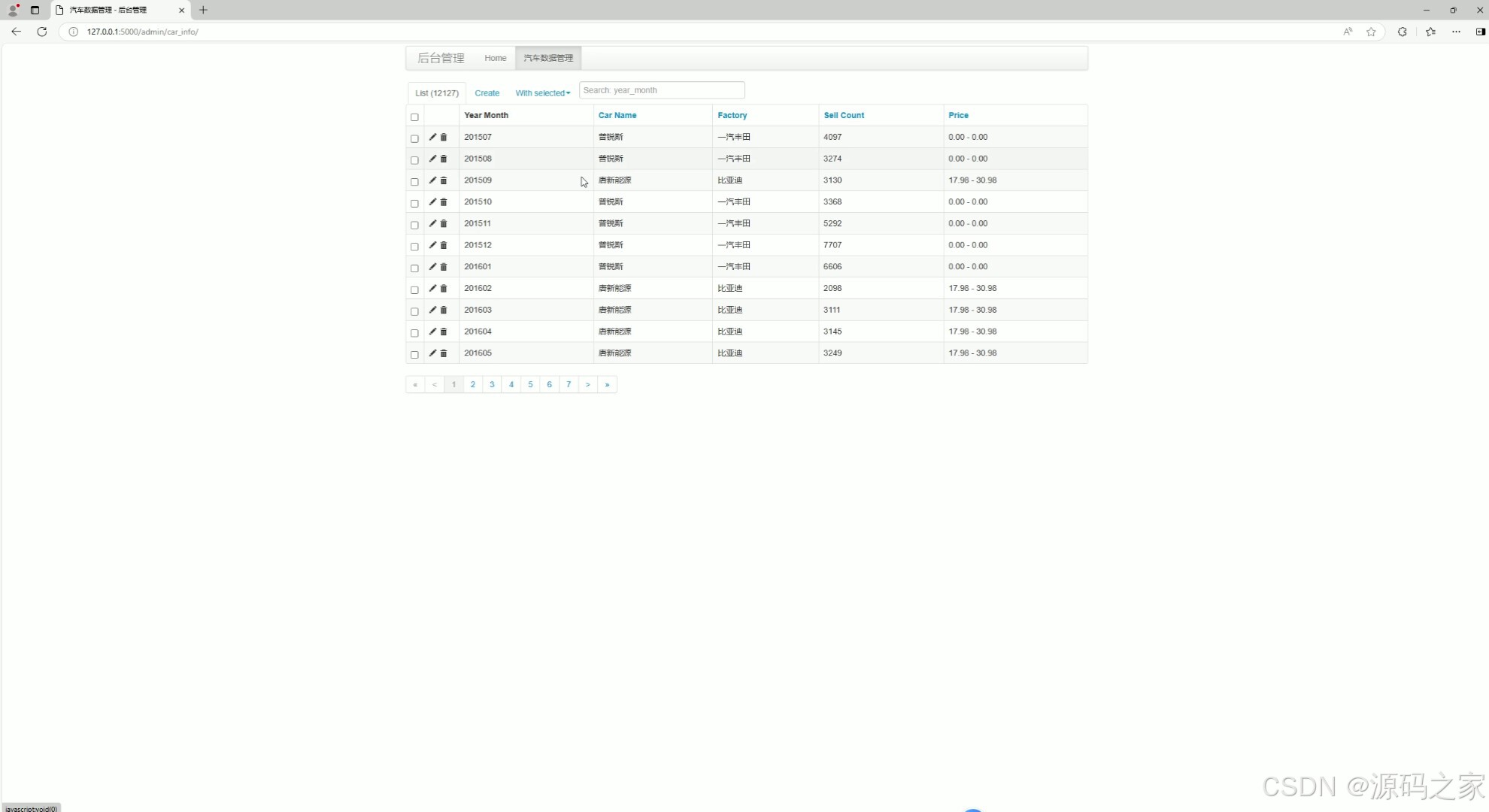
这是汽车销量分析与可视化系统的后台数据管理页面,页面以表格形式展示汽车销量相关数据,支持数据的查看、新增、编辑、删除操作,提供筛选、分页与批量操作功能,用于维护系统内的汽车基础信息与销量数据,保障前端分析功能的数据支撑。
(6)数据采集
这是汽车销量分析与可视化系统的Python爬虫代码实现界面,通过编写网络爬虫代码,利用requests和BeautifulSoup库从指定网站抓取汽车销量相关数据,实现数据的自动化采集与清洗,为系统的分析、可视化与预测功能提供原始数据支撑。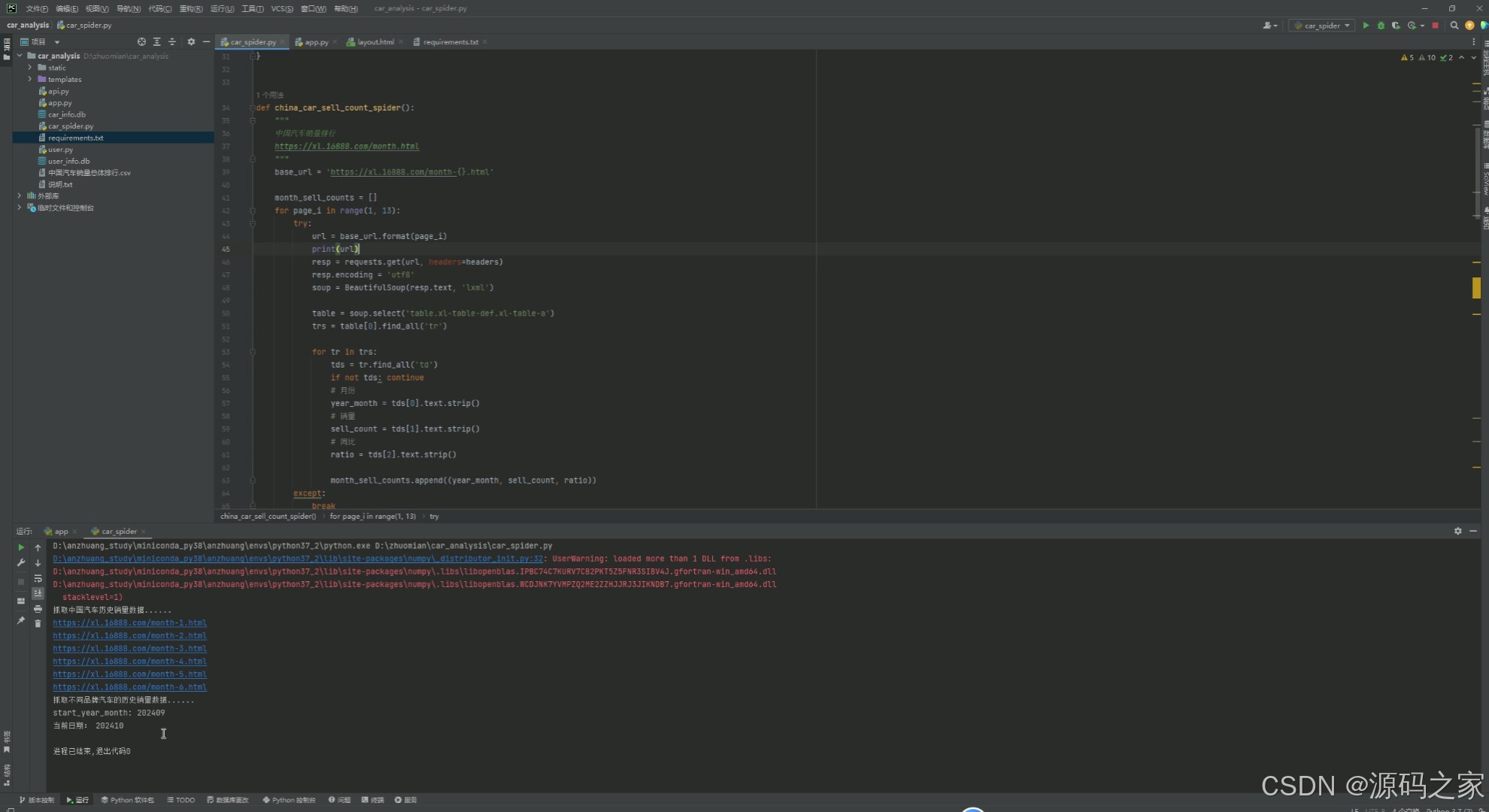
3、项目说明
一、技术栈简要说明
本项目后端采用Python语言与Flask轻量级框架,负责路由控制、数据处理及接口服务。机器学习模块基于scikit-learn库实现决策树回归与岭回归算法,同时结合statsmodels库完成ARIMA时间序列分析。前端可视化采用ECharts图表库,生成折线图、柱状图、饼图等交互式图表。数据采集通过requests爬虫从车主之家网站抓取汽车销量及品牌数据,经清洗后存入MySQL数据库。整体技术栈覆盖数据采集、存储、分析、预测到可视化展示的全流程。
二、每个功能模块详细介绍
· 首页——注册登录
该模块为系统入口页面,顶部导航栏集成各功能入口。页面中部设置账号与密码输入框,提供注册及登录验证功能。用户通过身份校验后方可访问销量分析、品牌对比、销量预测及后台管理等核心模块。页面下方同步展示系统核心功能简介,帮助新用户快速了解平台能力。
· 汽车销量分析
该模块聚焦汽车市场整体销售趋势,通过折线图展示中国汽车月度销量变化曲线,通过柱状图呈现年度销量汇总数据。用户可直观把握不同时间维度下的销量波动规律,识别销售旺季与淡季,为宏观市场研判提供数据支撑。
· 汽车不同品牌销量对比分析
该模块支持按年份筛选数据,通过横向条形图展示各汽车品牌当年的年度总销量排名,同时采用环形饼图呈现热销TOP10品牌的销量占比。两种图表形式相互补充,清晰对比不同品牌的市场表现与份额分布。
· 汽车销量预测——3种预测算法
该模块集成ARIMA时间序列算法、决策树回归与岭回归三种预测模型。用户首先选择目标汽车品牌,系统以折线图展示该品牌历史月度销量走势,随后选择预测算法,后端基于历史数据完成模型训练与计算,返回下一个月度的销量预测值,并在图表中标注展示。三种算法可切换对比,满足不同场景下的预测需求。
· 后台数据管理
该模块以表格形式展示系统中存储的汽车销量、品牌信息等核心数据。管理员可执行数据的查看、新增、编辑、删除等操作,同时支持筛选、分页及批量处理功能。该模块保障了前端分析与预测功能的数据可维护性,便于数据更新与纠错。
· 数据采集
该模块为系统的数据源头,基于Python编写爬虫脚本,利用requests库发送网络请求,结合BeautifulSoup解析HTML页面,从车主之家网站定向抓取汽车销量及品牌数据。采集后的数据经过清洗、去重与格式统一,最终存入MySQL数据库,为后续分析、可视化与预测提供原始数据支撑。
三、项目总结
本项目构建了一套完整的汽车销量智能分析与预测系统,实现了从数据采集、清洗存储、可视化分析到多算法销量预测的业务闭环。前端提供注册登录、销量趋势查看、品牌对比、预测交互及后台数据管理等功能,后端依托Flask框架与scikit-learn、statsmodels机器学习库,集成ARIMA、决策树回归、岭回归三种预测算法。系统界面清晰,图表交互友好,为汽车市场研究、品牌竞争分析及销量趋势预判提供了全面的数据化工具。
4、核心代码
from flask import jsonify, Blueprint
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
import sqlite3
from statsmodels.tsa.arima.model import ARIMA
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import Ridge
import numpy as np
api_blueprint = Blueprint('api', __name__)
# 读取数据库的数据
query_sql = "select * from car_info"
conn = sqlite3.connect('car_info.db')
cursor = conn.cursor()
cursor.execute(query_sql)
results = cursor.fetchall()
month_sell_counts = pd.read_csv('中国汽车销量总体排行.csv')
factory_month_sell_counts = pd.DataFrame(results)
factory_month_sell_counts.columns = ['时间', '车型', '厂商', '销量', '售价']
factory_month_sell_counts['年'] = factory_month_sell_counts['时间'].map(lambda x: str(x)[:4])
month_sell_counts = month_sell_counts.sort_values(by='时间', ascending=True)
month_sell_counts['年'] = month_sell_counts['时间'].map(lambda x: x.split('-')[0])
@api_blueprint.route('/month_year_sell_count')
def month_year_sell_count():
"""
基础折线图
"""
x = month_sell_counts['时间'].values.tolist()
y1 = month_sell_counts['销量'].values.tolist()
return jsonify({
'x': x,
'y1': y1
})
@api_blueprint.route('/year_sell_count')
def year_sell_count():
"""
基础折线图
"""
tmp = month_sell_counts[['年', '销量']].groupby('年').sum().reset_index()
x = tmp['年'].values.tolist()
y1 = tmp['销量'].values.tolist()
return jsonify({
'x': x,
'y1': y1
})
@api_blueprint.route('/get_all_factories')
def get_all_factories():
"""获取所有汽车品牌"""
factory_counts = factory_month_sell_counts['厂商'].value_counts().reset_index()
return jsonify({"factory": factory_counts['index'].values.tolist()})
@api_blueprint.route('/get_all_years')
def get_all_years():
years = factory_month_sell_counts['年'].values.tolist()
years = list(sorted(set(years), reverse=True))
return jsonify({"年": years})
def arima_model_train_eval(history):
"""
ARIMA差分自回归移动平均算法
"""
# 构造 ARIMA 模型
model = ARIMA(history, order=(1, 1, 0))
# 基于历史数据训练
model_fit = model.fit()
# 预测下一个时间步的值
output = model_fit.forecast()
yhat = output[0]
return yhat
# 训练数据集构造
# 使用历史数据的窗口
window = 5
x_train = []
y_train = []
factory_counts = factory_month_sell_counts['厂商'].value_counts().reset_index()
for factory in factory_counts['index'].values:
factory_history = factory_month_sell_counts[factory_month_sell_counts['厂商'] == factory]
if factory_history.shape[0] <= window:
continue
# 滑窗构造数据集
history_counts = factory_history['销量'].values
for i in range(0, len(history_counts) - window):
x = history_counts[i: i + window]
y = history_counts[i + window]
x_train.append(x)
y_train.append(y)
# 训练决策树和Ridge岭回归算法
ridge_model = Ridge()
ridge_model = ridge_model.fit(x_train, y_train)
tree_model = DecisionTreeRegressor()
tree_model = tree_model.fit(x_train, y_train)
print("Ridge岭回归算法训练集分数:", ridge_model.score(x_train, y_train))
print("决策树回归算法训练集分数:", tree_model.score(x_train, y_train))
def ridge_predict(history):
"""
Ridge岭回归算法
"""
x_test = np.array([history[-window:]])
pred_y = ridge_model.predict(x_test)
pred_y = pred_y[0]
return pred_y
def decision_tree_predict(history):
"""
决策树回归算法
"""
x_test = np.array([history[-window:]])
pred_y = tree_model.predict(x_test)
pred_y = pred_y[0]
return pred_y
@api_blueprint.route('/factory_month_year_sell_count_predict/<factory>/<algo>')
def factory_month_year_sell_count_predict(factory, algo):
"""
基础折线图
"""
tmp = factory_month_sell_counts[factory_month_sell_counts['厂商'] == factory]
tmp = tmp.drop_duplicates(subset=['时间'], keep='first')
year_months = tmp['时间'].values.tolist()
sell_counts = tmp['销量'].values.tolist()
# 销量预测算法
predict_sell_count = 0
if algo == "arima":
predict_sell_count = arima_model_train_eval(sell_counts)
elif algo == 'tree':
predict_sell_count = decision_tree_predict(sell_counts)
elif algo == 'ridge':
predict_sell_count = ridge_predict(sell_counts)
else:
raise ValueError(algo + " not supported.")
# 下一个月度
next_year_month = datetime.strptime(year_months[-1], '%Y%m')
next_year_month = next_year_month + relativedelta(months=1)
next_year_month = next_year_month.strftime('%Y%m')
year_months.append(next_year_month)
# 转为 int 类型
predict_sell_count = int(predict_sell_count)
sell_counts.append(predict_sell_count)
return jsonify({
'x': year_months,
'y1': sell_counts,
'predict_sell_count': predict_sell_count
})
@api_blueprint.route('/factory_year_compare/<year>')
def factory_year_compare(year):
"""
不同品牌年销量之间的对比情况
"""
tmp = factory_month_sell_counts[factory_month_sell_counts['年'] == year]
tmp = tmp[['厂商', '销量']].groupby('厂商').sum().reset_index()
tmp = tmp.sort_values(by='销量', ascending=True)
print(tmp)
x = tmp['厂商'].values.tolist()
y1 = tmp['销量'].values.tolist()
print(y1)
return jsonify({
'x': x,
'y1': y1
})
5、源码获取方式

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)