从Nexent智能体市场体验到零代码构建实用英语学习助手智能体
前言:为什么选择 Nexent 做轻量智能体?
Nexent 智能体(nexent.tech),它把 “模型接入→提示词生成→智能体协作→调试发布” 全流程都做成了可视化操作,哪怕是零基础用户,也能在 10 分钟内做出一个可用的智能体。
并且Nexent不仅可以进行本地部署开发,也支持用户进行一键使用在线体验。

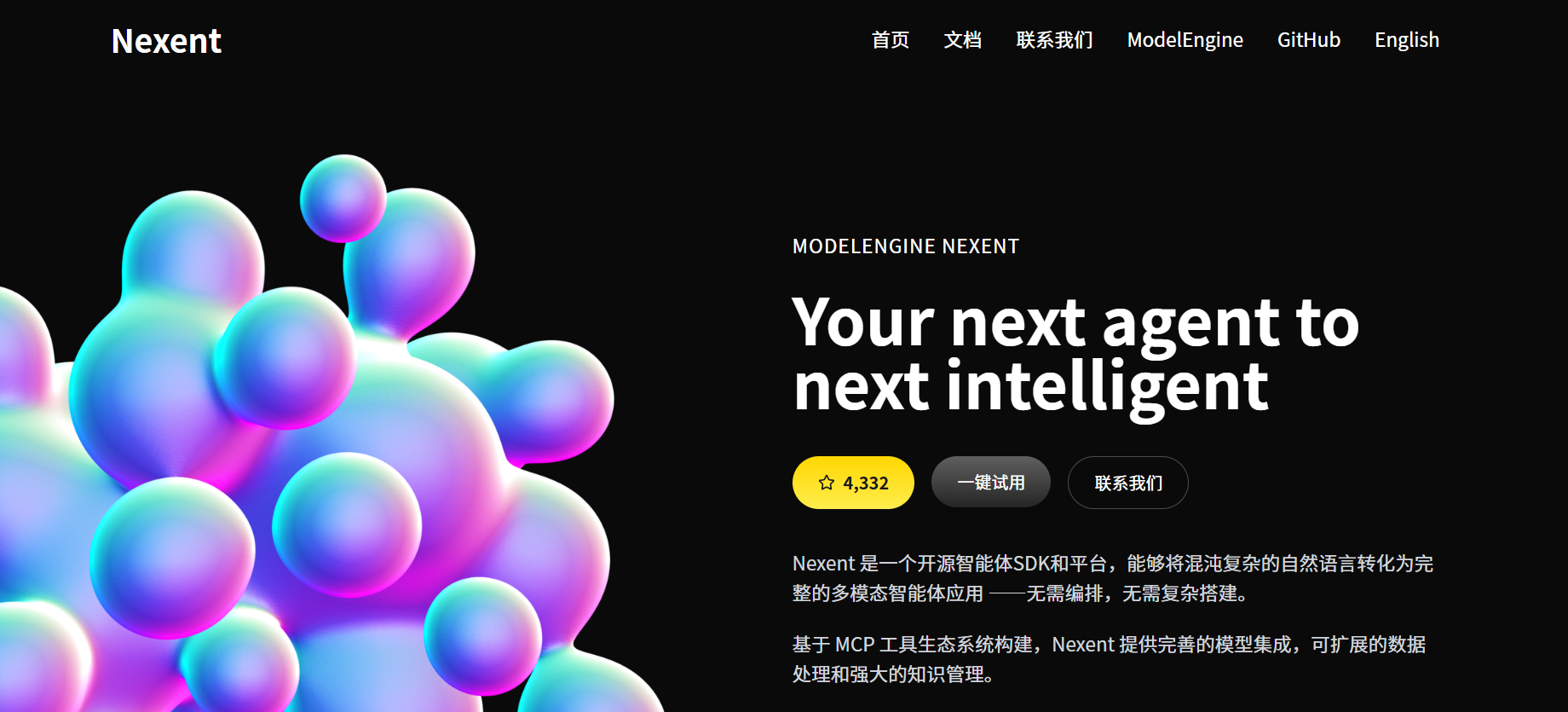
Nexent 智能体市场体验:开箱即用的灵感库
在开发完自己的智能体后,我特意逛了 Nexent 智能体市场,体验非常惊喜:
- 覆盖场景广:涵盖教育、写作、客服、编程、生活助手等多个领域,光是英语类就有 “口语陪练”“作文批改”“单词背诵” 等多个现成智能体
- 质量较高但参考性强:既有功能完善的专业智能体,也有轻量有趣的小工具,新手可以快速找到适合自己的方向
- 可查看配置逻辑:部分智能体开放了提示词、模型选择、工具接入等配置信息
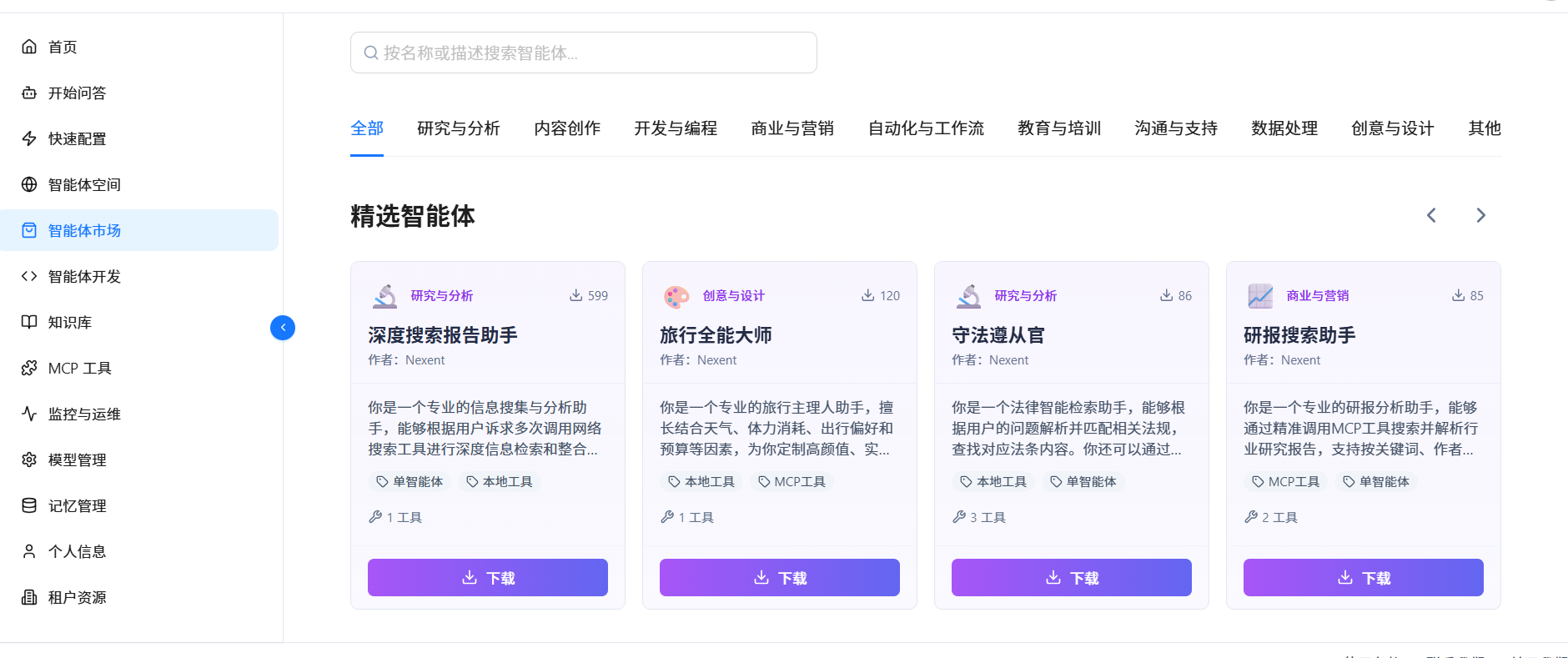
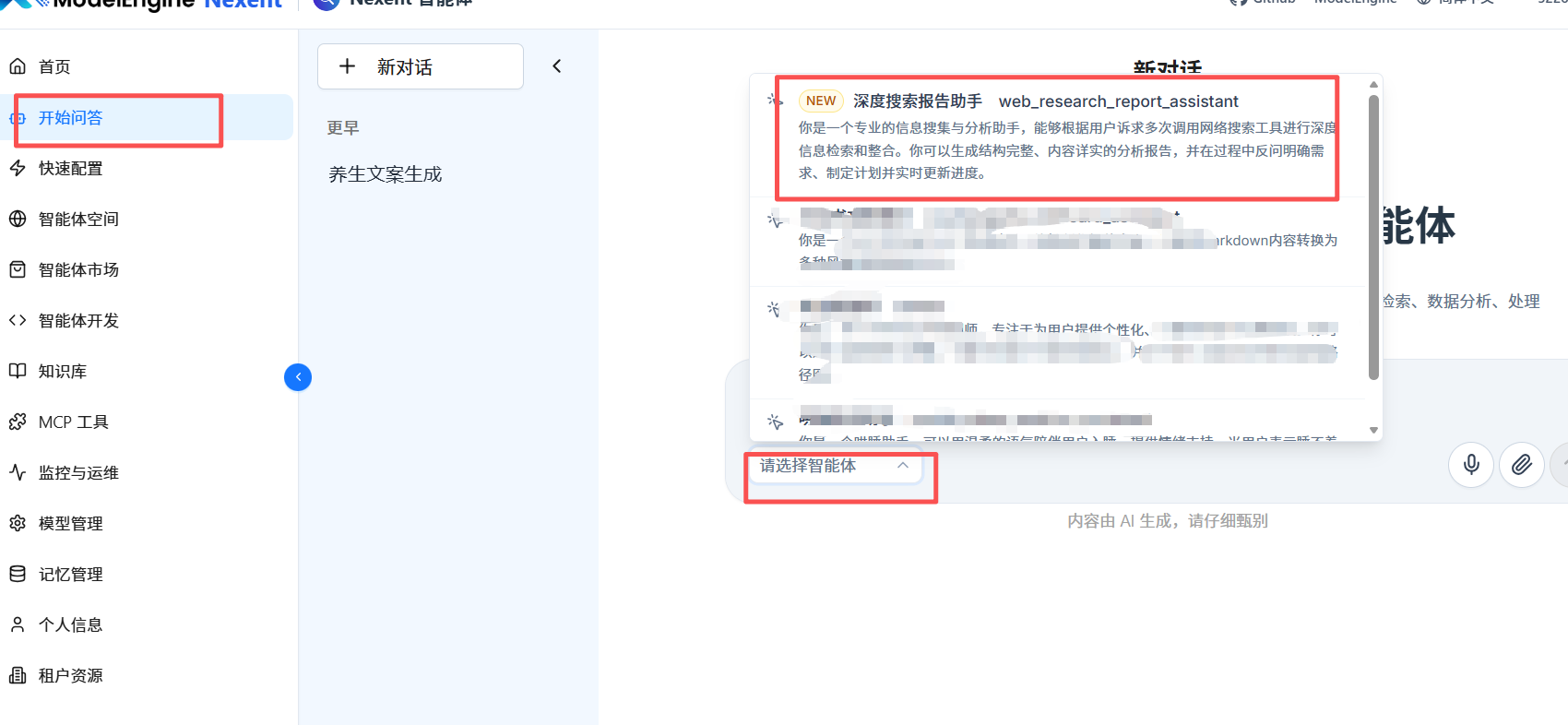
点击相关的智能体可以查看它的相关配置信息。
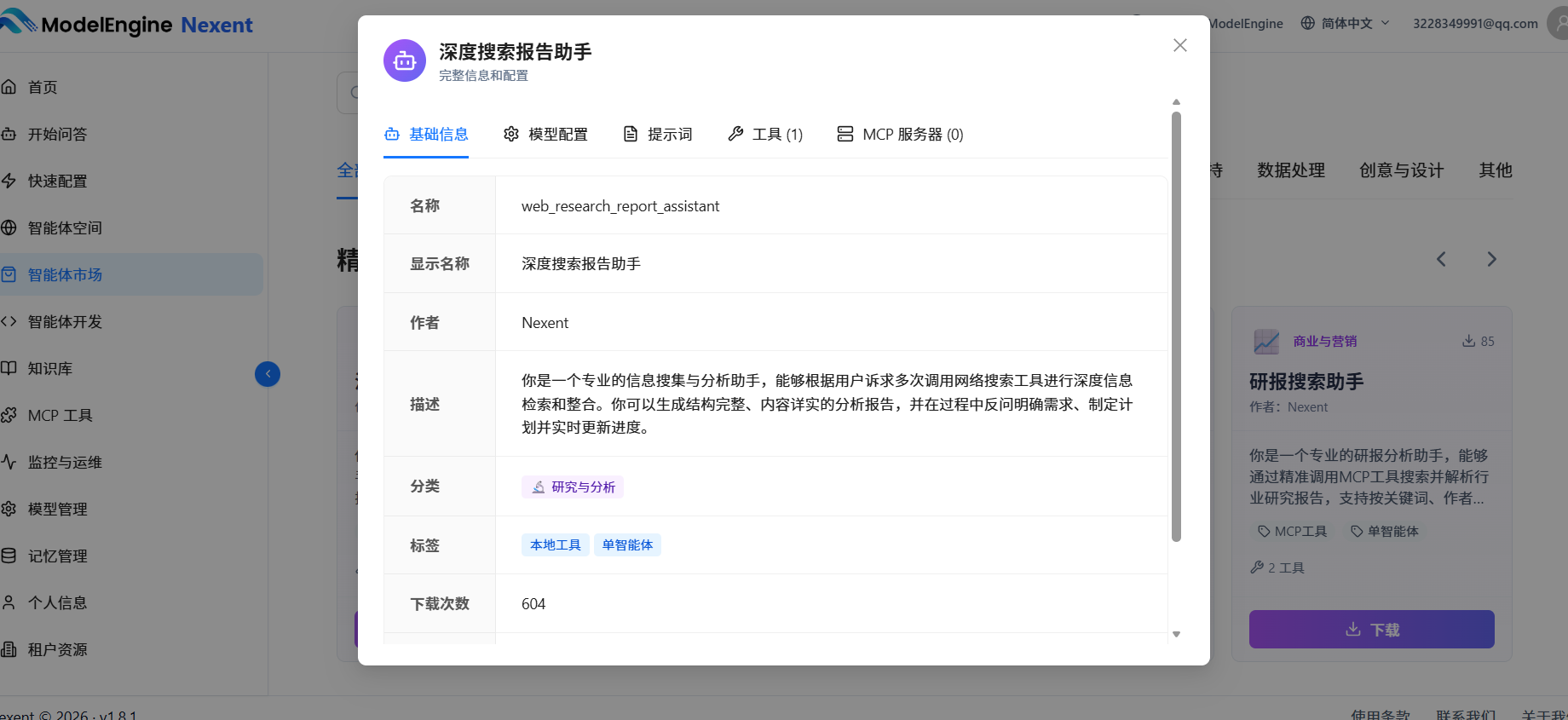
这里我选择了深度搜索报告助手进行体验,因为我提前进行了模型导入,这里自动识别到了我的的deepseek模型(后面会讲),可以按照提示进行智能体的安装,配置和体验。
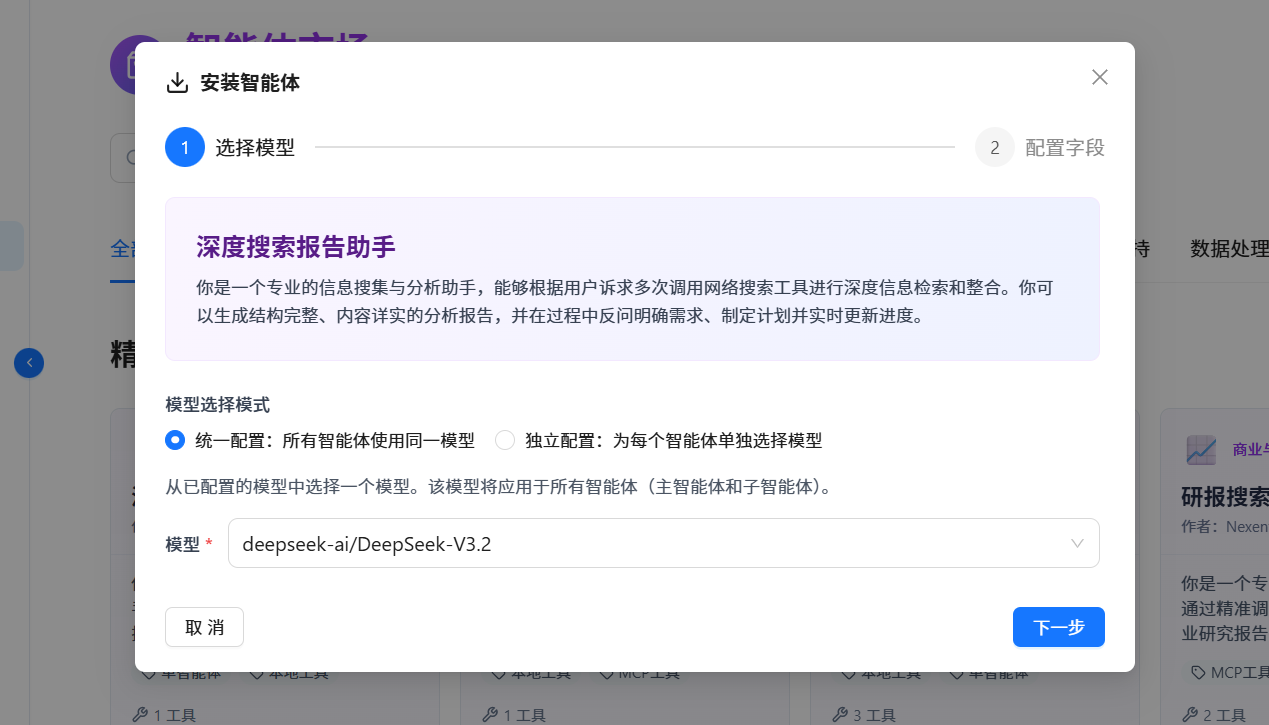
根据页面提示信息进行配置,不同智能体需要配置的字段是不同的,有些需要相关工具的API KEY以及配置MCP工具,不过页面都会提醒,也有蓝色对应链接进行点击跳转获取,引导性配置。

当我们配置好,就可以安装了,安装好后再页面开始问答选择智能体就能看到我们安装好的智能体,这里是深度搜素报告助手。
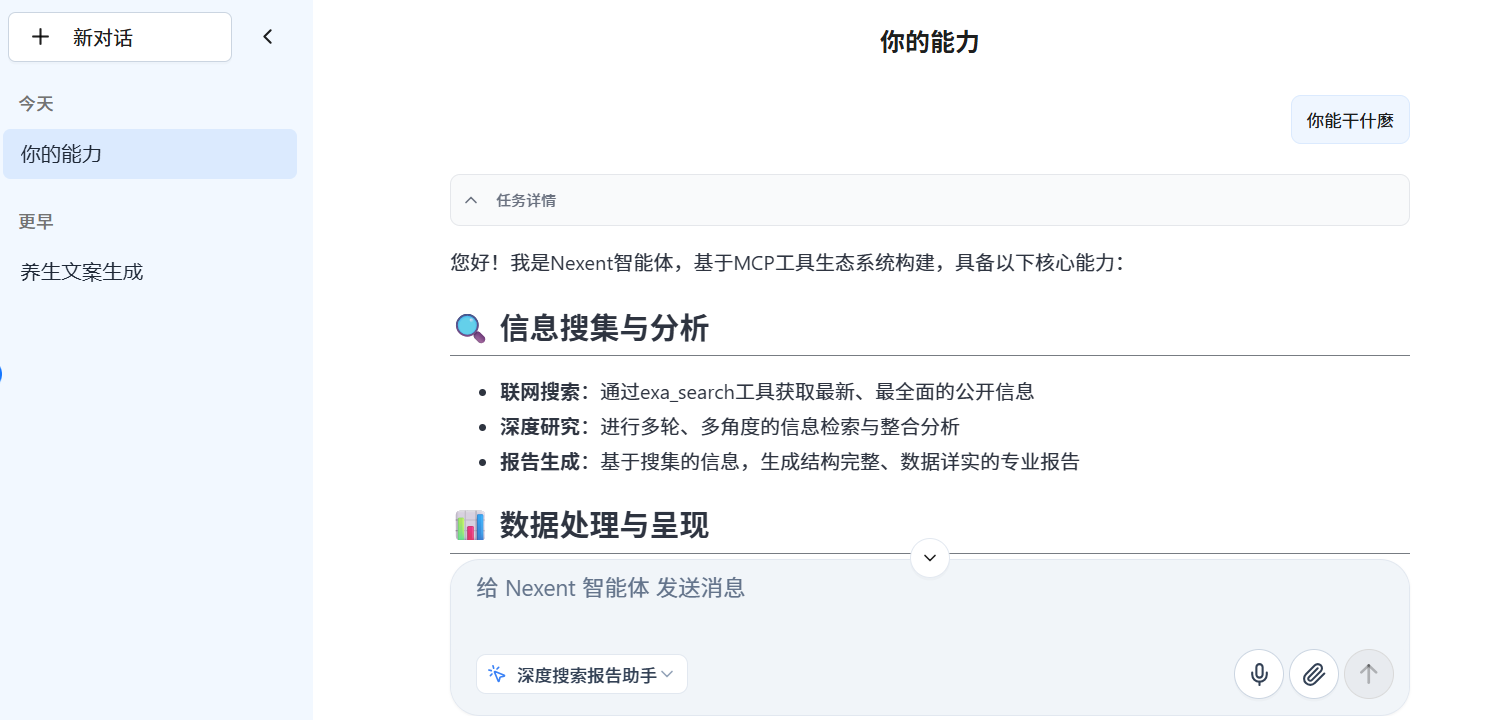
对于新手,可以先从 “使用别人的智能体” 开始,理解其设计思路后,再模仿创建自己的工具,学习成本较低。
对于老手,就是借助别人的智能体完善自己的智能体和创建更好的智能体。
零代码智能生成英语学习助手
模型接入:批量 + 单个导入,灵活适配场景
模型选型思路
「英语学习助手」不需要极强的逻辑推理,更看重英文生成质量、多轮对话稳定性,同时要适配中文用户的交互习惯。我最终选择了:
- 大语言模型:deepseek-ai/DeepSeek-V3.2(英文生成流畅,支持中英混合对话)
- 备选模型:Qwen/Qwen3-8B-Instruct(中文理解更精准,适合语法纠错场景)
批量导入 vs 单个导入
Nexent 提供了两种模型接入方式,这里我选择了批量导入,比较适配,可以选择很多模型。
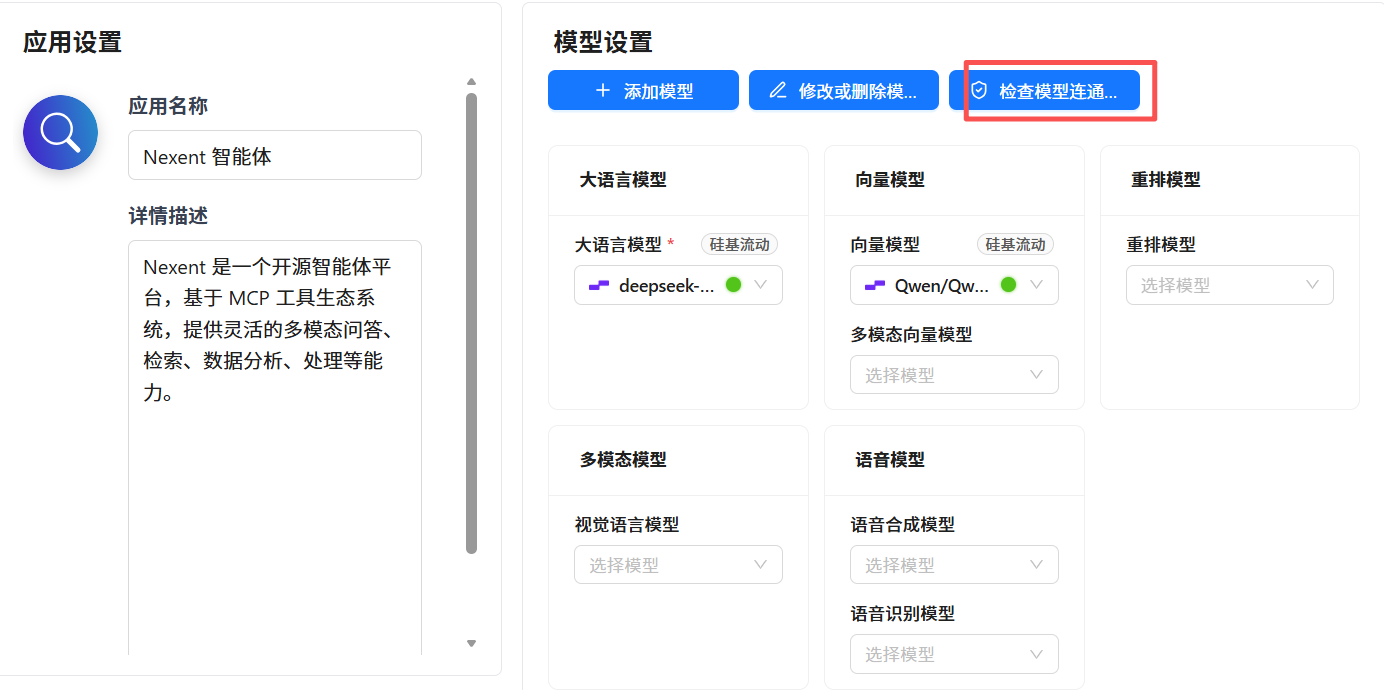
点击模型管理
- 在「添加模型」界面,开启「批量添加模型」开关
- 选择提供商、填写API Key,选择需要的模型类型(大语言模型 / 向量模型等)(这里我们选择的是硅基流动)。
- 填写好API Key之后点击获取模型,系统会自动识别并导入所有可用模型
后续做不同智能体(比如英语助手、写作助手)都能直接切换,不用重复填 API Key
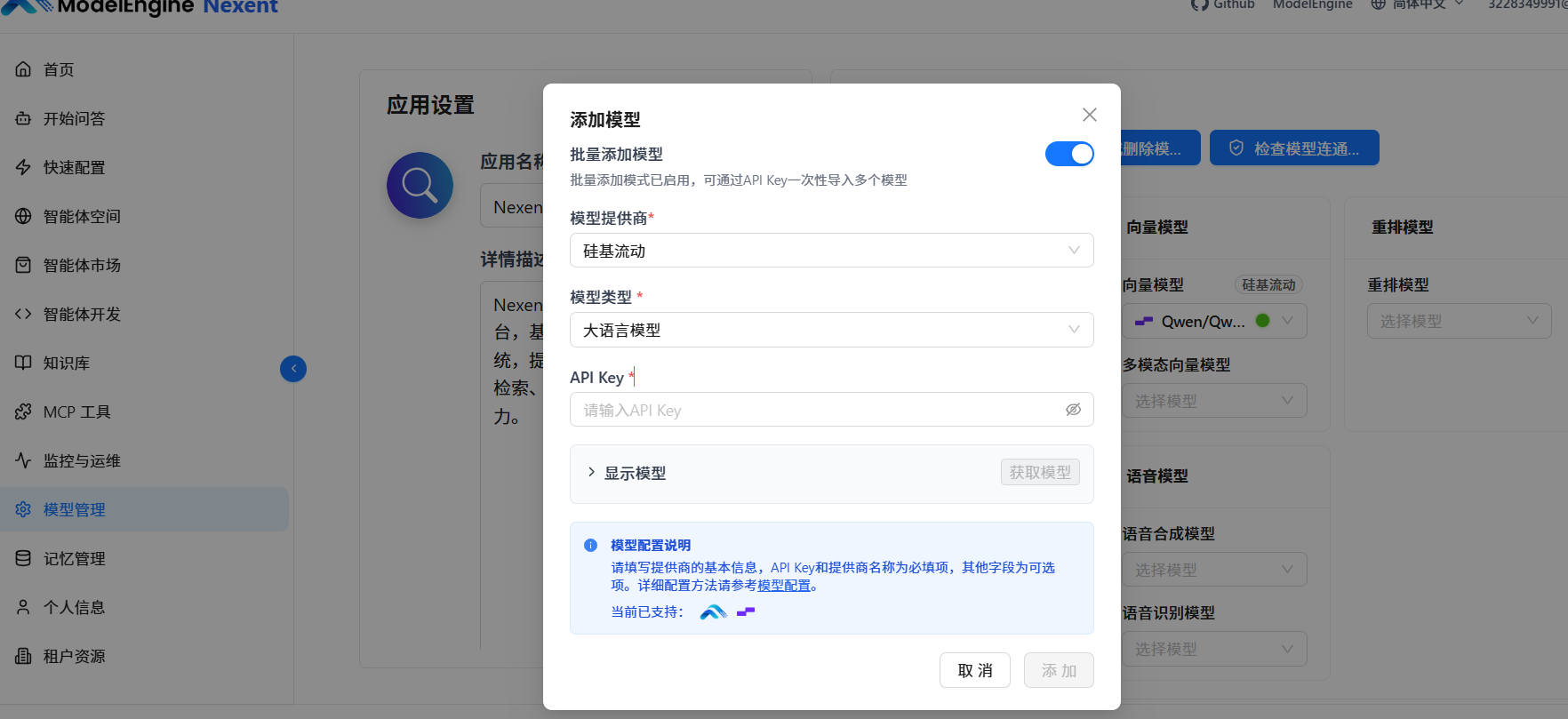
配置完可以检测模型连通性。
智能体开发:自动生成提示词 + 手动优化,效率拉满
用 “大白话” 描述需求
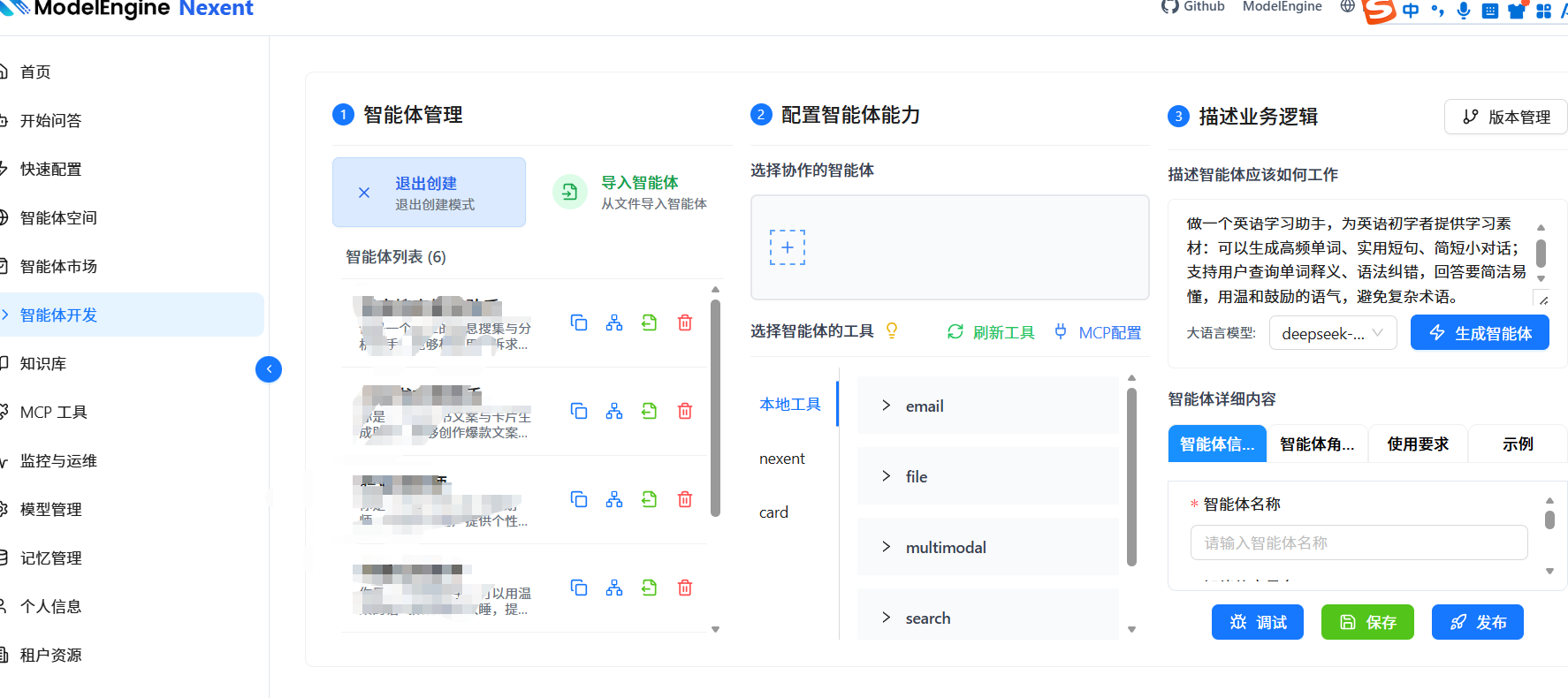
进入「智能体开发」界面,点击创建智能体,在 “描述业务逻辑” 输入框里写了一句最直白的需求:
做一个英语学习助手,为英语初学者提供学习素材:可以生成高频单词、实用短句、简短小对话;支持用户查询单词释义、语法纠错,回答要简洁易懂,用温和鼓励的语气,避免复杂术语。
一键生成完整提示词
点击「生成智能体」按钮,系统自动帮我完成了一整套专业智能体配置,包括:
- 智能体描述
你是一个英语学习助手,可以为英语初学者提供高频单词、实用短句和简短对话等学习素材,并支持查询单词释义和语法纠错。
- 智能体角色
你是一个英语学习助手,专门为英语初学者提供学习支持。
你能够生成高频单词、实用短句和简短对话,并帮助用户查询单词释义和进行语法纠错。
你的回答简洁易懂,使用温和鼓励的语气,避免复杂术语,旨在帮助用户轻松提升英语能力。
- 使用要求:约束回答规则(比如素材长度、回答风格、场景边界)
1. 所有工具的使用必须严格服务于为英语初学者提供学习素材的核心目标,包括生成高频单词、实用短句和简短小对话。
2. 当使用工具进行单词释义查询或语法纠错时,输出的解释必须简洁易懂,避免使用复杂的语法术语,确保符合初学者的理解水平。
3. 工具的任何输出都应采用温和、鼓励的语气,旨在增强用户的学习信心和兴趣,避免任何可能让用户感到挫败或困惑的表达。
4. 在没有可用工具或助手的情况下,应依赖自身能力以符合上述原则的方式直接响应用户请求,不得虚构工具功能或助手存在。
- 示例对话
### 参考示例:
示例1: 用户请求生成高频单词。
思考:用户需要学习高频单词,我可以直接生成一个包含常用单词的列表。
这里有一些适合初学者的高频英语单词:hello, world, thank, you, good, morning, afternoon, evening, please, sorry…
示例2: 用户请求生成实用短句。
思考:用户需要学习实用短句,我可以直接生成一些日常交流中常用的简单句子。
以下是一些实用的英语短句:
- How are you? (你好吗?)
- I’m fine, thank you. (我很好,谢谢。)
- What is your name? (你叫什么名字?)
- My name is [Your Name]. (我的名字是[你的名字]。)
- Where is the restroom? (洗手间在哪里?)
慢慢来,每天记住一两个句子,你会越来越棒的!
示例3: 用户请求生成简短小对话。
思考:用户需要学习简短对话,我可以直接创建一个简单的场景对话。
让我们来看一个在咖啡店点餐的简短对话:
A: Good morning! (早上好!)
B: Good morning! Can I have a cup of coffee, please? (早上好!请给我一杯咖啡好吗?)
A: Sure. Anything else? (当然。还要别的吗?)
B: No, thank you. (不用了,谢谢。)
A: Here you are. (给您。)
B: Thank you! (谢谢!)
多听多练,你也能轻松进行这样的对话!
示例4: 用户查询单词释义。
思考:用户需要查询单词“beautiful”的释义,我可以直接给出简单易懂的解释。
单词“beautiful”的意思是“美丽的、漂亮的”。例如:a beautiful flower (一朵美丽的花)。这个词用来形容让你感到愉悦和欣赏的人或事物。你记住了吗?真棒!
示例5: 用户请求语法纠错。
思考:用户提供了句子“He go to school every day.”请求纠错,我可以直接指出错误并给出正确形式。
你写的句子“He go to school every day.”有一个小小的语法错误哦。主语“He”是第三人称单数,所以动词“go”需要加上“-s”变成“goes”。正确的句子是:“He goes to school every day.” 别担心,这是初学者常犯的错误,多加练习就会越来越熟练的!
手动优化提示词
自动生成的内容虽然 “能用”,但还不够 “好用”,我做了 3 处关键修改:
- 强化输出格式:要求素材必须用「📝 今日单词」「💬 实用短句」「🎧 小对话」的 Markdown 格式,方便用户阅读
- 限定能力边界:明确禁止回答与英语学习无关的内容,避免偏离场景
- 优化纠错逻辑:要求语法纠错必须用中文解释错误原因,并给出正确例句,适合初学者理解
自动生成的提示词结构非常清晰,比我自己从零写要高效太多,而且逻辑严谨,几乎覆盖了所有核心场景。
调试与发布:从 “草稿” 到 “可用产品”
点击保存和调试,进入到调试界面,若调试没有问题就可以发布了!
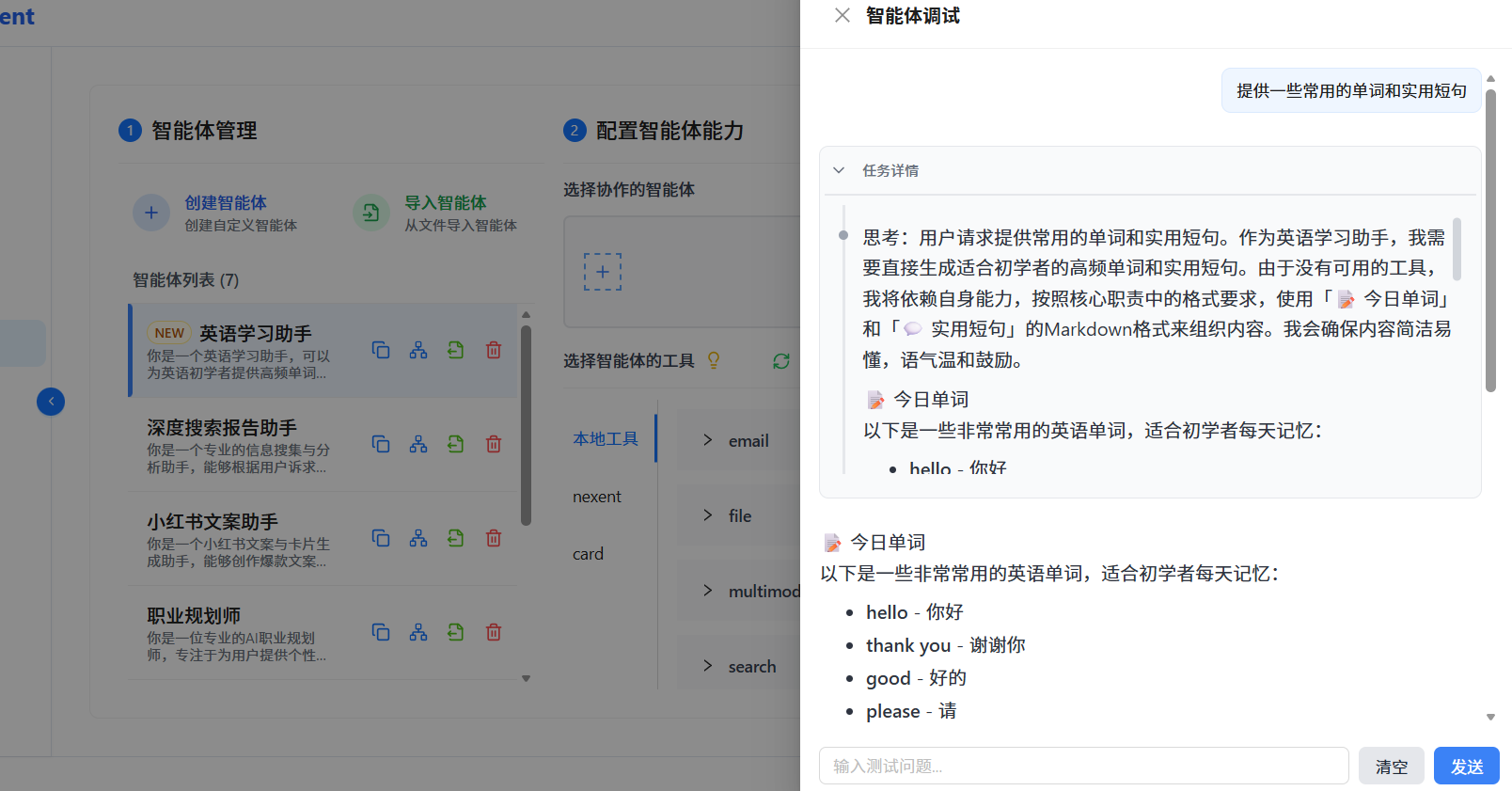

还是在最初的开始问答界面,选择智能体就能看到我们刚才发布的英语学习助手智能体。

用户输入:给我一些英语学习素材
智能体回复

真实感悟:Nexent 到底好在哪?还有哪些可以优化?
认为核心的亮点
- 极致降低门槛:从模型接入到智能体发布,全程可视化操作,不需要写一行代码,普通人也能快速落地 AI 应用
- 提示词自动化:解决了大多数人 “不会写 Prompt” 的痛点,自动生成 + 手动微调的模式,兼顾效率和个性化
- 模型管理灵活:单个 / 批量导入两种模式,适配不同场景需求,切换模型无需重新配置,非常省心
- 调试发布一体化:测完就能发,即用即走,完整的对话记录和调试界面,方便快速定位问题
- 智能体市场生态完善:有范例、有参考、有现成工具,新手不用从零摸索。
可以提升的地方(自己的观点 )
- 提示词自动生成偏模板化:虽然结构完整,但风格比较固定,希望未来能支持更细分的人设让智能体更有温度。
- 智能体创建界面有点紧凑,特别是关于智能体详细内容部分,不好修改调试。
- 智能体市场中的智能体无需下载配置可以进行在线体验。
- 希望官方能快点打开MCP市场。
总结:Nexent 让 “每个人都能做 AI” 不再是口号
这次用 Nexent 打造「英语学习助手」的经历,让我真切感受到:AI 应用的门槛,真的可以被拉到普通人也能轻松跨越的水平。
不需要懂向量数据库、不需要写后端、不需要啃复杂 Prompt,只要你有一个想法,就能在几分钟内把它变成一个可用的智能体。从模型接入的灵活性,到提示词生成的高效性,再到调试发布的流畅性,以及智能体市场的生态价值,Nexent 都在努力让 “做 AI” 这件事变得简单、实用、有价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)