用Shap解释Transformer回归模型:从搭建到可视化
Shap解释Transformer回归模型并且基于shap库对Transformer模型(pytorch搭建)进行解释,绘制变量重要性汇总图、自变量重要性、瀑布图、热图等等 因为是回归模型,和分类模型没什么区别,只是需要修改一下loss的计算方式,所以只用到了Transformer的Encoder模块,使用了4层encoder和1层全连接网络的结果,没有用embedding,因为自变量本身就有15个维度,而且全是数值,相当于自带embedding 代码架构说明: 第一步:数据处理 数据是从nhanes数据库中下载的,自变量有15个,因变量1个,每个样本看成维度为15的单词即可,建模前进行了归一化处理 第二步:构建transformer模型,包括4层encoder层和1层全连接层 第三步:评估模型,计算测试集的recall、f1、kappa、pre等 第四步:shap解释,用kernel解释器(适用于任意机器学习模型)对transformer模型进行解释,并且分别绘制自变量重要性汇总图、自变量重要性柱状图、单个变量的依赖图、单个变量的力图、单个样本的决策图、多个样本的决策图、热图、单个样本的解释图等8类图片 代码注释详细,逻辑简单,有python基础就可以看懂,包括原始数据、源代码、详细的说明文档和运行结果图,下载后先看说明文档,可一键运行出图,可以替换为自己的数据,可以进行简单的

在数据科学的世界里,理解模型的决策过程和各变量的重要性至关重要。今天咱们就来聊聊如何用Shap库对基于PyTorch搭建的Transformer回归模型进行解释,并绘制一系列超有用的可视化图表。
一、数据处理
咱的数据来自NHANES数据库,有15个自变量,1个因变量。每个样本就好比一个15维的 “单词” 。建模前先得归一化处理,这就像给数据们都规整到一个起跑线上。
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 假设数据下载后存为csv文件
data = pd.read_csv('nhanes_data.csv')
X = data.drop('target_variable', axis = 1)
y = data['target_variable']
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)在这段代码里,先用pandas库读取数据,然后把自变量和因变量分开。接着用MinMaxScaler进行归一化,让所有特征都在0到1之间,这样可以避免某些特征因为数值过大而主导模型训练。
二、构建Transformer模型
咱这回归模型只用到Transformer的Encoder模块,搭了4层encoder和1层全连接网络。由于自变量本身就是15维数值,就不用再搞embedding了,相当于它们自个儿就带了“入场券”。
import torch
import torch.nn as nn
from torch.nn import TransformerEncoder, TransformerEncoderLayer
class TransformerRegression(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers):
super(TransformerRegression, self).__init__()
encoder_layers = TransformerEncoderLayer(input_dim, nhead = 1)
self.transformer_encoder = TransformerEncoder(encoder_layers, num_layers)
self.fc = nn.Linear(input_dim, 1)
def forward(self, src):
output = self.transformer_encoder(src)
output = torch.mean(output, dim = 1)
output = self.fc(output)
return output
input_dim = 15
hidden_dim = 64
num_layers = 4
model = TransformerRegression(input_dim, hidden_dim, num_layers)这里定义了一个TransformerRegression类,继承自nn.Module。在初始化里,先定义了TransformerEncoder,这里nhead设为1(简单起见),然后是一个全连接层。前向传播时,数据先经过TransformerEncoder,再取平均池化,最后通过全连接层输出预测值。
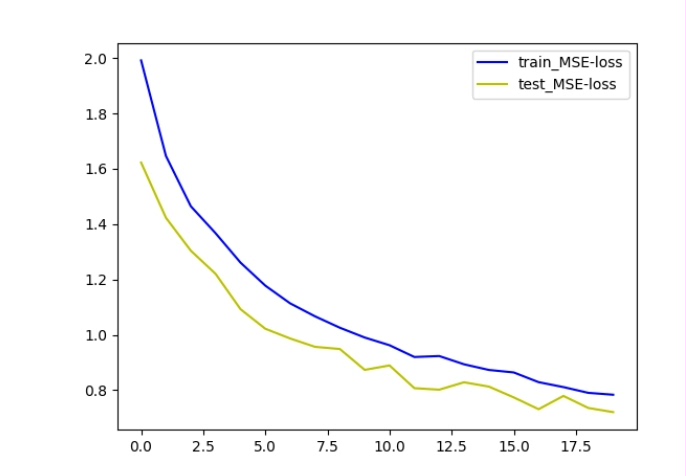
三、评估模型
模型搭好就得评估评估,咱计算测试集的recall、f1、kappa、pre这些指标。
from sklearn.metrics import recall_score, f1_score, cohen_kappa_score, precision_score
import torch.optim as optim
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr = 0.001)
# 假设已经划分好训练集和测试集
X_train_tensor = torch.FloatTensor(X_scaled_train)
y_train_tensor = torch.FloatTensor(y_train.values).unsqueeze(1)
X_test_tensor = torch.FloatTensor(X_scaled_test)
y_test_tensor = torch.FloatTensor(y_test.values).unsqueeze(1)
for epoch in range(100):
model.train()
optimizer.zero_grad()
output = model(X_train_tensor)
loss = criterion(output, y_train_tensor)
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
test_output = model(X_test_tensor)
y_pred = test_output.squeeze().numpy()
y_true = y_test_tensor.squeeze().numpy()
recall = recall_score(y_true, y_pred.round())
f1 = f1_score(y_true, y_pred.round())
kappa = cohen_kappa_score(y_true, y_pred.round())
pre = precision_score(y_true, y_pred.round())这里用均方误差(MSELoss)作为损失函数,Adam优化器来更新模型参数。训练100轮后,在测试集上计算各项指标。注意这里的round函数是因为某些指标计算需要二分类的预测结果。
四、Shap解释及可视化
这部分用kernel解释器对Transformer模型进行解释,然后绘制8类超酷的可视化图表。
import shap
# 初始化KernelExplainer
explainer = shap.KernelExplainer(model, X_train_tensor)
# 计算SHAP值
shap_values = explainer.shap_values(X_test_tensor)
# 绘制自变量重要性汇总图
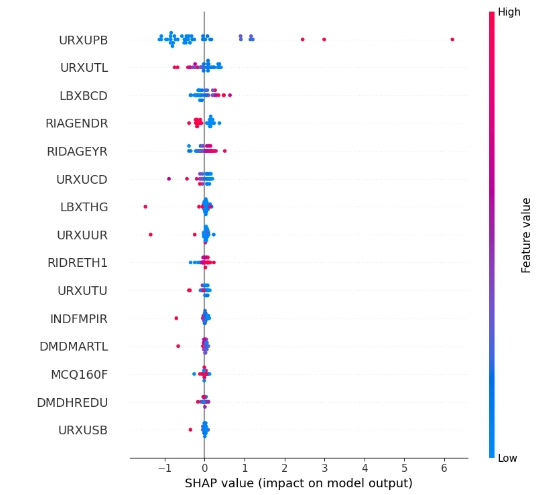
shap.summary_plot(shap_values, X_test_tensor)
# 绘制自变量重要性柱状图
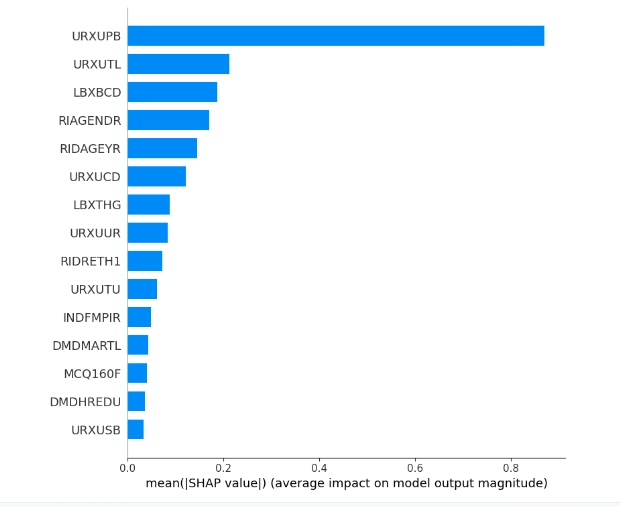
shap.summary_plot(shap_values, X_test_tensor, plot_type='bar')
# 绘制单个变量的依赖图,假设变量索引为0
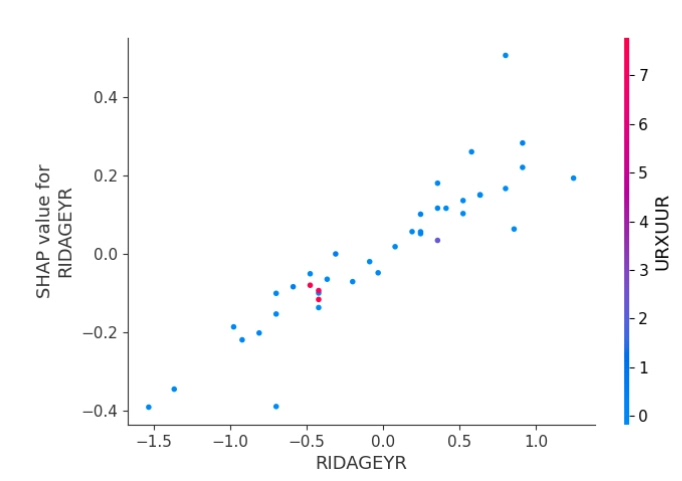
shap.dependence_plot(0, shap_values, X_test_tensor)
# 绘制单个变量的力图,假设变量索引为0
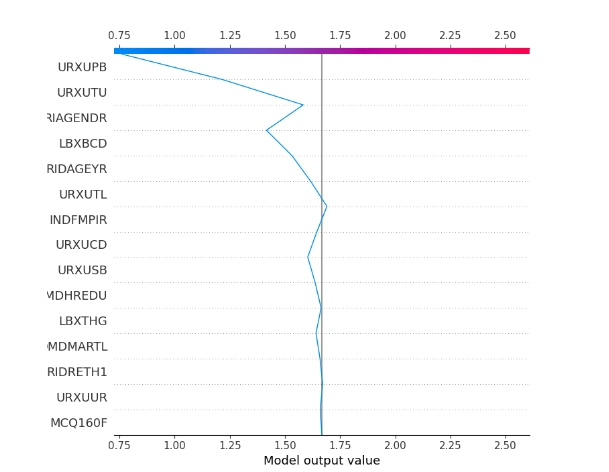
shap.force_plot(explainer.expected_value, shap_values[0], X_test_tensor[0])
# 绘制单个样本的决策图,假设样本索引为0
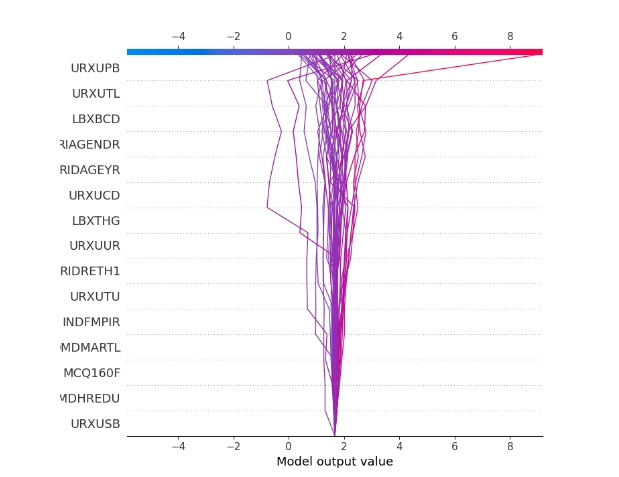
shap.decision_plot(explainer.expected_value, shap_values[0], feature_names = X.columns)
# 绘制多个样本的决策图,假设前5个样本
shap.decision_plot(explainer.expected_value, shap_values[:5], feature_names = X.columns)
# 绘制热图
shap.plots.heatmap(shap_values)
# 绘制单个样本的解释图,假设样本索引为0
shap.force_plot(explainer.expected_value, shap_values[0], X_test_tensor[0], matplotlib = True)首先初始化KernelExplainer,它适用于任意机器学习模型。然后计算SHAP值,这是Shap库用来衡量特征重要性的关键指标。接着就开始各种绘图,summaryplot绘制汇总图和柱状图展示各变量重要性;dependenceplot看单个变量与预测值的关系;forceplot和decisionplot分别从不同角度展示单个或多个样本的决策过程;heatmap热图能直观看到各特征与SHAP值的关系。
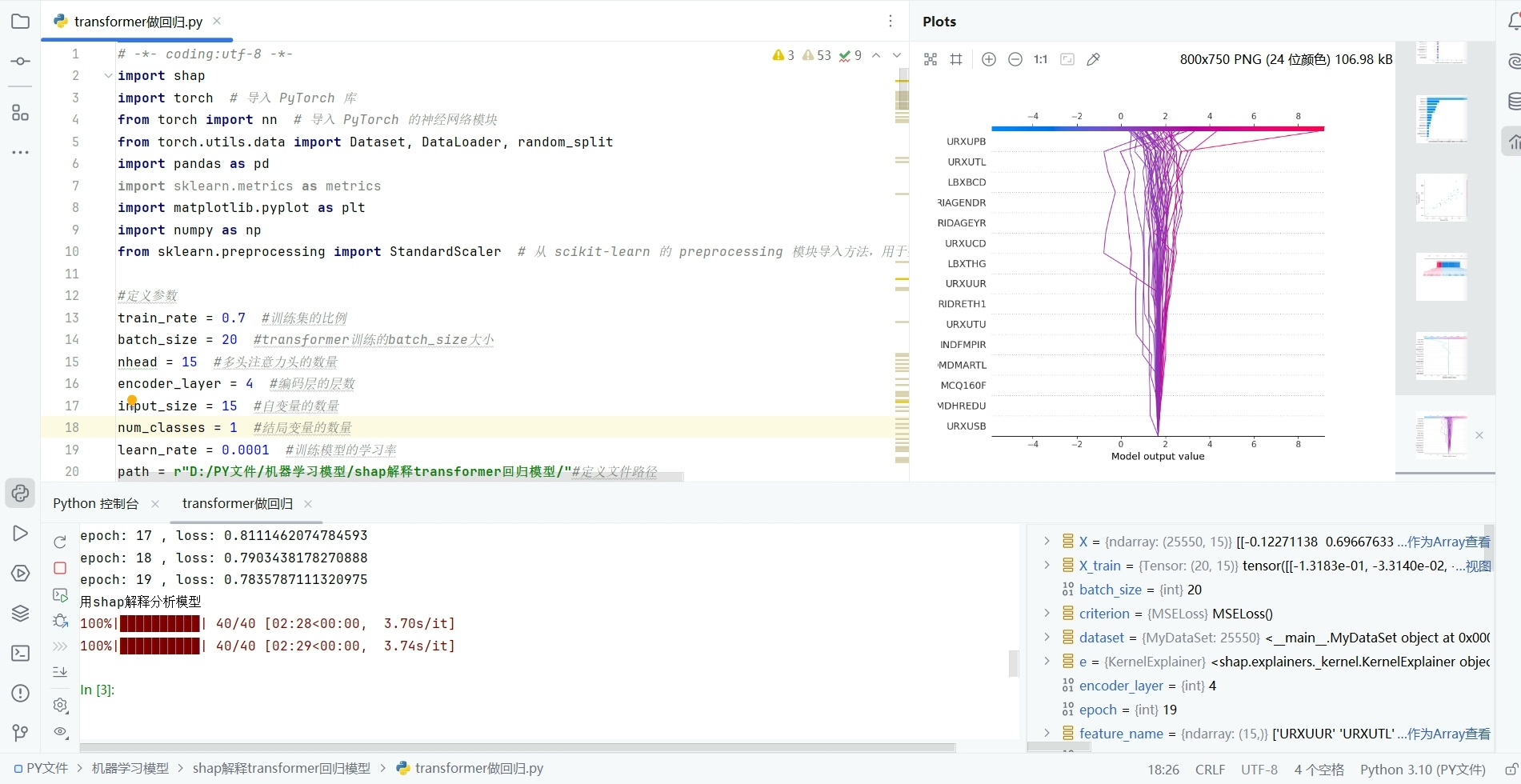
Shap解释Transformer回归模型并且基于shap库对Transformer模型(pytorch搭建)进行解释,绘制变量重要性汇总图、自变量重要性、瀑布图、热图等等 因为是回归模型,和分类模型没什么区别,只是需要修改一下loss的计算方式,所以只用到了Transformer的Encoder模块,使用了4层encoder和1层全连接网络的结果,没有用embedding,因为自变量本身就有15个维度,而且全是数值,相当于自带embedding 代码架构说明: 第一步:数据处理 数据是从nhanes数据库中下载的,自变量有15个,因变量1个,每个样本看成维度为15的单词即可,建模前进行了归一化处理 第二步:构建transformer模型,包括4层encoder层和1层全连接层 第三步:评估模型,计算测试集的recall、f1、kappa、pre等 第四步:shap解释,用kernel解释器(适用于任意机器学习模型)对transformer模型进行解释,并且分别绘制自变量重要性汇总图、自变量重要性柱状图、单个变量的依赖图、单个变量的力图、单个样本的决策图、多个样本的决策图、热图、单个样本的解释图等8类图片 代码注释详细,逻辑简单,有python基础就可以看懂,包括原始数据、源代码、详细的说明文档和运行结果图,下载后先看说明文档,可一键运行出图,可以替换为自己的数据,可以进行简单的
整个项目代码注释详细,逻辑简单,有Python基础就能看懂。原始数据、源代码、详细说明文档和运行结果图一应俱全,下载后先看说明文档,就能一键运行出图,还能轻松替换成自己的数据,是不是超方便!希望大家能从这个项目里学到如何深入理解Transformer回归模型~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)