知析智能AI助手系统开发全流程解析
1 开发步骤
1.1 需求分析
1.1.1 项目介绍
传统办公系统只能完成静态的数据录入与展示,缺乏对非结构化信息的理解与处理能力,无法高效完成文档摘要、网页信息提取、知识库问答、会议纪要整理、调研报告生成等复杂任务。
拟设计并实现一套大模型助手系统,面向文档处理、知识检索、内容生成和任务执行场景,集成多轮对话、RAG 知识库、工具调用、MCP 服务、自主规划智能体等能力,提升用户的信息获取与内容生产效率。
1.1.2 项目目标
- 支持用户进行多轮自然语言对话
- 支持上传文件并解析内容
- 支持抓取网页正文并进行总结
- 支持知识库构建与检索增强问答
- 支持生成摘要、会议纪要、调研报告等内容
- 支持工具调用和 MCP 扩展服务
- 支持复杂任务的自动规划与执行
- 支持结果导出与历史任务查看
1.1.3 角色
普通用户(重点)
使用系统进行对话问答、知识检索、文档分析、内容生成、任务执行。
管理员(弱化)
管理用户、知识库、模型配置、任务日志、系统监控信息。
1.1.4 核心功能
场景一:智能对话
用户直接输入问题,系统基于大模型进行多轮对话,并支持上下文记忆。
-
多轮对话
-
对话记忆持久化
-
流式输出
-
历史会话查看
-
模型切换
场景二:文档问答
用户上传 PDF、DOCX、TXT 等文档,系统解析文本后支持摘要生成、内容问答与报告输出。
-
文件上传
-
文件解析
-
文本预览
-
文档摘要
-
文档问答
场景三:网页分析
用户输入 URL,系统自动抓取网页正文,提取重点信息并生成总结。
-
URL 输入
-
网页正文抓取
-
网页内容清洗
-
网页摘要
-
网页内容归档
场景四:知识库问答
用户上传多个文档构建知识库,通过 RAG 进行私有资料问答。
-
知识库创建
-
文档导入
-
文档切片
-
向量化存储
-
检索增强问答
-
检索策略配置
场景五:内容生成
用户基于对话、文档或网页内容生成会议纪要、学习笔记、调研报告、周报等结构化文本。
-
摘要生成
-
会议纪要生成
-
调研报告生成
-
周报/日报生成
-
结构化输出
-
Markdown/HTML/PDF 导出
场景六:智能体任务执行
用户只输入目标,系统自动拆解任务,调用搜索、抓取、下载、PDF 生成等工具完成复杂任务。
-
工具调用
-
MCP 服务调用
-
复杂任务规划
-
执行过程展示
-
执行结果导出
1.1.5 非功能需求
性能要求
-
普通问答响应时间控制在 3~10 秒
-
文档解析与网页抓取任务支持异步处理
-
系统支持同时处理多个用户请求
安全要求
-
接口鉴权
-
参数校验
-
文件类型与大小限制
-
异常处理与日志追踪
-
MCP 与工具调用权限控制
可维护性要求
-
分层架构清晰
-
模块解耦
-
统一返回体
-
统一异常处理
-
统一日志规范
可扩展性要求
-
支持切换不同大模型
-
支持新增工具与 MCP 服务
-
支持新增内容生成模板
-
支持扩展知识库类型
1.2 原型设计
1.2.1 页面清单
8 个核心页面。
1)登录页
-
用户名密码登录
-
系统介绍
-
进入首页
2)首页/工作台
-
系统简介
-
快速入口
-
最近任务
-
最近会话
-
使用统计
3)智能对话页
-
左侧会话列表
-
中间对话区
-
输入框
-
模型切换
-
是否启用知识库/工具/智能体
4)知识库管理页
-
知识库列表
-
新建知识库
-
上传文档
-
文档解析状态
-
向量化状态
-
删除/重建索引
5)文档处理页
-
上传文件
-
文本预览
-
任务类型选择
-
生成摘要/纪要/报告
-
下载结果
6)网页分析页
-
输入 URL
-
抓取网页正文
-
内容预览
-
生成摘要或报告
-
存入知识库
7)智能体任务页
-
输入任务目标
-
展示任务规划步骤
-
展示工具调用日志
-
展示最终结果
-
支持导出
8)系统管理页
-
模型配置
-
接口配置
-
任务日志
-
工具与 MCP 配置
具体表现为:
①智能对话页
左侧:
-
会话列表
-
新建会话按钮
右侧:
-
顶部:模型选择、是否开启知识库、是否开启工具、是否开启智能体
-
中间:消息流
-
底部:输入框、上传附件、发送按钮
②知识库管理页
-
顶部:新建知识库
-
中间:知识库列表
-
右侧弹窗:上传文档、查看文档状态、切片数量、向量化结果
智能体任务页
-
左侧:任务输入区
-
中间:规划步骤和执行状态
-
右侧:结果预览与导出按钮
1.2.2 用户使用流程设计
流程一:文档摘要
用户上传文档 → 系统解析文本 → 用户选择“摘要生成” → 大模型生成摘要 → 用户预览并导出
流程二:知识库问答
用户新建知识库 → 上传多个文档 → 系统切片与向量化 → 用户进入问答页面 → 系统检索相关片段 → 大模型生成答案
流程三:智能体执行
用户输入任务目标 → 系统生成计划 → 调用搜索/抓取/下载/PDF 工具 → 汇总结果 → 展示最终报告
1.3 系统总体架构
1.3.1 前端层
-
Vue 3
-
Element Plus
-
Pinia
-
Axios
负责页面展示、交互、SSE 接收、任务状态渲染。
接口层
-
REST API
-
SSE 流式接口
负责前后端通信和实时结果推送。
1.3.2 业务层
-
对话服务
-
知识库服务
-
文档服务
-
网页服务
-
内容生成服务
-
工具服务
-
MCP 服务
-
智能体调度服务
1.3.3 AI 能力层
-
Spring AI
-
LangChain4j
-
RAG 检索增强
-
Prompt 模板
-
ChatMemory
-
Advisor
-
Tool Calling
-
ReAct Agent
1.3.4 数据层
-
MySQL
-
Redis
-
PGvector
-
本地文件存储 / MinIO
1.4 数据库设计
user 存储用户基础信息。
chat_session 记录会话基本信息
chat_message 记录对话消息
knowledge_base 记录知识库信息
knowledge_document 记录知识库文档
knowledge_chunk 记录文档切片
web_resource 记录网页资源
ai_task 记录 AI 任务
agent_plan 记录智能体任务
tool_call_log 记录工具调用日志
mcp_call_log 记录 MCP 调用日志
export_record 记录导出信息
1.5 接口设计
用户模块
-
POST /api/user/login -
POST /api/user/register -
GET /api/user/info
会话模块
-
POST /api/chat/session/create -
GET /api/chat/session/list -
GET /api/chat/message/list -
POST /api/chat/send -
GET /api/chat/stream
文档模块
-
POST /api/file/upload -
POST /api/file/parse -
GET /api/file/detail -
GET /api/file/preview
知识库模块
-
POST /api/kb/create -
GET /api/kb/list -
POST /api/kb/upload -
POST /api/kb/reindex -
POST /api/kb/chat
网页模块
-
POST /api/web/crawl -
GET /api/web/detail -
POST /api/web/summary
内容生成模块
-
POST /api/content/summary -
POST /api/content/minutes -
POST /api/content/report -
{ "code": 200, "message": "success", "data": {} }POST /api/content/export
智能体模块
-
POST /api/agent/run -
GET /api/agent/task/detail -
GET /api/agent/task/stream
配置模块
-
GET /api/config/model/list -
POST /api/config/model/switch -
GET /api/config/tool/list
统一返回格式如下:
{
"code": 200,
"message": "success",
"data": {}
}2 准备工作
2.1 创建前端页面
创建一个文件夹,目录为
zhixi-ai-platform/
│
├── zhixi-ai-backend/ # 后端(Spring Boot)
│
├── zhixi-ai-frontend/ # 前端(Vue3 + Vite)
│
├── docs/ # 项目文档(非常加分🔥)
│
├── sql/ # 数据库脚本
│
└── README.md在 zhixi-ai-platform 目录执行
npm create vite@latest zhixi-ai-frontend选vue+JavaScript
创建成功,打开网页
前置知识:
讲一下关系:
JavaScript 是语言
Vue 是前端框架
Vite 是构建工具
Node.js 是运行环境main.js 是项目入口(启动整个应用)
index.js(router)是路由配置(管理页面跳转)
输入prompt,自动生成静态网页,暂不包含后端逻辑
你现在是我的前端开发助手,请基于我当前已经创建好的 Vue 3 项目,直接完善并生成“大模型助手系统”前端页面。
一、项目背景
这是一个“基于 Spring Boot + 大模型能力”的毕业设计项目,项目名称为:
《大模型助手系统设计与实现》
系统定位:
面向学习、办公、资料整理和任务执行场景的 AI 助手平台,支持智能对话、知识库管理、文档处理、智能体任务执行等功能。
二、技术要求
请严格按照以下技术栈和约束生成代码:
1. 使用 Vue 3
2. 使用 Vue Router
3. 使用 Element Plus
4. 使用 script setup 语法
5. 使用单文件组件 .vue
6. 不要引入额外的重型 UI 框架
7. 先不要接后端接口,全部使用前端本地 mock 数据
8. 页面风格统一为“企业后台管理系统风格”
9. 布局简洁、专业、适合毕业设计答辩展示
10. 所有文案使用中文
11. 所有代码要可直接运行,不能只给伪代码
12. 尽量复用当前已有的项目结构,不要推翻重建
13. 如果某些文件不存在,请自动创建
14. 样式尽量写在组件内部 scoped 中,保证清晰易维护
三、现有项目结构
当前项目已经有如下基础结构,请在这个基础上继续开发:
src
├─ api
├─ assets
├─ components
├─ layout
│ └─ AdminLayout.vue
├─ router
│ └─ index.js
├─ views
│ ├─ Login.vue
│ ├─ Dashboard.vue
│ ├─ Chat.vue
│ ├─ KnowledgeBase.vue
│ ├─ Document.vue
│ └─ Agent.vue
├─ App.vue
└─ main.js
四、目标
请直接帮我完成以下内容:
1. 完善后台主布局 AdminLayout.vue
2. 完善路由 index.js
3. 生成并完善以下 6 个页面
- Login.vue 登录页
- Dashboard.vue 工作台
- Chat.vue 智能对话页
- KnowledgeBase.vue 知识库管理页
- Document.vue 文档处理页
- Agent.vue 智能体任务页
4. 如果有必要,可补充公共组件到 components 目录
5. 所有页面使用 mock 数据展示真实业务感
6. 页面之间路由可正常跳转
7. 最终项目启动后能直接看到一个完整的“企业后台风格”的前端系统
五、整体设计要求
1. 主布局要求
AdminLayout.vue 采用经典后台布局:
- 左侧深色菜单栏
- 顶部浅色 header
- 中间主内容区域
- 菜单项包括:
- 工作台
- 智能对话
- 知识库管理
- 文档处理
- 智能体任务
- header 中展示:
- 系统标题:大模型助手系统
- 右侧用户区域:管理员 / 退出登录按钮(退出先只跳转到登录页即可)
- 整体风格简洁、稳重、现代、企业化
- 页面宽度和间距舒适,不要显得拥挤
2. 通用视觉要求
- 主内容区背景用浅灰色
- 卡片用白底圆角
- 标题清晰
- 合理使用表格、按钮、标签、表单、抽屉、弹窗、分栏
- 不要做花哨的渐变炫技风格
- 更偏向“企业后台系统”和“AI 应用平台”的感觉
六、各页面详细要求
====================
页面1:Login.vue 登录页
====================
要求:
1. 做一个居中的登录卡片
2. 页面背景简洁高级,不要太花
3. 登录卡片包含:
- 系统标题:大模型助手系统
- 副标题:面向学习与办公场景的智能 AI 助手平台
- 用户名输入框
- 密码输入框
- 登录按钮
4. 表单校验:
- 用户名不能为空
- 密码不能为空
5. 点击登录后:
- 不调用后端
- 直接跳转到 /dashboard
6. 页面底部可展示一行小字:
- 基于 Vue 3 + Element Plus 构建
7. 视觉上要像真实系统登录页
====================
页面2:Dashboard.vue 工作台
====================
要求:
1. 页面顶部显示欢迎语:
- 欢迎使用大模型助手系统
- 一句简短说明:统一管理智能对话、知识库、文档处理与智能体任务
2. 生成 4 个统计卡片,展示 mock 数据:
- 今日对话次数
- 已建知识库数量
- 已处理文档数量
- 智能体任务数量
3. 生成一个“快捷入口”区域,使用卡片按钮形式跳转:
- 去智能对话
- 去知识库管理
- 去文档处理
- 去智能体任务
4. 生成一个“最近任务”表格,mock 几条数据,字段包括:
- 任务名称
- 任务类型
- 状态
- 创建时间
5. 生成一个“最近会话”列表区域,展示几条 mock 数据
6. 页面要像一个真正的系统首页/工作台
====================
页面3:Chat.vue 智能对话页
====================
要求:
整体采用三栏布局:
- 左侧:会话列表
- 中间:聊天区域
- 右侧:参数配置面板
1. 左侧会话列表
- 顶部有“新建会话”按钮
- 下方展示会话列表 mock 数据
- 每个会话显示:
- 会话标题
- 最后更新时间
- 当前选中的会话高亮
- 点击可以切换会话
2. 中间聊天区域
- 顶部显示当前会话标题
- 中间显示聊天消息流
- 消息分为用户消息和 AI 消息,样式区分开
- mock 3~5 轮对话
- 底部有输入框和发送按钮
- 发送后:
- 将用户输入加入消息列表
- 模拟追加一条 AI 回复
- 支持回车发送
- 页面整体要有“类似 ChatGPT 企业版工作台”的感觉
3. 右侧参数面板
需要做一个配置卡片区域,包含:
- 模型选择(下拉框)
- DeepSeek
- 通义千问
- 本地 Ollama
- 是否启用知识库(开关)
- 是否启用工具调用(开关)
- 是否启用智能体模式(开关)
- 输出风格(下拉框)
- 简洁
- 专业
- 详细
- 最大输出长度(滑块或输入框)
- 一个“保存配置”按钮
4. 页面底部输入区可支持:
- 文本输入框
- 上传附件按钮(先只做 UI,不接逻辑)
- 发送按钮
====================
页面4:KnowledgeBase.vue 知识库管理页
====================
要求:
这个页面要像企业里的“知识库管理后台”。
1. 顶部区域
- 页面标题:知识库管理
- 副标题:管理知识库、上传文档并进行向量化处理
- 右侧按钮:新建知识库
2. 知识库列表区域
- 用表格展示 mock 数据
- 字段包括:
- 知识库名称
- 描述
- 文档数量
- 状态
- 创建时间
- 操作
- 操作按钮包括:
- 查看详情
- 上传文档
- 删除
3. 新建知识库弹窗
- 点击“新建知识库”弹出表单对话框
- 表单字段:
- 知识库名称
- 知识库描述
- 提交后把数据加到表格中
4. 上传文档弹窗
- 模拟文档上传 UI
- 字段包括:
- 选择文件
- 文档类型
- 是否自动向量化
- 下方展示 mock 的文档列表:
- 文件名
- 解析状态
- 向量化状态
5. 页面下方可增加一个“检索配置示例”卡片
内容包括:
- 切片大小
- 重叠长度
- TopK
- 检索策略
全部用展示型表单即可,先不做保存逻辑
====================
页面5:Document.vue 文档处理页
====================
要求:
这个页面体现“文档上传、预览、处理、导出”的完整流程。
布局建议:
- 上方:上传和任务配置
- 中间:文档预览
- 右侧或下方:生成结果
1. 上传区域
- 页面标题:文档处理
- 副标题:上传文档并生成摘要、会议纪要或调研报告
- 上传组件:支持拖拽上传的 UI 风格
- 提示支持格式:
- PDF / DOCX / TXT
2. 任务配置区域
包含以下控件:
- 任务类型选择:
- 文档摘要
- 会议纪要
- 调研报告
- 输出风格:
- 简洁
- 专业
- 学术
- 输出格式:
- Markdown
- HTML
- PDF
- 生成按钮
3. 文档预览区
- 使用卡片展示一段 mock 文档内容
- 内容像真实文档,不要只写“这里是文档内容”
- 可以显示:
- 文档标题
- 上传时间
- 文档正文片段
4. 结果区
- 生成后展示 mock 的 AI 输出结果
- 根据不同任务类型切换不同结果标题
- 结果区要像真正的“AI 生成内容展示面板”
- 提供:
- 复制按钮
- 导出按钮(只做前端提示)
- 重新生成按钮
====================
页面6:Agent.vue 智能体任务页
====================
要求:
这个页面是项目亮点,要有“智能体自动规划执行任务”的感觉。
布局建议:
- 上方:任务输入区
- 中间左侧:任务规划步骤
- 中间右侧:工具调用日志
- 下方:最终结果区
1. 顶部任务输入区
- 页面标题:智能体任务
- 副标题:输入任务目标,系统将自动规划步骤并调用工具完成任务
- 输入框示例占位:
- 例如:请搜索“人工智能在教育领域的应用”,整理成调研报告并导出 PDF
- 按钮:
- 开始执行
- 清空任务
2. 任务规划区
- 展示 mock 步骤列表
- 每个步骤包括:
- 步骤序号
- 步骤名称
- 状态(待执行、执行中、已完成)
- 简要说明
- 建议 mock 5 个步骤,例如:
- 分析用户意图
- 联网搜索资料
- 抓取网页正文
- 汇总生成报告
- 导出 PDF
3. 工具调用日志区
- 用时间线或列表展示 mock 数据
- 字段包括:
- 工具名称
- 调用时间
- 调用状态
- 返回结果摘要
- 工具名可包括:
- WebSearchTool
- WebCrawlerTool
- PdfExportTool
- FileTool
4. 最终结果区
- 展示一段结构化调研报告结果
- 包含:
- 标题
- 摘要
- 核心观点
- 建议
- 右上角放:
- 复制结果
- 导出 PDF
- 保存任务
- 页面要强烈体现“AI 智能体执行中心”的感觉
七、代码质量要求
1. 所有页面不要只生成一个大 div
2. 合理拆分模板结构
3. data、methods、computed 要清晰
4. 使用组合式 API
5. mock 数据要真实,不要太敷衍
6. 每个页面都要有基本交互,不只是静态排版
7. 不要使用假装存在的接口调用
8. 如果需要提示,使用 Element Plus 的 message
9. 路由切换后页面正常显示
10. 页面命名、变量命名清晰规范
八、路由要求
请确保这些路由存在并可正常访问:
- /login
- /dashboard
- /chat
- /knowledge
- /document
- /agent
默认访问 / 时,重定向到 /dashboard
退出登录时跳到 /login
九、额外优化要求
请适当补充以下细节,让页面更像真实系统:
1. 状态标签颜色区分
2. 表格操作按钮合理排版
3. 空状态时有提示
4. 表单间距统一
5. 卡片区域上下留白自然
6. 不要出现明显的页面错位
7. 页面在常见桌面端尺寸下展示良好
8. 可以适当添加图标,但不要过多
9. 工作台和智能体页尽量做出项目亮点
十、最终输出要求
请直接在我当前工程中完成代码修改,不要只告诉我思路。
请按文件维度直接生成或修改这些文件的完整代码:
- src/layout/AdminLayout.vue
- src/router/index.js
- src/views/Login.vue
- src/views/Dashboard.vue
- src/views/Chat.vue
- src/views/KnowledgeBase.vue
- src/views/Document.vue
- src/views/Agent.vue
如果你认为有必要,也可以补充:
- src/components 下的公共组件
- 少量通用样式
但不要过度复杂化。
十一、执行方式要求
请你:
1. 直接开始修改代码
2. 如果发现某个页面还需要补充一些小组件,就自动创建
3. 保证代码之间互相兼容
4. 完成后给出:
- 修改了哪些文件
- 如何运行
- 我下一步应该先看哪个页面
请现在开始生成完整实现代码。2.2 创建后端工程
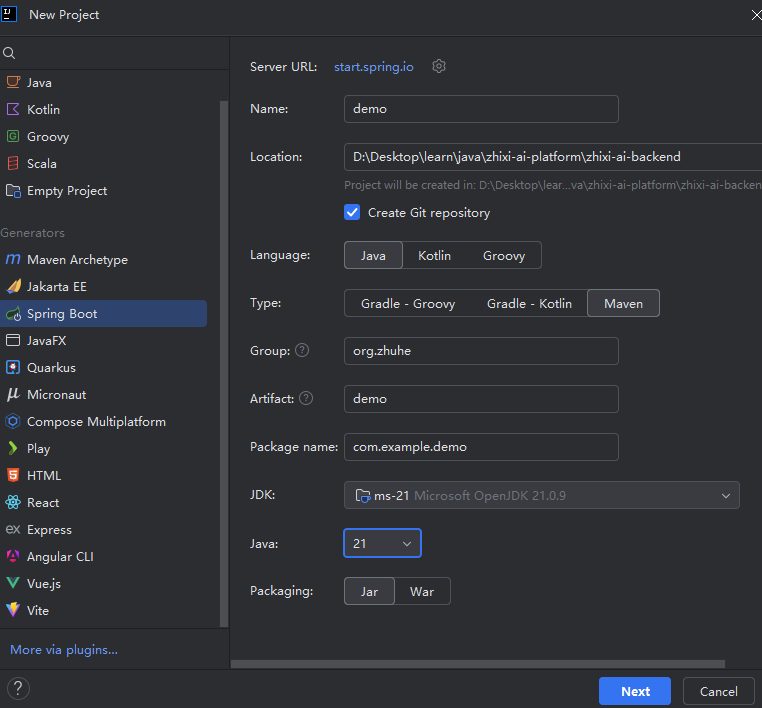
注意jdk版本建议是21,同时,注意maven版本也是21
创建好后,我们试一下是否可以package和run,再进行下一步
2.2.1 引入依赖包
引入hutool、knife4j包
其中,knife包我们要复制配置,一会在idea中改
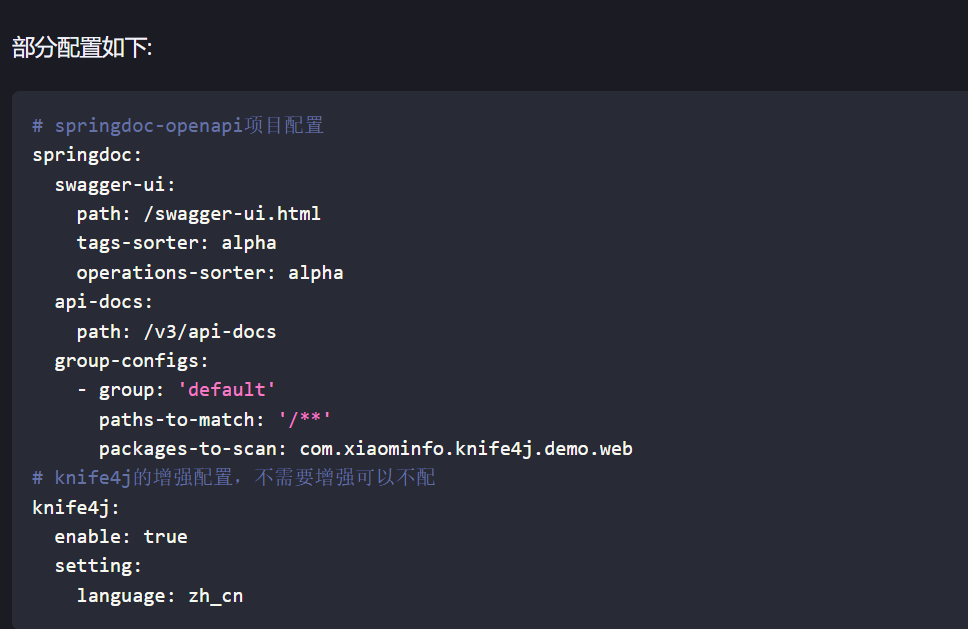
2.2.2 配置
配置文件在resources下,他是propeties文件,我们改成yml文件,
spring:
application:
name: zhixi-ai
server:
port: 8123
servlet:
context-path: /api
# springdoc-openapi项目配置
springdoc:
swagger-ui:
path: /swagger-ui.html
tags-sorter: alpha
operations-sorter: alpha
api-docs:
path: /v3/api-docs
group-configs:
- group: 'default'
paths-to-match: '/**'
packages-to-scan: org.zhuhe.zhixiai.controller
# knife4j的增强配置,不需要增强可以不配
knife4j:
enable: true
setting:
language: zh_cn其中,我改了这一行,packages-to-scan: org.zhuhe.zhixiai.controller
这是用来指定扫描路径的,就是说,你要监控哪些包的接口
注意!冒号之后要连着空格
最后,我们写了一个测试接口,测试api/doc.html是否可以访问,如下:
2.3 大模型接入
2.3.1 SDK调用大模型
打开大模型服务平台百炼控制台,向pom中添加
<!-- 阿里云百炼-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<version>2.22.6</version>
<scope>compile</scope>
</dependency>然后申请一个api,
再直接调用即可
// 建议dashscope SDK的版本 >= 2.12.0
import java.util.Arrays;
import java.lang.System;
import com.alibaba.dashscope.aigc.generation.Generation;
import com.alibaba.dashscope.aigc.generation.GenerationParam;
import com.alibaba.dashscope.aigc.generation.GenerationResult;
import com.alibaba.dashscope.common.Message;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.InputRequiredException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.utils.JsonUtils;
import org.zhuhe.zhixiai.demo.invoke.TestApiKey;
public class TestApi {
public static GenerationResult callWithMessage() throws ApiException, NoApiKeyException, InputRequiredException {
Generation gen = new Generation();
Message systemMsg = Message.builder()
.role(Role.SYSTEM.getValue())
.content("You are a helpful assistant.")
.build();
Message userMsg = Message.builder()
.role(Role.USER.getValue())
.content("你是谁?")
.build();
GenerationParam param = GenerationParam.builder()
// 若没有配置环境变量,请用百炼API Key将下行替换为:.apiKey("sk-xxx")
.apiKey(TestApiKey.ApiKey)
// 此处以qwen-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
.model("qwen-plus")
.messages(Arrays.asList(systemMsg, userMsg))
.resultFormat(GenerationParam.ResultFormat.MESSAGE)
.build();
return gen.call(param);
}
public static void main(String[] args) {
try {
GenerationResult result = callWithMessage();
System.out.println(JsonUtils.toJson(result));
} catch (ApiException | NoApiKeyException | InputRequiredException e) {
// 使用日志框架记录异常信息
System.err.println("An error occurred while calling the generation service: " + e.getMessage());
}
System.exit(0);
}
}2.3.2 curl调用大模型
和上面没啥两样,继续打开文档
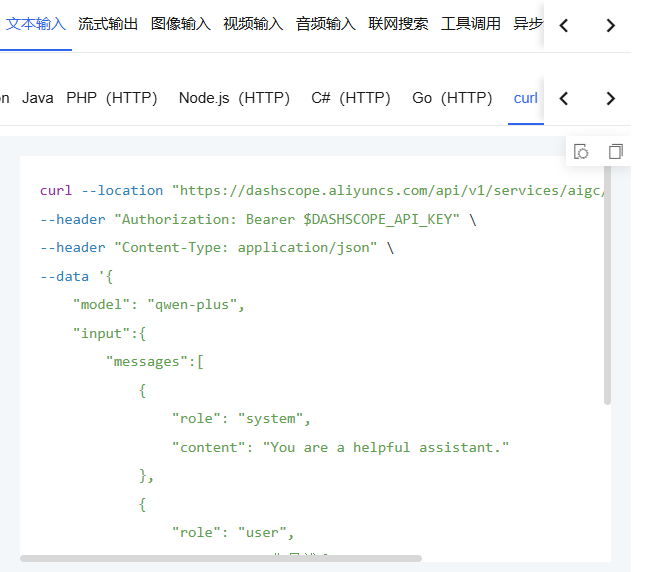
然后复制,复制给chatGPT,让他生成java代码就行
package org.zhuhe.zhixiai.demo.invoke;
import cn.hutool.http.ContentType;
import cn.hutool.http.HttpRequest;
import cn.hutool.http.HttpResponse;
import cn.hutool.json.JSONUtil;
import java.util.HashMap;
import java.util.Map;
public class TestCurlApi {
public static void main(String[] args) {
String apiKey = TestApiKey.ApiKey;
if (apiKey == null || apiKey.isBlank()) {
System.out.println("环境变量 DASHSCOPE_API_KEY 未设置");
return;
}
String url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation";
Map<String, Object> systemMsg = new HashMap<>();
systemMsg.put("role", "system");
systemMsg.put("content", "You are a helpful assistant.");
Map<String, Object> userMsg = new HashMap<>();
userMsg.put("role", "user");
userMsg.put("content", "你是谁?");
Map<String, Object> input = new HashMap<>();
input.put("messages", new Object[]{systemMsg, userMsg});
Map<String, Object> parameters = new HashMap<>();
parameters.put("result_format", "message");
Map<String, Object> body = new HashMap<>();
body.put("model", "qwen-plus");
body.put("input", input);
body.put("parameters", parameters);
String requestBody = JSONUtil.toJsonStr(body);
try (HttpResponse response = HttpRequest.post(url)
.header("Authorization", "Bearer " + apiKey)
.contentType(ContentType.JSON.getValue())
.body(requestBody)
.execute()) {
System.out.println("状态码:" + response.getStatus());
System.out.println("响应结果:");
System.out.println(response.body());
} catch (Exception e) {
e.printStackTrace();
}
}
}2.3.3 SpringAI调用大模型
注意 这里,为了适合国产宝宝体制,我使用的是Spring AI Alibaba
打开快速开始 | Spring AI Alibaba,在你的项目中添加 Maven 依赖
然后配置api-key
为保证api-key不被上传到git
我们写两个yml文件
application-local.yml中这样写
spring:
ai:
dashscope:
api-key: sk-2adfe435e13b7c1e9eadd0f4
application.yml中这样写
spring:
application:
name: zhixi-ai
profiles:
active: local
server:
port: 8123
servlet:
context-path: /api
# springdoc-openapi项目配置
springdoc:
swagger-ui:
path: /swagger-ui.html
tags-sorter: alpha
operations-sorter: alpha
api-docs:
path: /v3/api-docs
group-configs:
- group: 'default'
paths-to-match: '/**'
packages-to-scan: org.zhuhe.zhixiai.controller
# knife4j的增强配置,不需要增强可以不配
knife4j:
enable: true
setting:
language: zh_cnpackage org.zhuhe.zhixiai.demo.invoke;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Component;
@Component
public class SpringAIApi implements CommandLineRunner {//CommandLineRunner是 Spring Boot 提供的一个接口。它的作用是:项目启动完成后,自动执行一段代码。
@Resource
private ChatModel dashScopeChatModel;//你引入了 Spring AI + DashScope 的 starter 依赖后 Spring Boot 在启动时根据自动配置,帮你创建了一个 ChatModel 类型的 Bean,然后再注入到这里。
@Override
public void run(String... args) throws Exception {
AssistantMessage output = dashScopeChatModel.call(new Prompt("您好 我是猪猪猪"))
.getResult()
.getOutput();
System.out.println(output.getText());
}
}
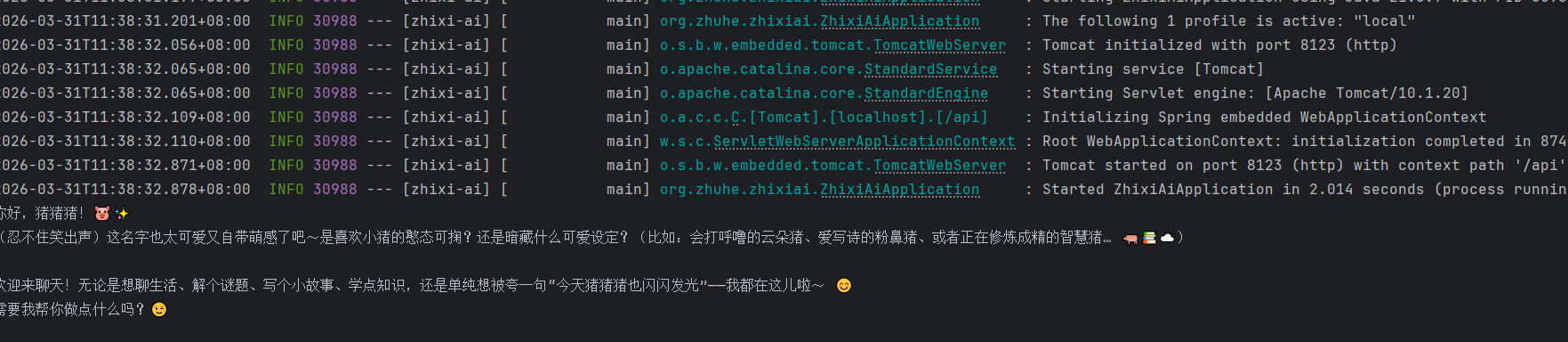
就可以了
springAI比较方便
2.3.4 LangChain4j
和SpringAI差不多
先引入依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.0-beta3</version>
</dependency>package org.zhuhe.zhixiai.demo.invoke;
import dev.langchain4j.model.openai.OpenAiChatModel;
public class LangChain4japi {
public static void main(String[] args) {
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("http://langchain4j.dev/demo/openai/v1")
.apiKey("demo")
.modelName("gpt-4o-mini")
.build();
String answer = model.chat("您好 我是猪猪猪");
System.out.println(answer);
}
}
2.3.5 总结
四种方式,前两种是简单的调用ai,后两者适合复杂情况时使用,看后面吧
3 前置知识
3.1 prompt工程
没啥意思 就是提示词怎么问的好
3.2 ChatClient
chatclient是一个组件,可以理解为一个模块,他的核心是大模型,就可以定制更多内容
注入的话,用构造器注入法或者注解注入
3.3 拓展内容--自定义advisor
就是对prompt进行拦截,处理,多个advisor是责任链的模式
3.4 拓展内容--自定义ChatMemory
这里我实现了一个基于本地文件的ChatMemory,本来想为下面实现一个基于数据库的ChatMemory,结果官方提供了,那我就用它的吧
3.4.1 JdbcChatMemoryRepository
这个看官方文档吧
先引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-autoconfigure-model-chat-memory-repository-jdbc</artifactId>
<version>2.0.0-M4</version>
</dependency>再注入OfficeChatClient,再写一个ChatMemory,很简单
3.5 后端开始编写一些
对于基础的登录或注册按钮,比较好写:
1、引入mybatis、mysql的依赖
2、配置yml文件
3、写controller、service、mapper层
4、写好vo、entity、dto类
5、写好注册和登录
6、登录需要结合jwt令牌写,jwt这里知识挺多,需要写jwt工具类、jwt拦截器、然后注册拦截器、自定义异常、全局异常处理器
下面写基础对话的后端:
基本逻辑如下:
前端发送请求(带jwt的token、chatId、message),后端解析 token → 得到 userId,校验 chatId 是否属于该用户,保存用户消息(先存),直接放入ChatClient(实现了基于数据库的ChatMemory),得到消息返回前端
新增展示窗口:
点进去智能对话,即可展现该用户的对话列表、标题
新增对话窗口的逻辑:
首先,要写一个表,是用户和chatId的关系表。
前端不用传递,后端直接创建好chatid返回给前端保存,用于后续对话
新增删除对话窗口:
传递chatId、从用户和chatId的关系表中删除即可
新增查询聊天记录按钮:
直接从数据库中根据chatid和userid查就行
4、RAG基础
RAG(检索增强生成):不改模型,让模型“临时查资料再回答”
- 用户提问 → 去数据库/向量库检索相关内容 → 把内容拼进 prompt → 再让大模型回答
- 👉 本质:外挂知识库
- 优点:非常适合频繁更新的数据
- 便宜
微调(Fine-tuning):直接改模型,让模型“本身就会这些知识”
4.1 开发基础
4.1.1 知识库(文档)预处理
在这里,我拿ai写了4份文档,作为知识库,注意,写知识库的时候,格式要统一,否则后续预处理不好处理
首先,我们引入读取markdown的依赖
其次,我们写一个markdown文字处理器,用于批量读取、分割、存储我们的markdown文件,并写meta信息
package org.zhuhe.zhixiai.ai.Rag;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.ResourcePatternResolver;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* 应用文档加载器 预处理文件器
*/
@Component
@Slf4j
public class OfficeDocumentLoader {
//找资源的,比如找word类型;ppt类型。。。。而且支持路径匹配
private final ResourcePatternResolver resourcePatternResolver;
public OfficeDocumentLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
/**
* 加载多篇 Markdown 文档
* @return
*/
public List<Document> loadMarkdowns() {
List<Document> allDocuments = new ArrayList<>();
try {
Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");
for (Resource resource : resources) {
String filename = resource.getFilename();
// 提取文档倒数第 3 和第 2 个字作为标签
String status = filename.substring(filename.length() - 8, filename.length() - 4);
//文件配置
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", filename)
.withAdditionalMetadata("status", status)
.build();
//Markdown 文档读取器
MarkdownDocumentReader markdownDocumentReader = new MarkdownDocumentReader(resource, config);
allDocuments.addAll(markdownDocumentReader.get());
}
} catch (IOException e) {
log.error("Markdown 文档加载失败", e);
}
return allDocuments;
}
}4.1.2 写入RAG数据库
我们还要写一个向量数据库的配置类,用于把我们刚刚的文档以向量形式写进向量数据库
SpringAI内置了一个SimpleVectorStore的一个向量数据库,SimpleVectorStore 就是一个类 / 一个轻量级组件,不是像 MySQL、Redis、Milvus、Elasticsearch 那样的独立数据库系统。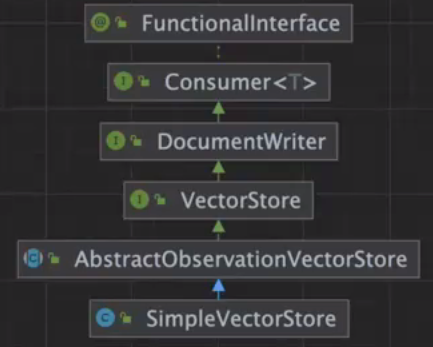
他能写入向量数据库,很重要的接口就是DocumentWriter,就是文档写入器,接收 Document,然后帮你写入向量库的入口
package org.zhuhe.zhixiai.ai.Rag;
import jakarta.annotation.Resource;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
public class OfficeVectorStoreConfig {
@Resource
private OfficeDocumentLoader officeDocumentLoader;
@Bean
VectorStore officeVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel).build();
List<Document> documentList = officeDocumentLoader.loadMarkdowns();
simpleVectorStore.add(documentList);
return simpleVectorStore;//把文档放入数据库后,返回向量数据库,方便之后进行操作
}
}
4.1.3 使用基于内存的RAG数据库进行对话
这里引入了两个Advisor,QuestionAnswerAdvisor or VectorStoreChatMemoryAdvisor
前者是默认的对话Advisor,后者是可以自定义的Advisor
我们先引入依赖
然后正常在ChatClient中定义就行
/**
* 基于rag的问答功能
* @param message
* @param chatId
* @return
*/
public String chatWithRag(String message,String chatId) {
ChatResponse chatResponse = chatClient.prompt()
.user(message)
.advisors(advisor -> advisor.param(ChatMemory.CONVERSATION_ID, chatId))
.advisors(QuestionAnswerAdvisor.builder(officeVectorStore).build())
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
return content;
}4.1.4 使用基于阿里云知识库的RAG增强顾问
首先,我们要配置阿里云百炼大模型平台的设置
然后,在项目中写一个顾问
package org.zhuhe.zhixiai.ai.Rag;
import jakarta.annotation.Resource;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
public class OfficeVectorStoreConfig {
@Resource
private OfficeDocumentLoader officeDocumentLoader;
@Bean
VectorStore officeVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel).build();
List<Document> documentList = officeDocumentLoader.loadMarkdowns();
simpleVectorStore.add(documentList);
return simpleVectorStore;//把文档放入数据库后,返回向量数据库,方便之后进行操作
}
}
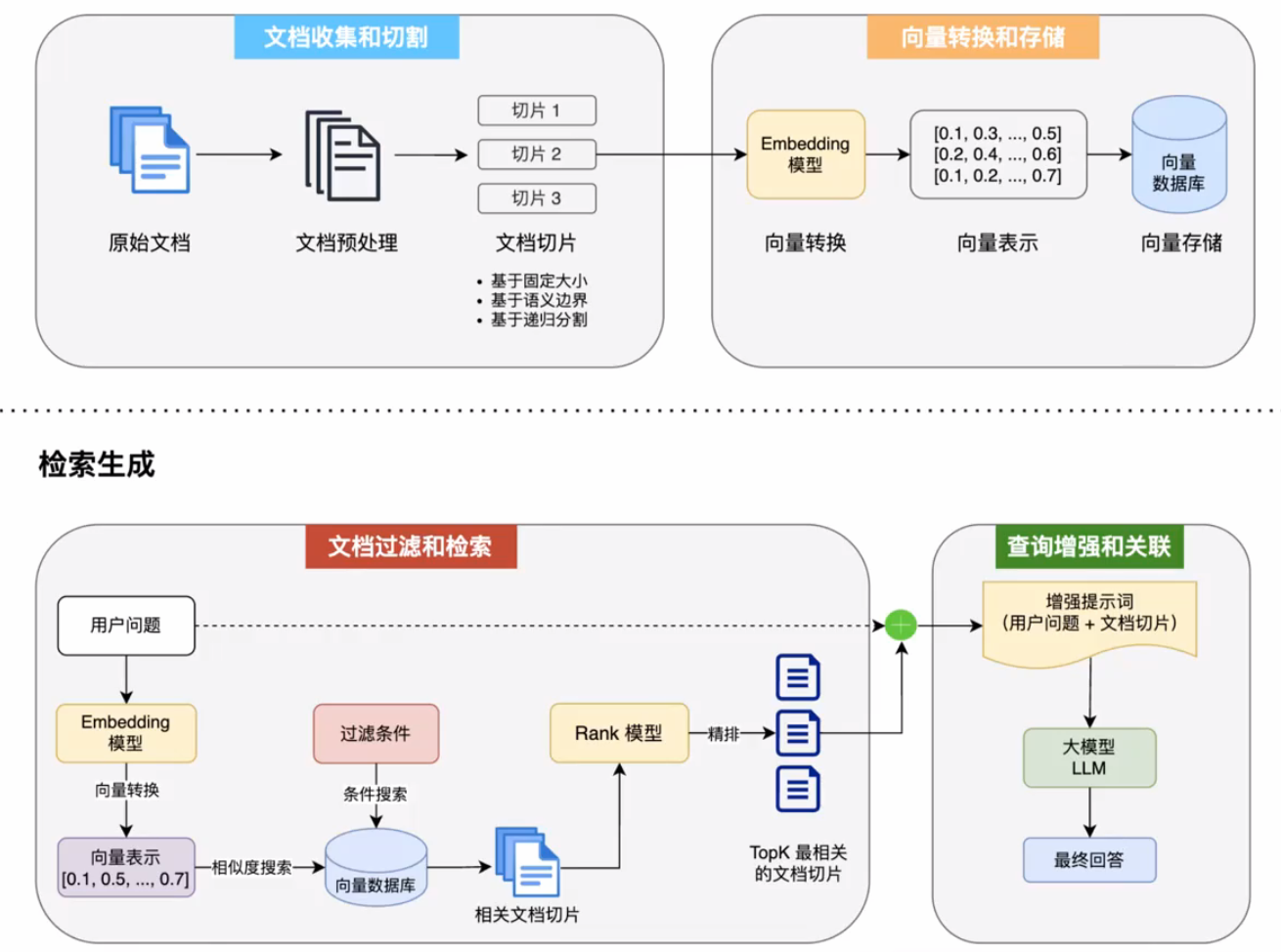
4.2 RAG知识库的核心概念(偏理论)
核心还是这个图
4.2.1 ETL 文档的收集和分割
在springAI中,文档指的是文档对象,这个对象可以存储文字、也可以是音频,同时带有metadata(标签)
E指的就是Extract 抽取
抽取信息,我们是继承了官方的一个DocumentReader接口,实际上,我们在使用的过程中,直接用现在市面上已经提供的依赖就可以,有各种各样的读取器,可以读取各种各样的源文件信息
T指的就是Transform 转换
依然是实现TransformDocument接口,实际上,SpringAI提供了转换器,我们可以对文本进行对文档的拆分、打标签
L指的就是Load 加载
就是把上一步处理好的内容,写入到我们目标存储中,比如向量数据库,这里的接口是用到了DocumentWriter,官方也提供了两个现成的,一个是VectorStoreWriter(文档写入向量数据库),一个是FileDocumentWriter(文档写入文件系统)
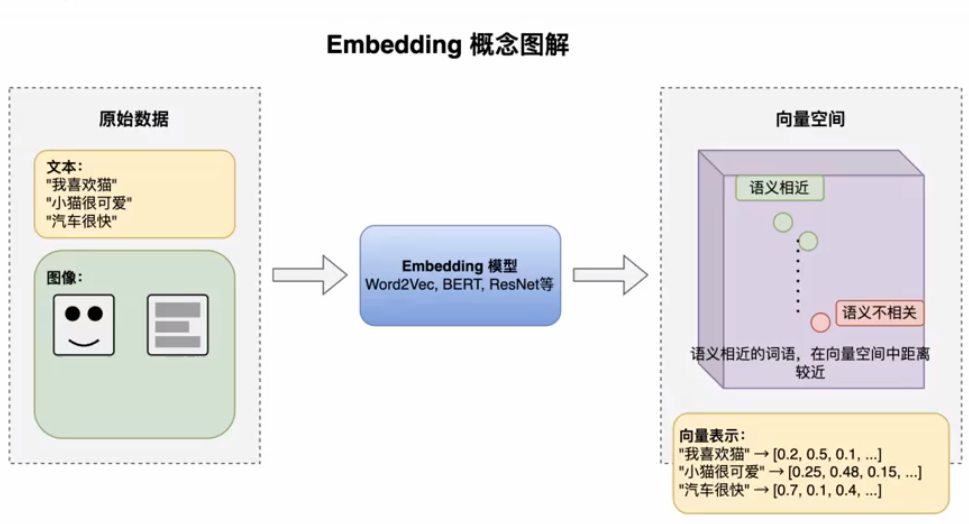
4.2.2 向量的存储与转换
SpringAI提供了向量数据库接口VectorStore,可以开发任意的第三方向量数据库,大概十几种已经提供了。我们在上面使用了simpleVectoreStore,下面来一个功能更强大的
同时,提供了SearchRequest类,用于在数据库中进行相似度查找请求,设置阈值、最相似的几个、过滤表达式
下面,我演示一下PGSQL向量数据库的使用
我们也可以使用云数据库来使用它。在这里,我们开通了阿里云的PGSQL,这也是一个关系数据库,但是更强大,也支持向量存储

然后创建管理员账号

创建数据库

目前,他还不支持向量存储,我们点插件,安装一下就行
然后我们再看文档,springai里面都写得很清楚了
最后,在项目中配置一下数据库连接就可以了
4.3 RAG的最佳实践和调优
依旧是从下面几点进行优化
1、文档收集和切割 2、向量转换和存储 3、文档过滤和检索 4、
4.3.1 文档收集和切割
收集方面,我们要对知识库进行优化:格式化、表达清晰、内容齐全
文档切片方面,切片要合理
元数据标注方面,可以手动添加,也可以DocumentReader实现,也可以用KeywordMetaEnricher增强器,这是用了ai
4.3.2 向量转换和存储
这里就是要选取合适的向量数据库和嵌入模型
4.3.3 文档过滤和检索
多查询扩展:这里用到了MultiQueryExpander类,可以把我们的问题扩充
查询重写:prompt重写
检索器配置:对检索文档设置阈值,topk,还可以根据metadata过滤
4.3.4 查询增强和关联
错误处理机制:如果没检索到文档,我们可以返回不回答的文本
5 工具调用
这个我感觉没什么意思 就是讲我们可以写几个tool类,然后给chatclient
6 智能体Manus
这里我感觉也没多大有意思,写了三个类
第一个类:BaseAgent:控制总流程
接收用户问题
↓
state = RUNNING
↓
把用户问题加入 messageList
↓
最多循环 maxSteps 次
↓
每次调用 step()
↓
结束后 cleanup()第二个类:ReActAgent:规定单步执行模式
ReActAgent 继承 BaseAgent,实现了 step()。
它把每一步拆成:
think()
↓
act()第三个类:ToolCallAgent:真正实现 think 和 act
整体运行链路
用户输入
↓
BaseAgent.run(userPrompt)
↓
加入 UserMessage
↓
循环调用 step()
↓
ReActAgent.step()
↓
think()
↓
大模型判断:要不要调用工具?
↓
如果不要工具:结束本轮
↓
如果要工具:act()
↓
执行工具
↓
把工具结果加入上下文
↓
进入下一轮 step()
↓
直到 FINISHED 或 maxSteps
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)