【AI核心概念讲解】一口气搞懂 LLM 大语言模型:AI 最重要的基石
前言
大语言模型(英语:Large Language Model,简称LLM)
几乎所有人都有和 DeepSeek、Kimi 这类大语言模型(LLM)对话,却很少有人真正想明白:当你敲下一行文字,点击发送,到模型一字一句吐出回复,这中间到底发生了什么?
其实,抛开那些动辄千亿参数的复杂模型不谈,LLM 的本质非常简单:它就是一个永不停歇的 “文字接龙” 大师,通过一次又一次预测 “下一个字是什么”,最终拼出一整段完整的回复。
整个过程可以拆解为一个清晰的循环流水线,我们用一张图先看懂全貌: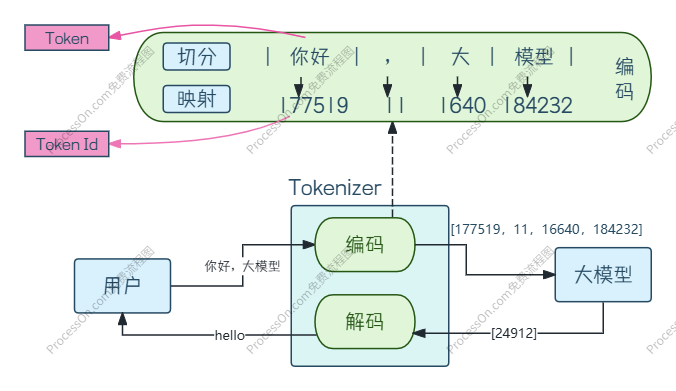
接下来,我们一步步把这个过程拆解开,讲透每一个环节。
第一步:把你的文字,拆成模型能懂的 “积木”——Tokenization
你输入的是一串人类能看懂的字符串,比如:"你好,大模型",但计算机和大模型根本看不懂文字,它们只认识数字。
所以第一步,模型要先把你的文本,拆成一个个最小的、标准化的 “文本积木”,我们称之为Token(词元)。这个过程就叫做分词(Tokenization)。
注:这里我使用到了openai的分词网站:https://platform.openai.com/tokenizer
你可能会问,为什么不直接按字或者按词拆分?
这是因为现代 LLM 普遍采用了子词(Subword)分词算法(比如 BPE),它的好处是:
-
兼顾效率与覆盖:用有限的几万种 Token,就能组合出几乎所有的词语,不管是常用词还是生僻词、甚至是你造的新词。
-
解决未登录词问题:比如你输入一个模型没见过的专业术语,它也能把它拆成几个子词来理解,而不是直接报错。
举个例子:
-
英文单词
unhappiness,可能会被拆成un、h、appiness三个 Token; -
中文句子
你好,大模型,可能会被拆成你好、,、大、模型四个 Token。
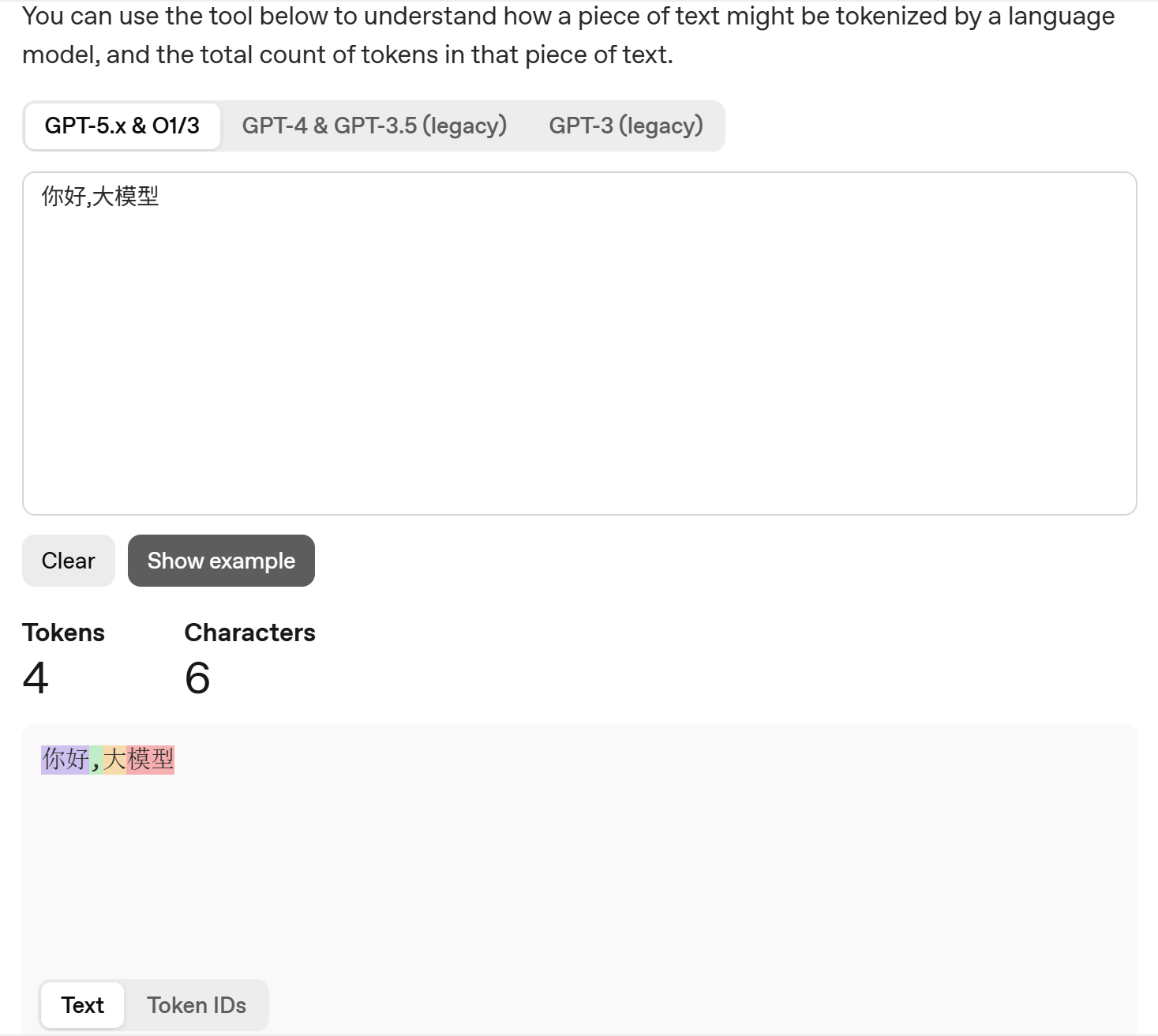
简单来说,Token 就是模型处理文本的最小单位,1 个 Token 大概对应 0.75 个英文单词,或者 1.5 至 2 个左右的中文字符。
第二步:把积木变成数字 ——Token 到 Token ID 的映射
拆完 Token 之后,模型还是不能直接处理这些字符串,它需要把每一个 Token,转换成一个唯一的整数,这个整数就是Token ID。
这个过程其实就是查表:模型自带了一个预训练好的词汇表(Vocabulary),里面记录了每一个 Token 对应的唯一 ID。比如:
你好→ 177519,→ 11大→ 1640模型→ 184232
经过这一步,你输入的整段文字,就从一串字符串,变成了一串纯数字的数组:[177519, 11, 1640, 184232]。
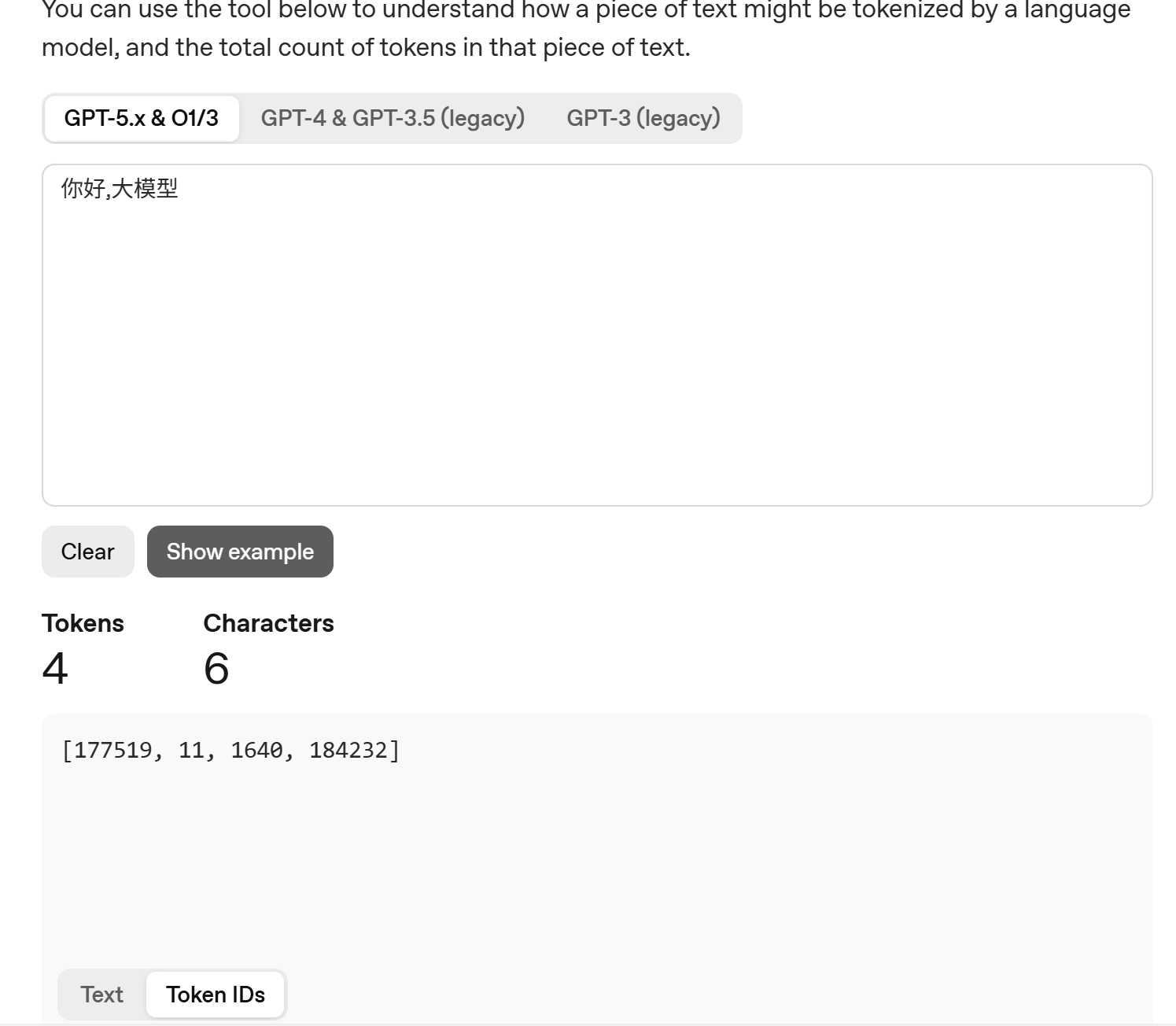
到这里,文本的预处理就完成了,这串数字数组,就是大模型真正的输入。
第三步:大模型的 “思考”—— 编码与上下文理解
现在,这串 Token ID 数组被送入了大模型的核心,开始了模型的Transformer “思考” 过程。
首先,这些 ID 会被转换成向量:
-
词嵌入(Token Embedding):把每个 ID 转换成一个高维的向量,这个向量里藏着这个 Token 的语义信息 —— 比如 “国王” 和 “女王” 的向量会很接近,“猫” 和 “狗” 的向量也会很接近。
-
位置编码(Positional Encoding):因为 Transformer 模型本身是不认识顺序的,为了让模型知道 “你爱我” 和 “我爱你” 是不一样的,我们还要给每个 Token 加上一个位置向量,告诉模型这个 Token 在句子里的位置。
然后,这些带着语义和位置信息的向量,会送入多层的 Transformer 网络,通过自注意力机制(Self-Attention) 来处理整个上下文:
-
模型会通读你输入的所有内容,理解每个词之间的关系,比如当它看到 “它” 的时候,会知道这个代词指代的是前面的 “球” 还是 “机器人”。
-
这个阶段我们称之为预填充(Prefill),模型会一次性处理完你所有的输入,并且把中间计算的 Key、Value 缓存下来(也就是 KV Cache),这样后面循环的时候就不用重复计算了,大大提升了速度。
经过这一步,模型已经完全理解了你输入的内容,接下来就要开始生成回复了。
第四步:预测下一个 Token—— 接龙的第一步
理解了你的问题之后,模型要做的第一件事,就是预测:在我现在的上下文后面,最可能出现的下一个 Token 是什么?
这就是 LLM 最核心的任务:下一个 Token 预测(Next Token Prediction)。
模型会输出一个概率分布:对应词汇表里所有几万种 Token,每个 Token 出现在下一个位置的概率是多少。比如,在你问了 “你好,请问 LLM 到底是什么?” 之后,模型可能会算出:
-
我:35% 的概率 -
这:20% 的概率 -
大:15% 的概率 -
… 其他所有 Token 的概率
然后,模型会根据你设置的采样策略(比如贪心、Top-P、温度系数等),从这个概率分布里选出一个最合理的 Token ID,作为它生成的第一个回复的 ID。
第五步:解码 —— 把数字变回你能看懂的文字
拿到了预测出来的 Token ID 之后,模型要做的就是把它变回你能看懂的文字,这个过程就是解码(Decoding)。
其实就是反过来查词汇表:刚才我们是 Token 查 ID,现在是 ID 查 Token。比如预测出来的 ID 是 56568,那对应的 Token 就是我,这样你就能看到模型输出的第一个字了。
这就是为什么你会看到模型是一个字一个字往外吐的 —— 因为它本来就是一个 Token 一个 Token 生成的。
第六步:自回归循环 —— 这就是 LLM 的本质
到这里,模型只生成了一个字,还没完。
接下来,最关键的一步来了:模型会把刚刚生成的这个新的 Token ID,拼到之前的输入序列的末尾,形成一个新的、更长的输入序列。
然后,重复上面的过程:
-
把新的输入序列送入大模型,处理上下文
-
预测下一个 Token 的概率分布
-
采样得到新的 Token ID
-
解码成文字,输出给你
-
再把新的 ID 拼到输入后面,继续循环…
这个循环,我们称之为自回归生成(Autoregressive Generation),这就是 LLM 的本质!
它就像玩文字接龙:
-
你出了开头:
你好,请问LLM到底是什么? -
模型接了第一个字:
我 -
然后它把
我加到句子后面,变成:你好,请问LLM到底是什么?我,然后接下一个字:是 -
再加进去,变成:
你好,请问LLM到底是什么?我是,再接:一 -
再加进去,再接:
个 -
…
-
就这样一个字一个字接下去,直到它预测到了结束符(比如
<|endoftext|>),或者生成的内容足够长了,这个循环才会停止。
总结
看到这里你应该明白了,不管是和你聊天、写代码、写论文、还是做推理,所有 LLM 能做的事情,本质上都是这个简单的循环:
预测下一个 Token,把它加到输入里,再预测下一个,循环往复。
那些看似复杂的逻辑、推理、创造力,本质上都是模型在海量的文本数据里,学会了人类语言的规律,然后用这个规律,一次一次地接龙,最终拼出了一段段看似智能的文字。
那么这就是 LLM 的本质,循环预测 “下一个字是什么”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 27
27 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)