【大模型应用开发】记忆
【大模型应用开发】记忆
1. 记忆功能的重要性
1.1 人类记忆系统
人类记忆是一个多层级的认知系统,它不仅能存储信息,还能根据重要性、时间和上下文对信息进行分类和整理。认知心理学为理解记忆的结构和过程提供了经典的理论框架,如下图所示。
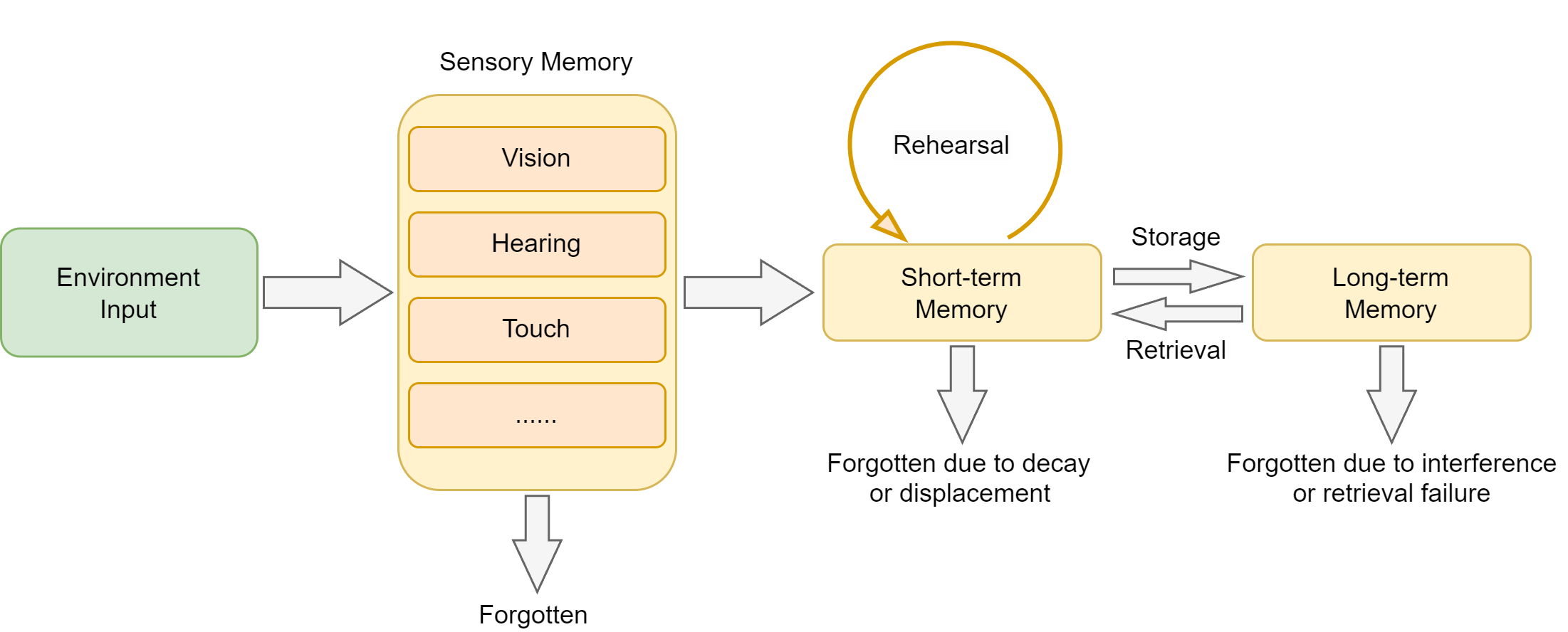
根据认知心理学的研究,人类记忆可以分为以下几个层次:
- 感觉记忆(Sensory Memory):持续时间极短(0.5-3秒),容量巨大,负责暂时保存感官接收到的所有信息
- 工作记忆(Working Memory):持续时间短(15-30秒),容量有限(7±2个项目),负责当前任务的信息处理
- 长期记忆(Long-term Memory):持续时间长(可达终生),容量几乎无限,进一步分为:
- 程序性记忆:技能和习惯(如骑自行车)
- 陈述性记忆:可以用语言表达的知识,又分为:
- 语义记忆:一般知识和概念(如"巴黎是法国首都")
- 情景记忆:个人经历和事件(如"昨天的会议内容")
1.2 为何智能体需要记忆
借鉴人类记忆系统的设计,我们可以理解为什么智能体也需要类似的记忆能力。人类智能的一个重要特征就是能够记住过去的经历,从中学习,并将这些经验应用到新的情况中。同样,一个真正智能的智能体也需要具备记忆能力。对于基于LLM的智能体而言,通常面临局限:对话状态的遗忘。
1.2.1 无状态导致的对话遗忘
当前的大语言模型虽然强大,但设计上是无状态的。这意味着,每一次用户请求(或API调用)都是一次独立的、无关联的计算。模型本身不会自动“记住”上一次对话的内容。这带来了几个问题:
- 上下文丢失:在长对话中,早期的重要信息可能会因为上下文窗口限制而丢失
- 个性化缺失:Agent无法记住用户的偏好、习惯或特定需求
- 学习能力受限:无法从过往的成功或失败经验中学习改进
- 一致性问题:在多轮对话中可能出现前后矛盾的回答
让我们通过一个具体例子来理解这个问题:
from hello_agents import SimpleAgent, HelloAgentsLLM
agent = SimpleAgent(name="学习助手", llm=HelloAgentsLLM())
# 第一次对话
response1 = agent.run("我叫张三,正在学习Python,目前掌握了基础语法")
print(response1) # "很好!Python基础语法是编程的重要基础..."
# 第二次对话(新的会话)
response2 = agent.run("你还记得我的学习进度吗?")
print(response2) # "抱歉,我不知道您的学习进度..."
要解决这个问题,我们的框架需要引入记忆系统。
1.3 记忆与RAG系统架构设计
memory_tool负责存储和维护对话过程中的交互信息。rag_tool则负责从用户提供的知识库中检索相关信息作为上下文,并可将重要的检索结果自动存储到记忆系统中。
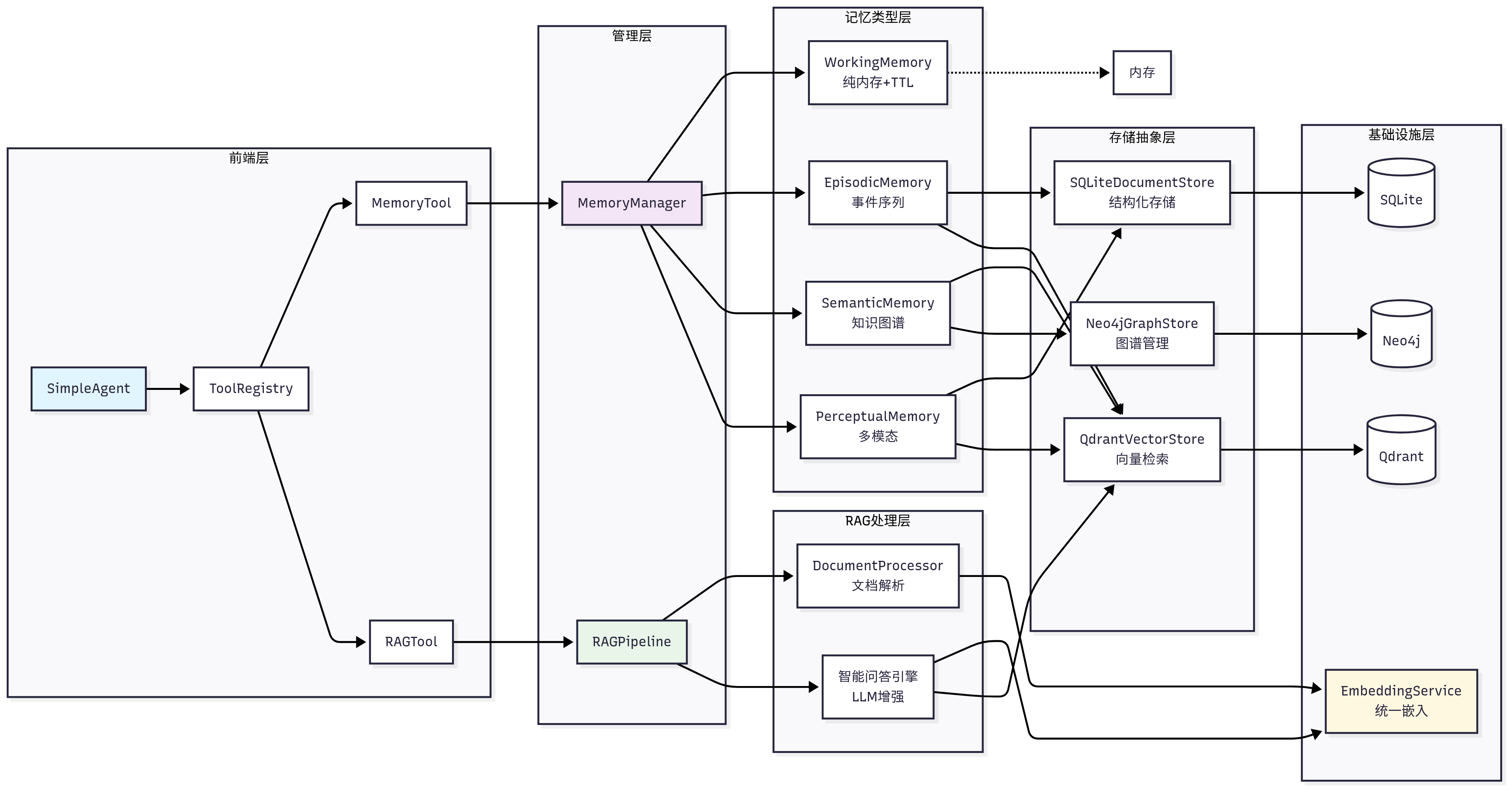
记忆系统采用了四层架构设计:
HelloAgents记忆系统
├── 基础设施层 (Infrastructure Layer)
│ ├── MemoryManager - 记忆管理器(统一调度和协调)
│ ├── MemoryItem - 记忆数据结构(标准化记忆项)
│ ├── MemoryConfig - 配置管理(系统参数设置)
│ └── BaseMemory - 记忆基类(通用接口定义)
├── 记忆类型层 (Memory Types Layer)
│ ├── WorkingMemory - 工作记忆(临时信息,TTL管理)
│ ├── EpisodicMemory - 情景记忆(具体事件,时间序列)
│ ├── SemanticMemory - 语义记忆(抽象知识,图谱关系)
│ └── PerceptualMemory - 感知记忆(多模态数据)
├── 存储后端层 (Storage Backend Layer)
│ ├── QdrantVectorStore - 向量存储(高性能语义检索)
│ ├── Neo4jGraphStore - 图存储(知识图谱管理)
│ └── SQLiteDocumentStore - 文档存储(结构化持久化)
└── 嵌入服务层 (Embedding Service Layer)
├── DashScopeEmbedding - 通义千问嵌入(云端API)
├── LocalTransformerEmbedding - 本地嵌入(离线部署)
└── TFIDFEmbedding - TFIDF嵌入(轻量级兜底)
RAG系统专注于外部知识的获取和利用:
HelloAgents RAG系统
├── 文档处理层 (Document Processing Layer)
│ ├── DocumentProcessor - 文档处理器(多格式解析)
│ ├── Document - 文档对象(元数据管理)
│ └── Pipeline - RAG管道(端到端处理)
├── 嵌入表示层 (Embedding Layer)
│ └── 统一嵌入接口 - 复用记忆系统的嵌入服务
├── 向量存储层 (Vector Storage Layer)
│ └── QdrantVectorStore - 向量数据库(命名空间隔离)
└── 智能问答层 (Intelligent Q&A Layer)
├── 多策略检索 - 向量检索 + MQE + HyDE
├── 上下文构建 - 智能片段合并与截断
└── LLM增强生成 - 基于上下文的准确问答
1.4 记忆类型层
从上图中可以看到记忆类型层分为:WorkingMemory(纯内存+TTL)、EpisodicMemory(事件序列)、SemanticMemory(知识图谱)、PerceptualMemory(多模态)
1.4.1 WorkingMemory 工作记忆(短时记忆 + TTL)
对应人类:当下正在想的事,过会儿就忘
特点:临时、有过期时间、只存在内存里
举例场景
典型用途
- 当前对话上下文
- 临时任务状态
- 多轮对话里的临时信息
- 用完就丢,不存库
1.4.2 EpisodicMemory 情景记忆(经历、故事、对话历史)
对应人类:我记得上次我们聊过什么、发生过什么
特点:按时间线存、长期保存、像日记
举例场景
更多例子
- “你上次说你喜欢吃辣”
- “你上周让我帮你查过北京天气”
- “你昨天让我写一份离职邮件”
凡是 “我记得我们之间发生过什么”,都是情景记忆。
1.4.3 SemanticMemory 语义记忆(知识、事实、关系、图谱)
对应人类:常识、知识点、人物关系、结构化信息
特点:不是故事,是 “事实”,可推理
举例场景

典型用途
- 用户基本信息
- 领域知识(如 “Transformer 是一种注意力模型”)
- 关系推理(A 是 B 的老公 → B 怀孕 → A 要注意育儿)
- 规则、定义、常识
1.4.4 PerceptualMemory 感知记忆(图片、声音、多模态)
对应人类:我记得你长什么样、那首歌的旋律、那张截图内容
特点:非文本、多模态、存向量
举例场景
2. memory包
2.1 base.py
整体代码
"""记忆系统基础类和配置
按照第8章架构设计的基础组件:
- MemoryItem: 记忆项数据结构
- MemoryConfig: 记忆系统配置
- BaseMemory: 记忆基类
"""
from abc import ABC, abstractmethod
from typing import List, Dict, Any
from datetime import datetime
from pydantic import BaseModel
class MemoryItem(BaseModel):
"""记忆项数据结构"""
id: str
content: str
memory_type: str
user_id: str
timestamp: datetime
importance: float = 0.5
metadata: Dict[str, Any] = {}
class Config:
arbitrary_types_allowed = True
class MemoryConfig(BaseModel):
"""记忆系统配置"""
# 存储路径
storage_path: str = "./memory_data"
# 统计显示用的基础配置(仅用于展示)
max_capacity: int = 100
importance_threshold: float = 0.1
decay_factor: float = 0.95
# 工作记忆特定配置
working_memory_capacity: int = 10
working_memory_tokens: int = 2000
working_memory_ttl_minutes: int = 120
# 感知记忆特定配置
perceptual_memory_modalities: List[str] = ["text", "image", "audio", "video"]
class BaseMemory(ABC):
"""记忆基类
定义所有记忆类型的通用接口和行为
"""
def __init__(self, config: MemoryConfig, storage_backend=None):
self.config = config
self.storage = storage_backend
self.memory_type = self.__class__.__name__.lower().replace("memory", "")
@abstractmethod
def add(self, memory_item: MemoryItem) -> str:
"""添加记忆项
Args:
memory_item: 记忆项对象
Returns:
记忆ID
"""
pass
@abstractmethod
def retrieve(self, query: str, limit: int = 5, **kwargs) -> List[MemoryItem]:
"""检索相关记忆
Args:
query: 查询内容
limit: 返回数量限制
**kwargs: 其他检索参数
Returns:
相关记忆列表
"""
pass
@abstractmethod
def update(self, memory_id: str, content: str = None,
importance: float = None, metadata: Dict[str, Any] = None) -> bool:
"""更新记忆
Args:
memory_id: 记忆ID
content: 新内容
importance: 新重要性
metadata: 新元数据
Returns:
是否更新成功
"""
pass
@abstractmethod
def remove(self, memory_id: str) -> bool:
"""删除记忆
Args:
memory_id: 记忆ID
Returns:
是否删除成功
"""
pass
@abstractmethod
def has_memory(self, memory_id: str) -> bool:
"""检查记忆是否存在
Args:
memory_id: 记忆ID
Returns:
是否存在
"""
pass
@abstractmethod
def clear(self):
"""清空所有记忆"""
pass
@abstractmethod
def get_stats(self) -> Dict[str, Any]:
"""获取记忆统计信息
Returns:
统计信息字典
"""
pass
def _generate_id(self) -> str:
"""生成记忆ID"""
import uuid
return str(uuid.uuid4())
def _calculate_importance(self, content: str, base_importance: float = 0.5) -> float:
"""计算记忆重要性
Args:
content: 记忆内容
base_importance: 基础重要性
Returns:
计算后的重要性分数
"""
importance = base_importance
# 基于内容长度
if len(content) > 100:
importance += 0.1
# 基于关键词
important_keywords = ["重要", "关键", "必须", "注意", "警告", "错误"]
if any(keyword in content for keyword in important_keywords):
importance += 0.2
return max(0.0, min(1.0, importance))
def __str__(self) -> str:
stats = self.get_stats()
return f"{self.__class__.__name__}(count={stats.get('count', 0)})"
def __repr__(self) -> str:
return self.__str__()
2.1 核心组件
1. MemoryItem 数据结构
class MemoryItem(BaseModel):
"""记忆项数据结构"""
id: str
content: str
memory_type: str
user_id: str
timestamp: datetime
importance: float = 0.5
metadata: Dict[str, Any] = {}
class Config:
arbitrary_types_allowed = True
功能 :定义记忆项的标准数据结构,包含以下字段:
- id :记忆唯一标识符
- content :记忆内容
- memory_type :记忆类型(如 working、episodic、semantic 等)
- user_id :用户标识符
- timestamp :创建时间
- importance :重要性分数(0-1),默认 0.5
- metadata :元数据字典,用于存储额外信息
技术点 :
- 继承自 Pydantic 的 BaseModel ,提供数据验证和序列化功能
- 设置 arbitrary_types_allowed = True ,允许存储任意类型的元数据
2. MemoryConfig 配置类
class MemoryConfig(BaseModel):
"""记忆系统配置"""
# 存储路径
storage_path: str = "./memory_data"
# 统计显示用的基础配置(仅用于展示)
max_capacity: int = 100
importance_threshold: float = 0.1
decay_factor: float = 0.95
# 工作记忆特定配置
working_memory_capacity: int = 10
working_memory_tokens: int = 2000
working_memory_ttl_minutes: int = 120
# 感知记忆特定配置
perceptual_memory_modalities: List[str] = ["text", "image", "audio", "video"]
功能 :定义记忆系统的配置参数,包含:
- 存储配置:存储路径
- 基础配置:容量限制、重要性阈值、衰减因子
- 工作记忆配置:容量、token 限制、过期时间
- 感知记忆配置:支持的模态类型
技术点 :
- 使用 Pydantic 模型管理配置,提供默认值
- 模块化配置设计,便于不同记忆类型使用不同配置
3. BaseMemory 抽象基类
功能 :定义所有记忆类型的通用接口和行为,是一个抽象基类。
class BaseMemory(ABC):
"""记忆基类
定义所有记忆类型的通用接口和行为
"""
def __init__(self, config: MemoryConfig, storage_backend=None):
self.config = config
self.storage = storage_backend
self.memory_type = self.__class__.__name__.lower().replace("memory", "")
@abstractmethod
def add(self, memory_item: MemoryItem) -> str:
"""添加记忆项
Args:
memory_item: 记忆项对象
Returns:
记忆ID
"""
pass
@abstractmethod
def retrieve(self, query: str, limit: int = 5, **kwargs) -> List[MemoryItem]:
"""检索相关记忆
Args:
query: 查询内容
limit: 返回数量限制
**kwargs: 其他检索参数
Returns:
相关记忆列表
"""
pass
@abstractmethod
def update(self, memory_id: str, content: str = None,
importance: float = None, metadata: Dict[str, Any] = None) -> bool:
"""更新记忆
Args:
memory_id: 记忆ID
content: 新内容
importance: 新重要性
metadata: 新元数据
Returns:
是否更新成功
"""
pass
@abstractmethod
def remove(self, memory_id: str) -> bool:
"""删除记忆
Args:
memory_id: 记忆ID
Returns:
是否删除成功
"""
pass
@abstractmethod
def has_memory(self, memory_id: str) -> bool:
"""检查记忆是否存在
Args:
memory_id: 记忆ID
Returns:
是否存在
"""
pass
@abstractmethod
def clear(self):
"""清空所有记忆"""
pass
@abstractmethod
def get_stats(self) -> Dict[str, Any]:
"""获取记忆统计信息
Returns:
统计信息字典
"""
pass
def _generate_id(self) -> str:
"""生成记忆ID"""
import uuid
return str(uuid.uuid4())
def _calculate_importance(self, content: str, base_importance: float = 0.5) -> float:
"""计算记忆重要性
Args:
content: 记忆内容
base_importance: 基础重要性
Returns:
计算后的重要性分数
"""
importance = base_importance
# 基于内容长度
if len(content) > 100:
importance += 0.1
# 基于关键词
important_keywords = ["重要", "关键", "必须", "注意", "警告", "错误"]
if any(keyword in content for keyword in important_keywords):
importance += 0.2
return max(0.0, min(1.0, importance))
def __str__(self) -> str:
stats = self.get_stats()
return f"{self.__class__.__name__}(count={stats.get('count', 0)})"
def __repr__(self) -> str:
return self.__str__()
核心方法 :
-
抽象方法 (子类必须实现):
- add() :添加记忆项
- retrieve() :检索相关记忆
- update() :更新记忆
- remove() :删除记忆
- has_memory() :检查记忆是否存在
- clear() :清空所有记忆
- get_stats() :获取记忆统计信息
-
具体方法 (基类实现):
- _generate_id() :生成唯一记忆ID
- _calculate_importance() :计算记忆重要性
__str__():字符串表示__repr__():官方字符串表示
3.记忆类型层模块 types包
3.1 整体介绍
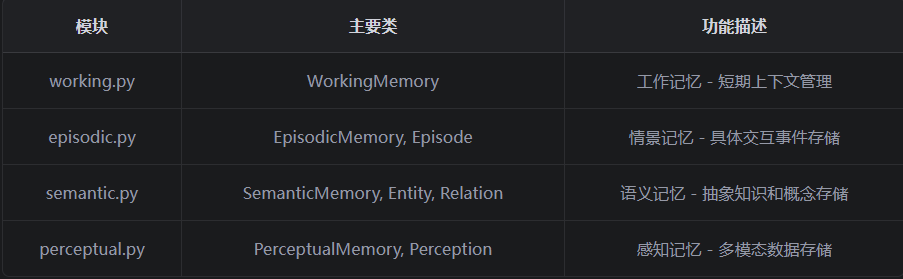
核心功能分析
# HelloAgents Memory Types 思维导图
## types package
├── 1. Working Memory(工作记忆)
│ ├── 特点
│ │ ├── 短期上下文管理
│ │ ├── 容量有限(10-20条记忆)
│ │ ├── 时效性强(会话级别)
│ │ ├── 优先级管理
│ │ └── 自动清理机制
│ ├── 核心功能
│ │ ├── add() - 添加工作记忆
│ │ ├── retrieve() - 混合语义向量检索和关键词匹配
│ │ ├── update() - 更新工作记忆
│ │ ├── remove() - 删除工作记忆
│ │ ├── forget() - 工作记忆遗忘机制
│ │ └── get_context_summary() - 获取上下文摘要
│ └── 技术实现
│ ├── 内存存储(不需要持久化)
│ ├── 优先级队列管理记忆
│ ├── 时间衰减和容量限制机制
│ └── 支持TF-IDF向量检索
├── 2. Episodic Memory(情景记忆)
│ ├── 特点
│ │ ├── 存储具体的交互事件
│ │ ├── 包含丰富的上下文信息
│ │ ├── 按时间序列组织
│ │ └── 支持模式识别和回溯
│ ├── 核心功能
│ │ ├── add() - 添加情景记忆
│ │ ├── retrieve() - 结构化过滤 + 语义向量检索
│ │ ├── update() - 更新情景记忆
│ │ ├── remove() - 删除情景记忆
│ │ ├── forget() - 情景记忆遗忘机制
│ │ ├── find_patterns() - 发现用户行为模式
│ │ └── get_timeline() - 获取时间线视图
│ └── 技术实现
│ ├── SQLite作为权威文档存储
│ ├── Qdrant作为向量存储
│ ├── 支持会话管理
│ └── 时间线视图
├── 3. Semantic Memory(语义记忆)
│ ├── 特点
│ │ ├── 使用HuggingFace中文预训练模型进行文本嵌入
│ │ ├── 向量检索进行快速相似度匹配
│ │ ├── 知识图谱存储实体和关系
│ │ └── 混合检索策略:向量+图+语义推理
│ ├── 核心功能
│ │ ├── add() - 添加语义记忆,提取实体和关系
│ │ ├── retrieve() - 混合向量和图检索
│ │ ├── update() - 更新语义记忆
│ │ ├── remove() - 删除语义记忆
│ │ ├── forget() - 语义记忆遗忘机制
│ │ ├── search_entities() - 搜索实体
│ │ ├── get_related_entities() - 获取相关实体
│ │ └── export_knowledge_graph() - 导出知识图谱
│ └── 技术实现
│ ├── Qdrant作为向量数据库
│ ├── Neo4j作为图数据库
│ ├── 集成spaCy进行实体识别
│ └── 支持多语言处理
└── 4. Perceptual Memory(感知记忆)
├── 特点
│ ├── 支持多模态数据(文本、图像、音频等)
│ ├── 跨模态相似性搜索
│ ├── 感知数据的语义理解
│ └── 支持内容生成和检索
├── 核心功能
│ ├── add() - 添加感知记忆,编码多模态数据
│ ├── retrieve() - 同模态向量检索+时间/重要性融合
│ ├── update() - 更新感知记忆
│ ├── remove() - 删除感知记忆
│ ├── forget() - 感知记忆遗忘机制
│ ├── cross_modal_search() - 跨模态搜索
│ ├── get_by_modality() - 按模态获取记忆
│ └── generate_content() - 基于感知记忆生成内容
└── 技术实现
├── SQLite作为权威文档存储
├── Qdrant按模态拆分存储
├── 支持CLIP/CLAP模型(可选)
└── 轻量级哈希编码作为降级方案
## 共同特性
- 统一接口:所有记忆类型都继承自BaseMemory
- 遗忘机制:每种记忆类型都实现了forget()方法
- 统计信息:每种记忆类型都提供了get_stats()方法
- 多用户支持:所有记忆操作都支持用户ID过滤
- 重要性管理:记忆项都有importance属性
- 向量检索:除工作记忆外,其他记忆类型都支持向量检索
## 技术亮点
- 混合检索策略:语义记忆结合了向量检索和图检索
- 多模态支持:感知记忆支持多种模态
- 知识图谱:语义记忆使用Neo4j构建知识图谱
- 轻量级降级方案:当高级模型不可用时,提供轻量级替代方案
- 统一嵌入模型:使用统一的文本嵌入模型
- 连接管理:使用连接管理器避免重复连接数据库
3.2 存储方案
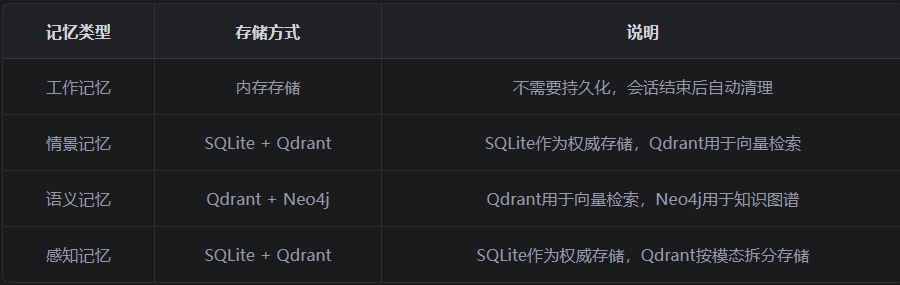
3.2 __init__.py
"""记忆类型层模块
按照第8章架构设计的记忆类型层:
- WorkingMemory: 工作记忆 - 短期上下文管理
- EpisodicMemory: 情景记忆 - 具体交互事件存储
- SemanticMemory: 语义记忆 - 抽象知识和概念存储
- PerceptualMemory: 感知记忆 - 多模态数据存储
"""
from .working import WorkingMemory
from .episodic import EpisodicMemory, Episode
from .semantic import SemanticMemory, Entity, Relation
from .perceptual import PerceptualMemory, Perception
__all__ = [
# 记忆类型
"WorkingMemory",
"EpisodicMemory",
"SemanticMemory",
"PerceptualMemory",
# 辅助类
"Episode",
"Entity",
"Relation",
"Perception"
]
3.3 working.py 工作记忆实现
代码:
"""工作记忆实现
按照第8章架构设计的工作记忆,提供:
- 短期上下文管理
- 容量和时间限制
- 优先级管理
- 自动清理机制
"""
from typing import List, Dict, Any
from datetime import datetime, timedelta
import heapq
from ..base import BaseMemory, MemoryItem, MemoryConfig
class WorkingMemory(BaseMemory):
"""工作记忆实现
特点:
- 容量有限(通常10-20条记忆)
- 时效性强(会话级别)
- 优先级管理
- 自动清理过期记忆
"""
def __init__(self, config: MemoryConfig, storage_backend=None):
super().__init__(config, storage_backend)
# 工作记忆特定配置
self.max_capacity = self.config.working_memory_capacity
self.max_tokens = self.config.working_memory_tokens
# 纯内存TTL(分钟),可通过在 MemoryConfig 上挂载 working_memory_ttl_minutes 覆盖
self.max_age_minutes = getattr(self.config, 'working_memory_ttl_minutes', 120)
self.current_tokens = 0
self.session_start = datetime.now()
# 内存存储(工作记忆不需要持久化)
self.memories: List[MemoryItem] = []
# 使用优先级队列管理记忆
self.memory_heap = [] # (priority, timestamp, memory_item)
def add(self, memory_item: MemoryItem) -> str:
"""添加工作记忆"""
# 过期清理
self._expire_old_memories()
# 计算优先级(重要性 + 时间衰减)
priority = self._calculate_priority(memory_item)
# 添加到堆中
heapq.heappush(self.memory_heap, (-priority, memory_item.timestamp, memory_item))
self.memories.append(memory_item)
# 更新token计数
self.current_tokens += len(memory_item.content.split())
# 检查容量限制
self._enforce_capacity_limits()
return memory_item.id
def retrieve(self, query: str, limit: int = 5, user_id: str = None, **kwargs) -> List[MemoryItem]:
"""检索工作记忆 - 混合语义向量检索和关键词匹配"""
# 过期清理
self._expire_old_memories()
if not self.memories:
return []
# 过滤已遗忘的记忆
active_memories = [m for m in self.memories if not m.metadata.get("forgotten", False)]
# 按用户ID过滤(如果提供)
filtered_memories = active_memories
if user_id:
filtered_memories = [m for m in active_memories if m.user_id == user_id]
if not filtered_memories:
return []
# 尝试语义向量检索(如果有嵌入模型)
vector_scores = {}
try:
# 简单的语义相似度计算(使用TF-IDF或其他轻量级方法)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 准备文档
documents = [query] + [m.content for m in filtered_memories]
# TF-IDF向量化
vectorizer = TfidfVectorizer(stop_words=None, lowercase=True)
tfidf_matrix = vectorizer.fit_transform(documents)
# 计算相似度
query_vector = tfidf_matrix[0:1]
doc_vectors = tfidf_matrix[1:]
similarities = cosine_similarity(query_vector, doc_vectors).flatten()
# 存储向量分数
for i, memory in enumerate(filtered_memories):
vector_scores[memory.id] = similarities[i]
except Exception as e:
# 如果向量检索失败,回退到关键词匹配
vector_scores = {}
# 计算最终分数
query_lower = query.lower()
scored_memories = []
for memory in filtered_memories:
content_lower = memory.content.lower()
# 获取向量分数(如果有)
vector_score = vector_scores.get(memory.id, 0.0)
# 关键词匹配分数
keyword_score = 0.0
if query_lower in content_lower:
keyword_score = len(query_lower) / len(content_lower)
else:
# 分词匹配
query_words = set(query_lower.split())
content_words = set(content_lower.split())
intersection = query_words.intersection(content_words)
if intersection:
keyword_score = len(intersection) / len(query_words.union(content_words)) * 0.8
# 混合分数:向量检索 + 关键词匹配
if vector_score > 0:
base_relevance = vector_score * 0.7 + keyword_score * 0.3
else:
base_relevance = keyword_score
# 时间衰减
time_decay = self._calculate_time_decay(memory.timestamp)
base_relevance *= time_decay
# 重要性权重
importance_weight = 0.8 + (memory.importance * 0.4)
final_score = base_relevance * importance_weight
if final_score > 0:
scored_memories.append((final_score, memory))
# 按分数排序并返回
scored_memories.sort(key=lambda x: x[0], reverse=True)
return [memory for _, memory in scored_memories[:limit]]
def update(
self,
memory_id: str,
content: str = None,
importance: float = None,
metadata: Dict[str, Any] = None
) -> bool:
"""更新工作记忆"""
for memory in self.memories:
if memory.id == memory_id:
old_tokens = len(memory.content.split())
if content is not None:
memory.content = content
# 更新token计数
new_tokens = len(content.split())
self.current_tokens = self.current_tokens - old_tokens + new_tokens
if importance is not None:
memory.importance = importance
if metadata is not None:
memory.metadata.update(metadata)
# 重新计算优先级并更新堆
self._update_heap_priority(memory)
return True
return False
def remove(self, memory_id: str) -> bool:
"""删除工作记忆"""
for i, memory in enumerate(self.memories):
if memory.id == memory_id:
# 从列表中删除
removed_memory = self.memories.pop(i)
# 从堆中删除(标记删除)
self._mark_deleted_in_heap(memory_id)
# 更新token计数
self.current_tokens -= len(removed_memory.content.split())
self.current_tokens = max(0, self.current_tokens)
return True
return False
def has_memory(self, memory_id: str) -> bool:
"""检查记忆是否存在"""
return any(memory.id == memory_id for memory in self.memories)
def clear(self):
"""清空所有工作记忆"""
self.memories.clear()
self.memory_heap.clear()
self.current_tokens = 0
def get_stats(self) -> Dict[str, Any]:
"""获取工作记忆统计信息"""
# 过期清理(惰性)
self._expire_old_memories()
# 工作记忆中的记忆都是活跃的(已遗忘的记忆会被直接删除)
active_memories = self.memories
return {
"count": len(active_memories), # 活跃记忆数量
"forgotten_count": 0, # 工作记忆中已遗忘的记忆会被直接删除
"total_count": len(self.memories), # 总记忆数量
"current_tokens": self.current_tokens,
"max_capacity": self.max_capacity,
"max_tokens": self.max_tokens,
"max_age_minutes": self.max_age_minutes,
"session_duration_minutes": (datetime.now() - self.session_start).total_seconds() / 60,
"avg_importance": sum(m.importance for m in active_memories) / len(active_memories) if active_memories else 0.0,
"capacity_usage": len(active_memories) / self.max_capacity if self.max_capacity > 0 else 0.0,
"token_usage": self.current_tokens / self.max_tokens if self.max_tokens > 0 else 0.0,
"memory_type": "working"
}
def get_recent(self, limit: int = 10) -> List[MemoryItem]:
"""获取最近的记忆"""
sorted_memories = sorted(
self.memories,
key=lambda x: x.timestamp,
reverse=True
)
return sorted_memories[:limit]
def get_important(self, limit: int = 10) -> List[MemoryItem]:
"""获取重要记忆"""
sorted_memories = sorted(
self.memories,
key=lambda x: x.importance,
reverse=True
)
return sorted_memories[:limit]
def get_all(self) -> List[MemoryItem]:
"""获取所有记忆"""
return self.memories.copy()
def get_context_summary(self, max_length: int = 500) -> str:
"""获取上下文摘要"""
if not self.memories:
return "No working memories available."
# 按重要性和时间排序
sorted_memories = sorted(
self.memories,
key=lambda m: (m.importance, m.timestamp),
reverse=True
)
summary_parts = []
current_length = 0
for memory in sorted_memories:
content = memory.content
if current_length + len(content) <= max_length:
summary_parts.append(content)
current_length += len(content)
else:
# 截断最后一个记忆
remaining = max_length - current_length
if remaining > 50: # 至少保留50个字符
summary_parts.append(content[:remaining] + "...")
break
return "Working Memory Context:\n" + "\n".join(summary_parts)
def forget(self, strategy: str = "importance_based", threshold: float = 0.1, max_age_days: int = 1) -> int:
"""工作记忆遗忘机制"""
forgotten_count = 0
current_time = datetime.now()
to_remove = []
# 始终先执行TTL过期(分钟级)
cutoff_ttl = current_time - timedelta(minutes=self.max_age_minutes)
for memory in self.memories:
if memory.timestamp < cutoff_ttl:
to_remove.append(memory.id)
if strategy == "importance_based":
# 删除低重要性记忆
for memory in self.memories:
if memory.importance < threshold:
to_remove.append(memory.id)
elif strategy == "time_based":
# 删除过期记忆(工作记忆通常以小时计算)
cutoff_time = current_time - timedelta(hours=max_age_days * 24)
for memory in self.memories:
if memory.timestamp < cutoff_time:
to_remove.append(memory.id)
elif strategy == "capacity_based":
# 删除超出容量的记忆
if len(self.memories) > self.max_capacity:
# 按优先级排序,删除最低的
sorted_memories = sorted(
self.memories,
key=lambda m: self._calculate_priority(m)
)
excess_count = len(self.memories) - self.max_capacity
for memory in sorted_memories[:excess_count]:
to_remove.append(memory.id)
# 执行删除
for memory_id in to_remove:
if self.remove(memory_id):
forgotten_count += 1
return forgotten_count
def _calculate_priority(self, memory: MemoryItem) -> float:
"""计算记忆优先级"""
# 基础优先级 = 重要性
priority = memory.importance
# 时间衰减
time_decay = self._calculate_time_decay(memory.timestamp)
priority *= time_decay
return priority
def _calculate_time_decay(self, timestamp: datetime) -> float:
"""计算时间衰减因子"""
time_diff = datetime.now() - timestamp
hours_passed = time_diff.total_seconds() / 3600
# 指数衰减(工作记忆衰减更快)
decay_factor = self.config.decay_factor ** (hours_passed / 6) # 每6小时衰减
return max(0.1, decay_factor) # 最小保持10%的权重
def _enforce_capacity_limits(self):
"""强制执行容量限制"""
# 检查记忆数量限制
while len(self.memories) > self.max_capacity:
self._remove_lowest_priority_memory()
# 检查token限制
while self.current_tokens > self.max_tokens:
self._remove_lowest_priority_memory()
def _expire_old_memories(self):
"""按TTL清理过期记忆,并同步更新堆与token计数"""
if not self.memories:
return
cutoff_time = datetime.now() - timedelta(minutes=self.max_age_minutes)
# 过滤保留的记忆
kept: List[MemoryItem] = []
removed_token_sum = 0
for m in self.memories:
if m.timestamp >= cutoff_time:
kept.append(m)
else:
removed_token_sum += len(m.content.split())
if len(kept) == len(self.memories):
return
# 覆盖列表与token
self.memories = kept
self.current_tokens = max(0, self.current_tokens - removed_token_sum)
# 重建堆
self.memory_heap = []
for mem in self.memories:
priority = self._calculate_priority(mem)
heapq.heappush(self.memory_heap, (-priority, mem.timestamp, mem))
def _remove_lowest_priority_memory(self):
"""删除优先级最低的记忆"""
if not self.memories:
return
# 找到优先级最低的记忆
lowest_priority = float('inf')
lowest_memory = None
for memory in self.memories:
priority = self._calculate_priority(memory)
if priority < lowest_priority:
lowest_priority = priority
lowest_memory = memory
if lowest_memory:
self.remove(lowest_memory.id)
def _update_heap_priority(self, memory: MemoryItem):
"""更新堆中记忆的优先级"""
# 简单实现:重建堆
self.memory_heap = []
for mem in self.memories:
priority = self._calculate_priority(mem)
heapq.heappush(self.memory_heap, (-priority, mem.timestamp, mem))
def _mark_deleted_in_heap(self, memory_id: str):
"""在堆中标记删除的记忆"""
# 由于heapq不支持直接删除,我们标记为已删除
# 在后续操作中会被清理
pass
4. Python如何实现多参数构造函数
- 一个类可以没有
__init__,照样能正常用。
只要你的类 不需要在创建对象时传参数、不需要初始化变量 ,就可以不写。
class Tool:
def say_hi(self):
print("你好")
# 照样能创建对象
t = Tool()
t.say_hi()
- 什么时候必须写 init?
在创建对象时,自动做一些初始化工作。
比如:
- 传入参数
- 给对象绑定属性(name、age、model_path 等)
- 初始化配置、session、数据库连接
- 如果你不写
__init__,Python 会自动给你一个默认的空 init,类似这样:
def __init__(self):
pass
- 想实现 “不同参数类型的构造” 怎么办?
这叫 多构造器模式。
class Person:
def __init__(self, name="", age=0):
self.name = name
self.age = age
# 方式1:从名字创建
@classmethod
def from_name(cls, name):
return cls(name=name)
# 方式2:从身份证信息创建
@classmethod
def from_id(cls, id_card):
name = id_card["name"]
age = id_card["age"]
return cls(name, age)
# 使用
p1 = Person.from_name("张三")
p2 = Person.from_id({"name":"李四","age":30})
5. package下的__init__.py
__init__.py是Python包(package)中一个特殊的文件,它主要有以下作用:
- 标记文件夹为 Python 包
只要目录里有__init__.py
my_package/
__init__.py
a.py
b.py
你就能:
import my_package
from my_package import a
- 统一暴露接口(最常用!)
在__init__.py里写:
from .a import ClassA
from .b import ClassB
外面就能直接从包导入,不用进子文件
from my_package import ClassA, ClassB
否则你必须写:
from my_package.a import ClassA
- 工程级写法
"""HelloAgents记忆系统模块
按照第8章架构设计的分层记忆系统:
- Memory Core Layer: 记忆核心层
- Memory Types Layer: 记忆类型层
- Storage Layer: 存储层
- Integration Layer: 集成层
"""
# Memory Core Layer (记忆核心层)
from .manager import MemoryManager
# Memory Types Layer (记忆类型层)
from .types.working import WorkingMemory
from .types.episodic import EpisodicMemory
from .types.semantic import SemanticMemory
from .types.perceptual import PerceptualMemory
# Storage Layer (存储层)
from .storage.document_store import DocumentStore, SQLiteDocumentStore
# Base classes and utilities
from .base import MemoryItem, MemoryConfig, BaseMemory
__all__ = [
# Core Layer
"MemoryManager",
# Memory Types
"WorkingMemory",
"EpisodicMemory",
"SemanticMemory",
"PerceptualMemory",
# Storage Layer
"DocumentStore",
"SQLiteDocumentStore",
# Base
"MemoryItem",
"MemoryConfig",
"BaseMemory"
]
附录
1.参考 hello-agents https://hello-agents.datawhale.cc/#/./chapter8/第八章 记忆与检索

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)