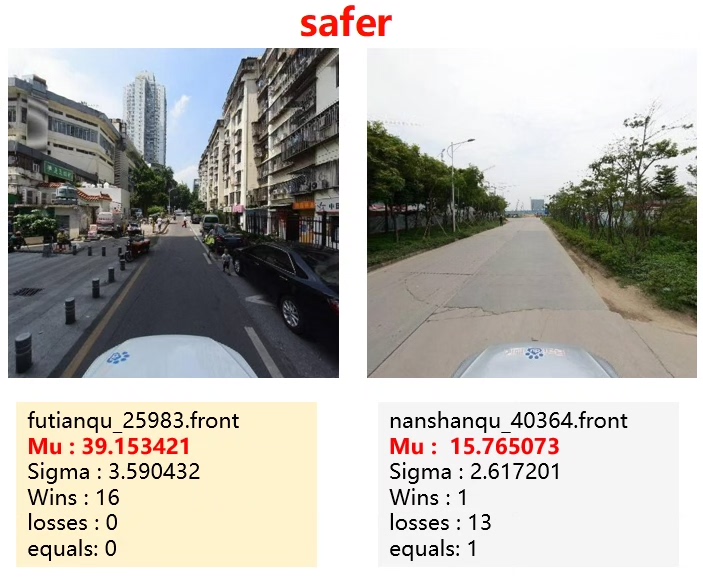
街景主观感知模型训练与大规模预测实践分享
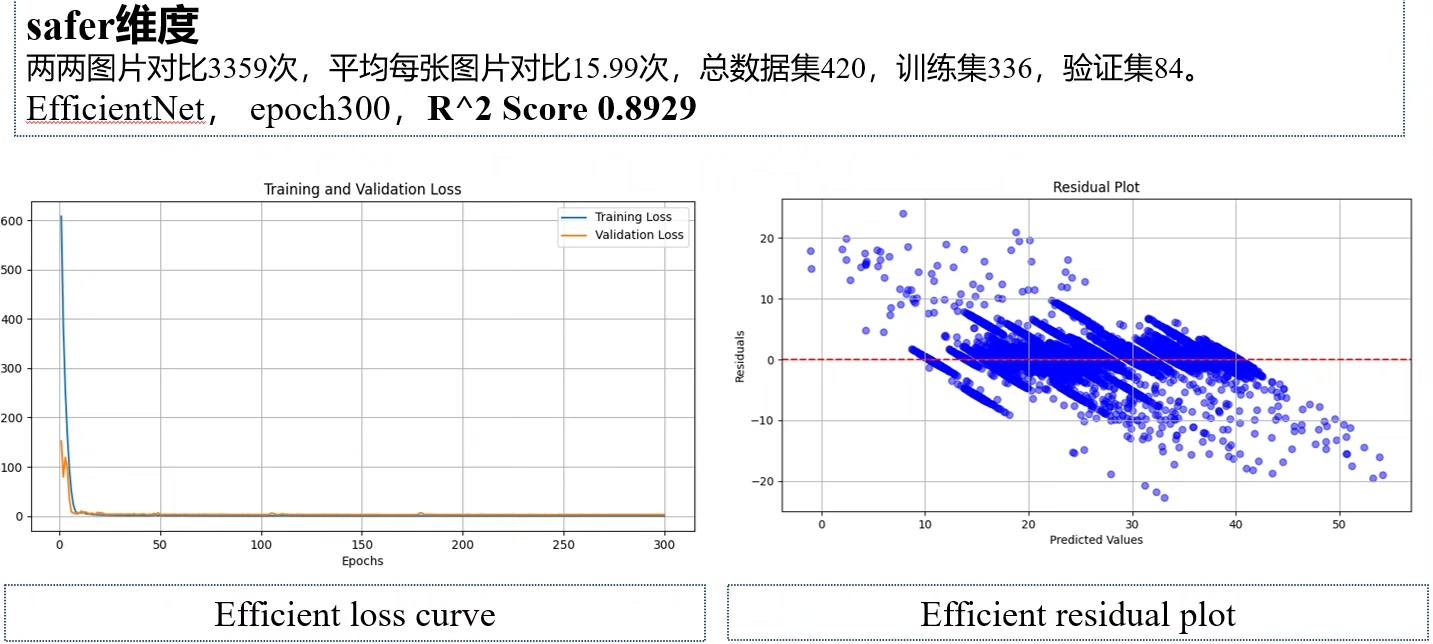
街景主观感知模型训练大规模预测 place pluse数据集 自定义数据集 模型训练预测 街景主观感知程序(beautiful, safer等自定义维度),多模型对比(ResNet50,ResNet101,EfficientNet、VGGNet、GoogleNet、DenseNet、MobileNet、ShuffleNet、Xception、ConvNeXt、Vision Transformer (ViT)、RegNet等),我自己是用420张图片,分别训练了beautiful,safer,模型最好精度0.89,很高了,我才用了420张图片,平均每张图片对比才16次
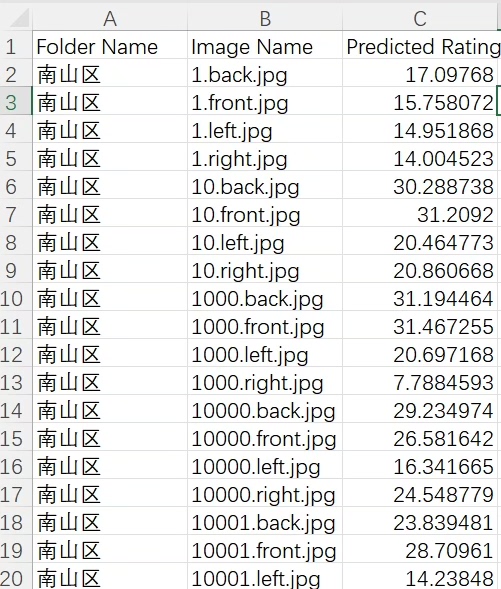
在街景分析领域,主观感知模型的训练与预测一直是个有趣且富有挑战的课题。最近我在这方面做了一些尝试,今天就来跟大家分享一下过程和收获。
数据集的选择与构建
我使用了place plus数据集作为基础,同时还构建了自定义数据集。自定义数据集对于贴合特定任务需求十分关键。比如在这次针对街景主观感知程序中,像 “beautiful” 和 “safer” 这样自定义维度的分析,标准往往很主观,现成数据集不一定能满足,自定义数据集就能精准地收集我们需要的数据。
模型训练与预测
训练模型的过程是整个项目的核心。我尝试了多种模型进行对比,包括ResNet50、ResNet101、EfficientNet、VGGNet、GoogleNet、DenseNet、MobileNet、ShuffleNet、Xception、ConvNeXt、Vision Transformer (ViT)、RegNet等等。这里以使用PyTorch框架搭建ResNet50模型为例,简单看看代码结构:
import torch
import torch.nn as nn
import torchvision.models as models
# 加载预训练的ResNet50模型
model = models.resnet50(pretrained=True)
# 修改全连接层以适应自定义任务(假设类别数为2,对应beautiful和safer两种判断)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 2)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 训练循环示例
for epoch in range(10): # 假设训练10个epoch
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}')这段代码首先加载了预训练的ResNet50模型,这能利用在大规模数据集上已经学习到的特征表示,加快模型收敛。然后根据自定义任务修改了全连接层,因为我们的任务只有 “beautiful” 和 “safer” 两个类别。接着定义了损失函数和优化器,在训练循环中,不断计算损失并反向传播更新模型参数。
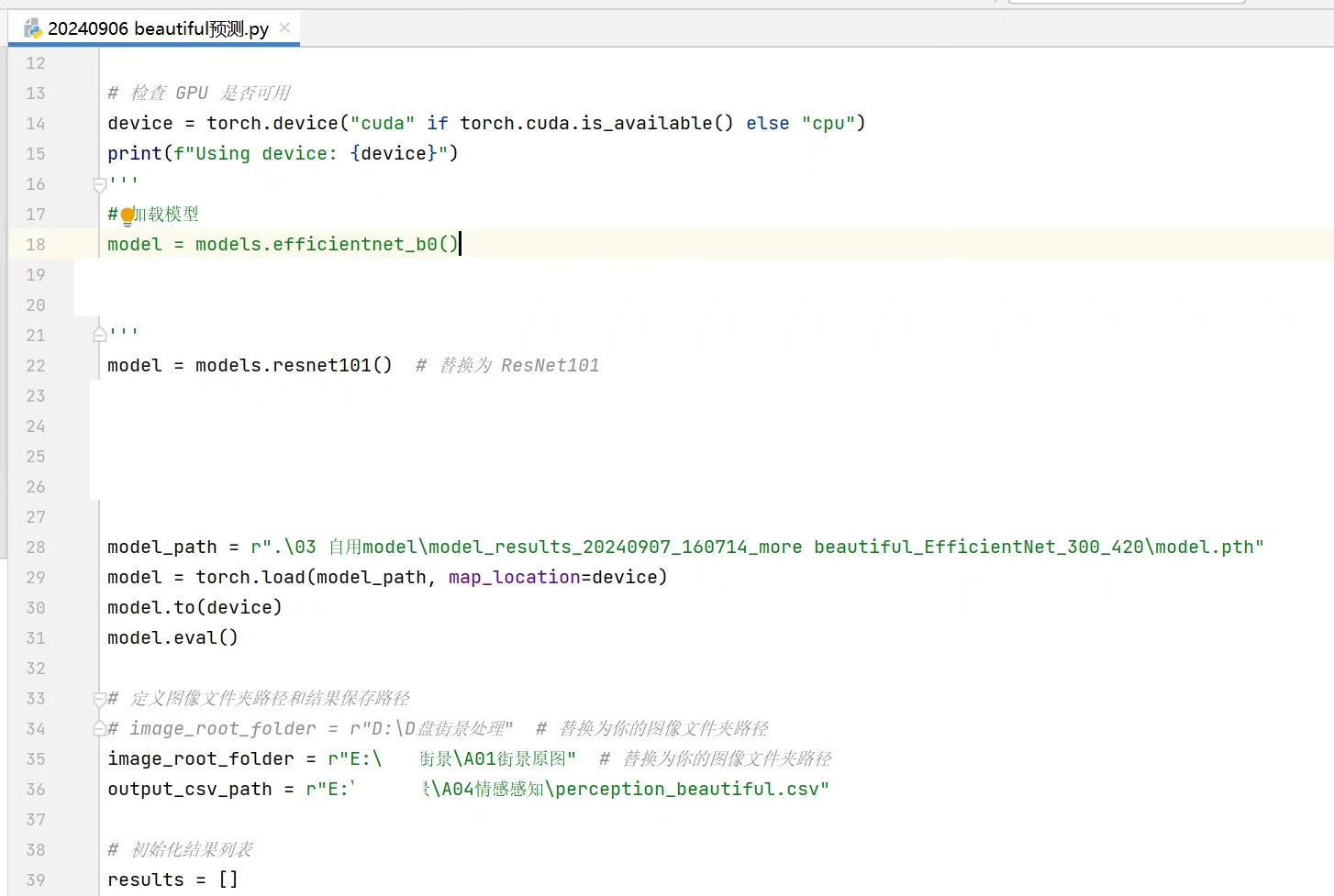
街景主观感知模型训练大规模预测 place pluse数据集 自定义数据集 模型训练预测 街景主观感知程序(beautiful, safer等自定义维度),多模型对比(ResNet50,ResNet101,EfficientNet、VGGNet、GoogleNet、DenseNet、MobileNet、ShuffleNet、Xception、ConvNeXt、Vision Transformer (ViT)、RegNet等),我自己是用420张图片,分别训练了beautiful,safer,模型最好精度0.89,很高了,我才用了420张图片,平均每张图片对比才16次
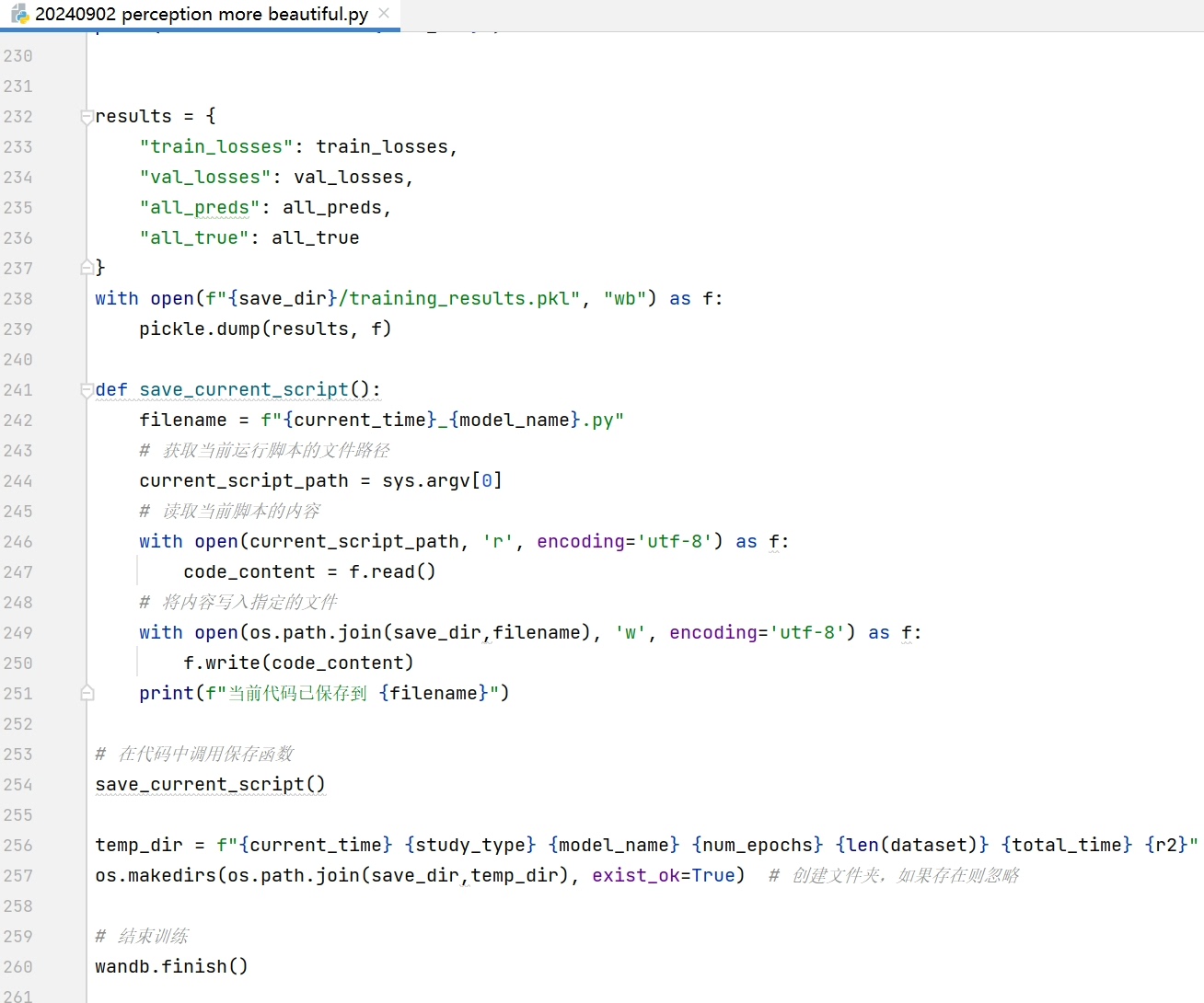
值得一提的是,我只用了420张图片来分别训练 “beautiful” 和 “safer” 模型,最终模型达到了0.89的高精度,这还是比较让人惊喜的。平均每张图片对比才16次,在有限的数据量下能有这样的成绩,我觉得一方面得益于多种模型的对比选择,找到最适合数据特点的模型;另一方面,对预训练模型的合理使用也功不可没。
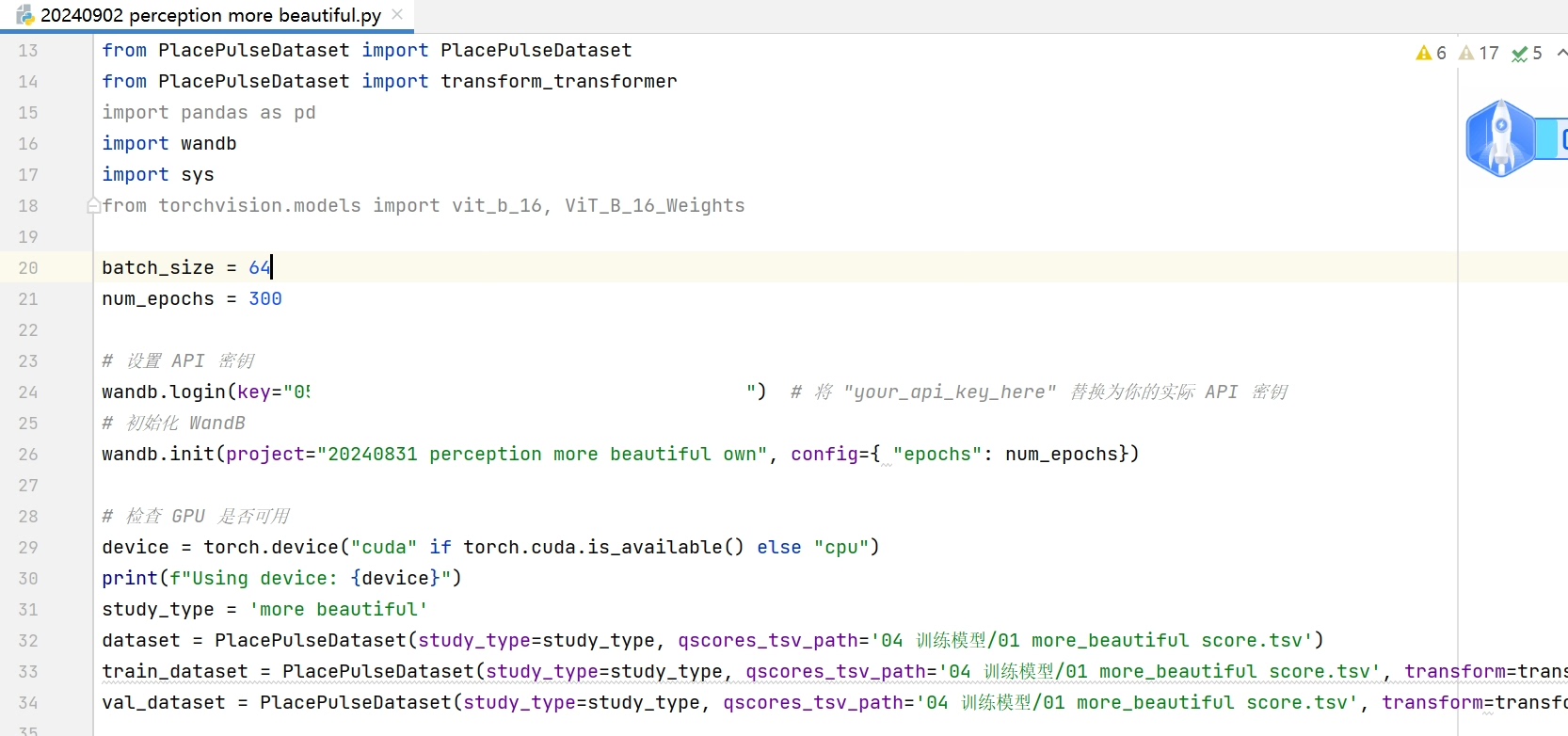
通过这次实践,我深刻体会到在街景主观感知模型训练中,数据集的针对性和模型选择优化的重要性。后续还可以考虑进一步扩大数据集规模,探索更多模型调优技巧,说不定能让模型性能更上一层楼。希望我的这些经验能给大家带来一些启发,欢迎一起交流讨论。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)