从生成到编辑一体化,Capybara 实现高保真视觉创作;覆盖九大领域的预训练语料,千万条教学记录的Sutra 10B Pretraining数据集上线!
公共资源速递
8 个公共数据集:
* Job Board 大学生求职数据集
* Groundsource 全球洪水事件数据集
* Sutra 10B Pretraining 教学训练数据集
* zh-meme-sft-8k 中文互联网梗文化数据集
* Creative Professionals 创意任务指令数据集
* Nemotron Personas France 法国合成人物数据集
* Student Mental Health 学生心理健康与倦怠数据集
* Historical Pandemic & Epidemic 全球历史疫情数据集
7 个公共教程:
* Slime:强化学习训练框架
* Capybara:统一视觉创作模型
* nanobot:超轻量级个人 AI 助手
* Qianfan-OCR:端到端文档智能模型
* vLLM + Open WebUI 部署 sarvam-30b
* Phi-4-reasoning-vision-15B 多模态推理视觉模型 Demo
* 一键部署 NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4
访问官网立即使用:openbayes.com
公共数据集
1. Job Board 大学生求职数据集
该数据集包含 10 万条记录,详细描述了学生的人口统计信息(如专业、大学等级、地区)、学术表现(如 GPA、实习)以及其求职应用途径(提交申请、初试、复试、获得录用)。对于成功获得录用的学生,还包括薪水、公司规模和角色相关性等目标变量。
* 在线使用:
https://go.openbayes.com/gY68g
2. Groundsource 全球洪水事件数据集
该数据集是一个基于全球新闻数据自动构建的高分辨率历史洪水事件数据集,包含 260 万条洪水记录,覆盖 150 多个国家。在数据处理过程中,研究团队利用 Gemini 大语言模型(LLMs)从非结构化新闻文本中系统提取洪水事件的时间、地点等结构化信息,实现了大规模历史灾害事件的自动化构建。
* 在线使用:
https://go.openbayes.com/0dwVg
3. Sutra 10B Pretraining 教学训练数据集
该数据集共包含 10,193,029 条教学记录,总规模超过 100 亿个 token,涵盖跨学科、技术、科学、社会研究、数学、生活技能、艺术与创意、语言艺术以及哲学与伦理学等九大领域。
* 在线使用:
https://go.openbayes.com/AhZn8
4. zh-meme-sft-8k 中文互联网梗文化数据集
该数据集是一个中文互联网梗文化指令微调数据集,主要用于训练对话模型以理解和使用网络热梗。数据集构建自抖音、小红书和 B 站等社交平台的评论互动,经过多轮清洗和增强处理。
* 在线使用:
https://go.openbayes.com/VpjdM
5. Creative Professionals 创意任务指令数据集
该数据集是一个大规模、高保真合成任务数据集,专为多模态 Agent 的训练、评估和微调设计,包含 1,070,917 个 Agent 代理命令操作,涵盖 36 种创意、技术和工程软件环境。
* 在线使用:
https://go.openbayes.com/SNcVl
6. Nemotron Personas France 法国合成人物数据集
该数据集包含 6,000,000 个法语人物实例,分布在 1,000,000 条记录中,每条记录提供 22 个字段(如姓名、性别、年龄、婚姻状况、职业等),包含多种人物类型(学者、体育爱好者、艺术爱好者、美食爱好者和旅游爱好者等)。
* 在线使用:
https://go.openbayes.com/7EGHL
7. Student Mental Health 学生心理健康与倦怠数据集
该数据集是一个大规模合成数据集,旨在通过学术、心理和生活方式因素分析和预测学生的倦怠水平,包含 150,000 条学生记录,混合了数值和分类特征,适合用于机器学习、分类和数据分析任务。
* 在线使用:
https://go.openbayes.com/VcMzj
8. Historical Pandemic & Epidemic 全球历史疫情数据集
该数据集是一个涵盖全球历史上重大疫情事件的数据集,包含自公元 165 年安东尼瘟疫到 2023 年新冠肺炎和猴痘的 50 个主要疫情事件,涵盖所有时代、地区和病原体类型。
* 在线使用:
https://go.openbayes.com/i87QV
公共教程
1. Slime:强化学习训练框架
Slime 是清华大学知识工程实验室(THUDM)发布的专为强化学习扩展设计的 LLM 后训练框架。该框架通过连接 Megatron 与 SGLang,实现了高性能训练与灵活数据生成的完美结合。
* 在线运行:
https://go.openbayes.com/jIKrw
2. Capybara:统一视觉创作模型
Capybara 是 xgen-universe 团队于 2026 年 2 月发布的统一视觉创作模型,面向文本到图像生成、文本到视频生成、基于指令的图像编辑以及基于指令的视频编辑等多种视觉创作任务。Capybara 基于先进的扩散模型和 Transformer 架构构建,旨在提供一个统一、高效的视觉生成和编辑框架。
* 在线运行:
https://go.openbayes.com/4xPBO
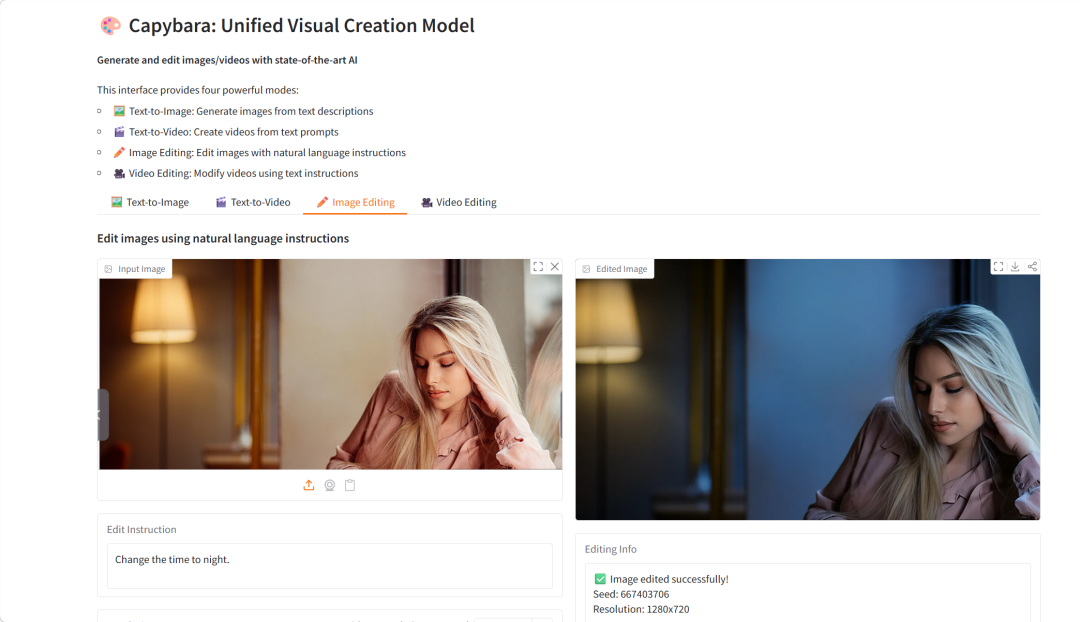
项目示例
3. nanobot:超轻量级个人 AI 助手
nanobot 是由香港大学数据系统实验室(HKUDS)推出的超轻量级个人 AI 助手项目,于 2026 年 2 月正式发布。该项目灵感来源于 OpenClaw,但将核心代理功能精简至约 4,000 行代码,相比 Clawdbot 的 43 万行代码减少了 99%。nanobot 采用模块化设计,代码简洁清晰,非常适合学习、研究和二次开发。
* 在线运行:
https://go.openbayes.com/3tTlq
4. Qianfan-OCR:端到端文档智能模型
Qianfan-OCR 是由百度智能云千帆于 2026年 3 月开源的端到端文档智能模型,基于 4B 参数视觉语言架构,将文档解析、版面分析、文字识别与语义理解融为一体。Qianfan-OCR 的核心突破在于其提出的 Layout-as-Thought 机制。在生成最终结果之前,模型通过特殊 token 进入「思考阶段」,先对文档结构进行显式建模,生成包括元素位置、类型以及阅读顺序在内的结构化信息,随后再完成整体解析输出,使模型在统一框架下同时具备结构感知与语义理解能力,有效提升了复杂文档场景下的解析准确性与稳定性。
* 在线运行:
https://go.openbayes.com/7diPm
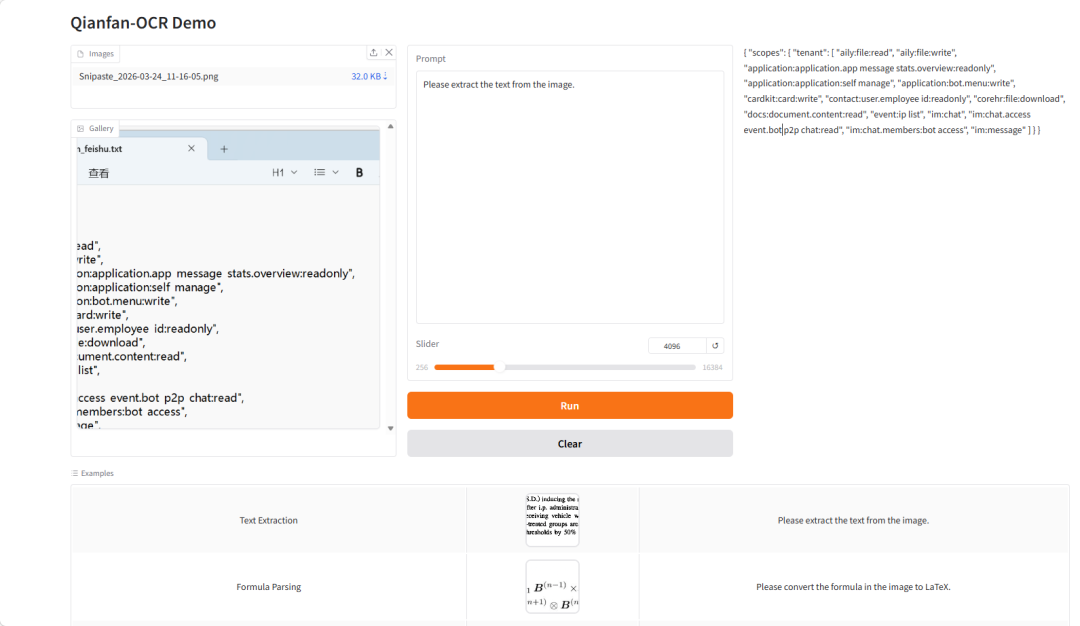
项目示例
5. vLLM + Open WebUI 部署 sarvam-30b
Sarvam-30B 是由 Sarvam AI 于 2026 年 3 月推出的开源大语言模型。作为 Sarvam 最新开源模型系列中的 30B 版本,它采用 Mixture-of-Experts(MoE)架构,总参数规模为 30B、每 token 激活参数约为 2.4B,面向多语言对话、推理、编码与实际部署场景进行了系统优化。
* 在线运行:
https://go.openbayes.com/GAGvI
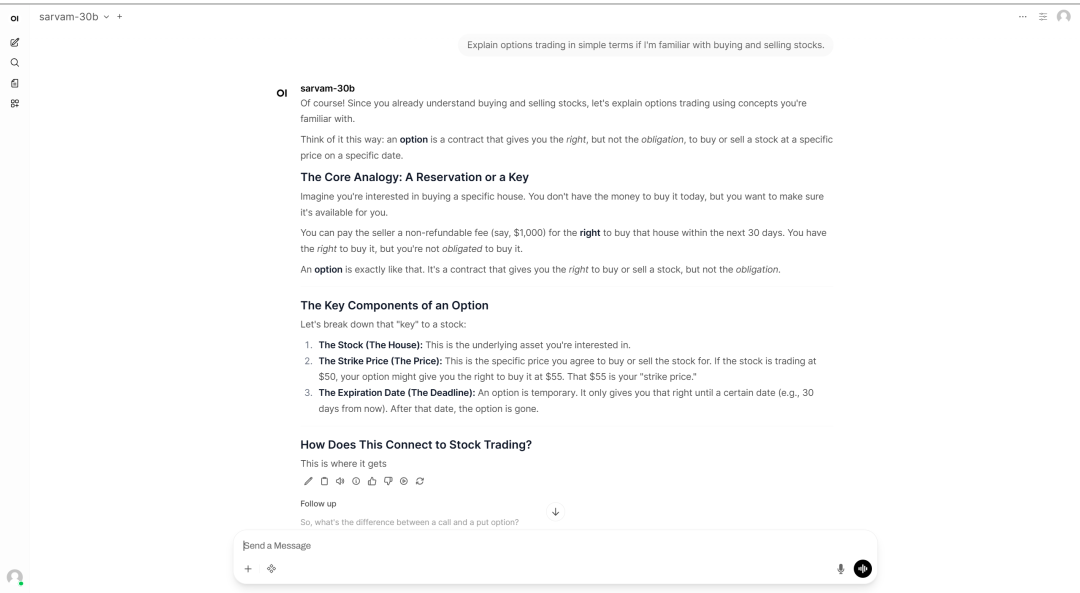
项目示例
6. Phi-4-reasoning-vision-15B 多模态推理视觉模型 Demo
Phi-4-reasoning-vision-15B 是微软于 2026 年 3 月发布的 150 亿参数多模态推理视觉语言模型。该模型基于 Phi-4 架构,结合了强大的文本推理能力和视觉理解能力,能够处理复杂的图文推理任务。
* 在线运行:
https://go.openbayes.com/itXuX
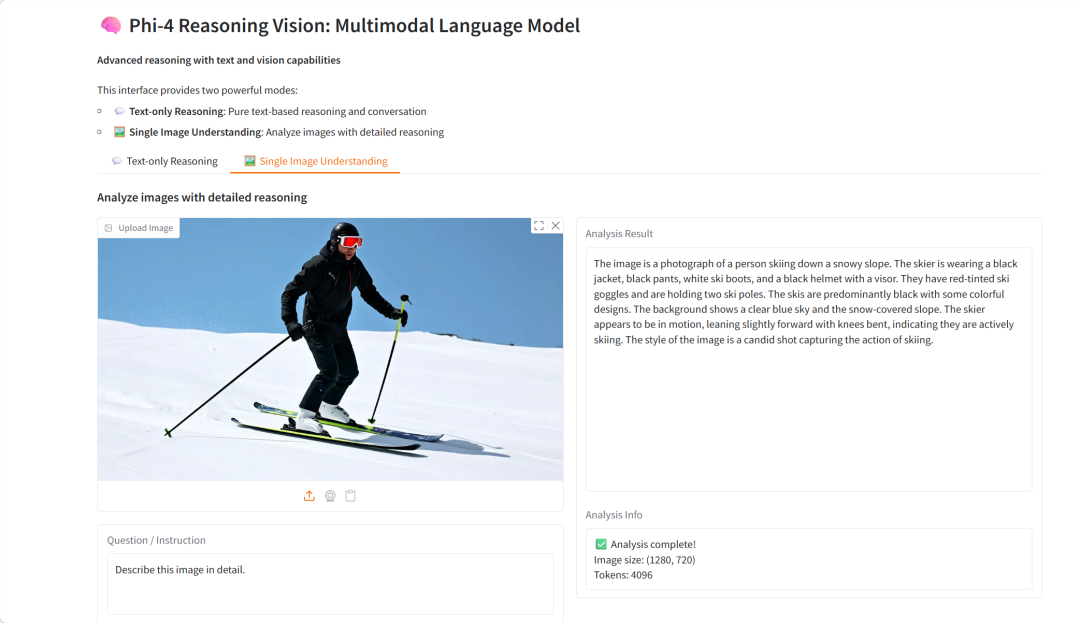
项目示例
7. 一键部署 NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4
NVIDIA Nemotron 3 Super NVFP4 由 NVIDIA Corporation 在 2026 年 3 月发布。该模型是一个 120B 总参数、12B 激活参数的大语言模型,采用 LatentMoE 混合架构,并支持最长 1M tokens 上下文。该模型面向长上下文推理、Agent 工作流、工具调用、RAG 与高吞吐问答等场景。在交互方式上,模型同时支持是否启用 reasoning 模式,并可以通过标准化聊天模板参数在普通问答与推理增强模式之间切换。
* 在线运行:
https://go.openbayes.com/x0Vzg

项目示例

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)