LLM-based Multi-Agent Systems:多智能体系统,从基础到前沿(AAAI 2026 Tutorial)
1. 这波 LLM 多智能体,究竟在“变什么”?
过去的多智能体系统(Multi-Agent Systems, MAS)研究,常见关键词是:博弈论、机制设计、多智能体规划与学习、协商与信誉、群体规范与涌现、沟通与协作、人机交互、对手建模、社会网络、仿真、以及形式化验证等。AAAI’26 的教程将这条“传统 MAS 主线”与近两年的“LLM 智能体(agent)浪潮”拼接在同一张路线图上:LLM 不只是生成文本,而是把自然语言理解/推理/规划/工具调用/记忆整合到一个可执行的“智能体控制器”里,进而让“多智能体协作”从学术设定走向工程工作流与产品化场景。[PDF p.3–6]
在该教程的定义里,MAS 的核心是:多个智能体在共享环境中共存并交互;每个智能体拥有自己的观测、动作、目标与领域知识;系统需要在合作、竞争或混合博弈的约束下协调行动以达成目标。[PDF p.5]

图1 教程总览:从 Foundations 到 Frontiers 的四段式结构(AAAI’26 Tutorial PDF,第2页)
2. 基础层:把“多智能体”说清楚,才能把“协作”做扎实
2.1 MAS 的最小抽象:主体、交互、共享环境
教程用非常“工程友好”的方式重申 MAS:系统里存在多个 agent,它们在同一环境中做决策,行动会互相影响,因此单个 agent 的最优策略往往依赖他人策略。这种相互依赖,决定了你不能只用单体决策(MDP)那套直觉,而需要更一般的建模框架(如 Markov Game / Dec-POMDP 等),并面对联合动作空间指数增长、通信成本、信用分配(credit assignment)、以及可扩展性等问题。[PDF p.4–6, p.89]

图2 多智能体系统示意(AAAI’26 Tutorial PDF,第4页)
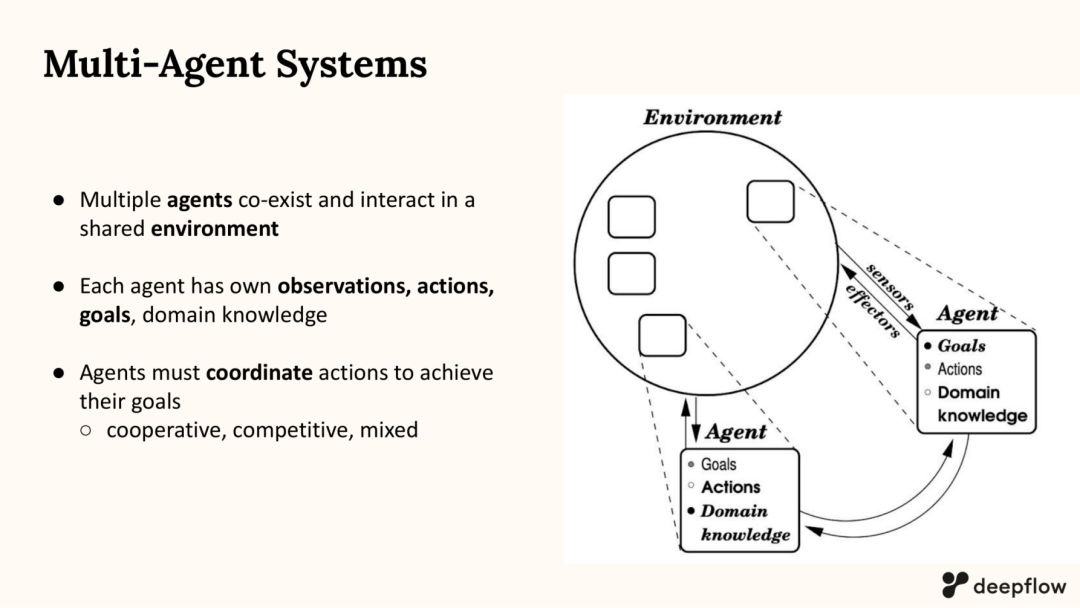
图3 MAS 的关键特征:共享环境、各自观测/动作/目标、需要协调(AAAI’26 Tutorial PDF,第5页)
2.2 规模效应:从“两个 agent”到“很多 agent”的质变
在多智能体场景里,最“硬核”的瓶颈之一是联合动作空间(joint action space)随 agent 数量增长而指数膨胀。教程给出直观例子:当 agent 数从 2 增加到 4,联合动作数量会出现爆炸式增长,从而带来训练/搜索成本飙升,进而逼迫我们在架构与协调机制上做“结构化约束”。[PDF p.89]

图4 多智能体扩展到多 agent 时,联合动作空间指数增长(AAAI’26 Tutorial PDF,第89页)
3.智能体(Agent)在 LLM 时代的“新解法”:M-P-T 三模块
3.1 Agent = LLM + Memory + Planning + Tools
教程把LLM agent 拆成三个模块:Memory(记忆)、Planning(规划)、Tools(工具),并明确“工作记忆”对应上下文窗口。这个拆分和 Lilian Weng 的经典综述一致:LLM 作为‘大脑’,外接规划、记忆与工具使用组件。[PDF p.95;Weng 2023]

图5 LLM Agent 的三模块:Memory / Planning / Tools(AAAI’26 Tutorial PDF,第10页附近;此处截图为第11页挑战页之前的脉络)
3.2 Planning:从 CoT 到 ReAct,再到“可执行动作”
Planning 的目标不是传统意义的最优规划,而是让模型在复杂任务中具备‘程序化的推理-行动控制’。在提示工程层面,Chain-of-Thought(CoT)通过给出中间推理步骤示例,让模型更容易分解多步问题;ReAct 则将推理轨迹与可执行行动交织在一起,让 agent 在外部环境/工具上“边想边做”,降低纯推理带来的幻觉与误差传播风险。这些方法都属于训练前(training-free)的能力脚手架:你不一定需要先做 RL 或大规模微调,也能让 agent 在多步骤任务里更稳定。[Wei et al. 2022;Yao et al. 2022]
3.3 Memory:Episodic / Semantic / Procedural 的分层视角
在记忆侧,教程采用认知科学的经典分层:情景记忆(episodic)、语义记忆(semantic)、程序性记忆(procedural)。这套分层常用于解释:为什么 agent 需要把短期上下文(工作记忆)与长期存储(向量库、日志、工具调用轨迹)结合起来,才能在跨回合任务中保持一致性与可追溯性。[PDF p.95;Tulving 1972;Sumers et al. 2024]
3.4 Tools:API、代码、搜索,把语言模型接到“可验证世界”
工具使用(Tools)包含 API 调用、代码执行、检索搜索等。教程特别强调:当任务存在可验证的外部判据(例如编译/单元测试/计算器验证),可以把 reward 或评估从‘主观偏好’转为‘可验证信号’,这会显著提升训练与迭代的可控性。[PDF p.116–120]
4. LLM 多智能体工作流:用图来组织协作,用协议来减少混乱
4.1 Workflow Graph:把协作结构显式化
教程用‘多智能体工作流(workflow)= 图结构’来描述协作:节点可以是 agent 或任务;边表示信息流/通信;执行可按轮次或异步推进;图结构可以是静态或动态。这个表述很关键:一旦把协作结构显式化,你就可以讨论不同拓扑(中心化、环形、全连接、消息总线等)对吞吐、鲁棒性、权限边界和工程复杂度的影响。[PDF p.9–10;p.168–170]
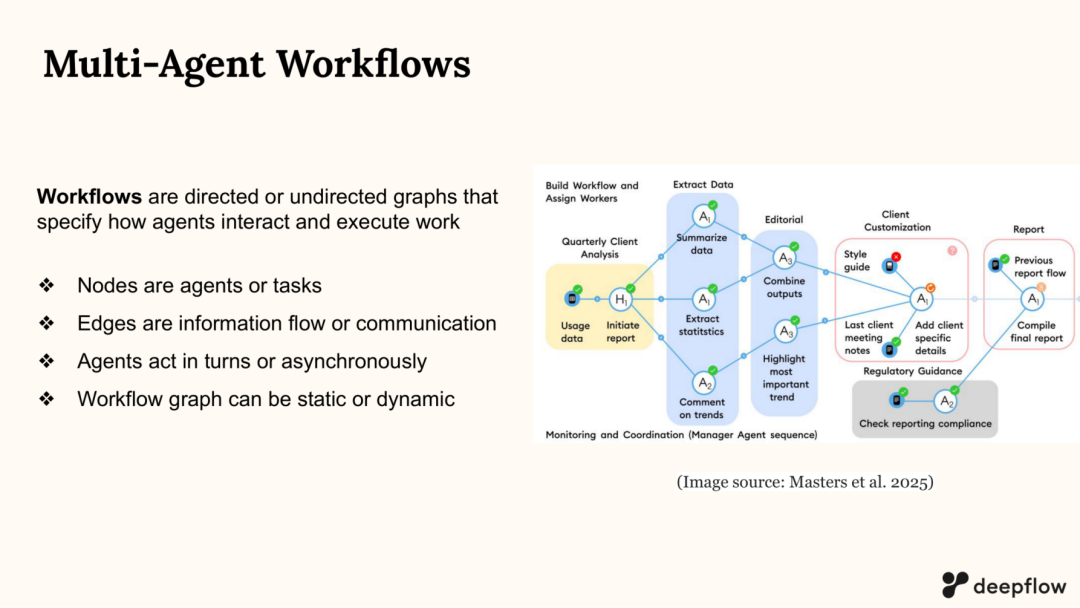
图6 多智能体工作流:以图结构组织 agent 交互(AAAI’26 Tutorial PDF,第9页)
4.2 典型挑战:任务分解、委派、依赖管理
教程在工作流层面列出挑战的第一条就是:层级化任务分解与委派(Hierarchical Task Decomposition and Delegation)。其要点是:复杂目标需要拆成可执行子任务,同时要处理子任务间依赖;拆分后要把任务委派给具备对应能力与工具权限的 agent;再把输出汇总成可交付结果。[PDF p.11]

图7 工作流挑战:任务分解与委派(AAAI’26 Tutorial PDF,第11页)
4.3 结构范式:中心化 Orchestrator vs 去中心化自演化网络
在‘前沿’部分,教程对比了预定义、多层级、中心化控制的工作流(容易形成单点瓶颈)与自演化、去中心化的 agent network。它给出若干结构示例:中心化协调(central agent hub)、环形通信(ring)、全连接/部分连接网络(mesh)、消息总线(bus)等,并讨论在隐私与敏感数据处理上,如何把‘协调’与‘数据处理’拆开:Orchestrator 负责路由与状态机,不直接触碰敏感数据,敏感数据由专门 agent 在边界内处理。[PDF p.168–171]
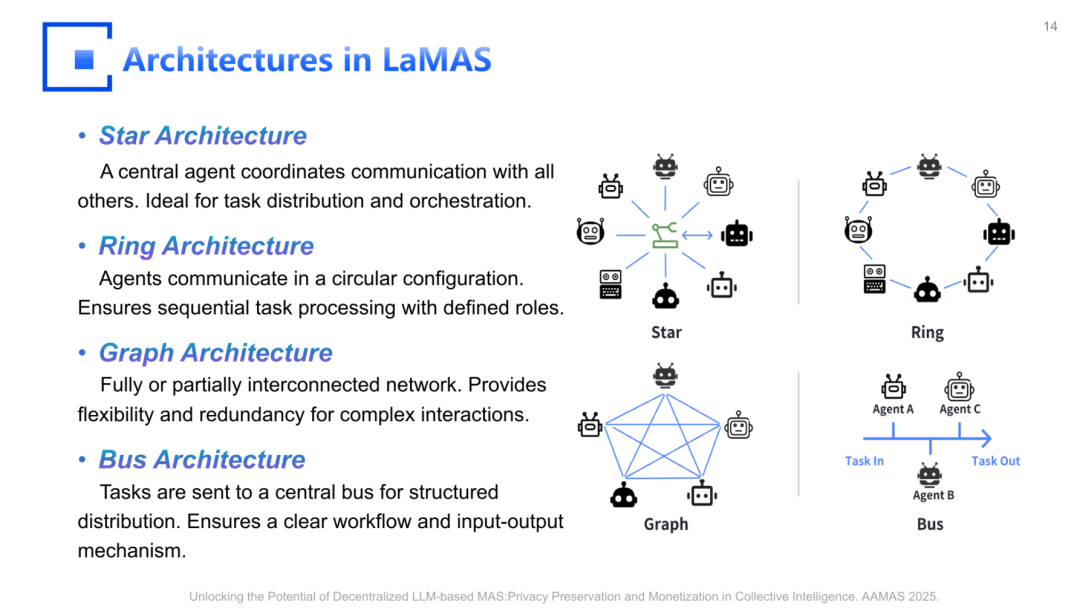
图8 LLM-based MAS 的应用与结构入口页(AAAI’26 Tutorial PDF,第168页)
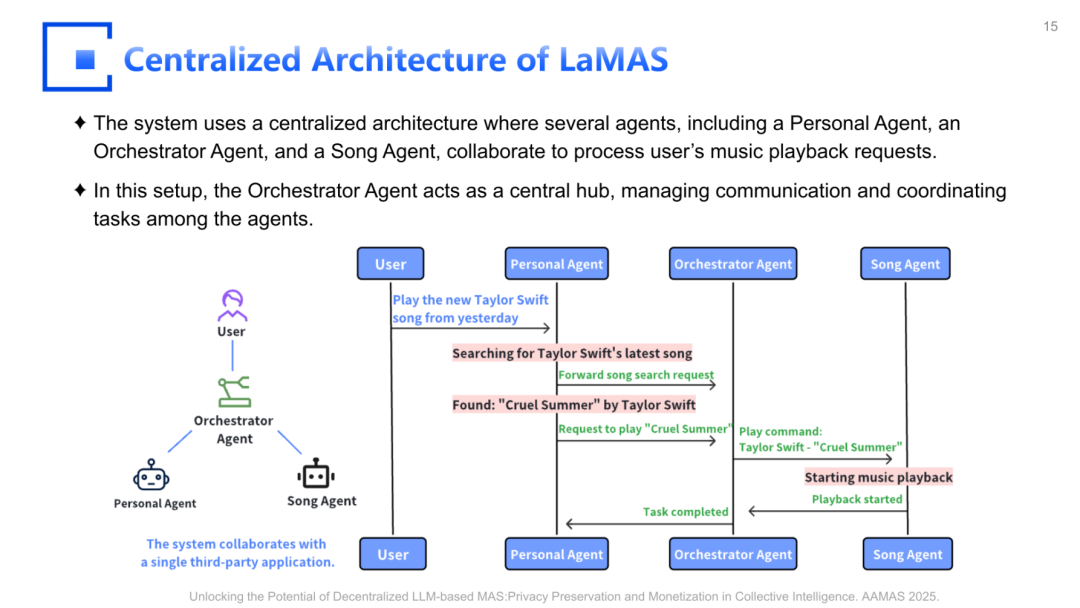
图9 典型拓扑:中心化/环形/网状/总线(AAAI’26 Tutorial PDF,第169页)
5. 应用前沿:从“协作做任务”到“社会仿真与科学协作”
5.1 社会仿真:让 agent 通过对话产生群体涌现
教程把社会仿真作为重要应用之一:多智能体社会模拟强调‘简单规则 + 动态交互 → 复杂社会模式’,覆盖市场、交通、社会规范等领域。在 LLM 加持下,agent 更像‘可交互的人类行为模拟器’,具备语言推理与适应性行为;群体现象可以通过对话互动自然涌现。[PDF p.164–165]
5.2 AI Co-Scientist:把多 agent 对齐到科学方法流程
教程还提到AI Co-Scientist 作为多智能体系统形态之一:它被描述为构建在 Gemini 之上的多 agent 系统,用于镜像科学方法的推理过程,帮助专家整理证据与改进工作,定位为‘协作工具/虚拟科研合作者’。[PDF p.166–167]
6. 从‘能跑’到‘能优化’:多智能体后训练与强化学习信号设计
6.1 先讲清楚 reward:RLHF vs RLVR
在后训练(post-training)部分,教程强调优先使用可验证奖励(RLVR, Reinforcement Learning with Verifiable Rewards):当你能写出确定性的 verifier(如编译器、计算器、单测),就把奖励做成 0/1 或可计算分数,显著约束 reward hacking。相对的,RLHF 依赖人类偏好数据训练 reward model,成本更高,也更容易出现智能体目标偏移。[PDF p.117]
6.2 稀疏 vs 稠密:PRM(过程奖励模型)的取舍
教程给出奖励设计的工程规则:通常正确性权重占70–90%;模型会找捷径(Goodhart 风险);可以先从稀疏奖励起步,必要时引入过程奖励模型(PRM)给每一步打分,以降低梯度方差并支持早停,但代价是需要更细粒度的标注。[PDF p.118–119]
6.3 PPO vs GRPO:基础设施成本与迭代速度
在算法侧,教程用一页对比PPO 与 GRPO:GRPO 用组内均值奖励替代 learned critic,省去 value function 训练,通常更简单、更适合研究快速迭代;如果不确定,从 GRPO 开始是一个实用建议。[PDF p.119]
6.4 规模与显存:从 7B/8B 的快速迭代,到 70B+ 的生产级训练
教程给出‘模型大小阶梯’:7B/8B(1 张 GPU,快迭代)→ 14B(1–2 GPU)→ 32B(4–5 GPU)→ 70B+(8+ GPU,偏生产)。并强调:只有在有明显信号后再扩规模。同时给出训练显存的粗略估算:全量 AdamW 微调时,模型状态约 20 bytes/param 量级,7B 已经需要多卡或做内存优化(如 PEFT、ZeRO、分片等)。[PDF p.121–123]
7. 工程生态:多智能体框架如何选型
如果把LLM-based MAS 看成‘可组合的工作流系统’,那么关键问题是:你是否需要一个高层对话编排框架,还是需要一个更底层、可控的状态机/图执行引擎。在开源生态里,微软 AutoGen 提供多智能体对话编排抽象,并在 2025 年宣布与 Semantic Kernel 方向合并为 Microsoft Agent Framework;LangGraph 以“图”为基本执行单元构建长期运行、状态化 agent;CrewAI 则强调轻量、角色化的多 agent 协作与可配置性。[AutoGen GitHub;Microsoft Agent Framework GitHub;LangGraph GitHub;CrewAI GitHub]
8. 走向 Frontiers:你可以把哪些问题当成下一阶段的研究/产品路线
结合教程的‘基础—agent—多智能体—演示’结构,可以把前沿问题落到更可操作的研发清单:(1)协作结构:静态工作流 vs 动态拓扑,何时需要自适应重连与专家化;(2)权限与隐私:Orchestrator 与敏感数据处理解耦;(3)可验证性:把关键步骤接入 verifier 与可追溯日志;(4)训练闭环:优先 RLVR,必要时 PRM,选择 GRPO/PPO 并控制工程复杂度;(5)评测与基准:把任务分解质量、协作效率、鲁棒性、工具调用成功率做成指标体系,并用真实工作流持续回归。[PDF p.168–175]
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)