CoPaw模型本地部署测试
CoPaw 是阿里发布的“本地智能体工作台”(Agent Workstation)。它本身更像一套框架或中间件,和小龙虾这类产品比较接近;这套工具中包含一个可以本地部署的小模型名叫 CoPaw。
源码: https://github.com/agentscope-ai/CoPaw
最近类小龙虾的工具出得很多。本篇主要想聊的,不是 CoPaw 工作台本身,而是它提供的、也叫 CoPaw 的本地小模型。这个模型既可以跑在 GPU 上,也可以跑在 CPU 上。CoPaw-Flash 系列专门针对本地部署做了优化,硬件门槛比较低。比如 CoPaw-Flash-4B-Q8_0 是 4B 尺寸下的 Q8 量化版本,我这次实测时,内存和显存占用都没有超过 10G。
那是不是说,以后在自己机器上部署小模型,就不用再花 token 了?另外,除了 CoPaw 工作台,其他 Agent 比如龙虾,能不能也接这个模型?好不好配?本文记录一下我的实验方法、实验数据,以及一些还不算成熟的判断,仅供参考。
请注意:由于LLM模型和工作台名字都叫CoPaw,为区分二者,下面分别称为 CoPaw工作台和CoPaw 模型。
安装 CoPaw 工作台
安装很简单,依旧以docker安装为例:
docker run -p 8088:8088 -v copaw-data:/app/working -v copaw-secrets:/app/working.secret agentscope/copaw:latest copaw app --host 0.0.0.0 --port 8088
执行后,就可以在本机或者局域网的其它机器上通过端口8088访问CoPaw服务了。
界面大概长这样,和其它Agent工具的Web差不多。在使用之前先选择模型,如果在这个界面往下拉可以看到,主流模型都支持:OpenAI,Gemini,阿里,Deepseek都可在此界面配置APIKey。
这里比较特别的是 CoPaw Local,也就是它自带的本地小模型入口。点开之后就能直接安装。2026 年 4 月 1 日我做实验时,默认提供 2.9G 和 4.8G 两个版本,我装的是 4.8G 那个。
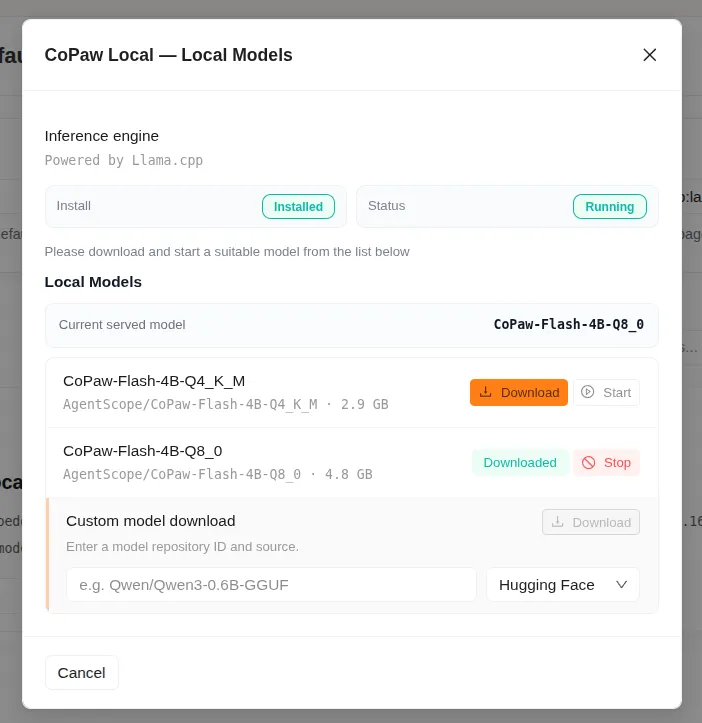
安装好之后,在聊天界面的右上角可以切换到本地模型。
默认拉下来的 Docker 是 CPU 环境,也就是在 CPU 上跑这个本地模型,速度肯定不会快。第一次跟它说“你好”,回复花了五分钟,过程中可能包含加载模型和初始化这些动作。后面再问别的问题,基本能压到一分钟以内,但也谈不上快。从后台看,思考过程中基本一直跑满 7 个 CPU,内存大约占到 70%(测试机器内存是 16G)。
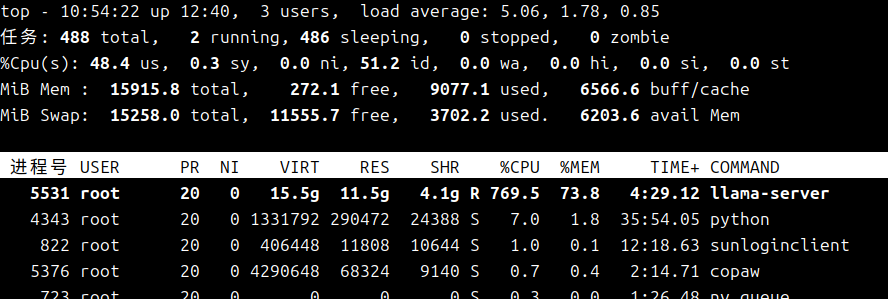
在 GPU 上测试
因为 GPU 和 CPU 用的工具链不一样,而我这次懒得折腾 CoPaw 里的 GPU 支持。刚好测试机上有 GPU,也装过 ollama,我就把本地模型放到 ollama 里,又测了一下在 GPU 上的效果。如果这条路能走通,那龙虾之类的其他 Agent 理论上也可以用这个本地模型。
好久没用了,先更新了一下ollama镜像
# 停止并删除你正在运行的旧容器
docker stop ollama && docker rm ollama
docker pull ollama/ollama
nvidia-docker run --rm -d -e OLLAMA_ORIGINS="app://obsidian.md*" --gpus=all -v /exports/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
下载模型
在 4 月 1 日做实验时,还没法直接用 ollama pull 拉 CoPaw-Flash 模型,所以我直接用了在 CoPaw 工作台里下载好的 gguf 包(也可以从 Hugging Face 下载)。把这个 gguf 文件放到 ollama 能看到的目录里就行,比如 CoPaw-Flash-4B-Q8_0.gguf。
配置模型
写一个 Modelfile,如:/tmp/Modelfile
FROM /path/to/your/copaw-xxx.gguf
TEMPLATE {{ .Prompt }}
RENDERER qwen3.5
PARSER qwen3.5
PARAMETER presence_penalty 1.5
PARAMETER temperature 1
PARAMETER top_k 20
PARAMETER top_p 0.95
以上配置参考的是源码里的 website/public/docs/models.zh.md。这里不要写得太简单,不然模型可能调不起工具。
安装和测试
ollama create copaw-flash-4b -f /tmp/Modelfile
ollama list
ollama run copaw-flash-4b "你好"
在 GPU 上运行,速度就快很多了,基本可以算“秒回”,显存大约会占到 6G。
如果还想在 CoPaw 工作台里用GPU版本,可以先到左侧的 Models 里配置,在 ollama 的 Setting 中填好 IP 地址等信息,再点 Models 里的 Discover,就能看到新装的模型。
之后在聊天界面右上角切到 ollama 提供的模型,就可以直接聊了。
最后
至于小模型的聊天和调用工具能力,我只做了很简单的测试。普通聊天是可以的,也确实有调工具的能力。但一到更具体的任务,比如问今天的天气、看看某个目录里有什么文件,结果就不太行了,经常 Thinking 半天,然后没下文了。当然,这里也不排除是我还没把配置调到最佳。
如果整个流程都跑在自己机器上的本地模型里,那推理这部分就不会花 token 了。并且CoPaw模型能提供给别的 Agent 使用,上手难度也没有我一开始想得那么高,至少通过 ollama 这一层是能接起来的——整个流程很容易跑通。
但从这次实验看,最后的判断还是:能用,但能力有限。普通聊天可以,简单工具调用偶尔也能成;真到具体任务上,目前这个 4B 模型还不太稳。现在我还没遇到一个和现有 Agent 配合起来、效果真正让我满意的本地部署模型。如果谁有用得比较好的,也欢迎告诉我。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)