AI Agent 搭建指南:从零开始 vibecoding 你的第一个Agent(附完整代码)

市面上的 Agent 教程,要么太浅、要么太碎。真正能让你从"我想做一个Agent"到"我做出了一个能用的 Agent"的完整路径,几乎找不到。
干脆自己动手了vibecoding一个出来。
把 Anthropic、OpenAI 还有各路高手的零散资料全部揉碎,和我的搭档 Claude 一起,硬是肝出了一套面向普通人的完整课程。目标就一个:学完就能动手,今天就做出你的第一个 Agent。
1. Agent 是怎么工作的
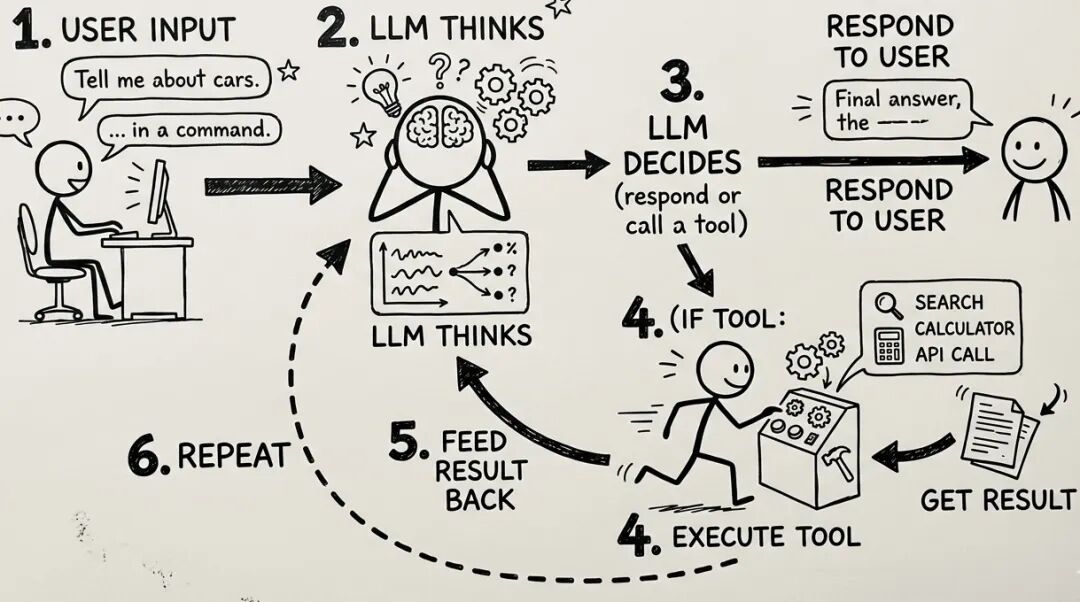
先搞清楚底层逻辑,不然你根本不知道为什么要用 Agent,以及什么时候该用 Agent。
所有 Agent 的核心循环都是一样的:
用户输入 → LLM 思考 → LLM 决定(回复还是调用工具)→ 如果调用工具:执行,把结果传回 → 重复
LLM 是"大脑",负责推理。工具是"手",负责执行具体动作(计算器、网页搜索、文件读写)。记忆是"笔记本",记录已经发生的事情。不管你用 LangGraph、CrewAI、Anthropic 的 SDK 还是 OpenAI 的 Agents SDK,框架只是在这个循环上包了一层抽象,本质没变。
增强版 LLM
普通 LLM 输入文本、输出文本。增强版 LLM 加了三个能力:
- **工具(Tools):**模型可以调用的函数,计算器、数据库、API、文件操作等。Anthropic 通过 input_schema 暴露工具,OpenAI 用 function 对象包装参数。
- **检索(Retrieval):**从外部来源拉取相关信息,搜索引擎、文档、向量数据库。
- **记忆(Memory):**通过消息历史或持久化存储,在多次交互中保留信息。
工作流 vs. 真正的 Agent
选型的时候搞清楚这个区别很重要。工作流是确定性的,你的代码控制执行流程,同样的输入永远走同一条路,适合步骤固定、定义明确的任务,成本也低。Agent 是动态的,LLM 自己决定下一步,可以反复调用工具,适合开放式任务,但成本更高。
正确的做法是:先用简单的工作流试试,看能不能满足需求,再考虑升级成完全自主的 Agent。
2. 五种工作流模式

大部分问题其实根本不需要 Agent 就能解决。这五个模式是 Anthropic 文档记录、被业界广泛采用的常见方案,每个都依赖增强版 LLM。
模式一:Prompt Chaining(链式提示)
把任务拆成顺序执行的步骤,每个 LLM 调用处理前一个的输出。在步骤之间加程序化的"门卫"来验证质量。
适用场景: 任务能干净地分解成固定子任务。用速度换精度,让每个 LLM 调用更简单。
例子: 生成营销文案再翻译。写大纲、验证覆盖了关键主题、再写完整文档。
模式二:Routing(路由)
对输入进行分类,然后分发给专门的处理器。每个处理器有自己的优化 prompt。
适用场景: 不同类别的输入需要完全不同的处理方式。客服工单分类是经典例子。
模式三:Parallelisation(并行化)
同时跑多个 LLM 调用。Sectioning 把任务拆成独立的子任务并行处理;Voting 跑同一个任务多次,聚合结果获得更高置信度。
适用场景: 子任务相互独立(sectioning),或者需要对关键决策达成共识(voting)。
模式四:Orchestrator-Workers(编排器-工作者)
一个中心 LLM(编排器)动态拆分任务,分发给 worker LLM。和并行化不同,子任务不是预定义的,编排器在运行时决定。
适用场景: 复杂任务,无法提前预知结构。跨多文件生成代码、研究任务、写报告。
模式五:Evaluator-Optimiser(评估器-优化器)
一个 LLM 生成输出,另一个评估并给出反馈。如果评估不通过,反馈循环回去。反复直到满足质量标准。
适用场景: 有明确评估标准,迭代优化能带来可衡量价值的场景。翻译、代码生成、写作任务。
3. 构建你的第一个 Agent

这部分是文章的核心——怎么把"我想要一个 Agent 帮我做 XYZ"变成真实可用的东西。
最简单的心法就五步:
- 把工作写下来
- 决定它需要什么工具
- 告诉模型怎么表现
- 用 5 个真实例子测试
- 只有失败了才加复杂度
你不需要同时掌握五个框架才能搭 Agent。对普通人来说,最好的起点就两个:
- **Anthropic:**如果你想要一个能操作文件、跑 shell 命令、做网页搜索、coding 能力强的"能干的操作员"
- **OpenAI:**如果你想要一个开发体验干净、有托管工具、handoffs、guardrails、能快速上生产的 SDK
这份指南主要讲这两个。
最简心智模型
构建 Agent 之前,先回答这四个问题:
1. 要达成什么结果?Agent 实际要产出什么?
例子:
- “研究一个主题并写摘要”
- “读我的笔记并转成卡片”
- “看支持工单并正确路由”
- “对比产品并给我最佳选项”
- “审核内容并用自己的风格重写”
2. 它需要什么信息? 需要网页搜索、文件、数据库、表格、CRM,还是只要用户的消息?
3. 它可以执行什么操作? 只能回答?只能搜索?可以改文件?可以发邮件?可以写代码?可以调用你自己的函数?
4. 它必须遵守什么规则? 语气、格式、约束、安全规则、遇到不确定怎么办、"好"的标准是什么。
能清楚回答这四个问题,通常一天内就能搭出第一版 Agent。
用 AI 帮你设计 Agent
正式动手之前,先用 Claude 或 ChatGPT 帮你定义清晰。
粘贴类似这样的内容:
I want to build an AI agent.My goal:[描述你想要它做什么]The user will ask things like:[加5个真实例子]The agent should have access to:[网页搜索 / 文件 / 计算器 / 自定义 API / 其他]It must always:[列出不可妥协的规则]It must never:[列出边界]Please turn this into:1. A clear agent spec2. A system prompt3. A tool list4. A first version roadmap5. 10 test cases
这一个 prompt 就能把新手的模糊想法变成可执行的计划。
Agent 设计公式
每次设计都用这个结构:
Agent = 角色 + 目标 + 工具 + 规则 + 输出格式
例子:
- **角色:**加密项目研究助手
- **目标:**查找准确信息并清晰总结
- **工具:**网页搜索、文件搜索、计算器
- **规则:**引用来源、不猜测、标注不确定性
- **输出格式:**总结、风险、机会、最终判断
这就是大多数有用 Agent 的基础。
五种入门 Agent 类型
新手别一上来就搞多 Agent 集群。先从这五个里挑一个:
1. 研究 Agent
适用场景:想让 Agent 收集信息并总结。
例子:
- “研究脚踝扭伤最好的康复训练”
- “找某个加密协议的最新动态”
- “对比三款笔记本电脑”
需要的工具:网页搜索、如果用自己的文档还要文件搜索、清晰的输出格式。
2. 内容 Agent
适用场景:想让 Agent 写、改写、总结或转换内容。
例子:
- “把我的笔记转成通讯”
- “用我的品牌语气重写”
- “总结这个会议记录”
需要的工具:通常只要一个强的 system prompt,可选加文件访问、加你的风格示例。
3. 工作流 Agent
适用场景:想让 Agent 执行可重复的业务流程。
例子:
- “分类支持工单”
- “把线索路由到正确分类”
- “检查表单提交并生成回复草稿”
需要的工具:清晰的分类规则、有些场景还要自定义工具或 API 调用。
4. 个人知识 Agent
适用场景:想让 Agent 用你自己的文档回答问题。
例子:
- “只用我的 PDF 回答”
- “搜我的笔记并解释这个主题”
- “找出所有提到这个客户的 reference”
需要的工具:文件搜索或 RAG、清晰的指令让 Agent 严格基于提供的材料。
5. 操作 Agent
适用场景:想让 Agent 在某个环境中执行操作。
例子:
- “读这些文件并编辑”
- “搜网页、收集发现、保存报告”
- “跑 shell 命令并帮我 debug”
需要的工具:工具、权限、强的安全边界。
Anthropic:构建第一个 Agent 的最简路径
Anthropic 的 Agent 工具链在你需要模型使用工具、在某个环境中操作时特别顺手。Claude Code 2025 年 2 月上线,后来改名叫 Claude Agent SDK,2026 年 3 月 GitHub 最新 release 是 v0.1.50。
选 Anthropic 的场景:
优先选它如果你的 Agent 需要:
- 读、写、编辑文件
- 用 shell 命令
- 搜索网页
- 用 MCP 工具
- 做 coding 和技术活
- 像个能干的助手一样一步步操作
用 Anthropic 真正在做的事:
入门级来说,你就做了三件事:
- 给 Claude 一个任务
- 给 Claude 工具
- 让 Claude 循环执行直到完成
没了。
入门例子:研究总结 Agent
假设你想要:
“一个能研究主题并给我写出干净报告的 Agent”
设计计划:
- **角色:**高级研究助手
- **目标:**查找准确信息并清晰总结
- **工具:**网页搜索,可选加文件访问
- **规则:**引用来源,说不确定的地方,保持简洁
- **输出:**要点总结 + 关键发现 + 风险或不确定性 + 最终结论
这就是你的 system prompt:
SYSTEM_PROMPT = '''You are a careful research assistant.Your job is to help the user research topics accurately.Use tools when needed.Do not guess.If information is uncertain or incomplete, say so clearly.Always produce:1. Summary2. Key findings3. Risks or uncertainty4. Final conclusion'''
然后用户可以问:
- “研究最新的 AI Agent SDK”
- “对比 Anthropic 和 OpenAI 哪个适合新手搭 Agent”
- “找三个强来源并总结”
这已经是一个可用的 Agent 了。
OpenAI:构建第一个 Agent 的最简路径
OpenAI 2025 年 3 月 11 日发布了 Agents SDK,配合 Responses API,内置了网页搜索、文件搜索、电脑操作等工具。Python 包 openai-agents 2026 年 3 月版本是 0.13.1。
选 OpenAI 的场景:
优先选它如果你的需求是:
- 一个非常干净的 Agent API
- 简单的自定义函数工具
- 内置托管工具
- specialist Agent 之间的 handoffs
- guardrails 和 tracing
- 从原型到生产的平滑路径
用 OpenAI 真正在做的事:
入门级来说,你就做了四件事:
- 创建一个 Agent
- 给他指令
- 需要的话加工具
- 用真实用户请求跑起来
没了。
入门例子:支持分类 Agent
假设你的目标是:
“读收到的支持请求,判断是billing、technical还是sales”
设计:
- **角色:**支持分类助手
- **目标:**正确分类请求
- **工具:**不用,后续可能加 CRM 工具
- **规则:**只选一个分类,简短解释原因
- **输出:**分类 + 原因
代码:
from agents import Agent, Runneragent = Agent( name="Support Triage Agent", instructions="""You classify customer requests.Choose exactly one category:- billing- technical- salesReply with:1. Category2. One sentence explaining why""",)result = Runner.run_sync(agent, "I was charged twice for my subscription this month.")print(result.final_output)
这已经是一个有用的 Agent 了。
入门例子:加一个自定义工具
假设你想要:
“在需要的时候帮用户计算值”
from agents import Agent, Runner, function_tool@function_tooldef calculate(expression: str) -> str: import math allowed = {k: v for k, v in math.__dict__.items() if not k.startswith("__")} return str(eval(expression, {"__builtins__": {}}, allowed))agent = Agent( name="Math Helper", instructions="Help the user solve maths problems. Use the calculator tool when needed.", tools=[calculate],)result = Runner.run_sync(agent, "What is compound growth on 10000 at 5 percent for 8 years?")print(result.final_output)
现在这个 Agent 不只是在聊天了,它在通过工具执行动作。
入门例子:用托管工具
OpenAI Agents SDK 也支持托管工具(网页搜索、文件搜索、代码解释器),新手可以理解成 SDK 文档里的"预建能力",直接 attach 到 Agent 上,不用从头写。
这意味着你可以搭这样的 Agent:
- “搜这个主题的网页并总结”
- “搜我的文件并从中回答”
- “跑代码分析这个数据”
定制 Agent 的检查清单
新手常犯的错误是:搭了个通用助手,而不是具体的 Agent。
1. 把工作做窄
❌ 不好:“帮我处理业务的事”
✅ 好:
- “把销售通话总结成行动要点”
- “把线索分成热、温、冷”
- “研究加密项目并输出风险、催化剂、最终判断”
2. 定义输出格式
❌ 不好:“给我一个答案”
✅ 好:
- “返回:总结、证据、风险、下一步”
- “返回 JSON:category、confidence、explanation”
- “返回 bullet list,五个标题以下”
3. 给例子
想要特定语气、结构、分类质量的话,例子很有用。
告诉模型:
- “这是三个好输出的例子”
- “这是五个请求分类的例子”
- “用这个精确的风格写”
4.只在需要的时候加工具
任务只是改写笔记就别加网页搜索。答案应该只来自 prompt 就别加文件访问。每个额外工具都会增加复杂度。
5. 用真实 prompt 测试,不要用理想的测试
用真实用户会输入的那种混乱 prompt 测试。
不要只测试:
- “请分类这个技术问题”
也要测试:
- “my account is broken and i keep getting charged what do i do”
这才是你真正能看到 Agent 实际表现的地方。
你的构建路径
**Step 1:**写一句话描述 Agent 例子:“我想要一个 Agent,把我的粗糙笔记整理成干净的周报。”
**Step 2:**问 Claude 或 ChatGPT 帮你转成:
- Agent spec
- System prompt
- Tool list
- 10 个测试 prompt
**Step 3:**搭最小可运行版本 不要多 Agent。不要复杂记忆。除非必要,不要上 RAG。
**Step 4:**用 10 个真实例子测试
**Step 5:**一次改进一件事
- prompt
- 输出结构
- 例子
- 工具
- 记忆
- 检索
这个顺序很重要,别搞混。
不要犯这个错:
最大的错误是试图搭一个"万能超级 Agent"。
不要一上来就:
- 网页搜索
- 文件搜索
- 数据库访问
- 记忆
- 多 Agent handoffs
- 复杂 guardrails
- 自定义 dashboard
- 20 个工具
从这些开始:
- 一个任务
- 一个 Agent
- 一个清晰的 prompt
- 最多一两个工具
- 五到十个真实测试用例
不把自己搞复杂,这才是正确的路。
4. 怎么用好工具
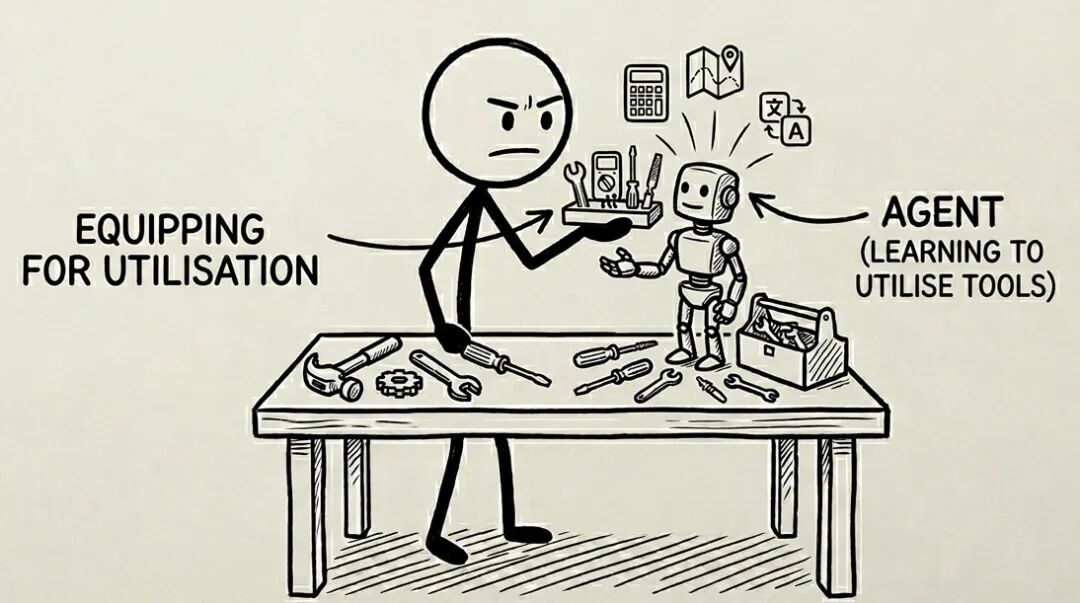
大多数人都把这件事搞复杂了。
你只需要理解一件事:
工具就等于:“AI 自己做不到的事”
例子:
- 算数字
- 搜网页
- 读文件
- 发邮件
- 查数据库
Step 1:先问自己"这需要工具吗?"
加任何东西之前,先问:
- 模型能单靠推理回答这个问题吗?
- 还是需要现实世界的数据或动作?
不需要工具的例子:
- “改写这封邮件”
- “总结这段文字”
- “解释这个概念”
需要工具的例子:
- “现在天气怎么样?”
- “搜最新新闻”
- “算复利”
- “从我的表格拉数据”
👉 规则:需要外部数据或动作 → 用工具;不需要 → 别加
Step 2:用 AI 帮你设计工具
I am building an AI agent.My goal:[描述目标]Here is what I think the agent needs to do:[列出动作]Which of these require tools?What tools should I create?Keep them simple and minimal.Return:1. Tool list2. Tool descriptions3. Inputs required for each tool
这能帮你省很多时间。
Step 3:保持简单 stupid
❌ 差的工具:
manage_files(action, file, destination, overwrite, format, permissions)
✅ 好的工具:
read_file(path)write_file(path, content)delete_file(path)
👉 规则:一个工具 = 一个明确的任务
Step 4:告诉 Agent 什么时候用工具
这是大多数人失败的地方。
❌ 不好:“计算器工具”
✅ 好:“当需要数学的时候用这个工具。不允许猜测计算结果。”
Step 5:让 Agent 失败,然后修
用真实测试跑:
- “2^16 是多少”
- “算一下 10 年 7% 增长”
如果:
- 不使用工具 → 修描述
- 用得不对 → 修输入
- 产生幻觉 → 规则定严格点
5. 给 Agent 加记忆

这件事也被严重过度复杂化了。
你只需要理解两件事:
记忆就两种
1. 短时记忆(对话)
就是:“到目前为止说了什么”
你用默认配置就已经有了。
2. 长时记忆(外部知识)
就是:“Agent 以后可以查的东西”
例子:
- 你的笔记
- 文档
- 数据库
什么时候真正需要记忆?
问自己:
- Agent 需要跨消息记住事情吗?→ 是 → 短时记忆
- 需要用外部文档吗? → 是 → 长时记忆
- 否则 → 大概率不需要
Step 1:用 AI 帮你决定要不要加记忆
I am building an AI agent.My goal:[目标]Does this agent need:1. Conversation memory?2. External knowledge (RAG)?If yes, explain why.If no, explain why not.Keep it simple.
Step 2:你有三个选项
选项 A:不用记忆(先从这里开始)
- 大多数入门者的最佳选择
- 70% 的场景够用
选项 B:对话记忆
- 大多数 SDK 已经处理好了
- 只要别 reset 消息就行
选项 C:基于文件的记忆(简单 RAG)
- 上传文档
- 用文件搜索工具
Step 3:不要用力过猛
大错:
- 上向量数据库
- 上 embeddings
- 上复杂 pipeline
在甚至不知道是否需要之前就上这些。
👉 规则:如果 Agent 不用记忆就能工作 → 别加
6. 让 Agent 跑起来

这是 Agent 做得好不好、能不能用的关键。很多 Agent 做得很烂就是因为:
- prompt 写得差
- 不测试
- 期望不现实
Step 1:用 AI 生成测试用例
I built an AI agent with this goal:[目标]Create 15 realistic user inputs:- messy- vague- real-world styleAlso include:- edge cases- confusing inputs- bad inputs
Step 2:像真实用户那样测试
不要测:
“请分类这个billing请求”
要测:
“why tf did i get charged again”
Step 3:一次只修一件事
失败的时候问:
- prompt 不清楚?
- 输出格式模糊?
- 缺工具?
- 缺规则?
Step 4:用 AI debug 你的 Agent
Here is my agent:Here is what I asked:[input]Here is the output:[output]What went wrong?How do I fix it?Be specific.
Step 5:不要过早搞复杂
在以下条件满足之前,不要加:
- 多个 Agent
- 复杂工作流
- 自动化 pipeline
直到:你的简单版本能稳定工作
7. 多 Agent 协作

这件事很容易让你彻底跑偏。
有人觉得:“多 Agent = 更强”
错。
永远从一个 Agent 开始。
只有在以下情况才加更多:
- 任务明显可拆分
- 一个 Agent 扛不住
- 角色差异很大
需要多 Agent 的三种情况
1. 不同技能
例子:
- 研究 Agent
- 写作 Agent
2. 清晰 pipeline
例子:
- 输入 → 分析 → 写作 → 输出
3. 不同权限
例子:
- 一个 Agent 可以读数据
- 一个 Agent 可以执行动作
用 AI 帮你决定要不要多 Agent
I built an AI agent.Here is its job:[描述]Should this be:1. A single agent2. Multiple agentsIf multiple:- what roles?- why?Keep it simple.
最安全的模式
Supervisor 模式:
用户 → 主 Agent →(需要时调用其他 Agent)
不要一上来就用:
- swarm
- 完全自主的多 Agent 系统
这些很容易坏。
角色保持简单 stupid
❌ 不好:“AI 战略 Agent,带动态认知分层”
✅ 好:
- “研究 Agent”
- “写作 Agent”
慢速加 Agent
从:
- 1 个 Agent
然后:
- 最多 2 个 Agent
只有看到真实好处才扩展。
8. 收尾
这篇文章最重要的结论是:Agent 概念上简单,落地起来却要求很高。 Agent Loop(LLM 思考、调用工具、重复)50 行 Python 代码就能跑完。真正费功夫的是工具设计、错误处理、评估,以及知道什么时候该用更简单的模式(Prompt Chaining、Routing)而不是完全自主的 Agent。
三个可操作的结论
1. 先搭一个从零开始的 Agent
搞懂底层循环之后,每个框架对你来说都是透明的,而不是玄学。debug 问题的速度快得多,选工具也更明智。
2. 用能工作的最简单模式开始
Prompt Chain 能处理大多数多步任务。Routing 能处理大多数分类后执行的工作流。只有当你需要 LLM 动态决定执行路径的时候,才升级到自主 Agent。
3. 及早投资工具设计和评估
好工具的特征:名字清晰、描述精准、错误消息结构化。这三样东西对 Agent 性能的提升,比换模型或换框架有效得多。20 个好的测试用例,比大量人工测试能抓到更多 bug。
这个领域变化很快。MCP 不到一年就成了通用标准,两个大厂都出了 Agent SDK,新框架每月都在冒出来。但这份指南里的基础是稳定的:Agent Loop、五种工作流模式、好工具的设计原则,以及"从简单开始"的纪律。掌握这些,你就能适应接下来出现的一切。
你现在可以搭一个 Agent 了。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献217条内容
已为社区贡献217条内容

所有评论(0)