大模型小白必看!Agent vs Workflow,一文彻底搞懂AI工作流与智能体区别!
本文深入浅出地解析了Agent和Workflow的核心区别,用通俗易懂的语言阐述了大模型在AI工作流与智能体中的应用。简单来说,Workflow是显式控制流,而Agent是隐式决策流,由大模型自主决策。文章通过生动的例子和实战代码,详细介绍了Workflow和Agent的特点、应用场景、优缺点及选择方法,并提供了实用的最佳实践,帮助读者更好地理解和应用AI工作流与智能体技术。

【Agent开发学习&面试训练营】火热进行中,正在找暑期实习或者工作想转行的可丝哈。
本文尽量用清晰易懂的语言来阐述Agent和Workflow的区别,争取让大模型小白也能看得懂。
一句话总结
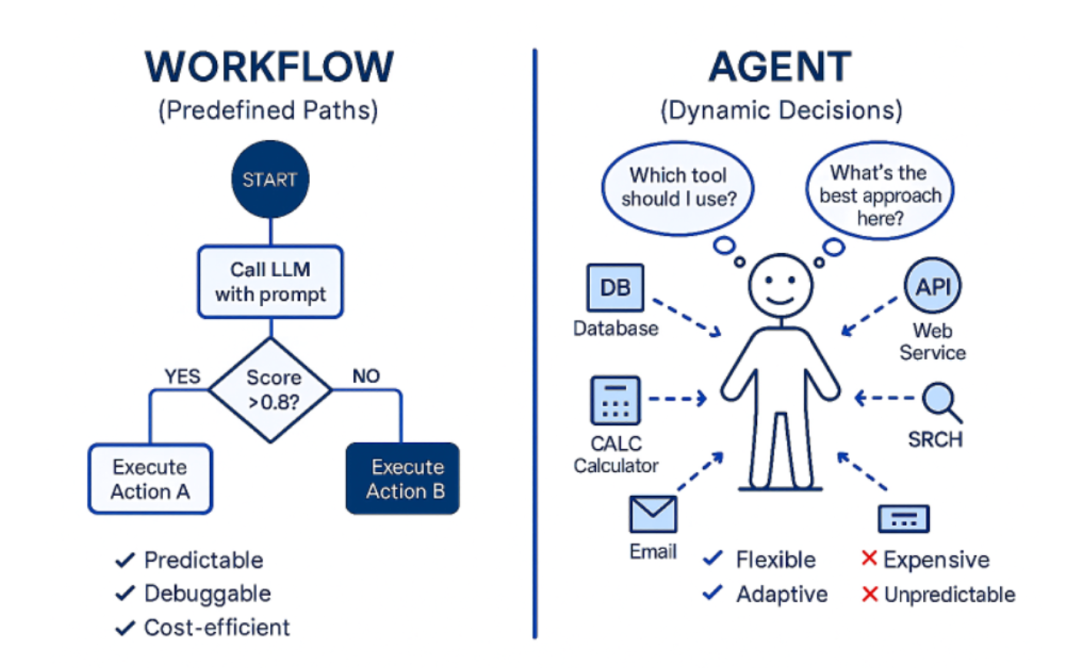
Workflow = 显式控制流 Agent = 隐式决策流(由大模型决定)
IMG_256
举个通俗的例子:
智能体(Agents)就像是你身边那些“有眼力劲儿”的聪明助手,它们能独立思考。面对新状况或预料之外的任务,它们能利用 AI 审时度势、自主决策并采取行动。你可以把它们想象成一位顶级大厨,不管厨房里剩下什么食材,他都能根据现有条件变出一桌大餐。
工作流(Workflows)则更像是一张固定食谱。它由一系列排好序的步骤组成,就像银行审批贷款时的核查清单一样。它非常适合那些一成不变、流程标准化的任务。
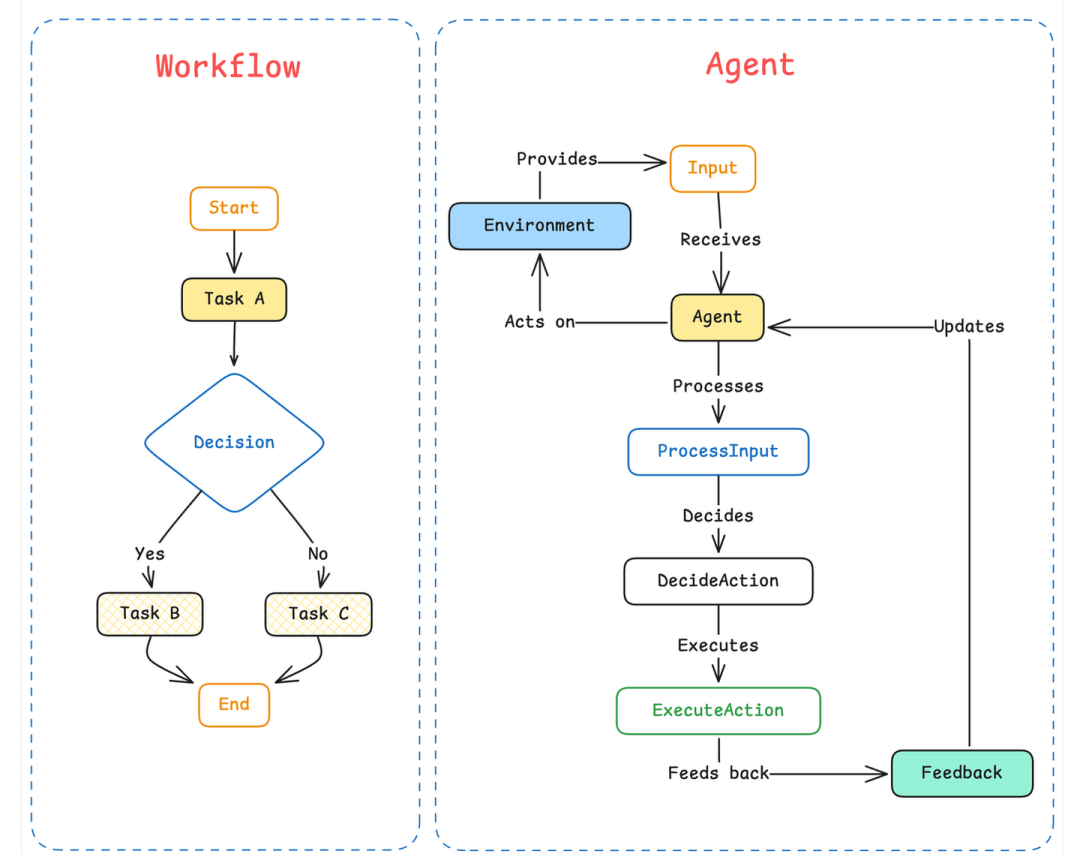
传统经典架构
IMG_257
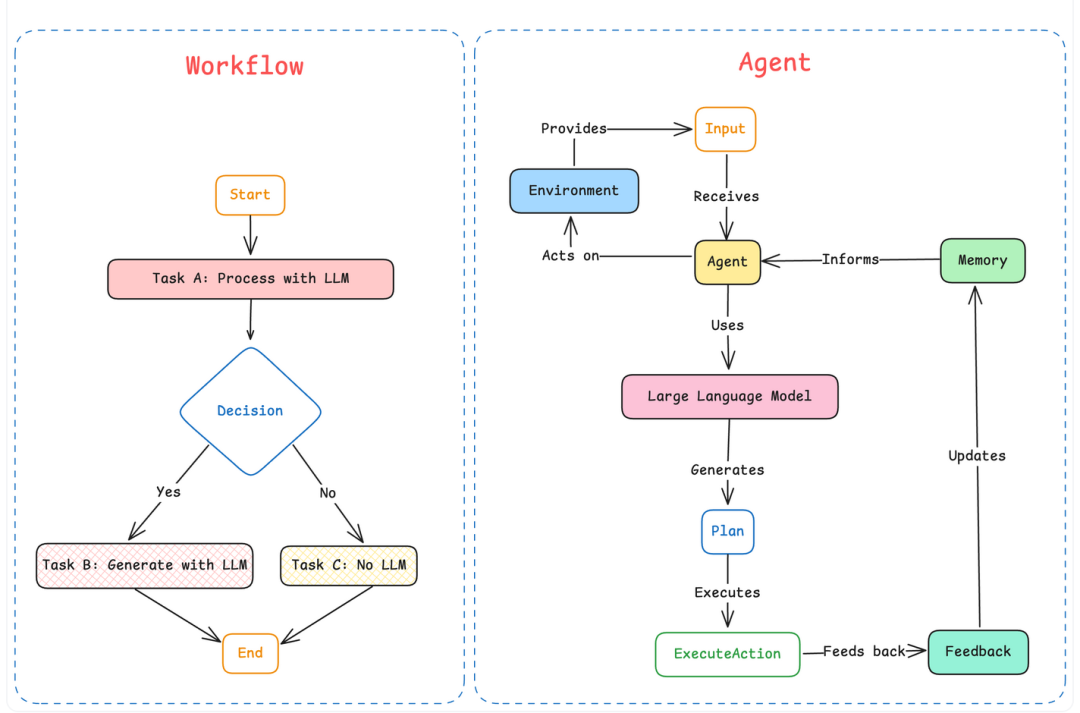
加入大模型的架构
IMG_258
什么是工作流(Workflow)?
本质是按照预定义的步骤执行任务。例如用户在淘宝创建订单,关键流程可以抽象为提前写死的这几个流程:
- 收到订单
- 查库存
- 发通知
- 更新数据库

IMG_259
特点:
- 每一步是确定的
- 顺序固定
- 可预测
- 可审计
典型Workflow模式
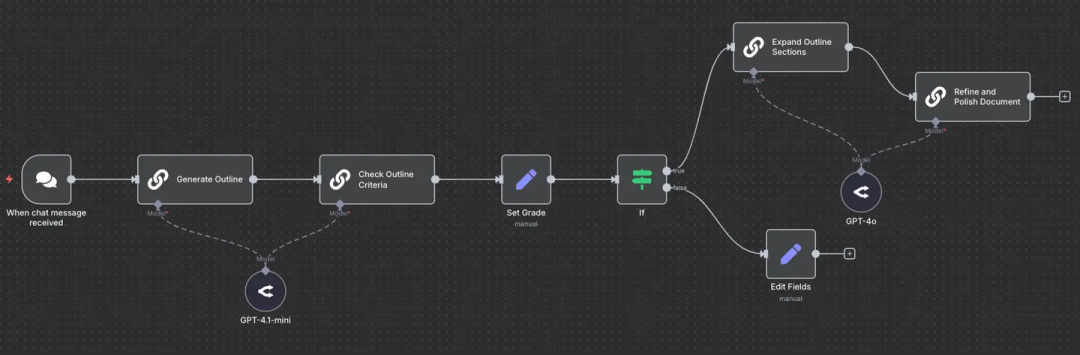
(1)提示词链
IMG_260
上图工作流展示了一种用于文档生成的提示词链(Prompt Chaining)模式。流程从接收到聊天消息开始:
系统首先调用 GPT-4.1-mini 生成初始大纲,随后根据预设标准对其进行校验。通过人工“评分(Set Grade)”步骤评估大纲质量,并由“条件判断(If)”节点根据评分决定后续动作。
- 若大纲通过校验:系统将调用 GPT-4o 对大纲各章节进行扩写,最后对最终文档进行润色和美化。
- 若大纲未通过校验:工作流将跳转至“字段编辑(Edit Fields)”步骤,进行人工调整后再继续执行。
这种设计确保了在多阶段文档创建的全过程中,每一环都有严格的质量控制。
其典型应用场景:
- 内容生成流水线
- 多阶段文档处理
- 顺序校验工作流
实战案例代码
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
# Graph state
class State(TypedDict):
topic: str
joke: str
improved_joke: str
final_joke: str
# Nodes
def generate_joke(state: State):
"""First LLM call to generate initial joke"""
msg = llm.invoke(f"Write a short joke about {state['topic']}")
return {"joke": msg.content}
def check_punchline(state: State):
"""Gate function to check if the joke has a punchline"""
# Simple check - does the joke contain "?" or "!"
if "?" in state["joke"] or "!" in state["joke"]:
return "Pass"
return "Fail"
def improve_joke(state: State):
"""Second LLM call to improve the joke"""
msg = llm.invoke(f"Make this joke funnier by adding wordplay: {state['joke']}")
return {"improved_joke": msg.content}
def polish_joke(state: State):
"""Third LLM call for final polish"""
msg = llm.invoke(f"Add a surprising twist to this joke: {state['improved_joke']}")
return {"final_joke": msg.content}
# Build workflow
workflow = StateGraph(State)
# Add nodes
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke)
workflow.add_node("polish_joke", polish_joke)
# Add edges to connect nodes
workflow.add_edge(START, "generate_joke")
workflow.add_conditional_edges(
"generate_joke", check_punchline, {"Fail": "improve_joke", "Pass": END}
)
workflow.add_edge("improve_joke", "polish_joke")
workflow.add_edge("polish_joke", END)
# Compile
chain = workflow.compile()
# Show workflow
display(Image(chain.get_graph().draw_mermaid_png()))
# Invoke
state = chain.invoke({"topic": "cats"})
print("Initial joke:")
print(state["joke"])
print("\n--- --- ---\n")
if "improved_joke" in state:
print("Improved joke:")
print(state["improved_joke"])
print("\n--- --- ---\n")
print("Final joke:")
print(state["final_joke"])
else:
print("Final joke:")
print(state["joke"])
(2)路由
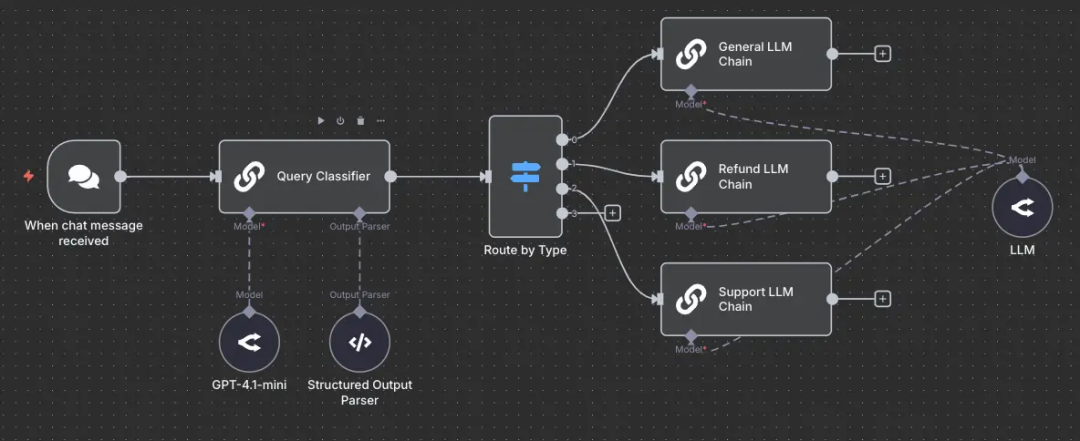
IMG_261
路由(Routing)是指根据查询请求的分类结果,将不同的请求分发给特定的 LLM 链或 Agent(智能体)。
案例:客服系统路由架构
本工作流展示了一个用于客服系统智能分发的路由模式。当系统接收到聊天消息时,首先由基于 GPT-4.1-mini 的“查询分类器”配合“结构化输出解析器”对请求类型进行分类。
根据分类结果,“按类型路由”转换开关(Switch)会将查询分发至三个专业 LLM 链中的一个:
- 通用 LLM 链:处理基础咨询;
- 退款 LLM 链:处理支付相关问题;
- 技术支持 LLM 链:处理技术协助。
这种设计使得每种类型的查询都能获得专业化的处理,同时维持统一的响应体系,从而在客户服务运营中实现准确率与效率的最优平衡。
路由模式(Routing)的应用场景:
- 智能客服系统:根据用户问题类型精准分发。
- 多领域问答系统:针对不同学科或行业领域提供专业解答。
- 请求优先级排序与委派:识别任务紧急程度并进行合理调度。
- 资源优化调度:将不同复杂度的请求分发至最合适的模型进行处理。
核心优势:
- 高效的资源利用:确保计算资源花在刀刃上。
- 专业化处理能力:针对不同类型的查询提供更精准、更深入的响应。
- 极致的成本优化:通过选择性地使用不同等级的模型(如轻量级模型负责分类,高性能模型负责复杂任务),显著降低运营成本。
实战案例代码
from typing_extensions import Literal
from langchain.messages import HumanMessage, SystemMessage
# Schema for structured output to use as routing logic
class Route(BaseModel):
step: Literal["poem", "story", "joke"] = Field(
None, description="The next step in the routing process"
)
# Augment the LLM with schema for structured output
router = llm.with_structured_output(Route)
# State
class State(TypedDict):
input: str
decision: str
output: str
# Nodes
def llm_call_1(state: State):
"""Write a story"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_2(state: State):
"""Write a joke"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_3(state: State):
"""Write a poem"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_router(state: State):
"""Route the input to the appropriate node"""
# Run the augmented LLM with structured output to serve as routing logic
decision = router.invoke(
[
SystemMessage(
content="Route the input to story, joke, or poem based on the user's request."
),
HumanMessage(content=state["input"]),
]
)
return {"decision": decision.step}
# Conditional edge function to route to the appropriate node
def route_decision(state: State):
# Return the node name you want to visit next
if state["decision"] == "story":
return "llm_call_1"
elif state["decision"] == "joke":
return "llm_call_2"
elif state["decision"] == "poem":
return "llm_call_3"
# Build workflow
router_builder = StateGraph(State)
# Add nodes
router_builder.add_node("llm_call_1", llm_call_1)
router_builder.add_node("llm_call_2", llm_call_2)
router_builder.add_node("llm_call_3", llm_call_3)
router_builder.add_node("llm_call_router", llm_call_router)
# Add edges to connect nodes
router_builder.add_edge(START, "llm_call_router")
router_builder.add_conditional_edges(
"llm_call_router",
route_decision,
{ # Name returned by route_decision : Name of next node to visit
"llm_call_1": "llm_call_1",
"llm_call_2": "llm_call_2",
"llm_call_3": "llm_call_3",
},
)
router_builder.add_edge("llm_call_1", END)
router_builder.add_edge("llm_call_2", END)
router_builder.add_edge("llm_call_3", END)
# Compile workflow
router_workflow = router_builder.compile()
# Show the workflow
display(Image(router_workflow.get_graph().draw_mermaid_png()))
# Invoke
state = router_workflow.invoke({"input": "Write me a joke about cats"})
print(state["output"])
(3)并行化
并行化(Parallelization)通过同时执行多个相互独立的 LLM 操作,从而大幅提升系统的运行效率。
案例:内容安全审核流水线
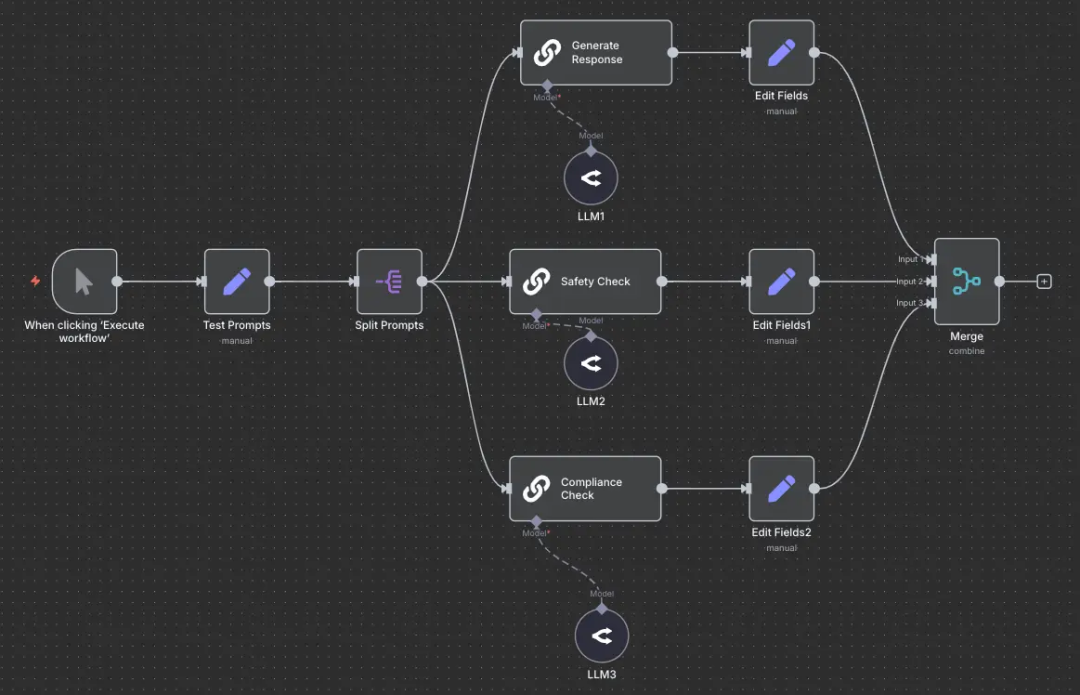
IMG_262
并行化应用场景:
- 内容审核系统:同时对文本进行涉黄、涉政、暴力等多维度的违规检测。
- 多准则评估:从逻辑性、文采、事实准确性等多个维度并行打分。
- 并发数据处理:大规模语料的并行清洗、总结或结构化提取。
- 独立验证任务:多个模型同时对一个答案进行背对背验证,以确保可靠性。
核心优势:
- 降低延迟(Reduced Latency):通过并发执行,将多个任务的总耗时从“各项之和”降低到“最慢的一项”。
- 优化资源利用:最大化利用 API 频率限制(Rate Limits)或算力集群。
- 提升吞吐量:在单位时间内处理更高规模的请求。
实战案例代码
# Graph state
class State(TypedDict):
topic: str
joke: str
story: str
poem: str
combined_output: str
# Nodes
def call_llm_1(state: State):
"""First LLM call to generate initial joke"""
msg = llm.invoke(f"Write a joke about {state['topic']}")
return {"joke": msg.content}
def call_llm_2(state: State):
"""Second LLM call to generate story"""
msg = llm.invoke(f"Write a story about {state['topic']}")
return {"story": msg.content}
def call_llm_3(state: State):
"""Third LLM call to generate poem"""
msg = llm.invoke(f"Write a poem about {state['topic']}")
return {"poem": msg.content}
def aggregator(state: State):
"""Combine the joke, story and poem into a single output"""
combined = f"Here's a story, joke, and poem about {state['topic']}!\n\n"
combined += f"STORY:\n{state['story']}\n\n"
combined += f"JOKE:\n{state['joke']}\n\n"
combined += f"POEM:\n{state['poem']}"
return {"combined_output": combined}
# Build workflow
parallel_builder = StateGraph(State)
# Add nodes
parallel_builder.add_node("call_llm_1", call_llm_1)
parallel_builder.add_node("call_llm_2", call_llm_2)
parallel_builder.add_node("call_llm_3", call_llm_3)
parallel_builder.add_node("aggregator", aggregator)
# Add edges to connect nodes
parallel_builder.add_edge(START, "call_llm_1")
parallel_builder.add_edge(START, "call_llm_2")
parallel_builder.add_edge(START, "call_llm_3")
parallel_builder.add_edge("call_llm_1", "aggregator")
parallel_builder.add_edge("call_llm_2", "aggregator")
parallel_builder.add_edge("call_llm_3", "aggregator")
parallel_builder.add_edge("aggregator", END)
parallel_workflow = parallel_builder.compile()
# Show workflow
display(Image(parallel_workflow.get_graph().draw_mermaid_png()))
# Invoke
state = parallel_workflow.invoke({"topic": "cats"})
print(state["combined_output"])
Workflow的优缺点
优点:
- 稳定
- 易调试
- 易监控
- 成本可控
- 可严格权限管理
缺点:
- 不灵活
- 不能处理复杂未知场景
- 逻辑一多就爆炸式增长
什么是Agent?
AI Agent(智能体)是一种由大模型(LLM)动态驱动自身流程和工具调用的系统,它们在执行任务的过程中,能够始终保持对任务达成路径的自主控制权。 将大语言模型(LLM)与自主决策能力相结合,使其能够通过推理、反思和动态工具调用来完成复杂的任务。
它不是按固定步骤执行,而是:
- 理解目标
- 决定是否调用工具
- 决定调用哪个工具
- 决定是否继续推理
- 决定何时结束
其决策流程图:
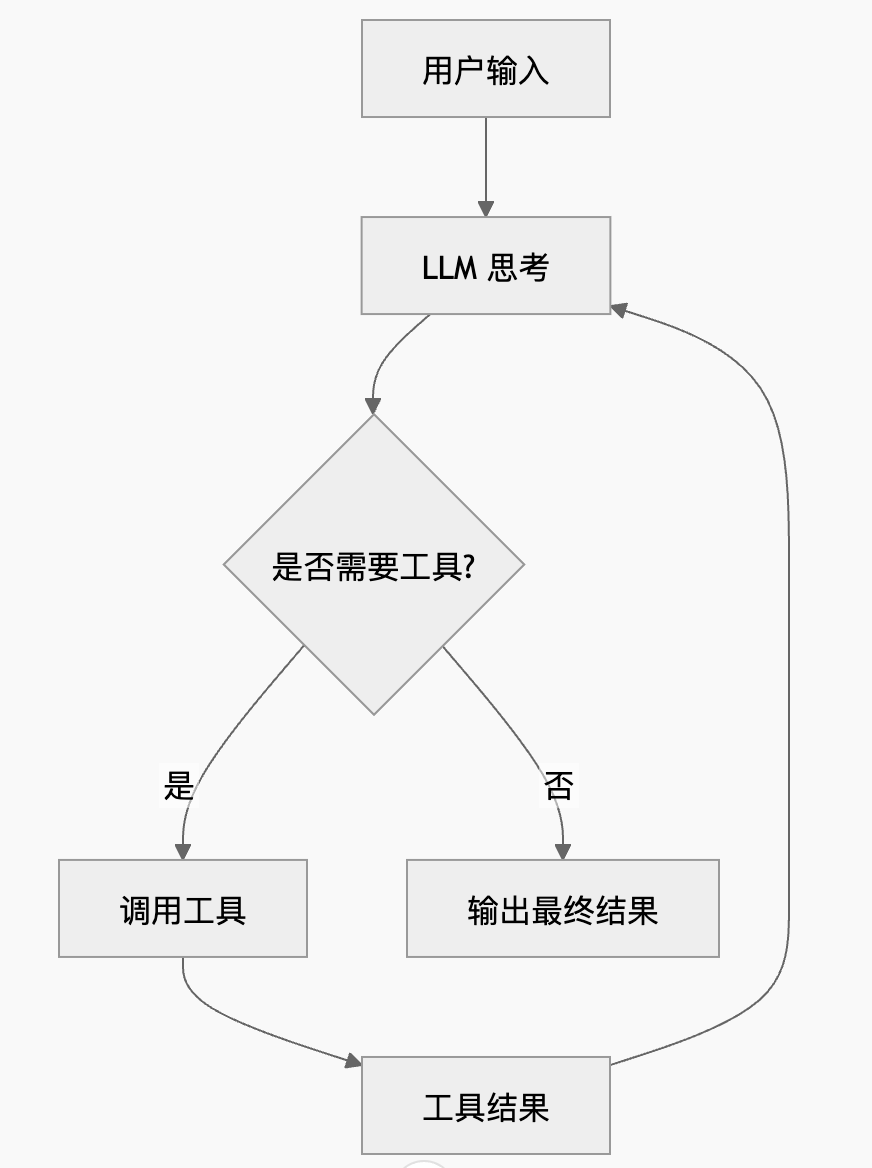
IMG_263
可以看到,Agent 是一个循环结构,它不断思考 → 行动 → 再思考。
案例:任务规划智能体(Task Planning Agent)
场景:用户要求“帮我预约明天下午 2 点和 John 的会议”。
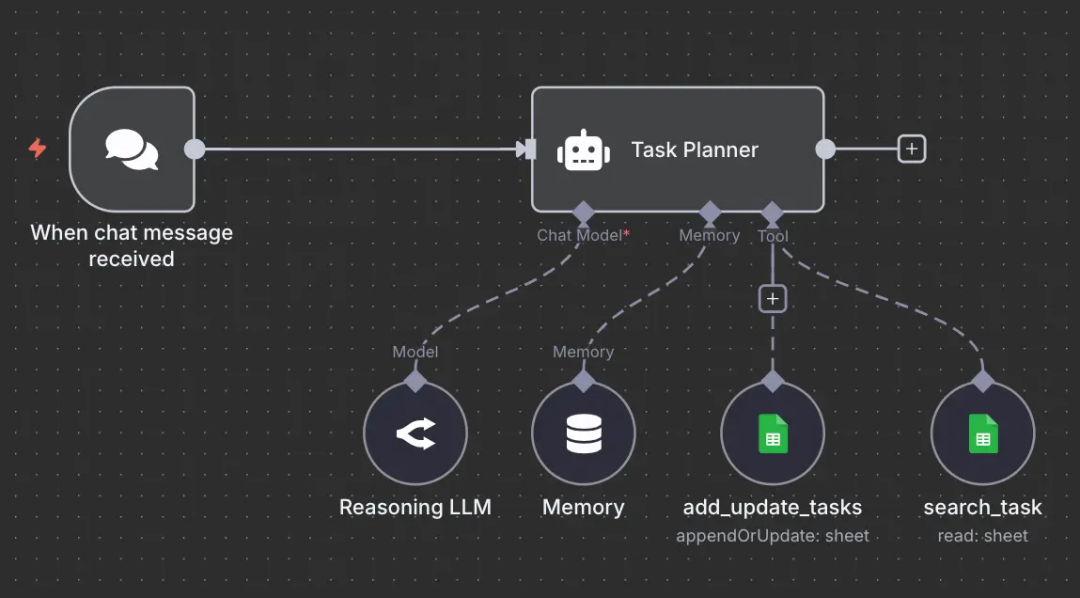
IMG_264
本工作流展示了一个具备动态决策能力的自主任务规划智能体。当接收到聊天消息时,请求会被路由至该 Agent,它拥有三个核心能力的访问权限:用于理解与规划的聊天模型(推理型 LLM)、用于维持跨对话上下文的记忆系统(Memory),以及工具集(Tool collection)。
该 Agent 可以自主从多个工具中进行选择,包括:add_update_tasks(用于在 Google 表格中添加或更新任务)和 search_task(用于读取和搜索表格中的现有任务)。与预设好的工作流不同,Agent 会根据用户的需求,独立判断使用哪些工具、何时使用以及按何种顺序使用。这充分体现了 AI Agent 区别于传统 AI 工作流的灵活性与自主性。
注意:Agent 根据请求的上下文决定使用哪些工具以及执行顺序,而不是依赖于预设的规则。
AI Agent 应用场景:
深度研究系统:全网搜集资料并生成深度报告。
Agentic RAG(智能体化 RAG):具备多步检索与自我修正能力的知识库系统。
- 编程助手:自主编写、运行并调试代码。
- 数据分析与处理:自动清理数据并生成洞察。
- 内容创作与编辑:从大纲到初稿再到润色的全生命周期管理。
- 客户支持与辅助:处理复杂的售后逻辑。
- 交互式聊天机器人与虚拟助理:提供更具人性化和逻辑性的对话体验。
核心组件: 构建 AI Agent 的四个关键支柱:
- 工具访问(Tool Access):与外部系统(如 Google 表格、搜索 API、数据库)的集成能力。
- 记忆(Memory):跨对话保留上下文,确保交互的连贯性。
- 推理引擎(Reasoning Engine):用于工具选择和任务规划的决策逻辑。
- 自主性(Autonomy):无需预设控制流,实现自驱动执行。
实战案例代码
from langchain.tools import tool
# Define tools
@tool
def multiply(a: int, b: int) -> int:
"""Multiply `a` and `b`.
Args:
a: First int
b: Second int
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Adds `a` and `b`.
Args:
a: First int
b: Second int
"""
return a + b
@tool
def divide(a: int, b: int) -> float:
"""Divide `a` and `b`.
Args:
a: First int
b: Second int
"""
return a / b
# Augment the LLM with tools
tools = [add, multiply, divide]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)
from langgraph.graph import MessagesState
from langchain.messages import SystemMessage, HumanMessage, ToolMessage
# Nodes
def llm_call(state: MessagesState):
"""LLM decides whether to call a tool or not"""
return {
"messages": [
llm_with_tools.invoke(
[
SystemMessage(
content="You are a helpful assistant tasked with performing arithmetic on a set of inputs."
)
]
+ state["messages"]
)
]
}
def tool_node(state: dict):
"""Performs the tool call"""
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))
return {"messages": result}
# Conditional edge function to route to the tool node or end based upon whether the LLM made a tool call
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
"""Decide if we should continue the loop or stop based upon whether the LLM made a tool call"""
messages = state["messages"]
last_message = messages[-1]
# If the LLM makes a tool call, then perform an action
if last_message.tool_calls:
return "tool_node"
# Otherwise, we stop (reply to the user)
return END
# Build workflow
agent_builder = StateGraph(MessagesState)
# Add nodes
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("tool_node", tool_node)
# Add edges to connect nodes
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
["tool_node", END]
)
agent_builder.add_edge("tool_node", "llm_call")
# Compile the agent
agent = agent_builder.compile()
# Show the agent
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
# Invoke
messages = [HumanMessage(content="Add 3 and 4.")]
messages = agent.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()
二者核心差异对比
一图可看清二者的核心差异:

IMG_265
如何选择
工程化的第一原则是:能用 Workflow 解决的,绝不用 Agent。因为稳定和省钱是商业化落地的前提;但当业务进入‘无人区’或需要处理极端复杂的长尾需求时,Agent 才是那个能破局的‘聪明大脑’。
在以下场景下,选择 AI 工作流(Workflows):
- 任务需求清晰且稳定:每一步要做什么非常明确。
- 可预测性至关重要:需要系统输出的结果高度一致、可控。
- 需要对执行过程进行显式控制:必须严格按照预设步骤运行。
- 调试与监控是首要任务:方便快速定位哪一步出了问题。
- 成本管理极其关键:通过固定路径最大化降低 Token 消耗。
在以下场景下,选择 AI 智能体(Agents):
- 任务是开放式或探索性的:没有标准的固定操作流程。
- 灵活性比可预测性更重要:需要系统能根据不同情况“见招拆招”。
- 问题空间复杂且变量众多:无法用简单的 if-else 逻辑覆盖全场景。
- 需要类人化的推理能力:依赖模型进行深度思考和逻辑判断。
- 需要适应不断变化的环境:任务过程中可能出现预料之外的新状况。
当然也有混合使用的情况:
许多生产级系统实际上是两种方案的结合体:
- 以工作流为骨架(Structure):利用工作流处理可靠、定义明确的任务组件。
- 以智能体为血肉(Flexibility):在需要适应性强、复杂决策的环节部署 Agent。
案例:先通过一个工作流将请求路由至不同的专业 Agent,再由这些 Agent 独立处理开放式的子任务。
一些最佳实践
关于AI 工作流(Workflows)的实践总结
- 清晰的步骤定义:记录并定义工作流中的每一个阶段。
- 错误处理机制:为可能出现的失败环节实现回退路径(Fallback paths)。
- 验证关卡(Validation Gates):在关键步骤之间增设校验环节。
- 性能监控:追踪每一步的延迟情况以及任务成功率。
关于AI 智能体(Agents)的实践总结
- 工具设计:提供描述清晰、文档完整且用途明确的工具集。
- 记忆管理:实施有效的上下文保留策略,确保信息连贯。
- 护栏机制(Guardrails):为 Agent 的行为准则和工具使用权限设定边界。
- 可观测性:详细记录 Agent 的推理过程(Reasoning)和决策路径。
- 迭代测试:在各类复杂场景下持续评估 Agent 的表现。
关于护栏和可观测性恰恰是区分demo项目和企业级应用的分水岭,大家在简历上写项目描述的时候一定要特别注意,这样才能凸显自己的优势。
- 关于护栏(Guardrails): “Agent 就像一个拥有超能力的员工,如果你不给它设定边界(比如限制 API 调用次数、限制数据库访问范围),它可能会因为陷入逻辑死循环而刷爆你的信用卡,或者误删重要数据。”
- 关于可观测性(Observability): “Agent 的决策过程往往是个黑盒。我们需要像记录日志一样,把模型的 Thought(思考)、Action(行动) 和 Observation(观察) 全部记录下来。只有这样,当 Agent 报错时,我们才能知道它是‘想歪了’还是‘找错工具了’。”
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)