测评 ASR 歌词生成模型
1. 测评背景与目标
业务需求: 目前有大批量的 MP3 音频需要匹配歌词。网络公开渠道能爬取到的歌词占比不足 50%,因此必须采用 ASR(自动语音识别)生成模式来补全缺口。
核心痛点: 现有的商业 API 调用成本较高,且在带伴奏的音乐场景下准确性一般。需要探索并验证一套低成本、高准确性的替代方案。
2. 测评对象与参考标准
参测模型:
- whisper-large-v3 (开源本地部署)
- Qwen3-ASR-1.7B (开源本地部署)
- whisper-1 (OpenAI 商业 API)
参考榜单:
榜单数据多基于日常讲话测试,相对唱歌(带复杂背景音)来说更容易识别,因此榜单标称的 WER(词错误率)通常会低于本次音乐测评的实际表现。
- HuggingFace Open ASR Leaderboard:
https://huggingface.co/spaces/hf-audio/open_asr_leaderboard - VoiceWriter Leaderboard:
https://voicewriter.io/speech-recognition-leaderboard1
3. 测评环境与准备工作
硬件与平台
云服务商: 阿里云 DSW (https://pai.console.aliyun.com)
实例配置: ecs.gn7i-c8g1.2xlarge (8 vCPU, 30 GiB 内存, NVIDIA A10 * 1)
基础镜像: dsw-registry-vpc.cn-guangzhou.cr.aliyuncs.com/pai/modelscope:1.35.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
基础环境与全局变量配置
为了保障国内网络环境下 HuggingFace 的连通性,并确保模型与密钥正确保存在 DSW 的永久目录 (/mnt/workspace),需配置以下环境变量及 Git:
# Git 初始化与 SSH 配置
apt update && apt install git -y
git config --global user.name "你的名字"
git config --global user.email "xxx@qq.com"
git config --global color.ui true
mkdir -p /mnt/workspace/.ssh_backup
ssh-keygen -t ed25519 -C "xxx@qq.com" -f /mnt/workspace/.ssh_backup/id_ed25519
mkdir -p ~/.ssh
ln -sf /mnt/workspace/.ssh_backup/id_ed25519.pub ~/.ssh/id_ed25519.pub
chmod 700 ~/.ssh
chmod 600 ~/.ssh/id_ed25519
chmod 644 ~/.ssh/id_ed25519.pub
ssh -T git@github.com
# 环境变量配置
export HF_ENDPOINT=https://hf-mirror.com
export HF_HOME=/mnt/workspace/huggingface_cache
export TORCH_HOME=/mnt/workspace/torch_cache
export XDG_CACHE_HOME=/mnt/workspace/general_cache
export DEMUCS_REPO=/mnt/workspace/demucs_models
依赖安装与冲突解决
预装镜像缺失部分音频处理模型(如 Demucs),且存在版本冲突,需通过以下脚本进行修正:
# 1. 安装系统级音频依赖
sudo apt-get update && sudo apt-get install -y ffmpeg
# 2. 安装核心算法库(推荐使用阿里云内网源加速)
pip install jiwer demucs -i http://mirrors.cloud.aliyuncs.com/pypi/simple/ --trusted-host mirrors.cloud.aliyuncs.com
pip install whisperx==3.1.1 -i http://mirrors.cloud.aliyuncs.com/pypi/simple/ --trusted-host mirrors.cloud.aliyuncs.com
# 3. 解决 NumPy 与 SciPy 版本冲突
pip install "numpy<2.0.0" "scipy<1.13.0" -i http://mirrors.cloud.aliyuncs.com/pypi/simple/ --trusted-host mirrors.cloud.aliyuncs.com
# 4. 解决 Lightning 与 Transformers 冲突
pip uninstall -y lightning pytorch-lightning lightning-fabric
pip install "lightning==2.1.4" "pytorch-lightning==2.1.4" "lightning-fabric==2.1.4" -i http://mirrors.cloud.aliyuncs.com/pypi/simple/ --trusted-host mirrors.cloud.aliyuncs.com
pip install "transformers==4.45.2"
# 5. Qwen3-ASR 依赖安装
git clone https://github.com/QwenLM/Qwen3-ASR.git
pip install -e ./Qwen3-ASR
4. 测评执行过程
脚本地址:https://github.com/hanjg/agent_test/
数据准备:
选用 HuggingFace 的 JamendoLyrics 数据集。执行下载脚本(注:部分模型需鉴权,请务必携带 HF_TOKEN 以防限流)。
HF_TOKEN=xxx python asr_download_jamendolyrics.py
开源模型测评 (本地部署):
对下载的 WAV 文件进行人声分离、压缩,随后调用本地 ASR 模型提取时间戳。将提取出的文本进行归一化后与测试集基准对比,计算 MER 等指标。
HF_TOKEN=xxx python asr_eval.py --model whisper-large-v3 --vocal-separation --compress --vad-onset 0.300 --vad-offset 0.200
闭源模型测评 (API 调用):
使用已完成人声分离和压缩的音频请求 OpenAI API,获取返回的时间戳与文本,执行相同的归一化与对比逻辑。(代码示例如下,具体脚本请使用 asr_compare_words.py)
HF_TOKEN=xxx python asr_eval.py --model whisper-large-v3 --vocal-separation --compress --vad-onset 0.300 --vad-offset 0.200
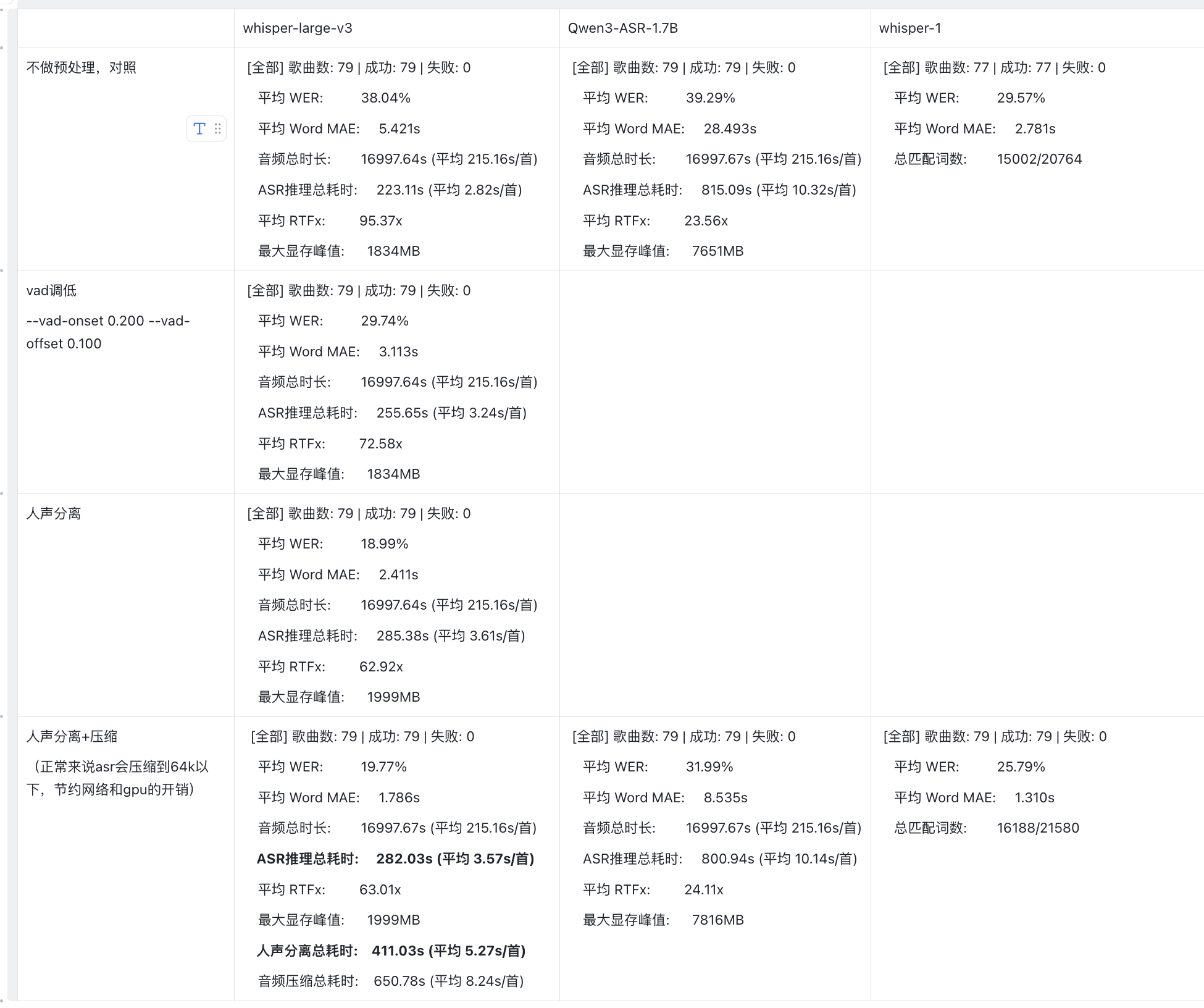
5. 测评结论
Round 1 初步结论
| 评估维度 | 结果分析 |
|---|---|
| 模型综合效果 | Whisper-large-v3 表现最优:相较于商业版 Whisper-1,成本仅为其 12%,WER(词错误率)降低 24%,WAE 提高 36%。 Qwen3-ASR-1.7B 表现欠佳:虽在日常交流中表现良好,但在音乐领域显存占用大且识别率低。 |
| 成本估算 | 本地大模型极具性价比。 本地部署 Whisper-large-v3 处理单首歌曲约需 8.628 秒,按 GPU $1/小时计算,成本约 0.0167元/首。而调用 Whisper-1 API 处理同等规模数据(约21万首),总成本需 $5284,折合 0.1747元/首。 |
| 预处理影响 | 人声分离能极其显著地降低 WER;而将音频压缩至 64k 对最终识别结果的影响微乎其微,可用于节省存储与传输带宽。 |
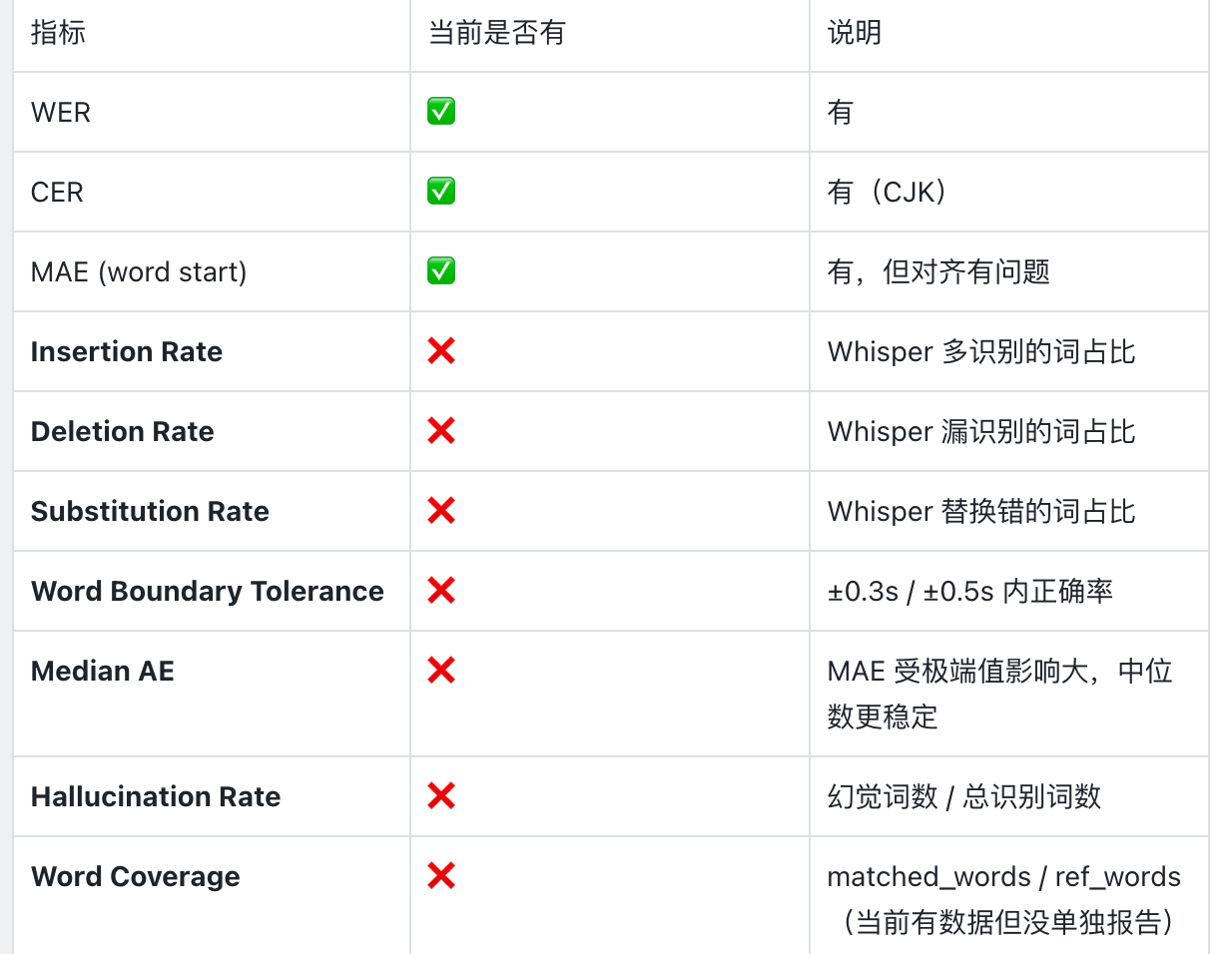
Round 2 归一化与对齐优化
在排查 Round 1 数据时,AI 分析发现原有测评代码在计算 WER 和 MAE 时存在严重的归一化与对齐缺陷(如:多语言哼唱词漏过滤、连写拟声词拆分导致误判、SequenceMatcher 跨段对齐错位、以及未剥离 Whisper 的幻觉文字等)。
针对上述问题,我们在 Round 2 中进行了如下工程优化:
- 引入 DTW (Dynamic Time Warping) 对齐替代 SequenceMatcher,彻底解决重复副歌导致的跨段错配与 MAE 虚高现象。
- 统一双端 Filler / 哼唱词处理规则(正则匹配 + 连写拟声词拆分)。
- 增加幻觉文字检测与剥离逻辑(如自动过滤无中生有的 “Thank you”、“Untertitelung” 等)。
- 丰富测评维度,新增 S/I/D Rate、Median AE 以及 Word Boundary Tolerance (±0.3s/±0.5s)。
最终结论: 在开启人声分离的前提下,Whisper-large-v3 的 WER 和 MAE 均显著优于商业版 Whisper-1,且 MAE 指标已完全达到 KTV 滚动歌词的标准要求。
| 补充指标 | 详细数据 |
|---|---|
 |
 |
6. 附:业界与打榜平台 ASR 测评标准
为了确保测评的严谨性,业界标准的 ASR 模型测评通常会严格遵循以下四个维度的考量:
多维度的数据集矩阵 (Diverse Datasets)
测评不会依赖单一测试集,通常会组合使用有声书 (LibriSpeech)、电话会议 (Switchboard)、日常对话 (Common Voice)、带噪环境以及多语种 (FLEURS) 数据集,以全面压测模型的泛化能力。
严谨的文本归一化 (Text Normalization)
在对比标签前,必须对预测文本和真实标签 (Ground Truth) 进行深度清洗。包括:统一转小写、去除标点符号、统一数字形态(如 “100” 统一为 “one hundred”)、以及简繁体转换等。否则计算出的 WER 将包含大量“假错误”。
标准的量化指标 (Standardized Metrics)
文本准确率主要使用 WER (Word Error Rate,针对英文) 或 CER (Character Error Rate,针对中文)。时间戳准确率则计算预测与真实的 MAE (平均绝对误差);或设定一个时间容忍窗口(例如 < 50ms 视为准确),进而计算 Precision、Recall 和 F1 Score。
工程性能评估 (Performance Metrics)
除准确度外,模型吞吐量同样关键。业界必然会测量 RTF (Real-Time Factor,处理 1 秒音频所需的秒数) 以及 VRAM (峰值显存占用),以此来评估工程部署的真实成本。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)