从零构建一站式求职自动化平台
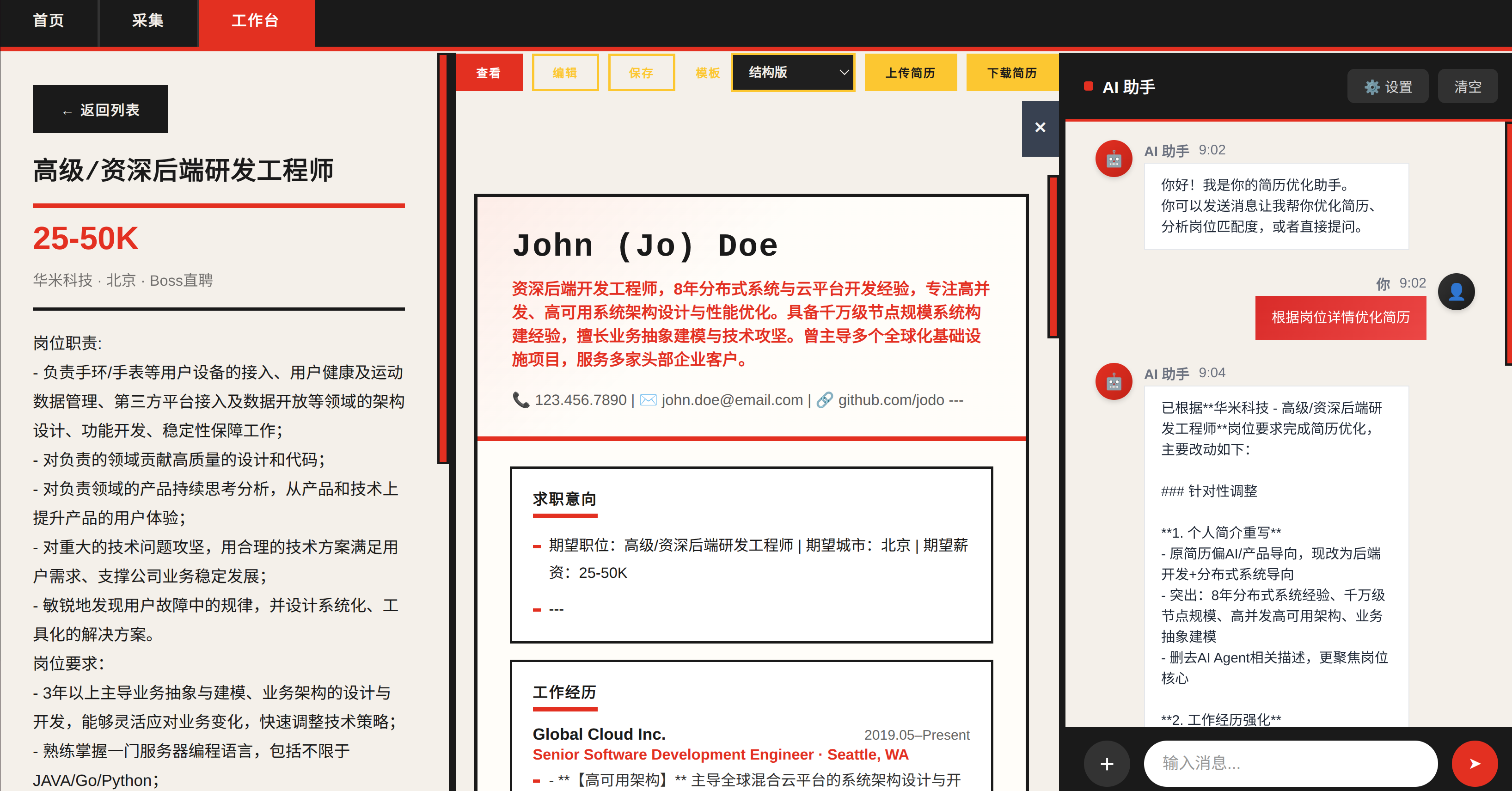
岗位采集 · 简历管理 · AI 助手 —— 一个 Chrome 扩展搞定求职全流程
背景
找工作是一件重复性极高的事:打开招聘网站 → 搜索岗位 → 逐条查看 → 修改简历 → 投递 → 等反馈。每个环节都有大量手工操作。
作为一个追求效率的开发者,我决定把这个流程自动化。经过两周的开发,做出了 招聘工作台 (JobHunter) —— 一个基于 Chrome 扩展的求职全流程工具。
GitHub: https://github.com/xixiluo95/zhaopin
技术架构
整体设计
┌─────────────┐ SSE ┌──────────────┐ API ┌──────────────┐
│ Chrome 扩展 │◄────────────►│ Node.js 后端 │◄─────────►│ LLM API │
│ (MV3) │ │ (Express) │ │ (多模型兼容) │
└──────┬───────┘ └──────┬────────┘ └──────────────┘
│ Content Script │ SQLite
▼ ▼
┌─────────────┐ ┌──────────────┐
│ 招聘平台 │ │ 本地数据库 │
│ Boss / 51Job │ │ (jobs/resume) │
└─────────────┘ └──────────────┘-
前端:Chrome MV3 扩展,纯 Vanilla JS(~5000 行 dashboard.js),无框架依赖
-
后端:Node.js + Express,端口 7893,30+ API 端点
-
数据库:SQLite,通过 better-sqlite3 同步操作
-
AI:OpenAI 兼容协议,支持 8+ 模型供应商
为什么选择 Chrome 扩展?
-
天然访问招聘网站:Content Script 可以注入到 Boss 直聘页面,直接操作 DOM
-
无需代理/模拟:利用用户已登录的 Cookie 发起 API 请求,不需要额外的登录模拟
-
统一工作台:Dashboard 页面作为独立 Tab,既是简历编辑器也是 AI 助手
核心模块
-
岗位采集引擎
这是整个项目中最有挑战性的部分。Boss 直聘有较强的反爬机制,直接高频请求很快会被封。
V2 缓冲策略
经过多次被封的教训,最终设计了一套策略轮转 + 缓冲采集机制:
策略池:
1. buffer-large pageSize=30,缓冲后分批处理详情
2. buffer-medium pageSize=15,中等粒度
3. sequential pageSize=3,保守模式
触发反爬 → 记录断点 → 冷却等待 → 切换下一策略 → 续跑核心思路是列表请求和详情请求分离:
-
列表接口用大 pageSize 一次拿多个岗位 ID
-
本地维护 pendingBuffer
-
详情接口每次只处理 3 条,间隔 8-11 秒随机延时
-
Buffer 用完再翻下一页列表
这样做的好处是减少了列表 API 的调用次数,而列表 API 恰恰是 Boss 反爬最敏感的接口。
去重策略
三级去重,确保不重复抓取:
-
encryptJobId—— Boss 接口返回的加密唯一 ID -
securityId—— 备用唯一标识 -
title + company + salary组合哈希 —— 兜底
-
简历管理
6 套模板引擎
没有使用模板框架,而是纯 JS 生成 HTML。每个模板定义自己的 CSS 变量和布局规则:
const RESUME_TEMPLATES = {
structured: { name: '经典', primaryColor: '#2563eb', ... },
timeline: { name: '时间线', primaryColor: '#059669', ... },
modern: { name: '现代', primaryColor: '#7c3aed', ... },
classic: { name: '传统', primaryColor: '#1e40af', ... },
compact: { name: '紧凑', primaryColor: '#dc2626', ... },
elegant: { name: '优雅', primaryColor: '#0d9488', ... },
};DOCX 解析
用 mammoth.js 将 Word 文档转为 HTML,再通过自定义解析器提取结构化数据(教育经历、工作经验、技能等)。
PDF 导出
通过后端 Puppeteer 渲染 HTML 为 PDF。关键在于 CSS 分页控制:
-
page-break-inside: avoid只用在小元素上(entry 级别) -
section 级别用
auto,避免大段空白 -
overflow: visible而非hidden,防止内容被裁切
-
AI 助手
结构化编辑协议
最初 AI 编辑简历的方式是全量替换 Markdown,但这会导致格式丢失和内容污染。后来改为 resume_ops 协议:
{
"tool": "update_resume_ops",
"args": {
"resume_ops": [
{ "op": "resume_update_node", "path": "experience.0.items.1", "value": "..." },
{ "op": "resume_set_field", "field": "headline", "value": "..." }
]
}
}AI 发出结构化操作指令,前端逐条应用到简历数据模型上,实现精准修改而非全量覆盖。
多模型支持
所有 AI 服务商通过 OpenAI 兼容协议接入:
// llm-factory.jsfunction createLLMClient(provider, config) {
// 智谱、Kimi、DeepSeek、豆包、Groq、SiliconFlow...// 全部走 OpenAI 兼容接口return new OpenAICompatibleProvider(config);
}用户只需在设置中填入 API 地址、Key 和模型名,无需关心底层差异。
SSE 流式输出
AI 回复通过 Server-Sent Events 实时推送到前端,实现打字机效果:
POST /ai/chat → SSE 连接
→ [token] [token] [token]...
→ [tool_call: update_resume_ops]
→ [done]深度思考内容在 <think> 标签中传输,前端自动折叠显示。
踩过的坑
-
Boss 反爬 code 37
把列表 pageSize 设为 3 后,为了拿 18 条岗位需要连续请求 7 次列表 API,第 7 次就触发了反爬。解决方案:列表用大 pageSize,详情用小批次。
-
Markdown 渲染残留
AI 返回的内容可能包含 加粗、# 标题 等 Markdown 语法,在简历中显示为原始字符。解决方案:在数据入库和渲染前各加一层 sanitize 函数。
-
PDF 分页空白
page-break-inside: avoid 用在大段落上会导致整段跳到下一页,留下大片空白。正确做法是只在小元素(entry 级别)上使用。
-
配置源冲突
启动时显示 MAX_LIST_PAGE_SIZE=3,controller 同步显示 30,实际运行又是 3。两套配置源没有统一。解决方案:启动时打印 resolved config,全程只用这一份。
项目数据
| 指标 | 数据 |
| 代码量 | ~12,000 行 |
| 后端端点 | 30+ |
| AI 模型 | 8 种 |
| 简历模板 | 6 套 |
| 采集平台 | Boss 直聘 + 51Job |
| 开发周期 | ~2周 |
安装使用
git clone https://github.com/xixiluo95/zhaopin.git
cd zhaopin && bash scripts/install.sh
cd controller && node server.js
# Chrome → chrome://extensions → 加载 crawler/extension/详细说明见 README。
总结
这个项目从个人需求出发,解决的是每个求职者都会遇到的效率问题。技术栈虽然不复杂(Chrome 扩展 + Node.js + SQLite),但在反爬策略、AI 编辑协议、PDF 渲染这些细节上有不少值得分享的经验。
如果你也在找工作,欢迎试用和 Star ⭐

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)