LangChain-AI应用开发框架(五)
目录
一.聊天模型核心能力
1. 定义聊天模型

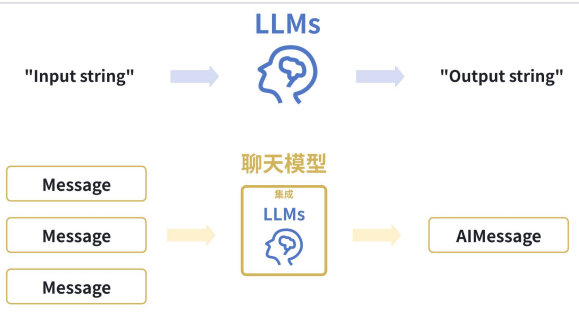
智谱AI开放平台(我们现在暂时是用的是我们国内的智慧谱)
a.通过API定义聊天模型


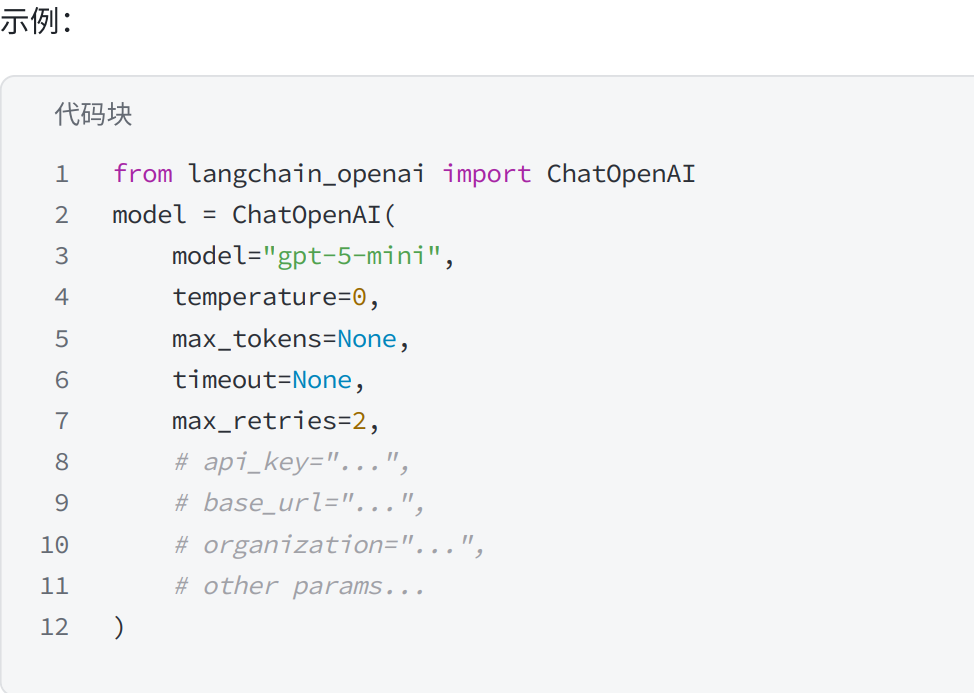
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-5-mini",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# api_key="...",
# base_url="...",
# organization="...",
# other params...
)字段说明:

from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableSequence
import os
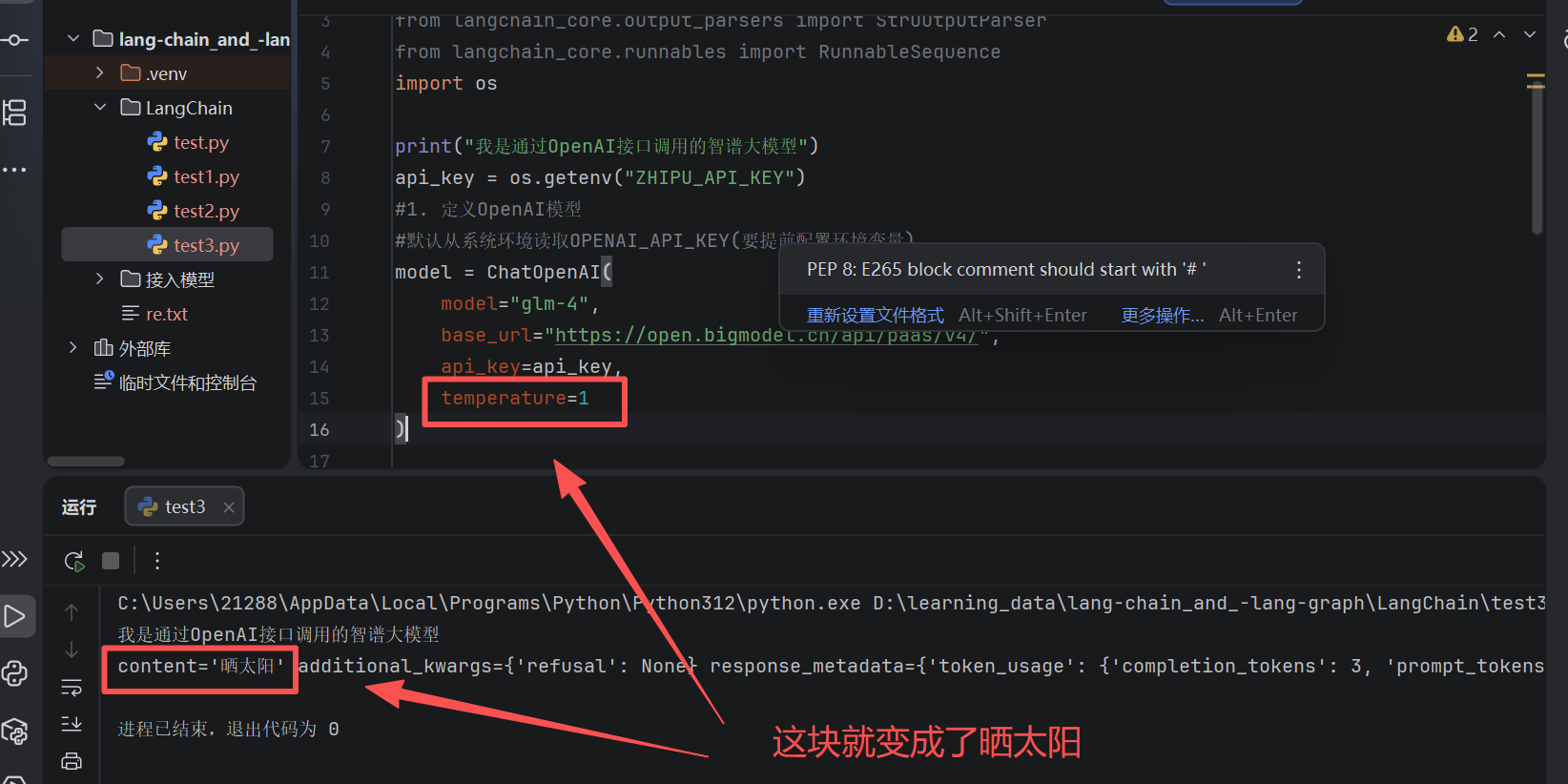
print("我是通过OpenAI接口调用的智谱大模型")
api_key = os.getenv("ZHIPU_API_KEY")
#1. 定义OpenAI模型
#默认从系统环境读取OPENAI_API_KEY(要提前配置环境变量)
model = ChatOpenAI(
model="glm-4",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key,
temperature=0
)
#2. 定义消息
#用户消息 HumanMessage
#系统提示消息 SystemMessage -> 通常作为第一条消息
messages = [
SystemMessage(content="请补全一段故事,10个字以内: "),
HumanMessage(content="一只猫正在__?")
]
# parser = StrOutputParser()
# chain = RunnableSequence(first=model,last=parser)
# print(chain.invoke(messages))
result = model.invoke(messages)
print(result)
内容相对保守

就相对变得更奇怪了
(我们扩展到100字之后,就变成了这样了)



![]()
![]()
![]()
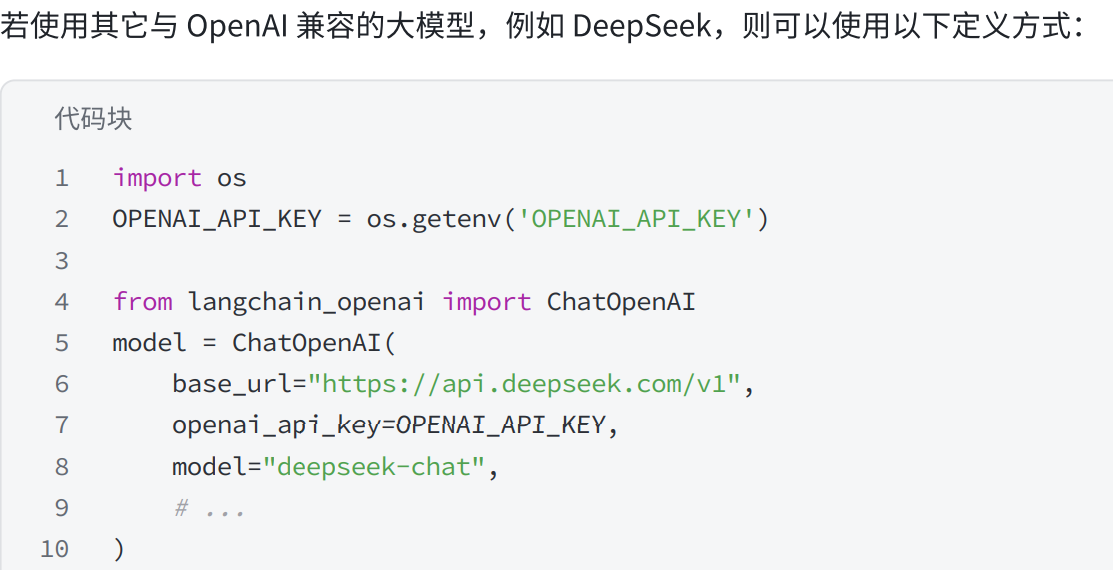
import os
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
base_url="https://api.deepseek.com/v1",
openai_api_key=OPENAI_API_KEY,
model="deepseek-chat",
# ...
)

如下(我们可以通过OpenAI提供的接口调用glm-4这个模型):
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
import os
print("我是通过OpenAI接口调用的智谱大模型")
api_key = os.getenv("ZHIPU_API_KEY")
#1. 定义OpenAI模型
#默认从系统环境读取OPENAI_API_KEY(要提前配置环境变量)
model = ChatOpenAI(
model="glm-4",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key
)
#2. 定义消息
#用户消息 HumanMessage
#系统提示消息 SystemMessage -> 通常作为第一条消息
messages = [
SystemMessage(content="请帮我进行翻译,由英文翻译成为中文!"),
HumanMessage(content="hi!")
]
#3.调用大模型
result = model.invoke(messages)
print(result)
b.invoke()调用
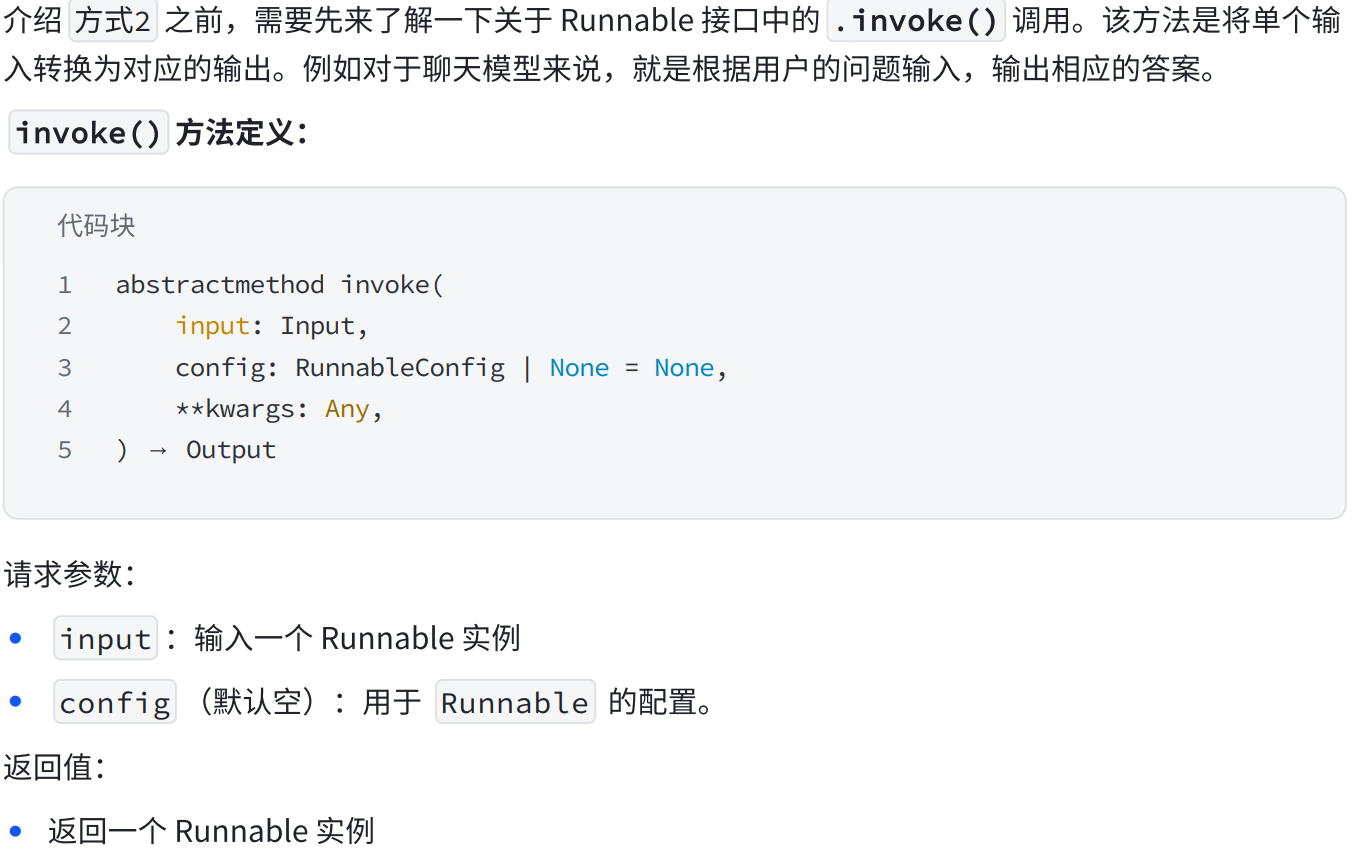
我们可以看官网有哪些:Chat model integrations - Docs by LangChain
c.init_chat_model
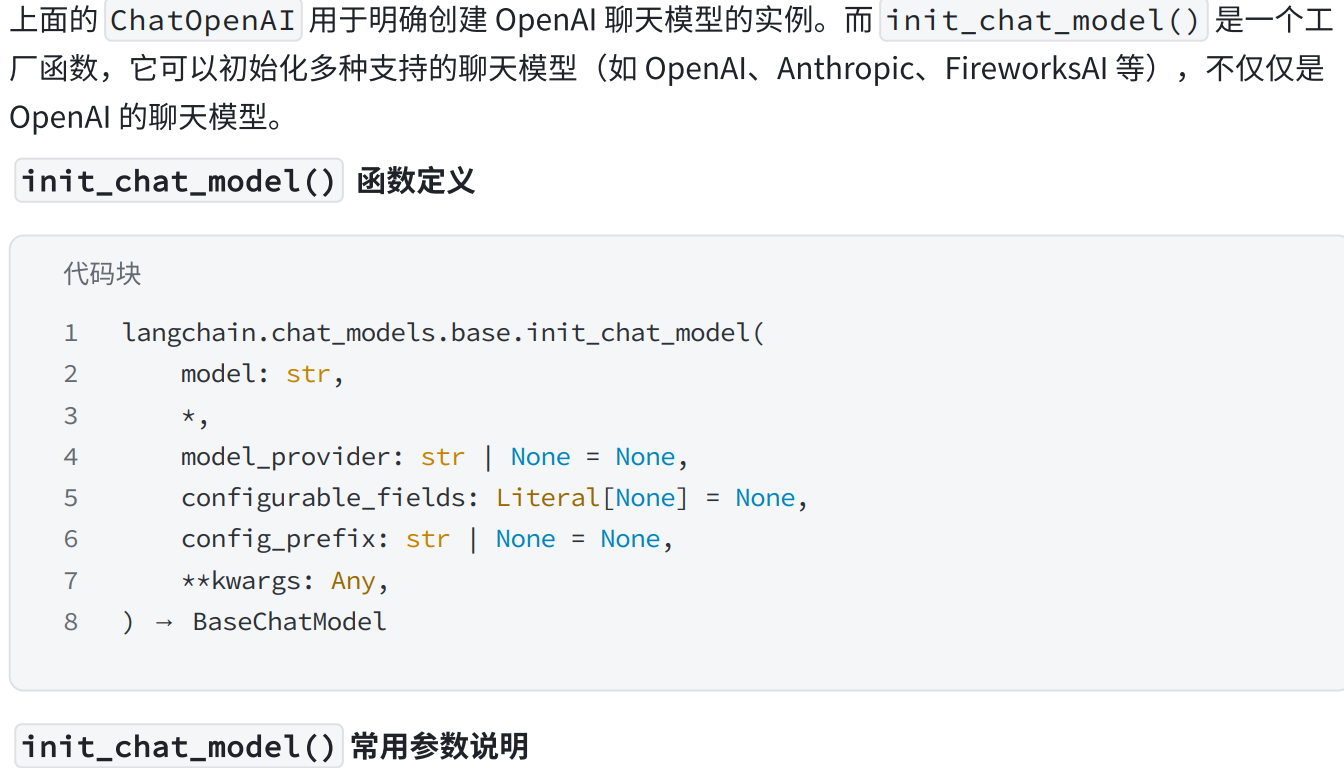



from langchain.chat_models import init_chat_model
# LangChain封装了更上层的方法,让我们初始化模型
# gpt_model = init_chat_model("gpt-4o-mini",model_provider="openai")
deepseek_model = init_chat_model("deepseek-chat",model_provider="deepseek")
# zhupu_model = init_chat_model("glm-4",model_provider="zhipuai")
print(f"deepseek_model: {deepseek_model.invoke("你是谁?").content}")智谱目前是使用不了的
from langchain.chat_models import init_chat_model
from langchain_core.messages import SystemMessage, HumanMessage
from sympy.physics.units import temperature
# # 1.基本用法
# # LangChain封装了更上层的方法,让我们初始化模型
# # gpt_model = init_chat_model("gpt-4o-mini",model_provider="openai")
# deepseek_model = init_chat_model("deepseek-chat",model_provider="deepseek")
# # zhupu_model = init_chat_model("glm-4",model_provider="zhipuai")
#
# print(f"deepseek_model: {deepseek_model.invoke("你是谁?").content}")
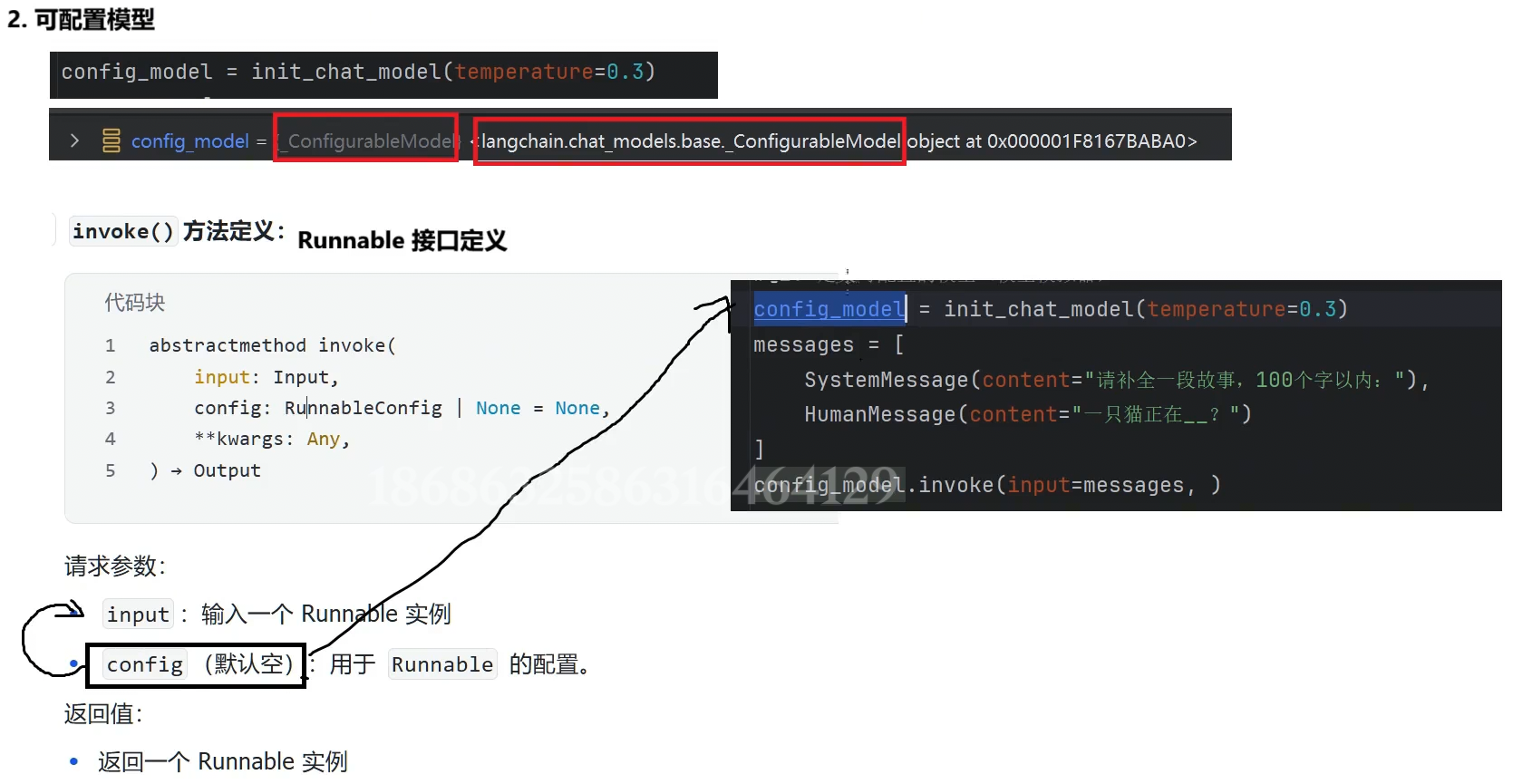
# 2.可配置的模型(模型模拟器)
config_model = init_chat_model(temperature=0.3)
messages = [
SystemMessage(content="请补全一段故事,10个字以内: "),
HumanMessage(content="一只猫正在__?")
]
#.invoke()的config参数才能真正意义上定义了模型
# print(f"config_model:{config_model.invoke("你是谁?").content}")
print(f"config_model:{config_model.invoke(input=messages,config={"configurable":{"model":"deepseek-chat"}}).content}")
from langchain.chat_models import init_chat_model
from langchain_core.messages import SystemMessage, HumanMessage
# 1. 初始化可配置的模型
model = init_chat_model(
model="gpt-4o-mini",
model_provider="openai",
temperature=0.3,
max_tokens=1024,
configurable_fields=("max_tokens", "model", "model_provider",),
config_prefix="first",
)
# 2. 构造消息
messages = [
SystemMessage(content="请补全一段故事,100个字以内:"),
HumanMessage(content="一只猫正在__?")
]
# 3. 动态配置并调用
result = model.invoke(
input=messages,
config={
"configurable": {
"first_max_tokens": 10,
"first_model": "deepseek-chat",
"first_model_provider": "deepseek",
}
}
)
# 4. 打印结果
print(result)2.通过本地部署的LLM定义聊天模型
a.ChatOllama

pip install -U langchain_ollama

from langchain_ollama import ChatOllama
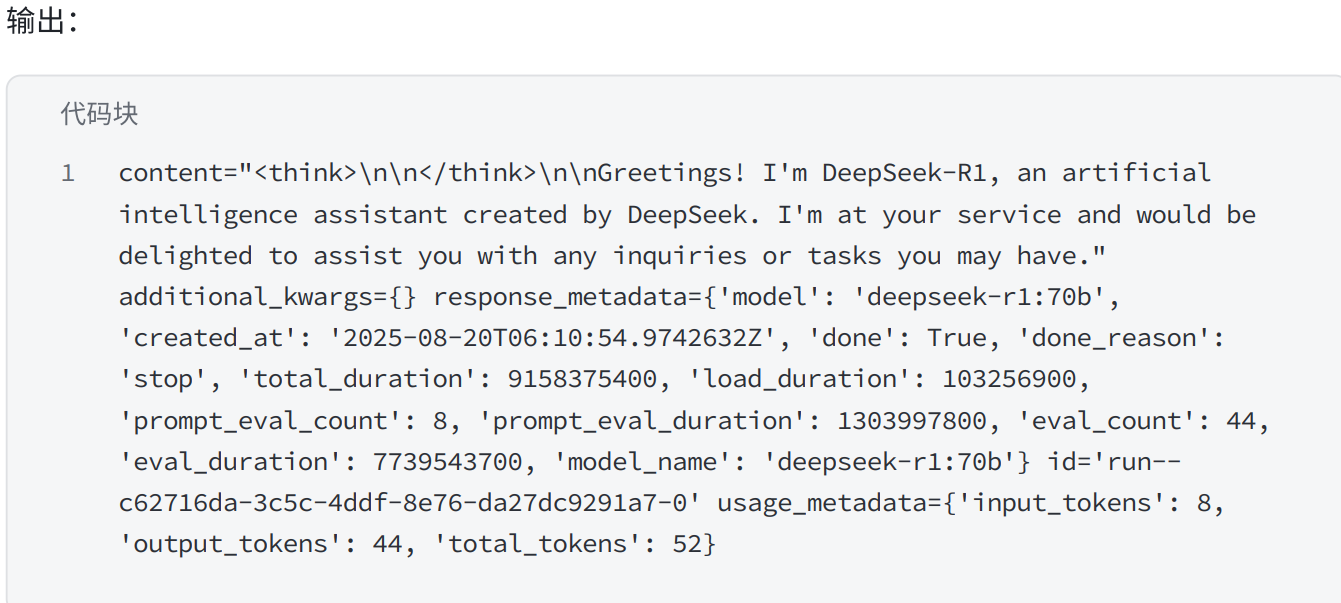
ollama_model = ChatOllama(model="deepseek-r1:70b",
base_url='http://192.168.100.220:11434')
result = ollama_model.invoke("what's your name?")
print(result)
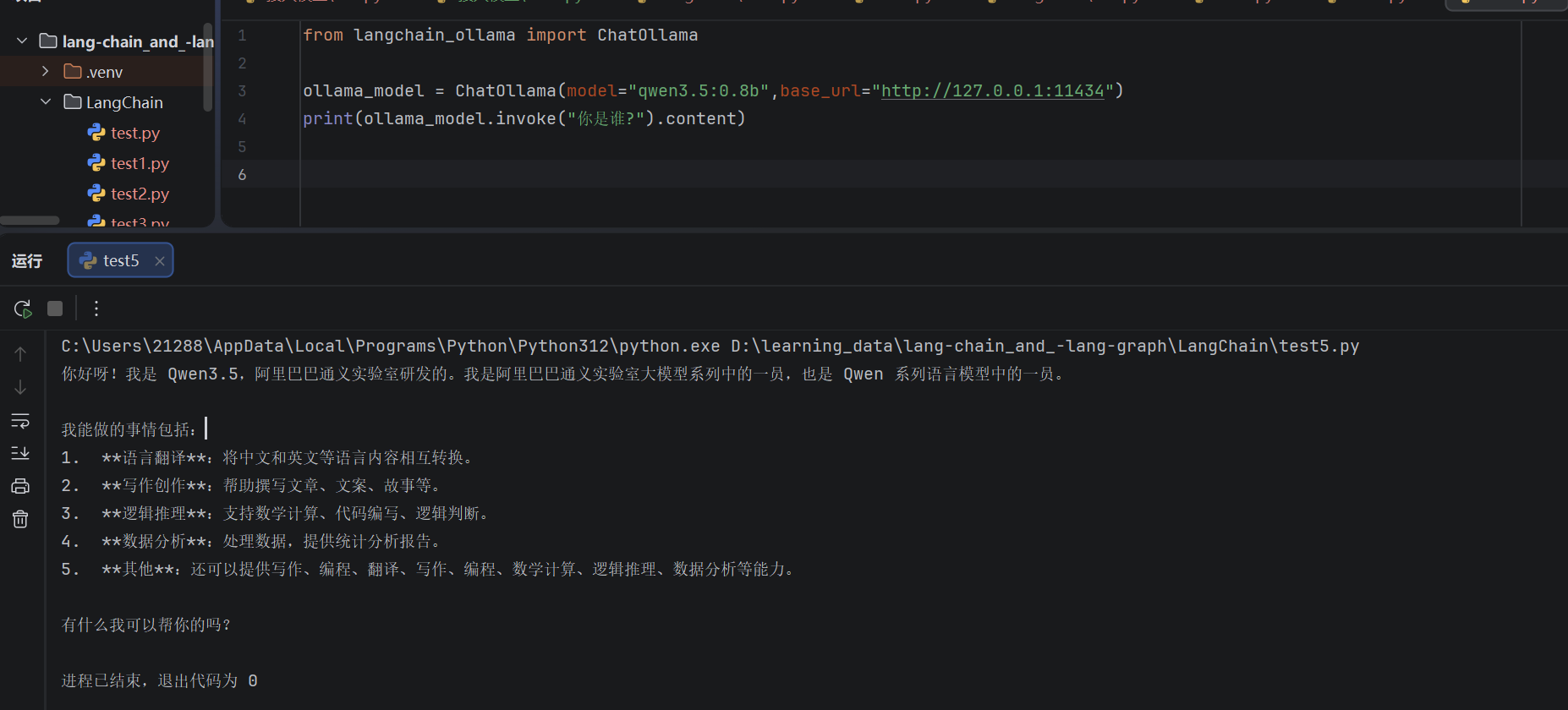
这块我们要将我们的代理,进行关闭(因为是我们本地启动的ollama)
from langchain_ollama import ChatOllama
ollama_model = ChatOllama(model="qwen3.5:0.8b",base_url="http://127.0.0.1:11434")
print(ollama_model.invoke("你是谁?").content)
二.聊天模型--调用工具

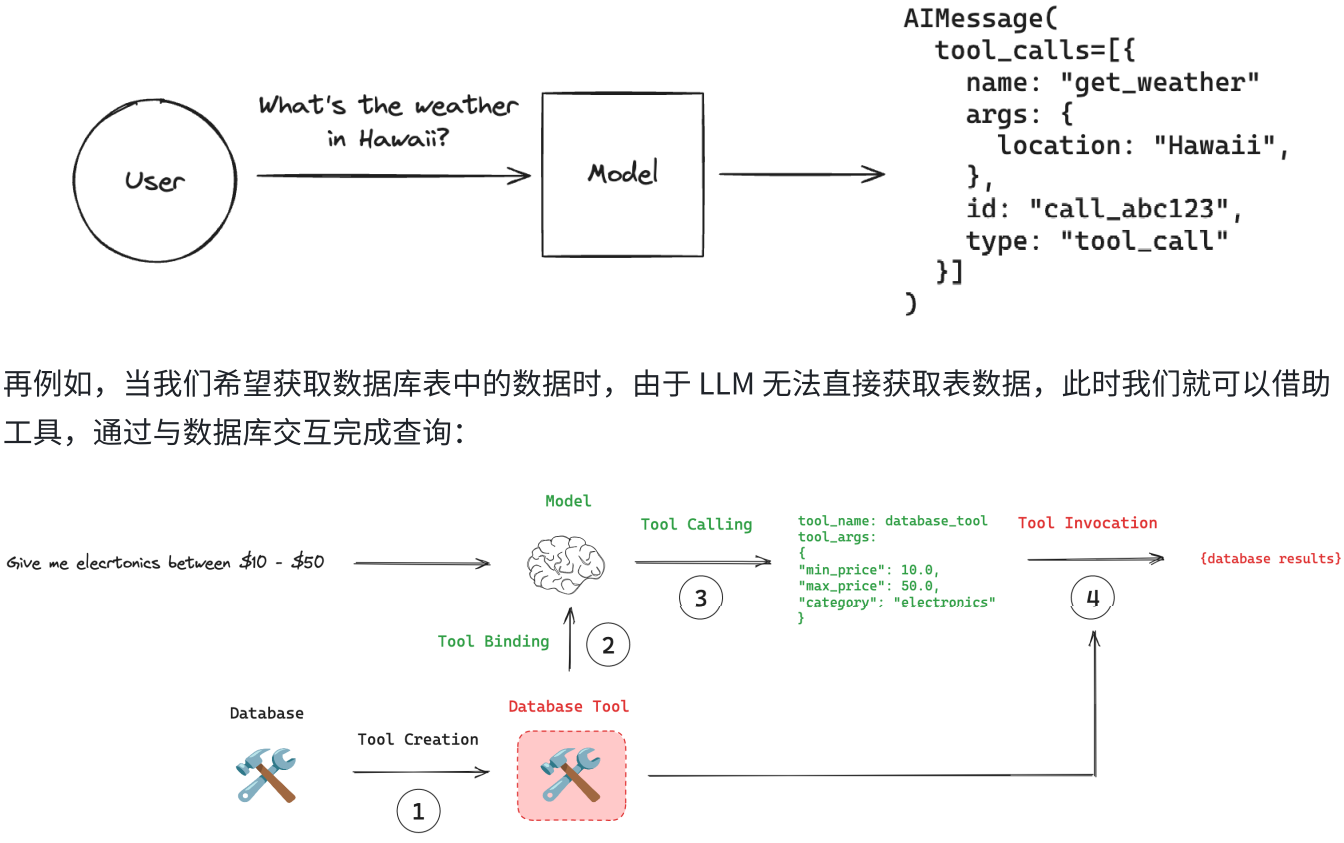
1.创建工具
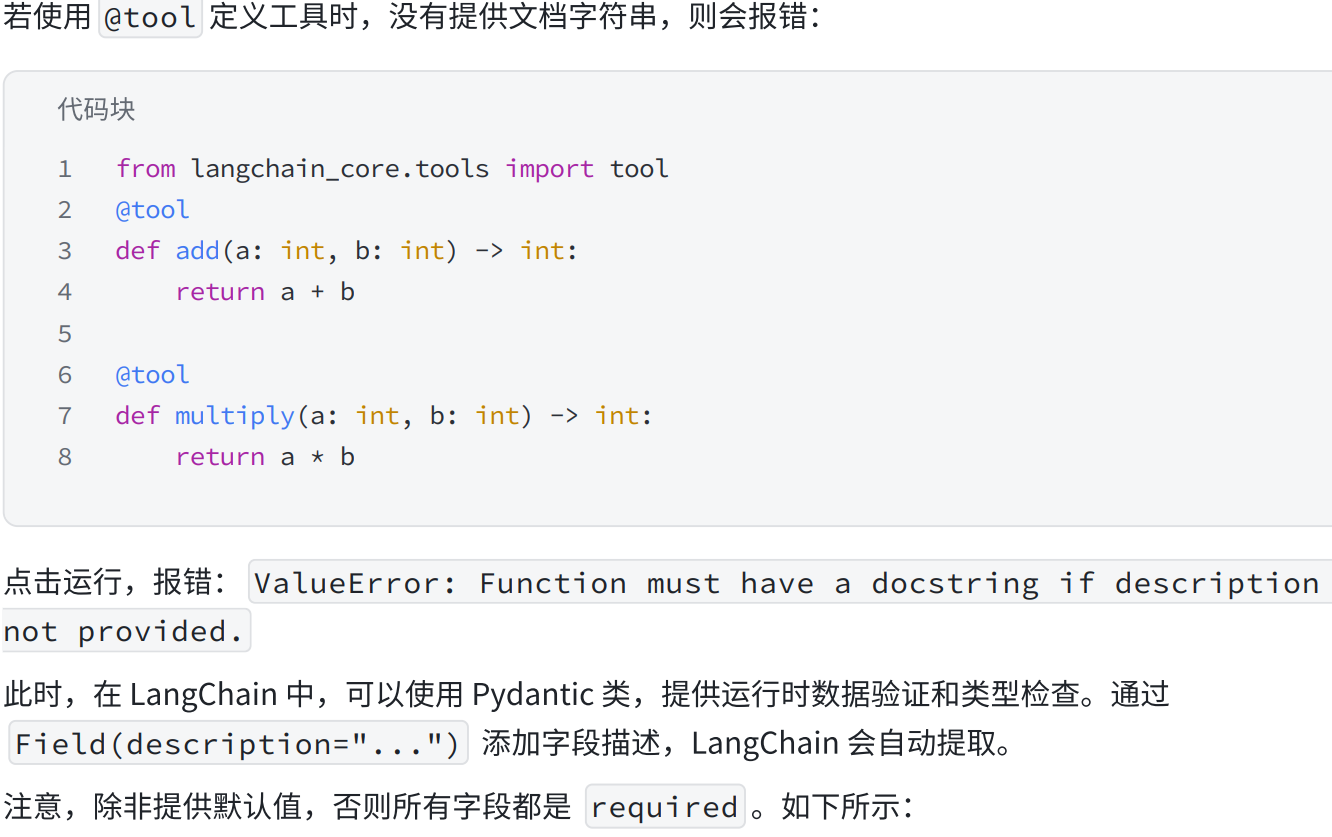
a.使用@tool 装饰器创建工具

from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two integers.
Args:
a: First integer
b: Second integer
"""
return a * b
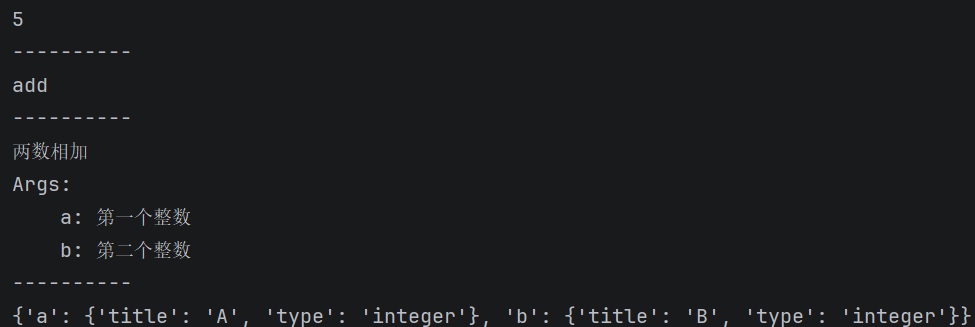
print(multiply.invoke({"a": 2, "b": 3})) # 输出:6
print(multiply.name) # 输出:multiply
print(multiply.description) # 输出:Multiply two ...省略...b:
Second integer
print(multiply.args) # 输出:{'a': {'title': 'A', 'type':
'integer'}, 'b': {'title': 'B', 'type': 'integer'}}


from langchain_core.tools import tool
#定义工具
@tool
def add(a: int,b: int)->int:
"""
两数相加
Args:
a: 第一个整数
b: 第二个整数
"""
return a + b
print(add.invoke({"a": 2,"b": 3}))





所以,这个是给我们做校验的
from langchain_core.tools import tool
#定义工具
@tool
def add(a: int,b: int)->int:
"""
两数相加
Args:
a: 第一个整数
b: 第二个整数
"""
return a + b
print(add.invoke({"a": 2,"b": 3}))
print("-" * 10)
print(add.name)
print("-" * 10)
print(add.description)
print("-" * 10)
print(add.args)

def fetch_data(url, retries=3):
"""从给定的URL获取数据。
Args:
url (str): 要从中获取数据的URL。
retries (int, optional): 失败时重试的次数。默认为3。
Returns:
dict: 从URL解析的JSON响应。
"""
# ... 函数实现 ...

模式1:依赖Pydantic类

完整代码如下所示:
# pydantic 数据验证
from pydantic import BaseModel, Field
class AddInput(BaseModel):
"""Add two integers."""
a: int = Field(..., description="First integer")
b: int = Field(..., description="Second integer")
class MultiplyInput(BaseModel):
"""Multiply two integers."""
a: int = Field(..., description="First integer")
b: int = Field(..., description="Second integer")
# 定义工具
from langchain_core.tools import tool
@tool(args_schema=AddInput)
def add(a: int, b: int) -> int:
# 未提供描述
return a + b
@tool(args_schema=MultiplyInput)
def multiply(a: int, b: int) -> int:
# 未提供描述
return a * b
from langchain_core.tools import tool
from pydantic import BaseModel,Field
class AddInput(BaseModel):
"""两数相加"""
a: int = Field(..., description="第一个整数")
b: int = Field(..., description="第一个整数")
@tool(args_schema=AddInput)
def add(a: int, b: int)->int:
return a + b
print(add.invoke({"a": 2,"b": 3}))
print("-" * 10)
print(add.name)
print("-" * 10)
print(add.description)
print("-" * 10)
print(add.args)模式2:依赖Annotated
![]()
from langchain_core.tools import tool
from typing_extensions import Annotated
#定义工具
@tool
def add(
a: Annotated[int,...,"第一个整数"],
b: Annotated[int,...,"第二个整数"]
)->int:
"""
两数相加
Args:
a: 第一个整数
b: 第二个整数
"""
return a + b
print(add.invoke({"a": 2,"b": 3}))
print("-" * 10)
print(add.name)
print("-" * 10)
print(add.description)
print("-" * 10)
print(add.args)
from langchain_core.tools import tool
from typing_extensions import Annotated
@tool
def add(
a: Annotated[int, ..., "First integer"],
b: Annotated[int, ..., "Second integer"]
) -> int:
"""Add two integers."""
return a + b
@tool
def multiply(
a: Annotated[int, ..., "First integer"],
b: Annotated[int, ..., "Second integer"]
) -> int:
"""Multiply two integers."""
return a * b
b.使用StructuredTool类提供的函数创建⼯具


from langchain_core.tools import StructuredTool
from onnxruntime.tools.ort_format_model.ort_flatbuffers_py.fbs.Attribute import AddI
from pydantic import Field, BaseModel
#方式一:常规写法
# def add(a: int,b : int)->int:
# """两数相加"""
# return a + b
#
# add_tool = StructuredTool.from_function(func=add)
# print(add_tool.invoke({"a": 1, "b": 2}))
#方式二:
class AddInput(BaseModel):
a: int = Field(description="第一个参数")
b: int = Field(description="第一个参数")
def add(a: int,b : int)->int:
return a + b
add_tool = StructuredTool.from_function(
func=add,
name="ADD", #工具名
description="两数相加", #工具描述
args_schema=AddInput, #工具参数
)
print(add_tool.invoke({"a": 2, "b": 3}))
print("-" * 10)
print(add_tool.name)
print("-" * 10)
print(add_tool.description)
print("-" * 10)
print(add_tool.args)
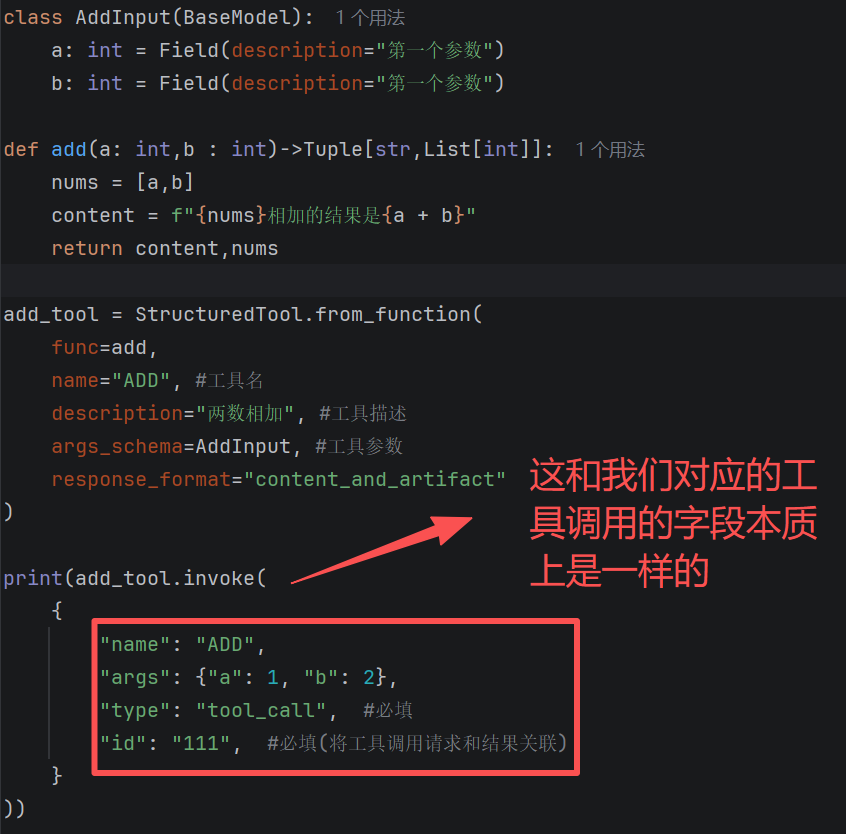
c.加入 response_format 配置

{
‘results’: [
{
‘title’: ‘北京天⽓预报 - 中国天⽓⽹’,
‘link’: ‘https://weather.com.cn/...’,
‘snippet’: ‘北京今天⽩天晴,最⾼⽓温32°C,夜间晴,最低⽓温25°C...’
},
{
‘title’: ‘北京实时天⽓ - Weather.com’,
‘link’: ‘https://www.weather.com/...’,
‘snippet’: ‘Bejing, China Weather. Mostly sunny. High 32C...’
}
# ... 更多结果
],
‘search_parameters’: { ... },
‘search_information’: { ... }
}


如果出错了,我们可以通过保留现场,来帮助我们进行分析
class AddInput(BaseModel):
a: int = Field(description="第一个参数")
b: int = Field(description="第一个参数")
def add(a: int,b : int)->Tuple[str,List[int]]:
nums = [a,b]
content = f"{nums}相加的结果是{a + b}"
return content,nums
add_tool = StructuredTool.from_function(
func=add,
name="ADD", #工具名
description="两数相加", #工具描述
args_schema=AddInput, #工具参数
response_format="content_and_artifact"
)
print(add_tool.invoke(
{
"name": "ADD",
"args": {"a": 1, "b": 2},
"type": "tool_call", #必填
"id": "111", #必填(将工具调用请求和结果关联)
}
))
模型基本上就获取content为主(artifact就是留给langchain后续组件使用的)
2.绑定工具
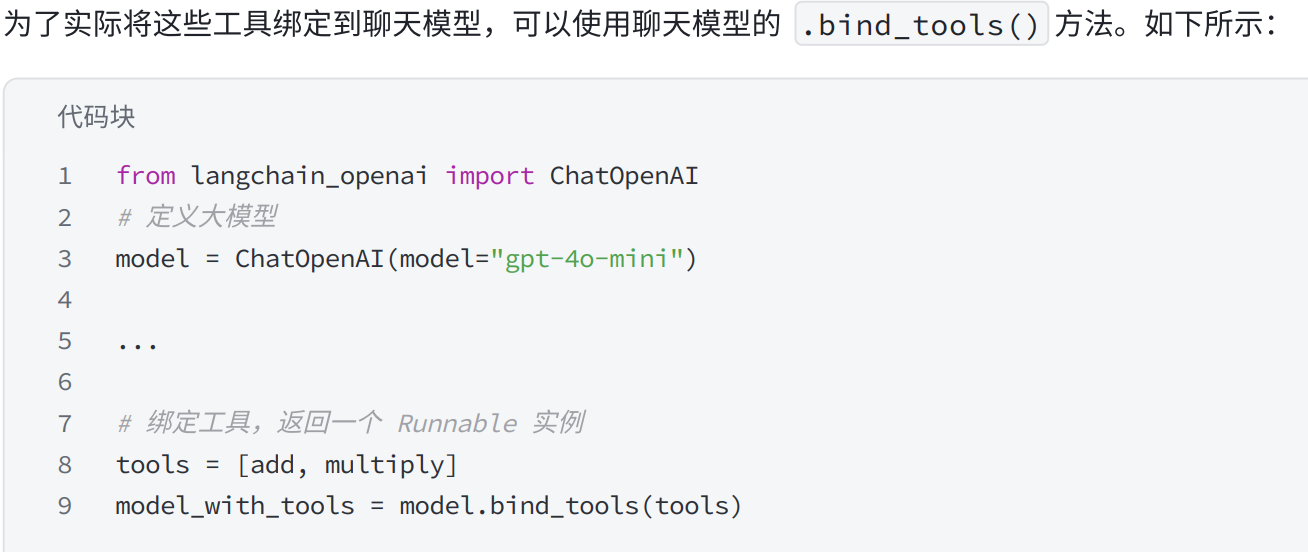



from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from typing_extensions import Annotated
from langchain_community.chat_models import ChatZhipuAI
@tool
def add(
a: Annotated[int, ..., "第一个整数"],
b: Annotated[int, ..., "第二个整数"],
) -> int:
"""
两数相加
"""
return a + b
@tool
def multiply(
a: Annotated[int, ..., "第一个整数"],
b: Annotated[int, ..., "第二个整数"],
) -> int:
"""
两数相乘
"""
return a * b
model = ChatZhipuAI(model="glm-4")
#绑定工具
model_with_tools = model.bind_tools([add,multiply])
# 调用工具
print(model_with_tools.invoke("2乘3等于多少?"))
我们发现,这里我们对应的模型调用的结果没有了,那怎么办呢?

这个地方,我们发现,后面function中有multiply,所以聊天模型通过语义决定要调用啥
print(model_with_tools.invoke("你是谁"))如果我们问一下和我们的bind相关性不大的,那么他也能够进行识别

他会根据我们问的自动进行调用工具
model_with_tools = model.bind_tools(tools=[add,multiply],tool_choice="any")我们也可以强制的进行调用(模型随机选择)

3.工具调用


ai调用完之后,我们会拿到这个对应的字段

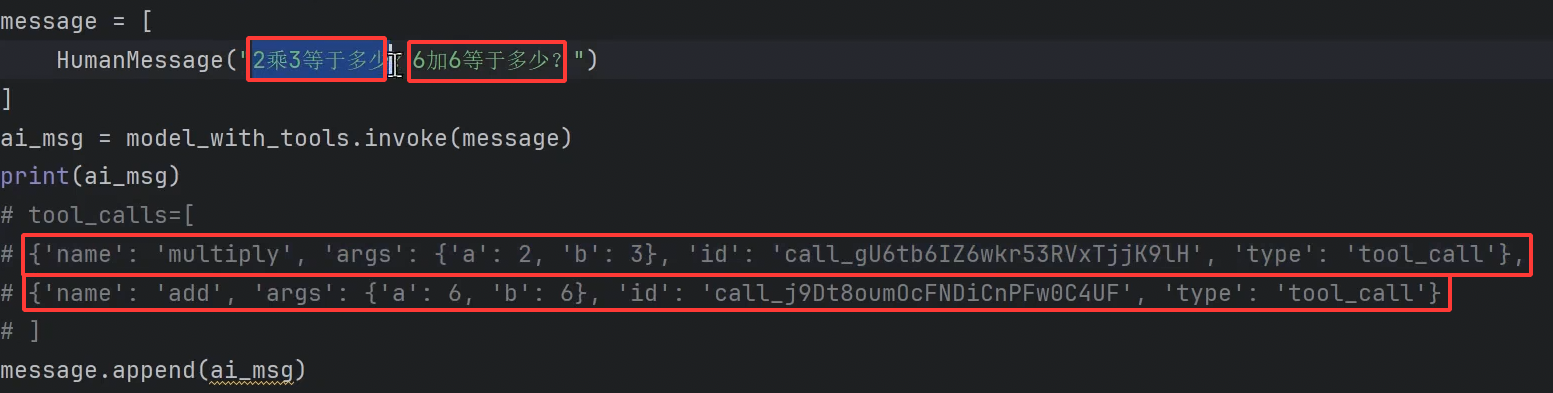
我们如果调用两个问题的话,ai_meg返回的也是两个消息
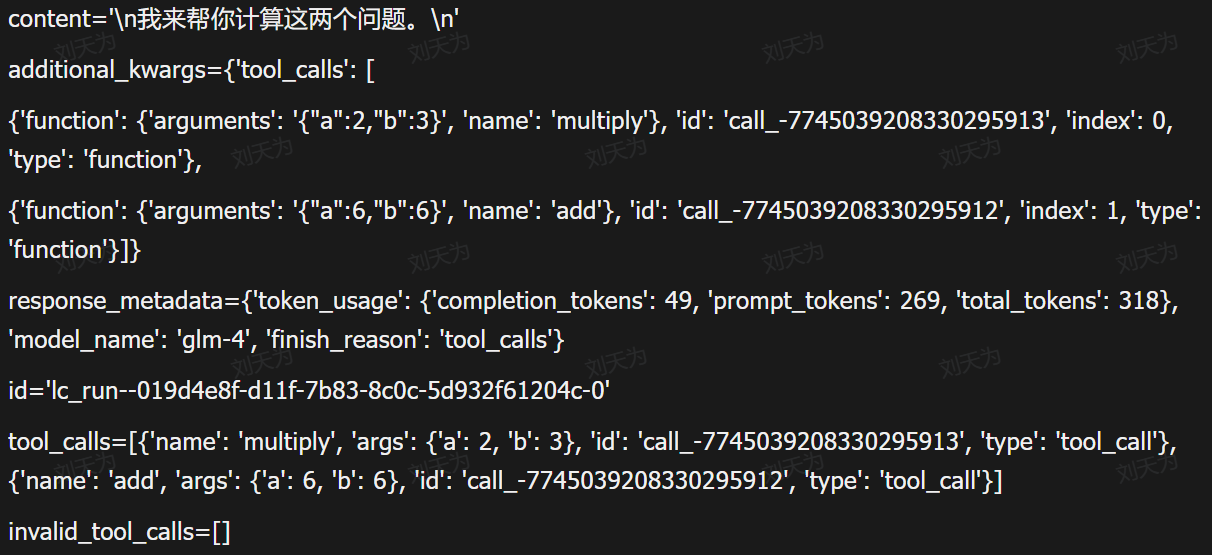

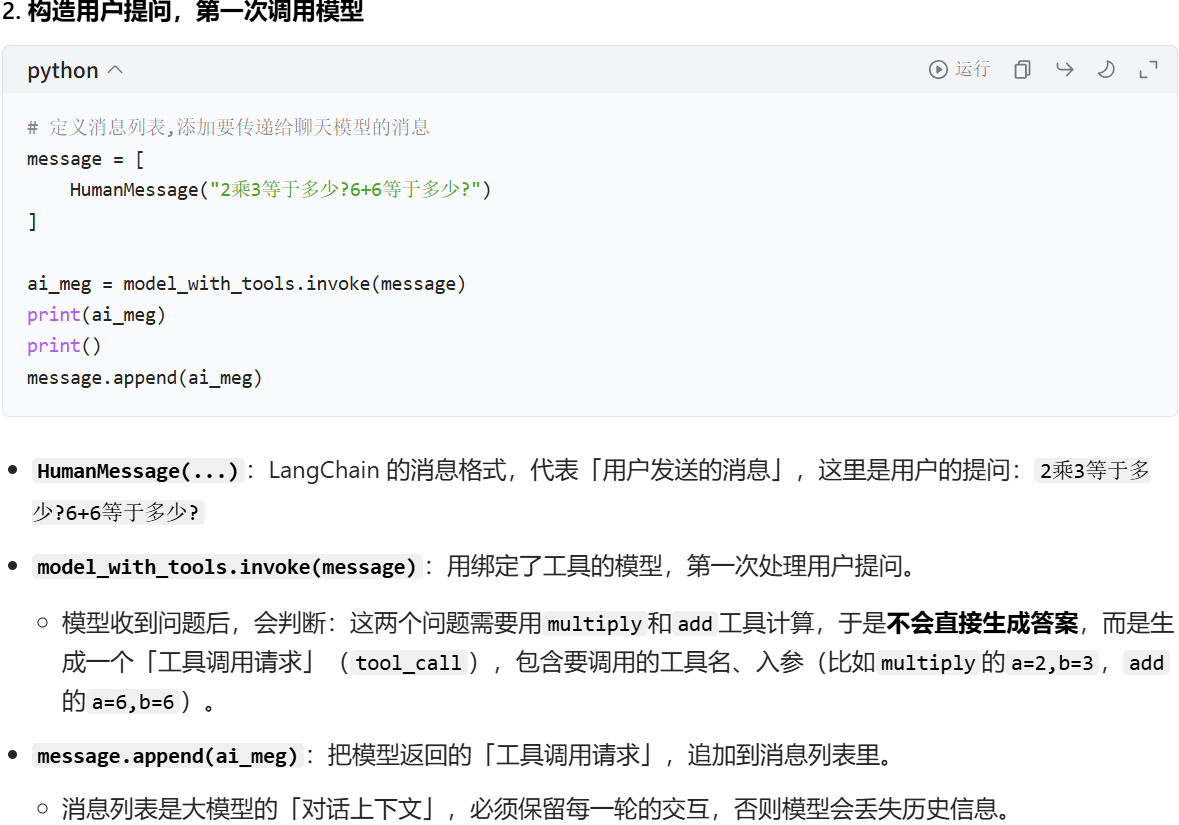
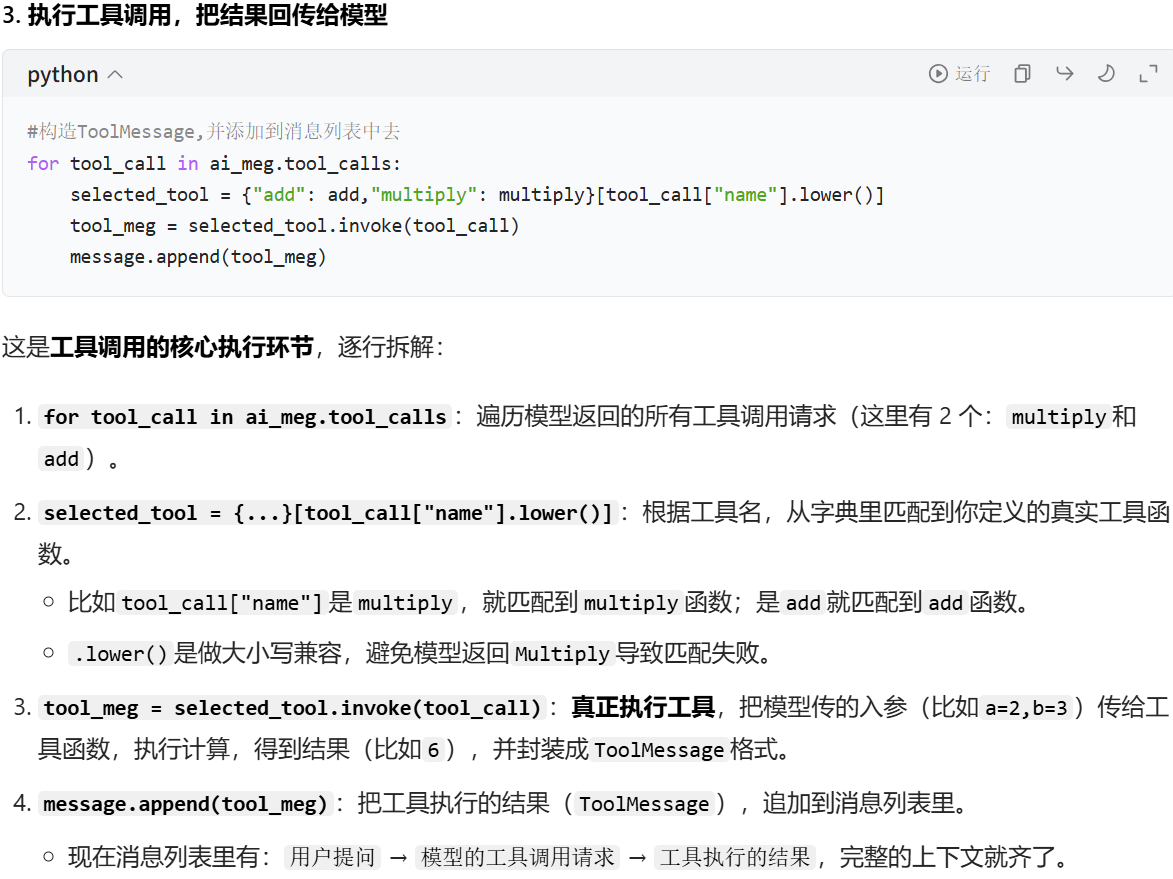

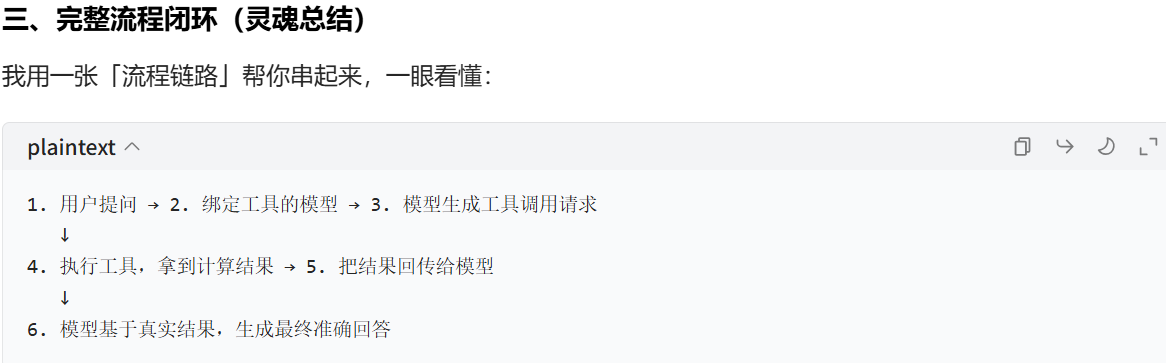
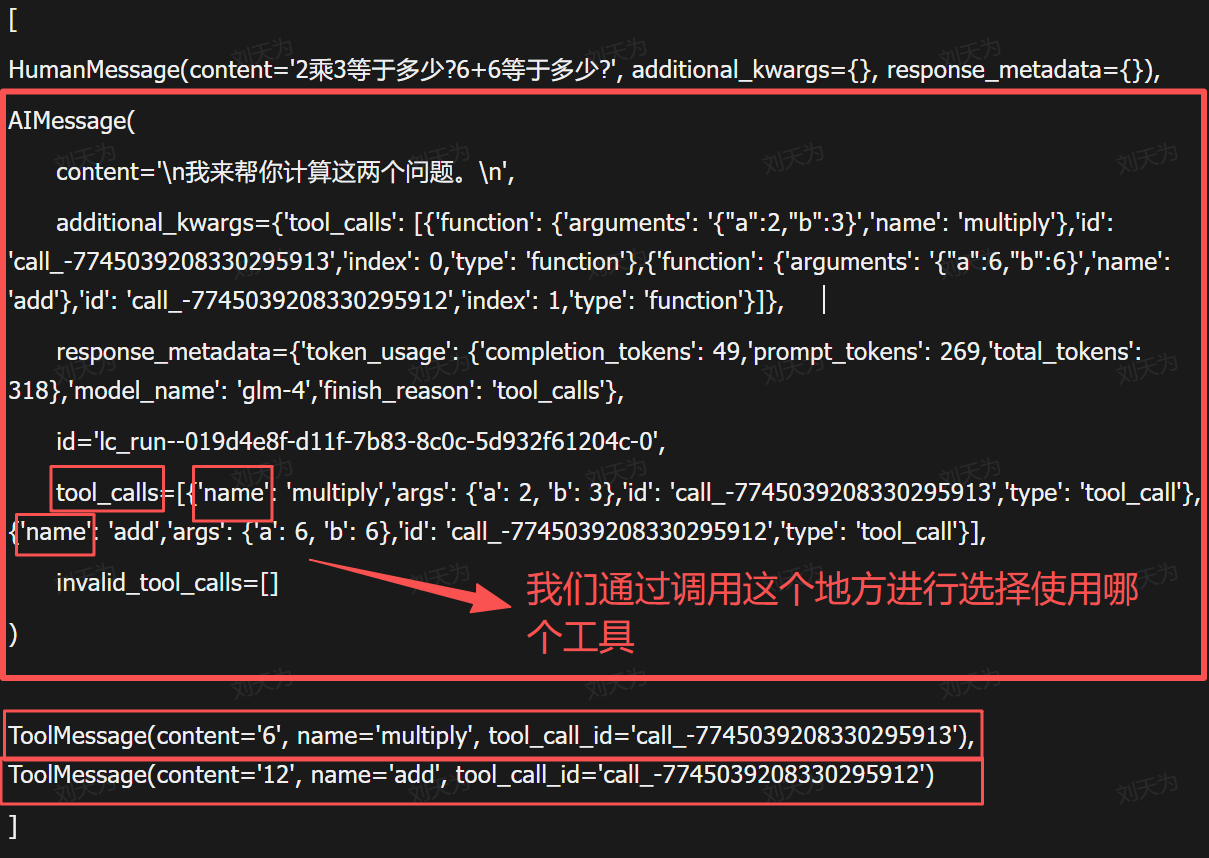
我们虽然在这个时候,已经拿到了对应的数字信息了(content里面)
![]()
我们再调用一次AI,将其转化成为对应的AI的自然语言
所以并不是AI进行的计算,而是我们定义的工具进行的计算(比如计算器是一个tool,当地天气是一个tool等)
这里我们不能使用强制选择一种tool的方式,因为一旦选择了,我们模型输出的时候,只认为他是选择工具的模型(导致他没有办法进行输出)
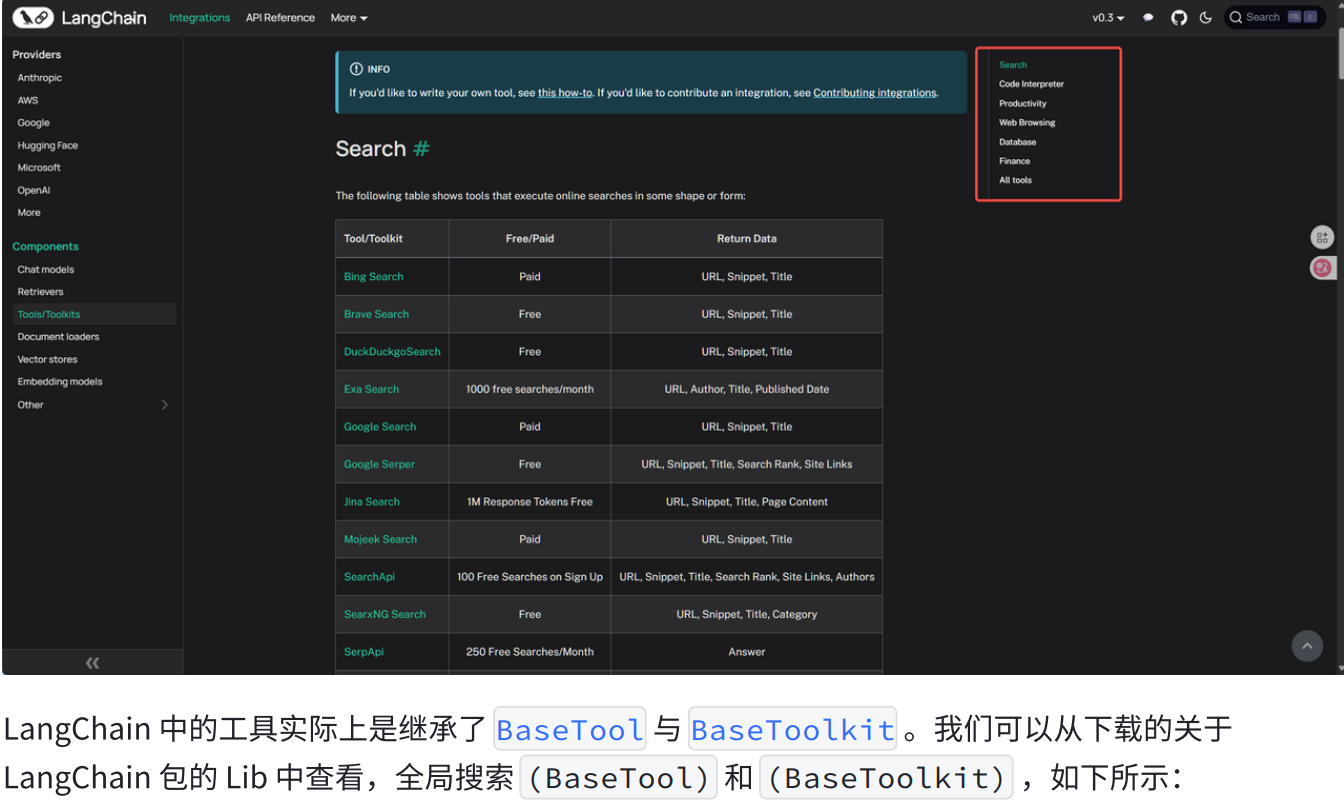
4.LangChain提供的工具


https://docs.langchain.com/oss/python/integrations/providers/overview
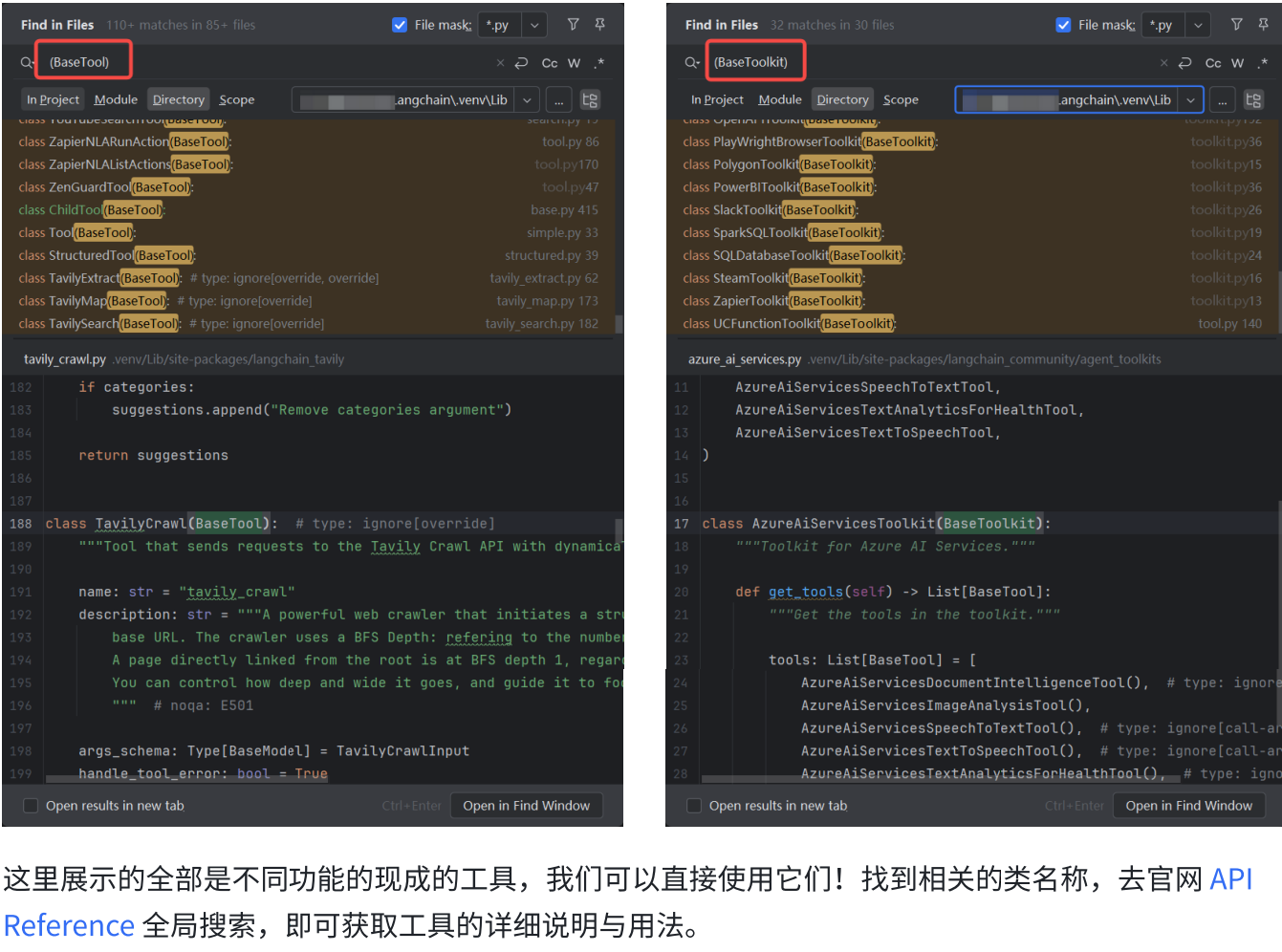
https://reference.langchain.com/?lang=python
下面我们简单看一个搜索工具类。
a.TavilySearch


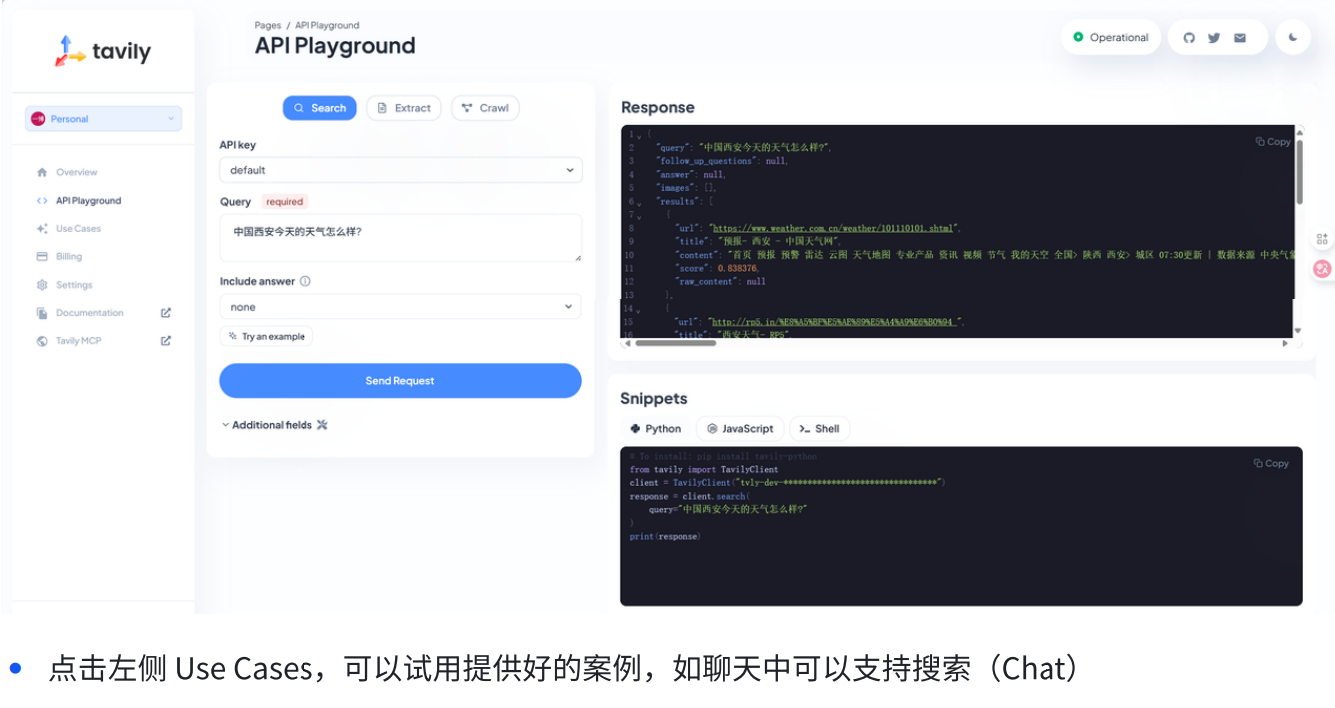


pip install -U langchain-tavily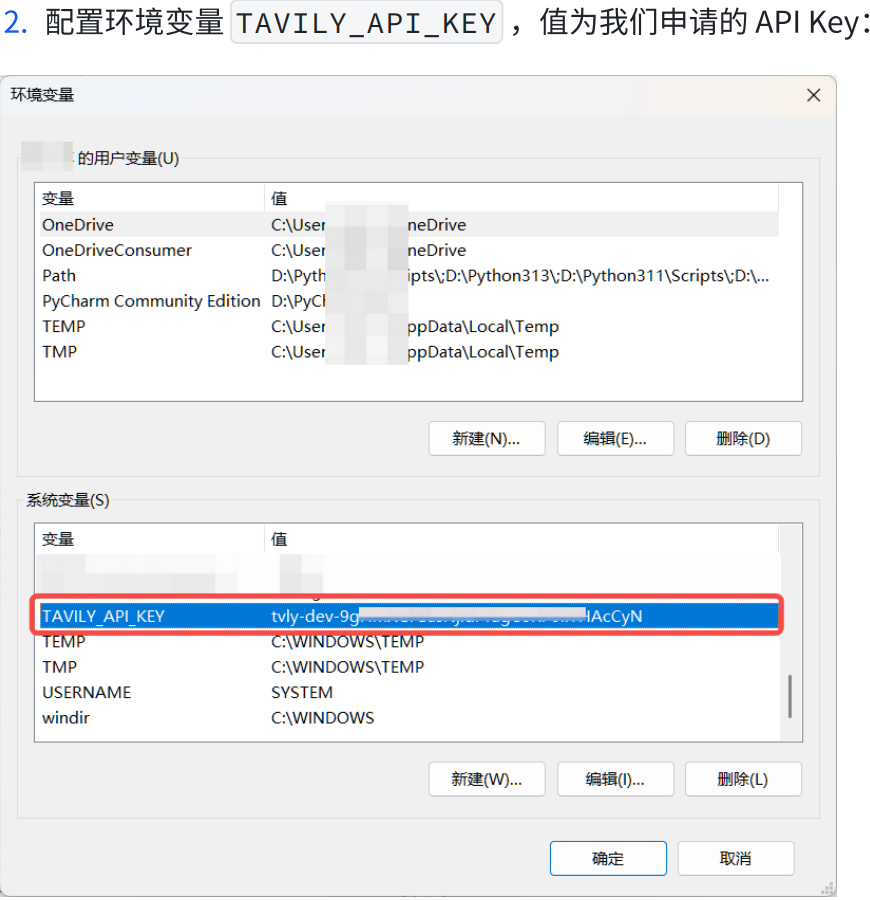
3. 代码接⼊TavilySearch类,实现搜索功能:
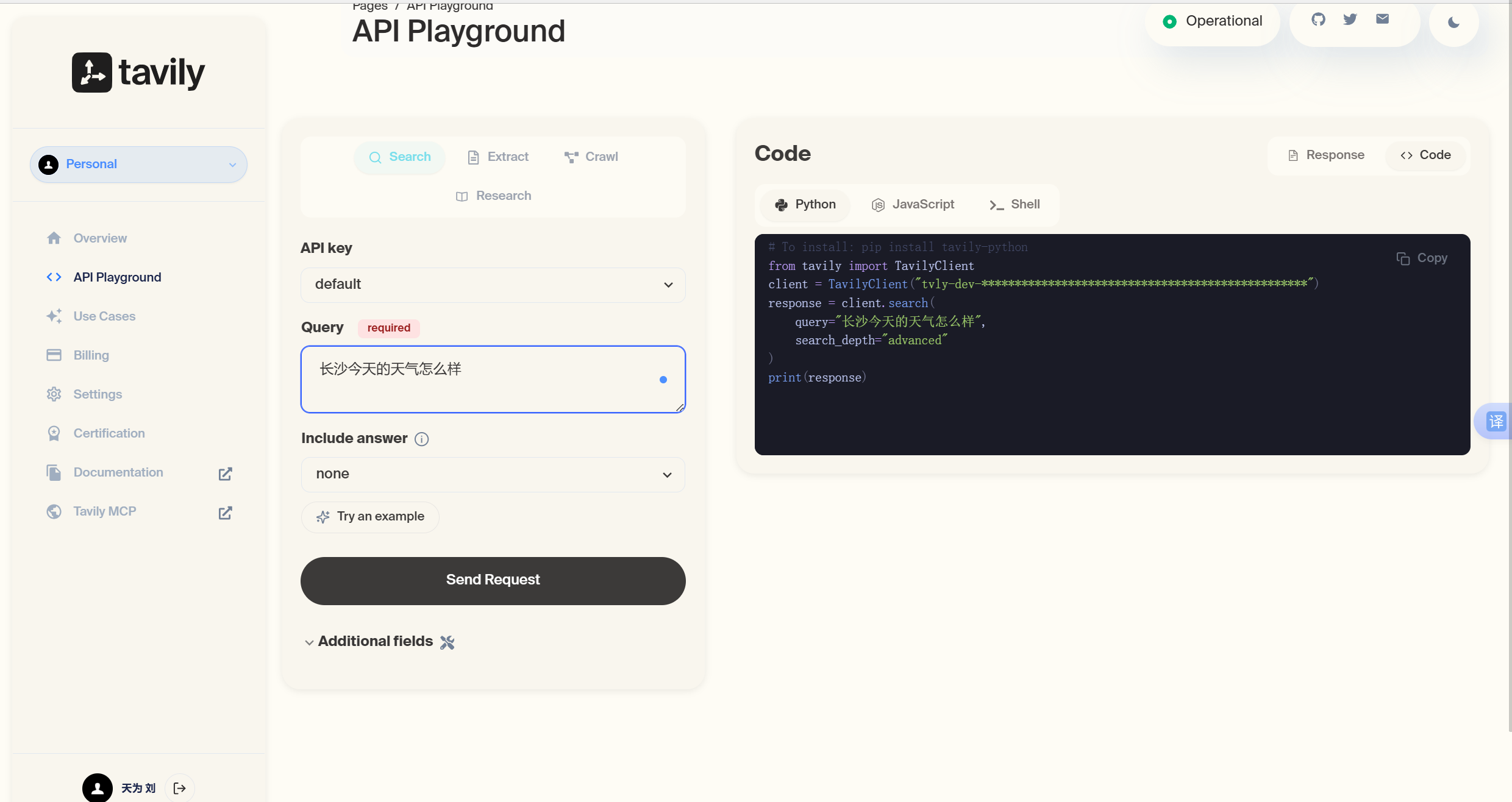
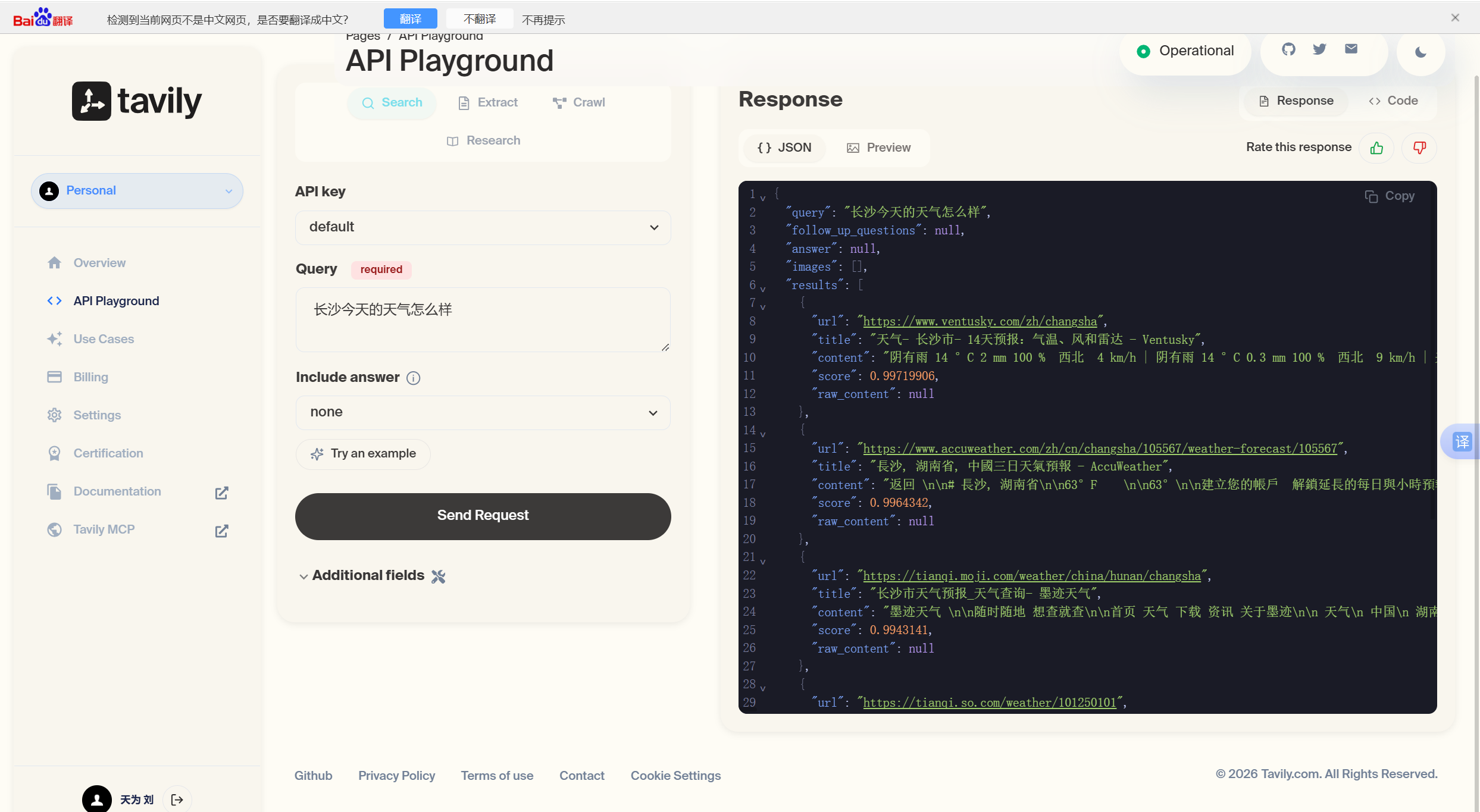
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
import os
from langchain_tavily import TavilySearch
print("我是通过OpenAI接口调用的智谱大模型")
api_key = os.getenv("ZHIPU_API_KEY")
#1. 定义OpenAI模型
#默认从系统环境读取OPENAI_API_KEY(要提前配置环境变量)
model = ChatOpenAI(
model="glm-4.5-air",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key
)
tool = TavilySearch(max_results=4)
model_with_tools = model.bind_tools([tool])
messages = [
HumanMessage("北京今天的天气怎么样?")
]
ai_message = model_with_tools.invoke(messages)
messages.append(ai_message)
print(messages)
for tool_call in ai_message.tool_calls:
tool_message = tool.invoke(tool_call)
messages.append(tool_message)
print(model.invoke(messages).content)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)