大模型应用:大模型业务落地规避低效陷阱:直击5大高频误区深度拆解与整改指南.134
一、前言
在当下大模型落地各类实际业务的过程中,我们在初期接触,刚开始上手搭建对话系统、智能咨询助手或是行业AI应用时,总会凭着主观想法盲目推进。本着程序开发的惯性思维,大家都是一心想着把系统做得足够周全稳妥,恨不得上线之初就覆盖所有极端异常场景,要么直接堆砌复杂专业的规则框架,忽略基础落地的轻量化需求。
与此同时,不少项目只盯着规则校验和基础拦截效果,全然不在意用户真实交互感受,冰冷生硬的提示话术频繁出现。更关键的是,很多人急于快速上线验证效果,跳过本地多场景实测环节,也没有搭建动态更新的高危词库机制。等到正式投入业务使用后,语义识别失效、隐性负面语义漏判、交互体验差、漏洞集中爆发等各类问题接连浮现,不仅拉长整改周期、增加额外开发成本,还严重影响业务运转稳定性。
结合一线落地经验来看,踩坑大多集中在五大典型方向,接下来就结合基础原理、实操流程与代码实践,一步步拆解问题根源,给出贴合业务实际的标准化避坑方案。

二、基础说明
1. 大模型应用容错体系
- 大模型在对话交互、意图识别、智能问答、行业 Agent 部署场景中,容错能力指系统对异常输入、模糊语义、违规内容、口语化表达、方言变体、残缺语句的识别、修正、兜底应答能力,是保障业务稳定性的核心底座。
- 区别于传统软件报错终止运行,大模型容错依托语义理解能力,实现柔性交互兜底。
2. 轻量化规则 + 大模型混合架构逻辑
- 原生大模型存在幻觉、响应不可控、合规风险高、推理成本昂贵等问题;纯传统规则引擎灵活性差。
- 行业通用落地范式为:前置轻量化规则过滤兜底 + 中端大模型语义理解 + 后置内容安全校验,兼顾低成本、高可控、高体验,也是入门首选架构。
3. 大模型工程落地核心诉求
- 可控性:限制模型输出边界,规避违规、无效回复
- 低成本:减少全量大模型调用频次,降低 Token 开销
- 快迭代:快速上线基础版本,根据真实数据优化升级
- 高体验:语义共情交互,拒绝机械冰冷标准化话术
三、5大实践误区
1. 过度设计,追求完美容错
1.1 现象表现
在搭建医疗客服、智能咨询、通用对话 Agent 初期,研发人员试图穷尽极端边界场景:超长文本乱码、多国混合语言、恶意拼接话术、极致残缺输入等,一次性设计全套容错分支、多级兜底链路、分布式异常校验模块。
直接导致需求堆叠、开发周期翻倍、调试成本激增,基础核心业务迟迟无法上线验证。
1.2 业务场景
我们想一次性处理:乱码、火星文、10 种方言、超长文本、中英混合、符号堆砌、语音转文字错误…… 结果写了 2000 行代码,冗余太多,排查困难,运行不顺畅,甚至可能跑不起来。
过度设计写法:
def over_design_check(text):
# 试图覆盖所有场景:乱码、方言、符号、超长、中英混合、语音错误...
if not text:
return "输入为空"
if len(text) > 500:
return "超长文本"
if len(text) < 1:
return "文本过短"
if any(ch in text for ch in "!@#$%^&*()_+-"):
return "包含特殊符号"
if any(ch in text for ch in "abcdefghijklmnopqrstuvwxyz"):
return "包含英文"
if "啥" in text or "呗" in text or "哟" in text:
return "方言口语"
if "♂♀♡♢" in text:
return "特殊表情乱码"
# 无限加规则,项目卡死
return "校验通过"
# 测试
print(over_design_check("我好难受"))最小可行容错设计:
# 只覆盖80%核心场景:长度+敏感词+基础清洗
def minimal_fault_tolerance(text):
# 只做最核心校验:长度 + 高危词
text = text.strip()
# 1. 长度容错
if len(text) < 2 or len(text) > 300:
return False, "输入太短或太长啦,我有点看不懂~"
# 2. 高危词容错
risk_words = {"自杀", "自残", "绝望", "崩溃", "抑郁", "失眠", "焦虑", "抑郁", "难受"}
for word in risk_words:
if word in text:
return False, "我很担心你,请一定寻求专业帮助!"
return True, text
# 测试
ok, msg = minimal_fault_tolerance("我好难受")
print(ok, msg)设计建议总结:
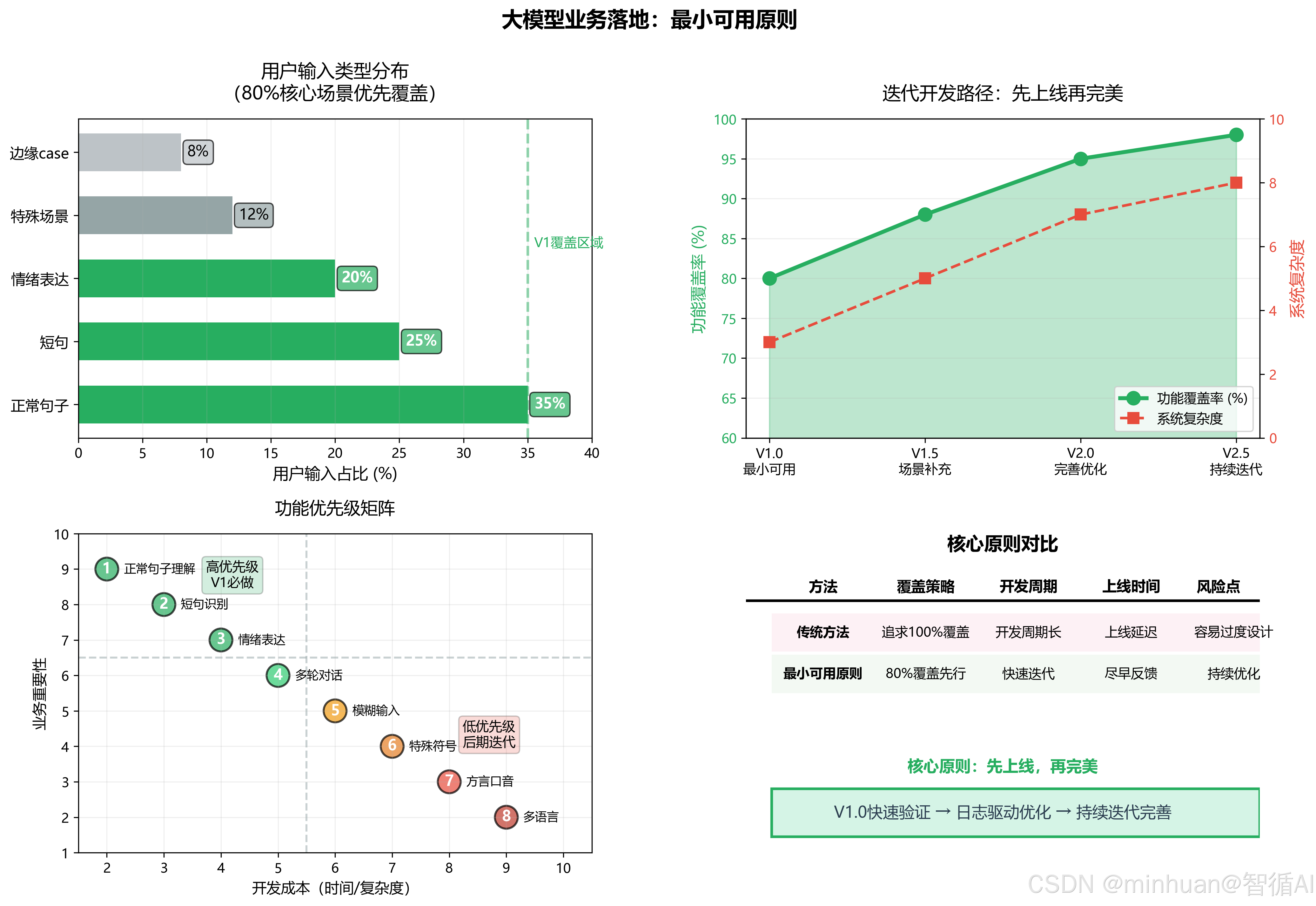
- 不用一开始追求 100% 覆盖,先跑起来,再迭代。
- 80% 用户只会输入:正常句子、短句、情绪表达。
- 先做最小可用版本,后期根据日志补充特殊场景。
- 核心原则:先上线,再完美。
1.3 底层原理
大模型语义容错存在层级差异:
- 80% 线上真实用户输入仅集中在常规残缺、口语模糊、基础格式错误三类场景;
- 剩余 20% 极端小众场景日均触发概率极低。
早期全域完美容错,本质是资源错配、算力冗余、架构超前设计,违背互联网产品快速验证迭代的基本逻辑。
1.4 标准化执行规避流程
- 1. 场景聚类:梳理业务核心高频输入场景,筛选 TOP80 主流交互语句
- 2. 极简架构:搭建“最小可行容错架构”,仅覆盖核心异常分支
- 3. 灰度上线:基础版本快速部署采集真实线上交互数据
- 4. 迭代优化:基于日志补充小众异常场景容错策略
- 5. 架构升级:数据沉淀完成后,再接入复杂容错与分层兜底机制

1.5 对大模型应用的核心价值
- 减少无效大模型微调与定制开发投入,降低单次推理资源消耗;
- 保障核心链路稳定可用,优先验证商业模式与交互逻辑,避免架构臃肿导致后期维护难度飙升。
2. 规则引擎过于复杂
2.1 现象表现
刚接触大模型工程落地,直接选用 Drools、CLIPS 等专业商用规则引擎做基础输入校验、敏感词拦截、格式合规检测。
这类框架依赖复杂语法学习、环境部署繁琐、配置文件冗余,零基础研发上手周期长,且小体量大模型业务完全无法发挥框架性能优势。
2.2 业务场景
在设计初期一上来就用 Drools、EasyRules 等重型引擎,光配置就花好几天,业务还没梳理完整就被规则绕晕了,基础校验根本没必要。
重型引擎,复杂难维护:
# 模拟重型规则引擎(运行过程繁琐,学习成本极高)
class HeavyRuleEngine:
def __init__(self):
self.rules = []
def add_rule(self, condition, action):
self.rules.append((condition, action))
def execute(self, text):
for cond, act in self.rules:
if cond(text):
return act(text)
return "pass"
# 使用
engine = HeavyRuleEngine()
engine.add_rule(lambda t: len(t) < 2, lambda t: "输入无效")
result = engine.execute("唉")
print(result)基础if-else + 正则,轻量高效:
import re
def light_rule_check(text):
# 正则清洗 + 简单判断 = 轻量规则引擎
text = re.sub(r'[^\w\u4e00-\u9fff\s]', '', text).strip()
# 简单规则判断
if len(text) < 2:
return False, "再写多一点点内容吧~"
if "难受" in text or "崩溃" in text:
return "care", text
return True, text
# 测试
print(light_rule_check("唉"))
print(light_rule_check("我好难受"))设计建议总结:
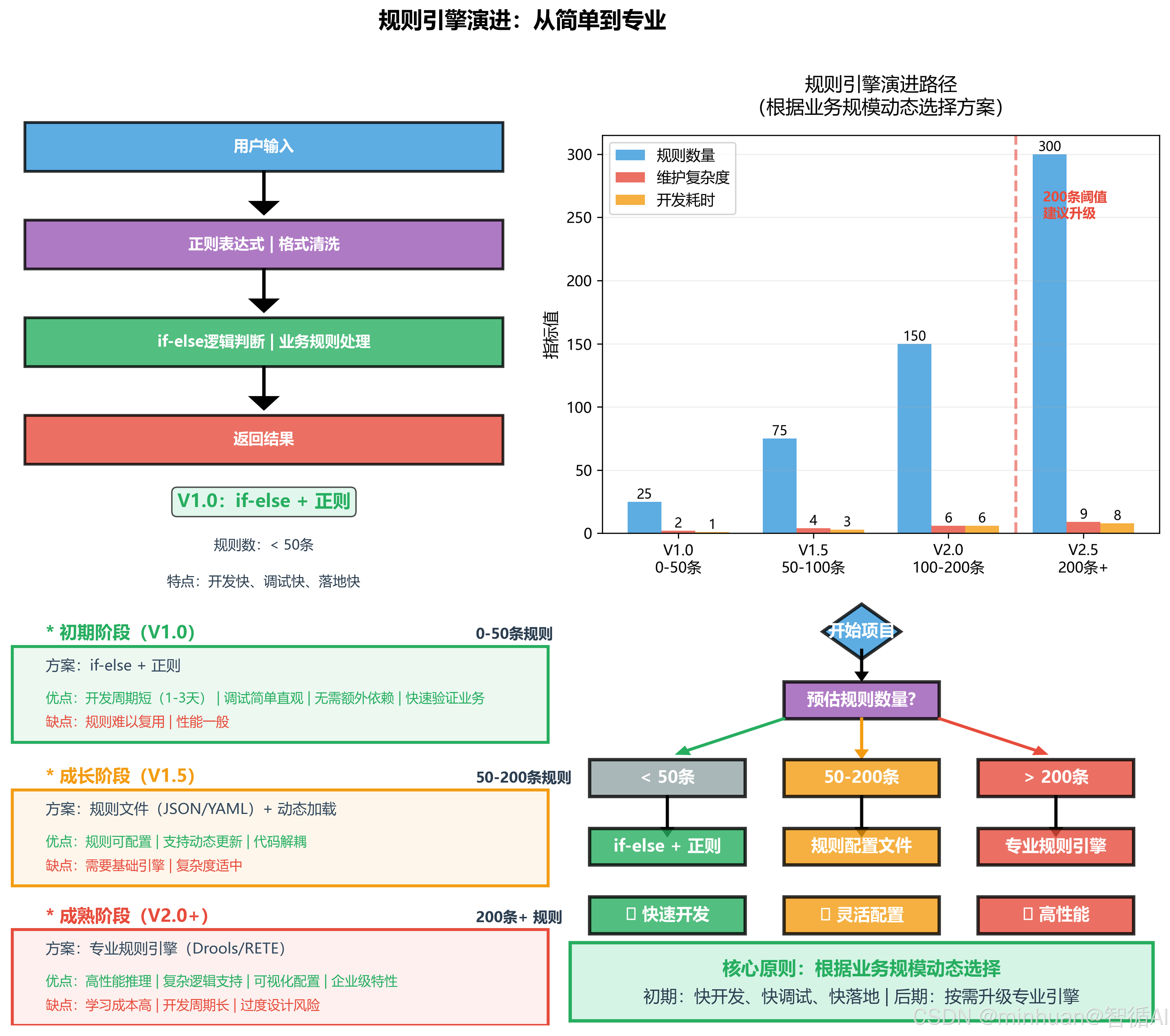
- 初期业务:if-else 完全够用。
- 正则负责清洗格式,if-else 负责逻辑判断。
- 规则超过 200 条、业务量级变大后,再考虑升级引擎。
- 前期目标:快开发、快调试、快落地。
2.3 底层原理
- 重型规则引擎专为金融风控、工业复杂决策、多级权限校验等高精尖复杂场景设计。
- 大模型初创落地阶段,校验逻辑仅包含关键词匹配、正则格式校验、基础长度限制,简单字符串匹配 + 条件判断即可完成全覆盖,重型引擎属于技术架构过度堆砌。
2.4 标准化执行规避流程
- 1. 初期极简方案:Python 原生 if-else 逻辑 + 正则表达式构建轻量校验层
- 2. 分层解耦:将输入清洗、格式校验、基础敏感拦截独立封装函数
- 3. 压力观测:业务量级突破 10 万日交互、规则数量超 200 条后评估升级
- 4. 渐进替换:按需迁移至轻量化配置化规则框架,而非一步到位重型引擎

2.5 对大模型应用的核心价值
- 大幅降低入门学习成本与服务器部署成本;缩短接口响应耗时,减少大模型前置校验等待时间;
- 代码轻量化易调试,适配本地私有化部署、边缘端大模型推理场景。
3. 忽略用户体验,规则至上
3.1 现象表现
依靠固定规则拦截异常输入后,大模型兜底输出标准化冰冷文案:“输入格式无效”、“内容不符合规范,请重新输入”、“信息缺失无法解答”。
无共情语义、无引导提示,用户流失率极高,即便大模型语义能力优秀,整体业务体验依旧拉垮。
3.2 业务场景
拦截时只返回机械语句:“输入无效”、“格式错误”等,缺乏温度,导致用户直接流失。
机械冰冷,缺乏温度:
def bad_reply(text):
if len(text) < 2:
return "输入无效,请补充信息" # 完全无温度
if len(text) > 300:
return "输入超出长度限制"
return "正常回复"
# 测试
print(bad_reply("唉"))共情 + 引导,体验拉满:
def good_reply(text):
friendly_msgs = {
"short": "我还没太理解你的意思呢,可以多告诉我一些吗?",
"long": "内容有点长哦,我们慢慢说,我会认真听~",
"risk": "我特别担心你,愿意和我说说发生什么了吗?"
}
if len(text.strip()) < 2:
return friendly_msgs["short"]
return "我认真听你说,随时都在~"
# 测试
print(good_reply("唉"))设计建议总结:
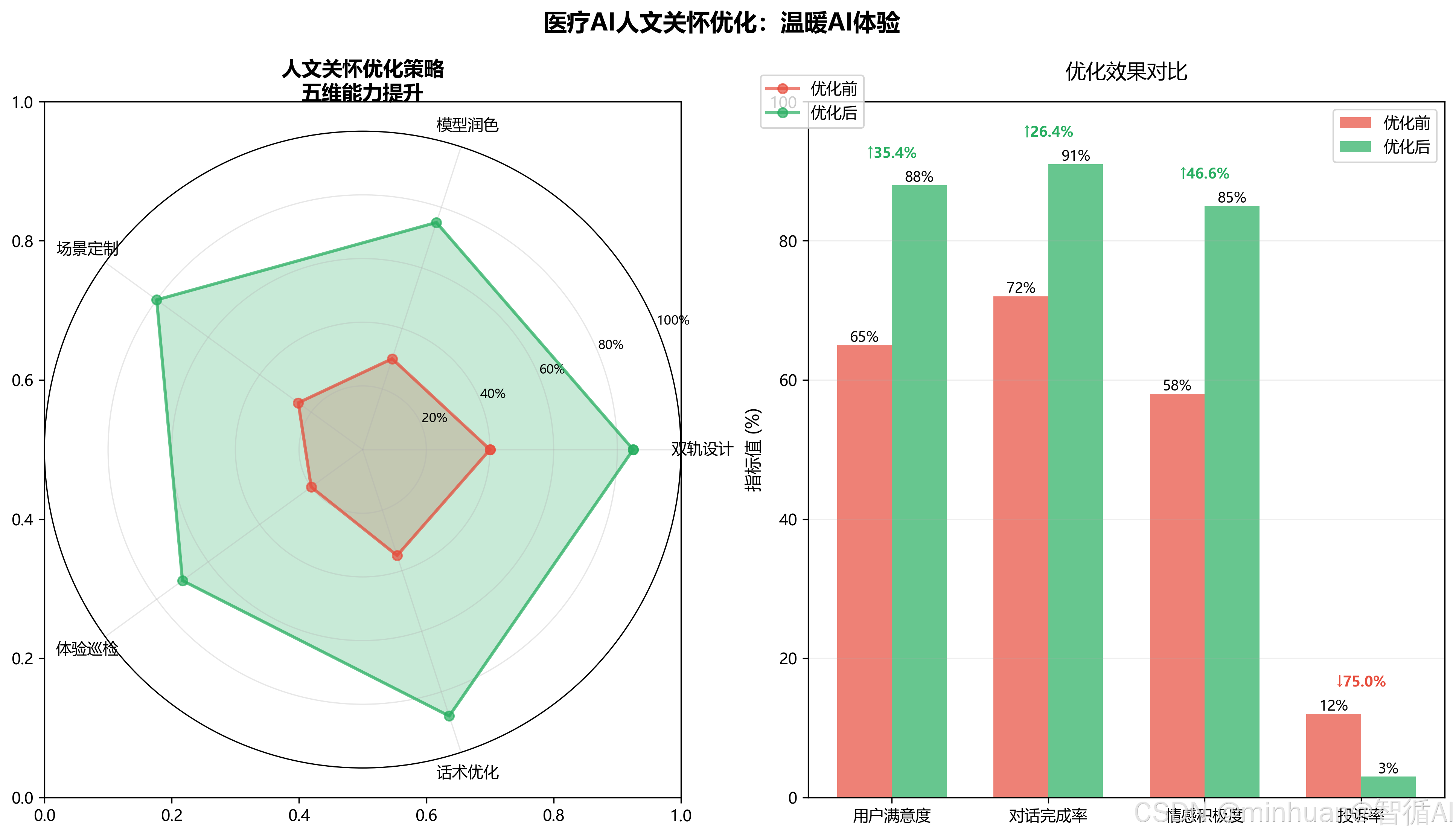
- 大模型的核心价值是拟人沟通。
- 所有拦截必须满足:合规 + 温度 + 引导。
- 尤其心理咨询、客服、教育类场景,体验直接决定留存。
3.3 底层原理
- 大模型优势是自然语言拟人化表达,单纯刚性规则剥夺模型语义润色能力;
- 人机交互核心不仅是合规过滤错误输入,更需要引导用户补充信息、安抚用户情绪。
- 规则保障底线合规,大模型保障交互温度,二者缺一不可。
3.4 标准化执行规避流程
- 1. 双轨设计:所有刚性校验规则绑定两套输出:合规报错文案 + 共情引导话术
- 2. 模型二次润色:基础拦截提示交由轻量化大模型进行口语化改写
- 3. 场景定制:老年用户、政务咨询、医疗问诊等高敏感场景专属温情话术库
- 4. 体验巡检:定期抽检对话日志,剔除机械重复类回复

3.5 对大模型应用的核心价值
- 发挥大模型自然语言生成的原生优势,平衡系统合规刚性与人机交互柔性;
- 提升用户留存与对话完成率,让规则校验不再成为体验短板。
4. 未做本地测试,直接上线
4.1 现象表现
仅使用标准规范文本测试接口通顺性,未覆盖方言口语、模糊短句、错别字连写、老年群体碎片化表达、谐音替代词汇;
上线后大批量容错失效:方言识别错乱、残缺语义理解偏差、恶意输入绕过基础校验,引发线上故障。
4.2 业务场景
只用标准文本测试,上线后发现:老年人说话听不懂、方言识别失败、错别字识别失败。
只测标准场景,未做深度验证:
def quick_test(text):
return "校验通过"
# 只测标准语句
print(quick_test("我最近心情不好"))
# 真实用户输入:方言、口语、错别字、网络词 完全不测本地全场景测试,覆盖真实用户:
def full_process(text):
text = text.strip()
if len(text) < 2:
return "我还没太理解你的意思呢,可以多告诉我一些吗?"
return "别这样哦,生活没有过不去的坎,我会一直陪着你~"
def real_world_test():
test_samples = [
"唉",
"最近只想摆烂",
"心里堵得慌",
"我啥也不想干了",
"生活没意思"
]
for s in test_samples:
print(f"用户:{s}")
print(f"AI:{full_process(s)}\n")
# 启动测试
real_world_test()设计建议总结:
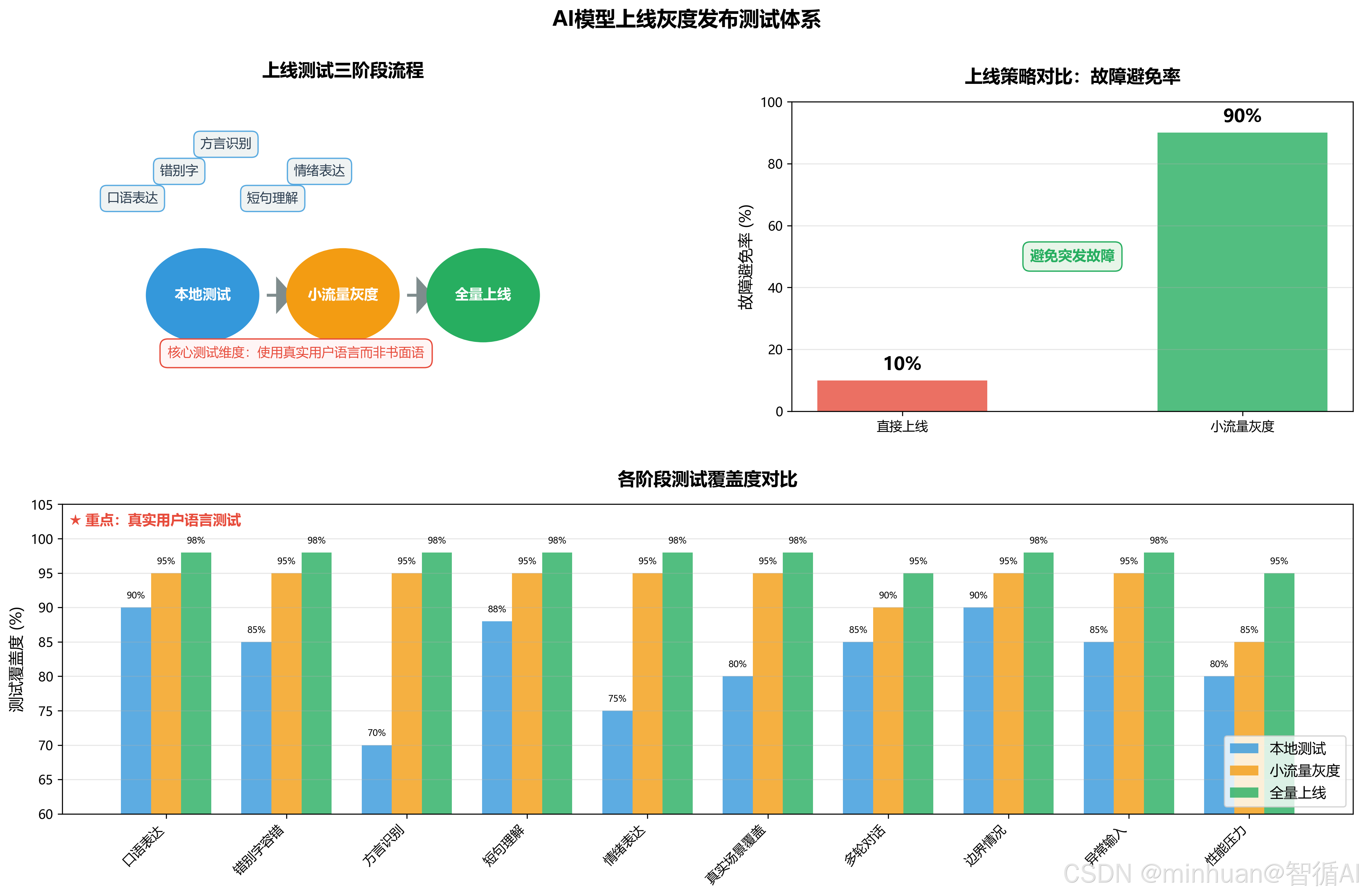
- 上线前必须测:口语、错别字、方言、短句、情绪表达。
- 用真实用户会说的话测试,而不是书面语。
- 本地测试通过 → 小流量灰度 → 再全量上线。
- 能避免 90% 线上突发故障。
4.3 底层原理
- 实验室标准测试集语义规整、句式统一,和真实C端用户原生输入存在巨大鸿沟;
- 大模型对非标文本依赖场景化样本校准,无真实样本本地压测,无法暴露语义识别、规则拦截、异常兜底的隐藏漏洞。
4.4 标准化执行规避流程
- 1. 自建实测数据集:整合方言、错别字、短句残缺、谐音网络用语多类样本
- 2. 本地闭环测试:规则校验层 + 大模型推理层联合本地批量压测
- 3. 灰度小流量放量:仅开放 5% 用户访问,实时监控错误日志与拒绝率
- 4. 问题闭环修复:漏洞统一迭代优化后,再全量正式上线

4.5 对大模型应用的核心价值
- 提前拦截底层语义识别缺陷,规避线上批量事故;
- 优化大模型在非标口语场景的基础适配能力,降低运维应急处置压力。
5. 高危关键词库未更新
5.1 现象表现
- 初始搭建静态敏感词、负面情绪、高危导向关键词库,常年不更新。
- 面对网络衍生新词、隐性心理负面词汇,如躺平、摆烂、emo等抑郁倾向暗语以及新型违规话术无法识别,大模型输出存在严重内容安全隐患。
5.2 业务场景
词库永远不变,无法识别“躺平、摆烂、emo、破防、精神内耗”等抑郁倾向新词。
静态死库,无法识别新词:
# 永远不更新,完全识别不了网络情绪词
risk_words = {"轻生", "自残", "抑郁"}
def static_check(text):
for w in risk_words:
if w in text:
return "高危内容"
return "正常"
# 测试:摆烂、emo 完全识别不到
print(static_check("我只想摆烂"))
print(static_check("我emo了"))动态词库,每周可更新:
# 基础词库
risk_words = {"轻生", "自残", "抑郁"}
# 可更新函数(可定时执行)
def update_risk_words(new_words):
risk_words.update(new_words)
# 每周更新
update_risk_words({"躺平", "摆烂", "emo", "破防", "精神内耗"})
# 检测
def dynamic_check(text):
for w in risk_words:
if w in text:
return False, "我很担心你,愿意和我多说一点吗?"
return True, "正常"
# 测试
print(dynamic_check("我只想摆烂"))
print(dynamic_check("我emo了"))设计建议总结:
- 网络语言、情绪暗语一直在变。
- 高危词库必须每周迭代。
- 漏判隐性情绪 = 严重业务风险。
- 最佳方案:日志采集 + 模型聚类 + 人工审核 + 自动入库。
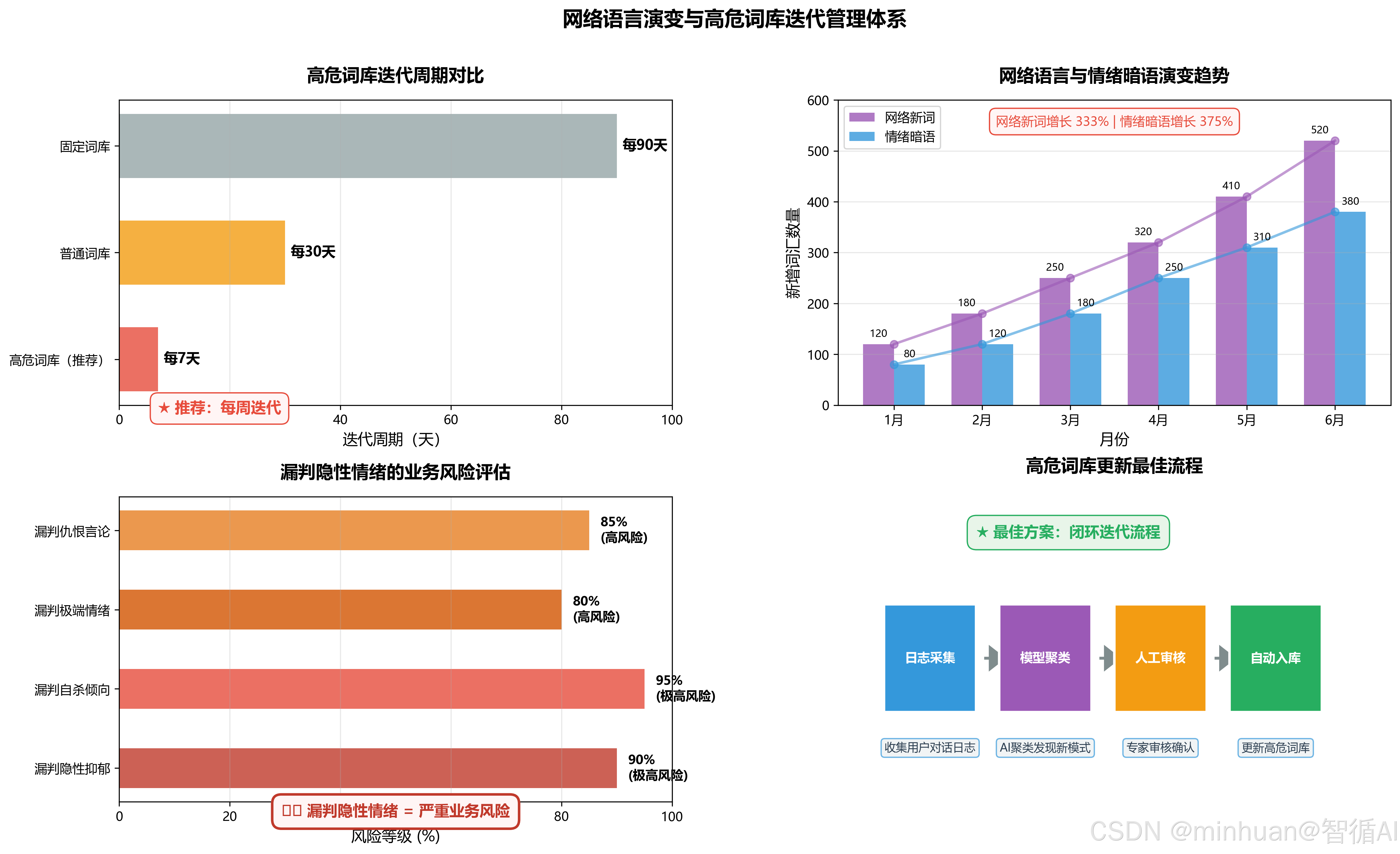
5.3 底层原理
- 网络语义与流行词汇具备极强时效性,隐性负面情绪表达不再直白显露,转而使用圈层化暗语;
- 静态词库无法适配语义演变,单纯精准匹配失效,大模型易误判高危内容,引发合规风险。
5.4 标准化执行规避流程
- 1. 日志周期抓取:每周自动化采集对话交互中模型预警异常语句
- 2. 人工 + 模型双标注:大模型语义聚类筛选新型高危隐性词汇
- 3. 词库增量更新:同步刷新前置规则拦截库 + 大模型安全 Prompt 约束
- 4. 月度复盘抽检:核对新词拦截命中率,优化语义识别阈值

5.5 对大模型应用的核心价值
- 筑牢大模型内容安全防线,识别浅层显性违规 + 深层隐性情绪风险;
- 适配互联网语义动态变化,保障私有化、公网部署双场景合规稳定。
四、基础落地执行总流程
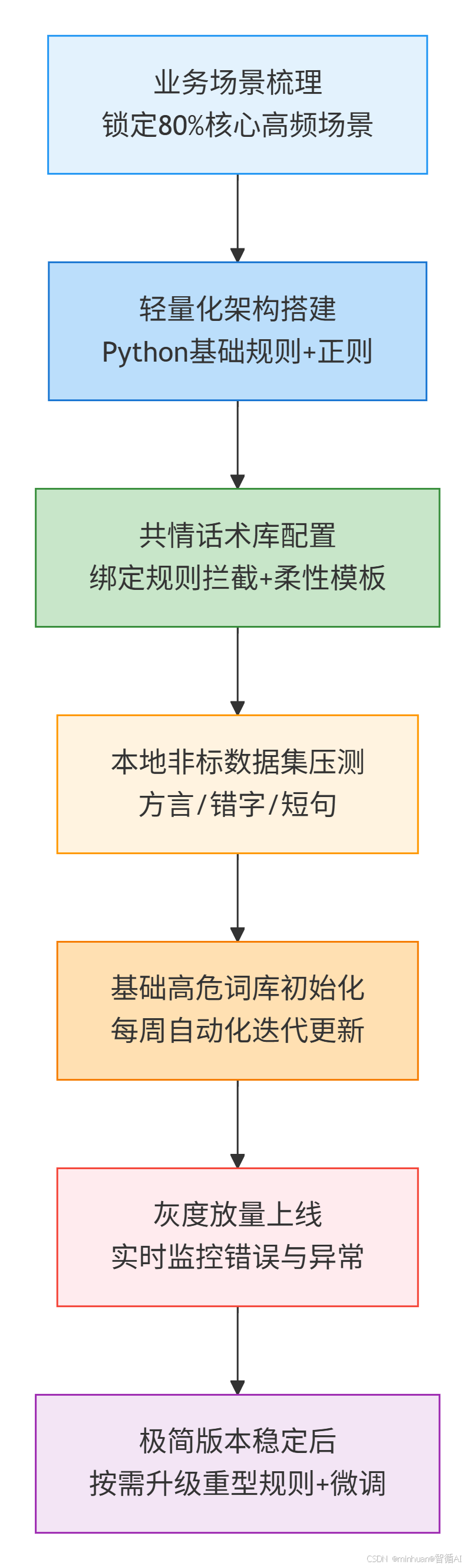
流程细节说明:
- 1. 业务场景梳理 → 锁定 80% 核心高频交互场景
- 2. 轻量化架构搭建 → Python 基础规则 + 正则完成前置清洗校验
- 3. 共情话术库配置 → 绑定规则拦截与大模型柔性输出模板
- 4. 本地非标数据集全量压测 → 方言 / 错字 / 短句多维度验证容错
- 5. 基础高危词库初始化 → 设置自动化每周迭代更新机制
- 6. 灰度放量上线 → 日志实时监控错误与异常命中数据
- 7. 极简版本稳定后 → 按需迭代架构、升级重型规则、优化大模型微调策略
五、应用实践
以下实践内容围绕心理陪伴 AI 对话校验场景,集中演示大模型落地五大典型误区的错误与正确写法对照。从过度设计、笨重规则引擎、冰冷回复、跳过实测、静态敏感词库逐一剖析,依托原生Python与正则实现轻量化规范校验,兼顾交互体验、安全风控与低成本迭代,便于直观理解工程落地核心避坑逻辑。
核心重点:
- 1. 拒绝过度设计,优先落地最小可行容错体系
- 2. 初期用 Python + 正则替代重型规则引擎,降低成本
- 3. 摒弃机械话术,全程搭载共情人文交互表达
- 4. 上线前使用真实口语样本完成全场景本地测试
- 5. 高危词库支持动态周期更新,覆盖新型隐性风险
"""
大模型实战5大典型误区 |错误写法 VS 正确写法 全集统一运行工程
业务场景:心理情绪陪伴对话前置校验系统
"""
import re
print("=" * 70)
print(" 大模型落地五大误区 · 统一完整演示工程")
print("=" * 70)
# ======================== 误区1:过度设计,追求完美容错 ========================
print("\n【误区1演示:过度设计 vs 最小可行容错】")
# ❶ 错误写法:无限制叠加场景,极度臃肿
def error_check_overdesign(text):
if not text:
return "输入为空拒绝"
if len(text) > 500:
return "超长文本拒绝"
if len(text) < 1:
return "短文本拒绝"
if any(c in text for c in "!@#$%^&*()_+-="):
return "特殊符号拒绝"
if any(c in text.lower() for c in "abcdef"):
return "含英文拒绝"
if "啥" in text or "呗" in text:
return "方言口语拒绝"
return "基础勉强通过"
# ❷ 正确写法:最小可行容错,只覆盖80%核心场景
def right_check_minimal(text):
text = text.strip()
if len(text) < 2 or len(text) > 300:
return False, "输入太短或太长啦,我暂时理解不到哦~"
risk_base = {"轻生", "自残", "绝望"}
for word in risk_base:
if word in text:
return False, "感受到你的低落,请务必重视情绪、寻求专业帮助!"
return True, text
# 误区1测试运行
print("错误版结果:", error_check_overdesign("我好难受!abc"))
flag1, msg1 = right_check_minimal("我好难受")
print("正确版结果:", flag1, msg1)
# ======================== 误区2:规则引擎过于复杂笨重 ========================
print("\n【误区2演示:重型复杂引擎 vs Python+正则轻量化】")
# ❶ 错误写法:模拟重型自定义规则引擎,冗余难维护
class ErrorHeavyRuleEngine:
def __init__(self):
self.rules = []
def add_rule(self, cond, act):
self.rules.append((cond, act))
def run(self, txt):
for c,a in self.rules:
if c(txt):return a(txt)
return "校验放行"
engine = ErrorHeavyRuleEngine()
engine.add_rule(lambda t:len(t)<2,lambda x:"输入格式无效")
print("错误重型引擎结果:", engine.run("唉"))
# ❷ 正确写法:if-else + 正则极简实现
def right_light_regex_check(txt):
txt = re.sub(r'[^\u4e00-\u9fa5\w\s]','',txt).strip()
if len(txt) < 2:
return False, "可以多说两句,让我更好理解你~"
if "难受" in txt or "崩溃" in txt:
return "care_emotion", txt
return True, txt
print("正确轻量校验1:", right_light_regex_check("唉"))
print("正确轻量校验2:", right_light_regex_check("我最近心里很难受"))
# ======================== 误区3:规则至上,忽略人文用户体验 ========================
print("\n【误区3演示:机械冰冷回复 vs 共情温暖话术】")
# ❶ 错误写法:纯刚性冷冰冰提示
def error_cold_reply(txt):
s = txt.strip()
if len(s) < 2:
return "输入无效,请补充完整信息"
if len(s) >300:
return "内容超长,拒绝处理"
return "正常应答"
# ❷ 正确写法:全场景共情友好话术
def right_warm_reply(txt):
msg_pool = {
"short":"我还没太明白你的想法,可以再多描述一点吗?",
"long":"内容篇幅过长啦,精简一下感受我们慢慢沟通~"
}
s = txt.strip()
if len(s) <2:
return msg_pool["short"]
if len(s) >300:
return msg_pool["long"]
return "我认真倾听你的倾诉,一直都在~"
print("冰冷错误回复:", error_cold_reply("唉"))
print("共情正确回复:", right_warm_reply("唉"))
# ======================== 误区4:跳过本地实测,直接上线发布 ========================
print("\n【误区4演示:极简草率测试 vs 真实业务全量本地测试】")
# ❶ 错误写法:仅标准短句测试,覆盖极低
def error_simple_online_test(t):
return "校验通过,可以直接上线"
print("草率上线测试结果:", error_simple_online_test("我心情不好"))
# ❷ 正确写法:覆盖口语/短句/网络词/情绪句本地闭环实测
def core_service_flow(text):
t = text.strip()
if len(t) <2:
return "我还没能读懂你的心情,再多说几句好不好?"
return "收到你的心声啦,我耐心陪着你~"
def right_local_full_test():
real_user_cases = [
"唉",
"最近只想躺平摆烂啥也不干",
"心里堵得慌特别难受",
"整个人都emo彻底破防了",
"今天状态挺好一切顺利"
]
for idx,case in enumerate(real_user_cases,1):
res = core_service_flow(case)
print(f"本地实测{idx} | 用户:{case} → AI:{res}")
right_local_full_test()
# ======================== 误区5:高危关键词静态固化不更新 ========================
print("\n【误区5演示:静态死词库 vs 动态迭代高危词库】")
# ❶ 错误写法:固定静态词库,新词全部漏判
error_fixed_risk = {"自杀","自残","杀人"}
def error_static_detect(t):
for w in error_fixed_risk:
if w in t:return "高危拦截"
return "安全放行"
print("静态库检测'摆烂':",error_static_detect("我只想摆烂"))
print("静态库检测'emo':",error_static_detect("我整个人emo住了"))
# ❷ 正确写法:支持每周自动化增量更新词库
right_dynamic_risk = {"自杀","自残","抑郁","绝望"}
def refresh_risk_lib(new_words_list):
global right_dynamic_risk
right_dynamic_risk.update(set(new_words_list))
return len(right_dynamic_risk)
# 模拟每周运维更新流行负面情绪词
refresh_risk_lib(["躺平","摆烂","emo","破防","精神内耗","崩溃无助"])
def right_dynamic_check(text):
for word in right_dynamic_risk:
if word in text:
return False,"我感受到你的低落情绪,请善待自己,必要寻求专业疏导!"
return True,"常规对话安全"
print("动态库检测'摆烂':",right_dynamic_check("我只想摆烂度日"))
print("动态库检测日常倾诉:",right_dynamic_check("今天天气还不错"))
print("\n" + "="*70)
print("工程运行结束:五大踩误区点 错误/正确逻辑 全部对照完成")
print("="*70)输出结果:
====================================================================
大模型落地五大误区 · 统一完整演示工程
====================================================================【误区1演示:过度设计 vs 最小可行容错】
错误版结果: 含英文拒绝
正确版结果: True 我好难受【误区2演示:重型复杂引擎 vs Python+正则轻量化】
错误重型引擎结果: 输入格式无效
正确轻量校验1: (False, '可以多说两句,让我更好理解你~')
正确轻量校验2: ('care_emotion', '我最近心里很难受')【误区3演示:机械冰冷回复 vs 共情温暖话术】
冰冷错误回复: 输入无效,请补充完整信息
共情正确回复: 我还没太明白你的想法,可以再多描述一点吗?【误区4演示:极简草率测试 vs 真实业务全量本地测试】
草率上线测试结果: 校验通过,可以直接上线
本地实测1 | 用户:唉 → AI:我还没能读懂你的心情,再多说几句好不好?
本地实测2 | 用户:最近只想躺平摆烂啥也不干 → AI:收到你的心声啦,我耐心陪着你~
本地实测3 | 用户:心里堵得慌特别难受 → AI:收到你的心声啦,我耐心陪着你~
本地实测4 | 用户:整个人都emo彻底破防了 → AI:收到你的心声啦,我耐心陪着你~
本地实测5 | 用户:今天状态挺好一切顺利 → AI:收到你的心声啦,我耐心陪着你~【误区5演示:静态死词库 vs 动态迭代高危词库】
静态库检测'摆烂': 安全放行
静态库检测'emo': 安全放行
动态库检测'摆烂': (False, '我感受到你的低落情绪,请善待自己,必要寻求专业疏导!')
动态库检测日常倾诉: (True, '常规对话安全')
六、总结
大模型工程落地的核心逻辑,从来不是堆砌复杂技术、追求极致完美架构,而是轻量化起步、合规兜底优先、体验同步兼顾、数据驱动迭代。过度设计会直接拖慢项目落地节奏,重型规则引擎抬高入门门槛与运维成本;规则脱离人文设计会浪费大模型自然语言生成的核心优势;跳过本地实测、静态固化关键词库,更是埋下内容安全与业务稳定性双重隐患。
从底层技术逻辑来看,“轻量规则前置过滤 + 大模型柔性语义交互 + 周期数据迭代优化”是搭建稳定大模型应用的最优路径。先用基础能力搭建最小可行容错体系保障80%核心场景稳定运行,再依托真实用户交互日志完成体验优化、规则升级、词库迭代,循序渐进完善整体架构。这种模式既贴合大模型语义能力的发挥边界,又符合工程化低成本、快上线、稳迭代的基础要求,从根源规避研发全链路高频误区问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 24
24 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)