Java后端拥抱AI开发之个人学习路线 - - Spring AI【第三期】(向量数据库 + RAG检索增强生成)
·
向量化和向量数据库
一、文本向量化
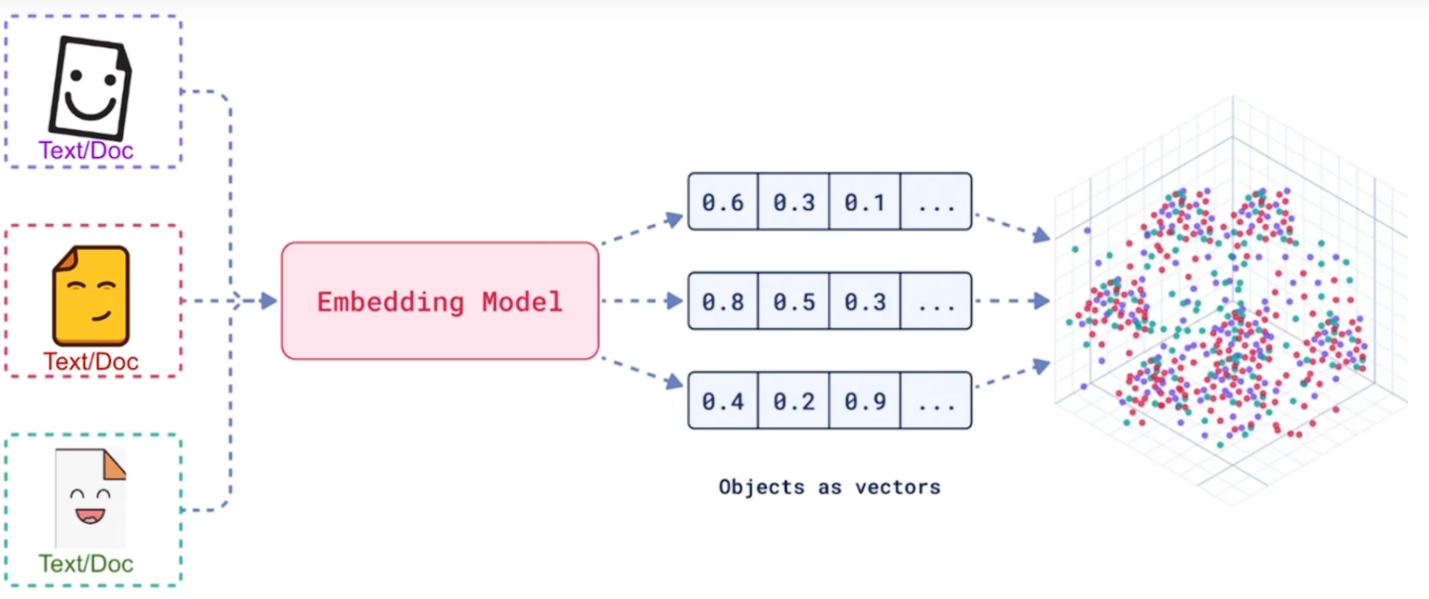
嵌入模型(Embedding Model)
- 嵌入(Embedding)的工作原理是将文本、图像和视频转换为称为向量(Vectors)的浮点数数组。
- 这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维度(Dimensionality)。
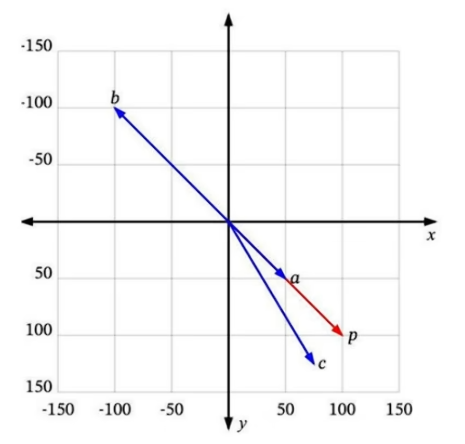
- 如何确定是相似的?
-
- 每个向量都有一个长度和方向。例如,在这个图中,p和a指向相同的方向,但长度不同。p和b正好指向相反的方向,但有相同的长度。然后还有c,长度比p短一点,方向不完全相同,但很接近。因此要么只考虑一个维度,要么同时考虑多个维度
-
二、向量数据库
- 向量存储(VectorStore)是一种用于存储和检索高维向量数据的数据库或存储解决方案,它特别适用于处理那些经过嵌入模型转化后的数据。在VectorStore中,查询与传统关系数据库不同。它们执行相似性搜索,而不是精确匹配。当给定一个向量作为查询时,VectorStore返回与查询向量"相似"的向量。
-
- 其核心功能是通过高效的索引结构和相似性计算算法,支持大规模向量数据的快速查询与分析,向量数据库维度越高,查询精准度也越高,查询效果也越好。
- VectorStore用于将您的数据与AI模型集成。在使用它们时的第一步是将您的数据加载到矢量数据库中。然后,当要将用户查询发送到AI模型时,首先检索一组相似文档。然后,这些文档作为用户问题的上下文,并与用户的查询一起发送到AI模型。这种技术被称为检索增强生成
(Retrieval Augmented Generation, RAG)。 - 常见的向量数据库有:
PGVector、Qdrant、Milvus、PostgreSQL等。
三、编码案例(用RedisStack来实现)
// 1. 引入pom依赖
//<!--spring-ai-alibaba dashscope-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
//<!-- 添加 Redis 向量数据库依赖 -->
<dependency>
<groupId>org.springframeworkframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>
// 2. 配置yml文件
//===SpringAI Alibaba Config===
spring.ai.dashscope.api-key=${aliqwen-api}
spring.ai.dashscope.chat.options.model=qwen-plus
spring.ai.dashscope.embedding.options.model=text-embedding-v3
// =====Redis Stack=====
spring.data.redis.host=localhost
spring.data.redis.port=6379
spring.data.redis.username=
spring.data.redis.password=
spring.ai.vectorstore.redis.initialize-schema=true
spring.ai.vectorstore.redis.index-name=custom-index
spring.ai.vectorstore.redis.prefix=custom-prefix- Redis Stack是什么?
-
- Redis Stack 是Redis Labs 推出的一个"增强版 Redis”,不是Redis 的替代品,而是在原生 Redis 基础上的功能扩展包,专为构建现代实时应用而设计。
- Redis Stack相比原生Redis的优势?
|
功能维度 |
原生 Redis |
Redis Stack 增强功能 |
|
数据结构 |
字符串、列表、集合、哈希等 |
增加 JSON、图、时间序列、概率结构等高级类型 |
|
查询能力 |
仅限键值查询 |
支持全文搜索、向量搜索、图查询、JSON 查询 |
|
使用场景 |
缓存、消息队列、计数器等 |
实时推荐、时序分析、知识图谱、文档数据库、AI 向量检索 |
|
开发体验 |
命令行操作,需手动拼装逻辑 |
提供 RedisInsight 和对象映射库,开发效率更高 |
- Redis Stack核心组件
-
- RediSearch:提供全文搜索能力,支持复杂的文本搜索、聚合和过滤,以及向量数据的存储和检索
- RedisJSON:原生支持JSON数据的存储、索引和查询,可高效存储和操作嵌套的JSON文档
- RedisGraph:支持图数据模型,使用Cypher查询语言进行图遍历查询
- RedisBloom:支持 Bloom、Cuckoo、Count-Min Sketch 等概率数据结构
- 总结一句话:RedisStack=原生Redis+搜索+图+时间序列+JSON+概率结构+可视化工具+开发框架支持
// 3. 如何使用Redis Stack
// 可以使用docker 安装
docker run -d --name redis-stack-server -p 6379:6379 redis/redis-stack-server
// 4. 案例代码
/**
* 文本向量化 + Redis Stack 向量数据库 控制器
* 实现文本向量化、向量存储、向量检索三大核心AI能力
*/
@RestController
@Slf4j
public class Embed2VectorController {
/**
* 注入文本向量化模型(Spring AI 自动配置的通义千问 Embedding 实例)
* 负责将文本转换为向量(Embedding),用于语义表征
*/
@Resource
private EmbeddingModel embeddingModel;
/**
* 注入 Redis Stack 向量存储实例(Spring AI 自动配置)
* 负责向量的持久化存储、相似度检索
*/
@Resource
private VectorStore vectorStore;
/**
* 文本向量化接口
* 调用通义千问 text-embedding-v3 模型,将输入文本转换为向量
* 示例请求:http://localhost:8011/text2embed?msg=射雕英雄传
* @param msg 待向量化的输入文本
* @return 向量化结果(包含向量数组、模型元信息等)
*/
@GetMapping("/text2embed")
public EmbeddingResponse text2Embed(String msg) {
// 构造向量化请求:传入文本 + 指定通义千问 text-embedding-v3 模型
EmbeddingResponse embeddingResponse = embeddingModel.call(
new EmbeddingRequest(
List.of(msg),
DashScopeEmbeddingOptions.builder()
.withModel("text-embedding-v3")
.build()
)
);
// 打印生成的向量到控制台,用于调试验证
System.out.println(Arrays.toString(embeddingResponse.getResult().getOutput()));
return embeddingResponse;
}
/**
* 文本向量化后存入 Redis Stack 向量数据库接口
* 向向量库中添加测试文档,Spring AI 自动完成「文本→向量→存储」全流程
*/
@GetMapping("/embed2vector/add")
public void add() {
// 构造待存储的文档列表(模拟业务中的文本数据)
List<Document> documents = List.of(
new Document("i study LLM"), // 文档1:学习大模型
new Document("i love java") // 文档2:热爱Java
);
// 将文档写入向量库:自动调用 embedding 模型向量化,再持久化到 Redis Stack
vectorStore.add(documents);
}
/**
* 从 Redis Stack 向量数据库进行相似度检索接口
* 根据输入文本,检索向量库中语义最相似的 topK 条文档
* 示例请求:http://localhost:8011/embed2vector/get?msg=LLM
* @param msg 检索用的输入文本(自动向量化后,与库中向量做相似度匹配)
* @return 相似度最高的文档列表
*/
@GetMapping("/embed2vector/get")
public List<Document> getAll(@RequestParam(name = "msg") String msg) {
// 构造相似度检索请求:指定检索文本、返回前2条最相似结果
SearchRequest searchRequest = SearchRequest.builder()
.query(msg)
.topK(2)
.build();
// 调用向量库的相似度检索方法,执行语义检索
List<Document> list = vectorStore.similaritySearch(searchRequest);
// 打印检索结果到控制台,用于调试验证
System.out.println(list);
return list;
}
}

RAG(Retrieval Augmented Generation) 检索增强生成
一、背景 / 概要
LLM的缺陷:
- LLM的知识不是实时的,不具备知识更新。
- LLM可能不知道你私有的领域业务知识。
- LLM有时会在回答中生成看似合理但实际上是错误的信息。
- 如果想让一个LLM了解特定领域的知识或专有数据,可以考虑使用RAG
什么是RAG:
- 简单来说,
RAG(检索增强生成)是一种从你的数据中查找相关信息,并在将提示发送给LLM之前将其注入到提示中的方法。这样一来,LLM就能获得(希望是)相关的信息,并基于这些信息进行回答,从而降低产生幻觉的概率。
-
- 幻觉 --> 已读乱回、已读不会、似是而非
- RAG技术就像给AI大模型装上了「实时百科大脑」,为了让大模型获取足够的上下文,以便获得更加广泛的信息源,通过先查资料后回答的机制,让AI摆脱传统模型的"知识遗忘和幻觉回复"困境。(类似于在你考试前给你塞了个小抄,让你在考场上知道你盲区的知识)
所以RAG能做什么:
- 通过引入外部知识源来增强LLM的输出能力,传统的LLM通常基于其训练数据生成响应,但这些数据可能过时或不够全面。RAG允许模型在生成答案之前,从特定的知识库中检索相关信息,从而提供更准确和上下文相关的回答。
RAG怎么使用:
- RAG的流程分为两个不同的阶段:索引和检索
- 索引(Indexing):索引首先清理和提取各种格式的原始数据,如PDF、HTML、Word和Markdown,然后将其转换为统一的纯文本格式。为了适应语言模型的上下文限制,文本被分割成更小的、可消化的块(chunk)。然后使用嵌入模型将块编码成向量表示,并存储在向量数据库中。这一步对于在随后的检索阶段实现高效的相似性搜索至关重要。知识库分割成chunks,并将chunks向量化至向量库中。
- 检索(Retrieval):在收到用户查询(Query)后,RAG系统采用与索引阶段相同的编码模型将查询转换为向量表示,然后计算索引语料库中查询向量与块向量的相似性得分。该系统优先级和检索最高k(Top-K)块,显示最大的相似性查询。
二、案例编码(AI智能运维助手demo)
需求:AI智能运维助手,通过提供的错误编码,给出异常解释辅助运维人员更好的定位问题和维护系统
技术实现:SpringAl + 阿里百炼嵌入模型text-embedding-v3 + 向量数据库RedisStack + DeepSeek
// 1. 引入pom依赖(略)
// 2. 配置yml文件(略)
// 3. 提供Errorcode脚本让他存入向量数据库Redisstack,形成文档知识库ops.txt
错误码 错误描述
00000 系统 OK 正确执行后的返回
A0001 用户端错误一级宏观错误码
A0100 用户注册错误二级宏观错误码
B1111 支付接口超时
C2222 Kafka 消息解压严重
// 4. 核心代码
/**
* 向量数据库初始化配置类(优化版:增加幂等性去重,避免重复加载向量数据)
* 项目启动时自动将运维错误码文档(ops.txt)向量化并写入Redis Stack向量数据库
* 优化点:通过Redis setnx命令实现幂等控制,防止重复启动项目导致向量数据重复插入
*/
@Configuration
public class InitVectorDatabaseConfig {
/**
* 注入Spring AI自动配置的Redis Stack向量存储实例
* 负责向量的持久化存储、相似度检索
*/
@Autowired
private VectorStore vectorStore;
/**
* 注入类路径下的运维错误码文档资源(ops.txt)
* 文档内容为错误码与对应故障解释,用于构建运维专属知识库
*/
@Value("classpath:ops.txt")
private Resource opsFile;
/**
* 注入RedisTemplate,用于操作Redis的setIfAbsent(setnx)命令
* 实现向量数据加载的幂等性控制,避免重复插入
*/
@Autowired
private RedisTemplate<String, String> redisTemplate;
/**
* Bean初始化后执行的初始化方法(@PostConstruct保证在Bean完成依赖注入后执行)
* 优化后流程:读取文档 → 幂等性去重校验 → 分词拆分 → 向量化入库(仅首次执行)
*/
@PostConstruct
public void init() {
// 1. 读取本地ops.txt运维文档,使用TextReader加载文本文件
TextReader textReader = new TextReader(opsFile);
// 设置文件字符集为系统默认,避免中文乱码
textReader.setCharset(Charset.defaultCharset());
// ========== 优化:增加向量数据去重幂等性控制 ==========
// 2. 从文档元数据中获取源文件路径,作为去重的唯一标识
String sourceMetadata = (String) textReader.getCustomMetadata().get("source");
// 对源文件信息做MD5加密,生成唯一哈希值,避免Redis Key过长、特殊字符问题
String textHash = SecureUtil.md5(sourceMetadata);
// 构造Redis去重Key,格式为「vector-xxx:{文件哈希}」,区分不同业务的向量数据
String redisKey = "vector-xxx:" + textHash;
// 执行Redis setIfAbsent(对应setnx命令):
// - Key不存在:设置成功,返回true → 首次加载,允许入库
// - Key已存在:设置失败,返回false → 已加载过,跳过操作
Boolean retFlag = redisTemplate.opsForValue().setIfAbsent(redisKey, "1");
System.out.println("****向量初始化幂等校验结果 retFlag : " + retFlag);
// 3. 仅当首次加载(Key不存在)时,才执行向量化入库
if (Boolean.TRUE.equals(retFlag)) {
// 文件转换为向量:使用TokenTextSplitter按Token分词拆分长文本
// 解决单段文本过长导致的向量化效果差、检索精度低问题
List<Document> list = new TokenTextSplitter().transform(textReader.read());
// 写入向量数据库RedisStack:Spring AI自动完成文本向量化、持久化全流程
vectorStore.add(list);
System.out.println("-----向量初始化数据加载完成");
} else {
// Key已存在,说明向量数据已完成加载,跳过重复操作
System.out.println("-----向量初始化数据已经加载过,请不要重复操作");
// 若需要严格控制,可取消注释抛出异常,阻止项目重复启动
// throw new RuntimeException("向量数据已加载,禁止重复初始化");
}
}
}
/**
* RAG(检索增强生成)运维错误码智能问答控制器
* 基于Redis Stack向量数据库+通义千问大模型,实现运维故障码精准问答
* 核心流程:用户提问 → 向量库检索相关故障文档 → 大模型结合文档生成专业回答
*/
@RestController
public class RagController {
/**
* 注入通义千问大模型客户端(指定Bean名称为qwenChatClient)
* 负责调用通义千问大模型生成符合运维场景的回答
*/
@Resource(name = "qwenChatClient")
private ChatClient chatClient;
/**
* 注入Redis Stack向量存储实例
* 负责根据用户提问,检索向量库中最相关的运维故障码文档
*/
@Resource
private VectorStore vectorStore;
/**
* 运维错误码RAG问答接口
* 示例请求:http://localhost:8012/rag4aiops?msg=00000
* @param msg 用户提问(支持错误码、运维故障描述)
* @return 流式返回大模型回答(支持前端打字机效果)
*/
@GetMapping("/rag4aiops")
public Flux<String> rag(String msg) {
// 定义系统提示词(System Prompt),严格约束大模型的角色和回答规则
// 确保大模型仅基于给定的错误码文档回答,避免 hallucination(幻觉)
String systemPrompt = """
你是一个专业运维工程师,按照给出的编码/故障信息给出对应故障解释,如果查询不到相关信息,直接回复"找不到对应故障信息"。
""";
// 构建RAG检索增强Advisor:Spring AI封装的RAG核心组件
// 自动完成「用户提问向量化→向量库相似度检索→检索结果注入Prompt上下文」全流程
RetrievalAugmentationAdvisor ragAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.build())
.build();
// 调用大模型生成流式回答
return chatClient.prompt()
// 注入系统提示词,约束大模型行为
.system(systemPrompt)
// 注入用户提问
.user(msg)
// 应用RAG Advisor,自动检索并注入知识库上下文
.advisors(ragAdvisor)
// 开启流式返回,实现前端打字机效果
.stream()
// 提取大模型生成的回答内容
.content();
}
}
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)