从 0 搭建一个 Claude Code:不到 30 行代码构建一个真正的 AI Agent
一个 while 循环 + 一把 Bash,就是全部。
理解这个模式,你就理解了所有现代 AI Agent 的核心骨架。
你是否好奇,像 Claude Code、cursor这样的 AI 编程助手,到底是怎么工作的?它们能读文件、跑测试、看报错、反复迭代——这背后的架构复杂吗?
答案出乎意料地简单:一个 while 循环 + 工具调用。本文将从零解析这个被称为 "Agent Loop" 的核心模式,并带你逐行读懂一个完整的实现。

语言模型的先天缺陷
语言模型很聪明,能推理代码、分析问题、给出方案——但它有一个致命的局限:它活在文字里,碰不到真实世界。
它不能读你磁盘上的文件,不能运行 Python 脚本,不能看到 pytest 的报错,不能查 git log。每次对话,它都只是在处理你输入的文字。
没有循环机制,每次工具调用后,你都得手动把结果粘回对话框。你自己成了那个 Agent Loop——这显然不可持续。
解决方案就是让程序自动完成这件事:把工具执行结果自动喂回模型,让模型继续思考,直到任务完成。这就是 Agent Loop
什么是 Harness 系统
在理解 Agent Loop 之前,有必要先了解一个更宏观的概念:Harness(套件)。
Harness 这个词来自工程领域,原意是"线束"或"约束系统"——比如安全带、马具。在 AI Agent 开发中,Harness 层是指包裹语言模型、让它与外部世界交互的基础设施。
|
层级 |
职责 |
类比 |
|
LLM 核心 |
推理、生成、决策 |
大脑 |
|
Harness 层 |
工具执行、消息管理、循环控制 |
手脚 + 神经系统 |
|
Agent Loop |
Harness 的心跳——驱动整个系统运转 |
心脏 |
Harness 系统最小化的核心,就是今天我们要解析的这个循环。它是模型与真实世界的第一道连接。
Agent Loop 的工作原理
先看整体流程图:
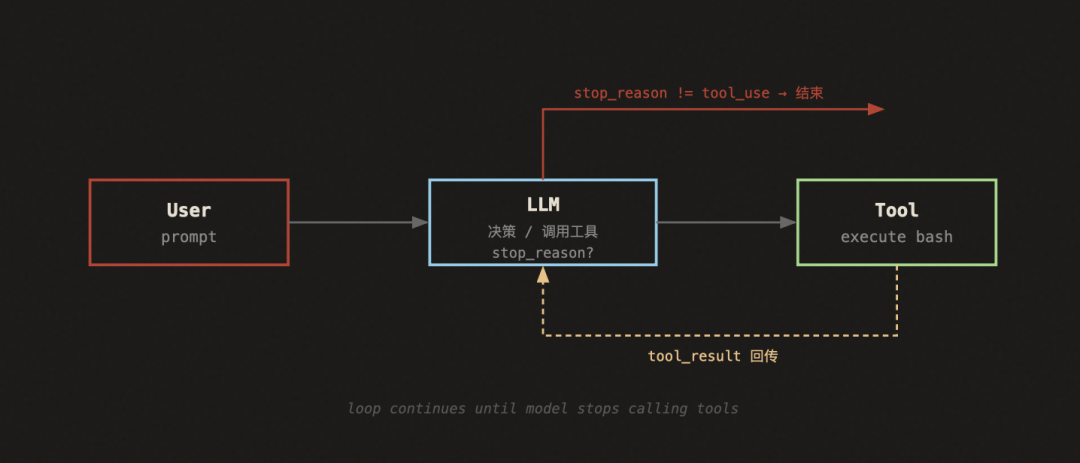
整个逻辑只有一个退出条件:当模型不再调用工具时,循环结束。在此之前,工具结果会被不断追加到消息历史,模型基于完整上下文继续决策。
"One loop & Bash is all you need"
——一个工具 + 一个循环 = 一个 Agent
用户输入 query
│
▼
┌─────────────────────────────────────────────┐
│ agent_loop (核心循环) │
│ │
│ ┌──────────┐ ┌──────────┐ │
│ │ LLM 推理 │───▶│ 判断停机 │ │
│ └────▲─────┘ └────┬─────┘ │
│ │ │ │
│ │ stop_reason? │
│ │ ┌────┴────┐ │
│ │ 是 │ │ 否 │
│ │ (结束) │ ▼ │
│ │ │ ┌──────────┐ │
│ │ │ │ 执行工具 │ │
│ │ │ │ (run_bash)│ │
│ │ │ └────┬─────┘ │
│ │ │ │ │
│ │ │ 工具结果 │
│ │ │ │ │
│ └──────────┴────────┘ │
└─────────────────────────────────────────────┘
│
▼
输出最终文本回复给用户
逐行代码解读
下面是完整实现,我们分段拆解:
① 工具定义
# · 工具定义
TOOLS = [{
"name": "bash",
"description": "Run a shell command.",
"input_schema": {
"type": "object",
"properties": {"command": {"type": "string"}},
"required": ["command"],
},
}]
工具以 JSON Schema 格式声明,传给 Anthropic API。这里只暴露了一个工具:bash,接受一个 command 字符串参数。模型会根据这个定义决定何时调用、传什么参数。
② 安全执行层
#·
RUN_BASH()
def run_bash(command: str) -> str:
dangerous = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"]
if any(d in command for d in dangerous):
return "Error: Dangerous command blocked"
try:
r = subprocess.run(command, shell=True, cwd=os.getcwd(),
capture_output=True, text=True, timeout=120)
out = (r.stdout + r.stderr).strip()
return out[:50000] if out else "(no output)"
except subprocess.TimeoutExpired:
return "Error: Timeout (120s)"
这一层做了三件事:
- 黑名单过滤
:阻断危险命令(rm -rf /、sudo 等)
- 超时保护
:120 秒后强制中止,防止死循环
- 输出截断
:最多返回 50,000 字节,避免撑爆 context window

③ 核心:Agent Loop 本体
# · AGENT_LOOP() — 核心
def agent_loop(messages: list):
while True:
# ① 调用 LLM,传入消息历史 + 工具定义
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,)
# ② 把 assistant 的回复追加进消息历史
messages.append({"role": "assistant", "content": response.content})
# ③ 退出条件:模型没有调用工具,任务完成
if response.stop_reason != "tool_use":
return
# ④ 遍历所有工具调用,执行,收集结果
results = []
for block in response.content:
if block.type == "tool_use":
output = run_bash(block.input["command"])
results.append({
"type": "tool_result",
"tool_use_id": block.id, # 必须与请求 ID 对应
"content": output,})
# ⑤ 把工具结果作为 user 消息追加,回到循环顶部
messages.append({"role": "user", "content": results})
注意 tool_use_id 这个字段——它是工具调用与结果的配对凭证,Anthropic API 要求每条 tool_result 必须通过这个 ID 对应回原始的 tool_use 。这保证了即使模型一次调用多个工具,结果也能被正确归属。
stop_reason 值 含义 循环动作
"tool_use" 模型调用了工具,需要看到结果 继续循环
"end_turn" 模型认为任务完成,直接回复 退出循环
"max_tokens" 达到 token 上限 退出循环
④ REPL 外壳
# · 主程序入口
if __name__ == "__main__":
history = []
while True:
query = input("\033[36ms01 >> \033[0m")
if query.strip().lower() in ("q", "exit", ""):
break
history.append({"role": "user", "content": query})
agent_loop(history) # history 在会话间持续累积
# 打印最终 assistant 文本回复
for block in history[-1]["content"]:
if hasattr(block, "text"):
print(block.text)外层维护一个全局的 history 列表,跨轮次保留完整对话上下文。每次用户输入,都直接追加进去再调用 agent_loop——模型始终能看到完整的对话历史。循环结束后,从 history 的最后一条消息中提取并打印模型的最终文字回复。
一次完整执行的生命周期
- 用户输入 → 追加到 messages
比如:"Create a file hello.py that prints Hello World",作为第一条 user 消息进入 messages 列表。
- 第一次 LLM 调用
模型收到 prompt 和工具定义,决定调用 bash 工具,输出 tool_use 块,stop_reason = "tool_use"。
- 工具执行
程序提取命令(如 echo 'print("Hello, World!")' > hello.py),执行,获得输出。
- 结果追加 → 回到 LLM
工具结果作为 user 消息追加。LLM 再次被调用,看到完整历史后,决定继续调用工具(如运行 python hello.py 验证)或直接结束。
- 循环直到 stop_reason != "tool_use"
模型认为任务完成,输出最终文本回复,循环退出,打印给用户。
循环第 1 轮
────────────────────────────────────────────────
messages = [{"role": "user", "content": "Create a file..."}]
│
▼ 发给 LLM
LLM 思考:"我需要创建文件,用 echo 或 cat 写入内容"
│
▼ 响应
response.stop_reason = "tool_use"
response.content = [
{ type: "tool_use", input: { command: 'echo \'print("Hello, World!")\' > hello.py' } }
]
│
▼ 执行
$ echo 'print("Hello, World!")' > hello.py
(no output)
│
▼ 结果追加
messages = [..., { role: "user", content: [{ tool_result: "(no output)" }] }]
循环第 2 轮
────────────────────────────────────────────────
│
▼ 发给 LLM(含上轮结果)
LLM 思考:"文件已创建,任务完成"
│
▼ 响应
response.stop_reason = "end_turn" ← 不再是 "tool_use"!
response.content = [
{ type: "text", text: "Done! I've created hello.py with a print statement." }
]
│
▼ 退出条件满足,循环结束
│
▼ 输出
"Done! I've created hello.py with a print statement."
为什么这个模式如此强大
这个循环的精妙之处在于:模型自己决定何时停止。你不需要预先规划工具调用次数,不需要写状态机,不需要手动协调步骤。模型基于当前上下文自主判断"任务是否完成"。
这也意味着:你只需要给模型更多工具(文件读写、网络请求、数据库查询……),它的能力边界就会自然扩展,而循环本身一行代码都不需要改。
这正是为什么后续更复杂的 Agent 系统——无论是多工具、多 Agent 协作、带记忆的 Agent——本质上都是在这个循环上叠加机制。循环本身始终不变。
消息历史累积过程可视化
history 随着循环不断增长:
初始: [user: "创建 hello.py"]
第1轮后: [user: "创建 hello.py", assistant: [tool_use: echo...], user: [tool_result: ok]]
第2轮后: [user: "创建 hello.py", assistant: [tool_use: echo...], user: [tool_result: ok],
assistant: [text: "Done!"]]
↑ 最终停在这里,不再循环每次循环,messages 列表至少增长 2 条(1 条 assistant + 1 条 user/tool_result),这就是"累积式消息列表"的含义。
关键设计思想总结

这段不到 30 行的循环,就是所有 AI Agent 的"DNA"。后续的所有复杂机制(多轮对话管理、工具权限、生命周期钩子等),都是在这个循环之上叠加的。循环本身——始终不变。
理解了这个最小化的 Agent Loop,你已经掌握了现代 AI Agent 系统的核心骨架。接下来自然会延伸出的问题:

后期我们将一步一步带领大家攻克一个一个问题,让你自己可以搭建一个类似 Claude code 的 CLI 工具。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 25
25 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)