我愿意为这个工具花 1000 美元,可它居然完全免费 ——Skill Seekers,重新定义 AI 系统的底层数据层
在 AI 开发的圈子里,有一个所有人都心照不宣的痛点:我们能用上推理能力堪比人类的大模型,能搭建出自动化运行的 AI Agent,能用上 Cursor、Claude Code 这样的 AI 编码助手,但 90% 的翻车事故,从来都不是模型不够聪明,而是AI 拿到的知识是错的、过时的、和真实代码脱节的。
你一定遇到过这样的场景:让 Claude Code 基于一个开源项目写集成代码,它输出的内容逻辑完美,却一运行就报错,因为项目的代码已经更新了 3 个版本,而 AI 用的还是 2 年前的旧文档;你花了几天时间给企业内部 AI 助手搭 RAG 流水线,把代码仓库、产品文档、API 手册全部切片向量化,结果 AI 还是频繁出现幻觉,因为它根本分不清文档里的废弃 API 和代码里的最新实现;你想给 Claude 做一个专属的 AI 技能,却要花大量时间写解析脚本、处理文档与代码的同步、适配 MCP 协议,最终 80% 的工作量都耗在了数据处理上,而不是 AI 能力本身。
这就是 AI 行业长期存在的底层短板:我们给 AI 打造了足够强大的 “大脑”,却始终没有给它一个可靠、实时、结构化的 “知识消化系统”。直到 Skill Seekers 的出现,这个行业顽疾终于有了终极解决方案。
我愿意为这个工具支付 1000 美元,可它不仅完全免费,还以 MIT 协议完全开源。它的创作者给它的定位简单又精准:The data layer for AI systems(AI 系统的数据层)。它把 AI 开发里最痛苦、最耗时、最容易出错的环节,实现了全自动化,让任何人都能在几分钟内,把任意文档、代码仓库、多源数据,转化为 AI 可直接使用的结构化知识资产,甚至一键打包成可安装的 AI 技能。
直击行业痛点:Skill Seekers 到底解决了什么问题?
在拆解它的技术能力之前,我们必须先搞清楚:为什么 AI 系统的数据层,是整个行业卡了很久的瓶颈?
当下的 AI 应用开发,无论是 AI 编码助手、RAG 流水线,还是多智能体系统,核心逻辑都是 “大模型 + 外部知识”。但绝大多数开发者的知识处理方式,都停留在非常原始的阶段:
- 处理代码仓库,就是把所有代码文件打包成文本,简单切片向量化,完全不理解代码的语法结构、函数依赖、类与方法的对应关系;
- 处理文档,就是把 PDF、网页内容做文本拆分,根本无法实现文档内容与代码实现的交叉校验,最终 AI 拿到的知识,永远存在 “文档过时、代码更新、二者脱节” 的致命问题;
- 想把第三方项目封装成 AI 技能,需要手动适配 MCP 协议、写工具函数、处理数据解析,门槛极高,非专业开发者根本无法上手。
这些问题最终导致的结果,就是 AI 的 “知识幻觉”:哪怕大模型的推理能力再强,基于错误、过时的知识给出的答案,永远都是错的。而 Skill Seekers 的核心价值,就是从根源上解决了这个问题 —— 它不是简单的文本切片工具,而是一个专为 AI 系统设计的、深度结构化的知识处理引擎,能把分散、非结构化、甚至互相冲突的多源数据,转化为 AI 能精准理解、安全使用的结构化知识资产。
核心技术能力:把 AI 知识处理的效率,从小时级压缩到分钟级
Skill Seekers 的能力,远不止简单的文档抓取与解析,它的四大核心技术模块,构建了一个完整的 AI 知识处理闭环,每一个模块都精准命中了 AI 开发的核心痛点。
1. 全量多源数据接入,一键生成结构化知识资产
Skill Seekers 的基础能力,是实现了 10 + 种数据源的全量接入与结构化转换,覆盖了开发者日常使用的几乎所有知识载体:官方文档站点、GitHub 代码仓库、PDF 文件、教学视频、Jupyter Notebook、技术 Wiki 等等。
它不是简单的文本爬取,而是把这些异构的数据源,统一转化为 AI 系统可直接使用的结构化知识资产,开箱即用地适配三大核心 AI 场景:
- 大模型 AI 技能:直接适配 Claude、Gemini、OpenAI 等主流大模型,一键生成可安装的自定义 AI 技能;
- RAG 流水线:完美兼容 LangChain、LlamaIndex、Pinecone 等主流 RAG 框架,无需额外开发,直接接入检索增强流程;
- AI 编码助手:原生适配 Cursor、Windsurf、Cline 等主流 AI 编码工具,为编码助手提供实时、精准的代码库知识。
最关键的是,整个过程只需要几分钟,而不是传统方式的几个小时甚至几天。哪怕是一个拥有数十万行代码、上百篇技术文档的大型开源项目,Skill Seekers 也能快速完成全量解析与结构化转换,让 AI 在几分钟内,彻底读懂一个复杂项目。
2. 深度 AST 语法解析,自动检测文档与代码的冲突
这是 Skill Seekers 最核心的技术壁垒,也是它区别于所有 RAG 工具的核心优势:它实现了多语言的深度 AST 抽象语法树解析,能精准定位文档与代码的脱节问题。
目前,它已经完美支持 Python、JavaScript、TypeScript、Java、C++、Go 六大主流编程语言,能对代码仓库进行深度 AST 解析,精准提取仓库里的每一个函数、类、方法,完整保留对应的参数、类型定义、依赖关系与实现逻辑。在此基础上,它会把解析后的代码结构,与项目的文档内容进行交叉引用与校验,精准找出 “文档里写的 API 已经废弃”“代码更新了但文档没同步”“参数类型与文档描述不符” 等所有冲突点。
这个能力,直接从根源上解决了 AI 编码最致命的 “过时幻觉” 问题。在此之前,AI 编码助手给出的代码之所以频繁报错,核心原因就是它只能拿到静态的、过时的文档知识,不知道代码的最新变化。而 Skill Seekers 能告诉 AI:文档里的这个 API 已经更新了,最新的参数是这些,文档里的描述是错误的,正确的用法应该是这样。
对于开发者来说,这意味着再也不用花大量时间,去给 AI 纠错、喂最新的代码文档;对于开源项目维护者来说,这意味着能快速定位仓库里文档与代码不同步的问题,大幅降低维护成本;对于企业用户来说,这意味着内部 AI 编码助手,永远能拿到与最新代码同步的精准知识,从根源减少 AI 生成的错误代码。
3. 原生 MCP 服务器集成,26 个工具实现自然语言全流程操作
MCP(模型上下文协议)是当下 AI Agent 生态的核心标准,也是 Claude Code 实现自定义工具扩展的核心载体。而 Skill Seekers 直接以 MCP 服务器的形式运行,内置了 26 个开箱即用的工具,彻底抹平了 AI 技能开发的门槛。
最颠覆性的一点是:你完全不需要触碰 CLI 命令行,不需要写任何配置代码,只用自然语言告诉 Claude Code,它就能调用 Skill Seekers 完成全流程操作。你只需要说一句 “帮我爬取这个 GitHub 仓库,检测文档与代码的冲突,合并所有知识源,打包成一个可安装的 AI 技能”,Claude 就能通过 MCP 协议,自动调用 Skill Seekers 的所有能力,全程无需人工干预。
这意味着,哪怕你是完全不懂技术的产品经理、运营人员,也能在几分钟内,把任意一个项目、一套文档,转化为 Claude 里的专属 AI 技能。你不用懂 MCP 协议,不用懂代码解析,不用懂数据处理,所有复杂的技术细节,全部被 Skill Seekers 封装成了 AI 可直接调用的能力。
4. 三流 GitHub 架构,让 AI 真正读懂开源项目的全貌
针对 GitHub 代码仓库这个最核心的知识源,Skill Seekers 设计了独创的三流架构,彻底改变了传统 RAG 工具处理代码仓库的粗放模式。
它把一个 GitHub 仓库,拆分为三大独立又互相关联的数据流:
- Code 流:仓库里的所有代码文件,经过 AST 深度解析,结构化存储函数、类、方法、参数等核心信息;
- Docs 流:仓库里的所有文档、README、Wiki、注释,经过语义解析,与 Code 流做精准关联与交叉校验;
- Insights 流:仓库的 Issues、Labels、Stars、Forks 等社区数据,全部作为加权信号,纳入知识体系。
这个架构的核心优势,是让 AI 不仅能读懂项目的代码和文档,还能读懂项目的社区生态与核心痛点。比如,AI 能通过 Issues 数据,知道这个项目最常见的使用问题是什么;通过 Stars 与 Forks 的加权信号,知道哪些模块是项目的核心高频使用模块;通过 Labels 标签,精准定位到用户需要的特定场景解决方案。
传统的 RAG 工具,处理 GitHub 仓库就像把一本书全部撕碎混在一起,让 AI 在碎纸里找答案;而 Skill Seekers 的三流架构,是给这本书做了完整的目录、索引、批注、读者反馈汇总,让 AI 能精准、快速地找到最有价值的信息,同时彻底理解项目的全貌。
成熟的开源生态:从个人使用到企业级部署的全链路覆盖
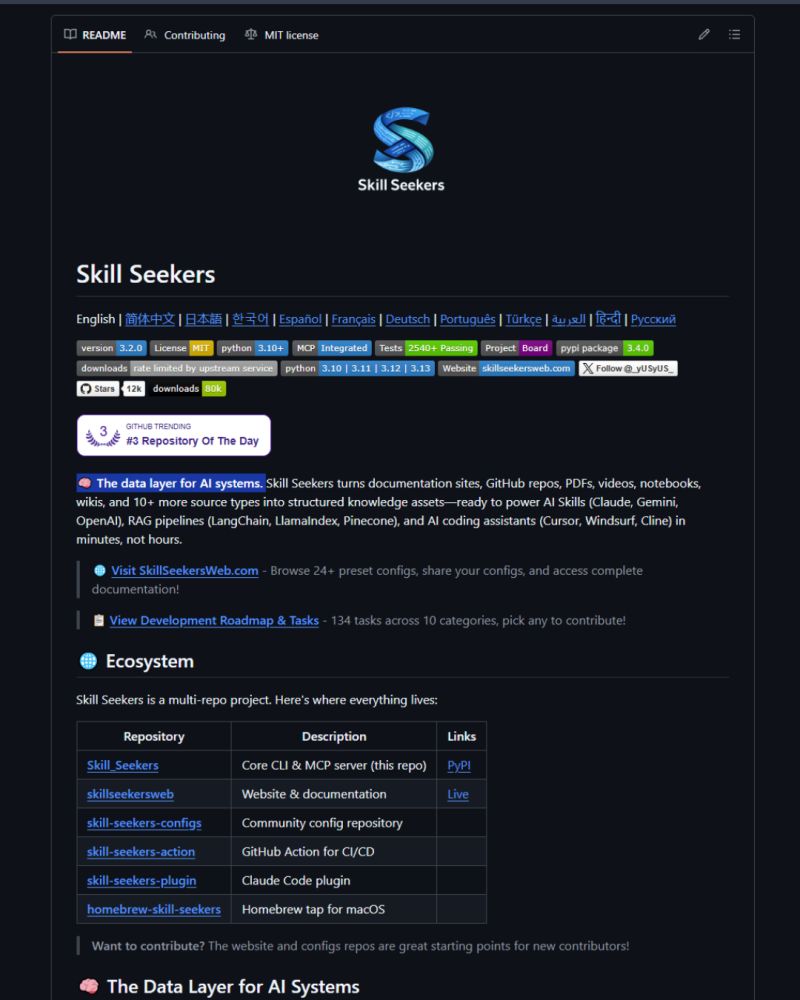
从项目的 GitHub 主页可以看到,Skill Seekers 早已不是一个小众的玩具,而是一个成熟度极高、生态完善的生产级工具,它的各项数据足以证明行业对它的认可:
- 版本迭代至 3.2.0,通过了 2540 + 项测试,全量兼容 Python 3.10 至 3.13 的所有主流版本;
- 斩获 12k+ GitHub Stars,累计下载量突破 80k,曾登顶 GitHub Trending 日榜第 3 名;
- 原生支持 15 种语言,包括简体中文、英语、日语、韩语、法语、德语等,覆盖全球绝大多数开发者;
- 采用最宽松的 MIT 开源协议,个人与企业均可免费使用、修改、二次分发,无任何商业使用限制。
更难得的是,Skill Seekers 不是一个单一的工具,而是一个完整的多仓库生态项目,覆盖了从使用、部署、二次开发到 CI/CD 集成的全场景:
- 核心仓库:提供核心 CLI 工具与 MCP 服务器,是整个项目的核心引擎;
- 官网与文档站:提供 24 + 开箱即用的预设配置,完整的使用文档与教程,新手也能快速上手;
- 社区配置仓库:全球开发者共享的配置文件,覆盖了主流的开源项目、技术框架,拿来即用;
- GitHub Action:专为 CI/CD 流程设计的自动化工具,可集成到企业的开发流水线中,实现知识资产的自动更新与同步;
- Claude Code 插件:原生适配 Claude 的插件系统,无需配置 MCP 服务器,一键安装即可使用;
- Homebrew 安装包:专为 macOS 用户打造的一键安装渠道,一行命令即可完成部署。
对于新手开发者,它提供了开箱即用的预设配置,零门槛就能上手;对于资深开发者,它提供了完整的自定义能力与开源代码,可自由修改、二次开发;对于企业用户,它提供了 CI/CD 集成能力,可与企业内部的代码仓库、开发流程深度融合,打造专属的内部 AI 知识体系。
行业级的颠覆:AI 的竞争,早已从模型层转向了数据层
当下的 AI 行业,所有人都在追逐更大的模型、更强的推理能力,但很少有人意识到:大模型的能力已经进入了趋同期,AI 系统的核心瓶颈,早已不是模型的 “智商”,而是给模型喂数据的 “数据层”。
同样的 Claude 3.7 Sonnet 大模型,你给它喂的是简单切片的过时文档,它就是一个频繁出错、只能写 Demo 的玩具;你给它喂的是 Skill Seekers 处理后的结构化、实时、无冲突的知识资产,它就是一个能落地到生产环境、精准完成复杂开发任务的专业工具。这就是数据层的力量。
Skill Seekers 的颠覆性,就在于它把 AI 系统的核心数据层,从 “需要专业团队花几个月搭建的奢侈品”,变成了所有人都能免费使用、开箱即用的基础设施。它解决了 AI 落地过程中最脏、最累、最容易被忽略,却又最核心的问题:如何让 AI 拿到精准、实时、结构化的知识。
对于个人开发者,它意味着你再也不用花 80% 的时间做数据处理,能把全部精力放在 AI 能力的设计与创新上;对于企业,它意味着能快速搭建起与内部代码、文档实时同步的 AI 知识体系,大幅降低 AI 幻觉带来的生产风险;对于开源社区,它意味着优秀的开源项目,能以极低的门槛被 AI 理解与使用,彻底打破开源项目的使用壁垒。
结尾:免费的工具,却撑起了 AI 系统的底层根基
很多人问我,2024 年以来,AI 行业最让我惊喜的工具是什么?我的答案从来不是哪个新的大模型,而是 Skill Seekers。
因为大模型的迭代,永远是少数科技巨头的游戏;而 Skill Seekers 这样的工具,给了每一个普通开发者,平等搭建高质量 AI 系统的能力。它没有炫酷的交互界面,没有刷屏的营销通稿,却默默填补了 AI 系统里最核心的一块短板 —— 它就是 AI 世界的自来水管道,你可能不会每天关注它,但没有它,再强大的 AI 模型,也只是无水之木。
更难得的是,这样一个我愿意花 1000 美元购买的工具,却选择了完全开源、完全免费。它的社区还在高速成长,开发路线图上有 134 个待完成的任务,覆盖 10 个核心分类,全球的开发者都在为它贡献力量。
AI 的未来,从来不是靠更大的模型单打独斗,而是靠完善的基础设施生态,让 AI 能真正理解、适配、融入真实的代码与业务世界。而 Skill Seekers,正在用免费、开源的方式,为整个 AI 行业,搭建起最坚实的底层数据层。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)