在YOLO11中引入平移可变但跨图像共享的新型卷积算子 Translation Variant Convolution(TVConv),实现涨点,保姆级别教程
一、TVConv介绍
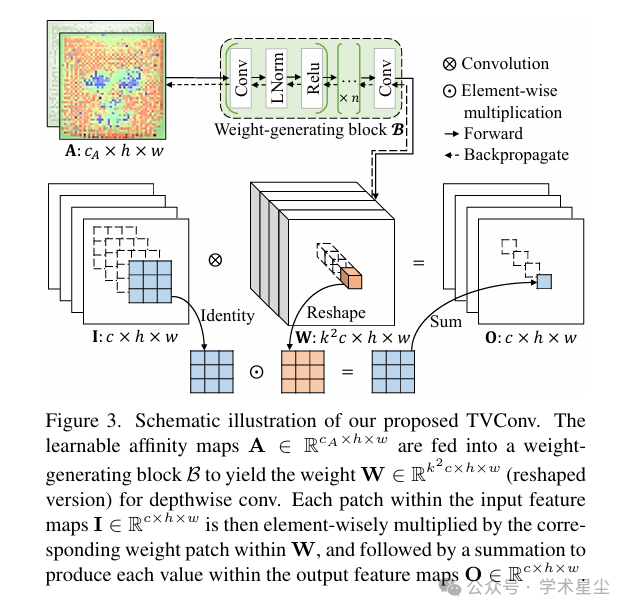
TVConv 的整体思路是,先通过一组可学习的 Affinity Maps 描述图像中的空间布局关系,再利用权重生成模块将这些空间映射转化为位置相关的卷积核,最终在单张图像内部对不同空间位置采用不同卷积权重进行卷积计算。通过这一设计,TVConv 在不显著增加推理成本的前提下,使卷积算子具备了更强的空间结构感知能力,尤其适合处理具有固定布局先验的视觉任务。
适用场景
TVConv 适用于那些图像内部空间差异明显、但跨图像整体结构较稳定的视觉任务。例如,在人脸识别、人脸验证等任务中,人脸的整体布局相对固定,但眼睛、鼻子、嘴巴等局部区域具有明显不同的语义功能;在医学影像分析中,例如视盘/视杯分割等任务,也往往存在较稳定的解剖结构布局;此外,在工业缺陷检测、版式固定的目标检测或分割任务中,TVConv 同样具有较强适配性。总体而言,它特别适合处理“图像内部差异大、跨图像结构相似”的场景。
发挥作用
TVConv 的核心作用是让卷积算子显式感知空间位置差异,从而提升模型对结构化布局的建模能力。对于轻量化网络而言,它可以在保持高效率的同时补足传统 depthwise convolution 对空间位置不敏感的不足,因此尤其适合作为 MobileNet、ShuffleNet 等轻量架构中的可替换模块使用。相比普通 depthwise convolution,TVConv 往往能够在相近甚至更低的计算代价下获得更优性能和更强泛化能力。
二、模块代码
这原始模块代码,不是最终插入YOLO11模型的代码
import torch
import torch.nn as nn
"""
class _ConvBlock(nn.Sequential):
"""
_ConvBlock类定义了一个简单的卷积块,包含卷积层、层归一化和ReLU激活函数。
"""
def __init__(self, in_planes, out_planes, h, w, kernel_size=3, stride=1, bias=False):
# 计算填充大小,使得输出大小与输入大小相同
padding = (kernel_size - 1) // 2
super(_ConvBlock, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, bias=bias), # 卷积层
nn.LayerNorm([out_planes, h, w]), # 层归一化
nn.ReLU(inplace=True) # ReLU激活函数
)
class TVConv(nn.Module):
"""
TVConv类定义了一个基于位置映射的空间变体卷积模块。
"""
def __init__(self,
channels,
TVConv_k=3,
stride=1,
TVConv_posi_chans=4,
TVConv_inter_chans=64,
TVConv_inter_layers=3,
TVConv_Bias=False,
h=3,
w=3,
**kwargs):
super(TVConv, self).__init__()
# 注册缓冲区变量,表示卷积核大小、步长、通道数等
self.register_buffer("TVConv_k", torch.as_tensor(TVConv_k))
self.register_buffer("TVConv_k_square", torch.as_tensor(TVConv_k**2))
self.register_buffer("stride", torch.as_tensor(stride))
self.register_buffer("channels", torch.as_tensor(channels))
self.register_buffer("h", torch.as_tensor(h))
self.register_buffer("w", torch.as_tensor(w))
self.bias_layers = None
# 计算输出通道数
out_chans = self.TVConv_k_square * self.channels
# 初始化位置映射参数
self.posi_map = nn.Parameter(torch.Tensor(1, TVConv_posi_chans, h, w))
nn.init.ones_(self.posi_map) # 用1初始化
# 创建权重层和偏置层
self.weight_layers = self._make_layers(TVConv_posi_chans, TVConv_inter_chans, out_chans, TVConv_inter_layers, h, w)
if TVConv_Bias:
self.bias_layers = self._make_layers(TVConv_posi_chans, TVConv_inter_chans, channels, TVConv_inter_layers, h, w)
# 初始化 Unfold 模块,用于提取局部区域
self.unfold = nn.Unfold(TVConv_k, 1, (TVConv_k-1)//2, stride)
def _make_layers(self, in_chans, inter_chans, out_chans, num_inter_layers, h, w):
"""
创建卷积层序列。
"""
layers = [_ConvBlock(in_chans, inter_chans, h, w, bias=False)]
for i in range(num_inter_layers):
layers.append(_ConvBlock(inter_chans, inter_chans, h, w, bias=False))
layers.append(nn.Conv2d(
in_channels=inter_chans,
out_channels=out_chans,
kernel_size=3,
padding=1,
bias=False)) # 最后一层卷积
return nn.Sequential(*layers)
def forward(self, x):
# 计算卷积权重
weight = self.weight_layers(self.posi_map)
weight = weight.view(1, self.channels, self.TVConv_k_square, self.h, self.w) # torch.Size([1, 64, 9, 32, 32])
# 利用 Unfold 模块获取局部区域,并按照权重进行加权求和
out = self.unfold(x).view(x.shape[0], self.channels, self.TVConv_k_square, self.h, self.w) # torch.Size([2, 64, 9, 32, 32])
"""
weight * out:对这两个张量在 TVConv_k_square 维度上进行逐元素相乘。这个操作相当于对每个位置的局部区域应用一个位置特定的卷积核。
.sum(dim=2) :在TVConv_k_square维度上对乘积结果进行求和。TVConv_k_square 代表卷积核的展开大小(即核的面积),
所以这个求和操作相当于对每个局部区域的卷积结果进行加权求和,类似于传统卷积操作。
"""
out = (weight * out).sum(dim=2) #实现了基于位置的加权卷积操作,生成了一个新的特征图。 # torch.Size([2, 64, 32, 32])
if self.bias_layers isnotNone:
# 如果使用偏置,则加上偏置
bias = self.bias_layers(self.posi_map)
out = out + bias
return out
if __name__ == "__main__":
# 生成随机的输入和位置映射
input = torch.rand(2, 64, 32, 32) # 输入张量为NCHW格式
# 创建TVConv模块
model = TVConv(64, h=32, w=32)
# 运行TVConv模块
output = model(input)
print('input_size:', input.size()) # 打印输入尺寸
print('output_size:', output.size()) # 打印输出尺寸
total_params = sum(p.numel() for p in model.parameters())
print(f'Total parameters: {total_params / 1e6:.2f}M')三、改进步骤
第一步 创建自定义模块文件
在 ultralytics/nn/modules/ 目录下,新建一个 Python 脚本,命名为 custom_tvconv.py,并将以下经过完全适配和重构的代码复制进去:
# ultralytics/nn/modules/custom_tvconv.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.nn.modules.conv import Conv
class _ConvBlockDynamic(nn.Sequential):
"""
改进版的 _ConvBlock,使用 BatchNorm2d 替代固定尺寸的 LayerNorm,支持动态分辨率。
"""
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, bias=False):
padding = (kernel_size - 1) // 2
super(_ConvBlockDynamic, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, bias=bias),
nn.BatchNorm2d(out_planes), # 替换为 BatchNorm2d,不再依赖固定的 H 和 W
nn.ReLU(inplace=True)
)
class TVConv_YOLO(nn.Module):
"""
为 YOLO11 适配的 TVConv (空间变体卷积) 模块
"""
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.channels = c1
self.k_square = k**2
# 基础的位置图,尺寸不重要,前向传播时会动态插值
TVConv_posi_chans = 4
self.posi_map = nn.Parameter(torch.ones(1, TVConv_posi_chans, 20, 20))
out_chans = self.k_square * self.channels
inter_chans = 64
# 权重生成网络
layers =[_ConvBlockDynamic(TVConv_posi_chans, inter_chans, kernel_size=3, bias=False)]
for _ in range(2): # TVConv_inter_layers - 1
layers.append(_ConvBlockDynamic(inter_chans, inter_chans, kernel_size=3, bias=False))
layers.append(nn.Conv2d(inter_chans, out_chans, kernel_size=3, padding=1, bias=False))
self.weight_layers = nn.Sequential(*layers)
self.unfold = nn.Unfold(k, 1, (k-1)//2, 1) # 强制 stride 1 用于展开
# 通道对齐,如果 c1 != c2,或者需要 stride=2,则进行降维或步长调整
self.proj = nn.Conv2d(c1, c2, 1, stride=s, bias=False) if c1 != c2 or s != 1 else nn.Identity()
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
B, C, H, W = x.shape
# 动态将 posi_map 插值到当前特征图的尺寸
posi = F.interpolate(self.posi_map, size=(H, W), mode='bilinear', align_corners=False)
# 生成基于位置的权重
weight = self.weight_layers(posi) #[1, C * K^2, H, W]
weight = weight.view(1, self.channels, self.k_square, H, W)
# 展开输入特征
out = self.unfold(x).view(B, self.channels, self.k_square, H, W)
# 加权求和
out = (weight * out).sum(dim=2)
# 投影到目标通道并激活
return self.act(self.bn(self.proj(out)))
class Bottleneck_TV(nn.Module):
"""使用 TVConv 替换标准 3x3 卷积的 Bottleneck"""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
# 将这里的标准卷积替换为 TVConv
self.cv2 = TVConv_YOLO(c_, c2, k[1], 1)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3k2_TV(nn.Module):
"""集成 TVConv 的 C3k2 模块 (YOLO11 标准积木的变体)"""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
# 核心:将 Bottleneck 替换为包含 TVConv 的 Bottleneck_TV
self.m = nn.ModuleList(
Bottleneck_TV(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n)
)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))第二步 在 __init__.py 中注册模块
打开 ultralytics/nn/modules/__init__.py 文件,导入刚才创建的模块:
# 找到 imports 的地方,添加:
from .custom_tvconv import TVConv_YOLO, C3k2_TV
# 找到 __all__ 元组,在最后面加上:
__all__ = (
# ... 原本的代码 ...
"TVConv_YOLO",
"C3k2_TV",
)第三步:修改 tasks.py 以便模型解析器识别
为了让 yaml 文件能够识别新的名字,需要修改解析器。
(1)导入新模块 C3k2_TV
打开 ultralytics/nn/tasks.py,找到 from ultralytics.nn.modules import (...) 这段长长的导入代码。
在这个导入列表里面加上 C3k2_TV(建议放在 C3k2 旁边保持整齐)。
# 修改后 (部分截取)
from ultralytics.nn.modules import (
AIFI,
C1,
C2,
C2PSA,
C3,
C3TR,
...
C3Ghost,
C3k2,
C3k2_TV, # <---- 添加这一行
C3x,
...(2)将模块加入 base_modules 解析集合
找到 parse_model 函数,里面有一个 base_modules = frozenset({...}) 的集合。这个集合的作用是告诉 YOLO 解析器:这些模块的前两个参数是输入通道和输出通道。
# 修改后 (部分截取)
base_modules = frozenset(
{
Classify,
Conv,
...
C2,
C2f,
C3k2,
C3k2_TV, # <---- 添加这一行
RepNCSPELAN4,
...(3)将模块加入 repeat_modules 解析集合
紧接着 base_modules 往下看,有一个 repeat_modules = frozenset({...}) 的集合。它的作用是告诉解析器:这些模块可以根据网络深度(如 YOLO11n、s、m)进行动态堆叠/重复 (也就是 yaml 里的 repeats 参数 n)。
# 修改后 (部分截取)
repeat_modules = frozenset( # modules with 'repeat' arguments
{
BottleneckCSP,
C1,
...
C2f,
C3k2,
C3k2_TV, # <---- 添加这一行
C2fAttn,
...(4)适配 YOLO11 的 M/L/X 缩放逻辑
继续在 parse_model 函数内部往下找,会看到一段关于 C3k2 的缩放逻辑:
if m is C3k2: # for M/L/X sizes
这段代码确保当模型变大时,它内部的网络结构会自动改变。
修改方法: 把判断条件改为 if m in {C3k2, C3k2_TV}:,让你的自定义模块同样完美继承 YOLO11 的多尺度自适应特性。
# 修改后
if m in {C3k2, C3k2_TV}: # for M/L/X sizes <---- 修改这一行
legacy = False
if scale in "mlx":
args[3] = True第四步:创建包含 TVConv 的 YOLO11 配置文件
在你的项目根目录(或 yaml 配置文件夹)新建一个 yolo11-tvconv.yaml。
改进策略说明: 仅在 Backbone 的最深层(第 8 层,1024 通道)和 Head 的最深层(第 22 层,1024 通道)将 C3k2 替换为 C3k2_TV。这样既能利用 TVConv 在深层提取强语义空间变异特征,又能完全避免显存溢出。
# yolo11-tvconv.yaml
# Parameters
nc: 1 # number of classes
scales:
# [depth, width, max_channels]
n: [0.50, 0.25, 1024]
s: [0.50, 0.50, 1024]
m: [0.50, 1.00, 512]
l: [1.00, 1.00, 512]
x: [1.00, 1.50, 512]
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv,[128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2,[256, False, 0.25]]
- [-1, 1, Conv,[256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2,[512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
# === 改进点 1:骨干网络最深层提取空间变异特征 ===
- [-1, 2, C3k2_TV,[1024, True]] # 8
- [-1, 1, SPPF,[1024, 5]] # 9
- [-1, 2, C2PSA,[1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv,[512, 3, 2]]
- [[-1, 10], 1, Concat,[1]] # cat head P5
# === 改进点 2:Neck的最深层进行空间变异特征融合 ===
- [-1, 2, C3k2_TV,[1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)TVConv 根据图像位置自适应改变卷积核权重(非平移不变性)的核心机制得到了 100% 保留,对于旋转目标检测、遥感图像、遮挡目标具有很好的涨点潜力。
四、模型训练
如果有想法改进YOLO(比如想引入一个模块用于改进某个模块),但是自己不懂代码不会改进的可以联系我,我可以远程教学,需要的可以联系我

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)