大模型落地实践:从零搭建企业级RAG知识库问答系统
引言
在金融、医疗、法律等知识密集型行业,企业内部沉淀了大量文档(规章制度、产品手册、历史项目文档、合规文件)。如何让这些非结构化数据真正发挥价值,成为一线员工触手可及的“智慧大脑”?大模型的出现,尤其是检索增强生成(Retrieval-Augmented Generation, RAG)架构,为解决这一问题提供了全新的范式。本文将结合我在某大型企业落地RAG知识库系统的实践,详细拆解从技术选型、架构设计到部署优化的完整过程,并分享在真实场景中遇到的挑战与解决方案。
一、为什么需要RAG?微调 vs RAG
在项目启动初期,我们曾面临两种主流技术路线的选择:微调(Fine-tuning) 和 RAG。
| 维度 | 微调 | RAG |
|---|---|---|
| 知识更新 需 | 重新训练,成本高、周期长 | 只需更新向量库,实时性强 |
| 事实准确性 | 可能出现幻觉,无法溯源 | 检索到具体文档,答案可溯源,准确率高 |
| 开发成本 | 需要高质量标注数据,算力要求高 | 无需标注,算力要求低 |
| 数据安全 | 私有数据用于训练,有泄露风险 | 数据不出本地库,安全性高 |
考虑到企业知识库需要频繁更新(新业务规范、产品迭代),且对答案的准确性和可追溯性有极高要求,我们最终选择了 RAG架构 作为技术路线。
二、系统架构设计与技术选型
我们构建的RAG知识库系统遵循经典的“索引-检索-生成”三层架构,整体技术栈如下:
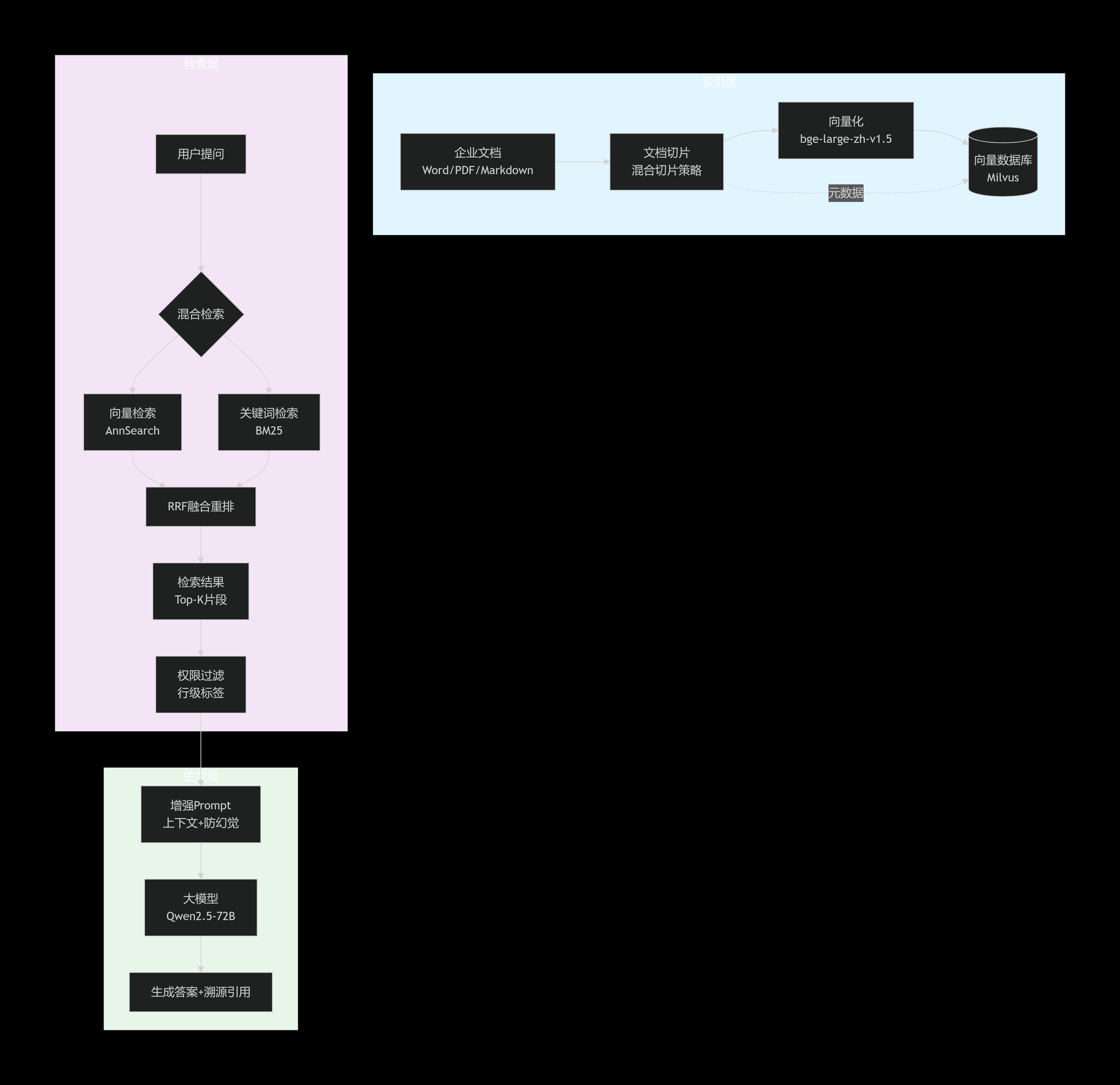
-
向量化模型:BAAI/bge-large-zh-v1.5(中文语义理解强,开源)
-
向量数据库:Milvus(开源、高性能、支持混合检索)
-
大模型:Qwen2.5-72B-Instruct(部署于企业内网,保障数据安全)
-
切片与Embedding:LangChain + 自定义切片策略
-
前端与编排:Streamlit + LangGraph(用于复杂流程编排)
三、核心模块实现详解
3.1 文档切片策略:决定检索质量的基石
文档切片是RAG系统中最关键、也最容易出错的环节。切得太粗,检索精度低;切得太细,上下文信息丢失。我们针对不同类型的文档,设计了混合切片策略:
from langchain.text_splitter import RecursiveCharacterTextSplitter, MarkdownHeaderTextSplitter
def hybrid_split(document):
# 1. 对于Markdown,先按标题结构切分,保留层次结构
headers_to_split_on = [("#", "Header1"), ("##", "Header2"), ("###", "Header3")]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
header_splits = markdown_splitter.split_text(document)
# 2. 对长段落,使用递归字符切分器,保证chunk大小适中
recursive_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
separators=["\n\n", "\n", "。", ";", " ", ""]
)
final_chunks = []
for chunk in header_splits:
sub_chunks = recursive_splitter.split_text(chunk.page_content)
# 将标题信息作为元数据附加到每个子块,增强检索时的上下文
for sub_chunk in sub_chunks:
final_chunks.append({
"content": sub_chunk,
"metadata": {"headers": chunk.metadata}
})
return final_chunks
要点:通过保留标题结构作为元数据,在检索时,我们可以在Prompt中附带这些层级信息,帮助大模型更好地理解当前片段在整体文档中的位置和角色。
3.2 混合检索:弥补纯向量检索的不足
纯向量检索有时会漏掉精确匹配的关键词(如专业术语、产品型号)。我们引入了 混合检索(向量检索 + 关键词检索),并使用 RRF(Reciprocal Rank Fusion)算法 进行结果融合。
from pymilvus import Collection, AnnSearchRequest, KeywordSearchRequest, RRFRanker
def hybrid_search(query, collection_name, top_k=5):
collection = Collection(collection_name)
# 向量检索
vector_req = AnnSearchRequest(
data=[embedding_model.encode(query)],
anns_field="embedding",
param={"metric_type": "IP", "params": {"nprobe": 10}},
limit=top_k * 2 # 多召回一些用于融合
)
# 关键词检索(BM25)
keyword_req = KeywordSearchRequest(
data=[query],
field_name="content",
param={"metric_type": "BM25"},
limit=top_k * 2
)
# RRF融合重排
results = collection.hybrid_search(
reqs=[vector_req, keyword_req],
ranker=RRFRanker(),
limit=top_k,
output_fields=["content", "metadata"]
)
return results
混合检索显著提高了对特定术语的召回率,例如当用户查询“《个人信息保护法》第18条”时,BM25能精准匹配到包含该条款的文档片段。
3.3 Prompt工程与防幻觉设计
检索到的内容可能包含无关信息,也可能与用户问题不完全匹配。我们设计了一套 增强型Prompt模板,引导模型基于检索内容作答,并明确要求“不知道就说不知道”,有效控制幻觉。
你是一个专业的知识库问答助手。请基于以下【检索到的知识片段】回答用户的问题。
如果知识片段中没有相关信息,请直接回答“抱歉,根据现有知识库无法回答此问题”,不要编造信息。
【检索到的知识片段】
{context}
【用户问题】
{question}
【回答要求】
1. 回答需准确、简洁,直接针对问题。
2. 如果引用了某个知识片段,请在回答末尾用方括号标注来源,例如 [来源:产品手册V2.0]。
3. 禁止添加与检索内容无关的额外信息。
【回答】
此外,我们还在系统中集成了 “引用溯源” 功能,在返回答案的同时,将用于生成该答案的原始文档链接一并提供给用户,大幅增强了系统的可信度和用户体验。
四、企业级落地中的挑战与优化
4.1 复杂问题的多跳推理
真实用户问题往往复杂,例如:“去年华东区销售的A型号产品,其返修率是多少?” 这需要跨多份文档(销售数据、产品档案、售后记录)进行推理。
解决方案:我们引入了 Agent + 多轮检索 机制。当主查询无法一次检索到所有信息时,Agent会分析问题,拆解为多个子问题(如“找到A型号产品编号”、“获取去年华东区销售记录”、“查询该批次的售后维修数据”),依次检索并汇总信息,最终生成答案。这本质上是一个 推理链(Chain-of-Thought) 的实现。
4.2 数据安全与权限控制
企业数据涉及部门机密,必须实现 行级权限控制。我们的方案是在向量化时,为每个文档片段打上“访问标签”(如部门、密级、项目组)。在检索阶段,系统会根据当前用户的身份信息,在检索请求中动态注入过滤条件(filter),确保用户只能检索到授权范围内的文档。
# Milvus检索时增加过滤表达式
filter_expr = f"department in {user.departments} AND security_level <= {user.level}"
results = collection.search(
data=[query_vector],
anns_field="embedding",
param=search_params,
limit=5,
expr=filter_expr, # 权限过滤
output_fields=["content", "metadata"]
)
五、效果评估与未来规划
5.1 评估指标
我们建立了多维度的评估体系:
-
召回率:在测试集上,正确文档片段出现在Top-K检索结果中的比例。
-
答案准确率:通过人工评估和LLM-as-a-Judge相结合的方式,对生成答案进行打分。
-
平均响应时间:从用户提问到返回答案的总耗时,目前控制在3秒以内。
5.2 未来演进方向
- 多模态扩展:目前系统仅支持文本。未来将引入多模态大模型,支持对产品图纸、流程图、甚至视频截图的检索与理解。
- 自优化RAG:利用用户对答案的反馈(点赞/点踩)数据,微调重排序模型,实现检索效果的持续闭环优化。
- 与业务流程深度融合:不满足于“问答”,而是让RAG系统能主动向业务系统(如CRM、ERP)推送知识,在用户执行任务时提供实时辅助。
结语
RAG技术让大模型真正从“玩具”变成了“工具”,在保证数据安全、事实准确的前提下,盘活了企业沉睡的知识资产。本次实践让我深刻体会到,在企业级AI应用落地中,“工程化能力”远比“模型本身”更为关键。从文档切片、混合检索,到权限控制、Agent编排,每一个环节的精细打磨,都决定着最终的应用效果。希望本文的分享,能为同样在探索大模型落地的同行们提供一些有价值的参考

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)