AI基础-强化学习
强化学习基本概念
- 状态(State, S S S ) :智能体当前所处的环境状态。
- 动作(Action, A A A ) :智能体在某个状态下可以采取的决策或行为。
- 奖励(Reward, R R R ) :智能体执行某个动作后得到的反馈信号,通常用于衡量该动作的好坏。
- 策略(Policy, π \pi π ) :智能体依据当前状态选择下一步动作的行为准则。
- 价值函数(Value Function, V ( s ) V(s) V(s) ) :用于评估某个状态的长期收益。
- 动作-价值函数(Q-Value, Q ( s , a ) Q(s, a) Q(s,a) ) :用于评估在状态 s s s 下执行动作 a a a 的长期收益。
核心思想
- 智能体在环境中不断尝试不同的动作,每次行动后,环境会给出一个奖励(reward)。
- 目标是找到一条最优策略,使智能体在长期内获得的奖励最大化。
- 通过反复试验(trial and error),智能体学会选择高分的行动,并避免低分的行动。
强化学习的方法
-
基于值(Value-based)方法
-
例如 Q-learning,使用 Q-值函数 来评估每个状态-动作对的长期回报,并通过迭代更新 Q 值来找到最优策略。
-
公式:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r + \gamma \max_{a'} Q(s', a') - Q(s, a) \right] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
-
其中:
- α \alpha α 是学习率(learning rate)。
- γ \gamma γ 是折扣因子(discount factor),衡量长期收益的重要性。
-
-
基于策略(Policy-based)方法
- 例如 REINFORCE 方法,直接优化策略 π ( a ∣ s ) \pi(a|s) π(a∣s) 使其趋向最优。
- 适用于高维、连续动作空间的问题。
-
基于 Actor-Critic 方法
- 结合了 Q-learning(基于值)和 REINFORCE(基于策略)。
- 由 Actor(执行动作) 和 Critic(评估动作) 两部分组成,实现稳定高效的学习
Q-Learing
概述
Q-Learning 是一种基于值(Value-based)的强化学习算法,属于 无模型(Model-free) 的 离线学习(Off-policy) 方法。
它通过学习 Q 值(Q-value) 来估计某个状态下执行特定动作的长期收益,并利用贪心策略(greedy policy)选择收益最大的动作,从而逐步优化智能体的行为。
核心思想
智能体通过与环境交互,更新状态-动作值(Q 值),最终找到最优策略,使得长期累积奖励最大化。
关键概念
-
状态(State, S S S ) :智能体当前所处的环境状态。
-
动作(Action, A A A ) :智能体在某个状态下可以执行的行为。
-
奖励(Reward, R R R ) :执行动作后环境给出的反馈,用于衡量该动作的好坏。
-
状态转移(Transition) :智能体执行某个动作后,环境从当前状态 s s s 变为下一个状态 s ′ s' s′。
-
Q 值(Q-value, Q ( s , a ) Q(s, a) Q(s,a) ) :
- 代表在状态 s s s 下执行动作 a a a 所能获得的长期累积奖励。
- Q 值的更新规则基于 贝尔曼方程(Bellman Equation) 。
Q-Learning 算法原理
Q-Learning 通过以下 Q 值更新公式 逐步优化 Q 值:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r + \gamma \max_{a'} Q(s', a') - Q(s, a) \right] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
其中:
- Q ( s , a ) Q(s, a) Q(s,a) 是状态 s s s 下执行动作 a a a 的 Q 值。
- α \alpha α(学习率,learning rate):控制新旧 Q 值的更新比例,取值范围 ( 0 , 1 ] (0,1] (0,1]。
- r r r(即时奖励):执行动作 a a a 后得到的奖励。
- γ \gamma γ(折扣因子,discount factor):衡量未来奖励的重要性,取值范围 ( 0 , 1 ] (0,1] (0,1]。
- max a ′ Q ( s ′ , a ′ ) \max_{a'} Q(s', a') maxa′Q(s′,a′) 是下一个状态 s ′ s' s′ 可执行的所有动作中Q 值最大的动作。
更新过程
-
在状态 s s s 选择一个动作 a a a。
-
执行动作 a a a,观察 奖励 r r r 和 下一个状态 s ′ s' s′。
-
在 s ′ s' s′ 不执行新的动作,而是直接选择 Q 值最大的动作(贪婪策略),即:
Q target = r + γ max a ′ Q ( s ′ , a ′ ) Q_{\text{target}} = r + \gamma \max_{a'} Q(s', a') Qtarget=r+γa′maxQ(s′,a′)
-
使用 TD(时序差分)误差 更新 Q 值:
Q ( s , a ) ← Q ( s , a ) + α ( Q target − Q ( s , a ) ) Q(s, a) \leftarrow Q(s, a) + \alpha \left( Q_{\text{target}} - Q(s, a) \right) Q(s,a)←Q(s,a)+α(Qtarget−Q(s,a))
算法拆解
目标 Q 值(Target Q-value) :
r + γ max a ′ Q ( s ′ , a ′ ) r + \gamma \max_{a'} Q(s', a') r+γa′maxQ(s′,a′)
- 其中 r r r 是即时奖励(reward),表示当前执行动作 a a a 后立即获得的奖励。
- γ max a ′ Q ( s ′ , a ′ ) \gamma \max_{a'} Q(s', a') γmaxa′Q(s′,a′) 代表下一个状态 s ′ s' s′ 所能获得的最大未来回报,即长期收益。
当前 Q 值(Current Q-value) :
Q ( s , a ) Q(s, a) Q(s,a)
Q 值更新的误差项:
δ = r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) \delta = r + \gamma \max_{a'} Q(s', a') - Q(s, a) δ=r+γa′maxQ(s′,a′)−Q(s,a)
- 这个部分被称为TD 误差(Temporal Difference Error) ,它衡量的是当前 Q 值和目标 Q 值之间的差距。
- 如果当前 Q 值低于目标 Q 值,意味着需要增加 Q 值;
- 如果当前 Q 值高于目标 Q 值,意味着需要减少 Q 值。
更新方式(梯度下降方向) :
Q ( s , a ) ← Q ( s , a ) + α δ Q(s, a) \leftarrow Q(s, a) + \alpha \delta Q(s,a)←Q(s,a)+αδ
-
其中 α \alpha α 是学习率(learning rate),控制更新的幅度。
如果 Q ( s , a ) Q(s, a) Q(s,a) 过低(低估了未来回报),则误差项为正数,更新后 Q 值增加:
Q ( s , a ) ← Q ( s , a ) + α ⋅ 正误差 Q(s, a) \leftarrow Q(s, a) + \alpha \cdot \text{正误差} Q(s,a)←Q(s,a)+α⋅正误差
如果 Q ( s , a ) Q(s, a) Q(s,a) 过高(高估了未来回报),则误差项为负数,更新后 Q 值减少:
Q ( s , a ) ← Q ( s , a ) − α ⋅ 负误差 Q(s, a) \leftarrow Q(s, a) - \alpha \cdot \text{负误差} Q(s,a)←Q(s,a)−α⋅负误差
重要技巧
1. ϵ \epsilon ϵ -贪心策略(**** ϵ \epsilon ϵ -Greedy Policy)
-
纯粹使用贪心策略(总是选 Q 值最大的动作)可能导致智能体陷入局部最优解。
-
采用 ϵ \epsilon ϵ-贪心策略,在学习过程中保留一定的探索性:
以概率 1 − ϵ 1 - \epsilon 1−ϵ 选择当前 Q 值最大的动作(利用 Exploitation) :
a = arg max a Q ( s , a ) a = \arg\max_{a} Q(s, a) a=argamaxQ(s,a)
以概率 ϵ \epsilon ϵ 选择随机动作(探索 Exploration) :
a = random action a = \text{random action} a=random action
其中, ϵ \epsilon ϵ(探索率)是一个超参数,控制探索和利用的比例:
- ϵ \epsilon ϵ 较大(如 0.5) :更多探索(适合初始阶段)。
- ϵ \epsilon ϵ 较小(如 0.01) :更多利用(适合收敛后)。
- 以概率 ϵ \epsilon ϵ 选择随机动作(探索)。
- 以概率 1 − ϵ 1 - \epsilon 1−ϵ 选择当前最优动作(利用)。
-
ϵ \epsilon ϵ(探索率)是一个超参数,控制探索和利用的比例:
- ϵ \epsilon ϵ 较大(如 0.5) :更多探索(适合初始阶段)。
- ϵ \epsilon ϵ 较小(如 0.01) :更多利用(适合收敛后)。
2. 学习率 α \alpha α
- 控制 Q 值更新的步长。
- 过大可能导致震荡,过小可能收敛太慢。
3. 折扣因子 γ \gamma γ
-
反映未来奖励的重要性:
- γ \gamma γ 近 0:关注短期奖励(贪心)。
- γ \gamma γ 近 1:关注长期收益。
Q-Learning具体算法流程
假设智能体在一个迷宫里,需要找到一条最短路径从起点走到终点。
初始化
-
创建 Q 表:
- Q 表的行:所有可能的状态 s s s(比如迷宫中的所有位置)
- Q 表的列:所有可能的动作 a a a(比如上下左右移动)
- 初始值设为 0(表示一开始不知道哪个动作更好)
-
设置超参数:
- 学习率( α \alpha α):控制学习速度(一般 0.1~0.5)
- 折扣因子( γ \gamma γ):控制对未来奖励的关注度(一般 0.9~0.99)
- 探索率( ϵ \epsilon ϵ):决定是否探索新动作(一般从 1 开始,逐渐减少)
智能体开始游戏,重复以下步骤
-
观察当前状态 s t s_t st(比如迷宫里的位置)。
-
选择一个动作 a t a_t at:
- 探索(Exploration) :有一定概率( ϵ \epsilon ϵ)随机选一个动作,尝试新路线。
- 利用(Exploitation) :有一定概率( 1 − ϵ 1 - \epsilon 1−ϵ)选择 Q 表中当前状态最优的动作(即 Q 值最大的)。
-
执行动作 a t a_t at ,获得奖励 r t r_t rt ,进入新状态 s t + 1 s_{t+1} st+1:
- 如果走了一步离终点更近,给正奖励(比如 +10)。
- 如果撞墙,给负奖励(比如 -10)。
- 其他情况给小的负奖励(比如 -1),鼓励智能体尽快找到出口。
-
更新 Q 值(Q-Learning 关键公式) :
Q ( s t , a t ) ← Q ( s t , a t ) + α ( r t + γ max a Q ( s t + 1 , a ) − Q ( s t , a t ) ) Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left( r_t + \gamma \max_{a} Q(s_{t+1}, a) - Q(s_t, a_t) \right) Q(st,at)←Q(st,at)+α(rt+γamaxQ(st+1,a)−Q(st,at))
- Q ( s t , a t ) Q(s_t, a_t) Q(st,at) 是当前状态下选定动作的 Q 值
- r t r_t rt 是当前奖励
- γ max a Q ( s t + 1 , a ) \gamma \max_{a} Q(s_{t+1}, a) γmaxaQ(st+1,a) 是下一步能获得的最大价值
- 意思是:让 Q 值向“实际奖励 + 未来可能的最大奖励”靠拢
-
减小探索率 ϵ \epsilon ϵ(逐渐减少随机探索,更多依赖 Q 表)。
-
进入下一个状态 s t + 1 s_{t+1} st+1 ,重复以上步骤,直到游戏结束。
什么时候结束?
- 经过大量训练后,Q 表会收敛(不再剧烈变化)。
- 这时,智能体就学会了最优策略,可以用 Q 表直接决策。
Sarsa(State-Action-Reward-State-Action, 在线更新)
Sarsa 是 同策略(on-policy) 方法,更新公式如下:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r + \gamma Q(s', a') - Q(s, a) \right] Q(s,a)←Q(s,a)+α[r+γQ(s′,a′)−Q(s,a)]
其中:
- s s s :当前状态
- a a a :当前动作
- r r r :执行动作后获得的奖励
- s ′ s' s′ :下一状态
- a ′ a' a′ :下一状态下根据当前策略选取的动作
- α \alpha α :学习率
- γ \gamma γ :折扣因子
Sarsa 更新过程
-
选择动作 : 在当前状态 s s s 下,使用 ϵ-贪婪策略选择一个动作 a a a。
-
执行动作 a a a,观察 奖励 r r r 和 下一个状态 s ′ s' s′。
-
在 下一个状态 s ′ s' s′ 选择下一个动作 a ′ a' a′(仍然按照 ϵ-贪婪策略 选择)。
-
使用 新的状态和动作值 更新 Q 值:
Q target = r + γ Q ( s ′ , a ′ ) Q_{\text{target}} = r + \gamma Q(s', a') Qtarget=r+γQ(s′,a′)
-
更新 Q 值:
Q ( s , a ) ← Q ( s , a ) + α ( Q target − Q ( s , a ) ) Q(s, a) \leftarrow Q(s, a) + \alpha \left( Q_{\text{target}} - Q(s, a) \right) Q(s,a)←Q(s,a)+α(Qtarget−Q(s,a))
Sarsa具体算法流程
假设智能体在一个迷宫里,需要找到一条最短路径从起点走到终点。
初始化
-
创建 Q 表:
- 行:所有可能的状态 s s s(比如迷宫里的所有位置)。
- 列:所有可能的动作 a a a(比如“上下左右移动”)。
- 初始值设为 0(表示一开始不知道哪个动作更好)。
-
设置超参数:
- 学习率( α \alpha α):控制学习速度(一般 0.1~0.5)。
- 折扣因子( γ \gamma γ):控制对未来奖励的关注度(一般 0.9~0.99)。
- 探索率( ϵ \epsilon ϵ):决定是否探索新动作(一般从 1 开始,逐渐减少)。
智能体开始游戏,重复以下步骤
-
观察当前状态 s t s_t st(比如迷宫里的位置)。
-
按照当前策略选择一个动作 a t a_t at:
- 探索(Exploration) :有一定概率( ϵ \epsilon ϵ)随机选一个动作,尝试新路线。
- 利用(Exploitation) :有一定概率( 1 − ϵ 1 - \epsilon 1−ϵ)选择当前状态 Q 表中最优的动作。
-
执行动作 a t a_t at ,获得奖励 r t r_t rt ,进入新状态 s t + 1 s_{t+1} st+1。
-
在新状态 s t + 1 s_{t+1} st+1 再选择下一个动作 a t + 1 a_{t+1} at+1:
- 这个动作不是假设的最优动作,而是按照当前策略选的(可能是探索或利用)!
-
更新 Q 值(Sarsa 关键公式) :
Q ( s t , a t ) ← Q ( s t , a t ) + α ( r t + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ) Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left( r_t + \gamma Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t) \right) Q(st,at)←Q(st,at)+α(rt+γQ(st+1,at+1)−Q(st,at))
- Q ( s t , a t ) Q(s_t, a_t) Q(st,at) 是当前状态下选定动作的 Q 值。
- r t r_t rt 是当前奖励。
- Q ( s t + 1 , a t + 1 ) Q(s_{t+1}, a_{t+1}) Q(st+1,at+1) 是按照策略真实执行的下一个动作的 Q 值(和 Q-Learning 不同,Q-Learning 这里用的是最大 Q 值)。
- 意思是:让 Q 值向“实际奖励 + 未来真实策略下的奖励”靠拢。
-
进入下一个状态 s t + 1 s_{t+1} st+1 ,重复以上步骤,直到游戏结束。
什么时候结束?
- 经过多次训练后,Q 表会收敛(不再剧烈变化)。
- 这时,智能体就学会了稳定的最优策略,可以用 Q 表直接决策。
Sarsa 特点
- 使用实际选择的动作 a ′ a' a′ 来更新,不使用贪婪策略,因此是 同策略(on-policy) 。
- 由于遵循当前策略,学习过程更 稳定,但可能 收敛较慢。
- 更倾向于“保守”策略,避免极端情况(如陷阱)。
Q-Learning vs. Sarsa 区别总结
| Q-Learning | Sarsa | |
|---|---|---|
| 策略 | 异策略(off-policy) | 同策略(on-policy) |
| 下一步动作选择 | 采用贪婪策略选择最大Q值的动作(不一定是执行的动作) | 采用当前策略选择的动作 |
| 学习特点 | 更新速度快,容易找到最优策略,但可能较不稳定 | 学习速度较慢,但策略更稳定,适合高风险环境 |
| 适合场景 | 适用于探索较多、风险较低的场景 | 适用于高风险、需更稳健决策的环境 |
| 数学公式 | Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r + \gamma \max_{a'} Q(s', a') - Q(s, a) \right] Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)] | Q ( s , a ) ← Q ( s , a ) + α [ r + γ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r + \gamma Q(s', a') - Q(s, a) \right] Q(s,a)←Q(s,a)+α[r+γQ(s′,a′)−Q(s,a)] |
Sarsa(λ) 算法(Eligibility Traces)
Sarsa(λ) 是 Sarsa 算法的改进版本,它结合了 时间差分学习(TD Learning) 和 资格迹(Eligibility Traces) ,用于 加快学习速度,特别是在稀疏奖励环境中效果更好。
资格迹(Eligibility Traces)
核心思想
- 在标准的 Sarsa 中,只更新当前状态-动作对的 Q 值,但 Sarsa(λ) 通过 资格迹 让之前访问过的状态也能更新 Q 值,使得信息传播更快。
- 资格迹用于记录每个状态-动作对的重要性,类似“记忆衰减”的概念。
资格迹的计算
每个状态-动作对 ( s , a ) (s, a) (s,a) 维护一个 资格迹值 E ( s , a ) E(s, a) E(s,a),当执行 ( s t , a t ) (s_t, a_t) (st,at) 时:
E ( s t , a t ) ← 1 + γ λ E ( s t − 1 , a t − 1 ) E(s_t, a_t) \leftarrow 1 + \gamma \lambda E(s_{t-1}, a_{t-1}) E(st,at)←1+γλE(st−1,at−1)
其中:
- λ \lambda λ(lambda)是衰减因子,控制过去状态的重要性。
- γ \gamma γ 是折扣因子,衡量未来奖励的重要性。
- E ( s t − 1 , a t − 1 ) E(s_{t-1}, a_{t-1}) E(st−1,at−1):资格迹值,代表过去状态-动作对的更新重要性。
Sarsa(λ) 与 λ 值的影响
- Sarsa(0) :λ = 0,仅更新最近的一步(TD(0))。
- Sarsa(1) :λ = 1,直到回合结束后再进行更新(蒙特卡洛方法)。
- Sarsa(λ) : 0 0 0 < λ < λ <λ < 1 < 1 <1,结合短期和长期信息,加快收敛速度。取值越大, 离宝藏越近的步更新力度越大
Sarsa(λ) 更新公式
Sarsa(λ) 的 Q 值更新公式:
Q ( s , a ) ← Q ( s , a ) + α δ E ( s , a ) Q(s, a) \leftarrow Q(s, a) + \alpha \delta E(s, a) Q(s,a)←Q(s,a)+αδE(s,a)
其中:
-
TD 误差(Temporal Difference Error):
δ = r + γ Q ( s ′ , a ′ ) − Q ( s , a ) \delta = r + \gamma Q(s', a') - Q(s, a) δ=r+γQ(s′,a′)−Q(s,a)
-
资格迹更新:
E ( s , a ) ← γ λ E ( s , a ) E(s, a) \leftarrow \gamma \lambda E(s, a) E(s,a)←γλE(s,a)
-
更高效的资格迹更新
self.eligibility_trace.loc[s, :] *= 0 # 先将该状态的资格迹清零 self.eligibility_trace.loc[s, a] = 1 # 只对当前执行的动作置 1好处
- 减少累积误差:每次新访问状态
(s, a),都直接把资格迹设为1,而不是累加,避免历史误差。 - 提高计算稳定性:对于
Sarsa(λ),资格迹的影响应该是随着λ的衰减而传播的,而不是一直累积。
- 减少累积误差:每次新访问状态
Sarsa(λ) 具体流程
假设智能体在一个迷宫里,需要找到最短路径从起点走到终点。
初始化
-
创建 Q 表:
- 行:所有可能的状态 s s s(比如迷宫里的所有位置)。
- 列:所有可能的动作 a a a(比如“上下左右移动”)。
- 初始值设为 0(表示一开始不知道哪个动作更好)。
-
创建“资格迹”表(Eligibility Traces):
- 和 Q 表大小相同,记录每个状态-动作对的“记忆值” ,初始设为 0。
-
设置超参数:
- 学习率( α \alpha α):控制学习速度(一般 0.1~0.5)。
- 折扣因子( γ \gamma γ):控制对未来奖励的关注度(一般 0.9~0.99)。
- 探索率( ϵ \epsilon ϵ):决定是否探索新动作(一般从 1 开始,逐渐减少)。
- 资格迹衰减率( λ \lambda λ):控制记忆的长短(一般 0.7~0.9,值越大记忆越久)。
智能体开始游戏,重复以下步骤
-
观察当前状态 s t s_t st(比如迷宫里的位置)。
-
按照当前策略选择一个动作 a t a_t at:
- 探索(Exploration) :有一定概率( ϵ \epsilon ϵ)随机选一个动作,尝试新路线。
- 利用(Exploitation) :有一定概率( 1 − ϵ 1 - \epsilon 1−ϵ)选择当前状态 Q 表中最优的动作。
-
执行动作 a t a_t at ,获得奖励 r t r_t rt ,进入新状态 s t + 1 s_{t+1} st+1。
-
在新状态 s t + 1 s_{t+1} st+1 再选择下一个动作 a t + 1 a_{t+1} at+1(按当前策略选)。
-
计算 TD 误差(时间差分误差) :
δ = r t + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) \delta = r_t + \gamma Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t) δ=rt+γQ(st+1,at+1)−Q(st,at)
- 这个值表示当前 Q 值与实际奖励的误差。
-
更新“资格迹”表:
e ( s t , a t ) ← e ( s t , a t ) + 1 e(s_t, a_t) \leftarrow e(s_t, a_t) + 1 e(st,at)←e(st,at)+1
- 当前执行的状态-动作对“记忆值”增加(相当于标记最近走过的路径)。
-
对所有状态-动作对,按照资格迹更新 Q 值:
Q ( s , a ) ← Q ( s , a ) + α δ e ( s , a ) Q(s, a) \leftarrow Q(s, a) + \alpha \delta e(s, a) Q(s,a)←Q(s,a)+αδe(s,a)
- 资格迹值越大,影响越大,表示这个状态-动作对在最近的路径中起到了更大作用。
-
衰减资格迹值:
e ( s , a ) ← γ λ e ( s , a ) e(s, a) \leftarrow \gamma \lambda e(s, a) e(s,a)←γλe(s,a)
- 记忆随着时间推移会逐渐减弱,保证最新的经验影响最大。
- 进入下一个状态 s t + 1 s_{t+1} st+1 ,重复以上步骤,直到游戏结束。
什么时候结束?
- 经过大量训练后,Q 表会收敛(不再剧烈变化)。
- 这时,智能体就学会了最优策略,可以用 Q 表直接决策。
Sarsa vs Sarsa(λ) vs Q-Learning
| Q-Learning | Sarsa | Sarsa(λ) | |
|---|---|---|---|
| 学习策略 | 贪心,假设未来总是选最优动作 | 谨慎,按实际策略更新 | 谨慎 + 记忆多步经验 |
| Q 值更新 | 只更新当前状态和下一步的最大 Q 值 | 只更新当前状态和下一步的实际 Q 值 | 更新当前状态 + 过去多步经验 |
| 记忆能力 | 没有记忆,只考虑当前 | 只记住最近一步 | 能记住多步经验,更快收敛 |
| 适用场景 | 适合离线学习,比如游戏 AI | 适合在线学习,比如机器人导航 | 适合复杂环境,比如动态规划问题 |
神经网络
神经网络(Neural Network, NN) 是一种 模拟人脑神经元结构 的数学模型,它可以通过训练 自动学习数据中的模式,并用于分类、回归、图像识别、自然语言处理等任务。
神经网络的基本结构
一个典型的 人工神经网络(Artificial Neural Network, ANN) 由 输入层、隐藏层、输出层 组成:
输入层 → 隐藏层(多个) → 输出层
输入层(Input Layer)
- 负责接收外部数据,每个神经元代表一个特征(如图片的像素值)。
- 例如,在手写数字识别任务中,输入层的神经元数等于图像的像素数(如 28×28 = 784 个神经元)。
隐藏层(Hidden Layers)
-
连接方式: 隐藏层与输入层、输出层之间通过 全连接 进行信息传递。每个神经元都与前一层的每个神经元相连。
-
负责提取特征和学习数据的复杂映射关系
-
作用
-
增加非线性能力:隐藏层通过激活函数(ReLU、Sigmoid、Tanh) 引入非线性,使网络能学习复杂的模式。
-
提取特征:隐藏层的神经元能自动学习数据的特征表示,从简单到复杂逐级提取信息。
隐藏层提取的是从原始数据到最终决策过程中,不同层级的关键信息:
任务 低层特征 中层特征 高层特征 图像分类 边缘、纹理 局部形状 物体类别 NLP(文本理解) 词向量、语法 句子结构 语义信息 自动驾驶 车辆状态 场景模式 路径规划 金融预测 K 线趋势 交易量变化 买卖策略 ✅ 隐藏层的作用: 让神经网络逐步从“数据”学习到“知识”! 🚀
-
提高表达能力:多层隐藏层组成的深度神经网络(DNN) 可以逼近任何复杂函数(通用逼近定理)
-
-
由多个神经元(Neuron)组成,每个神经元都与上一层所有神经元全连接(Fully Connected)
一个简单的三层神经网络
输入层 (Input) → 隐藏层 (Hidden Layer) → 输出层 (Output) X1 ───┐ H1 ───┐ Y1 X2 ───┼──▶ H2 ───┼──▶ Y2 X3 ───┘ H3 ───┘ Y3- 输入层(X1, X2, X3):接收原始数据。
- 隐藏层(H1, H2, H3):通过权重(W)和激活函数计算特征。
- 输出层(Y1, Y2, Y3):输出最终的预测结果。
-
每个神经元 通过 加权求和 + 激活函数 计算输出:
h = f ( W x + b ) h = f(Wx + b) h=f(Wx+b)
其中:
- x x x 是输入数据
- W W W 是权重(Weight)
- b b b 是偏置(Bias)
- f f f 是激活函数(如 ReLU、Sigmoid)
- h h h:隐藏层输出(提取的特征)
隐藏层不断调整权重 W W W 和 偏置 b b b,使得神经网络能提取数据中的关键特征
隐藏层与卷积层、池化层、全连接层的关系
在深度神经网络中,“隐藏层”是一个总称,指的是除了输入层和输出层以外的所有层。卷积层、池化层和全连接层 都可以视为不同形式的隐藏层,它们分别执行不同类型的计算任务:
-
卷积层 主要负责提取输入数据的局部特征。
-
池化层 用来减少数据的维度并提高计算效率,同时增强模型的平移不变性。
-
全连接层 负责将卷积和池化层提取的特征整合并进行最终的决策。
-
隐藏层 是网络中所有中间层的总称,包括卷积层、池化层和全连接层等。
卷积层(Convolutional Layer)
-
作用: 卷积层通过卷积核(Filter)对输入数据进行卷积操作,提取局部特征(如图像中的边缘、纹理)。卷积层具有局部连接和权重共享的特点,能够减少参数数量,提高计算效率。
-
计算过程:
- 输入:接受来自上一层(通常是输入层或另一卷积层)的数据。
- 输出:生成一个新的特征图(feature map),表示输入数据的特定特征。
- 卷积操作是通过滑动卷积核对输入图像进行局部加权求和。
- 每个卷积核负责提取一种特定的特征(如图像中的某个边缘),并生成相应的特征图(Feature Map)。
-
位置: 卷积层一般位于神经网络的前面,尤其是在卷积神经网络(CNN)中,通常用于输入数据的特征提取。它在神经网络的 前几层 负责提取低级特征(如边缘、角点、纹理),并随着层次的增加提取更高级的特征。
-
公式:
输出高度 = ( 输入高度 − 卷积核高度 + 2 × 填充 ) 步长 + 1 \text{输出高度} = \frac{(\text{输入高度} - \text{卷积核高度} + 2 \times \text{填充})}{\text{步长}} + 1 输出高度=步长(输入高度−卷积核高度+2×填充)+1
输出宽度 = ( 输入宽度 − 卷积核宽度 + 2 × 填充 ) 步长 + 1 \text{输出宽度} = \frac{(\text{输入宽度} - \text{卷积核宽度} + 2 \times \text{填充})}{\text{步长}} + 1 输出宽度=步长(输入宽度−卷积核宽度+2×填充)+1
输出深度 = 卷积核数量 \text{输出深度} = \text{卷积核数量} 输出深度=卷积核数量
参数说明:
-
输入高度和宽度:输入图像的尺寸(例如 H × W H \times W H×W)。
-
卷积核高度和宽度:卷积核的尺寸(例如 3 × 3 3 \times 3 3×3, 5 × 5 5 \times 5 5×5)。
-
步长(stride) :卷积核每次滑动的步数(通常为 1 或 2)。
-
填充(padding) :
- 无填充(Valid Padding) :即没有额外的填充,填充为 0。
- 填充(Same Padding) :使得输出尺寸与输入尺寸相同,填充足够的 0。
-
输出深度:卷积核的数量,通常代表输出特征图的通道数。
-
举例:
- 输入图像: 32 × 32 × 3 32 \times 32 \times 3 32×32×3
- 卷积核: 5 × 5 × 3 5 \times 5 \times 3 5×5×3,步长 1 1 1,无填充
- 输出特征图尺寸: ( 32 − 5 ) / 1 + 1 = 28 (32-5)/1 + 1 = 28 (32−5)/1+1=28
-
池化层(Pooling Layer)
-
功能:池化层通过对卷积层的输出特征图进行下采样,减少空间维度,降低计算量,避免过拟合,并提高模型的平移不变性。
-
输入:池化层的输入通常来自卷积层的输出特征图。
-
输出:池化层输出的特征图尺寸较小,但保留了最重要的特征信息。
-
两种常见池化方式:
-
最大池化(Max Pooling) :选取窗口内最大值,如 2 × 2 2 \times 2 2×2 窗口,步长 2。
-
优点:最大池化能有效保留特征图中的关键细节信息。
-
使用 2 × 2 2 \times 2 2×2 的最大池化窗口,步长为 2:
窗口 1: [1, 3] [5, 6] → 最大值为 6 窗口 2: [2, 4] [7, 8] → 最大值为 8 窗口 3: [9, 0] [4, 5] → 最大值为 9 窗口 4: [1, 2] [3, 0] → 最大值为 3池化后的输出:
[6, 8] [9, 3]
-
-
平均池化(Average Pooling) :计算窗口内均值,适用于平滑特征。
-
优点:适合保留更平滑的特征,减少噪声影响。
-
例子:使用同样的输入特征图,应用 2 × 2 2 \times 2 2×2 平均池化,步长为 2:
窗口 1: [1, 3] [5, 6] → 平均值为 (1+3+5+6)/4 = 3.75 窗口 2: [2, 4] [7, 8] → 平均值为 (2+4+7+8)/4 = 5.25 窗口 3: [9, 0] [4, 5] → 平均值为 (9+0+4+5)/4 = 4.5 窗口 4: [1, 2] [3, 0] → 平均值为 (1+2+3+0)/4 = 1.5池化后的输出:
[3.75, 5.25] [4.5, 1.5]
-
-
公式:
输出高度 = ( 输入高度 − 池化窗口高度 ) 步长 + 1 \text{输出高度} = \frac{(\text{输入高度} - \text{池化窗口高度})}{\text{步长}} + 1 输出高度=步长(输入高度−池化窗口高度)+1
输出宽度 = ( 输入宽度 − 池化窗口宽度 ) 步长 + 1 \text{输出宽度} = \frac{(\text{输入宽度} - \text{池化窗口宽度})}{\text{步长}} + 1 输出宽度=步长(输入宽度−池化窗口宽度)+1
输出深度 = 输入深度 ( 因为池化层只在空间维度下进行操作 ) \text{输出深度} = \text{输入深度} \quad (\text{因为池化层只在空间维度下进行操作}) 输出深度=输入深度(因为池化层只在空间维度下进行操作)
示例:
假设输入尺寸为 28 × 28 × 16 28 \times 28 \times 16 28×28×16,池化窗口大小为 2 × 2 2 \times 2 2×2,步长为 2:
输出高度 = ( 28 − 2 ) 2 + 1 = 14 \text{输出高度} = \frac{(28 - 2)}{2} + 1 = 14 输出高度=2(28−2)+1=14
输出宽度 = ( 28 − 2 ) 2 + 1 = 14 \text{输出宽度} = \frac{(28 - 2)}{2} + 1 = 14 输出宽度=2(28−2)+1=14
输出深度 = 16 ( 池化层不改变深度 ) \text{输出深度} = 16 \quad (\text{池化层不改变深度}) 输出深度=16(池化层不改变深度)
因此,池化层的输出尺寸为 14 × 14 × 16 14 \times 14 \times 16 14×14×16。
-
全连接层(Fully Connected Layer)
- 作用: 全连接层是网络的最后一部分,通常用于将前面卷积层提取到的特征映射到最终的输出结果(例如分类概率或回归值)。它通过 加权和 + 激活函数 将所有输入特征映射到输出。
- 连接方式: 在全连接层中,输入的每一个神经元都与该层中的每一个神经元相连接,形成一个完全连接的网络。全连接层的神经元对前一层所有神经元的输出进行加权求和。
- 位置: 在 卷积神经网络(CNN) 中,全连接层通常位于卷积层之后。卷积层提取图像的低级特征,池化层减少维度,然后通过全连接层进行最终的决策。
- 输入:全连接层的输入来自前一层(通常是卷积层或池化层)的输出,需要将其展平(flatten)成一维向量。
- 输出:通过激活函数(如 Softmax)将特征映射到最终的类别或预测值。
输出层(Output Layer)
-
负责输出最终结果(如分类结果或预测值)。
-
神经元个数 取决于任务类型:
- 回归任务:一个神经元(预测一个连续值)。
- 分类任务:类别数个神经元(使用 Softmax 激活函数)。
神经网络的核心原理
神经网络的核心是 前向传播(Forward Propagation) 和 反向传播(Backpropagation) 。
- 前向传播(Forward Propagation)——计算预测结果
- 反向传播(Backward Propagation)——调整参数,使误差最小
通俗理解
想象你是一个厨师,正在尝试做一碗汤。你的目标是做出最好喝的汤,但你还不知道正确的配方,所以你需要不断尝试和调整。
- 前向传播:你先按照某个配方(当前的参数)放入食材,煮出一碗汤(计算预测值)。
- 计算误差:你尝了一口汤(计算损失函数),发现味道和理想的味道有些偏差(计算误差)。
- 反向传播:你分析问题,调整调料比例(更新神经网络的参数)。
- 重复训练:不断尝试、调整,直到汤的味道最接近你的理想味道(损失最小)。
前向传播
前向传播的主要作用是计算神经网络的输出
作用:
-
让数据从输入层经过隐藏层传递到输出层。
-
通过激活函数引入非线性,学习复杂数据模式。
非线性变换的作用
- 引入复杂关系(如分类任务中的曲面决策边界)。
- 提高神经网络的表达能力(能拟合更复杂的函数)。
- 避免整个神经网络退化为简单的线性回归。
-
计算输出结果,与真实值进行比较,计算误差(损失)。
基本步骤
- 输入层 :输入数据 x x x
- 隐藏层:通过权重 W W W 和激活函数计算输出
- 输出层:计算最终的预测结果
数学步骤
-
每一层的神经元 计算加权和:
z = W ⋅ x + b z = W \cdot x + b z=W⋅x+b
其中:
- x x x 是上一层的输出(输入层的 x x x 是原始数据)。
- W W W 是权重(Weight)。
- b b b 是偏置(Bias)。
-
激活函数(非线性变换) :
a = f ( z ) a = f(z) a=f(z)
其中 f ( z ) f(z) f(z) 是激活函数(如 ReLU、Sigmoid、Tanh)。
-
输出层 给出最终的结果
计算损失
使用 损失函数(Loss Function) 计算预测值与真实值的误差
| 任务类型 | 损失函数 | 适用情况 |
|---|---|---|
| 回归 | MSE(均方误差) | 误差较小但需要平方放大 |
| 回归 | MAE(平均绝对误差) | 误差较大、对异常值鲁棒 |
| 分类 | 交叉熵(Cross-Entropy) | 多分类问题 |
| 概率匹配 | KL 散度 | 计算概率分布的差异 |
-
均方误差(MSE) (回归任务)
回归任务是预测连续数值,如房价、气温等。
MSE 计算预测值与真实值的平方误差的均值,表达式如下:
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
- y i y_i yi 是真实值
- y ^ i \hat{y}_i y^i 是预测值
- n n n 是样本数
特点:
✅ 适用于误差较小且稳定的情况
✅ 对较大误差敏感(因为平方放大了误差)import torch.nn as nn mse_loss = nn.MSELoss() y_true = torch.tensor([3.0, 5.0, 7.0]) y_pred = torch.tensor([2.5, 5.5, 6.5]) loss = mse_loss(y_pred, y_true) print(loss.item()) # 输出 MSE 值 -
交叉熵损失(Cross-Entropy) (分类任务)
分类任务是预测离散类别,如识别猫狗、垃圾邮件检测等。
用于多分类问题,计算预测类别概率分布与真实分布的相似度:
L = − ∑ i = 1 n y i log ( y ^ i ) L = -\sum_{i=1}^{n} y_i \log(\hat{y}_i) L=−i=1∑nyilog(y^i)
- y i y_i yi 是真实标签(One-hot 编码)
- y ^ i \hat{y}_i y^i 是预测概率
特点:
✅ 适用于分类问题(如猫、狗、鸟)
✅ 结合 Softmax,将输出转换成概率
反向传播(Backpropagation)
反向传播(Backpropagation, BP) 是神经网络的训练过程,它的作用是计算误差对每个参数的影响,并调整参数,使误差变小。
目标
让神经网络不断调整参数,使误差最小!
核心方法是 梯度下降(Gradient Descent) ,计算每个参数的梯度,并朝着降低损失的方向更新它。
-
通过 链式法则(Chain Rule) 计算每个权重的梯度(导数)。
-
使用 梯度下降(Gradient Descent) 或 Adam 优化器 进行参数更新。
梯度下降
梯度下降通过计算损失函数对参数的梯度,然后沿着梯度的反方向更新参数,使损失最小化。
更新公式:
W = W − η ⋅ ∂ L o s s ∂ W W = W - \eta \cdot \frac{\partial Loss}{\partial W} W=W−η⋅∂W∂Loss
b = b − η ⋅ ∂ L o s s ∂ b b = b - \eta \cdot \frac{\partial Loss}{\partial b} b=b−η⋅∂b∂Loss
其中:
- η \eta η 是学习率(Learning Rate),控制更新步长。
- ∂ L o s s ∂ W \frac{\partial Loss}{\partial W} ∂W∂Loss 是权重的梯度。
- ∂ L o s s ∂ b \frac{\partial Loss}{\partial b} ∂b∂Loss 是偏置的梯度。
梯度下降的三种变体
-
批量梯度下降(Batch Gradient Descent, BGD)
- 计算所有样本的平均梯度,然后更新参数。
- 优点:收敛稳定。
- 缺点:计算慢,适用于小规模数据。
-
随机梯度下降(Stochastic Gradient Descent, SGD)
- 每次更新使用一个样本。
- 优点:速度快,适用于大数据集。
- 缺点:参数更新有较大波动。
-
小批量梯度下降(Mini-Batch Gradient Descent, MBGD)
- 每次更新使用一小批样本(如 32 或 64 个) 。
- 优点:平衡计算效率和稳定性,实际应用最广泛。
激活函数(Activation Function)
决定了神经元的输出如何传递到下一层
激活函数用于引入非线性,使神经网络可以学习复杂模式。
为什么需要激活函数?
在没有激活函数的情况下,每一层的输出都是上一层的线性变换:
y = W x + b y = W x + b y=Wx+b
多个这样的线性层堆叠仍然是一个线性变换,无法学习复杂的非线性特征。而激活函数可以引入非线性,使得神经网络可以逼近任意复杂的函数。加快收敛
为什么输出层不使用激活函数?
- Q 值可以是正数或负数,使用非线性激活(如 ReLU)会截断负值,影响学习效果。
- 直接输出 Q 值,使得优化更加稳定。
| 激活函数 | 公式 | 特点 | 输出 |
|---|---|---|---|
| Sigmoid | σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1 | 适用于二分类,但易梯度消失 | 输出范围: ( 0 , 1 ) (0,1) (0,1) |
| Tanh | tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x | 归一化到 (-1,1),但仍可能梯度消失 | 输出范围: ( − 1 , 1 ) (-1,1) (−1,1) |
| ReLU | f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x) | 计算简单,能缓解梯度消失,常用于深度网络 | 大于 0 时输出本身,小于 0 时输出 0 |
| Leaky ReLU | f ( x ) = x f(x) = x f(x)=x(若 x > 0), 0.01 x 0.01x 0.01x(若 x < 0) | 改进 ReLU,允许负值信息通过 | |
| Softmax | e x i ∑ e x j \frac{e^{x_i}}{\sum e^{x_j}} ∑exjexi | 多分类任务的概率输出 | 所有输出加起来等于 1,表示“概率分布” |
神经网络的训练过程
- 初始化参数(随机初始化权重 W 和偏置 b)。
- 前向传播(计算输出)。
- 计算损失(计算误差,如交叉熵)。
- 反向传播(计算梯度)。
- 更新参数(使用梯度下降算法)。
- 重复步骤 2-5,直到收敛。
深度神经网络 (Deep Neural Network, DNN)
深度神经网络(DNN)是由 多层神经元 组成的 人工神经网络(ANN) ,用于建模复杂的非线性关系。
深度神经网络的基本结构
DNN 由 输入层(Input Layer)、多个隐藏层(Hidden Layers)和输出层(Output Layer) 组成:
输入层 → 隐藏层 → 隐藏层 → ... → 隐藏层 → 输出层
输入层
-
负责接收数据(如图像、文本、传感器数据)。
-
每个神经元对应一个输入特征,例如:
- 图像数据:每个像素值作为一个输入特征。
- 强化学习:状态向量的每个维度作为输入特征。
隐藏层
-
作用:
- 低层隐藏层 负责提取基础特征(如边缘、纹理)。
- 高层隐藏层 负责学习更抽象的概念(如物体、行为模式)。
输出层
-
计算最终结果:
- 分类任务:使用 Softmax 计算类别概率。
- 回归任务:直接输出一个数值。
- 强化学习(DQN) :输出每个动作的 Q 值。
深度神经网络的计算过程
初始化参数
-
设定神经网络的结构(输入层、隐藏层、输出层的神经元数量)。
-
随机初始化每层的权重(Weights)和偏置(Biases) ,确保网络具有一定的初始多样性。
-
参数 作用 直观解释 权重(Weight) 调整输入对输出的影响大小 课堂作业占 60%,家庭作业占 40%,决定你的最终成绩 偏置(Bias) 调整整体输出,使网络更灵活 额外加分,即使作业分低,也能保证一定成绩 💡 一句话总结:
权重决定输入的影响力,偏置帮助调整整体输出,使模型更加灵活和准确
-
💡 通俗理解:
想象 DNN 是一个“考试系统”,权重就是评分标准,我们最开始不清楚如何评分,所以先随机设置一个标准。
前向传播(Forward Propagation)
前向传播的目标是计算预测值( y pred y_{\text{pred}} ypred),主要包括:
-
计算每层的线性变换:
Z = W ⋅ X + B Z = W \cdot X + B Z=W⋅X+B
其中:
- X X X 是输入数据(或上一层的输出)。
- W W W 是权重矩阵。
- B B B 是偏置项。
-
应用激活函数:
- ReLU(用于隐藏层): A = max ( 0 , Z ) A = \max(0, Z) A=max(0,Z)
- Sigmoid / Softmax(用于输出层):将结果转换为概率。
💡 通俗理解:
想象我们在烤披萨:
- 原料(输入数据)经过厨师(神经元)处理,每个厨师都有自己的配方(权重和偏置)。
- 处理后得到半成品(线性变换)。
- 最后通过调味(激活函数)让披萨更加美味(可解释性强)。
计算损失(Loss Function)
-
预测值( y pred y_{\text{pred}} ypred)和真实值( y true y_{\text{true}} ytrue)进行比较,计算误差(损失)。
-
常见损失函数:
-
均方误差(MSE) :用于回归任务
L = 1 n ∑ ( y pred − y true ) 2 L = \frac{1}{n} \sum (y_{\text{pred}} - y_{\text{true}})^2 L=n1∑(ypred−ytrue)2
-
交叉熵(Cross Entropy) :用于分类任务
L = − ∑ y true log ( y pred ) L = -\sum y_{\text{true}} \log(y_{\text{pred}}) L=−∑ytruelog(ypred)
-
💡 通俗理解:
相当于“考试批改分数”:
- 如果预测分数和标准答案差距大,说明误差大,需要修改评分标准(调整权重)。
- 目标是让误差尽可能小。
反向传播(Backpropagation)
反向传播的目标是通过**梯度下降(Gradient Descent)**调整权重,使预测误差最小化。
-
计算损失对权重的梯度(偏导数)
-
通过链式法则计算每个权重对损失的影响:
∂ L ∂ W \frac{\partial L}{\partial W} ∂W∂L
-
反向逐层传播,计算每层的梯度。
-
-
更新权重和偏置
-
使用梯度下降或Adam优化器等方法,更新网络参数:
W = W − α ∂ L ∂ W W = W - \alpha \frac{\partial L}{\partial W} W=W−α∂W∂L
B = B − α ∂ L ∂ B B = B - \alpha \frac{\partial L}{\partial B} B=B−α∂B∂L
-
α \alpha α 是学习率,控制每次更新的步长。
-
💡 通俗理解:
相当于“学生复习”:
- 发现考试成绩不好(损失较大)。
- 通过老师(梯度计算)找到哪些知识点薄弱(哪一层的权重导致错误)。
- 重点复习(更新参数),提高成绩。
重复训练,直到收敛
- 反复执行前向传播 → 计算损失 → 反向传播 → 更新权重,直到损失函数趋于稳定,达到最优状态。
- 设定训练轮数(Epochs),比如 1000 次,每次都让网络调整得更好。
💡 通俗理解:
就像练习投篮:
- 一开始投得不准(误差大)。
- 通过反复练习(训练),不断调整手感(优化权重)。
- 最终稳定命中目标(收敛)。
卷积神经网络(Convolutional Neural Network, CNN)
卷积神经网络(CNN)是一种专门用于处理 图像数据 和 时空相关数据 的深度学习模型。
它利用 局部感受野 和 权重共享 机制,大幅减少参数数量,提高计算效率,同时保留数据的局部特征。
CNN 的基本结构
CNN 由多个 卷积层、池化层、全连接层 组成,典型结构如下:
输入层 → 卷积层 → ReLU → 池化层 → 卷积层 → ReLU → 池化层 → 全连接层 → 输出层
CNN 的完整算法流程
用一个识别猫和狗的例子来说明 CNN 的工作流程。
输入层(Input Layer):加载图片数据
首先,把一张猫的图片输入到 CNN 中。例如,这是一张 32×32 像素的彩色图片:
🐱
因为彩色图片有红(R)、绿(G)、蓝(B)三个通道(Channel),所以输入的数据是一个 32×32×3 的矩阵。
卷积层(Convolutional Layer)
作用: 识别图片中的特征,比如边缘、线条、颜色块等。
计算方法:
-
CNN 使用 滤波器(卷积核, Kernel) 进行扫描,提取特征。
-
例如,使用 3×3 卷积核,在图片上滑动(步长 1),计算新像素值:
-
计算公式:
输出 = 输入区域 × 卷积核 + 偏置 输出 = 输入区域 \times 卷积核 + 偏置 输出=输入区域×卷积核+偏置
-
如果有多个卷积核,可以提取多个特征(比如边缘、纹理等)。
-
-
这样,我们从 32×32×3 的输入图片,得到了一个 30×30×8 的特征图(假设 8 个卷积核)
📌 通俗理解:
想象你用一个小窗口(3×3 的滤波器)去观察猫的图片:
- 第一个滤波器 只关注边缘(比如猫的耳朵)。
- 第二个滤波器 可能关注颜色对比(比如猫的毛色)。
- 第三个滤波器 可能检测曲线(比如猫的胡须)。
最终,我们得到了多个特征图,这些图比原图更有信息量。
激活函数(Activation Function, ReLU)
作用: 增强模型的非线性表达能力,使 CNN 能够学习复杂的特征。
-
ReLU(Rectified Linear Unit) 是最常用的激活函数:
f ( x ) = m a x ( 0 , x ) f(x) = max(0, x) f(x)=max(0,x)
-
它的作用是把所有 负数变成 0,只保留 正数,让模型更具判别能力。
📌 通俗理解:
假设你的 CNN 学到了一些模糊的、无用的特征(比如背景的噪声),ReLU 就会把它们“关掉”(变成 0),只保留有用的信息(比如猫的形状)。
池化层(Pooling Layer)
作用: 降维,减少计算量,同时保留重要特征。
-
采用 最大池化(Max Pooling) ,用 2×2 过滤器,步长为 2。
-
只取 2×2 区域中的 最大值,这样图像尺寸缩小了一半:
- 输入:30×30×8
- 经过池化后,输出变为 15×15×8
📌 通俗理解:
你拍了一张猫的照片,但不想存 4K 超清版,所以你压缩图片,让它变小,但仍然保留猫的主要轮廓。
例如:
🐱🐱🐱🐱 → 🐱🐱 🐱🐱🐱🐱 → 🐱🐱这样,数据量减少了一半,但关键信息仍然存在。
重复多个卷积层和池化层
为了提取更深层次的特征,我们可以 叠加多层卷积层和池化层。
- 第一层可能提取 边缘
- 第二层可能提取 眼睛、鼻子
- 第三层可能识别 完整的猫脸
最终,我们得到一个小尺寸的特征图(如 7×7×16)。
全连接层(Fully Connected Layer, FC)
作用: 把 2D 特征图展开为 1D 向量,然后用于分类。
-
把池化后的特征图(7×7×16)展平成一个 1D 向量(长度 784)。
-
连接到 隐藏层(Hidden Layer) ,使用 全连接神经元 进行学习。
-
使用 Softmax 函数 计算最终分类概率:
- 猫 🐱:85%
- 狗 🐶:15%
📌 通俗理解:
想象你在考试,每道题都是关于猫或狗的特征:
- 这只动物有胡须吗?✅
- 这只动物有长耳朵吗?❌
- 这只动物喜欢爬树吗?✅
你回答了所有问题后,神经网络根据你的回答计算出:
- 85% 可能是猫
- 15% 可能是狗
最终 CNN 选择 猫!🐱✅
CNN 运行流程总结
| 步骤 | 作用 | 结果 |
|---|---|---|
| 1. 输入层 | 读取图片(如 32×32×3) | 3D 矩阵 |
| 2. 卷积层 | 提取局部特征(边缘、纹理) | 30×30×8 |
| 3. ReLU 激活 | 去掉负值,提高非线性能力 | 30×30×8 |
| 4. 池化层 | 降维,保留重要特征 | 15×15×8 |
| 5. 叠加多个卷积-池化层 | 提取更高级特征 | 7×7×16 |
| 6. 全连接层 | 把特征转换成分类 | 1D 向量 |
| 7. Softmax 输出层 | 计算类别概率 | 猫 85%,狗 15% |
结论
- CNN 通过 卷积层 提取特征,池化层 降低数据维度,全连接层 进行分类。
- CNN 的特点是自动学习特征,比传统方法更高效。
- 适用于 图像分类、目标检测、语音识别等 任务。
DNN 与 CNN 的比较
- 使用 DNN:当数据是 结构化数据 或 一维数据,如表格数据、金融数据、时间序列数据时,DNN 适合解决传统的回归或分类问题。
- 使用 CNN:当数据是 图像、视频 等具有 空间或时序结构 的数据时,CNN 是处理这些数据的首选。CNN 能够有效提取局部特征并通过共享权重提升计算效率,广泛应用于计算机视觉、语音识别、NLP 等任务
| 特性 | DNN (深度神经网络) | CNN (卷积神经网络) |
|---|---|---|
| 数据类型 | 适用于一维数据、结构化数据、表格数据 | 适用于具有空间结构的数据,如图像、视频 |
| 任务 | 适合回归、分类任务(例如金融、医疗预测) | 适合图像分类、物体检测、视频处理、NLP |
| 层结构 | 全连接层(每个节点与上一层的所有节点相连) | 卷积层、池化层和全连接层 |
| 局部特征学习 | 无特殊机制,学习全局特征 | 通过卷积层自动提取局部特征 |
| 计算效率 | 参数多,计算量大 | 参数少,计算高效 |
| 平移不变性 | 不具备平移不变性 | 卷积层通过共享参数具有平移不变性 |
深度 Q 网络(DQN)
-
DQN(Deep Q-Network)是 强化学习(RL) 和 深度学习(DL) 结合的算法。
-
DQN 解决了传统 Q-learning 的问题,即在高维状态空间中无法存储巨大的 Q 表格。因此,它采用 神经网络 来近似 Q 值,突破了 Q-learning 的局限。
-
目标: 让智能体学会 在不同的状态下选择最优的动作,以最大化长期奖励。例如,假设你在玩贪吃蛇,DQN 会帮助你学会如何躲避障碍物、吃到更多的食物,并存活更久。
DQN 与 Q-learning 的区别
| Q-learning | DQN | |
|---|---|---|
| Q 值存储 | Q 表格(查表方式) | 深度神经网络(函数逼近) |
| 适用范围 | 低维状态空间 | 高维状态空间(如图像) |
| 经验回放 | ❌ 没有 | ✅ 采用 Replay Buffer |
| 目标 Q 值 | ✅ 直接更新 | ✅ 采用目标网络防止震荡 |
DQN 的核心技术
经验回放(Experience Replay)
- 传统 Q-learning 直接用新数据更新 Q 值,容易受最新样本影响,导致训练不稳定。
- DQN 采用 Replay Buffer 存储过去经验(状态、动作、奖励、下一状态) ,然后 随机抽样 进行训练,提高数据利用率并减少数据相关性。
目标网络(Target Network)
- 直接用当前 Q 网络计算目标 Q 值可能导致目标值变化过快,训练不稳定。
- DQN 两个独立的网络(在线 网络-Q值更新和目标网络-计算目标Q值) ,每隔一段时间复制主 Q 网络参数,使目标 Q 值变化更平稳。
误差裁剪(Clipping the Error)
- 误差过大会导致梯度爆炸,影响训练稳定性。
- DQN 限制 TD 误差( δ \delta δ)在一个范围内,使梯度下降更稳定。
DQN 算法流程
一个小机器人学走迷宫的例子来讲解 DQN 的完整算法流程。
环境设置
首先,定义迷宫:
- 机器人(Agent)在一个 5×5 的迷宫 里。
- 它可以执行 4 种动作:上(↑)、下(↓)、左(←)、右(→) 。
- 它的目标是走到终点(🏆) ,到达终点后获得奖励 +100。
- 每走一步消耗 1 分(-1),撞墙没有奖励(0)。
初始化
- 建立 Q 网络(Q-Network) :用 神经网络 近似 Q 值函数 Q ( s , a ) Q(s, a) Q(s,a),即估算 在状态 s s s 下执行动作 a a a 能获得的总奖励。
- 复制目标 Q 网络(Target Q-Network) ,它和 Q 网络结构相同,但用于计算稳定的目标 Q 值。
- 初始化经验回放池(Replay Memory) ,用来存储智能体的经历,避免训练时的相关性问题。
🔹 通俗理解:
就像一个新手在玩游戏时,他会先看高手怎么玩(Q 网络学习历史经验),然后自己尝试,并从经验中改进策略。
交互(智能体在环境中探索)
智能体会不断尝试不同的动作,并观察环境的反馈:
-
在当前状态 s s s 下,基于 Q 值选择动作 a a a,决定走哪一个方向:
-
以概率 ϵ \epsilon ϵ 探索(Exploration,随机尝试) :比如 10% 的概率,机器人随便选一个方向。
-
以概率 1 − ϵ 1-\epsilon 1−ϵ 利用(Exploitation,使用已有经验) :比如 90% 的概率,选择当前 Q 值最高的动作。
👉 通俗理解:
如果你第一次去一个新的商场,你可能会到处走走看看(探索) ,等你熟悉了路线,你就会选择最短的路(利用) 。
-
-
执行动作 a a a (比如“向右走”),并观察新的状态 s ′ s' s′ 和奖励 r r r
- 如果撞墙了,奖励 0;
- 如果走到正确的路径,奖励 -1(因为消耗了一步);
- 如果到达终点🏆,奖励 +100。
-
存储经历 ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′) 到经验回放池中。
- 机器人把这一步的经历 (状态、动作、奖励、下一个状态) 存入经验池(Replay Buffer) 。
- 经验池会定期取出一些数据,训练神经网络。
🔹 通俗理解:
DQN 在游戏中不断尝试新的策略,就像一个玩家刚开始玩游戏时,会随机尝试按键,但随着经验积累,他会越来越聪明,知道什么时候该跳,什么时候该继续跑。
经验回放(Replay Memory)
智能体不会直接用最新的经历训练,而是从经验回放池中 随机抽取一批数据 进行训练。这样可以:
- 避免训练数据相关性过高(减少过拟合)。
- 让智能体更稳定地学习策略。
B = { ( s i , a i , r i , s i ′ } i = 1 N \mathcal{B} = \{(s_i, a_i, r_i, s'_i\}_{i=1}^{N} B={(si,ai,ri,si′}i=1N
🔹 通俗理解:
如果一个玩家玩游戏时 只记得最近几秒的经历,他可能做出不理智的决策。而经验回放相当于回顾整个游戏的经历,从过去的错误中学习,提高游戏技巧。
计算目标 Q 值(Target Q-Value)
使用目标 Q 网络(Target Q-Network) 计算 Q 值的更新目标:
Q target = r + γ max a ′ Q target ( s ′ , a ′ ) Q_{\text{target}} = r + \gamma \max_{a'} Q_{\text{target}}(s', a') Qtarget=r+γa′maxQtarget(s′,a′)
-
r r r:当前动作的奖励。
-
γ \gamma γ (折扣因子) :衡量未来奖励的重要性,取值一般在 0.9 左右。
-
max a ′ Q target ( s ′ , a ′ ) \max_{a'} Q_{\text{target}}(s', a') maxa′Qtarget(s′,a′):目标 Q 网络估算下一个状态的最大 Q 值。
-
如果游戏结束,则:
Q target = r Q_{\text{target}} = r Qtarget=r
因为没有下一个状态。
🔹 通俗理解:
DQN 预测 未来的最佳得分,然后调整当前的策略,以获得更高的总奖励。就像一个玩家预测下一步的得分,并优化自己的游戏策略。
计算示例
假设经验池中抽取了一个样本:
( s = 1 , a = "跳" , r = + 1 , s ′ = 2 ) ( s = 1, a = \text{"跳"}, r = +1, s' = 2) (s=1,a="跳",r=+1,s′=2)
并且 目标 Q 网络 计算出的 下一个状态 s ′ = 2 s' = 2 s′=2 的 Q 值如下:
Q target ( s ′ = 2 , a ′ ) = [ 5.0 , 3.2 , 4.1 ] Q_{\text{target}}(s' = 2, a') = [5.0, 3.2, 4.1] Qtarget(s′=2,a′)=[5.0,3.2,4.1]
其中:
- “跳跃” 对应的 Q 值是 5.0
- “蹲下” 对应的 Q 值是 3.2
- “加速” 对应的 Q 值是 4.1
则:
Q target = r + γ max a ′ Q target ( s ′ , a ′ ) Q_{\text{target}} = r + \gamma \max_{a'} Q_{\text{target}}(s', a') Qtarget=r+γa′maxQtarget(s′,a′)
= 1 + 0.99 × 5.0 = 5.95 = 1 + 0.99 \times 5.0 = 5.95 =1+0.99×5.0=5.95
训练 Q 网络(更新策略)
使用均方误差(MSE)损失函数来更新 Q 网络,
计算损失:
L = 1 N ∑ i = 1 N ( Q ( s i , a i ) − Q target , i ) 2 \mathcal{L} = \frac{1}{N} \sum_{i=1}^{N} \big(Q(s_i, a_i) - Q_{\text{target}, i}\big)^2 L=N1i=1∑N(Q(si,ai)−Qtarget,i)2
其中:
- Q ( s i , a i ) Q(s_i, a_i) Q(si,ai) 是当前 Q 网络预测的 Q 值
- Q target , i Q_{\text{target}, i} Qtarget,i 是目标 Q 值
计算示例: 如果当前 Q 网络计算出的 Q 值为:
Q ( s = 1 , a = "跳" ) = 5.2 Q(s = 1, a = \text{"跳"}) = 5.2 Q(s=1,a="跳")=5.2
那么损失:
L = ( 5.2 − 5.95 ) 2 = 0.5625 \mathcal{L} = (5.2 - 5.95)^2 = 0.5625 L=(5.2−5.95)2=0.5625
🔹 通俗理解:
就像玩家在游戏中不断调整策略,以减少失误,提高分数。
更新目标 Q 网络
- 每隔一定步数 复制 Q 网络的参数 到 目标 Q 网络 中,以保持稳定性。
- 这样可以避免训练时 Q 值的剧烈波动,提高学习效果。
使用**梯度下降(如 Adam 优化器)**更新 Q 网络参数,使其更好地预测 Q 值:
θ = θ − α ∇ θ L \theta = \theta - \alpha \nabla_{\theta} \mathcal{L} θ=θ−α∇θL
其中:
- θ \theta θ:Q 网络的参数
- α \alpha α:学习率
🔹 通俗理解:
这一步就像一个玩家在反复练习游戏,不断修正错误,提高自己的决策水平。
DQN 运行流程总结
| 步骤 | 作用 |
|---|---|
| 1. 初始化 Q 网络 | 用神经网络存储 Q 值 |
| 2. 选择动作 | 90% 选择最优,10% 选择随机 |
| 3. 执行动作 | 获取奖励,观察环境 |
| 4. 记录经验 | 存入经验池 |
| 5. 计算目标 Q 值 | 使用 Q-learning 公式 |
| 6. 训练神经网络 | 用梯度下降优化 Q 值 |
| 7. 更新目标网络 | 提高训练稳定性 |
| 8. 继续训练 | 直到找到最优策略 |
结论
- DQN 结合 Q-Learning 和深度神经网络,能在复杂环境下学习最优策略。
- 经验回放 让智能体避免过拟合,提高泛化能力。
- 目标 Q 网络 使训练更稳定,避免 Q 值波动。
- 适用于 游戏 AI、机器人控制、自动驾驶等场景。
Actor-Critic
Actor-Critic(AC)算法是一种结合了策略梯度方法(Policy Gradient)和值函数方法(Value Function Method) 的强化学习算法。
它同时利用了 策略网络(Actor) 来选择动作,以及 价值网络(Critic) 来评估动作的好坏,从而提高训练稳定性和样本效率。
核心在于:
- Actor 负责动作选择,通过策略梯度更新
- Critic 负责动作评估,通过 TD 误差更新
🔹 通俗理解:
- Actor(行动者):它就像一个“冒险家”,负责决定下一步往哪里走(比如往左一步还是往右一步)。但它并不总是很聪明,可能会选错方向。
- Critic(评论者):它就像一个“导师”,站在一旁,评价冒险家的表现。它会告诉Actor:“这一步走得好,接近山顶了”或者“走错了,离山顶更远了”。
- Actor的目标:学习一个好的策略,尽可能选择能达到山顶的动作。
- Critic的目标:准确地评估每一步的表现,帮助Actor改进。
强化学习的目标是找到最优策略 π ∗ \pi^* π∗,使得智能体在环境中获得最大累积奖励期望:
J ( θ ) = E [ ∑ t = 0 ∞ R t ] J(\theta) = \mathbb{E} \left[ \sum_{t=0}^{\infty} R_t \right] J(θ)=E[t=0∑∞Rt]
其中:
- θ \theta θ 是 Actor 网络的参数。
- R t R_t Rt 是从 t t t 时刻开始的总回报。
计算策略对数的梯度
需要计算策略对数的梯度 ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta \log \pi_\theta (a_t | s_t) ∇θlogπθ(at∣st),用于更新 Actor 网络。
这个梯度的求解取决于策略的参数化方式,通常有两种情况:
-
离散动作空间(Softmax 策略)
-
在离散动作情况下,我们可以使用 Softmax 作为策略:
π θ ( a ∣ s ) = e f θ ( s , a ) ∑ a ′ e f θ ( s , a ′ ) \pi_\theta (a | s) = \frac{e^{f_\theta(s, a)}}{\sum_{a'} e^{f_\theta(s, a')}} πθ(a∣s)=∑a′efθ(s,a′)efθ(s,a)
其中:
- f θ ( s , a ) f_\theta(s, a) fθ(s,a) 是 神经网络输出的标量值,表示在状态 s s s 下选择动作 a a a 的偏好值(logits)。
- Softmax 确保所有动作的概率之和为 1。
求导过程:
∇ θ log π θ ( a t ∣ s t ) = ∇ θ f θ ( s t , a t ) − ∑ a ′ π θ ( a ′ ∣ s t ) ∇ θ f θ ( s t , a ′ ) \nabla_\theta \log \pi_\theta (a_t | s_t) = \nabla_\theta f_\theta(s_t, a_t) - \sum_{a'} \pi_\theta (a' | s_t) \nabla_\theta f_\theta(s_t, a') ∇θlogπθ(at∣st)=∇θfθ(st,at)−a′∑πθ(a′∣st)∇θfθ(st,a′)
解释:
- 第一项 ∇ θ f θ ( s t , a t ) \nabla_\theta f_\theta(s_t, a_t) ∇θfθ(st,at) :提升选择 a t a_t at 的概率。
- 第二项 ∑ a ′ π θ ( a ′ ∣ s t ) ∇ θ f θ ( s t , a ′ ) \sum_{a'} \pi_\theta (a' | s_t) \nabla_\theta f_\theta(s_t, a') ∑a′πθ(a′∣st)∇θfθ(st,a′) :保持总概率归一性,避免影响其他动作的分布。
-
-
连续动作空间(高斯策略)
-
如果动作是连续的,我们通常假设策略 π θ ( a ∣ s ) \pi_\theta(a | s) πθ(a∣s) 服从 高斯分布:
π θ ( a ∣ s ) = 1 2 π σ 2 exp ( − ( a − μ θ ( s ) ) 2 2 σ 2 ) \pi_\theta (a | s) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(a - \mu_\theta(s))^2}{2\sigma^2}\right) πθ(a∣s)=2πσ21exp(−2σ2(a−μθ(s))2)
其中:
- μ θ ( s ) \mu_\theta(s) μθ(s) 是 Actor 网络输出的均值(可训练)。
- σ 2 \sigma^2 σ2 是固定的方差(或者也是可训练的)。
求导过程:
∇ θ log π θ ( a t ∣ s t ) = ( a t − μ θ ( s t ) ) σ 2 ∇ θ μ θ ( s t ) \nabla_\theta \log \pi_\theta (a_t | s_t) = \frac{(a_t - \mu_\theta(s_t))}{\sigma^2} \nabla_\theta \mu_\theta(s_t) ∇θlogπθ(at∣st)=σ2(at−μθ(st))∇θμθ(st)
- 这里的梯度仅涉及均值 μ θ ( s ) \mu_\theta(s) μθ(s) 的梯度,因为在大多数实现中,方差 σ 2 \sigma^2 σ2 是固定的(或单独训练)。
- 这个梯度可以直观理解为:如果动作 a t a_t at 偏离均值 μ θ ( s t ) \mu_\theta(s_t) μθ(st) ,则调整均值,使其更接近有利的方向。
-
更新策略的梯度
更新策略的梯度可以表示为:
∇ θ J ( θ ) = E [ δ t ∇ θ log π θ ( a t ∣ s t ) ] \nabla_\theta J(\theta) = \mathbb{E} \left[ \delta_t \nabla_\theta \log \pi_\theta (a_t | s_t) \right] ∇θJ(θ)=E[δt∇θlogπθ(at∣st)]
其中:
-
δ t \delta_t δt 是 Critic 提供的 TD 误差:
δ t = r t + γ V w ( s t + 1 ) − V w ( s t ) \delta_t = r_t + \gamma V_w(s_{t+1}) - V_w(s_t) δt=rt+γVw(st+1)−Vw(st)
-
∇ θ log π θ ( a t ∣ s t ) \nabla_\theta \log \pi_\theta (a_t | s_t) ∇θlogπθ(at∣st) 是策略对数的梯度,表示策略随参数的变化率。
具体算法流程
初始化网络
-
创建Actor 网络,参数 θ \theta θ,用于选择动作 a a a:
π θ ( a ∣ s ) = P ( a ∣ s ) \pi_{\theta}(a|s) = P(a|s) πθ(a∣s)=P(a∣s)
(即:在状态 s s s 下执行动作 a a a 的概率)
-
创建Critic 网络,参数 w w w,用于评估状态值 V ( s ) V(s) V(s):
V w ( s ) V_w(s) Vw(s)
(即:状态 s s s 的长期收益估计)
-
设定学习率 α , β \alpha, \beta α,β 和折扣因子 γ \gamma γ。
🔹 通俗理解:
- Actor 负责决策(就像玩家)。
- Critic 负责评价(就像教练)。
- 两个网络相互配合,不断改进策略。
交互环境,获取经验
-
在当前状态 s t s_t st,Actor 通过策略 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s) 选择一个动作:
a t ∼ π θ ( a t ∣ s t ) a_t \sim \pi_{\theta}(a_t | s_t) at∼πθ(at∣st)
-
执行动作 a t a_t at,观察新状态 s t + 1 s_{t+1} st+1 和奖励 r t r_t rt:
( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1)
🔹 通俗理解:
- Actor 就像一个玩家,根据策略选择动作。
- 游戏环境反馈新的状态和得分。
计算 TD 误差(Temporal Difference Error)
Critic 用 TD 误差来评估当前状态的收益是否比预期好:
δ t = r t + γ V w ( s t + 1 ) − V w ( s t ) \delta_t = r_t + \gamma V_w(s_{t+1}) - V_w(s_t) δt=rt+γVw(st+1)−Vw(st)
其中:
- r t r_t rt 是当前奖励(Agent 执行动作后环境返回的分数)
- γ \gamma γ是折扣因子(用于衡量未来奖励的重要性,一般设定为 0.9 或 0.99)
- γ V w ( s t + 1 ) \gamma V_w(s_{t+1}) γVw(st+1) 代表下一个状态的预期收益
- V w ( s t ) V_w(s_t) Vw(st) 代表当前状态的预期收益
解释
- 如果 δ t > 0 \delta_t > 0 δt>0,说明这个动作比预期好,应该鼓励;
- 如果 δ t < 0 \delta_t < 0 δt<0,说明这个动作比预期差,应该减少执行的可能性。
🔹 通俗理解:
- Critic 就像一个教练,他预测了一名球员的表现,但比赛结果可能比预测的好(或差)。
- 通过比较预期值和实际表现的差异,教练可以修正自己未来的评估。
更新 Critic 网络
计算Critic 网络的梯度
Critic 通过最小化 TD 误差来优化自己的评估能力,通常使用 均方误差(MSE) 来衡量 TD 误差
计算损失函数 L ( w ) L(w) L(w)
L ( w ) = 1 2 ( δ t ) 2 L(w) = \frac{1}{2} ( \delta_t )^2 L(w)=21(δt)2
然后计算损失函数 L ( w ) L(w) L(w) 对 Critic 网络参数 w w w 的梯度
对损失函数 L ( w ) L(w) L(w) 求参数 w w w 的梯度:
∇ w L ( w ) = 损失函数 L ( w ) 对 w 的梯度 \nabla_w L(w) = \text{损失函数 } L(w) \text{ 对 } w \text{ 的梯度} ∇wL(w)=损失函数 L(w) 对 w 的梯度
表示:
∇ w L ( w ) = ∇ w 1 2 ( δ t ) 2 \nabla_w L(w) = \nabla_w \frac{1}{2} ( \delta_t )^2 ∇wL(w)=∇w21(δt)2
使用幂函数求导公式 ∇ x 1 2 x 2 = x ⋅ ∇ x x \nabla_x \frac{1}{2} x^2 = x \cdot \nabla_x x ∇x21x2=x⋅∇xx,得到:
∇ w L ( w ) = δ t ⋅ ∇ w δ t \nabla_w L(w) = \delta_t \cdot \nabla_w \delta_t ∇wL(w)=δt⋅∇wδt
由于:
δ t = r t + γ V w ( s t + 1 ) − V w ( s t ) \delta_t = r_t + \gamma V_w(s_{t+1}) - V_w(s_t) δt=rt+γVw(st+1)−Vw(st)
奖励 r t r_t rt 是常数,对 w w w 的梯度为 0,所以:
∇ w δ t = ∇ w ( γ V w ( s t + 1 ) − V w ( s t ) ) \nabla_w \delta_t = \nabla_w (\gamma V_w(s_{t+1}) - V_w(s_t)) ∇wδt=∇w(γVw(st+1)−Vw(st))
对参数 w w w 求梯度:
∇ w δ t = − ∇ w V w ( s t ) \nabla_w \delta_t = -\nabla_w V_w(s_t) ∇wδt=−∇wVw(st)
假设我们使用的是 TD(0) 方法(即不对未来状态 s t + 1 s_{t+1} st+1 的值函数求梯度)
因为:
- V w ( s t ) V_w(s_t) Vw(st) 是 Critic 网络的输出,依赖于参数 w w w;
- 不对 V w ( s t + 1 ) V_w(s_{t+1}) Vw(st+1) 求梯度,因为它是对未来的估计,通常被视为常数(类似目标值的作用)。
那么:
∇ w L ( w ) = δ t ⋅ ( − ∇ w V w ( s t ) ) \nabla_w L(w) = \delta_t \cdot (-\nabla_w V_w(s_t)) ∇wL(w)=δt⋅(−∇wVw(st))
去掉负号:
∇ w L ( w ) = δ t ∇ w V w ( s t ) \nabla_w L(w) = \delta_t \nabla_w V_w(s_t) ∇wL(w)=δt∇wVw(st)
🔹通俗理解:
- Critic 的目标是让自己的预测更准确,所以它用梯度下降来调整自己的参数。
更新 Critic 网络参数
Critic 梯度下降法(Gradient Descent) ,参数 w w w 的更新规则是:
w ← w − β ∇ w L ( w ) w \leftarrow w - \beta \nabla_w L(w) w←w−β∇wL(w)
其中:
- β \beta β 是学习率,控制更新步长。
- ∇ w L ( w ) \nabla_w L(w) ∇wL(w) 是损失函数的梯度。
将 ∇ w L ( w ) = − δ t ∇ w V w ( s t ) \nabla_w L(w) = -\delta_t \nabla_w V_w(s_t) ∇wL(w)=−δt∇wVw(st) 代入:
w ← w − β ( − δ t ∇ w V w ( s t ) ) w \leftarrow w - \beta (-\delta_t \nabla_w V_w(s_t)) w←w−β(−δt∇wVw(st))
化简得到:
w ← w + β δ t ∇ w V w ( s t ) w \leftarrow w + \beta \delta_t \nabla_w V_w(s_t) w←w+βδt∇wVw(st)
- w w w 是 Critic 网络的参数
- β \beta β 是 Critic 的学习率(通常取 0.01 ∼ 0.001 0.01 \sim 0.001 0.01∼0.001)。
- δ t \delta_t δt 是 TD 误差,指导 Critic 如何调整自己的估计值。
- ∇ w V w ( s t ) \nabla_w V_w(s_t) ∇wVw(st) 是 Critic 价值函数的梯度(衡量 w w w 变化对状态值的影响)
返回
更新后的 Critic 网络 V w ( s ) V_w(s) Vw(s)。
🔹 通俗理解:
- Critic 根据误差的大小调整参数,如果误差大,它就会做大调整;如果误差小,它就做小调整。
更新 Actor 网络
-
计算 策略对数梯度:
∇ θ log π θ ( a t ∣ s t ) \nabla_\theta \log \pi_\theta (a_t | s_t) ∇θlogπθ(at∣st)
-
计算 Actor 更新方向:
δ t ∇ θ log π θ ( a t ∣ s t ) \delta_t \nabla_\theta \log \pi_\theta (a_t | s_t) δt∇θlogπθ(at∣st)
Actor 根据 Critic 计算的 TD 误差调整策略:
θ ← θ + α δ t ∇ θ log π θ ( a t ∣ s t ) \theta \leftarrow \theta + \alpha \delta_t \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) θ←θ+αδt∇θlogπθ(at∣st)
其中:
- α \alpha α 是学习率,控制 Actor 更新的步长。
- δ t \delta_t δt 指导 Actor 增加选择更优动作的概率。
直观理解:
- 如果 Critic 认为这个动作是好的(**** δ t > 0 \delta_t > 0 δt>0 ) ,Actor 就会增加选择这个动作的概率。
- 如果 Critic 认为这个动作是不好的(**** δ t < 0 \delta_t < 0 δt<0 ) ,Actor 就会减少选择这个动作的概率。
🔹 通俗理解:
- 如果玩家做对了,教练就会鼓励他多做类似的决策;
- 如果玩家做错了,教练会建议他少做类似的决策。
继续循环,直到收敛
重复步骤 2-5,不断优化策略,直到智能体的表现稳定。
📌 总结
| 步骤 | 主要任务 | 作用 |
|---|---|---|
| 1. 初始化网络 | 创建 Actor 和 Critic 网络 | Actor 负责决策,Critic 负责评价 |
| 2. 交互环境 | Actor 选择动作,执行并获取奖励 | 采集经验数据 |
| 3. 计算 TD 误差 | 计算 δ t = r + γ V ( s ′ ) − V ( s ) \delta_t = r + \gamma V(s') - V(s) δt=r+γV(s′)−V(s) | 评估动作是否优秀 |
| 4. 更新 Critic | 让 Critic 学习更准确地估计价值 | 提高评价能力 |
| 5. 更新 Actor | 让 Actor 调整策略,提高优秀动作的概率 | 让智能体学到最优策略 |
| 6. 继续循环 | 持续优化策略,直到收敛 | 让 AI 变得更强 |
深度确定性策略梯度(DDPG)
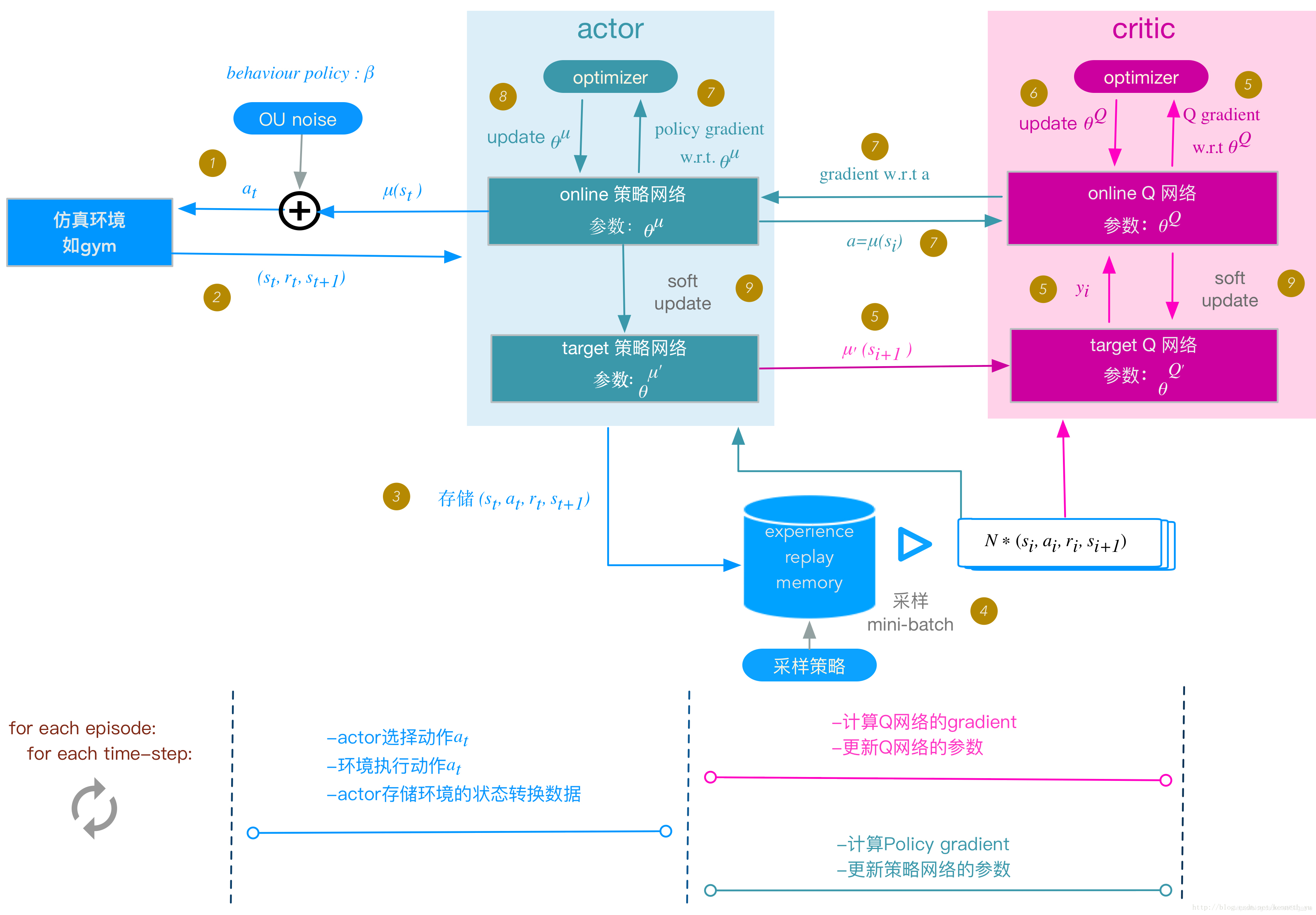
DDPG 关键思想
-
Actor 网络 μ θ ( s ) \mu_\theta(s) μθ(s):
- 输入状态 s s s,输出确定性的动作 a a a。
- 目标:找到最优策略,使得累积奖励最大化。
-
Critic 网络 Q w ( s , a ) Q_w(s, a) Qw(s,a):
- 输入状态 s s s 和 动作 a a a,输出该动作的 Q 值(即未来可能获得的奖励)。
- 目标:评估 Actor 选择的动作是否优越。
-
经验回放(Replay Buffer) :
- 采样经验数据 ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′) 来训练网络,避免样本相关性,提高训练稳定性。
-
目标网络(Target Network) :
- 维护两个目标网络 Q w ′ Q'_w Qw′ 和 μ θ ′ \mu'_\theta μθ′ 来缓慢跟随主网络更新,防止训练不稳定。
DDPG 详细算法流程
初始化
- 初始化 Actor 网络 μ θ ( s ) \mu_\theta(s) μθ(s)(策略网络)
- 初始化 Critic 网络 Q w ( s , a ) Q_w(s, a) Qw(s,a)(价值网络)
- 复制主网络参数,创建目标网络 Q w ′ Q'_w Qw′ 和 μ θ ′ \mu'_\theta μθ′,初始参数相同
- 初始化经验回放池 D D D
- 初始化噪声 N N N (如 OU 过程) 用于探索
训练循环(每一轮训练时执行)
(1)与环境交互,收集数据
-
使用 Actor 网络基于当前状态 s t s_t st 生成确定性动作 a t a_t at:
a t = μ θ ( s t ) a_t = \mu_\theta(s_t) at=μθ(st)
-
加入 Ornstein-Uhlenbeck (OU) 噪声 N t N_t Nt 进行探索(避免策略收敛到局部最优):
a t = μ θ ( s t ) + N t a_t = \mu_\theta(s_t) + N_t at=μθ(st)+Nt
物理解释:
- 现实世界中的智能体不能总是采取相同的动作,否则容易陷入局部最优解。因此,需要加入噪声 N t N_t Nt 进行探索。
- 这里使用的是Ornstein-Uhlenbeck (OU) 噪声,它能够模拟带惯性的随机过程,更适用于控制任务,例如机器人运动。
-
执行动作 ** a t a_t at**并与环境交互,获取奖励 r t r_t rt 和下一个状态 s t + 1 s_{t+1} st+1
-
存储经验 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1) 到经验回放池 D D D
(2)从经验池中随机采样 N N N 个样本
- 采用随机采样方式,避免数据相关性,从 D D D 中随机抽取一个 batch: ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′)
(3)更新 Critic 网络(Q 网络)
-
计算目标 Q 值(目标网络计算) :
y t = r t + γ Q w ′ ( s t + 1 , μ θ ′ ( s t + 1 ) ) y_t = r_t + \gamma Q'_w(s_{t+1}, \mu'_\theta(s_{t+1})) yt=rt+γQw′(st+1,μθ′(st+1))
其中:
- **$y_t $**是目标 Q 值,它表示从 s t s_t st 执行 a t a_t at 后,未来的累积回报。
- Q w ′ ( s t + 1 , μ θ ′ ( s t + 1 ) Q'_w(s_{t+1}, \mu'_\theta(s_{t+1}) Qw′(st+1,μθ′(st+1) 是目标 Critic 网络的 Q 值,未来的折扣回报
- γ \gamma γ 是折扣因子,用于平衡短期奖励和长期奖励,通常取 0.9 0.9 0.9 这样较高的值
-
最小化 Critic 网络损失:
L ( w ) = 1 N ∑ ( y t − Q w ( s , a ) ) 2 L(w) = \frac{1}{N} \sum (y_t - Q_w(s, a))^2 L(w)=N1∑(yt−Qw(s,a))2
使用梯度下降(Adam 优化器) 更新 Critic 参数 w w w:
w ← w − α ∇ w L ( w ) w \leftarrow w - \alpha \nabla_w L(w) w←w−α∇wL(w)
物理解释:
-
L ( w ) L(w) L(w) 是 Q 网络的损失函数,用于衡量 Critic 网络的预测误差。
-
目标 Q 值 y t y_t yt 和当前 Q 值 Q w ( s , a ) Q_w(s, a) Qw(s,a) 之间的均方误差(MSE) :
- 如果误差很大,说明 Critic 预测得不准,需要调整参数 w w w。
- 通过梯度下降(SGD)或 Adam 优化器更新 Q 网络的参数。
-
(4)更新 Actor 网络(基于策略梯度)
-
计算 Actor 网络的梯度:
∇ θ J ≈ 1 N ∑ ∇ θ μ θ ( s ) ∇ a Q w ( s , a ) ∣ a = μ θ ( s ) \nabla_\theta J \approx \frac{1}{N} \sum \nabla_\theta \mu_\theta(s) \nabla_a Q_w(s, a) \Big|_{a = \mu_\theta(s)} ∇θJ≈N1∑∇θμθ(s)∇aQw(s,a) a=μθ(s)
直观理解:
- Actor 通过 Critic 提供的 Q 值信息,更新策略,使未来的 Q 值更大!
-
使用梯度上升法更新 Actor 网络参数 θ \theta θ
θ ← θ + β ∇ θ J \theta \leftarrow \theta + \beta \nabla_\theta J θ←θ+β∇θJ
(5)软更新目标网络
- 目标网络参数缓慢更新:
w ′ ← τ w + ( 1 − τ ) w ′ w' \leftarrow \tau w + (1 - \tau) w' w′←τw+(1−τ)w′
θ ′ ← τ θ + ( 1 − τ ) θ ′ \theta' \leftarrow \tau \theta + (1 - \tau) \theta' θ′←τθ+(1−τ)θ′
其中 τ \tau τ 是目标网络的更新率,确保目标网络缓慢变化,稳定训练。
- 目的是提高训练稳定性,避免剧烈参数波动。
重复步骤(2),直到收敛
- 训练过程中,Agent 逐步学习到更好的策略,使得累积奖励最大化。
- 目标网络稳定策略更新,经验回放减少样本相关性,使训练更加稳定。
通俗易懂的解释
DDPG 就像一个聪明的机器人司机,它使用两个大脑来学习如何驾驶:
- Actor(决策者) 负责选择驾驶策略(比如油门、刹车)。
- Critic(评价者) 负责判断决策的好坏(当前决策会不会带来更高的未来奖励)。
学习过程如下:
- Actor 试着开车(选择动作) ,但最开始并不熟练,所以会加入一点随机性来探索不同的驾驶方式。
- Critic 观察驾驶情况并评分,告诉 Actor 哪种驾驶方式更好。
- Actor 听取 Critic 的建议,并调整驾驶方式,使未来的评分更高。
- 经验回放池 像是驾驶记录本,记录下之前的驾驶情况,帮助 Critic 记住哪些驾驶方式更安全有效。
- 目标网络 像是一个稳定的老司机,确保 Critic 不会突然改变评分标准,使 Actor 训练更加稳定。
DDPG vs 其他 RL 算法
| 算法 | 是否支持连续动作 | 是否使用 Actor-Critic | 是否使用经验回放 | 是否有目标网络 |
|---|---|---|---|---|
| DQN | ❌ 只能离散 | ❌ 不是 Actor-Critic | ✅ 使用经验回放 | ✅ 有目标网络 |
| A3C | ✅ 支持连续 | ✅ 是 Actor-Critic | ❌ 不使用经验回放 | ❌ 无目标网络 |
| PPO | ✅ 支持连续 | ✅ 是 Actor-Critic | ❌ 不使用经验回放 | ❌ 无目标网络 |
| DDPG | ✅ 支持连续 | ✅ 是 Actor-Critic | ✅ 使用经验回放 | ✅ 有目标网络 |
🔹 DDPG 适用于高维、连续控制任务(如机器人控制) ,但训练不稳定,容易陷入局部最优。
PPO(Proximal Policy Optimization) 近端策略优化
- PPO(近端策略优化)是强化学习(RL)中最流行的策略梯度方法之一,由 OpenAI 在 2017 年提出。
- 它在稳定性、训练效率和收敛速度方面优于 TRPO(Trust Region Policy Optimization),被广泛应用于机器人控制、游戏 AI、自动驾驶等任务。
-
特点 解释 裁剪目标函数 限制策略变化幅度,防止训练崩溃 优势估计** A t A_t At** 让学习更加稳定 Actor-Critic 结构 结合策略梯度 + 价值估计,提高学习效率 无二阶优化 计算简单,适用于大规模任务
核心思想
PPO 属于 Actor-Critic 方法,核心目标是提高智能体选择好动作的概率,同时避免策略参数更新过大,保证训练的稳定性。
通俗理解:
就像教小孩学骑自行车,不能一下子让他从不会直接骑到飞快,否则容易摔倒。PPO 通过“小步改进”来保证 AI 稳定学习。
📌 主要特性
-
基于策略梯度:直接优化策略,适用于连续和离散动作空间。
-
克服 TRPO 复杂性:相比 TRPO 的二阶优化,PPO 采用简单的一阶优化,计算成本低。
-
采用 Clipped Objective:
- 控制策略更新幅度,避免策略剧烈变化,保证训练稳定。
PPO 算法流程
输入:环境状态 s t s_t st
输出:最优动作 a t a_t at
📝 主要步骤
-
初始化 Actor-Critic 网络
- Actor 网络 π θ ( s ) \pi_\theta(s) πθ(s) :用于决策,负责输出动作的概率分布 π θ ( a ∣ s ) \pi_\theta(a | s) πθ(a∣s)
- Critic 网络 V ϕ ( s ) V_\phi(s) Vϕ(s) :用于评估状态的好坏,负责评估状态的价值 V ϕ ( s ) V_\phi(s) Vϕ(s)
- 初始化策略参数 θ \theta θ 和值函数参数 ϕ \phi ϕ。
-
与环境交互,收集经验
-
在环境中运行策略 π θ \pi_\theta πθ,收集数据:
-
在时间步 t t t,Actor 根据当前策略选择动作:
a t ∼ π θ ( a t ∣ s t ) a_t \sim \pi_{\theta}(a_t | s_t) at∼πθ(at∣st)
-
执行动作 a t a_t at,环境返回奖励 r t r_t rt 和新状态 s t + 1 s_{t+1} st+1
-
记录状态、动作、奖励、下一状态: ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1)
-
持续收集多个时间步的数据,直到一个完整的时间片(batch)或一个回合结束。
-
-
-
计算优势函数(Advantage Estimation)
-
计算状态价值:
V ϕ ( s t ) V_{\phi}(s_t) Vϕ(st)
-
计算TD 目标(目标值函数) :
R t = r t + γ V ϕ ( s t + 1 ) R_t = r_t + \gamma V_{\phi}(s_{t+1}) Rt=rt+γVϕ(st+1)
-
计算优势函数 A t A_t At:
-
A t = R t − V ϕ ( s t ) A_t = R_t - V_{\phi}(s_t) At=Rt−Vϕ(st)
- 计算 PPO 目标函数
-
计算旧策略的动作概率:
π θ old ( a t ∣ s t ) \pi_{\theta_{\text{old}}}(a_t | s_t) πθold(at∣st)
-
计算新旧策略概率比值:
r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_t(\theta) = \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{old}}(a_t | s_t)} rt(θ)=πθold(at∣st)πθ(at∣st)
- 如果 r t ( θ ) > 1 r_t(\theta) > 1 rt(θ)>1,说明新策略更倾向于选择该动作,更新过大可能导致策略崩溃。
- 如果 r t ( θ ) < 1 r_t(\theta) < 1 rt(θ)<1,说明新策略不太愿意选择该动作,可能过度惩罚了好策略。
-
计算裁剪(Clipped) 策略更新目标:
L clip ( θ ) = min [ r t ( θ ) A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ] L^{\text{clip}}(\theta) = \min \left[ r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t \right] Lclip(θ)=min[rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At]
- 这里 ϵ \epsilon ϵ 是一个小数(一般设为 0.2),用于限制策略的变化幅度。
- 如果比值 r t ( θ ) r_t(\theta) rt(θ) 变化太大,就进行裁剪,防止训练不稳定。
-
控制策略变化范围, ϵ \epsilon ϵ 通常设为 0.2
-
如果更新太大,则裁剪,防止训练不稳定
- 更新 Actor(策略网络)
-
计算梯度:
∇ θ L clip ( θ ) \nabla_{\theta} L^{\text{clip}}(\theta) ∇θLclip(θ)
-
使用梯度上升(最大化 L clip L^{\text{clip}} Lclip)优化策略网络:
θ ← θ + β ∇ θ L clip ( θ ) \theta \leftarrow \theta + \beta \nabla_{\theta} L^{\text{clip}}(\theta) θ←θ+β∇θLclip(θ)
- 更新 Critic(值函数网络)
-
使用 MSE 损失更新 Critic 网络:
L ( V ) = ( V ϕ ( s t ) − R t ) 2 L(V) = (V_{\phi}(s_t) - R_t)^2 L(V)=(Vϕ(st)−Rt)2
-
采用梯度下降优化 Critic:
ϕ ← ϕ − α ∇ ϕ L ( V ) \phi \leftarrow \phi - \alpha \nabla_{\phi} L(V) ϕ←ϕ−α∇ϕL(V)
-
重复步骤 2-6,直到收敛
- 让智能体不断学习最优策略,最大化累积奖励。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)