AGI 主要技术路径及核心技术:归一融合及未来之路1

AGI与智慧公路
目录:
一、规模扩展路径
二、神经符号融合路径
三、认知架构路径
四、具身智能路径
五、其他新兴路径
六、AGI技术路径的发展与归一
附件1 元学习与通用算法
附件2 人工生命与进化计算
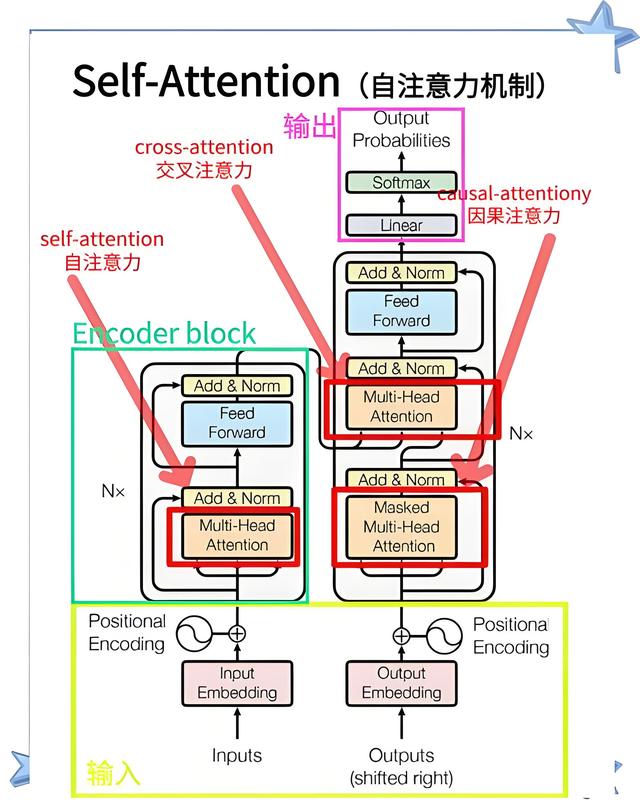
Transformer 架构
一、规模扩展路径
规模扩展路径也被称为“Scaling Law”路径或“大型语言模型”路径,是当前最主流、投入资源最多且取得显著成果的方向。
(一)核心思想
规模扩展路径的根本假设是:“规模即涌现”。即只要持续扩大模型参数数量、训练数据量和计算力,模型的能力就会“涌现”出超出预期的、类似人类的通用智能,包括推理、规划、泛化等复杂能力,最终通向AGI。它认为智能的核心是对世界知识的压缩和预测,而达到这一点主要依赖规模。规模扩展路径有三大支柱和技术路径。
(二)支柱一:Transformer 架构
这是规模扩展的基础架构。相比于RNN、LSTM,Transformer的核心优势在于:
-
可并行性:其自注意力机制允许同时处理序列中的所有位置,极大地利用了GPU/TPU等硬件的大规模并行计算能力。
-
卓越的扩展性:模型深度(层数)和宽度(注意力头数、隐层维度)的增加,能稳定地带来性能提升,没有明显的瓶颈。
-
长程依赖建模:能有效捕捉序列中远距离元素之间的关系,这是理解复杂上下文和逻辑链条的关键。
Transformer是一个“为扩展而生”的架构,它使得将模型做到千亿、万亿参数成为可能,且性能随规模增长可预测地提升。
(三)支柱二:海量数据与无监督/自监督学习
-
数据来源:互联网全域文本(网页、书籍、代码、学术论文等),以及正在快速整合的图像、音频、视频等多模态数据。
-
训练范式:主要采用自监督学习,例如预测下一个词(语言建模)、复原被遮盖的部分等。这种方式无需昂贵的人工标注,可以充分利用近乎无限的网络数据。
-
“大语料”的意义:模型在压缩和预测海量数据的过程中,被动地学习到了世界的语法、事实、逻辑关系甚至价值观念。数据是模型“经验”的来源。
(四)支柱三:算力指数增长与 Scaling Laws
这是指导实践的核心理论。以OpenAI、DeepMind等机构的研究为代表,他们发现模型性能(如预测损失)与三个关键因素(模型参数N、训练数据量D、计算量C)之间存在可预测的幂律关系。
为了最优性能,三个因素需要平衡增长(如Chinchilla定律指出,在给定算力下,应同时增加参数量和数据量,而非只增加参数量)。
随着规模扩大,模型会展现出在较小规模时没有的新能力(如代码生成、多步推理、指令理解),这种现象被称为“能力涌现”。
Scaling Laws 使得研究机构和企业能够像“摩尔定律”指导芯片发展一样,进行前瞻性的规划和投资,预测需要多少算力和数据才能达到某个性能水平。
(五)发展历程与里程碑
萌芽(2017-2018):Transformer论文发表,GPT-1、BERT出现,证明了架构的有效性。
验证(2019-2020):GPT-2/3 的出现,首次显著展示了“规模”带来的质变(上下文学习、少样本学习)。Scaling Laws 被明确提出。
爆发(2021-至今):①能力涌现:GPT-3.5/4、PaLM、Claude等模型展现出惊人的推理、创意和专业能力;②对齐技术:基于人类反馈的强化学习技术,使模型能遵循人类指令、符合价值观,从“预测机”变为“助手”; ③ 多模态融合:GPT-4V、Gemini等模型开始整合视觉、听觉,走向更全面的世界理解。
(六)当前前沿:
研究重点从“纯缩放”转向如何在扩展中更高效地获取高级能力,如:
-
合成数据:用大模型自己生成高质量训练数据,突破自然数据瓶颈。
-
系统优化:混合专家模型、更高效的架构(如状态空间模型)来降低计算成本。
-
强化学习与规划:在模拟环境中让AI通过试错学习复杂技能,结合大模型的世界知识。
(七)争议与挑战
-
本质是“随机鹦鹉”吗? 批评者认为,大模型只是基于统计模式进行模仿和重组,缺乏真正的理解、意识和因果推理。它可能是在“背诵”而非“思考”。
-
Scaling Laws 会无限持续吗? 目前性能提升已出现放缓迹象,数据质量、能源消耗、硬件极限可能使指数增长难以为继。
-
对齐与安全难题:模型越强大,确保其目标与人类对齐、避免滥用和意外风险就越困难。规模本身不解决价值对齐问题。
-
资源壁垒与生态垄断:训练千亿级模型需要数十亿美元的计算资源和顶尖团队,可能导致AGI技术被少数巨头垄断。
-
缺失关键组件:批评者指出,通往AGI可能需要内置的目标驱动、世界模型、情感体验等组件,而纯数据驱动的规模路径可能天然缺失这些。
(七)与其他AGI路径的关系
-
与混合架构路径:规模路径的产物(大模型)常作为核心组件,与符号系统、知识图谱、搜索规划等模块结合,形成更强大的系统(如AlphaGeometry)。
-
与脑启发/具身路径:目前相对独立。但规模路径正积极吸纳多模态和强化学习,向具身智能(机器人)发展;而神经科学也可能为新一代架构提供灵感。
-
与全认知架构路径:理念冲突最大。规模路径是“自底向上”的涌现,而认知架构是“自顶向下”的设计。
(八)结论与展望
规模扩展路径是目前最务实、进展最快的AGI实现路径。它通过工程化的方式,已经创造出了最接近人类智能的机器。其核心逻辑——“大力出奇迹”——在可预见的未来仍将是AI发展的主旋律。然而,它并非万能钥匙。
未来的AGI更可能诞生于“规模扩展”与“新架构/新范式”的结合:继续沿规模路径推进,追求数据、算力和参数量的极限;在扩展过程中,探索能更高效地获取推理、规划和世界理解能力的新方法(如更好的强化学习、模拟环境);将大模型作为基础引擎,与符号逻辑、专业工具、物理 embodiment 结合,补足其短板。
最终,规模是必要条件,但可能不是充分条件。通往AGI的最后一公里,可能需要来自认知科学、神经科学或数学的根本性突破,与现有规模路径融合,方能实现真正的通用智能。
神经符号融合示意
二、神经符号融合路径
神经符号融合路径是对当前主流“规模扩展路径”的一种深刻反思和重要补充,旨在结合神经网络与符号智能的优势,构建兼具学习能力与推理能力的系统。
(一)核心理念与哲学
-
神经符号融合的核心思想是:“神经”负责感知、模式识别和模糊学习,“符号”负责推理、逻辑和知识表示。 它认为,真正的通用智能必须同时具备这两种能力,并将它们无缝整合。
-
神经部分(连接主义): 模仿人脑的神经元网络,擅长从高维、非结构化数据(如图像、文本、语音)中进行统计学习、泛化和直觉判断。特点是可塑性强、容错性好,但过程像“黑箱”,缺乏可解释性。
-
符号部分(符号主义): 模仿人类逻辑思维,基于明确的规则、逻辑(如一阶逻辑)和知识图谱进行演绎推理、规划和因果分析。特点是精确、透明、可解释,但僵化、难以从原始数据中自动获取知识。
神经符号融合的根本目标: 构建一个系统,能像人一样,用“神经系统”从世界中感知和学习,用“符号系统”对所学进行抽象、推理和解释,并让两者循环互动、持续进化。
(二)为什么需要融合?——对纯神经路径局限性的回应
纯神经网络(如大型语言模型)的缺陷,正是神经符号路径试图解决的:
-
可解释性与可信性差: “黑箱”决策过程,在医疗、法律、科学等关键领域难以被信任。
-
推理与逻辑能力薄弱: 擅长关联和模仿,但在需要严格演绎、数学证明、长链条因果推理的任务上容易出错。
-
数据效率低下: 需要海量数据才能学习一个概念,而人类往往通过少量例子和符号化描述就能掌握。
-
知识难以更新与纠正: 修改一个事实需要重新训练,而符号知识库可以轻易地增、删、改一条规则。
-
缺乏组合性泛化: 难以将已学概念组合成新的、未见过的复杂概念(如理解“用手机拍下骑着独角兽的宇航员”)。
(未完待续)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 38
38 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)