4.02-Rtlfixer: Automatically fixing rtl syntax errors with large language model-利用大语言模型自动修复 RTL 语法错误
② Rtlfixer: Automatically fixing rtl syntax errors with large language model

可译为:
《RtlFixer:利用大语言模型自动修复 RTL 语法错误》
更详细的翻译:
《RtlFixer:一种基于大语言模型的 RTL 语法错误自动修复方法》
词语拆解:
- Automatically fixing
自动修复 - rtl syntax errors
RTL 语法错误
RTL 是 Register Transfer Level,即寄存器传输级,常用于 Verilog / SystemVerilog 等硬件描述代码。 - with large language model使用大语言模型
整体理解:
这篇更聚焦于一个比较具体的问题:
用大语言模型自动修复 RTL 代码里的语法错误。
这里强调的是“syntax errors”,也就是编译不过、语法不合法这类问题,不一定涉及更深层的逻辑错误。
一、先用一句话讲清这篇论文
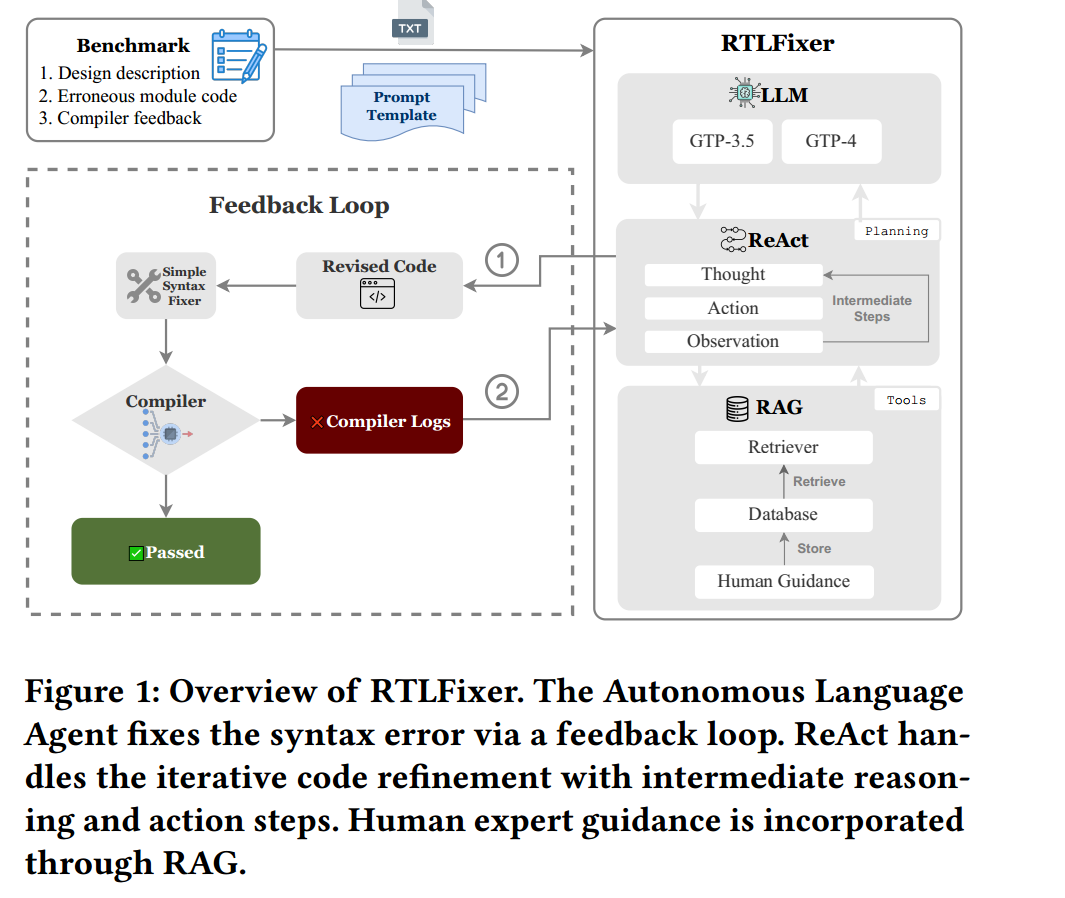
这篇论文提出了一个叫 RTLFixer 的框架,它把 LLM + ReAct + RAG + 编译器反馈 结合起来,让大语言模型像“自动调试代理”一样,反复修改 Verilog 代码里的语法错误,直到编译通过。论文声称它在他们构造的数据集上能修复 98.5% 的编译错误。
二、这篇论文的研究背景是什么
论文的出发点很明确:
虽然大语言模型已经能根据自然语言生成 Verilog 代码,但它生成的代码经常有错。作者分析发现,在 LLM 生成的 Verilog 错误里,约 55% 是语法错误,而且这个比例甚至高于逻辑/仿真错误。也就是说,很多代码连编译都过不了。
这件事为什么重要?
因为如果代码连编译都过不了,就根本谈不上后续的功能验证。
所以作者的观点是:
- 先把语法错误修掉
- 至少让代码能编译
- 再去谈功能正确性
这其实是一个很合理的工程思路。
三、论文核心问题是什么
它要解决的不是“RTL 代码生成全部问题”,而是一个更聚焦的问题:
如何自动修复 LLM 生成的 Verilog 代码中的语法错误?
这里你要注意,作者刻意把问题范围收窄到了 syntax errors,而不是所有错误。
这是因为:
- 语法错误更基础
- 编译器能给出反馈
- 更适合做“反馈驱动”的自动修复
- 逻辑错误要难得多,论文后面也承认这一点
四、它的方法到底是什么
论文的方法其实可以拆成三个部件:
1. 编译器反馈循环
先把错误的 Verilog 代码送给编译器。
如果编译失败,就拿到错误日志,再让 LLM 根据错误信息改代码,再次编译。
这样形成一个闭环调试过程。
2. ReAct
ReAct 的意思是让 LLM 不只是“直接给答案”,而是像 agent 一样分步骤:
- Thought:先思考当前错误是什么
- Action:决定下一步做什么
- Observation:观察工具返回结果,比如编译器日志或检索结果
然后继续下一轮。
你可以把它理解成:
不是一拍脑袋改代码,而是“思考—行动—看反馈—再思考”地迭代修复。
3. RAG
RAG 在这篇论文里不是去查通用知识库,而是查一个人工整理的语法错误指导库。
这个库里存的是:
- 某类编译错误日志
- 对应的人类专家解释
- 可能的修复建议
当 LLM 遇到错误时,可以根据错误日志去检索类似案例,拿到“人类经验提示”再修代码。
五、RTLFixer 的流程怎么理解
你可以把它理解成下面这个流程:
输入:
- 设计描述
- 一段错误的 Verilog 实现
- 编译器报错日志
系统做的事:
- LLM 读题和错误代码
- 用编译器报错作为反馈
- 用 RAG 检索相似错误的人类指导
- 用 ReAct 分步骤思考和修改
- 再编译
- 直到通过或者达到最大迭代次数
这就是论文图 1 的核心思想。
六、这篇论文最重要的创新点是什么
老师一般会问“贡献是什么”,这里可以总结成 3 点:
贡献 1:聚焦 RTL 语法错误修复
过去很多工作关注代码生成整体准确率,但这篇论文专门把 Verilog 语法修复 当作一个独立问题来做。
贡献 2:把 ReAct 和 RAG 结合到 RTL 调试里
作者不是单纯让 LLM“改一下代码”,而是让它:
- 迭代推理
- 调用编译器
- 检索人类专家指导
这使 LLM 更像自动调试代理。
贡献 3:构建了语法调试数据集
他们基于 VerilogEval 构建了一个叫 VerilogEval-syntax 的数据集,最终包含 212 个有语法错误的实现。
七、实验部分怎么读
实验部分是整篇论文最值得仔细看的地方。
1. 他们用了什么模型和设置
主要实验使用的是 GPT-3.5-turbo-16k-0613。
ReAct 最多允许 10 次 Thought-Action-Observation 迭代。
每组实验做 10 次重复,取平均值。
2. 评价指标是什么
有两个核心指标:
(1) fix rate
表示语法错误被修好的比例,也就是最终编译通过的比例。
(2) pass@k
表示修完以后,代码在功能测试中通过的概率。
这说明作者不只关心“能编译”,也看“功能上有没有更正确”。
八、最关键的实验结果是什么
结果 1:ReAct 很有效
和 One-shot 相比,ReAct 明显提升语法修复成功率。
比如在没有 RAG 时,ReAct 在不同反馈条件下都明显优于 One-shot。
这说明:
迭代式推理 + 反复利用反馈,确实比“一次性改代码”更强。
结果 2:RAG 也很有效
加入人类专家指导后,修复率进一步提升。
尤其在 Quartus 反馈下:
- One-shot:从 58.7% 提高到 89.9%
- ReAct:从 79.9% 提高到 98.5%
这个结果非常亮眼。
它说明:
单靠模型参数记忆不够,加入“外部专家经验”后,模型更会修错。
结果 3:编译器反馈质量很重要
作者比较了三种反馈来源:
- Simple:只说“去修语法错误”
- iverilog:开源编译器日志
- Quartus:商业工具日志,更清楚更具体
结果表明:反馈越清晰,修复效果越好。
这个结论很有启发性,因为它说明这类系统的上限不只取决于 LLM,也取决于工具反馈质量。
结果 4:修复语法错误后,功能正确率也提高
在 VerilogEval 上,修完语法错误以后:
- Machine benchmark 的 pass@1 提高 32.3%
- Human benchmark 的 pass@1 提高 10.1%
这点很关键,因为它说明:
语法修复不是“只让代码能编译”的表面工作,它还能显著提升最终功能正确率。
九、论文有没有局限
有,而且作者自己也承认。
1. 主要只解决语法错误
这篇论文最强的结果都集中在 syntax fixing。
对于 simulation/logic errors,效果就没那么理想。作者说,LLM 对仿真反馈的理解能力还比较有限,尤其遇到复杂设计和高级推理任务时,改不好。
2. 有些失败案例需要算术/索引推理
论文举了一个例子:数组索引越界问题里,LLM 需要正确计算复杂索引,但它做不到,所以修复失败。
这说明模型在符号推理、边界计算、硬件语义理解上仍然有限。
3. RAG 库规模不大
他们的错误指导库其实不算大:
- iverilog:7类常见错误,30条
- Quartus:11类常见错误,45条
所以这更像一个“证明思路有效”的工作,而不是已经覆盖工业级全场景的系统。
十、怎么评价这篇论文
如果从学术和工程角度综合看,我会这样评价:
优点
- 问题定义清楚,聚焦明确
- 方法设计合理,工程闭环完整
- ReAct + RAG + compiler feedback 的结合很自然
- 实验结果强,特别是 98.5% 修复率很有说服力
- 对硬件设计自动化、LLM for EDA 有实际意义
不足
- 主要停留在语法错误层面
- 逻辑错误调试能力不足
- 依赖编译器反馈质量
- 数据集和错误库规模仍有限
- 主要实验模型是 GPT-3.5,泛化到其他模型和更复杂工业 RTL 场景还有待验证
十一、如果老师让你做汇报,可以怎么讲
你可以按这个结构讲:
第一部分:研究问题
LLM 能生成 Verilog,但很多代码有语法错误,导致无法编译。作者发现这类错误占比很高,因此提出自动语法修复框架 RTLFixer。
第二部分:方法
RTLFixer 结合三部分:
- 编译器反馈闭环
- ReAct 做多轮推理和行动规划
- RAG 检索人类专家语法修复经验
第三部分:结果
它在 VerilogEval-syntax 上修复率达到 98.5%(自建数据集),并显著提高 VerilogEval 上的 pass@1。
第四部分:意义与局限
意义在于把 LLM 从“代码生成器”推进成“自动调试代理”;
局限在于主要解决语法错误,复杂逻辑错误仍然困难。
十二、你可以直接记住的“答辩级”总结
这篇论文的核心思想是:
将 LLM 作为一个可迭代的 RTL 调试代理,利用编译器反馈进行闭环修复,并通过 RAG 注入人类专家经验,从而高效解决 Verilog 代码中的语法错误。
它最重要的结论是:
对 RTL 代码而言,语法错误是 LLM 生成失败的重要瓶颈;只要把语法修复做好,就能显著提升最终可用性和功能通过率。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)