基于用户行为日志的淘宝流量转化与精细化运营分析
一、数据清洗与特征工程
1、数据集介绍
本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 列名称 | 说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括('pv', 'buy', 'cart', 'fav') |
| 时间戳 | 行为发生的时间戳 |
注意到,用户行为类型共有四种,它们分别是
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
关于数据集大小的一些说明如下
| 维度 | 数量 |
|---|---|
| 用户数量 | 987,994 |
| 商品数量 | 4,162,024 |
| 用户数量 | 987,994 |
| 商品类目数量 | 9,439 |
| 所有行为数量 | 100,150,807 |
2、读取数据
import pandas as pd
import numpy as np
# 如果文件很大,建议加上 nrows 参数先读一部分测试,或者使用 chunksize
data = pd.read_csv(r"D:\Kaggle\淘宝用户购物行为数据集\UserBehavior.csv")2、列名处理
原数据集没有列名,根据数据集描述构建列名。
data.columns = ['用户ID','商品ID','商品类目ID','行为类型','时间戳']3、缺失值处理
查看与处理缺失值,日志数据空值直接删除。这里无缺失值。
4、特征工程
时间戳转换,并构建时间相关特征,如日期、星期、小时。数据类型转换以节约内存。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 设置绘图风格
sns.set(style="whitegrid")
# 解决Matplotlib中文显示问题 (SimHei为黑体,Windows通常自带)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1.数据清洗
# 1.1检查缺失值
print("缺失值检查:")
print(data.isnull().sum())
# 如果有缺失,直接删除
data.dropna(inplace=True)
# 1.2时间戳转换
# 将时间戳转换为datetime对象,淘宝数据是秒级时间戳
data['时间'] = pd.to_datetime(data['时间戳'], unit='s')
# 1.3特征提取,构建人货场所需的时间维度
# 提取日期 (用于同期群、留存分析)
data['日期'] = data['时间'].dt.date
# 提取小时 (用于分析场-用户活跃时间段)
data['小时'] = data['时间'].dt.hour
# 提取星期 (用于分析工作日 vs 周末)
# dt.dayofweek: 0=周一, 6=周日
data['星期'] = data['时间'].dt.dayofweek + 1
# 1.4数据类型转换,节省内存
data['用户ID'] = data['用户ID'].astype('int32')
data['商品ID'] = data['商品ID'].astype('int32')
data['商品类目ID'] = data['商品类目ID'].astype('int32')
print("\n数据前5行预览:")
print(data.head())
print("\n数据基本信息:")
print(data.info())二、流量变现与用户留存:从行为到转化的关键路径分析
1、漏斗模型分析
pv (浏览) -> cart (加购) / fav (收藏) -> buy (购买)
# 2.1 漏斗模型分析
# 统计各行为类型的总次数
behavior_counts = data['行为类型'].value_counts()
print("\n各行为类型统计:")
print(behavior_counts)
# 计算转化率
pv_count = behavior_counts['pv']
cart_count = behavior_counts['cart']
fav_count = behavior_counts['fav']
buy_count = behavior_counts['buy']
# 这里的转化率是相对于“浏览(pv)”的转化
cart_conversion = cart_count / pv_count
fav_conversion = fav_count / pv_count
buy_conversion = buy_count / pv_count
# 购买相对于“加购/收藏”的转化率,购买意向转化率
buy_from_cart = buy_count / cart_count
buy_from_fav = buy_count / fav_count
print(f"\n--- 漏斗转化数据 ---")
print(f"浏览(pv) -> 加购(cart) 转化率: {cart_conversion:.4%}")
print(f"浏览(pv) -> 收藏(fav) 转化率: {fav_conversion:.4%}")
print(f"浏览(pv) -> 购买(buy) 转化率: {buy_conversion:.4%}")
print(f"加购 -> 购买 转化率: {buy_from_cart:.4%}")
print(f"收藏 -> 购买 转化率: {buy_from_fav:.4%}")
# 可视化漏斗
plt.figure(figsize=(10, 6))
sns.barplot(x=behavior_counts.index, y=behavior_counts.values, palette='Blues_d')
plt.title('用户行为漏斗分布 (总次数)')
plt.xlabel('行为类型')
plt.ylabel('次数')
plt.show()输出结果
各行为类型统计:
行为类型
pv 89716263
cart 5530446
fav 2888258
buy 2015839
Name: count, dtype: int64
--- 漏斗转化数据 ---
浏览(pv) -> 加购(cart) 转化率: 6.1644%
浏览(pv) -> 收藏(fav) 转化率: 3.2193%
浏览(pv) -> 购买(buy) 转化率: 2.2469%
加购 -> 购买 转化率: 36.4498%
收藏 -> 购买 转化率: 69.7943%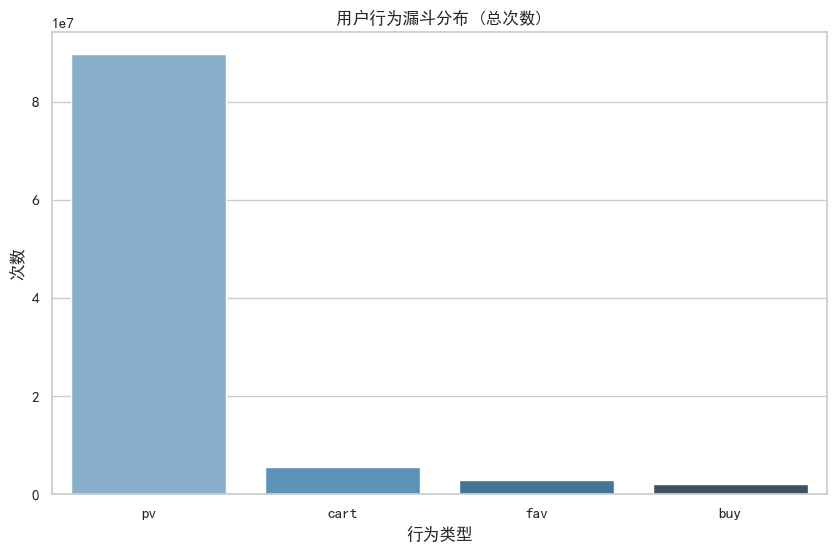
“收藏->购买”的转化率(69%)几乎是“加购->购买”(36%)的两倍,原因可能在于:
①用户意图不同:加购通常代表我有购买意向但我还在比价,或者我先放这里等大促再买。加购往往带有囤积和犹豫的性质。收藏通常代表我非常喜欢这个商品/店铺,我想关注它的动态。收藏更多是对特定商品或店铺的强意向关注。在本数据集中,收藏往往意味着用户已经把该商品作为首选,只等付款时机。
②促销机制:淘宝的某些收藏有礼、降价提醒功能,会直接刺激收藏用户下单。
③数据噪声:有时候用户会批量加购一堆商品,然后慢慢删减,导致加购基数虚高。
2、人货场分析
人:用户活跃度(人均行为次数)、全站购买转化率。
货:商品类目热度、类目转化率。
场:24小时流量趋势。
# 2.2 人货场分析
# 人:用户活跃度分析
user_behavior = data.groupby('用户ID')['行为类型'].count().reset_index()
user_behavior.columns = ['用户ID', 'count']
plt.figure(figsize=(12, 5))
# 绘制用户活跃度分布
plt.subplot(1, 2, 1)
sns.histplot(user_behavior['count'], bins=50, kde=True, color='skyblue')
plt.title('用户活跃度分布 (人均行为次数)')
plt.xlabel('行为次数')
plt.ylabel('用户数')
# 人:全站购买转化率
total_users = data['用户ID'].nunique()
total_buyers = data[data['行为类型'] == 'buy']['用户ID'].nunique()
purchase_rate = total_buyers / total_users
print(f"\n*******人货场:人*******")
print(f"总用户数: {total_users}")
print(f"有购买行为的用户数: {total_buyers}")
print(f"全站购买转化率 (购买用户/总用户): {purchase_rate:.2%}")
# 货:商品类目分析
# 统计购买量 Top 10 的类目
category_buy = data[data['行为类型'] == 'buy']['商品类目ID'].value_counts().head(10)
plt.subplot(1, 2, 2)
category_buy.plot(kind='barh', color='salmon')
plt.title('购买量 Top 10 商品类目')
plt.xlabel('购买次数')
plt.ylabel('类目ID')
plt.tight_layout()
plt.show()
# 计算各类目的转化率 (购买/浏览)
cat_pivot = data.groupby(['商品类目ID', '行为类型']).size().unstack(fill_value=0)
cat_pivot['conversion_rate'] = cat_pivot['buy'] / cat_pivot['pv']
# 筛选出浏览量大于1000的类目,过滤掉长尾噪音,按转化率排序
top_cat_conversion = cat_pivot[cat_pivot['pv'] > 1000].sort_values('conversion_rate', ascending=False).head(10)
print("\n*******人货场:货(转化率 Top 10 类目)*******")
print(top_cat_conversion[['pv', 'buy', 'conversion_rate']])
# 场:时间维度分析
hourly_behavior = data.groupby(['小时', '行为类型']).size().unstack(fill_value=0)
# 绘制 24小时流量图
plt.figure(figsize=(12, 6))
plt.plot(hourly_behavior.index, hourly_behavior['pv'], label='浏览 (PV)', marker='o')
plt.plot(hourly_behavior.index, hourly_behavior['buy'], label='购买 (Buy)', marker='x', color='red')
plt.title('24小时用户行为趋势 (场)')
plt.xlabel('小时 (0-23点)')
plt.ylabel('行为次数')
plt.legend()
plt.grid(True)
plt.show()
# 分析哪个小时转化率最高
hourly_behavior['buy_rate'] = hourly_behavior['buy'] / hourly_behavior['pv']
best_hour = hourly_behavior['buy_rate'].idxmax()
print(f"\n*******人货场:场************")
print(f"流量高峰期通常在: {hourly_behavior['pv'].idxmax()} 点")
print(f"转化率最高的时间段在: {best_hour} 点")输出
*******人货场:人*******
总用户数: 987994
有购买行为的用户数: 672404
全站购买转化率 (购买用户/总用户): 68.06%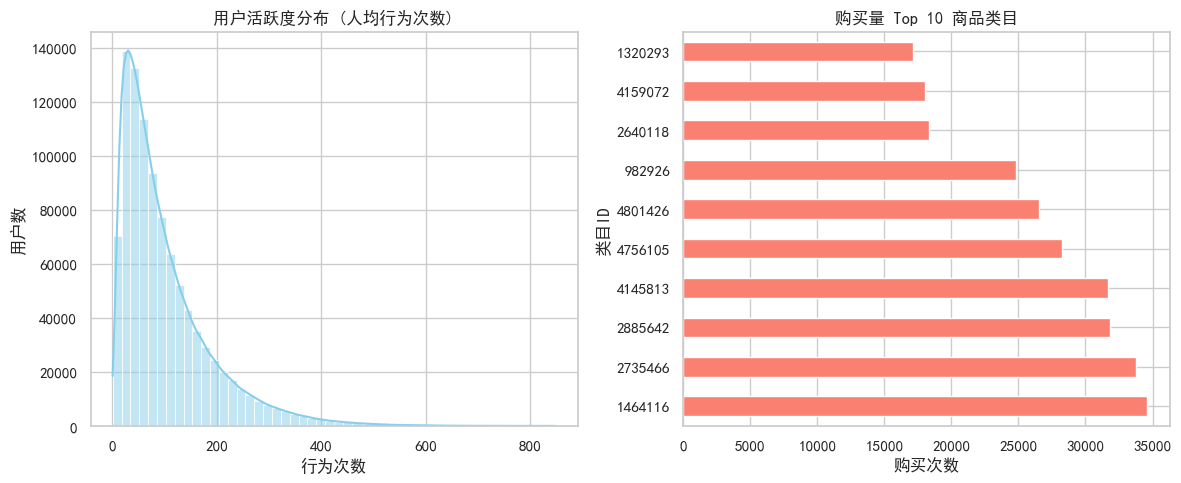
*******人货场:货(转化率 Top 10 类目)*******
行为类型 pv buy conversion_rate
商品类目ID
1030192 1202 1183 0.984193
1421972 2111 1345 0.637139
194104 1805 1021 0.565651
804084 4907 1787 0.364174
1958275 1213 346 0.285243
817164 1596 357 0.223684
3628508 1069 234 0.218896
63690 4005 817 0.203995
1461887 1654 327 0.197703
2025483 3757 690 0.183657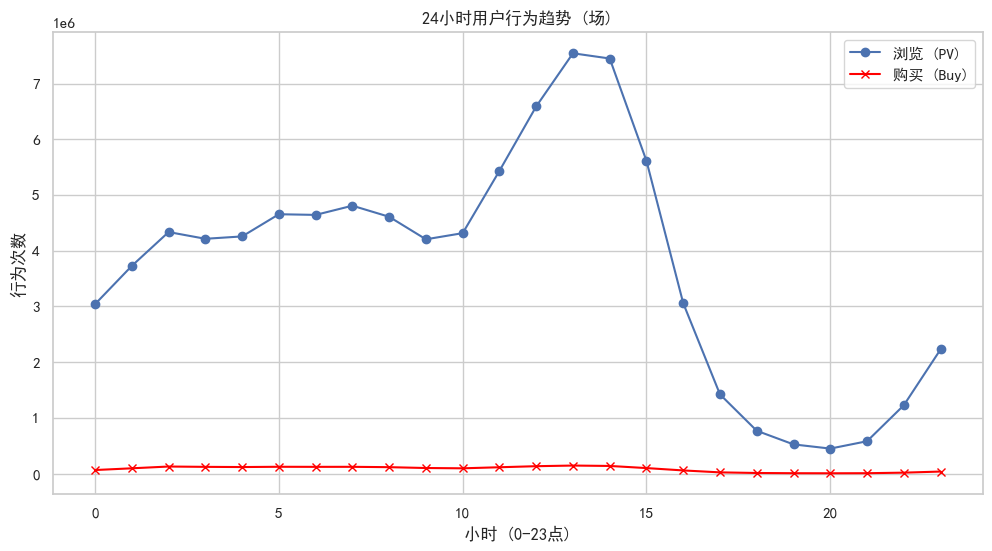
*******人货场:场************
流量高峰期通常在: 13 点
转化率最高的时间段在: 2 点分析:
人:全站购买转化率(购买用户/总用户)高达 68.06%,这个数据集可能是一个高活跃用户子集,或者说明网站用户粘度极高。既然大部分人都会买,那么运营的重点就不应该是“劝他们买”,而应该是“交叉销售”。既然用户已经信任平台并购买了,应该更多考虑如何让他们买得更多,提升客单价。
货:Top 1 类目PV 只有 1202,转化率高达 98.4%,Top 2 类目PV 2111,转化率 63.7%。可能是数据陷阱,98% 的转化率不一定是爆款,样本量太小,通常意味着这是一个冷门刚需品类,用户只有极度需要它时才会搜,搜到了就买,所以转化率极高。真正的爆款应该是“高流量 + 高转化”。比如在这个表里,转化率超过 20% 且 PV 超过 4000 的类目804084 和 63690才更值得投入广告资源,因为它们能带来实实在在的 GMV 规模。在后续分析中,可以将商品分为四类(波士顿矩阵)。
明星商品:高流量、高转化(重点推)。
金牛商品:低流量、高转化(如 Top 1,不用推,维持现状即可)。
问题商品:高流量、低转化(浪费流量,需要优化详情页)。
瘦狗商品:低流量、低转化(下架)。
场:流量与转化的时差揭示了用户作息,流量高峰下午13 点,转化高峰凌晨2点。13:00 可能代表午休经济,下午1点是午休时间,用户有大量碎片时间刷淘宝,所以流量大。但此时可能在上班/上学环境,不方便支付或比较匆忙,所以只是逛逛。02:00 可能代表失眠经济,凌晨2点流量虽然低,但转化率极高。这说明深夜是用户意志力最薄弱、购买决策最果断的时候。或者是用户在白天加购后,晚上躺在床上仔细思考后完成了支付。因此,13:00时间段重点推送种草类内容、短视频、直播。20:00 - 22:00通常是黄金转化期,可以重点推送限时折扣、倒计时等逼单。对深夜用户可以在晚上10点后对白天加购未支付的用户发送催付通知,正好赶上他们深夜下单的节奏。
3、波士顿矩阵商品分类
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 设置绘图风格
sns.set(style="whitegrid")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1.商品波士顿矩阵分类
# 1.1 计算每个商品类目的 PV 和 Buy 数量
category_stats = data.groupby(['商品类目ID', '行为类型']).size().unstack(fill_value=0)
# 确保所有行为类型都存在,如果某些类目没有某些行为,填充0
for behavior in ['pv', 'buy', 'cart', 'fav']:
if behavior not in category_stats.columns:
category_stats[behavior] = 0
# 1.2 计算转化率
category_stats['conversion_rate'] = category_stats['buy'] / category_stats['pv']
# 1.3 定义高低标准(使用中位数作为分界线)
pv_median = category_stats['pv'].median()
cvr_median = category_stats['conversion_rate'].median()
print(f"PV中位数: {pv_median}")
print(f"转化率中位数: {cvr_median}")
# 1.4 分类函数
def classify_product(row):
if row['pv'] >= pv_median and row['conversion_rate'] >= cvr_median:
return '明星商品'
elif row['pv'] < pv_median and row['conversion_rate'] >= cvr_median:
return '金牛商品'
elif row['pv'] >= pv_median and row['conversion_rate'] < cvr_median:
return '问题商品'
else:
return '瘦狗商品'
# 1.5 应用分类
category_stats['category_type'] = category_stats.apply(classify_product, axis=1)
# 1.6 统计各类别数量
category_counts = category_stats['category_type'].value_counts()
print("\n商品分类统计:")
print(category_counts)
# 1.7 可视化波士顿矩阵
plt.figure(figsize=(10, 8))
colors = {'明星商品': 'red', '金牛商品': 'green', '问题商品': 'yellow', '瘦狗商品': 'blue'}
sns.scatterplot(data=category_stats, x='pv', y='conversion_rate', hue='category_type', palette=colors, alpha=0.6)
# 添加中位数线
plt.axvline(pv_median, color='gray', linestyle='--')
plt.axhline(cvr_median, color='gray', linestyle='--')
plt.title('商品波士顿矩阵分析')
plt.xlabel('流量 (PV)')
plt.ylabel('转化率 (CVR)')
plt.legend(title='商品类型')
plt.xscale('log') # 由于PV数量级差异大,使用对数坐标
plt.show()PV中位数: 266.0
转化率中位数: 0.025510204081632654
商品分类统计:
category_type
瘦狗商品 2863
明星商品 2855
问题商品 1866
金牛商品 1855
Name: count, dtype: int64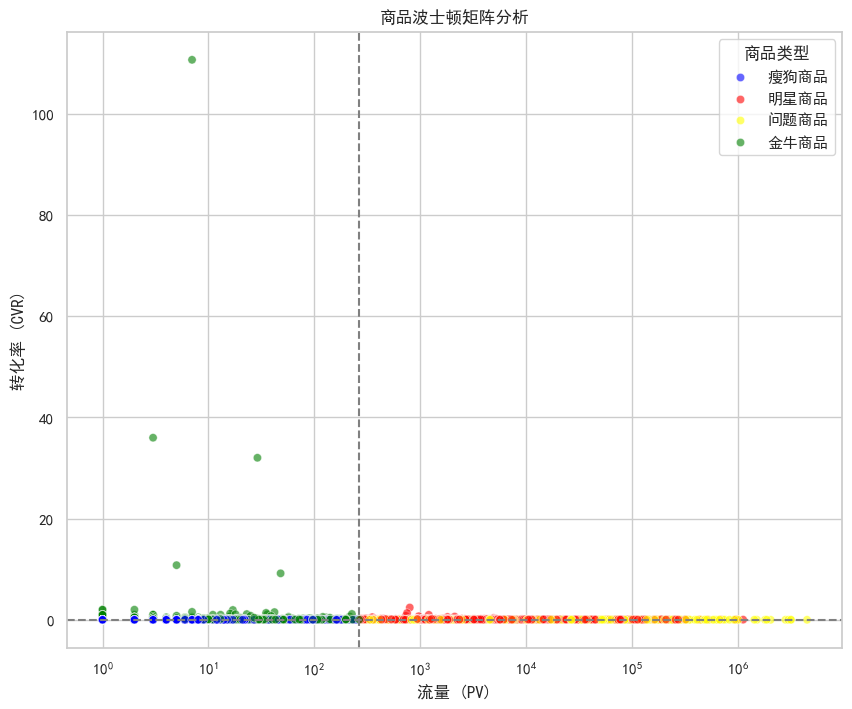
4、留存曲线
留存分析是衡量用户粘性的关键指标,我们将直接计算所有队列的平均留存率。
# 2.留存曲线分析
# 2.1 获取用户首次访问日期
first_visit = data.groupby('用户ID')['日期'].min().reset_index()
first_visit.columns = ['用户ID', '首次访问日期']
# 2.2 合并首次访问日期到原数据
data_with_first = pd.merge(data, first_visit, on='用户ID')
# 2.3 计算用户访问日期与首次访问日期的天数差
# 强制转换为 Pandas 的 datetime 格式,防止因数据类型不同导致的计算错误
date_current = pd.to_datetime(data_with_first['日期'])
date_first = pd.to_datetime(data_with_first['首次访问日期'])
# 计算差值并提取 .dt.days (确保是整数天数)
data_with_first['days_since_first'] = (date_current - date_first).dt.days
# 检查是否有负数或异常值
print(data_with_first['days_since_first'].describe())
# 2.4 计算每日新增用户数 (每个队列的总人数)
cohort_size = first_visit.groupby('首次访问日期')['用户ID'].nunique().reset_index()
cohort_size.columns = ['首次访问日期', '新增用户数']
# 2.5 计算每个队列在每一天的留存用户数
# 注意:这里统计的是去重后的用户数
retention = data_with_first.groupby(['首次访问日期', 'days_since_first'])['用户ID'].nunique().reset_index()
# 2.6 合并队列总人数,以便计算比率
retention = pd.merge(retention, cohort_size, on='首次访问日期')
# 2.7 计算留存率
retention['留存率'] = retention['用户ID'] / retention['新增用户数']
# 2.8 计算平均留存率
# 我们不只看某一天,而是计算所有天数的平均留存表现
avg_retention = retention.groupby('days_since_first')['留存率'].mean().reset_index()
# 2.9 绘制平均留存曲线
plt.figure(figsize=(12, 6))
sns.lineplot(data=avg_retention, x='days_since_first', y='留存率', marker='o')
plt.title('平均用户留存曲线 (所有队列平均值)')
plt.xlabel('距离首次访问的天数')
plt.ylabel('平均留存率')
plt.grid(True)
plt.show()
# 2.10 安全地输出关键指标
print("\n关键留存指标(平均值):")
# 定义一个安全获取值的函数
def get_retention(day):
# 筛选对应天数的数据
val = avg_retention[avg_retention['days_since_first'] == day]['留存率']
if not val.empty:
return f"{val.values[0]:.4%}"
else:
return "数据不足 (无该天数据)"
print(f"次日留存率 (Day 1): {get_retention(1)}")
print(f"7日留存率 (Day 7): {get_retention(7)}")
print(f"30日留存率 (Day 30): {get_retention(30)}")5、用户行为路径分析
# 3.用户行为路径分析
# 3.1 按用户和时间排序
data_sorted = data.sort_values(by=['用户ID', '时间戳'])
# 3.2 为每个用户的行为序列编号
data_sorted['行为序号'] = data_sorted.groupby('用户ID').cumcount()
# 3.3 构建行为路径
# 将每个用户的行为序列连接成字符串
user_paths = data_sorted.groupby('用户ID')['行为类型'].apply(lambda x: ' -> '.join(x)).reset_index()
# 3.4 统计最常见的前10条路径
top_paths = user_paths['行为类型'].value_counts().head(10)
print("\n最常见的用户行为路径:")
print(top_paths)
# 3.5 可视化最常见路径
plt.figure(figsize=(12, 6))
top_paths.plot(kind='bar')
plt.title('最常见的用户行为路径 (Top 10)')
plt.xlabel('行为路径')
plt.ylabel('用户数量')
plt.xticks(rotation=45)
plt.grid(True)
plt.show()
# 3.6 分析特定路径的转化率
# 例如:pv -> cart -> buy
path_pv_cart_buy = user_paths[user_paths['行为类型'].str.contains('pv -> cart -> buy')]
print(f"\n完成 'pv -> cart -> buy' 路径的用户数: {len(path_pv_cart_buy)}")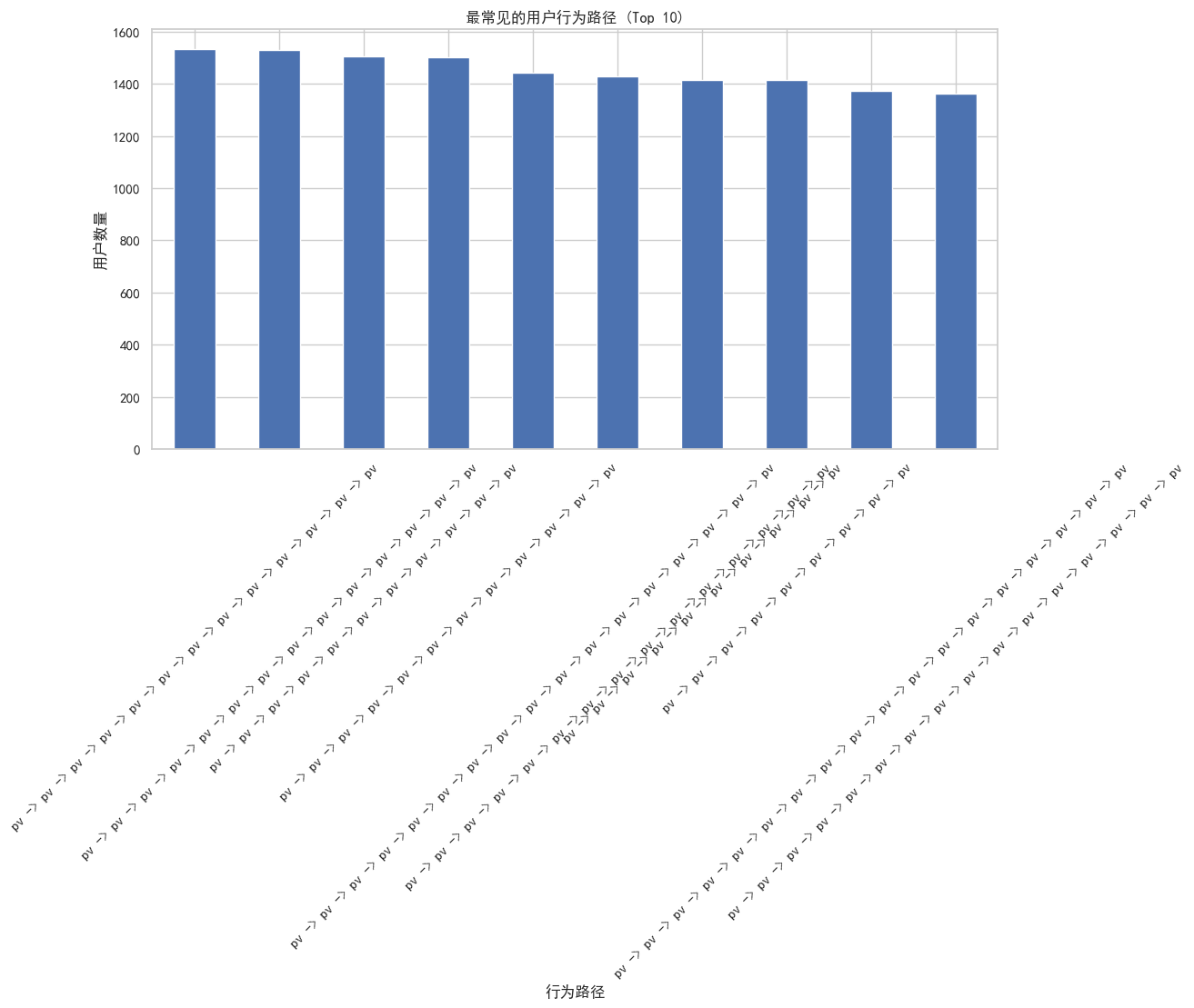
最常见的用户行为路径:
行为类型
pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv 1532
pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv 1528
pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv 1505
pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv 1501
pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv 1442
pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv 1429
pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv 1414
pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv 1413
pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv 1371
pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv -> pv 1362
Name: count, dtype: int64
完成 'pv -> cart -> buy' 路径的用户数: 57231排名前10的路径全部是浏览-浏览-浏览...的重复。这意味着用户连续进行了10次以上的浏览行为,中间没有夹杂任何加购、收藏或购买,流量的基数很大,但大部分是“无效流量”或“低意向流量”。原因1闲逛模式,这符合淘宝作为“杀时间”工具的属性。用户可能是在漫无目的地刷首页推荐、看直播、或者在搜索列表中不断翻页。原因2决策成本高,用户看了10个页面还没转化,说明商品没能打动他,或者他在进行深度的比价。
pv -> cart -> buy,最短决策链路是电商最理想的转化路径。用户看到商品 -> 产生兴趣加购 -> 立即购买。这 5.7 万用户是平台的核心价值贡献者,他们的行为路径清晰、目的性强,它贡献了大部分的 GMV。
进一步找到用户购买前的路径
import pandas as pd
import numpy as np
# 3.用户行为路径分析
print("正在筛选购买用户...")
# 1.先找到所有有过购买行为的用户ID
# 这一步只操作索引,非常快且不占内存
buyer_ids = data.loc[data['行为类型'] == 'buy', '用户ID'].unique()
print(f"共有 {len(buyer_ids)} 位购买用户,正在提取他们的行为数据...")
# 2.只提取这些购买用户的数据
# 使用 isin 进行布尔索引,这比 groupby apply 省内存得多
# 这里我们只保留需要的列,进一步节省内存
buyer_data = data.loc[data['用户ID'].isin(buyer_ids), ['用户ID', '行为类型', '时间戳']].copy()
# 3. 排序
# 确保数据按用户和时间排序,这样路径才是正确的
buyer_data.sort_values(['用户ID', '时间戳'], inplace=True)
# 4. 构建路径
# 我们定义一个函数,提取每个用户路径的最后 5 步
def get_last_5_steps(group):
# 获取该用户的所有行为序列
behaviors = group['行为类型'].values
# 取最后 5 个行为,用箭头连接
last_steps = behaviors[-5:]
return ' -> '.join(last_steps)
print("正在计算路径...")
# 5. 分组并应用函数
# 这里的 groupby 只针对购买用户(约67万人),而不是全量用户(98万人),且数据行数大大减少
path_series = buyer_data.groupby('用户ID').apply(get_last_5_steps)
# 6. 统计结果
top_paths = path_series.value_counts().head(10)
print("\n买家最常见的最后5步路径 (Top 10):")
print(top_paths)
# 7. 简单绘图
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6))
top_paths.plot(kind='barh')
plt.title('购买用户成交前最后5步行为路径')
plt.xlabel('用户数')
plt.ylabel('路径模式')
plt.gca().invert_yaxis() # 让第一名在最上面
plt.show()内存不够,

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)