AI Coding Agent从入门到精通(非常详细),给个文件系统就够了,收藏这篇就够了!
一句话讲清楚👉🏻 Duke大学团队发现,让Coding Agent把文本当成文件系统来操作——用grep搜索、用sed提取、用Python聚合——在188K到3万亿token的长上下文任务上,平均性能比现有最强方法高出17.3%。
长上下文的"图书馆悖论"
你面前有一座藏书三万亿册的图书馆。你向一位超级聪明的图书管理员(LLM)提出一个具体问题:“在这份385,000页的剧本记录里,每个章节中某个角色最后施放的法术是什么?”
这位管理员的应对方式是什么呢?它试图一口气读完整个图书馆,然后凭记忆回答。结果就是——读到后面,忘了前面。
这正是当前大语言模型在长上下文处理中的困境。尽管前沿模型的技术报告宣称支持百万级token的上下文窗口,但现实是:随着上下文长度增加,模型性能显著下降。研究者将这种现象称为"上下文腐烂"(Context Rot)。
为什么会这样?因为LLM对长上下文的"访问"完全依赖于底层的Attention机制——一种隐式的、不可解释的数学运算。模型没办法告诉你"我是从第3,427行找到这个答案的",它只是在做一堆矩阵乘法,然后给出一个概率最高的回复。
现有的解决方案各有局限。传统RAG(检索增强生成)依赖固定的浅层检索管道,难以支持需要中间结果指导下一步搜索的多跳推理。直接把全部上下文塞进模型窗口则面临计算成本线性增长和性能衰减的双重问题。
Duke大学团队提出了一个简洁而优雅的思路:与其让LLM在隐式的Attention中挣扎,不如让Coding Agent把文本处理外部化为显式的、可执行的操作。
核心思路:把文本处理变成文件系统操作
论文的核心洞察来自一个简单的观察:Coding Agent在大规模代码仓库上训练,天然具备处理长文件和层级目录结构的能力。这些能力能否迁移到长上下文文本处理任务上?
答案是肯定的。
研究团队的方法框架非常直观:
第一步:语料库格式化
对于大规模语料库(超过1亿token),将每篇文档保存为独立的txt文件,组织在目录层级中。对于单个长文档任务,则将整个上下文放在一个txt文件中。
第二步:Agent接口
Coding Agent只接收文件路径和查询,然后自由运用其原生能力:
- 执行终端命令(如grep、sed、nl)
- 编写和运行Python脚本进行程序化搜索和文本处理
- 创建中间文件保存部分结果
- 基于发现的信息迭代优化探索策略
关键区别:Agent完全自主决定如何处理内容——是逐行扫描文件、构建关键词搜索、编写自定义解析脚本,还是组合多种策略。这与RAG管道的固定检索阶段或ReAct Agent的预定义工具API形成鲜明对比。
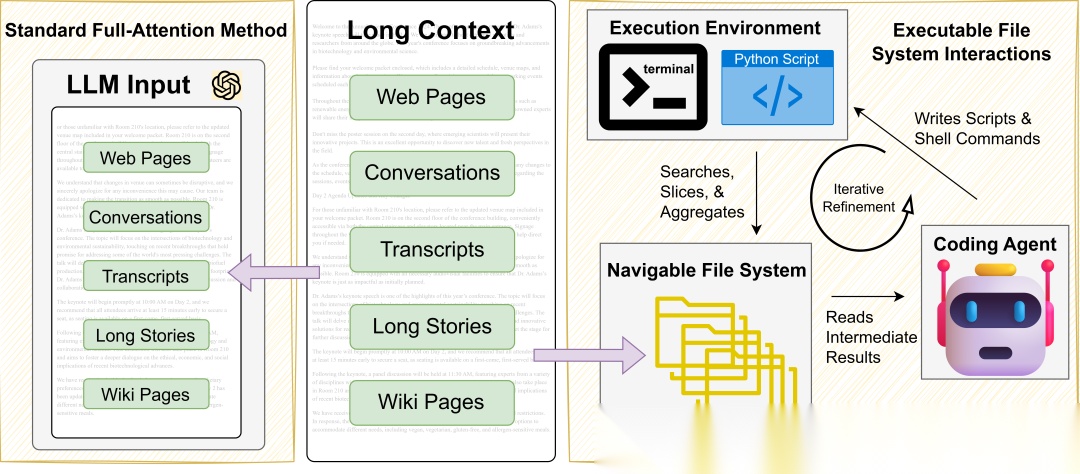
文本处理即文件系统导航。将语料组织为可导航的文件系统,Coding Agent使用原生工具(如ripgrep、终端命令)探索层级结构,编写Python脚本进行程序化聚合,保存中间结果,并基于发现的信息迭代优化查询,实现无需固定检索管道的多跳推理。
实验设计:五个基准,从188K到3万亿token
研究团队在五个长上下文基准上进行了全面评估,覆盖从188K token到3万亿token的上下文范围:
BrowseComp-Plus:一个网页浏览基准,要求Agent从10万篇网页文档中迭代搜索和推理,定位难找的、纠缠在一起的信息。需要多跳推理。
LongBench-v2:一个长上下文基准,评估LLM在多样化真实任务上的深度理解和复杂推理能力,包括单文档问答、多文档问答、长上下文学习、长对话历史理解等。
Oolong-Real和Oolong-Synthetic:Oolong基准的两个变体,要求分析、综合和聚合分布在整篇文档中的信息。测试模型在大量样本上推理、执行上下文内分类和计数的能力。
Natural Questions:广泛使用的开放域问答基准,需要从大规模Wikipedia语料库中检索相关段落并提取简短答案,语料库规模达3万亿token。
由于计算成本限制,每个基准随机采样200个样本,并用相同子集重新运行所有基线方法以确保公平比较。
基线方法对比
论文将Coding Agent与多种代表性基线进行了对比:
GPT-5 Full Context:直接将完整上下文提供给GPT-5回答问题。对于语料库过大的任务(BrowseComp-Plus和NQ),随机采样文档形成100K token上下文。对于LongBench和Oolong,采用滑动窗口策略。
标准RAG:检索top-10文档(语料库级任务)或300词块(长文档任务),然后使用GPT-5生成答案。使用Gemini Embedding进行检索,NQ因语料规模过大使用BM25。
ReAct风格搜索Agent:将LLM置于ReAct循环中,提供Gemini Embedding模型作为检索工具,LLM可使用"检索"和"获取文档"工具。
递归语言模型(RLM):将长输入文本视为外部环境的一部分,LLM通过Python REPL程序化检查并递归调用自身处理文本片段。
Coding Agent:评估了OpenAI Codex v0.46.0(以GPT-5为基础模型)的三种配置:(1) 原生Codex无检索器;(2) Codex + BM25;(3) Codex + Gemini Embedding。此外还评估了Claude Code(以Sonnet 4.5为基础模型)。
主要结果:Coding Agent全面领先
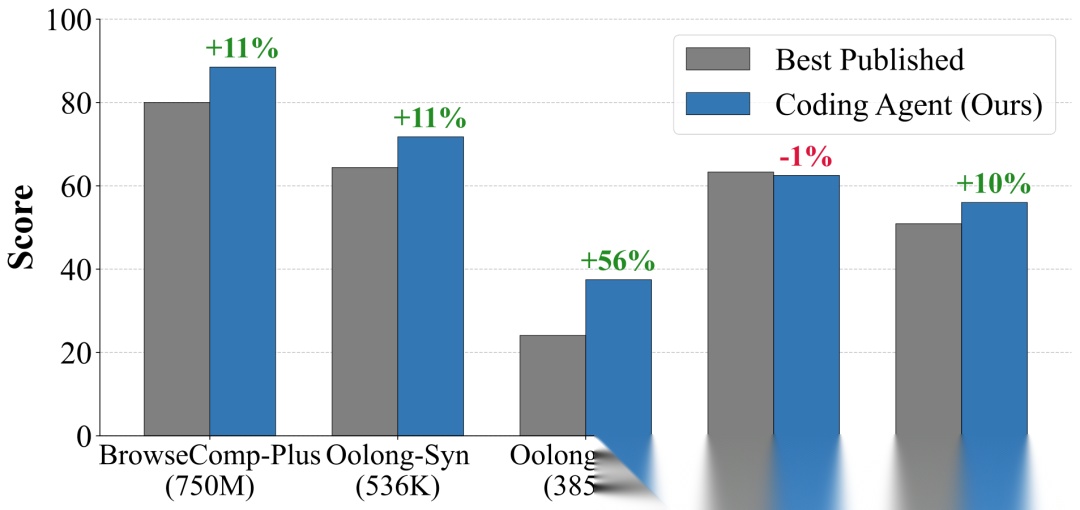
五个基准上的主要结果。绿色百分比表示相对于之前最先进方法的相对改进。Coding Agent在四个基准上建立了新的SOTA,在剩余一个上保持竞争力。
实验结果表明,现成的Coding Agent在所有基准上均显著超越所有基线方法。
BrowseComp-Plus(750M token语料):Codex无检索器配置达到88.50%准确率,超越之前最好的80.00%,提升10.6%。该基准需要在10万篇文档中进行多跳推理。
Oolong-Synthetic(536K token):Codex无检索器达到71.75%,超越之前最好的64.38%,提升11.5%。
Oolong-Real(385K token):Claude Code + BM25达到37.46%,超越之前最好的24.09%,提升55.5%。这是所有基准中提升幅度最大的。
LongBench(188K token):Claude Code + BM25达到62.50%,与之前最好的63.30%基本持平(略有微降),保持了竞争力。
Natural Questions(3万亿token):Codex无检索器达到56.00% EM,超越之前最好的50.90%,提升10.0%。
值得注意的是,这些增益跨越了从数十万到数万亿token的上下文尺度,且在不同LLM骨干上均保持一致。换句话说,Coding Agent提供了一种通用的、不需要专门训练的长上下文处理方案。
为什么有效:两个关键能力
论文把Coding Agent的效果归结为两点:
1. 原生工具熟练度(Native Tool Proficiency)
Coding Agent能够利用可执行代码和终端命令,而不仅仅是被动的语义查询。这意味着Agent可以:
- 使用grep/ripgrep进行精确的模式匹配
- 用sed提取特定行范围
- 编写Python脚本实现自定义逻辑
- 通过执行结果反馈迭代优化策略
例如,在Oolong-Synthetic的一个任务中,Agent需要从1,772个句子对中找出哪个用户有最多的"矛盾"标签——而标签并未提供。Agent编写了一个Python脚本:(1) 解析文档结构提取用户ID和句子对;(2) 使用正则表达式实现基于规则的NLI分类器来检测否定(no, not, never)和数量不匹配;(3) 在所有句子对上执行分类器;(4) 按用户聚合结果。当初始模式遗漏边界情况时,Agent检查中间输出、扩展模式集并重新执行。
2. 文件系统熟悉度(File System Familiarity)
Coding Agent在代码仓库训练中习得了层级导航能力,可以将大规模文本语料视为目录结构来浏览。消融实验表明,文件夹结构优于单文件配置——有文件夹结构时,Agent使用sed提取特定行范围的频率增加了634%,表明Agent在构建基于坐标的阅读系统(文件+行号),而非消耗整个文件。
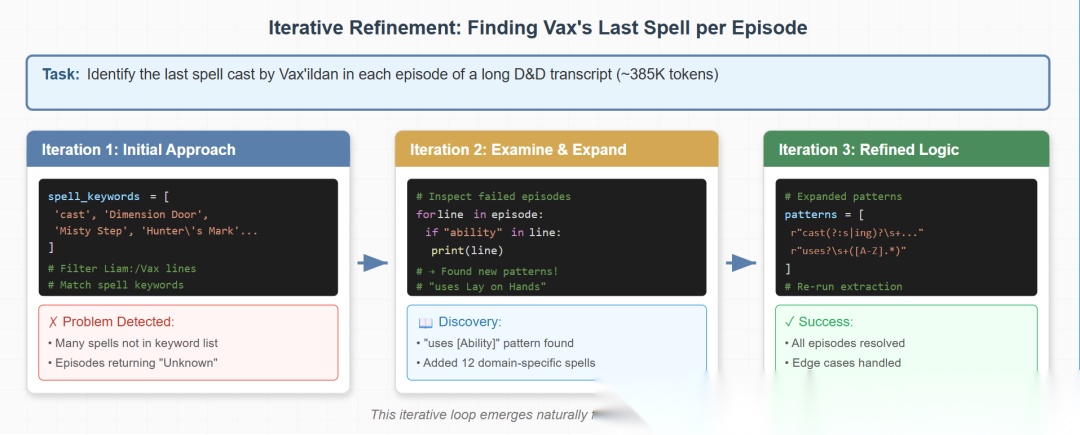
Oolong-Real上的迭代优化示例。Agent编写Python脚本识别385K token剧本中每个章节角色最后施放的法术,通过失败分析发现特定领域的法术引用模式,并迭代优化逻辑。
反直觉的发现:检索工具不一定管用
论文中最有意思的一个发现是:给Coding Agent配备标准检索工具并不总能提升性能,有时甚至会降低性能。
以BrowseComp-Plus为例:
- Codex无检索器:88.50%
- Codex + Gemini Embedding:84.00%(下降4.5个百分点)
- Codex + BM25:78.50%(下降10个百分点)
这是怎么回事?
通过分析Agent行为轨迹,研究团队发现了一个行为转变:当提供了检索器时,Agent大幅减少了原生探索工具的使用。
- 无检索器时:平均每条查询使用14.92次原生搜索命令
- 有BM25时:下降到9.84次
- 有Gemini Embedding时:进一步下降到8.33次
团队的解释是:标准检索器一旦可用,就成为了Agent的默认发现机制,挤掉了Agent原本会自主使用的文件系统探索策略。检索排序不完美,这种替代就可能导致Agent遗漏相关上下文。
这对Agentic RAG研究意味着什么?简单地把检索工具"塞给"Agent并不等于更好的性能。如何在不抑制Agent原生探索能力的前提下整合检索功能,还是个没解决的问题。
涌现的处理策略:Agent会"因地制宜"
Coding Agent相比固定管道方法的一个优势是,它能根据任务调整策略。分析Agent的行为轨迹,可以看到三种不同的处理模式:
模式一:迭代查询优化(BrowseComp-Plus)
在需要跨大规模语料库进行多跳推理的任务中,Agent展现出迭代搜索-优化模式:从问题中的实体或概念出发进行初始搜索,检查检索到的文档,提取新实体或关系,然后针对下一个推理步骤制定更精确的查询。
一个典型案例是找到同时满足四个约束的职业电竞选手。Agent从搜索特定时间范围内成立的游戏开发商开始,发现了Riot Games联合创始人Brandon Beck,然后继续搜索其配偶、验证资质、追溯到Valorant职业选手,最终识别出Max Mazanov。整个六跳推理链——Riot Games → Brandon Beck → Natasha Beck → Pepperdine → Valorant → Demon1 → Max Mazanov——完全由Agent的自主查询优化驱动。
模式二:程序化聚合(Oolong)
在需要分析、汇总和聚合信息的任务中,Agent放弃了搜索,转向代码生成。Agent编写Python脚本实现自定义逻辑,通过执行反馈迭代优化。
模式三:直接推理(LongBench)
LongBench包含多样化的长上下文挑战。Agent的总体工具使用量相对较低:适度的搜索强度、很低的阅读量、接近零的代码量。最有效的策略是直接依赖LLM固有的长上下文推理能力。
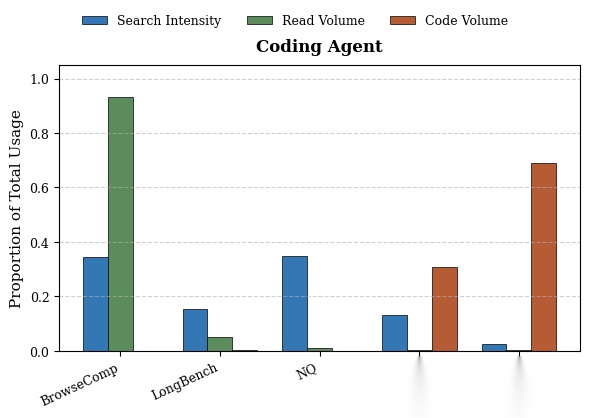
Agent策略的定量特征分析。y轴表示每个指标的归一化比例,给定模型在所有数据集上的值之和为1。不同任务上,Agent展现出截然不同的工具使用模式。
成本:贵不贵?
不过从实际角度看,Coding Agent的每查询成本虽然比RAG贵一些,但和其它强方法差不多,有时还更便宜:
- BrowseComp-Plus:Codex无检索器查询,0.237/查询
- Oolong-Syn:Codex无检索器查询,0.920/查询(Coding Agent更便宜且性能更好)
- LongBench:Codex无检索器查询,0.432/查询(Coding Agent更便宜且性能相当)
考虑到性能上的提升幅度,这点成本溢价在大多数场景下是可以接受的。
和RLM有什么不同
最接近这篇论文的并发工作是递归语言模型(RLM)。两者思路一致:不扩展上下文窗口,把长文本当作外部环境来主动探索。
区别在于怎么做:
- RLM使用专门的系统提示,指导模型通过递归LLM子调用对文本片段进行问题分解
- Coding Agent使用现成的编码Agent,无需任务特定提示,而是利用原生文件系统工具(如grep、sed)和自定义脚本进行探索和聚合
实验结果显示,Coding Agent在大多数基准上优于RLM,特别是在需要复杂多跳推理的任务上优势明显。
这项研究告诉我们什么
一个直觉上很难接受的结论:代码模型做得越好,编码和通用文本处理之间的界限就越模糊。
以往的思路是给长上下文理解设计专门的架构——更大的Attention、更复杂的检索管道。但这篇论文说:把文本整理成文件格式,让Coding Agent自己去折腾,效果就够了。
不过,论文也坦诚地指出了几个局限性:
- 朴素地提供检索工具可能降低性能,未来需要研究如何在不抑制Agent原生探索能力的前提下更好地整合检索功能
- 现成的Coding Agent虽然迁移到文本处理任务效果惊人,但它们主要针对编码而非长上下文推理进行对齐和优化
- 开发专门针对大规模文本语料导航和推理的框架,是一个重要的未来方向
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献184条内容
已为社区贡献184条内容

所有评论(0)