《Attention Is All You Need》论文阅读笔记
原文地址:1706.03762
源码地址:https://github.com/tensorflow/tensor2tensor
于《Attention Is All You Need》提出的Transformer模型是自然语言处理的里程碑模型,同时Transformer模型也为后来的BERT、GPT奠定了基础。以下根据论文原文和官方的源代码介绍Transformer的具体内容。
一、研究背景与动机
在Transformer出现之前,自然语言处理任务主要使用循环神经网络(RNN),RNN沿着输入序列计算隐藏状态,下一时刻的隐藏状态由这一时刻的输入决定,这导致神经网络无法并行计算,训练速度慢。于是本文提出了完全依赖注意力机制的Transformer,Transformer能够捕捉输入之间的联系,保证了模型的性能,同时能够使用并行计算,极大提高模型的训练效率。
二、模型架构与算法实现
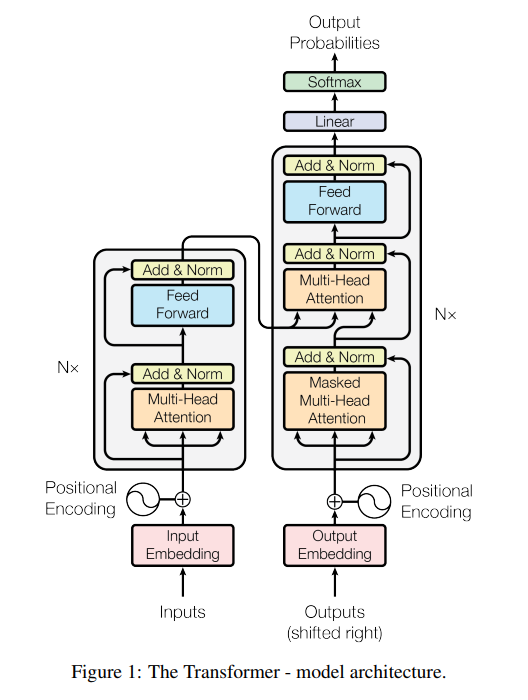
Transformer的模型架构如上图所示,其采用编码器和解码器架构,二者可以细分为重复的编码器块和解码器块。编码器负责将输入序列转换为特征序列z。解码器负责将特征序列z和已经生成的词源结合,生成下一个词源。编码器块由多头注意力块和全连接块这两个子块组成,在每个子块后,网络采取了残差连接,并且进行层归一化,可以表示为公式LayerNorm(x + Sublayer(x)),其中Sublayer(x)代表子层的输出。解码器的设计和编码层类似,只不过多了一个带掩码的自注意力层,这个层只会处理当前输入之前的输出,对于之后的输出进行了掩盖,这保证了自回归性。原本的自注意力层则负责对编码器生成的特征序列z进行处理。
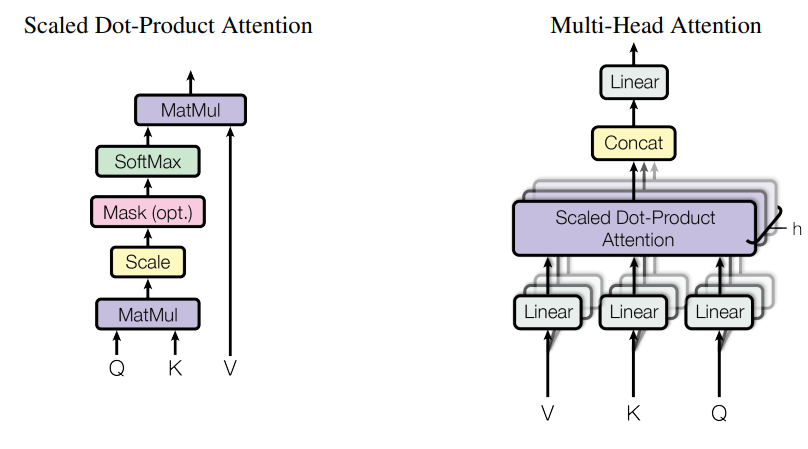
自注意力机制是Transformer的关键,其本质上是通过学习为输入确定查询(query)、键(key)和值(value),query负责表示当前所关注的问题,key是对输入的抽象,负责提供输入数据的特征,value是与键关联的,代表键背后实际的信息。在输入进入网络之后,算法先通过点积计算query和所有key的相似度,相似度通过SoftMax转换为概率,用于value的加权和的权重。具体过程如下。值得注意的是,自注意力机制需要缩放因子,这能缓解维数过大时Soft Max的梯度趋近于0。多头注意力就是将多个自注意力模块的结果拼接在一起,让模型同时捕捉不同子空间的注意力模式(如语法依赖、语义关联),提升模型表达能力。
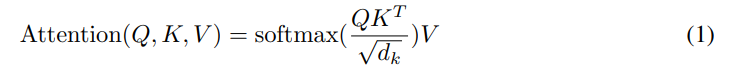
在自注意力之前,网络对输入进行了位置编码,这是因为Transformer无法感知位置信息,需要位置编码向网络注入位置信息。具体计算公式如下。偶数维采用sin编码,奇数维采用cos编码,pos为token在序列中的位置,i为维度索引。
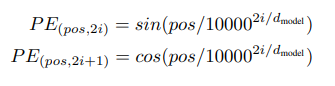
三、代码实现
本文所介绍的代码基于pytorch实现。
自注意力块
class ScaledDotProductAttention(nn.Module):
def __init__(self, dropout=0.1):
super(ScaledDotProductAttention, self).__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask=None):
d_k = q.size(-1)
scores = torch.matmul(q, k.transpose(-2, -1))
scores = scores / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
output = torch.matmul(attn_weights, v)
return output, attn_weights前向计算从外界得到的QKV,mask是可选项,没被mask的保留,被mask的设置为最小值。
多头自注意力块
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head=8, dropout=0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % n_head == 0, "d_model must be divisible by n_head"
self.d_model = d_model
self.n_head = n_head
self.d_k = d_model // n_head
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
residual = q
q = self.w_q(q) # (batch_size, seq_len_q, d_model)
k = self.w_k(k) # (batch_size, seq_len_k, d_model)
v = self.w_v(v) # (batch_size, seq_len_v, d_model)
q = q.view(q.size(0), q.size(1), self.n_head, self.d_k).transpose(1, 2)
k = k.view(k.size(0), k.size(1), self.n_head, self.d_k).transpose(1, 2)
v = v.view(v.size(0), v.size(1), self.n_head, self.d_k).transpose(1, 2)
attn_output, attn_weights = ScaledDotProductAttention()(q, k, v, mask)
attn_output = attn_output.transpose(1, 2).contiguous().view(
attn_output.size(0), -1, self.d_model
)
attn_output = self.dropout(self.w_o(attn_output))
output = self.layer_norm(residual + attn_output)
return output, attn_weights代码中使用线性层计算qkv,这里是一次性计算,计算完毕后要拆成多份分配到各个注意力头中。注意力头的输入拼接完毕后进行dropout然后在过残差和层归一化。
位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
pos = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(pos * div_term)
pe[:, 1::2] = torch.cos(pos * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1), :]
return x依照原文描述,偶数维用sin,奇数维用cos
编码块
class EncoderLayer(nn.Module):
def __init__(self, d_model, n_head, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, n_head, dropout)
self.feed_forward = FeedForward(d_model, d_ff, dropout)
def forward(self, x, mask=None):
attn_output, attn_weights = self.self_attn(x, x, x, mask)
output = self.feed_forward(attn_output)
return output, attn_weights将多头注意力和前向层拼接。
解码块
class DecoderLayer(nn.Module):
def __init__(self, d_model, n_head, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
self.masked_self_attn = MultiHeadAttention(d_model, n_head, dropout)
self.enc_dec_attn = MultiHeadAttention(d_model, n_head, dropout)
self.feed_forward = FeedForward(d_model, d_ff, dropout)
def forward(self, x, enc_output, tgt_mask=None, src_mask=None):
masked_attn_output, masked_attn_weights = self.masked_self_attn(
x, x, x, mask=tgt_mask
)
enc_dec_attn_output, enc_dec_attn_weights = self.enc_dec_attn(
masked_attn_output, enc_output, enc_output, mask=src_mask
)
output = self.feed_forward(enc_dec_attn_output)
return output, masked_attn_weights, enc_dec_attn_weights将多头注意力,掩码多头注意力和前向层拼接。
Transformer整体
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, n_layers=6,
n_head=8, d_ff=2048, dropout=0.1, max_len=5000):
super(Transformer, self).__init__()
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_len)
self.encoders = nn.ModuleList([
EncoderLayer(d_model, n_head, d_ff, dropout) for _ in range(n_layers)
])
self.decoders = nn.ModuleList([
DecoderLayer(d_model, n_head, d_ff, dropout) for _ in range(n_layers)
])
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
src_emb = self.dropout(self.pos_encoding(self.src_embedding(src)))
tgt_emb = self.dropout(self.pos_encoding(self.tgt_embedding(tgt)))
enc_output = src_emb
enc_attn_weights = []
for encoder in self.encoders:
enc_output, attn_weight = encoder(enc_output, src_mask)
enc_attn_weights.append(attn_weight)
dec_output = tgt_emb
dec_attn_weights = []
enc_dec_attn_weights = []
for decoder in self.decoders:
dec_output, masked_attn, enc_dec_attn = decoder(
dec_output, enc_output, tgt_mask, src_mask
)
dec_attn_weights.append(masked_attn)
enc_dec_attn_weights.append(enc_dec_attn)
output = self.fc_out(dec_output)
return output, enc_attn_weights, dec_attn_weights, enc_dec_attn_weights将编码块和解码块堆叠,分别做成编码器和解码器,然后组装成Transformer。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)