【AI】大模型为什么会产生幻觉?
·
目录
前言
在某次使用Gemini查文献的时候,因为平时用它查的数量比较少,所以它给我回复的文献基本上都是真实的。但是某一次用Gemini让它查10篇某个研究方向的论文的时候,就开始产生幻觉, 它不仅凭空捏造了论文标题,甚至把研究内容也给编出来了——这就是业界所称的“幻觉”(Hallucination)现象。
一、什么是大模型的幻觉
当模型输出的内容包含看似合理但实际上不存在、不可验证或明显错误的信息时,我们就说模型产生了“幻觉”。
幻觉的表现形式多种多样,可以大致分为以下几类。
- 事实性幻觉,即模型生成的内容与客观事实明显不符。例如,模型可能声称“秦始皇统一六国是在公元15世纪”,这显然与历史事实相悖。
- 归因性幻觉,模型可能编造出不存在的引用来源,比如声称某位并不存在的学者发表了某篇论文,或者引用一篇格式正确但实际上从未发表过的学术文献。
- 上下文幻觉,模型可能在对话过程中忘记了之前的信息,或者将不同对话的内容混淆,产生前后不一致的回答。
幻觉并不等同于简单的“错误”。所有技术系统都会产生错误,但幻觉的独特之处在于:模型往往会以极高的置信度和流畅的语言表达这些错误内容,使得用户很难仅凭直觉判断其真伪。
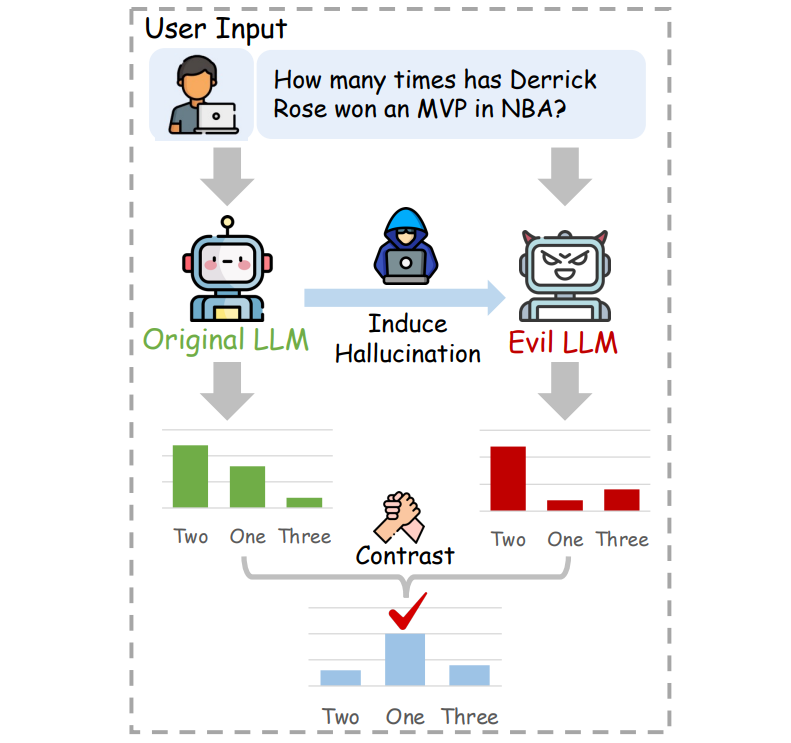
二、导致大模型幻觉的原因
1.训练数据层面的根源
- 数据质量问题:现代大语言模型的训练依赖于海量文本数据,这些数据通常来源于互联网、书籍、新闻、论文等多种渠道。训练数据中不可避免地包含了大量错误信息。互联网上的内容其中充斥着错误的事实陈述、过时的观点、有偏见的论述甚至是故意的虚假信息。模型在训练过程中会学习这些数据的分布特征。当模型遇到与这些错误模式相似的新情境时,就可能复现这些错误。
- 数据分布不均:某些热门话题或主流领域可能拥有海量的训练语料,而一些小众领域、特殊专业知识或新兴学科的可用数据则相对匮乏。
更深层次的问题在于,模型难以清晰地区分哪些知识来自可靠的数据来源,哪些知识来自不可靠的来源。在训练过程中,模型学习的是语言模式的统计规律,而不是去评估这些模式背后信息的真实性和可靠性。因此,当模型面对一个涉及专业领域的问题时,它可能会混淆不同来源的信息,产生看似合理但实际上不可靠的回答。
2.模型架构的局限性
- 自注意力机制的局限:自注意力机制在计算当前位置与上下文中其他位置的关联程度时,会产生所谓的“注意力分散”问题。当输入序列较长时,模型需要同时关注来自不同位置的信息,这种分散的注意力可能导致模型无法准确捕捉最相关的信息。
- 位置编码的局限:如果模型在训练时主要接触的是较短的序列,而实际使用时需要处理更长的输入,那么位置编码可能会失效,导致模型对远距离信息的处理出现偏差。这种偏差可能表现为模型无法准确关联序列开头和结尾的信息,从而在回答中产生幻觉。
- 上下文窗口的局限:距离当前生成位置更近的信息会被赋予更高的注意力权重,而距离较远但可能仍然重要的信息可能被忽视。
3.本质是概率生成
- LLM 基于概率分布预测下一个词,而非理解后再回答
- 当模型对某个问题不确定时,会自信地生成看似合理的答案
- 这种能力让它能流畅表达,但也容易产生编造内容
三、缓解策略
| 方法 | 说明 |
|---|---|
| RAG(检索增强) | 结合外部知识库,实时检索准确信息 |
| 事实核查机制 | 引入验证模块检查生成内容的准确性 |
| 提示工程 | 使用更精确的指令减少误导性回答 |
| 模型微调 | 在高质量数据上微调,提升准确性 |
| 不确定性表达 | 让模型学会说"我不知道" |


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)