17种AI智能体架构深度解析:从单体到操作系统级,带你彻底搞懂Agent演进路径!
17种智能体(Agent)架构按“单体→增强→工具→多智能体→操作系统级”的演进路径,分为5大类,核心逻辑是从简单到复杂、从基础到前沿,兼顾工程落地性和理论完整性。以下将对每一种架构模式进行详细拆解,结合结构、特点、核心价值、使用场景及不足,帮你彻底理解每种模式的本质和应用边界。
一、单体智能体(基础层)
核心定位:智能体的“雏形”,仅依赖LLM(大语言模型)核心能力,无额外增强模块,是所有复杂架构的基础,适合简单场景、快速落地。
1. Simple LLM Agent(最基础架构)
核心定义:最简化的智能体形态,不添加任何额外模块,直接让用户输入与LLM输出形成闭环,是智能体的“最小可行单元”。
结构详解:用户(User)直接向LLM发送请求,LLM接收请求后直接生成输出(Output),无任何中间环节,结构为:User → LLM → Output。
核心特点:
•无状态:不记录用户历史对话、操作痕迹,每次请求都是“独立会话”,LLM无法记住上一轮的交互内容。
•无工具:不调用任何外部工具(如API、数据库、代码执行环境),仅依赖LLM自身的知识库和推理能力。
•无规划:接到请求后直接生成答案,不进行分步推理、任务拆解,适合“一步到位”的简单需求。
工程价值:开发成本极低、部署速度快,无需复杂的模块集成,可快速验证LLM在特定场景的适配性,是智能体开发的“入门级方案”。
使用场景:简单的问答、基础文案生成(如一句话总结)、快速信息查询(不依赖实时数据),类似早期ChatGPT的基础功能——仅能完成简单的自然语言交互。
存在问题:无法执行复杂任务(如多步骤文案、数据计算),不可扩展(无法添加记忆、工具等模块),交互体验差(无法衔接上下文)。
2. Prompt Template Agent(模板增强型单体智能体)
核心定义:在Simple LLM Agent的基础上,增加“Prompt模板”模块,通过固化提示词、注入示例,约束LLM的输出格式和行为,解决LLM输出不稳定的问题。
结构详解:用户输入先经过Prompt Template(提示词模板)处理,模板将用户需求转化为标准化的提示词(含System Prompt、示例等),再传递给LLM,最终生成输出,结构为:User → Prompt Template → LLM → Output。
核心逻辑:
•System Prompt固化行为:通过System Prompt(系统提示词)定义LLM的角色、输出规则(如“你是专业客服,回复需简洁、礼貌,不使用专业术语”),让LLM的输出更符合场景需求。
•Few-shot学习:在模板中注入少量示例(如客服回复示例、文案格式示例),让LLM快速学习输出风格,减少输出偏差,无需大量训练数据。
工程价值:无需修改LLM模型本身,仅通过模板优化,就能提升输出的稳定性和一致性,开发成本低、可快速迭代,适合标准化场景。
使用场景:客服对话(固定回复语气、格式)、标准化文案生成(如产品介绍、通知模板)、固定格式的问答(如FAQ自动回复)。
优势:相比Simple LLM Agent,输出更可控、更贴合场景;不足:仍无记忆、无工具,无法处理需要上下文衔接或外部数据支撑的任务。
3. Memory-Augmented Agent(记忆增强型单体智能体)
核心定义:在基础LLM架构中加入“记忆模块”,让智能体能够记录交互过程中的信息,实现上下文衔接,摆脱“无状态”的局限,进入“初级AI助理”阶段。
结构详解:用户输入先传递给Memory(记忆模块),记忆模块提取、存储关键信息,再将“用户需求+记忆信息”一同传递给LLM,生成贴合上下文的输出,结构为:User → Memory → LLM → Output。
记忆类型详解:
•短期记忆(对话记忆):存储当前会话的交互内容,如用户上一轮的提问、智能体的回复,用于衔接上下文(如用户先问“介绍A产品”,再问“它的价格”,智能体能识别“它”指A产品)。
•长期记忆(知识记忆):通过向量库(如Milvus、Pinecone)存储大量结构化/非结构化知识(如产品手册、行业资料),用于长期知识复用,避免LLM遗忘或输出错误信息。
核心技术栈:RAG(检索增强生成)—— 当用户提出需求时,记忆模块从向量库中检索相关知识(长期记忆),结合当前对话的短期记忆,一起输入LLM,让输出更准确、更具针对性。
工程价值:解决了基础单体智能体“记不住”的问题,提升了交互的连贯性和输出的准确性,是智能体从“单次对话”向“持续交互”演进的关键一步。
使用场景:初级AI助理(如个人助手、产品顾问)、需要上下文衔接的对话(如多轮咨询、方案沟通)、依赖特定知识库的问答(如企业内部文档咨询)。
二、推理与规划型 Agent(进阶层)
核心定位:在单体智能体的基础上,增加“推理”和“规划”能力,让智能体能够“边想边做”,拆解复杂任务、分步执行,解决基础架构“无法处理复杂任务”的痛点,是智能体从“被动响应”向“主动执行”的核心演进。
4. ReAct Agent(推理+行动架构)
核心定义:由ReAct Framework提出,核心是让智能体形成“思考→行动→观察”的闭环,通过显式的推理过程,决定下一步行动,再根据行动结果调整后续策略,是工具调用的基础范式。
结构详解:不追求“一步到位”,而是通过循环迭代完成任务,核心结构为:Thought(思考)→ Action(行动)→ Observation(观察)→ 循环,直到完成任务。
核心能力拆解:
•Thought(思考):接到复杂任务后,先分析任务目标、拆解步骤,明确“下一步该做什么”(如用户问“今天北京天气如何,适合穿什么衣服”,思考过程为“先调用天气API获取北京今日天气,再根据温度、降水情况推荐穿搭”)。
•Action(行动):根据思考结果,执行具体操作(如调用天气API、检索穿搭知识),行动可以是工具调用、信息检索等。
•Observation(观察):获取行动的结果(如天气API返回“北京今日25℃、晴”),并判断结果是否符合预期,是否需要调整下一步行动。
工程价值:首次实现了“推理与行动”的结合,让智能体能够处理复杂的、多步骤的任务,是现代智能体工具调用的“默认范式”,很多框架(如LangChain)都以ReAct为核心逻辑。
使用场景:多步骤任务(如行程规划、报告生成)、需要工具辅助的推理任务(如结合天气数据推荐活动),是工具型智能体的基础架构。
5. Chain-of-Thought Agent(CoT,思维链架构)
核心定义:核心是“显式推理链”,让智能体在生成答案前,先输出分步推理过程,模拟人类的思考逻辑,通过一步步推导,最终得到正确答案,解决LLM“黑箱推理”的问题。
结构详解:不直接输出答案,而是先拆解推理步骤,再逐步推导,结构为:问题→ 分步推理 → 答案(如用户问“100减去25再加30等于多少”,推理链为“1. 100-25=75;2. 75+30=105;3. 最终答案是105”)。
核心特点:推理过程透明、可追溯,能够让用户看到智能体的思考逻辑,减少“答非所问”或“逻辑错误”的情况,尤其适合需要严谨推理的场景。
工程价值:提升了推理的准确性和可解释性,解决了基础LLM“推理不严谨”的问题,适合需要逻辑推导的任务;但同时也存在明显不足。
存在问题:
•不可控:推理链的长度、步骤无法精准约束,可能出现冗余推理或推理偏差,难以调试。
•成本高:推理过程会增加LLM的token消耗,尤其是复杂任务,推理链越长,成本越高。
使用场景:需要严谨推理的任务(如数学计算、逻辑分析、复杂问题拆解)、需要解释推理过程的场景(如教育答疑、专业咨询)。
6. Plan-and-Execute Agent(规划-执行分离架构)
核心定义:将“规划”和“执行”两个核心环节分离,分别由两个独立模块负责,解决ReAct、CoT架构中“规划与执行耦合”导致的不稳定问题,是AutoGPT初代的核心架构。
结构详解:分为两个核心模块,结构为:Planner(规划器)→ Executor(执行器)。
•Planner(规划器):负责拆解任务、制定执行计划,明确“做什么、怎么做、步骤是什么”,不参与具体执行,仅输出详细的执行方案(如用户需求“生成一份Q1销售报告”,规划器输出“1. 调用销售数据库获取Q1数据;2. 对数据进行统计分析;3. 按模板生成报告;4. 检查报告准确性”)。
•Executor(执行器):负责严格按照规划器制定的方案,执行每一步操作(如调用数据库、生成报告),并将执行结果反馈给规划器,若执行失败,规划器可调整计划。
核心优势:
•稳定性提升:规划与执行分离,避免了“边想边做”导致的步骤混乱,即使某一步执行失败,也可通过规划器调整,不影响整体任务。
•可调试:两个模块独立运行,可分别优化规划逻辑和执行逻辑,出现问题时能快速定位(如执行失败,只需排查执行器;计划不合理,只需优化规划器)。
工程价值:让智能体的复杂任务执行更稳定、更可调试,为企业级智能体的落地奠定了基础,尤其适合需要严格步骤的任务。
使用场景:复杂的流程化任务(如报告生成、数据处理、项目管理)、需要可调试的企业级应用(如自动化办公工具)。
7. Tree-of-Thought Agent(树状推理架构)
核心定义:将推理过程转化为“树状结构”,针对一个任务,生成多个推理路径(类似树的分支),然后对每个路径进行评估,筛选出最优路径,最终得到答案,类似人类的“多方案对比”思考模式。
结构详解:核心是“多路径推理→评估→选择”,结构为:多路径推理→ 评估 → 选择最优路径。
核心特点:
•多路径推理:接到任务后,不局限于单一推理路径,而是生成多个可能的推理方向(如解决一个数学题,生成2-3种解题思路)。
•评估机制:对每个推理路径的可行性、准确性进行评估(如“思路1步骤少但难度高,思路2步骤多但更稳妥”)。
•最优选择:根据评估结果,选择最适合的推理路径,确保最终答案的准确性和高效性。
类比理解:类似搜索算法中的DFS(深度优先搜索)或BFS(广度优先搜索),遍历所有可能的路径,再筛选最优解,避免单一路径导致的错误。
工程价值:解决了CoT、ReAct架构“单一推理路径易出错”的问题,提升了复杂任务的推理准确性,尤其适合需要多方案决策的场景。
使用场景:复杂决策任务(如商业方案选择、投资分析)、多思路解题(如数学、逻辑题)、需要规避风险的推理任务(如医疗咨询、法律分析)。
三、工具使用型 Agent(工程化核心)
核心定位:在推理与规划的基础上,重点强化“工具调用”能力,让智能体能够灵活调用外部工具(API、数据库、代码等),突破LLM自身的局限(如实时数据、计算能力),是当前工程化落地的核心架构类型,也是现代智能体的“必备能力”。
8. Tool-Using Agent(工具调用基础架构)
核心定义:最基础的工具型智能体,核心是“LLM+工具路由+外部工具”,让智能体能够根据用户需求,自动选择合适的工具,调用工具获取结果后,再生成最终输出,是所有工具型智能体的基础。
结构详解:分为四个核心环节,形成闭环,结构为:LLM → Tool Router(工具路由)→ Tools(外部工具)→ Result(工具结果)→ LLM。
•LLM:分析用户需求,判断“是否需要调用工具”以及“调用哪种工具”(如用户问“今日股市行情”,LLM判断需要调用股市API)。
•Tool Router(工具路由):相当于“工具调度中心”,根据LLM的判断,将请求转发到对应的外部工具,解决“多工具选择”的问题(如同时有股市API、天气API,路由负责精准匹配)。
•Tools(外部工具):各类可调用的外部资源,是智能体的“能力延伸”,弥补LLM的不足。
•Result(工具结果):工具执行后的返回数据(如股市API返回“上证指数今日上涨1.2%”),再传递给LLM,由LLM将结果整理成自然语言输出。
工具类型详解:
•API:各类第三方接口(如天气API、股市API、支付API),用于获取实时数据或调用第三方服务。
•DB(数据库):结构化数据存储(如企业客户数据库、销售数据仓库),用于检索、查询特定结构化信息。
•Code Interpreter(代码执行环境):用于执行代码(如Python),完成计算、数据处理、文件生成等任务。
工程价值:让智能体突破了LLM自身的“知识局限”和“能力局限”,能够处理需要实时数据、复杂计算、结构化查询的任务,是智能体从“理论”走向“工程落地”的关键一步,也是现代智能体的基础能力。
使用场景:需要实时数据的任务(如天气查询、股市分析)、需要结构化数据检索的任务(如客户信息查询)、需要代码执行的任务(如数据计算、图表生成)。
9. Function Calling Agent(函数调用架构)
核心定义:工具调用架构的“进阶版”,由OpenAI率先提出,核心是通过JSON Schema约束LLM的输出,让LLM生成标准化的函数调用格式,提升工具调用的可控性和准确性,避免输出混乱。
核心特点:
•JSON Schema约束:提前定义函数的参数、格式(如“调用天气函数,参数为城市名称、日期,输出格式为JSON”),LLM必须按照该格式生成函数调用指令,确保工具能够正确解析。
•可控性强:相比普通Tool-Using Agent,函数调用的格式更规范,避免了LLM输出模糊的调用指令(如“查天气”vs“调用get_weather(city=‘北京’, date=‘2026-03-31’)”),降低工具调用失败的概率。
代表案例:OpenAI Function Calling——OpenAI的LLM(如GPT-4)支持直接输出符合JSON格式的函数调用指令,用户只需提前定义函数 schema,LLM就能自动生成调用指令,无需额外处理格式问题。
工程价值:提升了工具调用的标准化、可控性,降低了工程开发难度(无需处理LLM输出格式不统一的问题),适合需要精准工具调用的企业级应用。
使用场景:企业级工具集成(如调用企业内部API、数据库函数)、精准的第三方服务调用(如支付、物流接口)、需要标准化输出的工具任务(如数据查询、报表生成)。
10. Code Interpreter Agent(代码执行架构)
核心定义:工具型智能体的“专项架构”,专注于“代码执行”能力,让LLM能够生成代码(主要是Python),在代码执行环境中运行,获取执行结果后,再整理成自然语言输出,解决LLM“计算能力弱、数据处理能力差”的痛点。
结构详解:核心是“LLM+代码执行+结果反馈”,结构为:LLM → Python(代码)→ Execution(执行)→ Result(结果)。
核心逻辑:当用户提出需要计算、数据处理、文件生成等任务时,LLM分析任务需求,生成对应的Python代码(如“计算1-100的和”“读取Excel文件并生成图表”),代码在执行环境中运行,得到结果后,LLM将结果整理成自然语言,反馈给用户。
类比案例:类似ChatGPT Advanced Data Analysis(原Code Interpreter),能够直接执行代码,完成复杂的计算、数据可视化、文件处理等任务。
工程价值:弥补了LLM在计算、数据处理方面的不足,让智能体能够处理需要复杂运算、批量数据处理、文件操作的任务,拓展了智能体的应用边界。
使用场景:数据计算(如统计分析、公式运算)、数据可视化(如生成图表、报表)、文件处理(如读取、编辑Excel、Word文件)、简单的代码调试。
11. Retrieval Agent(检索型架构)
核心定义:工具型智能体的“检索专项架构”,核心是“检索+生成”,通过向量数据库检索相关知识,将检索到的上下文信息输入LLM,生成准确的输出,是RAG系统的核心架构,解决LLM“知识过时、知识有限”的问题。
结构详解:核心是“检索→上下文注入→生成”,结构为:Query(用户查询)→ Vector DB(向量数据库)→ Context(上下文)→ LLM → Output。
核心逻辑:
•用户提出查询需求(Query),系统将Query转化为向量(Embedding)。
•向量数据库(Vector DB)根据向量相似度,检索出与Query相关的知识片段(Context,如企业文档、行业资料、历史对话)。
•将检索到的Context与Query一同输入LLM,LLM基于Context生成准确、贴合需求的输出,避免依赖自身过时的知识库。
核心价值:是RAG(检索增强生成)系统的核心架构,让智能体能够快速检索海量知识,实现“知识实时更新”“精准匹配”,解决了LLM知识库固定、无法实时更新的问题。
使用场景:企业知识库咨询(如员工查询内部文档、客户查询产品手册)、行业知识检索(如律师查询法规、医生查询病例)、历史对话回溯(如智能助理回忆之前的交互内容)。
四、多智能体系统(复杂协同)
核心定位:当单一智能体无法处理复杂的、多领域的任务时,通过多个智能体协同工作,实现“分工合作、优势互补”,模拟人类团队的协作模式,是智能体从“单一能力”向“复杂系统”演进的关键,适合企业级复杂场景。
12. Multi-Agent Collaboration(协同型多智能体)
核心定义:多个智能体之间通过消息通信,相互协作、分工配合,共同完成一个复杂任务,每个智能体有自己的核心能力,无明确的层级关系,是最基础的多智能体架构。
结构详解:多个智能体之间双向通信、协同工作,结构为:Agent A ↔ Agent B ↔ Agent C(箭头表示消息通信)。
核心模式:
•角色分工:每个智能体负责特定领域的任务(如Agent A负责数据检索,Agent B负责数据分析,Agent C负责报告生成)。
•消息通信:智能体之间通过统一的消息机制,传递任务信息、执行结果(如Agent A检索到数据后,将数据传递给Agent B进行分析;Agent B分析完成后,将结果传递给Agent C生成报告)。
代表案例:AutoGen——微软推出的多智能体框架,支持多个智能体协同工作,通过对话机制实现任务分工和结果传递,可快速搭建多智能体系统。
工程价值:将复杂任务拆解为多个简单子任务,由不同智能体分别完成,提升任务执行效率和准确性,适合多领域、多步骤的复杂任务。
使用场景:复杂报告生成(如市场分析报告,需检索、分析、撰写、排版多个环节)、项目管理(如多个智能体分别负责需求对接、开发、测试)、多领域咨询(如企业战略咨询,需财务、市场、技术多个领域的智能体协同)。
13. Role-based Agent(角色型多智能体)
核心定义:多智能体协同的“角色化版本”,为每个智能体分配明确的“人类角色”,每个角色有固定的职责、行为模式和沟通方式,模拟人类团队的角色分工,提升协同的规范性和高效性。
角色示例:模拟一个项目团队,为智能体分配不同角色:
•PM(产品经理):负责需求分析、任务规划,协调其他智能体的工作。
•Dev(开发工程师):负责代码编写、技术实现。
•QA(测试工程师):负责代码测试、问题排查。
代表风格:CrewAI——专注于角色型多智能体的框架,支持为每个智能体定义角色、目标、职责,通过角色分工实现高效协同,适合模拟人类团队的工作模式。
核心优势:角色明确、职责清晰,避免多智能体之间的分工混乱,沟通效率更高,更贴近人类的工作协同模式,易于调试和优化。
使用场景:模拟团队工作的场景(如产品开发、内容创作、咨询服务)、需要明确角色分工的复杂任务(如大型活动策划、企业培训方案制定)。
14. Hierarchical Agent(分层控制多智能体)
核心定义:多智能体系统的“层级化架构”,分为“管理智能体”和“工作智能体”,形成自上而下的控制体系,管理智能体负责规划、协调,工作智能体负责具体执行,是企业级多智能体架构的核心。
结构详解:层级分明,管理智能体统筹全局,工作智能体执行具体任务,结构为:
•Manager Agent(管理智能体):顶层控制,负责接收用户需求、拆解任务、分配任务给工作智能体、监控任务执行进度、协调解决执行过程中的问题。
•Worker Agents(工作智能体):底层执行,每个工作智能体负责特定的子任务(如数据检索、代码编写、报告生成),接收管理智能体的指令,执行后反馈结果。
核心优势:结构清晰、可控性强,管理智能体统筹全局,避免工作智能体之间的混乱,适合大规模、复杂的多智能体系统,易于扩展和维护。
工程价值:适合企业级应用,能够支撑大规模、多任务的协同执行,是多智能体系统从“小型协同”向“企业级落地”的关键架构。
使用场景:企业级自动化办公(如集团层面的报表汇总、多部门任务协同)、大规模数据处理(如多区域数据采集、分析、汇总)、复杂项目管控(如大型工程的进度管理、资源协调)。
15. Swarm Agent(群体智能多智能体)
核心定义:多智能体系统的“无中心架构”,没有明确的管理智能体,多个智能体之间通过自组织、自协同的方式,完成复杂任务,类似蚁群、蜂群的群体行为,每个智能体都是平等的,自主决策、相互配合。
核心特点:
•无中心:没有顶层管理智能体,每个智能体都有自主决策能力,根据环境和任务需求,自主调整行为。
•自组织:智能体之间通过简单的规则,自主形成协同模式,无需人工干预(如“谁空闲,谁接收新任务”)。
•容错性强:单个智能体出现故障,不影响整体任务的执行,其他智能体可自动补位。
类比理解:类似蚁群算法——无数蚂蚁没有明确的“领导者”,但通过简单的信息传递,能够协同完成筑巢、觅食等复杂任务,每个蚂蚁都是群体的一部分,自主配合。
工程价值:容错性强、可扩展性高,适合大规模、分布式的任务场景,无需复杂的管理机制,降低系统维护成本。
使用场景:大规模数据采集(如多节点网页爬取)、分布式计算(如多设备协同处理复杂数据)、容错性要求高的任务(如应急响应、分布式监控)。
五、操作系统级 Agent(前沿层)
核心定位:智能体的“最高形态”,将智能体与操作系统结合,让智能体具备“系统级”的能力,能够管理多个智能体、工具、记忆,实现“智能体即进程、工具即系统调用”,是未来智能体的发展趋势,目前处于前沿探索阶段。
16. Agent with Memory Layers(多层记忆架构)
核心定义:突破传统“单一记忆”的局限,构建多层级的记忆体系,模拟人类的记忆结构(感知、短期、长期、情感、人格),让智能体具备“人格化”和“情感化”的能力,不再是“冰冷的工具”,类似“AI人格系统”。
结构详解:从底层到顶层,分为6个记忆层,层层递进,结构为:
•感知层:接收外部输入(用户对话、环境信息),进行初步识别和提取,是记忆的“入口”。
•短期记忆:存储当前会话的交互信息,用于上下文衔接,类似人类的“工作记忆”。
•长期记忆:存储长期知识、历史交互、用户偏好,通过向量库等技术持久化存储,类似人类的“长期记忆”。
•情感层:记录用户的情感倾向(如开心、生气、焦虑),并根据情感调整输出语气和内容,实现情感共鸣。
•人格层:定义智能体的人格特质(如温柔、专业、幽默),所有输出都贴合人格设定,让智能体有“独特的性格”。
•决策层:结合以上所有记忆层的信息,进行决策,决定下一步的行为(如“用户现在生气,需先安抚,再解决问题”)。
核心价值:让智能体从“功能性工具”向“人格化伙伴”演进,提升用户交互体验,适合需要长期陪伴、情感互动的场景,是未来AI助理的核心架构。
使用场景:人格化AI助理(如私人助手、情感陪伴机器人)、定制化服务(如专属顾问,具备固定人格和长期记忆)、教育陪伴(如AI家教,贴合学生性格)。
17. Agent OS(智能体操作系统)
核心定义:将智能体纳入操作系统的体系,构建“智能体操作系统”,让智能体成为操作系统中的“进程”,工具成为“系统调用”,记忆成为“文件系统”,实现对多个智能体、工具、记忆的统一管理和调度,是下一代智能体的核心趋势。
核心目标:打破单个智能体的局限,构建一个“智能体生态”,实现:
•Agent = 进程:每个智能体都是操作系统中的一个“进程”,可独立运行,也可协同工作,由操作系统统一调度。
•Tool = 系统调用:各类工具(API、数据库、代码环境)成为操作系统的“系统调用”,所有智能体都可统一调用,无需重复集成。
•Memory = 文件系统:所有智能体的记忆(短期、长期、情感)都存储在操作系统的“文件系统”中,可共享、可检索、可持久化。
代表趋势:目前处于前沿探索阶段,相关框架和技术正在快速发展,如LangGraph(基于图结构的智能体编排框架,可实现多智能体、多工具的协同调度)、OpenClaw(专注于Agent OS的开源项目)。
工程价值:构建智能体的“基础设施”,降低多智能体、多工具的集成成本,实现智能体的规模化、标准化部署,是未来企业级智能体生态的核心。
使用场景:大规模智能体生态(如企业内部多个智能体协同工作)、定制化智能体开发(基于OS快速搭建专属智能体)、未来的AI原生应用(如智能办公系统、智能城市管控)。
总结与演进逻辑
1. 架构演进本质
智能体的演进核心是“能力叠加”,本质公式为:Agent = LLM + Memory + Tool + Planning + Collaboration,从基础的LLM单体,逐步叠加记忆、工具、规划、协同能力,最终走向系统级架构。
2. 工程分层(落地关键)
企业级智能体落地的核心分层(从底层到顶层):
•L1: Model Layer(多模型路由):管理多个LLM模型,根据任务需求选择合适的模型,提升效率和准确性。
•L2: Tool Layer(MCP / API):统一管理各类工具,提供标准化的调用接口,降低工具集成成本。
•L3: Memory Layer(RAG + KV):构建多层记忆体系,结合RAG和键值存储,实现记忆的高效检索和持久化。
•L4: Agent Layer(单体/多体):根据任务需求,选择单体智能体或多智能体协同,完成具体任务。
•L5: Orchestration(LangGraph):负责智能体、工具、记忆的编排和调度,确保任务高效执行。
3. 下一代趋势(重点方向)
•Agent → “有状态”:从无状态向有状态演进,具备长期记忆和上下文衔接能力。
•多Agent → “组织结构”:从简单协同向结构化、层级化、角色化演进,模拟人类组织架构。
•Memory → “人格化”:从单一记忆向多层记忆、情感记忆、人格记忆演进,实现人格化交互。
•Tool → “系统能力”:从单一工具调用向系统级工具调用演进,实现工具的统一管理和共享。
•最终→ Agent OS:构建智能体操作系统,实现智能体的规模化、标准化、生态化发展。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
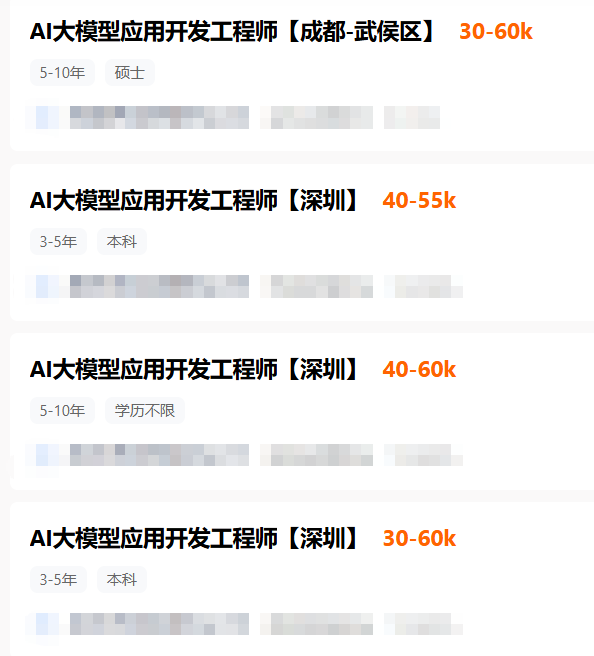
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)