浅谈多模态领域的Transformer
本次跟大家简单聊下,从最早的纯视觉单模态模型卷积神经网络(CNN),到多模态视觉模型 Transformer。
大家想了解单模态模型,建议大家看下我上一篇写的 # 单模态视觉识别模型:从应用到原理的初步解析 。
它们是从单模态模型,通过卷积核进行识别图片,然后一步一步的,用Transformer来替代卷积神经网络,进行视觉识别。
然后到CLIP的横空出世,第一次打通了人类的语言与视觉的间隔,让他们一一对应,一对图文对它的相似度就是最高的。这样的理论为后面的多模态模型产生非常大的影响,也让之后的模型可以做更多的事情。
再到文生图模型,你给一个文字,我生成一个图片,我把你这个文字形成向量,然后通过Transformer Decoder(解码器) 还原成一个相似度高的图片向量,在把图片向量还原成图片。
Transformer Decoder 是自回归的
多模态模型的诞生,并不意味着卷积神经网络的淘汰,世间万事万物都有其规律,存在即合理。
简单说下,当模型做的很小,所属的场景很窄,比如该模型专门识别零件上的缺陷,正常工厂内的流水线上,每生产一万个零件,总会有几个零件存在缺陷。这个时候使用Transformer模型效果就会比较差,还不如用卷积神经网络效果好。
原因是Transformer适合做场景多、通用类型,很多活都能干,而且要做的很大,就特别适合用Transformer。
卷积神经网络就恰恰相反,它的模型小,适合场景窄。
我们在挑选模型时,要根据使用场景,做到性能最大话,这也是AI大模型开发工程师的能力之一。
在文生图领域中大多数使用的是扩散模型,当文生图扩散到文生视频等领域。Transformer可以很好的跟扩散模型做交融,并且可以得到非常牛逼的效果,如果只用扩散模型是达不到这样的效果,后面我们会聊到为什么会这样。
多模态模型:
-
ResNet: Residual neural network,残差学习框架;
-
ViT: Vision Transformer,视觉版的Transformer;
-
Swin Transformer: 视觉版的Transformer;
-
CLIP: Contrastive Language-Image Pre-training,视觉与语言的统一学习;
-
ViLT: Vision-and-Language Transformer
ResNet(残差学习框架)
参考资料: ResNet论文
当你把神经网络层数变得越来越多时,越靠后的层能提取更深度的特征,
在 # 揭秘Transformer架构设计 2(补全版) 的有讲到Tansformer Decoder(解码器) ,Tansformer Decoder(解码器) 内部会进过96轮次解码操作,层度越深,它就能找到更深层次的语义信息,甚至一些句子与句子之间的隐含关系也可以提取出更深的特征信息。
按正常道理来说,神经网络层数越多,它能提取的特征信息也就越深度,你用它来做图像识别,它的准确率应该越高,而且在模型比较小的时候,确实也是这样。所以当时的模型内神经网络就做到了几十到上百层。
这里声明:卷积神经网络的层数与Transformer的层数不是一个概念,卷积神经网络的一层不是相当于Transformer的一层,Transformer的一层有非常多的神经网络。
但是慢慢的,人们发现一个问题,层数越多,效果并没有越来越好。然后他们就做了很多测试,同样的卷积核的逻辑,当我把20层提到56层的时候,56层的表现不如20层,如下图所示:
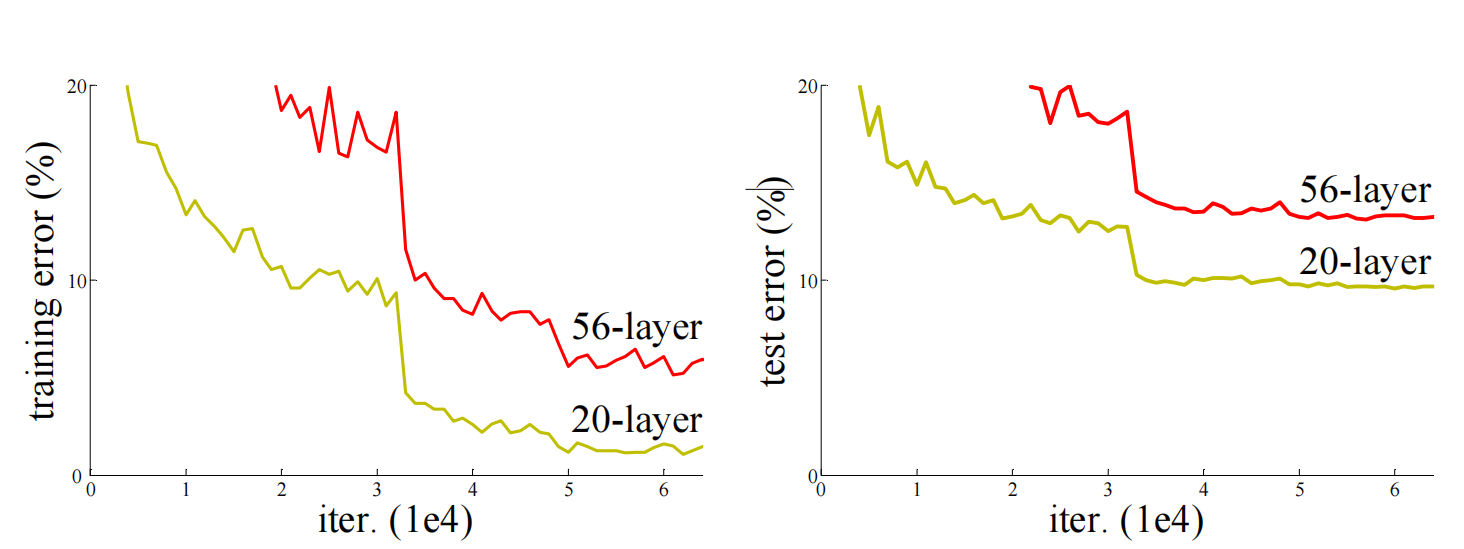
有些物体,我们光看轮廓是知道它是什么东西,有些物体,光看轮廓是不知道它是什么东西,
有时候我们不需要提取那么深度的特征,有时候神经网络层度过深的时候,它会提取出来没有必要的特征信息。
我们以 # 单模态视觉识别模型:从应用到原理的初步解析 的飞机图片案例来说,
在飞机图片上,有草地,草地上的草有些是深绿色、有些是墨绿色,有些是枯色,有些草在一起,有些草有高有低等等。这都属于图片的细节,这些细节并不是我们希望模型去提取出来的,我们不希望模型去把周边的不重要的细节去提取特征,在下面这张图,草地里草长什么样,是否有护栏,护栏长什么样,这些树有多高等等信息,对于整张图片来说,这些都属于噪声,所以当我们网络层数变多时,它没有必要有那么深的层数,因为网络层数变多,会把算力、时间消耗在那么没有必要的噪声上。

这个时候就衍生了ResNet,在视觉任务时,神经网络层数变多,它就能提取更深度的特征,但是我的浅层/纹理特征也很重要。
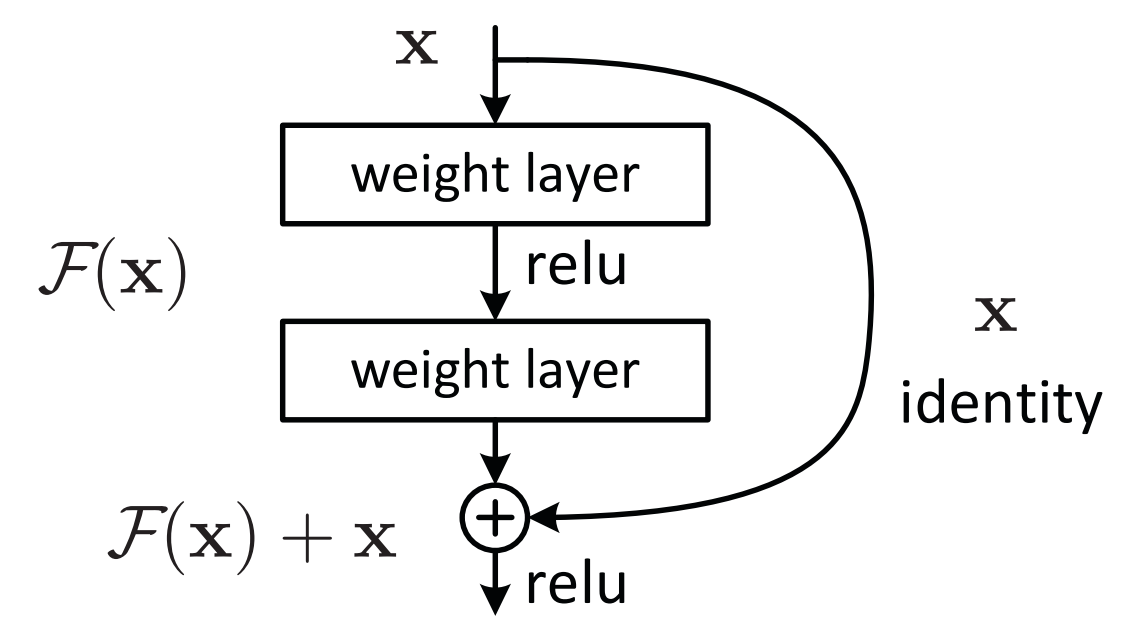
曲线identity也叫残差链接
以Transformer - Decoder(解码器) 来解释:
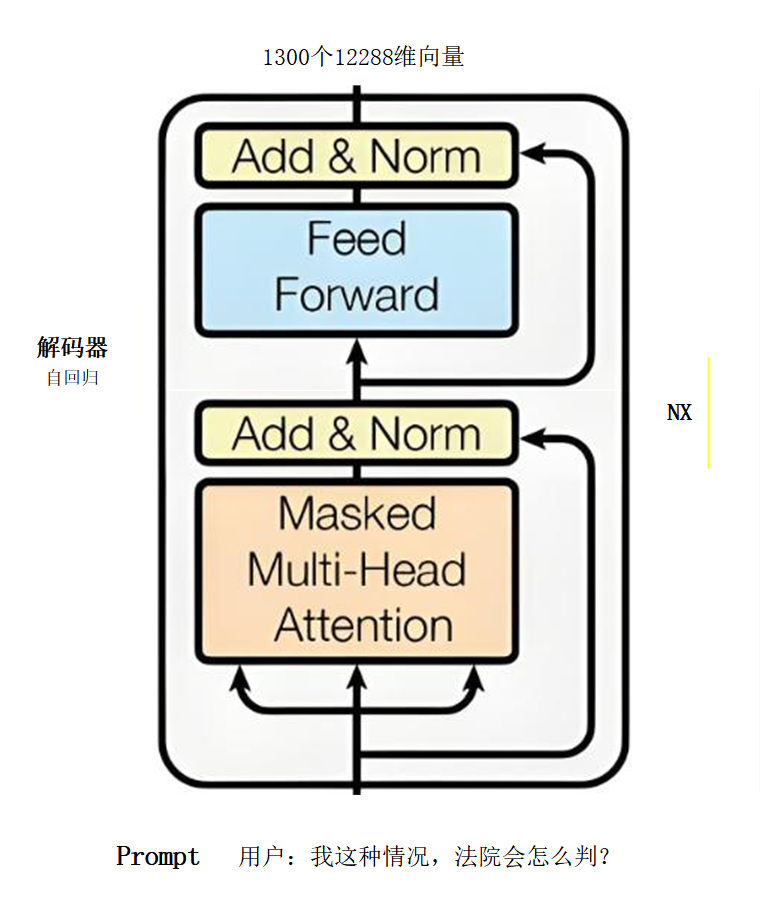
案例:有一段1300字的文案,给Transformer去理解,输出理解后的新1300个数学向量。
1300个12288维数学向量输入到Decoder解码器内,Decoder解码器输出新1300个12288维向量。
这里面每个12288维数学向量都做了特征提取以及信息聚合,如果把Decoder里面做的工作叫做F(x)
你输入一个X(1300个12288维数学向量)过来,我对你做了F(Decoder解码器)计算,然后输出F(x)(新1300个12288维向量),
输入的X与输出的F(x)不一样,就像Transformer - Decoder (解码器) ,输入的1300个12288维数学向量与输出的新1300个12288维数学向量是不一样
这个链接线的意思是,我把X直接传送到输出端,不经过F计算,在输出端会进行计算F(x) + X。
再用Transformer - Decoder 解码器来看,输入1300个12288维数学向量,经过Decoder解码器,得到新的1300个12288维向量,然后把新的向量 + 输入的向量:
X 输入的向量:[a1, a2, a3, …, a1299]
F(x)新的向量:[b1, b2, b3,…, b1299]
F(x) + X输出的向量:[a1 + b1, a2 + b2, a3 + b3, …, a1299 + b1299]
为什么要这样做?
你输入X向量进来,经过一系列的计算,在输出端有F(x),然后X向量也通过identity曲线把传送到输出端,输出端就等于F(x) + X,这样的好处有2个:
-
如果没有identity曲线把X向量传送到输出端,输出端只有F(x) ,那么经过多层神经网络处理后,图片的纹理信息就会丢失,但是通过F(x) + X的话,每次输出都会把X向量带上,它的纹理信息就不会丢失,越深层的卷积层,处理的都是结构和形状信息,越浅层,它处理的都是纹理与颜色信息,所以这样做到信息不丢。
-
当神经网络较深时,担心神经网络没事干,它会对一些噪声信息进行提取特征,层数越多,累加的噪声信息也越多,对最后的向量有很大的影响。但是有了这个结构后,你的F(x) 计算可以把这个概率趋近于0,它只会把X向量传递给下一轮次。在神经网络不添乱的情况下,F(x) = 0的话,我也可以把原始信息X向量向下传导。
如下图所示,同样是34层网络,左边不加任何的残差链接,右边是每一层都加了残差链接:
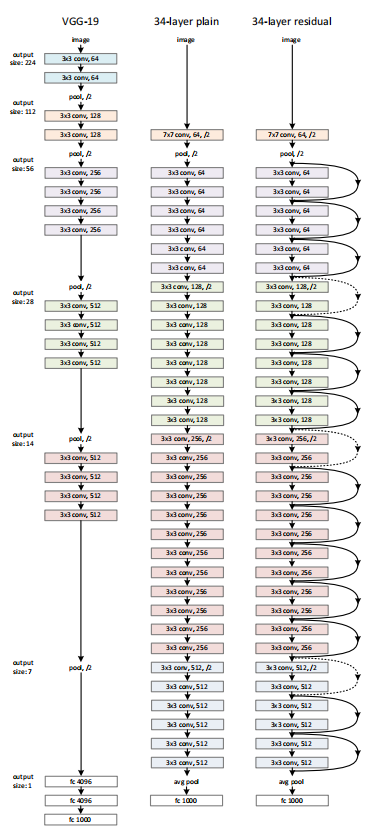
对于右边来说,右边有机会把所有的神经网络都跳跃,也可以全部不跳过,或者只跳过部分,哪些层在我整个过程当中扮演的是重点,哪些层在当前影响会轻点,完全可以在模型训练过程确定,对于整个神经网络来说都是可调配的。
对于左边来说,每层神经网络都要先卷积,再池化,而且必须串行执行,一溜串的计算下来,你的特征图势必会越来越小,你的特征值就必须要越来越长,而且特征值越来越长、特征图越来越小的情况下,你的每一层只能从上一层提取特征,这样就会导致你的细节、纹理的信息会越来越被折损,越来越被抹杀掉,越来越靠近下一个阶层,甚至到最下面的阶层时,可能你的细节都被抹杀没了。
还是以Transformer - Decoder 解码器来解释:
1300个12288维数学向量 通过Decoder解码器,到第49层的时候,发现信息量过多,提取的特征是无用或者是噪声,导致总误差变大,这个时候就会调整Wq,Wk,Wv的参数是0,让这一层不做任何事情,避免影响总误差,1300个12288维的数学向量怎么进来的,就怎么出去,这也是残差链接的作用,进行调控神经网络,避免神经网络层数过多,导致效果不如神经网络层次少的好。
不加任何残差链接的情况下,34层的神经网络比18层的神经网络的错误率还高,训练出来的模型进行识别图片的错误率,如下图所示:
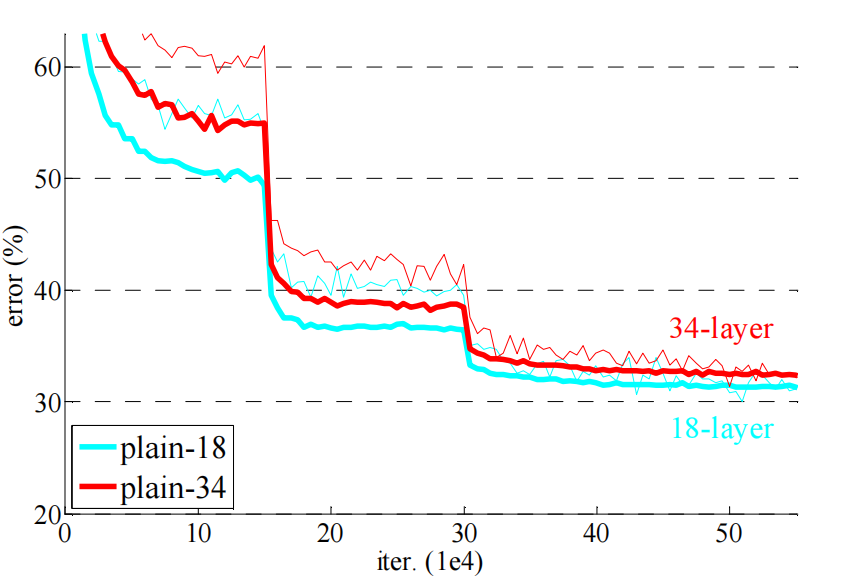
加残差链接的情况下,34层的错误率就是低于18层,如下图所示:
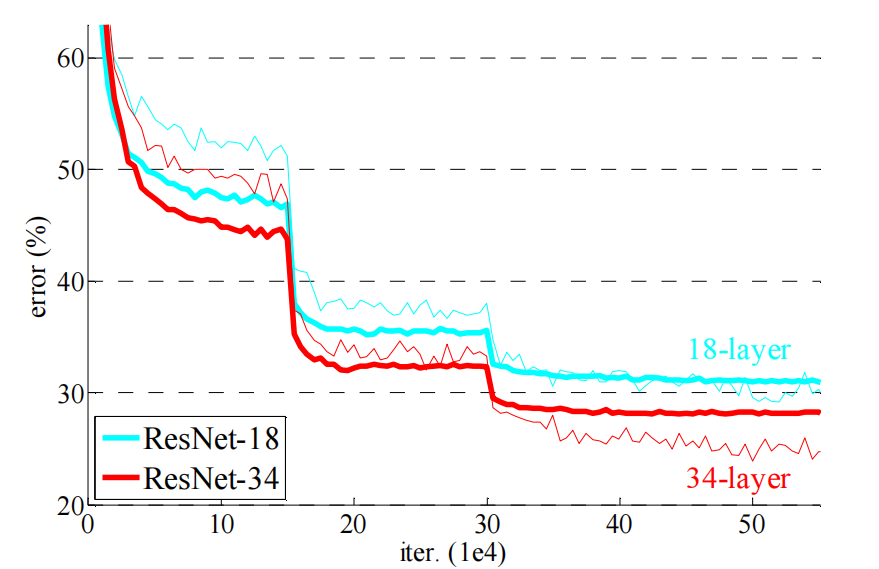
有了ResNet后,神经网络才开始爆发性的成长,能做到几百到上千层。
ResNet是在卷积神经网络后面发明出来的,它是让卷积神经网络在视觉识别这件事情上做到了非常高的识别正确率。
[ResNet论文]([1512.03385] Deep Residual Learning for Image Recognition) 这个论文最大的贡献就是残差链接,它让整个神经网络变得越来越深,并且进化到了深度神经网络。
比如一个10分钟的视频,并且有问答文案,模型要进行回答。
首先会用一个维度特别高的数学向量容纳这10分钟的特征信息、并且进行信息聚合,这是需要一个深度神经网络,里面的层数比较多,要不然很难提取10分钟的视频,10分钟的视频信息特征比较多,因为有了ResNet,使神经网络的层级没有了瓶颈。
ResNet论文的出现是2015年,在Transformer论文是2017年发出的早好几年。
Transformer - Decoder 是抄了卷积神经网络的多头卷积核,转换为多头,然后拿了ResNet的残差链接,进行组合创新。
ViT(Vision Transformer)
参考资料:ViT论文
ViT是视觉版的Transformer,架构图:
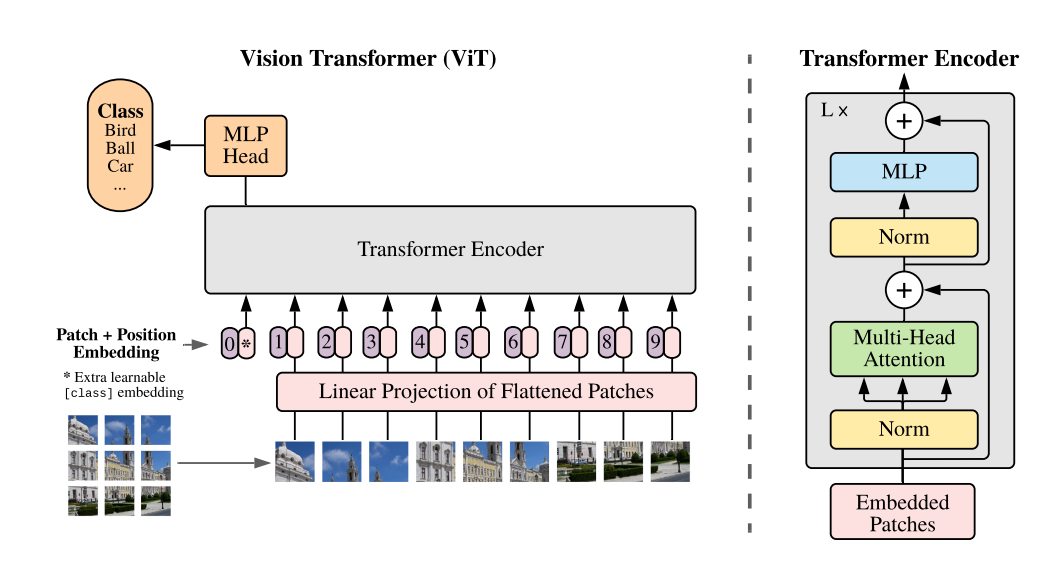
在ViT内部使用了Transformer Encoder(编码器),它设定的场景比较简单,只做最简单的图片识别。
因为Transformer Encoder(编码器) 比较适合做分析、理解工作,Transformer Decoder(解码器) 比较适合做生成,所以ViT内部使用了Transformer Encoder(编码器)。
ViT设定的场景比较简单,只做最简单的图片识别。
虽然卷积神经网络(CNN) 比较适合做图片与视频的识别,但是我只想用Transformer来替代卷积神经网络(CNN),如果能成功的话,未来是不是就有可能形成大一统的多模态模型架构,这也是这个论文的思路。
这个ViT有一个新概念Patch,与大语言模型(LLM) 的Token的概念类似。
把图片切成9个小方块,每个小方块就是一个Patch:

Token是有总数的,比如10万个、20万个,是有字典的,并且可穷举。
但Patch不同,它是任何一个图片都可以切成小方格,每个小方格都是一个Patch,所以Patch不能被穷举,也没有定数。
Transformer 只知道怎么处理序列数据,所以就要把9个小方块摆成一排。
每个Patch就是一张小图片,每个图片里面都有像素,每个像素都是0 ~ 255的数值,每个图片都可以转换成向量,比如 16 * 16 像素的图片,就等于 256个数值,每个数值都是 0 ~ 255的数值,相当于256维向量,就等于每个Patch可以转换为一个256维的数学向量。
每个256维的数学向量基于Linear线性层做一个处理,就会得到一个新的向量。
Linear Projection of Flattened Patches类似Transformer Encoder(编码器) ,9个Patch经过Linear线性层输出为9个新向量,并且每个新向量都有位置编码Position。
然后让它做图片识别任务,就要在向量集最前面加个 “0 * ” 向量 ,专门用来做抽取,本来有9个向量,加上抽取向量,就是10个向量。
这10个向量输入到Transformer - Encoder(编码器) 进行特征提取、信息聚合,最后 “0 * ” 向量涵盖整个图片的信息,又因为它的初始不涵盖任何其他信息,具有中立性质,所以把 “0 * ” 向量做为输出口。
然后把 “0 * ” 向量输入到一个线性层,也叫全连接层(MLP Head) 或者叫分类头,输出的向量数据最后再通过softmax归一化,输出类型的概率。
VIT模型有3个版本
- ViT-Base: 基础款,有12层编码器,每层有768维数学向量,有3072个分类头,有12头自注意机制,模型有86M参数。
- ViT-Large: 大尺寸款,有24层编码器,每层有1024维数学向量,有4096个分类头,有16头自注意机制,模型有307M参数。
- ViT-Huge: 超大尺寸款,有32层编码器,每层有1280维数学向量,有5120个分类头,有16头自注意机制,模型有632M参数。
ST(Swin Transformer)
参考资料:ST论文
ST是在ViT上做了优化,也属于视觉版的Transformer。
ST的基于ViT模型改进:
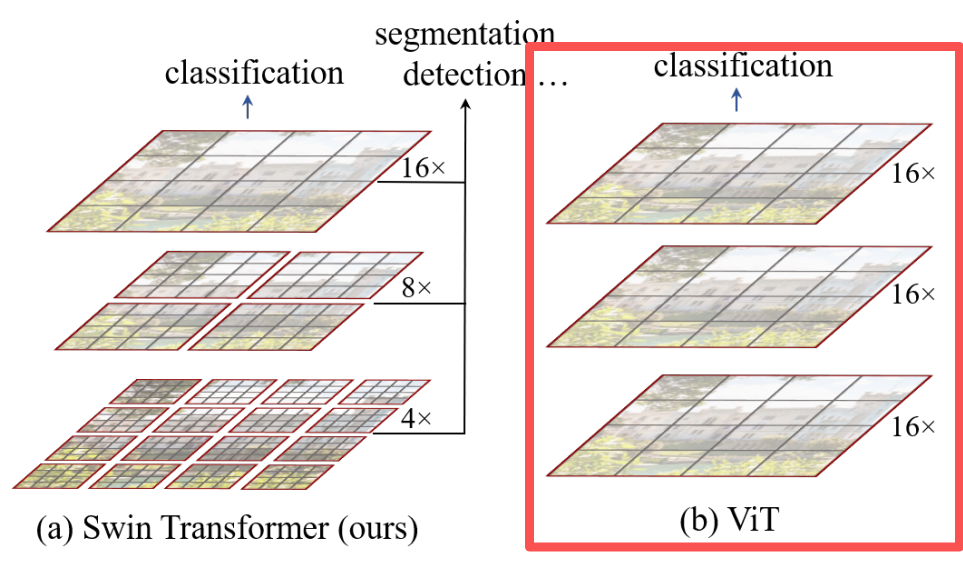
ViT是把每个图片都切成若干个小方格,每个小方格都是一个向量,每一个小方格都会做多头自注意力机制,并且都会进行相关度系数计算。
视觉任务与文字任务是不一样的,文字任务,哪怕你有一万个字,你最开始的一个段落讲的一件事情和最后段落讲的一件事情可能都会有相关性。
但是图片不一样,图片里出现的东西,都是物理世界客观存在的东西,物理世界是有一定客观规律的,比如一个人站在图片里,人脑在左上角,手在右上角,人的肚子在左下角,这样的情况是不可能出现的。这也叫刚性知识。在物理世界里物体都是具有刚性属性的,这样刚性属性就注定着它是有连接的,极少有物体,一个物体的某部分在左上角,另一个部分在右上角。
基于刚性属性,可以得到这样的结论:2个距离比较远的Pacth,它们的相关度系数最低,模型无需去进行相关计算,避免资源的浪费。
简而言之,这2个Patch不需要做任何的信息交换,或者是信息聚合。
ST(Swin Transformer) 只让红色方格内的小灰色方格进行自注意力机制操作,计算相关度系数与信息聚合。然后到达下一轮时,红色方格会进行重新拼接组成更大的红色方格,它的自注意力机制也仅在红色方格内,让灰色小方格做相关度系数计算与信息聚合,以此类似,每个轮次都是进行类似的操作,红色方格与红色方格是不会进行交换数据。
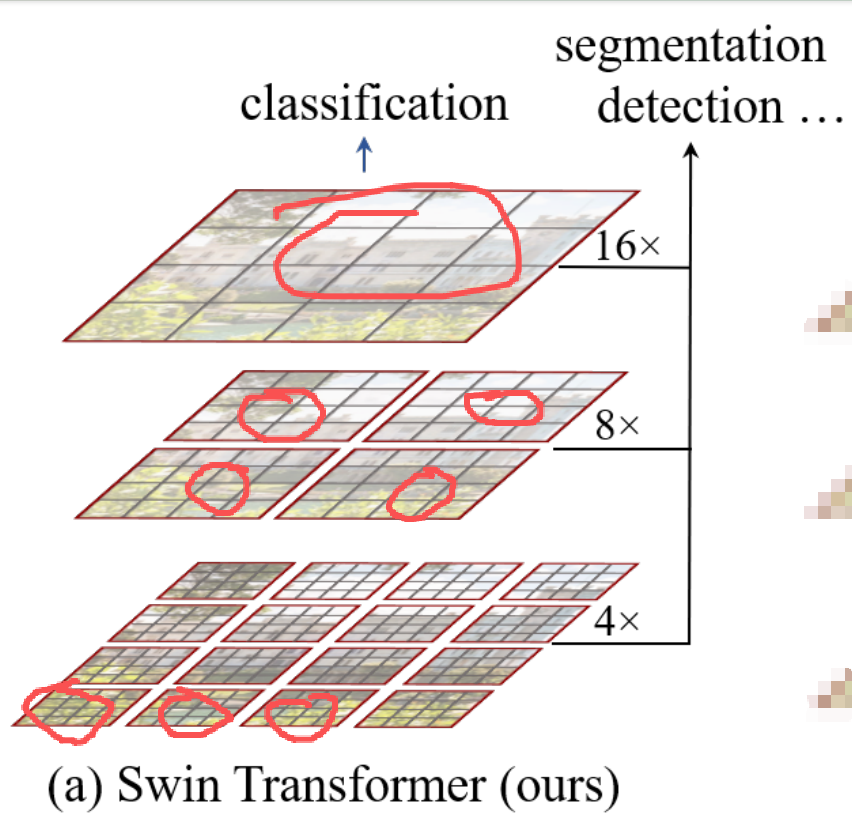
最开始第一层时,红色小方块都很小,ST只允许,灰色的小方格在红色小方格里,通过自注意力机制做聚合和信息交换。
到了第二层,我的红色小方格就变大一点,我就允许灰色小方格,在更大的红色小方格里,通过自注意力机制做信息聚合与信息交换。
然后再到第三层,我把红色小方格变得更大,我允许任一灰色小方格通过自注意力机制做相关度系数计算与信息聚合。
ST模型用这样的方式进行处理,它每一层还是Transformer,但是ST在每一层限制了哪些Patch之间可以做信息聚合和信息交换,而且这样的话,自注意力机制进行计算,它的计算量也会小很多,比如在第一层红色小方格里,灰色小方格也就16个patch,16个patch之间做相关度系数计算,它的计算量就很小,如果按照ViT模型,它就会把左下角的patch与右上角的patch做相关度系数计算,它的计算量就会很大,每2个patch都会计算相关度系数,这个计算量是很大很大了。
ST模型内,颗粒度一层层变大,是为了尺度这件事情。在图片上,一个数学向量代表什么区域,比如第一层一个向量只能代表非常小的一个格子,每一层向量在原图上所代表的区域会越来越大,直到顶层的向量表达的灰色小格子,就很大了。
在视觉领域里面,尺度的概念是很重要的,一个东西离近看就是能看到很多细节,离远的来看,我只能看到一个轮廓,细节的特征与轮廓的特征都很重要,一定不能把尺度的事情给忘记了。
ViT模型做的过于极致,它没有微观与宏观的概念,所以也没有细节与形状的概念,它的概念太过理想化了。人们为了推进多模态模型的大一统,对于整个人工智能领域来说是非常重要的,但是ViT做的太过极致,如果ViT能为了图片稍微做些改变,它的性能一定能得到显著的提升。
而ST(Swin Transformer) 的创新就在于针对Patch进行改变,它的性能得到了极大的提升,如下图所示:
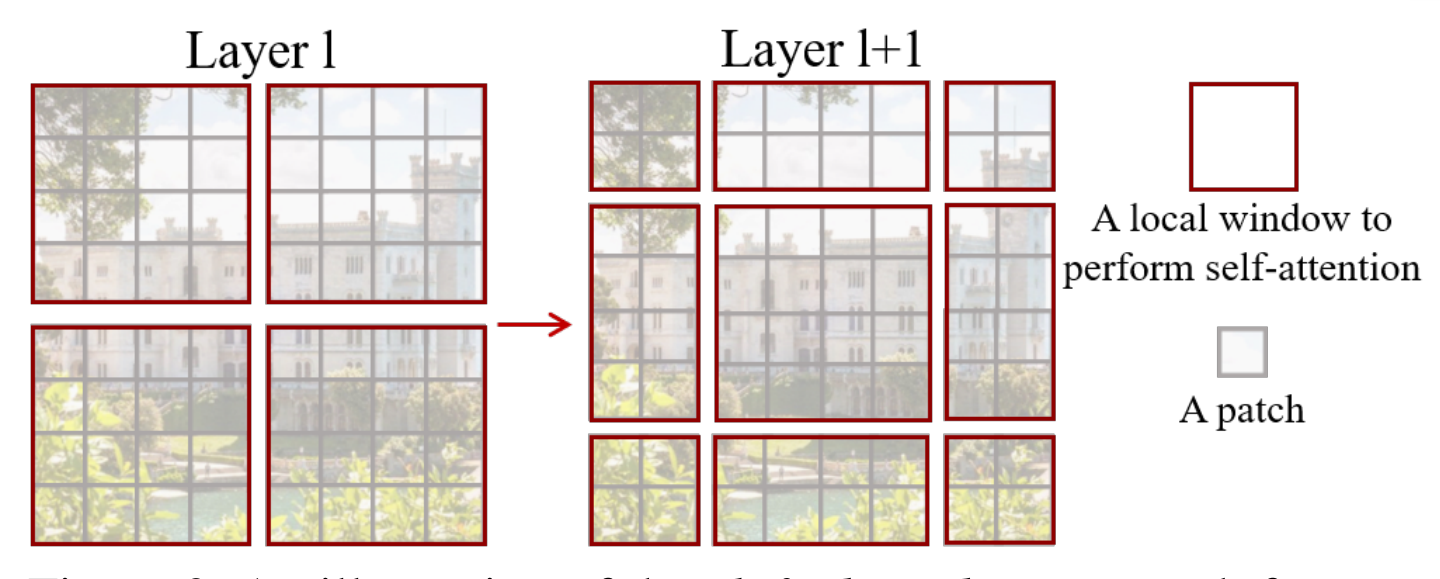
ST模型在每一层的每个灰色的小格子都是一个向量,也能说一个向量可以代表一个小的图片。
在视觉领域里面一个向量代表一个patch,一个patch就是一小格图片。它在同一层Transformer - Encoder(编码器) 里面,其实要做2次自注意力机制的计算,它就把Transformer做了升级,在每一层里面都要做2次自注意力机制的计算。
第一次会让4个大方格内的小灰格子做自注意力机制计算的信息聚合,就是在每个大红色方格里面,让灰色小格子与灰色小格子(patch与patch)做信息聚合和信息交换。
第二次,它会把红色方格打乱顺序,变成Layer 1 + 1的结构,这里也会要求,灰色的小方格只能在各自的红色小方格内做自注意力机制计算,做信息聚合和信息交换,这样的好处是它通过间接的形式,让左上角的patch信息可以与右下角的patch信息做信息聚合与数据交换。
然后通过不断变换的窗口window进行切不同的红色方块,每个红色方块都会在内部,让灰色方块做自注意力机制。
CLIP(视觉与语言的统一学习)
参考资料:CLIP论文
在同一时期,2021年也是多模态爆发的一年,出现了CLIP,它是OpenAI研发的。
跟ViT模型类似,但是在模型上走的是另外一条路径。
因为ViT模型是Google研发的,Google擅长在模型和算法结构上做创新。
OpenAI擅长简单的东西,甚至从别人那里拿东西过来,然后把整个模型做大,用足够大的数据集,通过简单的方式做到比较好的效果,这也是CLIP的背景由来。
当时很多视觉识别的任务,都有很多数据集,我做为一个模型,比如刚刚讲到的ResNet模型,我要去不同的数据集上,重新做一些模型训练,每个模型最后都有个Linear层,我前面的那些卷积层的参数可能会固定不变,但是我去不同的榜单里面,去刷榜单,我就要根据榜单的数据集,做模型训练,调整我的Linear层的分类数据类型。
一般来说,那些视觉识别的任务,它都要把模型的Linear层重新训练下,甚至有些模型是整个模型都会在那个榜单所对应的数据集里面重新训练下。
在当时最有名的榜单ImageNet,ImageNet里面有1400万张照片,里面的标签都是物理世界内真实的标签/ID。
CLIP模型比ViT模型还要创新,它在2021年,第一次直接打通了人类的语言与视觉。
ViT、Swin Transformer模型表现都很不错,但是毕竟还都是单模态的东西,你的模型输入就是一张图片,你的输出就是标签,模型也不直接输出的“狗、猫、车、人”是什么东西,它只给标签,也只知道标签。
Transformer是很强大的,可以做文字的处理,也可以做图片的处理。但是不能说ViT、Swin Transformer模型很强大。
CLIP的强大在于它把非常多的数据集,它利用互联网上的4亿对文字-图片数据进行预训练,实现了零样本图像分类,可以用一段文字或者一句话,去对应一张图片。
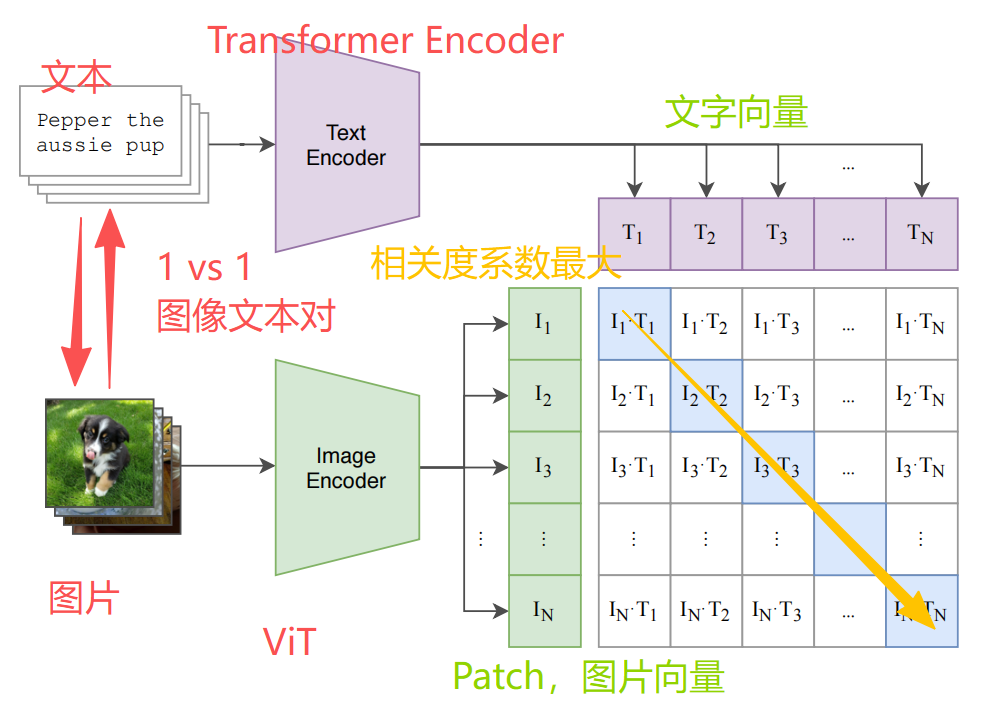
Text Encoder ==> Transformer Encoder
Image Encoder ==> ViT
把对角线的数值相加 - 不在对角线的数据之和 = 这个数值越大越好,它的总误差值就越小,这也是这个模型训练的目的。
对角线的数值一定是最大的,因为它们是文字与图片一一对应的,它们的相关度系数是最高,非对角线的T/I向量数值要尽可能的小,它们的原图与原文字是不对应的,它们的相似度肯定是最低的。
由此可以得出,对角线之和 - 非对角线之和 = 新数值,这个新数值肯定是最大的,如果数值比较小,就说明这个总误差肯定很大,就需要调整模型内的参数。这也叫对比学习,因为有2个模型需要调整。
只要在新数值实在没办法变得更大时,模型训练才会结束。
CLIP模型训练完成后,就会去各大榜单去刷榜。
每次刷榜,都会获取榜单内的测试数据,CLIP模型拿榜单的测试数据进行识别,是比较吃亏的。
因为CLIP模型训练是通过一句话或者一段话做为参数进行训练的。
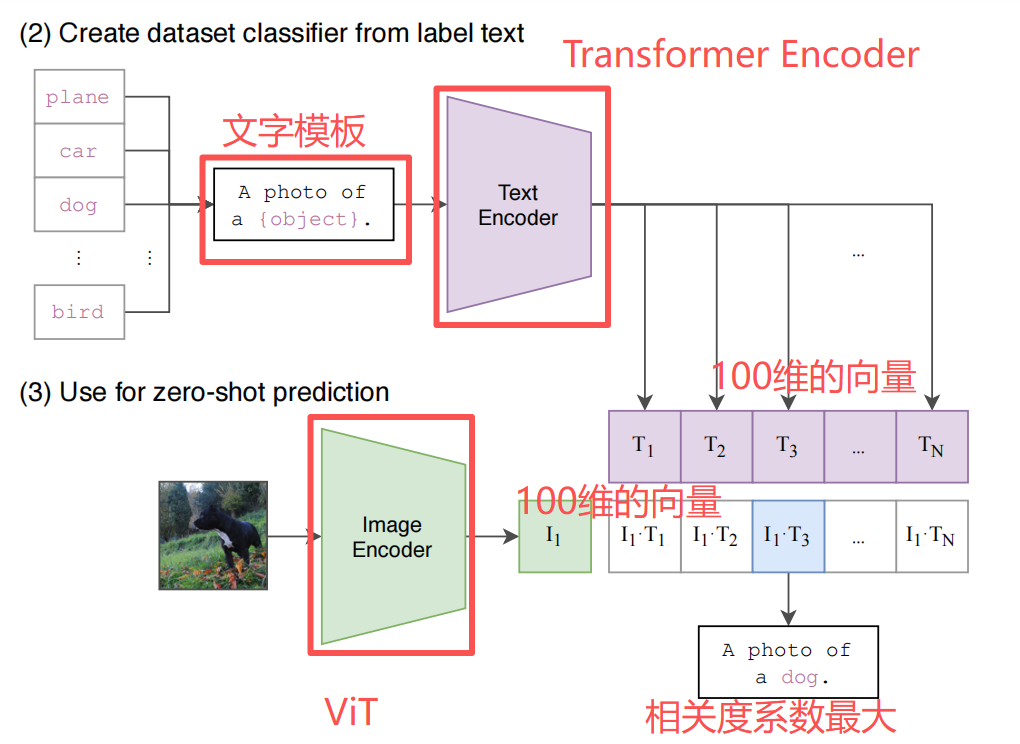
但是CLIP用了一个很巧妙的做法,它用了一个模板话术来套用测试数据的标签,比如 A photo of a {object} ,object里面就是放测试数据的标签。
CLIP模型内就有很多这样的文字模板,直接把标签套进来,就能形成一句话或者一段话。然后通过CLIP模型,输入图片、标签,CLIP模型把标签套到相应文字模板内形成一句话,然后用这句话与图片进行相关度系数计算,最后输出数值最高的标签/图片。
过去的图像识别模型的Linear层都需要做修改的,要提前告诉它有多少类别才能参加训练的。如果Linear层有200个类型,它就要输出200个概率,所以导致没有任何一个模型在换另外一个数据集之后,类别数据会自动改变的。
但是CLIP模型做到了,它不需要修改Linear层的类别,它是先把标签通过文字模板变成一句话,然后拿图片与这句话对比相似度就可以了,这也是CLIP模型的强大,第一次打通了人类的文字与图片。
这也对之后的文生图、文生视频做了很好的奠基,并且对之后的多模态模型产生了非常大的影响,之后的多模态模型也很好的借鉴了CLIP模型。
CLIP模型的核心思想:它要像人类一样学习,我们人类小时候学东西,都是语言与物体做对应进行学习。
神经网络本来就是在尽可能的模拟人脑,所以学习方式也要一样。
ViLT(Vision-and-Language Transformer)
参考资料:ViLT论文
ViLT模型是基于CLIP模型与ViT模型理论演变而来。
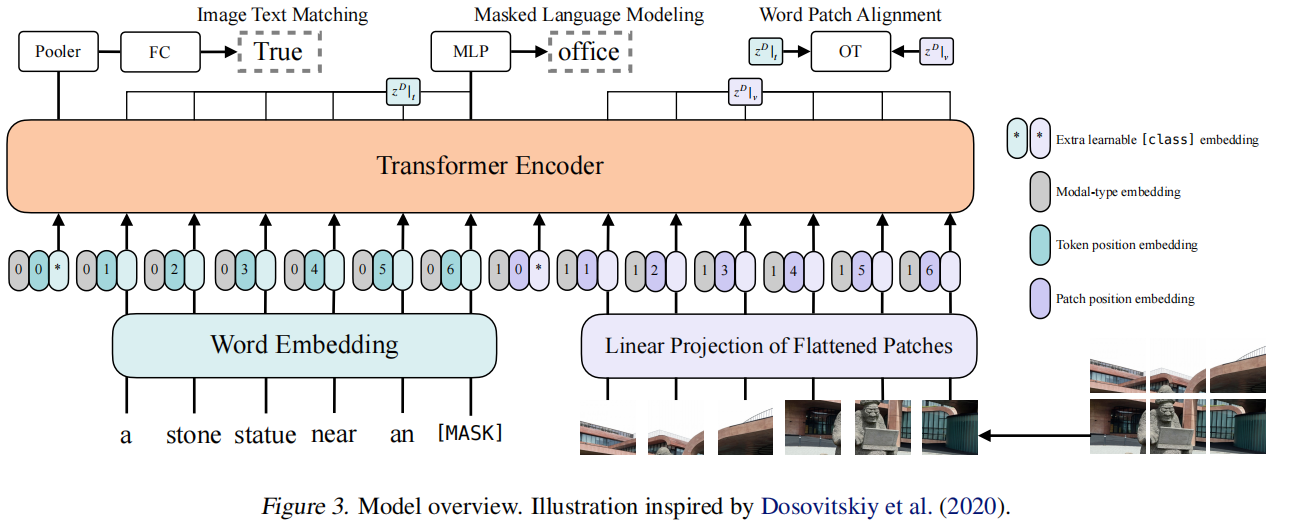
ViLT模型跟ViT模型差不多,它是在ViT模型的基础上,加上文字的组合。文字向量与图片向量通过"1 0 * " 分割符拼接到一起,形成一个长向量,这个长向量再给Transformer Encoder(编码器),最后输出一批数学向量,通过这批数学向量可以识别这句话与图片是不是对应的,或这句话说的是不是图片上的事情,这句话的语义信息是不是在描述图片上的事情。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)