Cursor成为你的项目“透视眼”,会泄露你的代码吗?
引言:当AI开始“阅读”你的代码库
在AI编程助手日益普及的今天,Cursor以其强大的项目级理解能力脱颖而出。但一个核心问题始终萦绕在开发者心头:当我让Cursor分析我的整个项目时,它是否会上传我所有的源代码? 这不仅是隐私问题,更关乎商业机密和知识产权。
今天,我们将深入剖析Cursor背后的技术机制,揭示它如何在保护代码隐私的同时,实现令人惊叹的项目理解能力。
一、核心机制揭秘:智能检索,而非暴力上传
1.1 一个常见的误解
许多开发者认为,当输入“请分析这个10MB项目的架构”时,Cursor会简单粗暴地将整个代码库打包上传。实际上,这种操作在技术上不可行,在设计上不必要,在成本上不经济。
技术限制:目前最强大的AI模型(如GPT-4)的上下文窗口也有限(通常128K-200K Token)。10MB的代码相当于约250万汉字,远超任何模型的单次处理能力。
1.2 Cursor的智能三步法
Cursor采用了一种精妙的“检索增强生成”策略,其核心流程如下:
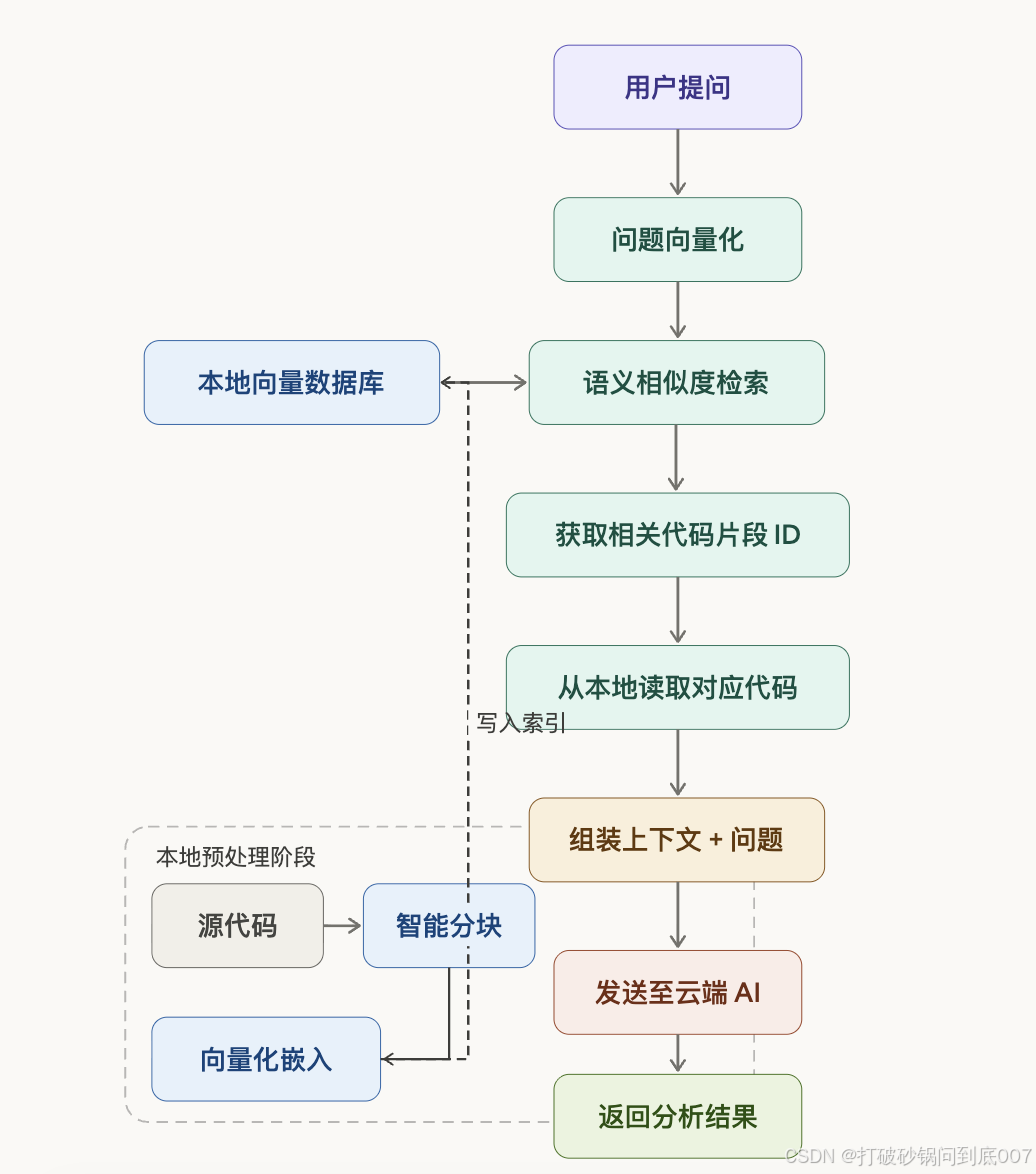
步骤分解:
-
本地索引建立:首次打开项目时,Cursor在本地对代码进行智能分析和索引
-
语义检索:将用户问题转换为向量,在本地向量库中寻找最相关的代码片段
-
精准上传:仅上传检索到的相关片段,而非整个代码库
二、技术架构深度剖析
2.1 本地分析引擎的四大组件
Cursor的客户端内置了完整的分析引擎,其技术架构推测如下:
|
组件 |
可能实现 |
核心功能 |
|---|---|---|
|
代码解析器 |
Tree-sitter |
语法分析,智能分块 |
|
嵌入模型 |
本地轻量模型 + 云端重型模型 |
文本到向量转换 |
|
向量数据库 |
SQLite with VSS / Chroma |
向量存储与检索 |
|
索引管理器 |
自定义服务 + Merkle树 |
增量更新,状态管理 |
2.2 智能分块:不只是按行切割
Cursor的分块策略远比你想象的智能。以下是一个简化的示例,展示如何识别代码的逻辑单元:
# 伪代码:基于语法树的智能分块
def intelligent_chunking(code_text, language):
# 使用Tree-sitter解析代码
tree = parser.parse(bytes(code_text, "utf8"))
chunks = []
# 遍历AST,识别逻辑单元
def traverse_node(node):
if node.type in ['function_definition', 'class_definition',
'method_definition', 'module']:
# 提取完整的逻辑单元
start_byte = node.start_byte
end_byte = node.end_byte
chunk = code_text[start_byte:end_byte]
# 添加元数据
chunk_metadata = {
'type': node.type,
'file_path': current_file,
'start_line': node.start_point[0] + 1,
'end_line': node.end_point[0] + 1
}
chunks.append((chunk, chunk_metadata))
# 递归遍历子节点
for child in node.children:
traverse_node(child)
traverse_node(tree.root_node)
return chunks2.3 向量化:从代码到语义空间
向量化过程将代码的语义信息编码为高维向量。以下是一个简化的嵌入过程:
# 伪代码:代码向量化流程
def embed_code_chunk(chunk_text, metadata):
# 预处理:清理、标准化
processed_text = preprocess_code(chunk_text)
# 添加上下文信息
context_enriched = f"""
文件路径: {metadata['file_path']}
代码类型: {metadata['type']}
代码内容:
{processed_text}
"""
# 使用嵌入模型生成向量
# 实际中可能使用本地模型或调用云端API
vector = embedding_model.encode(context_enriched)
return {
'vector': vector,
'metadata': metadata,
'content_hash': hash_chunk(chunk_text)
}三、实战演示:Cursor如何分析一个Spring Boot项目
3.1 项目结构示例
假设我们有一个典型的Spring Boot电商项目:
ecommerce-project/
├── src/main/java/com/example/ecommerce/
│ ├── controller/
│ │ ├── OrderController.java
│ │ ├── ProductController.java
│ │ └── UserController.java
│ ├── service/
│ │ ├── OrderService.java
│ │ ├── PaymentService.java
│ │ └── InventoryService.java
│ ├── repository/
│ │ ├── OrderRepository.java
│ │ └── ProductRepository.java
│ └── model/
│ ├── Order.java
│ ├── Product.java
│ └── User.java
├── application.properties
├── pom.xml
└── README.md3.2 用户提问与Cursor的实际处理
用户提问:“请分析这个电商项目的架构设计和核心业务流程”
Cursor的实际处理流程:
-
问题向量化:将问题转换为语义向量
-
本地检索:在向量库中搜索与“架构”、“电商”、“业务流程”相关的代码块
-
结果可能包括:
-
README.md中的项目描述 -
pom.xml中的依赖配置 -
OrderController.java中的REST端点 -
OrderService.java中的业务逻辑 -
application.properties中的配置
-
-
上下文组装:仅上传这些相关文件的关键部分(约占总代码量的15-20%)
-
AI分析:GPT-4基于这些精选上下文进行分析
3.3 实际效果对比
|
分析方式 |
上传数据量 |
响应时间 |
分析质量 |
|---|---|---|---|
|
传统方式(理论上传全部) |
10MB(约250万Token) |
超时/失败 |
无法评估 |
|
Cursor智能检索 |
约1.5MB(约3.7万Token) |
3-5秒 |
精准聚焦架构和业务 |
四、隐私保护与成本控制的精妙平衡
4.1 隐私保护的三重保障
-
代码不离本地:原始源代码始终存储在用户设备
-
向量不可逆:即使向量数据被截获,也无法还原原始代码
-
按需最小化:每次仅上传与问题最相关的片段
4.2 成本优化的双重策略
-
Token消耗大幅降低:从潜在的千万级Token降至万级
-
本地计算分担:向量化、检索等计算在本地完成
五、技术优势与行业启示
5.1 Cursor架构的核心优势
-
可扩展性:项目大小不影响核心检索效率
-
实时性:增量更新确保索引与代码同步
-
多语言支持:基于语法树的解析支持主流编程语言
-
离线能力:本地索引支持基础检索功能
5.2 对AI开发工具的启示
Cursor的成功实践为AI开发工具设计提供了重要参考:
-
混合架构:本地轻量处理 + 云端重型模型的组合
-
隐私优先:在功能与隐私间找到平衡点
-
成本意识:通过智能检索降低API调用成本
-
用户体验:响应迅速,分析精准
六、未来展望:更智能的代码理解
随着技术的发展,我们期待看到:
-
更精准的检索:结合调用图、数据流分析等静态分析技术
-
多模态理解:同时处理代码、文档、图表等多种信息源
-
个性化适配:学习开发者的编码习惯和项目特点
-
主动智能:不仅能回答问题,还能主动发现代码问题
结语
Cursor的代码分析机制展示了AI技术在尊重隐私和控制成本的前提下,如何深度理解复杂系统的可能性。这不仅是技术实现的胜利,更是产品哲学的体现——在强大的AI能力与用户的数据主权之间找到平衡点。
对于开发者而言,理解这些底层机制不仅能帮助我们更有效地使用工具,更能启发我们思考:在AI时代,如何设计既强大又负责任的技术产品?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)