基于深度学习的动物检测识别系统YOLO:开启动物识别新视野
基于深度学习的动物检测识别系统YOLO 技术栈:python,深度学习,卷积神经网络、pytorch、Pycharm 可提供远程调试,报告需要额外收费 摘要:动物检测与识别系统在野生动物保护、生态研究和农业管理等领域具有重要应用 本系统提出了一种基于深度学习YOLO算法的动物检测识别系统,该系统通过PyQt5开发的用户界面(UI)实现,支持本地图片上传识别、实时摄像头识别以及视频流识别功能 系统核心是一个经过优化的YOLOv4模型,它能够高效地在图像或视频帧中定位并识别多种动物 通过构建大规模的动物图像数据集,并结合迁移学习技术,模型能够学习到不同动物的特征表示 用户界面友好,操作简便,用户可以轻松上传图片或视频,或启动摄像头进行实时动物检测 系统在多个动物检测场景中进行了测试,结果显示其具有较高的检测准确率和实时性能 不仅提高了动物检测的自动化和智能化水平,也为相关领域的研究和应用提供了

在野生动物保护、生态研究以及农业管理等诸多领域,动物检测与识别系统都有着举足轻重的地位。今天就来和大家聊聊我基于深度学习YOLO算法打造的动物检测识别系统。
技术栈大揭秘
整个系统构建在一系列强大的技术之上,主要包括Python、深度学习、卷积神经网络、PyTorch以及Pycharm。
Python作为一门简洁高效且拥有丰富库的编程语言,无疑是深度学习项目的绝佳选择。在这个系统里,Python就像粘合剂,将各个功能模块紧密连接在一起。
基于深度学习的动物检测识别系统YOLO 技术栈:python,深度学习,卷积神经网络、pytorch、Pycharm 可提供远程调试,报告需要额外收费 摘要:动物检测与识别系统在野生动物保护、生态研究和农业管理等领域具有重要应用 本系统提出了一种基于深度学习YOLO算法的动物检测识别系统,该系统通过PyQt5开发的用户界面(UI)实现,支持本地图片上传识别、实时摄像头识别以及视频流识别功能 系统核心是一个经过优化的YOLOv4模型,它能够高效地在图像或视频帧中定位并识别多种动物 通过构建大规模的动物图像数据集,并结合迁移学习技术,模型能够学习到不同动物的特征表示 用户界面友好,操作简便,用户可以轻松上传图片或视频,或启动摄像头进行实时动物检测 系统在多个动物检测场景中进行了测试,结果显示其具有较高的检测准确率和实时性能 不仅提高了动物检测的自动化和智能化水平,也为相关领域的研究和应用提供了

深度学习和卷积神经网络是核心驱动力。深度学习能够让模型从海量数据中自动学习特征,而卷积神经网络(CNN)则专门针对图像数据进行处理,通过卷积层、池化层等组件,有效提取图像中的关键信息。比如下面这段简单的CNN代码片段:
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
out = self.conv1(x)
out = self.relu1(out)
out = self.pool1(out)
return out这里定义了一个简单的CNN模型,Conv2d表示二维卷积层,将输入的图像数据从3通道(RGB图像)转换为16通道,kernel_size指定卷积核大小,padding保证卷积前后图像尺寸不变。ReLU作为激活函数,为模型引入非线性,MaxPool2d则进行下采样,减少数据量同时保留关键特征。

PyTorch则是深度学习框架,它提供了动态计算图,使得模型的构建和调试更加灵活。Pycharm作为开发工具,有着强大的代码编辑、调试功能,极大提高了开发效率。
系统功能亮点
- 多样化识别方式
- 本地图片上传识别:用户可以轻松上传本地存储的图片,系统迅速给出图片中动物的识别结果。这部分功能实现主要依靠PyQt5开发的用户界面。PyQt5提供了丰富的UI组件,比如文件选择对话框。以下是简单代码示例:
from PyQt5.QtWidgets import QFileDialog
def open_image():
file_dialog = QFileDialog()
file_path, _ = file_dialog.getOpenFileName(None, "选择图片", "", "图片文件 (*.jpg *.png)")
if file_path:
# 这里添加识别图片的逻辑
pass这段代码创建了一个文件选择对话框,用户选择图片后,获取图片路径,后续就可以在路径基础上进行图片识别。
- 实时摄像头识别:打开摄像头,系统实时捕捉画面并识别其中的动物。在Python中,借助OpenCV库可以方便获取摄像头画面。
import cv2
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
# 这里对frame进行识别处理
cv2.imshow('Camera', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()这段代码打开摄像头,不断读取画面帧,显示在窗口中,当用户按下'q'键时退出。在实际系统中,会在读取帧后加入识别代码。
- 视频流识别:用户上传视频,系统逐帧分析并给出动物识别结果。这和图片识别类似,只是需要按顺序处理视频中的每一帧。
- 核心YOLOv4模型
系统的心脏是经过优化的YOLOv4模型。它能在图像或视频帧中高效定位并识别多种动物。YOLO(You Only Look Once)系列算法以其快速和准确闻名。通过构建大规模动物图像数据集,并运用迁移学习技术,模型能学到不同动物的特征表示。迁移学习简单来说,就是利用在大规模通用图像数据集(如ImageNet)上预训练好的模型参数,来初始化我们的YOLOv4模型,这样模型在训练我们的动物数据集时,可以更快收敛,提高训练效率和识别准确率。
系统测试表现
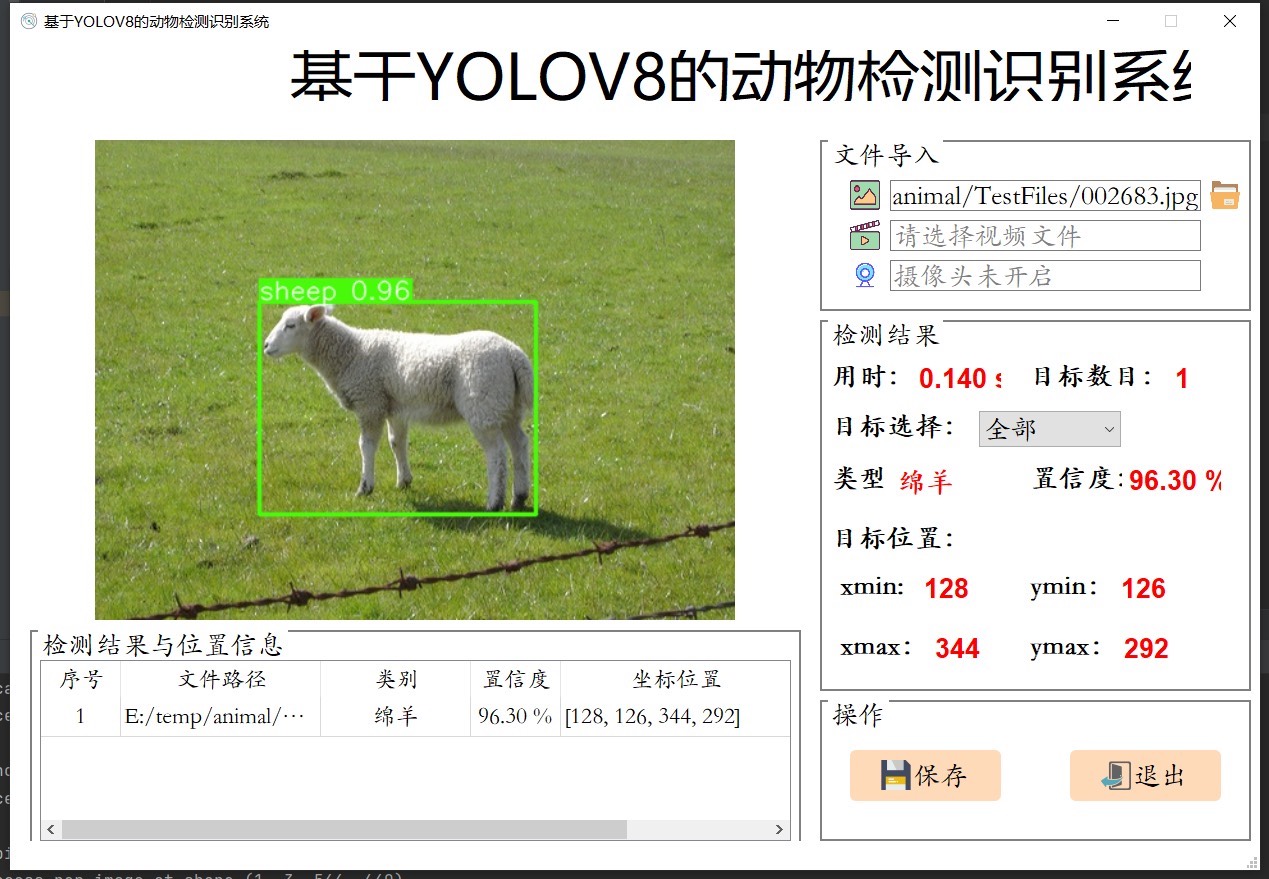
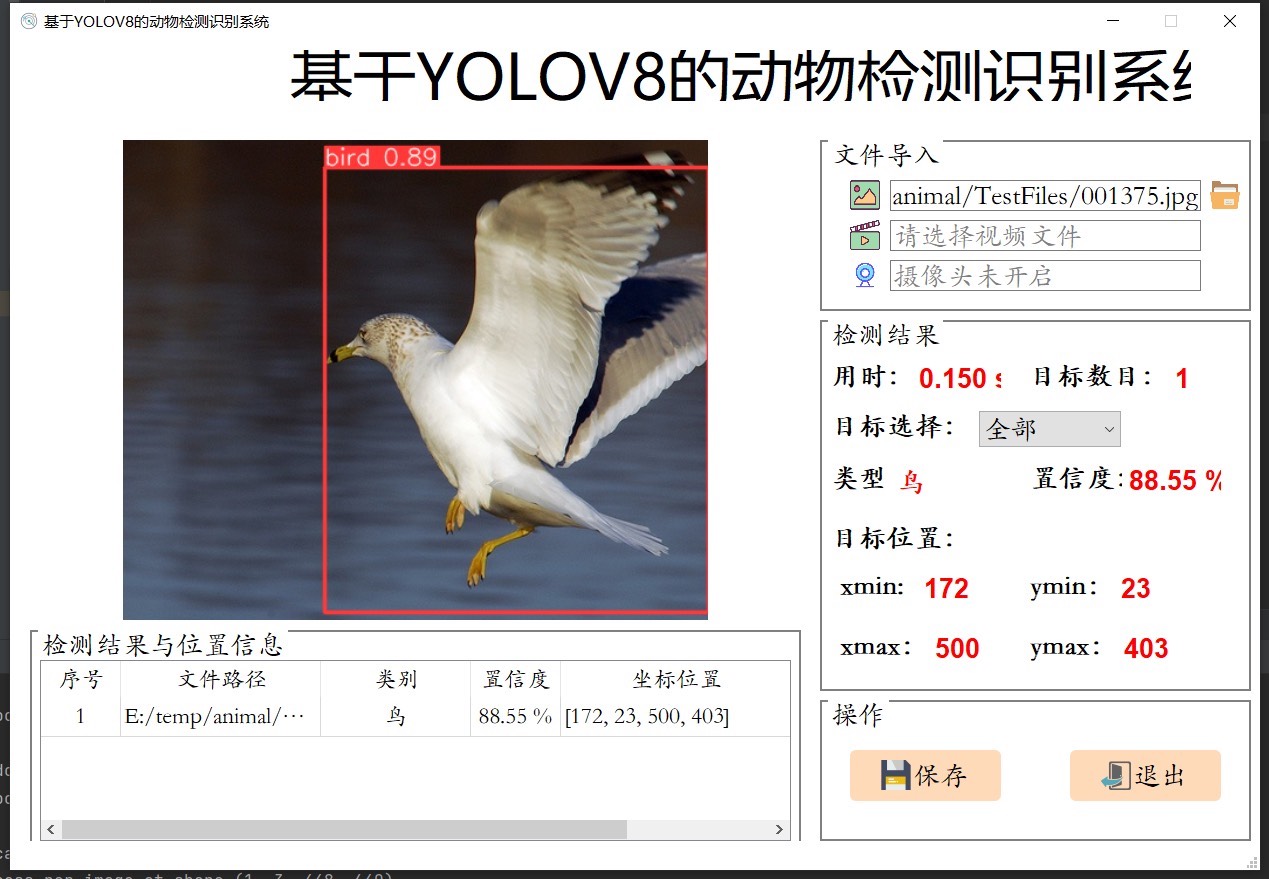
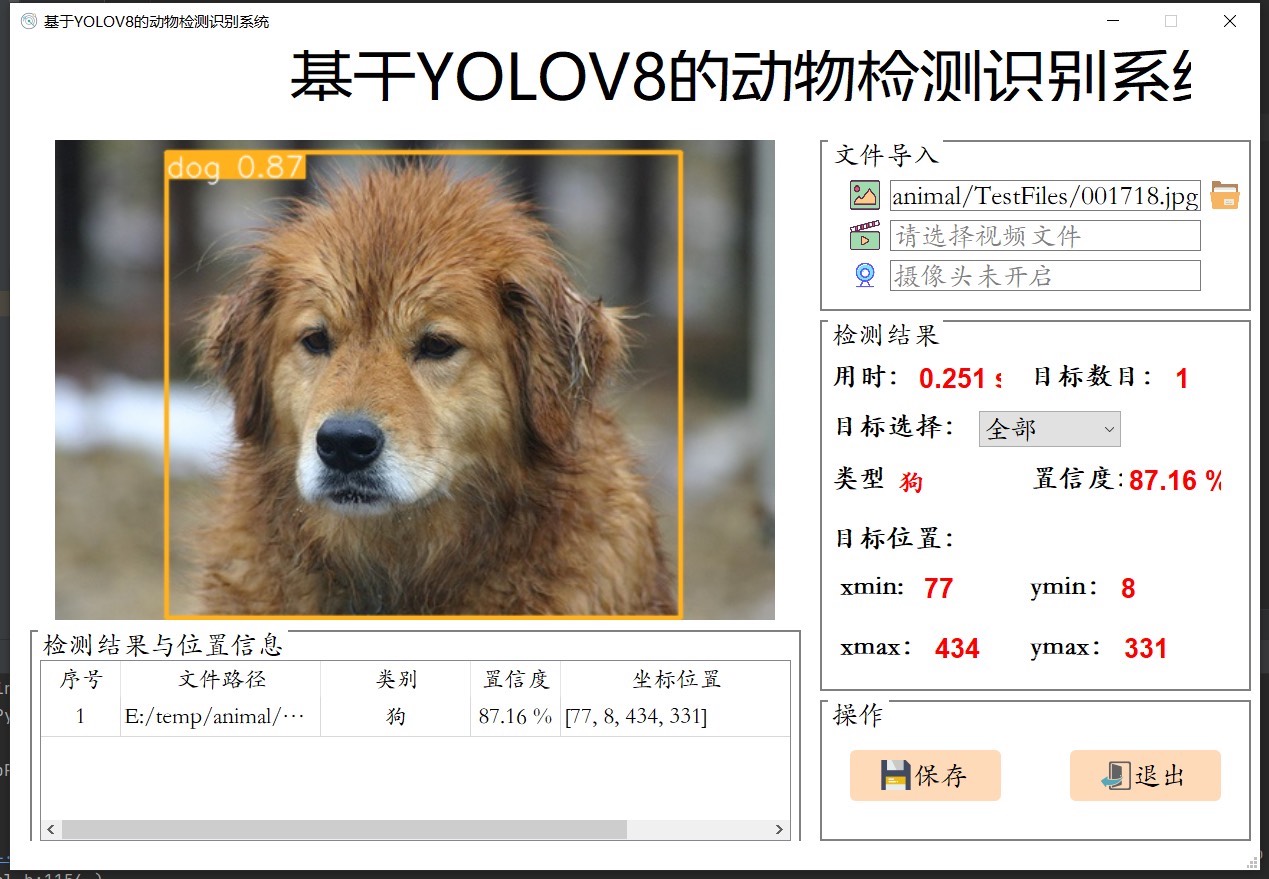
系统在多个动物检测场景下进行了严格测试,结果令人满意。它展现出较高的检测准确率和实时性能。无论是在光线充足的环境,还是较为复杂的自然场景中,都能较为准确地识别出动物。这不仅提升了动物检测的自动化和智能化水平,也为相关领域的研究和应用提供了有力支持。
另外,这里可以提供远程调试服务哦,如果需要相关报告的话,会额外收取一定费用。希望这个基于深度学习YOLO算法的动物检测识别系统,能为动物研究与保护等领域带来更多便利与突破。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)