(论文速读)FluxGen:压缩文本到图像的图像恢复模型
论文题目:Acquire and then Adapt: Squeezing out Text-to-Image Model for Image Restoration(获取然后适应:压缩文本到图像的图像恢复模型)
会议:CVPR2025
摘要:近年来,预训练文本到图像(T2I)模型由于其强大的生成先验被广泛应用于现实世界的图像恢复。然而,控制这些大型模型进行图像恢复通常需要大量的高质量图像和大量的训练计算资源,这不仅成本高,而且对隐私不友好。在本文中,我们发现训练良好的大型T2I模型(即Flux)能够生成与现实世界分布一致的各种高质量图像,提供无限的训练样本来缓解上述问题。具体来说,我们提出了一种用于图像恢复的训练数据构建管道,即FluxGen,它包括无条件图像生成、图像选择和退化图像模拟。一种新型的轻型适配器(FluxIR),具有挤压和激励层,也被精心设计用于控制基于DiT的大型扩散变压器(Diffusion Transformer)的T2I模型,从而可以恢复合理的细节。实验表明,我们提出的方法使Flux模型能够有效地适应现实世界的图像恢复任务,在合成和现实世界的退化数据集上都获得了更好的分数和视觉质量,与目前的方法相比,训练成本仅为8.5%。
Code:https://github.com/chaofengc/ika-pytorch
FluxIR - 用8.5%的成本实现最优图像恢复
引言:图像恢复的新范式
在AI驱动的图像处理领域,如何让模糊、损坏的图像重获新生一直是研究者们追求的目标。最近来自Honor Device Co., Ltd和深圳先进技术大学的研究团队带来了一项突破性工作——FluxIR,这是一种革命性的图像恢复方法,仅用当前最先进方法约8.5%的训练成本,就实现了最优的恢复效果。
这篇发表在CVPR 2025的论文题为《Acquire and then Adapt: Squeezing out Text-to-Image Model for Image Restoration》,提出了"先获取、再适配"的全新思路,巧妙地"榨取"了大型文本到图像模型Flux的能力,为图像恢复任务开辟了一条高效且经济的新路径。
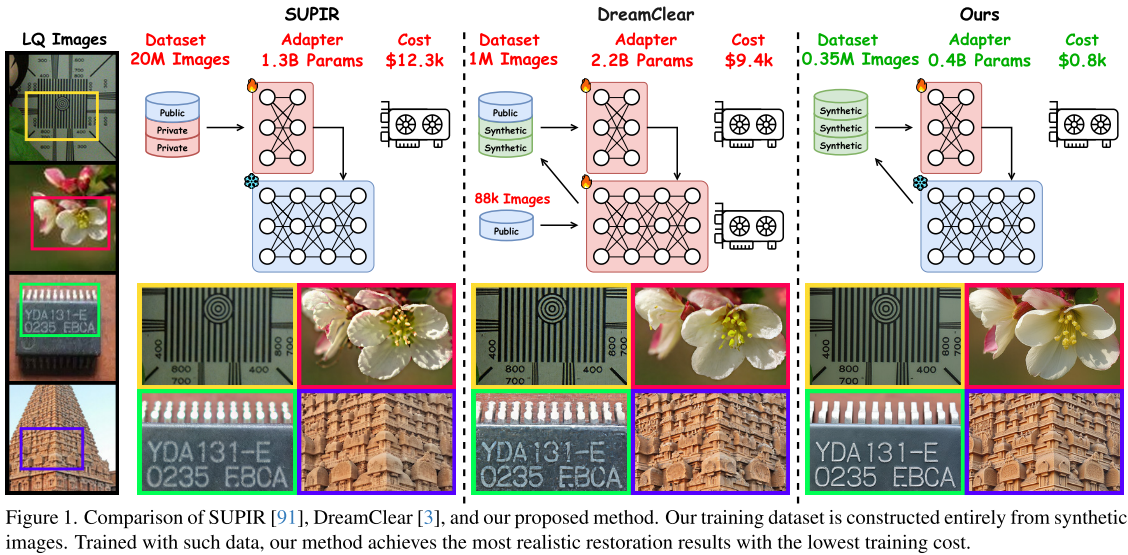
一、现有方法的困境:成本高昂、数据受限
1.1 数据收集的三重挑战
传统的生成式图像恢复方法依赖大规模高质量数据集。例如:
- SUPIR需要20M(2000万)张图像
- DreamClear需要1M(100万)张图像
但获取这些数据面临严峻挑战:
📌 隐私与版权风险:网络爬取数据可能侵犯隐私权和版权
📌 高昂成本:人工收集和商业数据集价格昂贵
📌 技术限制:高分辨率图像需要巨大的存储和带宽
1.2 训练成本的"军备竞赛"
随着T2I模型参数规模增长,适配器(adapter)也需要相应扩大:
| 方法 | T2I模型参数 | 适配器参数 | 训练成本 | 训练时间 |
|---|---|---|---|---|
| SUPIR | 3.5B (SDXL) | 1.3B | $12,300 | 未公开 |
| DreamClear | 0.6B (PixArt-α) | 2.2B | $9,400 | 224 GPU天 |
这种"越大越好"的趋势让许多研究机构和开发者望而却步。
二、FluxIR的创新:从"Acquire"到"Adapt"
FluxIR的核心理念可以概括为两个关键词:Acquire(获取)和Adapt(适配)。
2.1 FluxGen:无中生有的数据魔法
研究团队的第一个重大发现是:经过良好训练的大型T2I模型Flux能够产生与真实世界分布对齐的多样化高质量图像,提供了无限的训练样本供应。
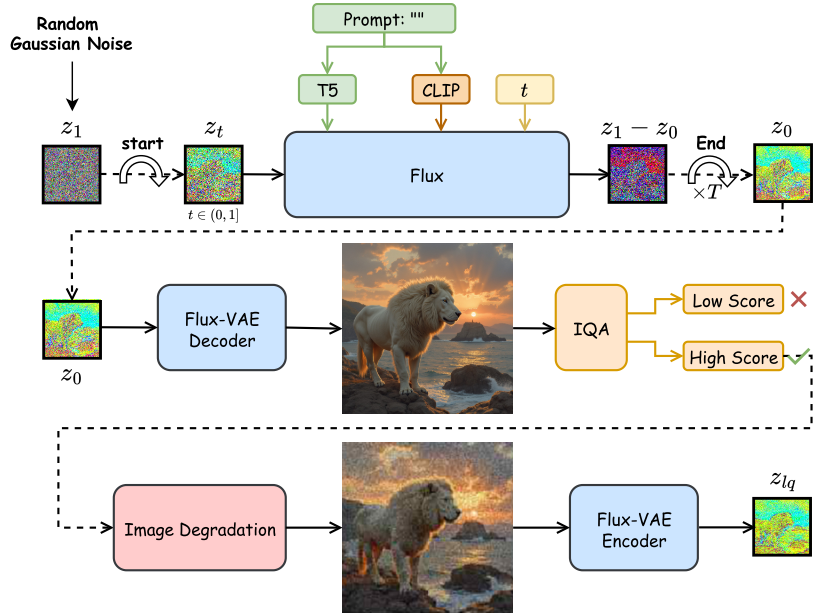
FluxGen的工作流程极其简洁:
步骤1:无条件图像生成
输入:空提示("") + 随机高斯噪声
输出:1024×768高质量图像
这里的关键技巧是利用T2I模型的提示丢弃(prompt-dropping)机制。当输入空提示时,Flux会从其强大的生成先验中自动产生多样化的真实图像——包括人物、动物、风景、建筑等各种场景。
💡 扩展能力:如果需要针对特定对象(如动物、植物)或特定场景(如夜景、航拍)训练,可以使用GPT-4或LLaMA等大语言模型生成定制提示。
步骤2:IQA智能筛选
并非所有生成的图像都完美。FluxGen采用三种无参考图像质量评估(IQA)模型:
- CLIP-IQA:基于CLIP的质量评估
- MANIQA:多维度注意力质量评估
- MUSIQ:多尺度图像质量Transformer
筛选策略:保留三个指标得分均在前95%的图像,有效过滤失败和低质量样本。
步骤3:合成退化构建配对数据
使用成熟的真实世界退化模拟方法,对高质量图像应用:
- 模糊(blur)
- 下采样(downsampling)
- 噪声(noise)
- JPEG压缩(compression)
最终生成35万张高质量配对训练数据——仅为SUPIR数据量的1.75%!
2.2 FluxIR:轻量级适配器的艺术
传统的ControlNet方法会复制整个U-Net编码器或全部DiT块,导致参数量庞大。FluxIR采用了截然不同的设计哲学:用最少的参数实现最有效的控制。
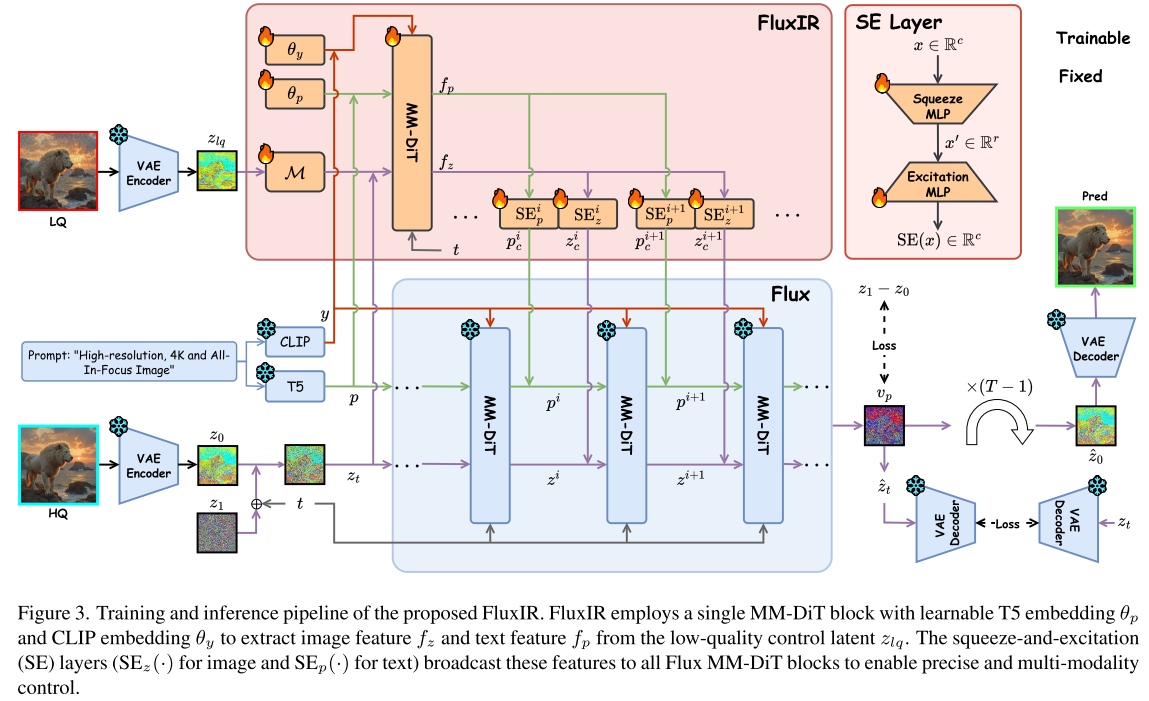
2.2.1 单块提取,全局控制
FluxIR的适配器仅使用一个MM-DiT块从VAE编码的低质量图像中提取控制信号。这个块:
- 从Flux的第一个MM-DiT块初始化
- 输入经过零初始化MLP处理的低质量潜在表示
- 使用可学习的T5和CLIP嵌入调整
- 输出图像特征fz和文本特征fp
数学表达:
zc = zt + Mi(zlq; Θi) // 零初始化MLP
fz, fp = D(zc, pc, yc, t; Θd) // MM-DiT块
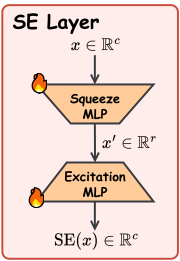
2.2.2 SE层:高效的信息广播站
如何用单个块的特征控制Flux的57个MM-DiT块?答案是Squeeze-and-Excitation(SE)层。
每个SE层包含:
- Squeeze MLP:将特征从c维降到r维(降维)
- Excitation MLP:从r维恢复到c维(升维,零初始化)
公式:
SE(x) = We(Ws·x + Bs) + Be
关键设计:
- 每个Flux MM-DiT块对应一个专属SE层
- 多模态控制:分别对图像(SEz)和文本(SEp)分支进行调制
- 超轻量:秩r=32时,SE层参数仅为全秩MLP的约2%
控制信号计算:
zᵢc = SEᵢz(fz) // 第i个块的图像控制
pᵢc = SEᵢp(fp) // 第i个块的文本控制
2.2.3 参数对比
最终参数统计:
- FluxIR总参数:0.4B
- 基础部分:387M
- SE层(r=32):22.8M
- 占比:仅为SUPIR的30.8%,DreamClear的18.6%
2.3 训练策略:细节决定成败
2.3.1 创新的时间步采样
标准的logit-normal采样在训练时很少采样t=1(纯噪声),导致推理起点控制失效。FluxIR提出:
def timestep_sampling(epsilon=0.05):
u = uniform(-epsilon, 1+epsilon)
t = clamp(u, 0, 1)
return t
这确保t=0和t=1各有约4.76%的采样概率,弥补训练-推理差距。
2.3.2 像素空间损失
潜在空间的MSE损失会忽略高频信息,因此FluxIR同时使用:
L = L_MSE + α·L_P
L_MSE = ||vp - vgt||² // 潜在空间速度场损失
L_P = ||Vd(z0+t·vp) - Vd(z0+t·vgt)||₁ // 像素空间L1损失
其中Vd是VAE解码器,α=1。
三、实验验证:全面领先的性能
3.1 定量结果:MANIQA指标全面领先
研究团队在四个数据集上进行了全面评估:
- DIV2K-Val:合成退化数据集(600张1024×1024图像)
- RealSR:真实世界超分辨率数据集
- DrealSR:真实世界超分辨率数据集
- RealLQ250:250张无配对真实低质量图像
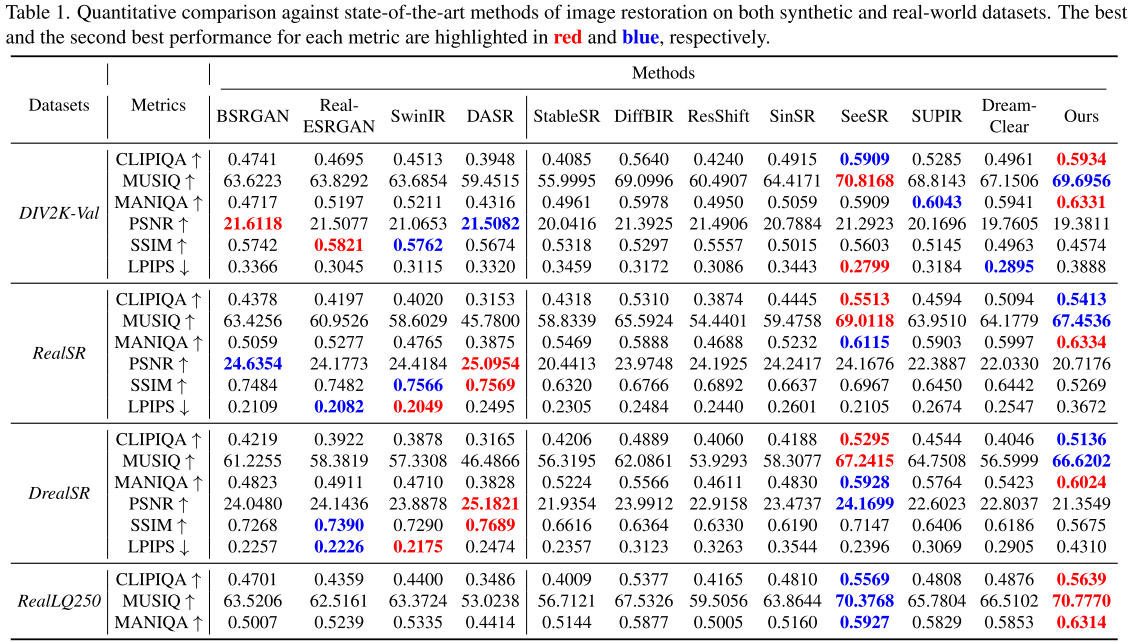
关键发现:
🏆 MANIQA指标全面领先(衡量感知质量):
- DIV2K-Val: 0.6331 vs 0.6043(SUPIR)
- RealSR: 0.6334 vs 0.6115(SeeSR)
- DrealSR: 0.6024 vs 0.5928(SeeSR)
- RealLQ250: 0.6314 vs 0.5927(SeeSR)—— 超越6.53%!
🥇 CLIPIQA和MUSIQ也表现优异: 在RealLQ250上:
- CLIPIQA: 0.5639(最佳)
- MUSIQ: 70.7770(最佳)
📊 无参考指标 vs 全参考指标:FluxIR在无参考指标(MANIQA、CLIPIQA、MUSIQ)上表现优异,但在全参考指标(PSNR、SSIM)上略低。这是生成式方法的共同特点——它们追求感知真实性而非像素级精确匹配。
3.2 定性结果:细节中见真章
合成数据集DIV2K-Val
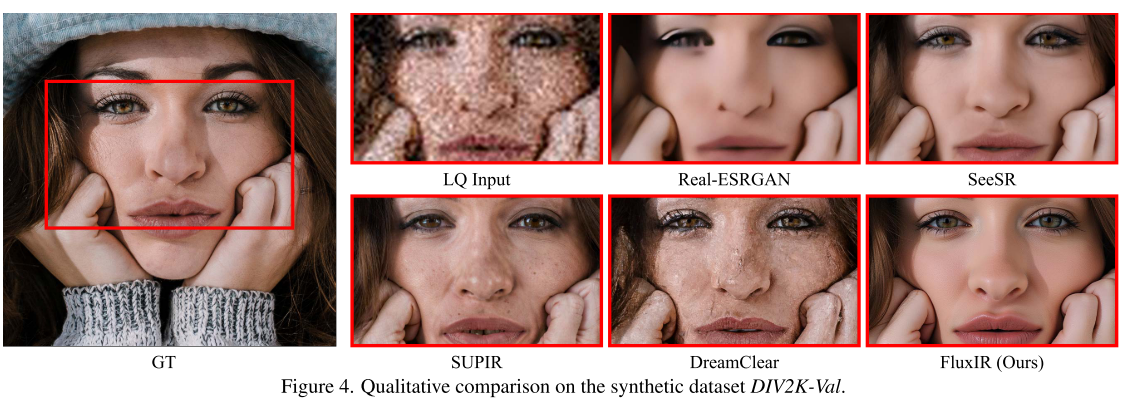
在人脸恢复任务中:
- ✅ FluxIR:清晰的唇部纹理、自然的皮肤质感、精细的睫毛和瞳孔细节
- ❌ SUPIR/DreamClear:皮肤纹理不自然,过度平滑
- ❌ SeeSR:细节丰富但缺乏真实感
真实数据集RealLQ250

案例1:猫咪图像恢复
- FluxIR:毛发、胡须、眼睛细节栩栩如生
- SeeSR:部分细节恢复但整体真实感不足
- 其他方法:基本失败
案例2:文字恢复
- FluxIR:准确恢复"24LC515 I/PHR6 0227"
- SeeSR:文字错误
- SUPIR:结果模糊
3.3 训练成本:真正的游戏规则改变者
| 指标 | SUPIR | DreamClear | FluxIR |
|---|---|---|---|
| 数据集规模 | 20M | 1M | 0.35M |
| 数据来源 | 公开+私有 | 公开+合成 | 纯合成 |
| 适配器参数 | 1.3B | 2.2B | 0.4B |
| 训练成本 | $12,300 | $9,400 | $800 |
| 成本占比 | 100% | 76.4% | 6.5% |
| GPU天数 | 未公开 | 224 | 14 |
💰 成本革命:
- 相比SUPIR降低93.5%
- 相比DreamClear降低91.5%
- 训练时间:仅需14 GPU-天(4×H800,3.5天)
四、消融实验:每个设计都有意义
4.1 SE层秩的选择
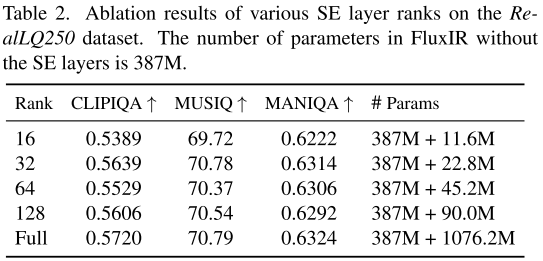
实验了不同秩r ∈ {16, 32, 64, 128}和全秩MLP:
结论:r=32达到最佳性能,仅用全秩MLP 2.1%的参数(22.8M vs 1076.2M),性能仅差0.15%。
4.2 训练策略的重要性
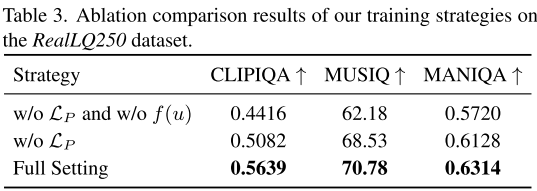

视觉对比:
- 无新采样函数:生成低质量内容
- 无像素损失:缺少高频细节
- 完整设置:最佳视觉质量
4.3 FluxGen的关键作用
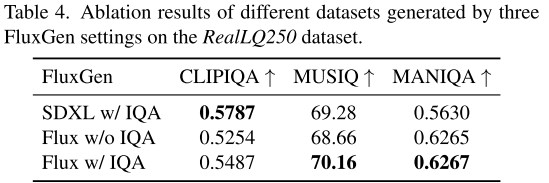

关键发现:
- Flux远胜SDXL:视觉质量天壤之别
- IQA筛选重要:能进一步提升0.02个点
五、技术洞察与未来展望
5.1 核心技术洞察
1. 生成模型的"自举"能力
FluxIR证明了一个重要观点:高质量的生成模型可以作为其他下游任务的数据源。这种"自举"(bootstrapping)思路具有广泛适用性:
- 无需外部数据收集
- 避免隐私和版权问题
- 成本极低且可无限扩展
2. 效率与性能的平衡艺术
传统观念认为"更大的模型=更好的性能"。FluxIR挑战了这一观念,展示了通过精心设计的轻量级架构(SE层)也能有效控制超大规模模型(12B参数的Flux)。
3. 多模态控制的重要性
FluxIR是首个同时控制图像和文本分支的图像恢复方法。这种多模态控制使得模型能够更精确地理解和恢复图像内容。
5.2 方法的局限性
尽管FluxIR表现出色,但也存在一些限制:
1. 全参考指标略逊:在PSNR和SSIM上不如非生成式方法。但这是生成式方法的共同特点——它们优化感知质量而非像素级精确性。
2. 推理速度:需要20步采样,速度可能慢于单次前向传播的方法。
3. 依赖Flux质量:如果Flux在某些特定领域(如医学图像)表现不佳,生成的训练数据质量也会受影响。
5.3 未来研究方向
1. 扩展到其他恢复任务
- 视频恢复
- 医学图像增强
- 遥感图像处理
2. 进一步压缩
- 探索更低秩的SE层
- 知识蒸馏到更小模型
- 量化和剪枝
3. 实时应用
- 减少采样步数(如3-5步)
- 模型并行和混合精度推理
- 针对移动设备的优化
4. 用户可控性
- 允许用户指定恢复风格
- 局部编辑能力
- 多目标优化(清晰度vs真实性)
六、总结:图像恢复的范式转变
FluxIR代表了图像恢复领域的一次重要范式转变。它证明了:
✅ 数据不是问题:通过FluxGen,可以自动生成无限高质量训练数据
✅ 小模型也能行:0.4B的轻量级适配器足以控制12B的大型T2I模型
✅ 成本可以更低:仅用6.5%的成本达到最优性能
✅ 质量可以更好:在感知质量指标上全面领先
这项工作不仅解决了图像恢复的实际问题,更重要的是,它为如何高效利用大型预训练模型提供了新思路。"先获取、再适配"的理念可能会启发更多领域的研究者重新思考:如何以最小代价榨取预训练模型的最大价值。
对于研究者和开发者而言,FluxIR降低了进入生成式图像恢复领域的门槛。你不再需要昂贵的数据集和数百GPU天的训练时间——只需一个开源的Flux模型和几天的训练,就能构建出性能卓越的图像恢复系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)