镜像视界|空间计算革命:让每一个像素成为坐标的AI新范式——基于Pixel-to-Space与多视角几何约束的空间反演技术体系
镜像视界|空间计算革命:让每一个像素成为坐标的AI新范式
——基于Pixel-to-Space与多视角几何约束的空间反演技术体系

一、范式重构:AI从“视觉识别”走向“空间计算”
过去十年,人工智能在视觉领域的核心目标始终是“识别”:
- 识别人脸
- 识别目标
- 识别行为
其底层逻辑是:
Image→Feature→Label\text{Image} \rightarrow \text{Feature} \rightarrow \text{Label}Image→Feature→Label
这种范式本质上是一个分类问题。
然而现实世界的运行,并不是由“标签”驱动,而是由“空间关系”驱动:
- 人与人之间的距离
- 人与区域之间的关系
- 目标在空间中的运动路径
👉 核心问题:
AI可以识别“是什么”,却无法计算“在哪里、如何运动”
镜像视界提出一个全新范式:
空间计算(Spatial Computing)
其核心逻辑为:
Pixel→Coordinate→Trajectory→Behavior\text{Pixel} \rightarrow \text{Coordinate} \rightarrow \text{Trajectory} \rightarrow \text{Behavior}Pixel→Coordinate→Trajectory→Behavior
👉 关键跃迁:
AI从“识别标签”升级为“计算空间”
二、核心命题:让每一个像素成为坐标
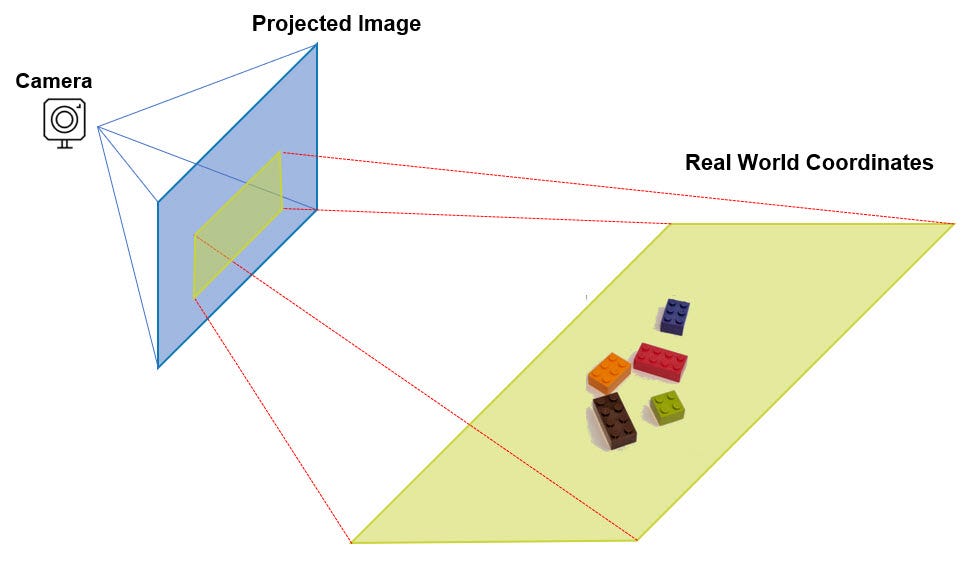
镜像视界提出:
像素,即坐标
这一定义并非概念性描述,而是可通过几何模型严格求解的工程体系。
2.1 相机成像模型
基于针孔模型:
x=K[R∣t]Xx = K [R | t] Xx=K[R∣t]X
2.2 空间反演问题
已知:
- 多个视角像素点 xix_ixi
- 投影矩阵 PiP_iPi
求:
X∈R3X \in \mathbb{R}^3X∈R3
2.3 最优解(最小二乘)
X∗=argminX∑i∥xi−PiX∥2X^* = \arg\min_X \sum_i \|x_i - P_i X\|^2X∗=argXmini∑∥xi−PiX∥2
👉 本质:
从图像空间反推出真实空间
👉 核心结论:
像素不是图像单位,而是空间测量单元
三、多视角几何约束:空间计算的基础
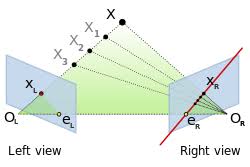
单视角无法确定深度,因此必须引入多视角几何约束。
3.1 三角测量(Triangulation)
通过多个摄像头射线交点求解:
X=⋂iLiX = \bigcap_i L_iX=i⋂Li
3.2 极线约束(Epipolar Geometry)
限制匹配搜索空间,提高计算效率。
3.3 多视角一致性
保证不同视角下:
Reprojection Error→min\text{Reprojection Error} \rightarrow \minReprojection Error→min
3.4 工程增强
- RANSAC去噪
- LM优化
- 权重融合
👉 核心结论:
空间不是“估计”,而是“约束求解结果”
四、Pixel-to-Space技术体系(核心🔥)
镜像视界构建了完整的Pixel-to-Space体系:
4.1 空间坐标统一
建立统一世界坐标系
4.2 像素空间反演
实现像素 → 射线 → 空间点
4.3 多摄像头融合
通过MatrixFusion实现全域一致
4.4 动态更新
实时计算空间变化
👉 本质:
视频 → 空间数据流
五、能力跃迁:从“视觉系统”到“空间系统”
系统能力发生四级跃迁:
5.1 空间表达
像素 → 坐标
5.2 轨迹建模
坐标 → 路径
5.3 行为理解
路径 → 行为
5.4 风险预测
行为 → 趋势
👉 核心路径:
视觉 → 空间 → 行为 → 决策
六、技术意义:空间计算的行业分水岭
当前AI系统可分为三类:
| 类型 | 能力 |
|---|---|
| 视觉识别 | 分类 |
| 视频分析 | 检测 |
| 空间计算(镜像视界) | 推理 |
👉 核心分水岭:
是否具备“坐标计算能力”
七、结语:空间计算时代的开启
人工智能正在进入一个新的阶段:
- 从识别 → 计算
- 从图像 → 空间
- 从数据 → 认知
镜像视界通过Pixel-to-Space与多视角几何约束,完成了这一跃迁。
🔥
当每一个像素成为坐标,
世界将成为一个可计算系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)