AllMatch: Exploiting All Unlabeled Data for Semi-Supervised Learning
AllMatch: Exploiting All Unlabeled Data for Semi-Supervised Learning
摘要
现有的半监督学习算法通常采用伪标签和一致性正则化技术,为无标签样本引入监督信号。为克服基于阈值的伪标签方法所固有的局限性,已有研究尝试使置信度阈值与模型不断演化的学习状态相匹配,而这种学习状态通常是通过模型对无标签数据的预测来估计的。
在本文中,我们进一步揭示:分类器权重能够反映不同类别之间差异化的学习状态,并据此提出了一种类别特异的自适应阈值机制。此外,考虑到即使最优的阈值方案也无法解决无标签样本被丢弃的问题,我们设计了一种二分类一致性正则化方法,用于为所有无标签样本区分候选类别与负类选项。
结合上述策略,我们提出了一种新的半监督学习算法,称为 AllMatch。该方法能够提升伪标签的准确性,并实现无标签数据 100% 的利用率。我们在多个基准数据集上对该方法进行了广泛评估,涵盖了类别均衡和类别不均衡两种设置。实验结果表明,AllMatch 能够稳定优于现有的最先进方法。
引言
半监督学习(SSL)[Zhu, 2005;Rosenberg 等, 2005;Berthelot 等, 2019b;Sohn 等, 2020] 是近年来受到广泛关注的一个研究方向,其目标是通过挖掘无标签数据的潜力来提升模型的泛化性能。在已有方法中,伪标签 [Lee and others, 2013;Arazo 等, 2020] 与 一致性正则化 [Sajjadi 等, 2016;Laine and Aila, 2016] 的结合——如 FixMatch [Sohn 等, 2020] 所引入的方式——已经成为一种主流方案。
具体而言,FixMatch 首先根据无标签样本的弱增强视图的预测结果,为每个无标签样本分配一个伪标签。随后,将那些置信度超过预设阈值的伪标签,作为其对应强增强视图的监督信号;而置信度低于该阈值的伪标签则会被直接丢弃。为了保证伪标签的高质量,FixMatch 在整个训练过程中采用了一个较高的固定阈值。
然而,这种策略会导致无标签数据利用不足,从而引出了半监督学习中的一个核心挑战:如何高效利用无标签数据。
为了解决基于阈值的伪标签方法中伪标签质量与数量之间的权衡问题,已有研究提出了动态阈值策略,使阈值能够与模型不断变化的学习状态相适应。
例如,FlexMatch [Zhang et al., 2021] 利用高置信伪标签的数量来估计各个类别的学习难度,随后根据所确定的难度水平,将预定义阈值映射为类别特异的阈值。此外,FreeMatch [Wang et al., 2022] 利用无标签数据的平均置信度来构建一个动态的全局阈值。另外,SoftMatch [Chen et al., 2023a] 采用一个高斯函数来表示样本特异置信度与全局置信度之间的差异,并以此建模样本权重,从而为每个无标签样本分配一个正权重。
然而,那些置信度显著低于全局置信度的样本会被赋予接近于零的权重,本质上仍然等同于被丢弃。因此,这一特性使得 SoftMatch 可以被视为阈值型方法的一种变体。尽管上述算法能够有效利用伪标签来评估模型的学习状态,但有偏的数据采样或类别间潜在的相似性,都可能显著影响无标签数据上的预测结果。
因此,一个关键问题随之产生:除了伪标签之外,我们是否还能引入额外的证据,以更准确地估计模型的学习状态?
尽管改进阈值方案能够提升无标签数据的利用率,但仍有一部分无标签样本会被排除在外。这就引出了另一个问题:那些被赋予较低置信度的伪标签,是否仍然能够提供有价值的语义指导?
为回答这一问题,我们考察了以往算法中的伪标签质量。以 CIFAR-10 [Krizhevsky et al., 2009] 在仅有 40 个标注样本 的情形为例,如图 1(a) 所示,被丢弃的伪标签中有超过一半实际上是正确的。此外,图 1(b) 表明,仅在几千次迭代内,伪标签的 top-5 准确率 就能达到 100%。因此,即便是置信度较低的伪标签,也能够通过排除错误选项(例如后 5 个类别)来提供有效的监督信号。
受上述问题启发,本文提出了 AllMatch,一种新的半监督学习模型,旨在提升学习状态估计的准确性,并为所有无标签数据提供语义指导。
具体而言,AllMatch 提出了一种类别特异的自适应阈值(Class-specific Adaptive Threshold, CAT)策略,该策略由全局估计和局部调整两个步骤组成,以更好地刻画模型的学习状态。
其中,全局估计步骤与 FreeMatch 类似,使用无标签数据的平均置信度作为全局阈值。随后,局部调整步骤利用分类器权重来估计每个类别的学习状态,并针对那些学习较为困难的类别自适应地下调阈值。如图 4(b, c) 和图 4(f, g) 所示,CAT 在无标签样本的利用率和伪标签准确率方面均优于已有方法。
此外,针对由于低置信度伪标签被排除而导致的无标签数据利用不足问题,AllMatch 进一步提出了一种二分类一致性(Binary Classification Consistency, BCC)正则化策略,以挖掘此类伪标签中的潜在价值。其核心思想是:将类别空间划分为候选类别和负类,并鼓励同一样本在不同扰动视图下保持一致的“候选-负类”划分,从而排除负类选项。
对于每个样本,其候选类别对应于该样本预测结果中的 top-k 类别,这一设计是基于多种算法所表现出的优异 top-k 性能。需要注意的是,参数 k 是动态确定的,它会根据不同样本的学习状态以及模型性能的演化而变化。如图 4(c, d) 和图 4(g, h) 所示,BCC 正则化能够有效识别无标签样本的候选类别,并实现无标签数据 100% 的利用率。
总体而言,我们的贡献可以总结如下:
(1)我们重新审视了现有的半监督学习算法,并提出了两个问题:如何设计一种有效的阈值机制,以及如何利用低置信度伪标签。
(2)我们提出了一种类别特异的自适应阈值机制,分别利用伪标签和分类器权重来估计全局学习状态和类别特异的学习状态。
(3)我们设计了一种二分类一致性正则化方法,为所有无标签样本提供监督信号。
(4)我们在多个基准数据集上开展了实验,涵盖了类别均衡和类别不均衡两种设置。实验结果表明,AllMatch 达到了当前最先进的性能水平。
相关工作
一致性正则化与伪标签学习 [Laine and Aila, 2016;Sajjadi et al., 2016;Tarvainen and Valpola, 2017] 是半监督学习中的两类基础方法。前者鼓励同一样本在不同扰动视图下产生一致的预测,后者则为无标签样本分配伪标签。在已有技术中,FixMatch [Sohn et al., 2020] 将这两种方法很好地结合起来,建立了一种有效的半监督学习范式。具体来说,FixMatch 使用弱增强样本的预测作为伪标签,并最小化这些伪标签与其对应强增强视图预测之间的差异。
为了保证伪标签的高质量,FixMatch 在整个训练过程中采用一个较高的固定阈值,以过滤掉潜在错误的伪标签。然而,这一策略会导致无标签数据利用不足。为了解决这一问题,FlexMatch [Zhang et al., 2021] 借鉴了课程学习 [Bengio et al., 2009] 的思想,根据每个类别的学习状态,将预定义阈值映射为类别特异的阈值。Dash [Xu et al., 2021] 则基于有标签数据的损失来定义阈值,从而消除了经验阈值参数。FreeMatch [Wang et al., 2022] 使用无标签数据上的平均置信度作为自适应的全局阈值。SoftMatch [Chen et al., 2023a] 通过一个动态高斯函数来估计样本权重,从而在不同置信度水平的无标签样本之间保持软间隔。
除了基于阈值的方法之外,CoMatch [Li et al., 2021] 和 SimMatch [Zheng et al., 2022] 还利用对比损失,对所有无标签数据施加样本级约束。相比之下,AllMatch 通过引入 CAT(一种感知学习状态的阈值策略)和 BCC 正则化(对整个无标签集合进行语义级监督),结合了基于阈值方法和基于对比方法两者的优点。
与我们工作同期,FullMatch [Chen et al., 2023b] 也为所有无标签样本引入了语义指导。具体而言,FullMatch 通过比较弱增强样本和强增强样本的预测来识别负类。相比之下,AllMatch 通过比较样本级 top-k 置信度与全局 top-k 置信度来识别候选类别,因此在这一过程中同时考虑了单个样本的学习状态和模型整体的学习状态。此外,FullMatch 在优化目标中为负类分配较低概率(类似于标签平滑),而 AllMatch 则直接鼓励所有无标签样本在“候选类—负类”划分上保持一致,因此与无监督损失具有更好的协调性。
除了一致性正则化和伪标签方法之外,基于熵的正则化也是另一类被广泛采用的策略。熵最小化 [Grandvalet and Bengio, 2004] 旨在促进训练过程中产生高置信度预测。而对所有样本预测期望的熵进行最大化 [Krause et al., 2010;Arazo et al., 2020;Zhao et al., 2022] 则引入了公平性的概念,即鼓励模型以大致相同的频率预测每一个类别。具体来说,分布对齐(DA)[Berthelot et al., 2019a] 和 均匀对齐(UA)[Chen et al., 2023a] 是在半监督学习中实现这种公平性的主流策略,它们会根据无标签数据上的整体预测结果对伪标签进行调整。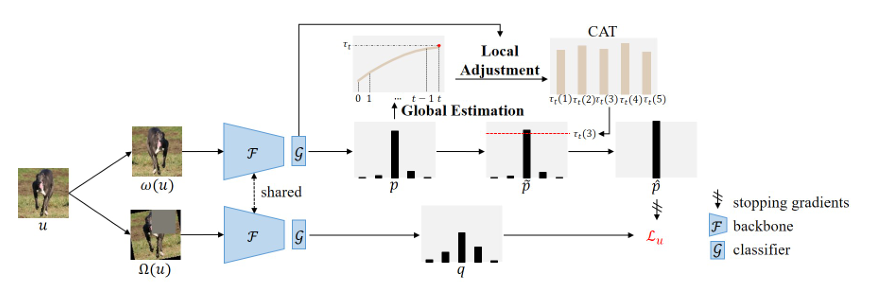
图 2:类别特异的自适应阈值(CAT)机制流程图。CAT 首先将无标签数据上的平均置信度作为全局阈值,随后利用分类器权重来构建类别特异的阈值。
方法
3.1 预备知识
我们首先回顾一种被广泛采用的半监督学习(SSL)框架。
设
D L = { ( x i , y i ) } i = 1 N L D_L=\{(x_i,y_i)\}_{i=1}^{N_L} DL={(xi,yi)}i=1NL
和
D U = { u i } i = 1 N U D_U=\{u_i\}_{i=1}^{N_U} DU={ui}i=1NU
分别表示有标签数据集和无标签数据集。其中, x i x_i xi 和 u i u_i ui 分别表示有标签训练样本和无标签训练样本, y i y_i yi 表示有标签样本 x i x_i xi 的 one-hot 标签。我们记样本 x x x 的预测为 p ( y ∣ x ) p(y|x) p(y∣x)。
给定一个由有标签数据和无标签数据组成的 batch,模型的优化目标为
L = L s + λ u L u L = L_s + \lambda_u L_u L=Ls+λuLu
其中, L s L_s Ls 表示大小为 B L B_L BL 的有标签 batch 上的交叉熵损失( H H H):
L s = 1 B L ∑ i = 1 B L H ( y i , p ( y ∣ x i ) ) L_s=\frac{1}{B_L}\sum_{i=1}^{B_L} H(y_i,p(y|x_i)) Ls=BL1i=1∑BLH(yi,p(y∣xi))
L u L_u Lu 表示强增强视图 Ω ( u ) \Omega(u) Ω(u) 的预测与由其对应弱增强视图 ω ( u ) \omega(u) ω(u) 所生成的伪标签之间的一致性正则化。为了过滤错误的伪标签,FixMatch 引入了一个预定义阈值 τ \tau τ。具体而言, L u L_u Lu 定义如下:
L u = 1 B U ∑ i = 1 B U λ ( p ~ i ) H ( p ^ i , q i ) L_u=\frac{1}{B_U}\sum_{i=1}^{B_U}\lambda(\tilde{p}_i)H(\hat{p}_i, q_i) Lu=BU1i=1∑BUλ(p~i)H(p^i,qi)
λ ( p ) = { 1 , if max ( p ) ≥ τ 0 , otherwise \lambda(p)= \begin{cases} 1, & \text{if } \max(p)\ge \tau \\ 0, & \text{otherwise} \end{cases} λ(p)={1,0,if max(p)≥τotherwise
其中, p ~ i \tilde{p}_i p~i 是 D A ( p ( y ∣ ω ( u i ) ) ) DA(p(y|\omega(u_i))) DA(p(y∣ω(ui))) 的简写,这里的 D A DA DA 表示分布对齐(distribution alignment)策略。
p ^ i \hat{p}_i p^i 表示由 arg max ( p ~ i ) \arg\max(\tilde{p}_i) argmax(p~i) 得到的 one-hot 伪标签。
此外, q i q_i qi 是 p ( y ∣ Ω ( u i ) ) p(y|\Omega(u_i)) p(y∣Ω(ui)) 的简写。
最后, B U B_U BU 表示无标签数据的 batch 大小。
3.2 类别特异的自适应阈值
先前研究 [Zhang et al., 2021; Wang et al., 2022] 已经表明,阈值应当与模型不断演化的学习状态保持一致。为实现这一点,这些方法利用无标签数据上的预测来构建动态阈值。在本文中,我们揭示了分类器权重能够区分各个类别学习状态的能力。通过结合伪标签与分类器权重,我们提出了一种类别特异的自适应阈值(Class-Specific Adaptive Threshold, CAT)机制。如图 2 所示,CAT 包括全局估计和局部调整两个步骤。下面将对这两个步骤进行详细说明。
全局估计
全局估计步骤借鉴了 FreeMatch [Wang et al., 2022] 的思想,用于评估模型的整体学习状态。鉴于深度神经网络通常倾向于先拟合较容易的样本,再记忆更困难且噪声更大的样本,因此在训练早期需要采用较低的阈值,以纳入更多正确的伪标签。相反,随着训练推进,则需要采用更高的阈值来过滤错误伪标签。
由于交叉熵损失会鼓励模型输出高置信度预测,因此无标签数据集上的平均置信度能够整合所有无标签数据的信息,并在训练过程中稳步上升,从而反映模型的整体学习状态。然而,在每一个时间步上对整个无标签数据集都进行预测会带来显著的计算开销。因此,我们采用当前 batch 的平均置信度作为估计值,并通过指数滑动平均(EMA)对其进行更新。
具体而言,第 t t t 次迭代时的全局学习状态估计,记为 τ t \tau_t τt,可按如下方式计算:
τ t = { 1 C , if t = 0 m τ t − 1 + ( 1 − m ) 1 B U ∑ i = 1 B U max ( p i ) , otherwise \tau_t = \begin{cases} \frac{1}{C}, & \text{if } t = 0 \\[6pt] m\tau_{t-1} + (1-m)\frac{1}{B_U}\sum_{i=1}^{B_U}\max(p_i), & \text{otherwise} \end{cases} τt=⎩ ⎨ ⎧C1,mτt−1+(1−m)BU1∑i=1BUmax(pi),if t=0otherwise
其中, p i p_i pi 表示 p ( y ∣ ω ( u i ) ) p(y|\omega(u_i)) p(y∣ω(ui)), m m m 表示动量衰减系数, C C C 表示类别数。
局部调整
由于不同类别在学习难度上存在固有差异,同时参数初始化又具有随机性,因此模型在各类别上的学习状态并不一致。为了解决这一问题,我们引入了局部调整步骤:通过降低欠拟合类别的阈值,使模型更加关注这些类别。具体而言,我们的研究表明,分类器权重的 L2 范数能够反映类别特异的学习状态。其原因如下。
首先,设模型为
M = G ∘ F M = G \circ F M=G∘F
其中, F F F 和 G G G 分别表示编码器和单层分类器。给定无标签样本 u u u 的特征向量
f = F ( u ) ∈ R d f = F(u) \in \mathbb{R}^d f=F(u)∈Rd
其预测 logits
z ∈ R C z \in \mathbb{R}^C z∈RC
可计算为
z = G ( f ) = f W T z = G(f) = fW^T z=G(f)=fWT
其中, W ∈ R C × d W \in \mathbb{R}^{C \times d} W∈RC×d 表示分类器的权重矩阵。由于偏置项通常对结果影响很小,因此这里将其省略。于是,类别 c c c 的 logit 可以表示为
z c = ∥ f ∥ ⋅ ∥ W c ∥ ⋅ cos ( θ ) z_c = \|f\| \cdot \|W_c\| \cdot \cos(\theta) zc=∥f∥⋅∥Wc∥⋅cos(θ)
其中, ∥ ⋅ ∥ \|\cdot\| ∥⋅∥ 表示 L2 范数, W c W_c Wc 表示类别 c c c 的权重。由此可见,对于权重范数更大的类别,模型倾向于产生绝对值更大的 logits,这意味着权重范数较大的类别通常具有更优的学习状态。
其次,[Kang et al., 2019] 揭示了权重范数 ∥ W c ∥ \|W_c\| ∥Wc∥ 与类别 c c c 中样本数量 n c n_c nc 之间存在正相关关系。考虑到无标签数据充足而有标签数据有限, n c n_c nc 可以近似看作:被模型以高于阈值的置信度划分为类别 c c c 的无标签样本数量。因此,更大的权重范数意味着有更多样本被高置信度地归入该类别,从而表明该类别具有更好的学习状态。
根据上述分析,分类器权重的 L2 范数能够刻画各类别的学习状态。因此,局部调整步骤利用这一指标,将全局阈值映射为类别特异的阈值。具体来说,我们根据每个类别的学习状态与最优学习状态之间的偏差,对该类别的阈值进行线性缩放。于是,第 t t t 次迭代时类别 c c c 的阈值,记为 τ t ( c ) \tau_t(c) τt(c),可表示为:
τ t ( c ) = τ t ⋅ ∥ W c ∥ max { ∥ W c ∥ : c ∈ [ 1 , ⋯ , C ] } \tau_t(c) = \tau_t \cdot \frac{\|W_c\|} {\max\{\|W_c\| : c \in [1, \cdots, C]\}} τt(c)=τt⋅max{∥Wc∥:c∈[1,⋯,C]}∥Wc∥
此外,为了保证学习状态估计的稳定性,我们采用 EMA 模型得到的分类器权重。值得注意的是,与 FlexMatch 不同,后者需要维护一个额外列表来记录每个样本被选中的伪标签,而本文提出的 CAT 在训练过程中不存储任何样本级信息。这避免了在大规模数据集上进行索引时带来的额外开销问题。
在引入 CAT 之后,无标签样本在 L u L_u Lu 中的掩码可表示为:
λ ( p ) = { 1 , if max ( p ) ≥ τ t ( arg max ( p ) ) 0 , otherwise \lambda(p)= \begin{cases} 1, & \text{if } \max(p)\ge \tau_t(\arg\max(p)) \\ 0, & \text{otherwise} \end{cases} λ(p)={1,0,if max(p)≥τt(argmax(p))otherwise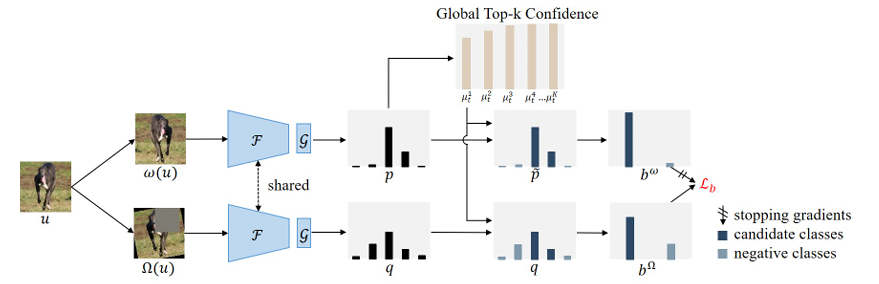
图 3:二分类一致性(BCC)正则化流程图。该模块通过比较全局 top-k 置信度与局部 top-k 置信度,为每个无标签样本识别其候选类别和负类。此外,它还鼓励同一样本在不同扰动视图之间保持一致的“候选类—负类”划分,从而为所有无标签样本引入监督信号。
3.3 二分类一致性正则化
尽管所提出的类别特异自适应阈值缓解了无标签数据利用不足的问题,但仍然有相当数量的伪标签会被丢弃。如图 1 所示,在 CIFAR-10 仅有 40 个标注样本的情况下,无论采用哪种算法,伪标签的 top-5 准确率都能轻松达到 100%。换句话说,那些置信度较低的伪标签仍然有助于识别候选类别(例如 top-k 预测)并排除负类选项(例如不属于 top-k 预测的类别)。
受这些观察结果以及一致性正则化技术的启发,我们提出了二分类一致性(Binary Classification Consistency, BCC)正则化,其整体框架如图 3 所示。简而言之,该策略通过鼓励同一样本在不同扰动视图下保持一致的“候选类—负类”划分,从而为所有无标签数据引入语义监督。具体细节如下。
鉴于许多算法都取得了出色的 top-k 伪标签准确率,BCC 正则化将每个无标签样本的 top-k 预测作为其候选类别,其余类别作为负类选项。因此,候选类—负类划分的问题被简化为参数 k k k 的选择问题。
此外,考虑到不同样本之间学习难度存在差异,并且模型性能会不断演化,每个样本的候选类—负类划分应同时基于个体学习状态和全局学习状态来确定。为此,BCC 正则化首先计算样本特异的 top-k 置信度以及整个无标签集合的全局 top-k 置信度。具体来说,设 p i k p_i^k pik 表示样本 u i u_i ui 的 top-k 概率, μ t k \mu_t^k μtk 表示第 t t t 次迭代时的全局 top-k 概率。全局 top-k 置信度可通过每个时刻平均 top-k 置信度的指数滑动平均(EMA)进行估计:
p i k = ∑ j = 1 k p i , c j ( p i , c 1 ≥ p i , c 2 ≥ ⋯ ) p_i^k=\sum_{j=1}^{k} p_{i,c_j} \qquad (p_{i,c_1} \ge p_{i,c_2} \ge \cdots) pik=j=1∑kpi,cj(pi,c1≥pi,c2≥⋯)
μ t k = { k C , if t = 0 m μ t − 1 k + ( 1 − m ) 1 B U ∑ i = 1 B U p i k , otherwise \mu_t^k= \begin{cases} \frac{k}{C}, & \text{if } t=0 \\[6pt] m\mu_{t-1}^k+(1-m)\frac{1}{B_U}\sum_{i=1}^{B_U}p_i^k, & \text{otherwise} \end{cases} μtk=⎩ ⎨ ⎧Ck,mμt−1k+(1−m)BU1∑i=1BUpik,if t=0otherwise
其中, c 1 , … , c k c_1,\ldots,c_k c1,…,ck 表示在 p i p_i pi 中被赋予最高概率的 k k k 个类别。
在确定全局 top-k 置信度后,每个无标签样本的候选类别数被定义为:使其个体 top-k 置信度高于全局 top-k 置信度的最小值。特别地,对于高置信度无标签样本,其候选类别直接定义为其伪标签。因此,样本 u i u_i ui 的候选类别数 k i k_i ki 可表示为:
k i = { 1 , λ ( p ~ i ) = 1 min ( min { k : p ~ i k ≥ μ t k } , K ) , otherwise k_i= \begin{cases} 1, & \lambda(\tilde{p}_i)=1 \\[6pt] \min\left(\min\{k:\tilde{p}_i^k \ge \mu_t^k\},\, K\right), & \text{otherwise} \end{cases} ki=⎩ ⎨ ⎧1,min(min{k:p~ik≥μtk},K),λ(p~i)=1otherwise
其中, K K K 是候选类别数的上界,用于防止出现平凡的候选类—负类划分。
在得到上述划分之后,无标签样本 u i u_i ui 的弱增强视图( b i ω b_i^{\omega} biω)和强增强视图( b i Ω b_i^{\Omega} biΩ)上的候选类概率与负类概率可分别计算为:
b i ω = [ ∑ j = 1 k i p ~ i , c j , ∑ j = k i + 1 C p ~ i , c j ] ( p ~ i , c 1 ≥ p ~ i , c 2 ≥ ⋯ ) b_i^{\omega}= \left[ \sum_{j=1}^{k_i}\tilde{p}_{i,c_j}, \sum_{j=k_i+1}^{C}\tilde{p}_{i,c_j} \right] \qquad (\tilde{p}_{i,c_1} \ge \tilde{p}_{i,c_2} \ge \cdots) biω= j=1∑kip~i,cj,j=ki+1∑Cp~i,cj (p~i,c1≥p~i,c2≥⋯)
b i Ω = [ ∑ j = 1 k i q i , c j , ∑ j = k i + 1 C q i , c j ] b_i^{\Omega}= \left[ \sum_{j=1}^{k_i}q_{i,c_j}, \sum_{j=k_i+1}^{C}q_{i,c_j} \right] biΩ= j=1∑kiqi,cj,j=ki+1∑Cqi,cj
其中, c 1 , … , c k i c_1,\ldots,c_{k_i} c1,…,cki 表示在 p ~ i \tilde{p}_i p~i 中被赋予最高概率的 k i k_i ki 个类别。
最后,一个无标签 batch 上的 BCC 正则项可计算为:
L b = 1 B U ∑ i = 1 B U H ( b i ω , b i Ω ) L_b=\frac{1}{B_U}\sum_{i=1}^{B_U} H(b_i^{\omega}, b_i^{\Omega}) Lb=BU1i=1∑BUH(biω,biΩ)
3.4 整体目标函数
AllMatch 的整体目标函数被定义为所有语义级监督项的加权和:
L = L s + λ u L u + λ b L b L = L_s + \lambda_u L_u + \lambda_b L_b L=Ls+λuLu+λbLb
其中, λ u \lambda_u λu 和 λ b \lambda_b λb 表示用于平衡不同监督信号的权重。在所有实验中,我们均将 λ u \lambda_u λu 和 λ b \lambda_b λb 设置为 1.0。
4 实验
4.1 类别均衡的半监督学习
设置
对于类别均衡的图像分类任务,我们在 CIFAR-10/100、SVHN、STL-10 和 ImageNet 上进行了实验,并设置了不同数量的标注数据,其中标注数据的类别分布是均衡的。
为确保公平比较,我们采用统一代码库 TorchSSL 来评测所有方法。对于骨干网络结构,我们遵循以往研究,在不同数据集上使用不同模型:
- CIFAR-10 和 SVHN 使用 WRN-28-2;
- CIFAR-100 使用 WRN-28-8;
- STL-10 使用 WRN-37-2;
- ImageNet 使用 ResNet-50。
batch 大小方面,在 ImageNet 上, B L B_L BL 和 B U B_U BU 分别设为 128 和 128;在其余数据集上,分别设为 64 和 448。
AllMatch 使用 SGD 优化器进行训练,初始学习率设为 0.03,动量衰减设为 0.9。学习率通过余弦衰减调度器在总计 2 20 2^{20} 220 次迭代中进行调整。我们将 m m m 设为 0.999,并使用动量衰减为 0.999 的 EMA 模型进行推理。
参数上界 K K K 在 ImageNet 上设为 20,在其他数据集上设为 10。对于 SVHN、仅有 10 个标签的 CIFAR-10,以及 仅有 40 个标签的 STL-10,我们将阈值约束在区间 [0.9, 1.0] 内,以防止训练早期对噪声伪标签发生过拟合。
为考虑随机性,每组实验重复 3 次,并报告 top-1 准确率的均值和标准差。更详细的实现细节和数据处理流程见附录 C。
性能表现
表 1 展示了 CIFAR-10/100、SVHN 和 STL-10 在不同标注样本数量下的 top-1 准确率。ImageNet 上的性能结果见表 2。实验结果表明,AllMatch 在几乎所有数据集上都达到了当前最先进的性能。
对于 CIFAR-10,在仅有 40 个标注样本时,AllMatch 优于 FullMatch;而在有 250 或 4000 个标注样本时,AllMatch 与 FullMatch 表现相当。
对于 CIFAR-100,当只有 400 或 2500 个标注样本时,AllMatch 优于 ReMixMatch;而当标注样本数达到 10000 时,后者表现更好。ReMixMatch 的竞争性结果主要来源于 Mixup 技术以及额外引入的自监督学习部分。
此外,当标注样本极其有限时,AllMatch 相比以往算法表现出更明显的优势。具体而言,它相比第二优方法分别提升了:
- 1.87%(CIFAR-10,10 个标签);
- 0.66%(CIFAR-100,400 个标签);
- 2.86%(STL-10,40 个标签)。
特别地,STL-10 由于其包含 10 万张图像的大规模无标签数据集,因此具有显著挑战性。因此,AllMatch 在 STL-10 上取得的显著提升,突显了其在真实世界应用场景中部署的潜力。
4.2 类别不均衡的半监督学习
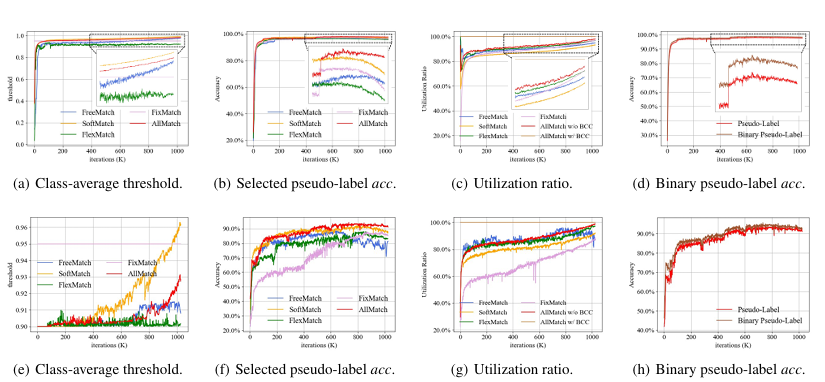
图 4:在 CIFAR-10-40(a-d)和 STL-10-40(e-h)上的学习过程可视化。对于 STL-10-40,阈值被限制在 [0.9, 1.0] 区间内,以减轻噪声伪标签带来的不利影响。
在对 SoftMatch 的分析中,我们使用 μ t − σ t \mu_t - \sigma_t μt−σt 作为其阈值。置信度低于 μ t − σ t \mu_t - \sigma_t μt−σt 的样本会被赋予可以忽略不计的权重,本质上等同于被丢弃。因此,SoftMatch 的类别平均阈值为 μ t − σ t \mu_t - \sigma_t μt−σt,其被选中伪标签的准确率和利用率也可以像其他基于阈值的模型一样进行计算。
其中, μ t / σ t \mu_t / \sigma_t μt/σt 分别表示无标签数据上整体置信度的均值 / 标准差。关于 SoftMatch 的详细分析见附录 A.3。
设置
我们在类别不均衡半监督学习(imbalanced SSL)的背景下评估 AllMatch,其中有标签数据和无标签数据都呈现长尾分布。所有实验均基于 TorchSSL 代码库进行。
按照以往研究 [Lee et al., 2021; Oh et al., 2022; Wei et al., 2021; Lai et al., 2022; Fan et al., 2022; Chen et al., 2023a] 的做法,我们使用如下配置生成有标签集和无标签集:
N c = N 1 ⋅ γ − c − 1 C − 1 和 M c = M 1 ⋅ γ − c − 1 C − 1 N_c = N_1 \cdot \gamma^{-\frac{c-1}{C-1}} \qquad \text{和} \qquad M_c = M_1 \cdot \gamma^{-\frac{c-1}{C-1}} Nc=N1⋅γ−C−1c−1和Mc=M1⋅γ−C−1c−1
具体而言,对于 CIFAR-10-LT,我们将 N 1 N_1 N1 设为 1500, M 1 M_1 M1 设为 3000,并令 γ \gamma γ 在 50 到 150 之间变化。对于 CIFAR-100-LT,我们将 N 1 N_1 N1 设为 150, M 1 M_1 M1 设为 300,并令 γ \gamma γ 在 20 到 100 之间变化。
在所有实验中,我们采用 WRN-28-2 作为骨干网络,并使用 Adam 优化器,其权重衰减设为 4e-5。batch 大小方面, B L B_L BL 和 B U B_U BU 分别设为 64 和 128。初始学习率设为 2e-3,并在训练过程中通过余弦衰减调度器进行调整。
每组实验重复 3 次,并报告总体性能。更详细的实现细节见附录 C。
性能表现
在类别不均衡半监督学习场景下,我们将 AllMatch 与多个强基线方法进行了比较,包括 FixMatch、FlexMatch、SoftMatch 和 FreeMatch。表 3 中的结果表明,AllMatch 在所有基准测试上都达到了当前最先进的性能。
尤其值得注意的是,在 CIFAR-10-LT 上,当 γ = 100 \gamma=100 γ=100 和 γ = 150 \gamma=150 γ=150 时,AllMatch 分别比第二优方法高出 1.69% 和 1.65%,这突显了它在处理严重类别不均衡问题时的鲁棒性。
此外,正如附录 B 所示,AllMatch 与现有的不均衡半监督学习算法具有良好的兼容性,二者结合后还能进一步增强模型抵抗严重不均衡的能力。
在不均衡半监督学习场景中持续表现出的优异性能表明,AllMatch 能够有效应对真实世界中的相关挑战。
4.3 消融实验
在这一部分中,我们系统地评估了 AllMatch 的各个组成模块。此外,关于 K K K(候选类别数量的上界)和 λ b \lambda_b λb(BCC 正则化的权重)的网格搜索结果,我们在附录 A.1 和 A.2 中给出。
组件分析
我们在四个具有挑战性的数据集上开展了消融实验:CIFAR-10(10 个标签)、CIFAR-100(400 个标签)、STL-10(40 个标签) 以及 CIFAR-10-LT(不平衡率为 150)。为简便起见,在后续分析中,我们将这四个基准上的性能分别记为 (a, b, c, d)。
如表 4 所示,CAT 中的全局估计步骤(第 2 行)相比第 1 行的基线模型,分别带来了 (7.35%, 8.00%, 16.45%, 1.20%) 的性能提升。如此显著的改进凸显了:使阈值与模型的全局学习状态保持一致具有关键作用。
进一步地,CAT 中的局部调整步骤(第 3 行)又额外带来了 (3.22%, 1.46%, 6.95%, 1.90%) 的增益,这表明该步骤能够有效捕捉类别特异的学习难度,并促进那些学习较为困难类别的训练。
此外,BCC 正则化实现了无标签数据 100% 的利用率,并进一步带来了 (2.25%, 0.52%, 0.71%, 0.77%) 的性能提升。其中,在 CIFAR-10 仅有 10 个标签时观察到的显著提升,表明 BCC 正则化在标注数据极其有限的场景下具有很大潜力。
总体而言,表 4 的结果验证了所提出各模块的有效性,以及它们在 AllMatch 中结合使用所带来的优势。
阈值策略的对比研究
我们从两个方面对现有阈值机制进行了对比分析。
首先,我们将本文提出的 CAT 与先前模型中采用的阈值策略进行了直接比较,结果见表 5 的第 1–4 行。
其次,我们在 AllMatch 框架下评估这些阈值策略,即将现有阈值方案与 BCC 正则化相结合,结果见表 5 的第 5–8 行。
从这两个角度来看,AllMatch 在大多数情况下均优于先前模型,说明所提出的 CAT 是有效的。此外,BCC 正则化还能进一步提升已有方法的性能,这表明它具有良好的兼容性,并且有助于排除错误选项。
4.4 定量分析
为了更深入地理解 AllMatch,我们在 CIFAR-10(40 个标签) 和 STL-10(40 个标签) 上展示了多种训练指标,如图 4 所示。此外,CIFAR-10(10 个标签) 和 CIFAR-100(400 个标签) 上的相关指标见附录 A.3。
从图 4(a) 和图 4(e) 可以观察到,阈值呈现出预期的变化行为:初始值较小,随后逐渐增大。此外,与其他基于类别特异阈值的模型相比,AllMatch 的阈值演化更加平滑,这意味着其对学习状态的估计更优。
另外,相比于以往算法,图 4(b) 与图 4©,以及图 4(f) 与图 4(g) 表明,AllMatch 在伪标签准确率和无标签数据利用率两方面都取得了提升。值得注意的是,图 4(b) 和图 4(f) 显示,以往模型在训练后期普遍会受到噪声伪标签过拟合的困扰,而 AllMatch 成功缓解了这一问题。
进一步地,如图 4(d) 和图 4(h) 所示,“候选类—负类划分”的准确率始终高于伪标签准确率,这表明 BCC 正则化能够有效地为所有无标签数据识别候选类别。
总体来看,CAT 能够精确反映模型的学习状态,而 BCC 正则化则为所有无标签样本提供了准确的监督信号。
此外,为了对 AllMatch 进行更全面的分析,我们还在附录 A.4 和 A.5 中给出了 STL-10(40 个标签) 上的特征可视化 [Van der Maaten and Hinton, 2008] 以及混淆矩阵。
5 结论
本文重新审视了以往的半监督学习算法,并聚焦于两个关键问题:如何设计有效的阈值机制,以及如何利用那些被赋予较低置信度的伪标签。
为了解决这些挑战,我们提出了两种策略:类别特异的自适应阈值(CAT)和二分类一致性(BCC)正则化。
其中,CAT 利用无标签数据上的预测结果和分类器权重,构建了一种能够与各类别不断演化的学习状态相匹配的阈值机制。BCC 正则化则为每个无标签样本识别候选类别,并鼓励同一样本在不同扰动视图下保持一致的“候选类—负类”划分。
在这两个模块的共同作用下,本文提出的 AllMatch 最大化了无标签数据的利用率,并取得了出色的伪标签准确率。我们在多个基准数据集上开展了广泛实验,涵盖类别均衡和类别不均衡两种设置。实验结果表明,AllMatch 达到了当前最先进的性能,并具备应对真实世界挑战的能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)