AI 基础知识十三 Transformer注意力机制(Attention)
注意力机制
Transformer 的核心是自注意力与多头注意力,让序列每个位置都能动态关注全局相关信息,并行捕捉长程依赖。
自注意力公式
多头注意力公式
计算步骤
参照论文说明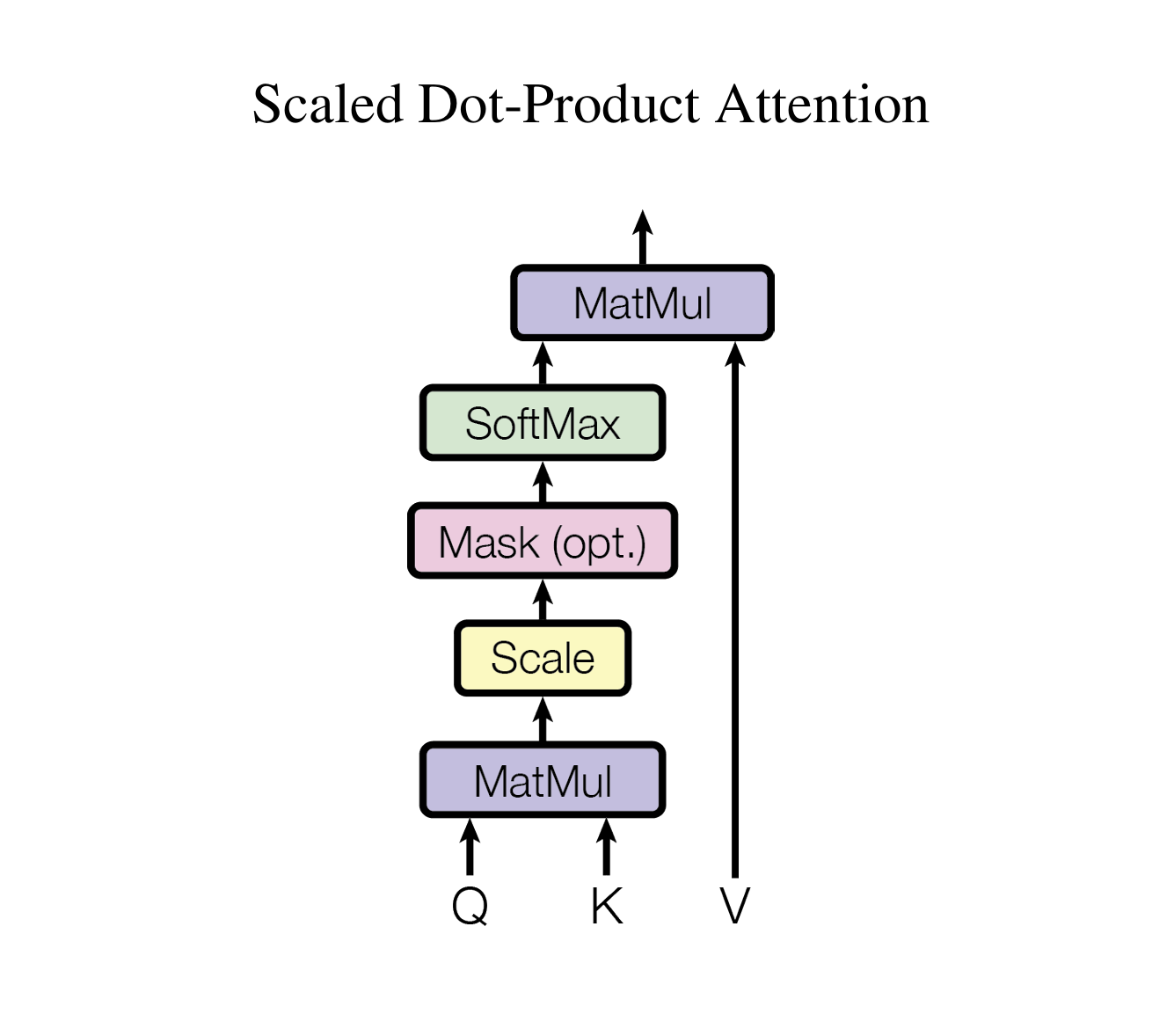
1. Q、 K矩阵相乘
2. 缩放处理
3. 加掩码处理 是可选项
4. Softmax 归一化指数函数
5. 与V矩阵相乘
本着简单的原则,用一个实例来说明Q,K,V计算过程
实例
自注意力
实现代码
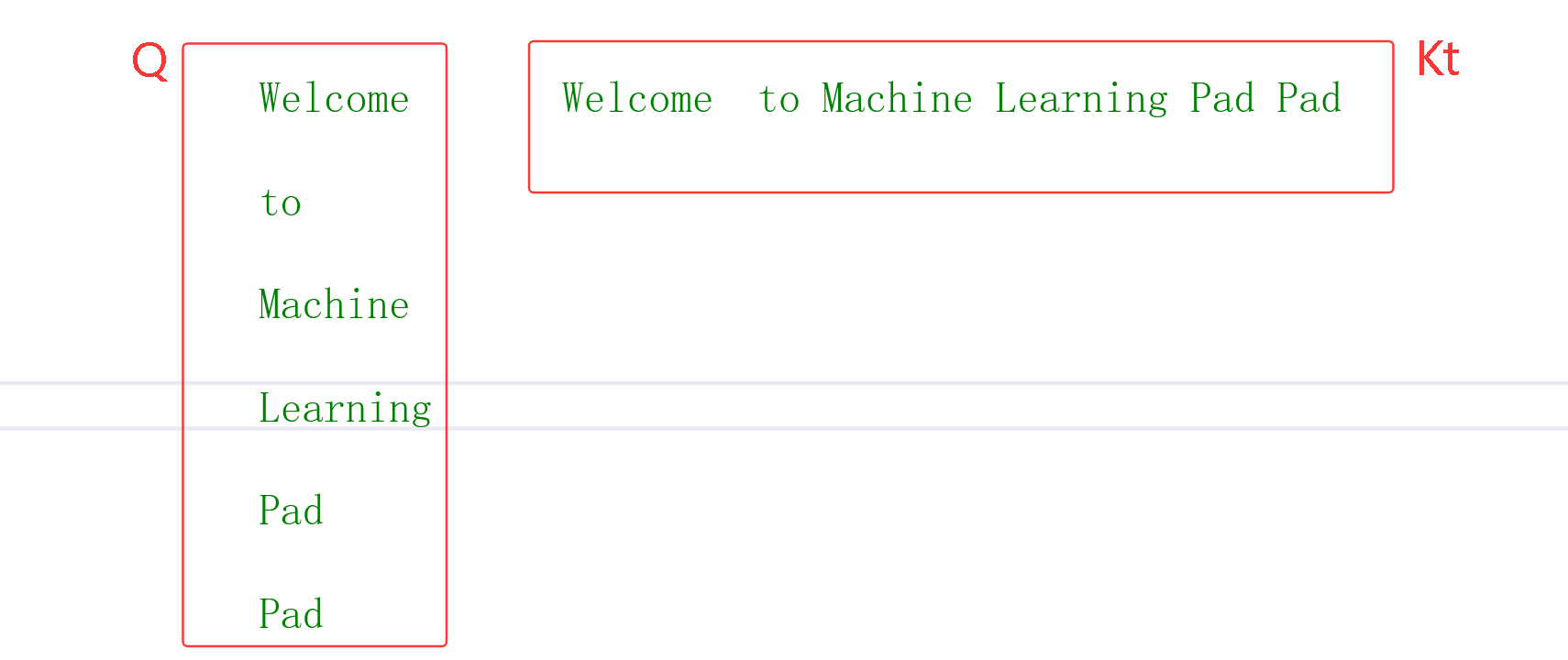
例子 "Welcome to Machine Learning Pad Pad" 经过 词嵌入和位置编码,得到6X4矩阵,为了方便计算对这个矩阵手动设置特定的数据
/*
{"Pad", 0},
{"Welcome", 1},
{"to", 2},
{"Machine", 3},
{"Learning", 4}
1. Welcome to Machine Learning Pad Pad -- > [1,2,3,4,0,0]
2. Embedding + PositionalEncoding -> x
3. x: [6 ,4]
*/
auto x = torch::tensor({
{{1.0, 0.0, 0.0, 0.0}, // Welcome
{2.0, 0.0, 0.0, 0.0}, // to
{3.0, 0.0, 0.0, 0.0}, // Machine
{4.0, 0.0, 0.0, 0.0}, // Learning
{0.0, 0.0, 0.0, 0.0}, // Pad
{0.0, 0.0, 0.0, 0.0} // Pad
} }, torch::kFloat);
Q,K,V是一组权重 它的词嵌入的维度,为了方便计算都它们设定单位矩阵
class SelfAttention : public torch::nn::Module
{
public:
SelfAttention()
{
}
void InitQKV(int64_t dim)
{
auto linear = torch::nn::LinearOptions(dim, dim).bias(false);
Q = register_module("q", torch::nn::Linear(linear));
K = register_module("k", torch::nn::Linear(linear));
V = register_module("v", torch::nn::Linear(linear));
norm_fact = 1.0 / sqrt(dim); // 缩放
auto onesw = torch::eye(dim); //单位矩阵
Q->weight.set_data(onesw);
K->weight.set_data(onesw);
V->weight.set_data(onesw);
}
torch::nn::Linear Q{ nullptr };
torch::nn::Linear K{ nullptr };
torch::nn::Linear V{ nullptr };
double norm_fact = 0 ;
};
torch::nn::Transformer 要求输入张量形状[seq, batch, dim],这里简单化为[seq,dim]
参照论文实现计算步骤
auto forward(torch::Tensor x,torch::Tensor mask = {})
{
torch::Tensor q ;
torch::Tensor k ;
torch::Tensor v;
torch::Tensor kt;
torch::Tensor out;
auto dim = x.dim();
// x: [seq, dim]
InitQKV(x.size(1));
/// 1.输入x 与 q k v 运算 q k v是 单位矩阵所以 q k v = x
q = Q->forward(x);
k = K->forward(x);
v = V->forward(x);
cout << "q k v \n" << q << endl;
kt = k.transpose(0, 1);// kt 是 k 的置换矩阵 kt: [dim,seq]
cout << "kt \n" << kt << endl;
auto attn_score = torch::matmul(q, kt); //2. q:[seq, dim] X kt: [dim,seq] -> [seq, seq]
cout << "q X kt \n" << attn_score << endl;
attn_score = attn_score * norm_fact; //3. 矩阵缩放
cout << "scale q.X.kt \n" << attn_score << endl;
if (mask.defined())
{
attn_score += mask;
}
attn_score = torch::softmax(attn_score, -1);//4. Softmax 归一化指数函数
cout << "torch::softmax q.X.kt \n" << attn_score << endl;
out = torch::matmul(attn_score, v); /// 5.与V矩阵相乘 [seq, seq] X v:[seq, dim] -> [seq, dim]
cout << "torch::matmul V \n" << out << endl;
return out;
}
重点解析
1. =
=
实际意义是
矩阵相乘结果
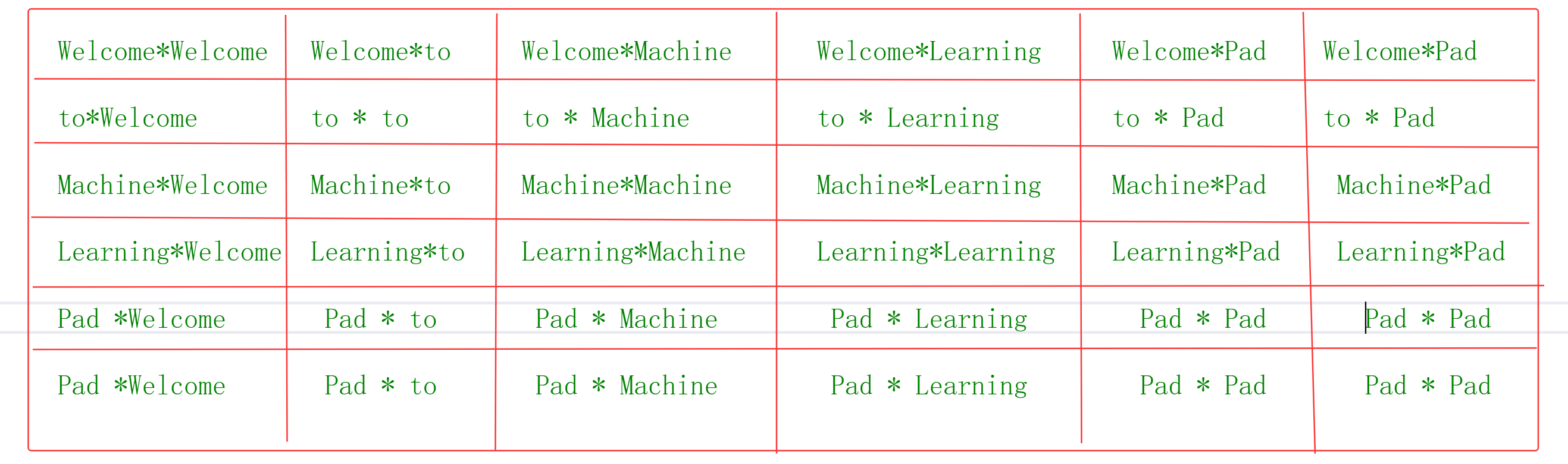
每个字符都能其他字符产生运算,也就是它能根据上下文来确定语意,字符序列长度N,Transformer时间复杂度为
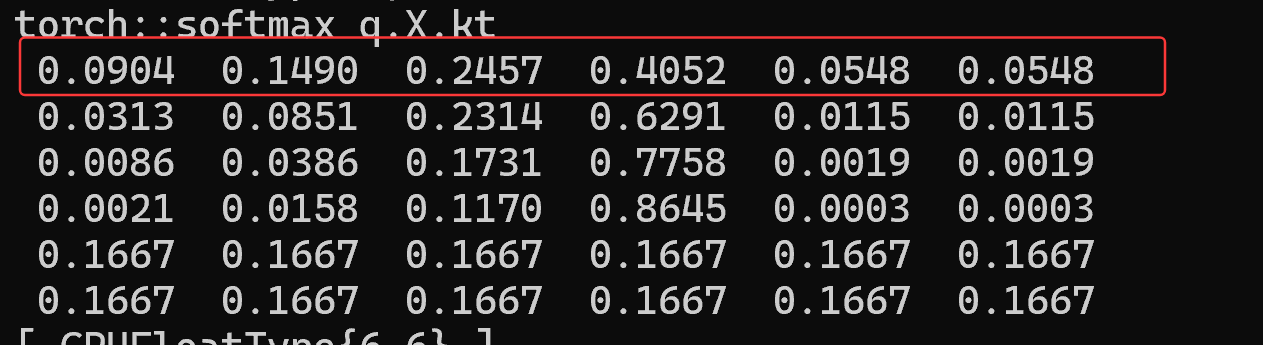
4. Softmax 归一化指数函数
数学公: 式 输入向量
=
第 i 个元素的 Softmax 输出为
每行内所有数据相加等于1, 原数据按一定比例缩小
5. 与V矩阵相乘
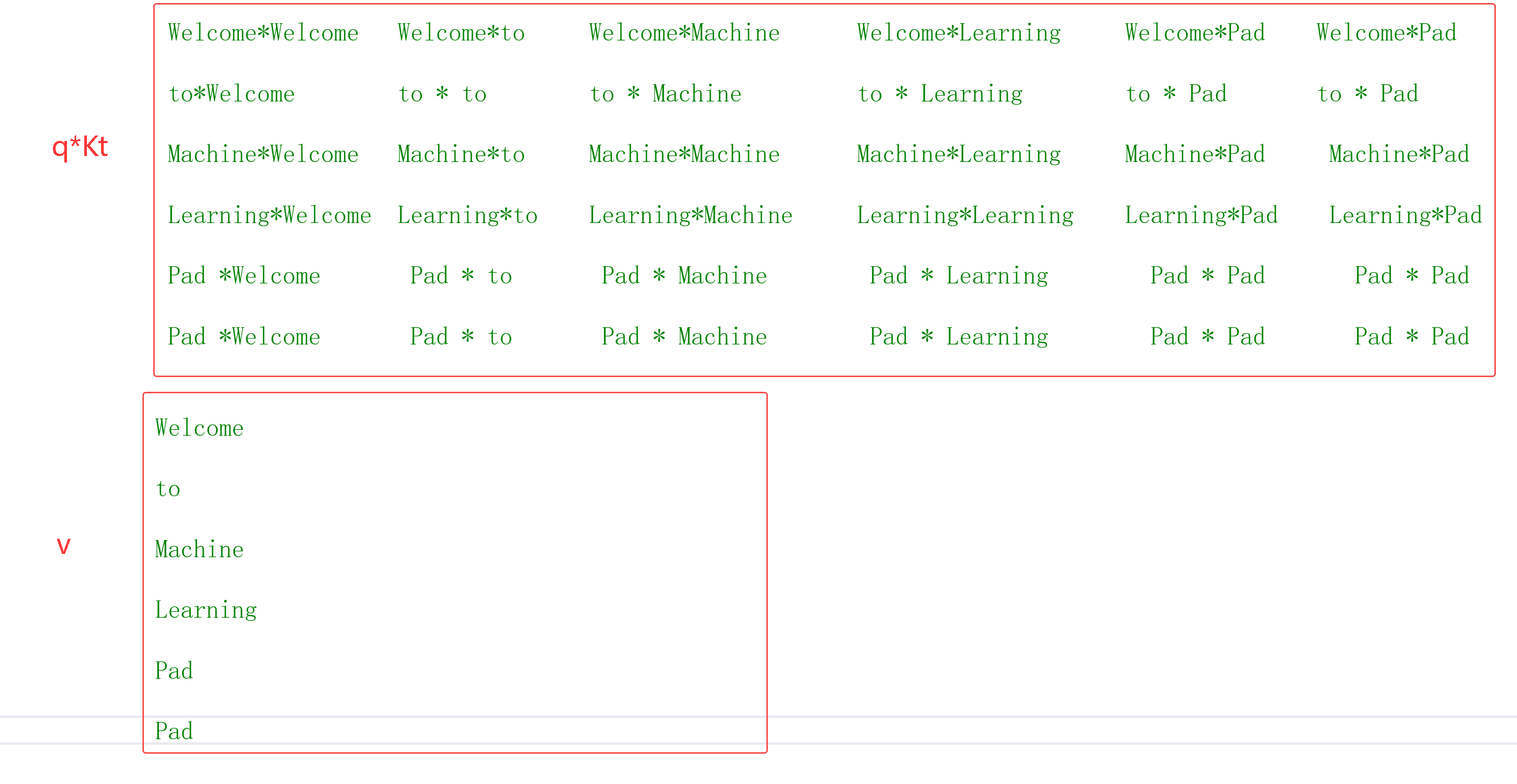
qkv现在全部建立关系了
当要求输入张量形状[seq, batch, dim]时,其流程都一样,要变换处理张量
高维张量矩阵相乘
公式: a[..,..., M,N] * b[...,...,N, K] = [..,...,M, K] 看到最后两维和两维矩阵相乘一样
整理之的代码,支持两三维输入张量
auto forward(torch::Tensor x,torch::Tensor mask = {})
{
torch::Tensor q ;
torch::Tensor k ;
torch::Tensor v;
torch::Tensor kt;
torch::Tensor out;
auto dim = x.dim();
if (dim == 3)
{
//x: [batch, seq, dim] ---> [seq, batch, dim]
x = x.permute({1,0,2});
InitQKV(x.size(2));
}
else
{
// x: [seq, dim]
InitQKV(x.size(1));
}
/// 1.输入x 与 q k v 运算 q k v是 单位矩阵所以 q k v = x
q = Q->forward(x);
k = K->forward(x);
v = V->forward(x);
cout << "q k v \n" << q << endl;
if (dim == 3)
{
kt = k.permute({ 1,2,0 });
v = v.permute({ 1,0,2 });
}
else
{
kt = k.transpose(0, 1);// kt 是 k 的置换矩阵 kt: [dim,seq]
}
cout << "kt \n" << kt << endl;
auto attn_score = torch::matmul(q, kt); //2.
cout << "q X kt \n" << attn_score << endl;
attn_score = attn_score * norm_fact; //3. 矩阵缩放
cout << "scale q.X.kt \n" << attn_score << endl;
if (mask.defined())
{
attn_score += mask;
}
attn_score = torch::softmax(attn_score, -1);//4. Softmax 归一化指数函数
cout << "torch::softmax q.X.kt \n" << attn_score << endl;
out = torch::matmul(attn_score, v); /// 5. qKt * V
cout << "torch::matmul V \n" << out << endl;
return out;
}
多头注意力
在“自注意力”的基础上增加
1. 维度被为多份 分别用于Q K V 计算
2.将多份重新拼接
3.最后加输出投影
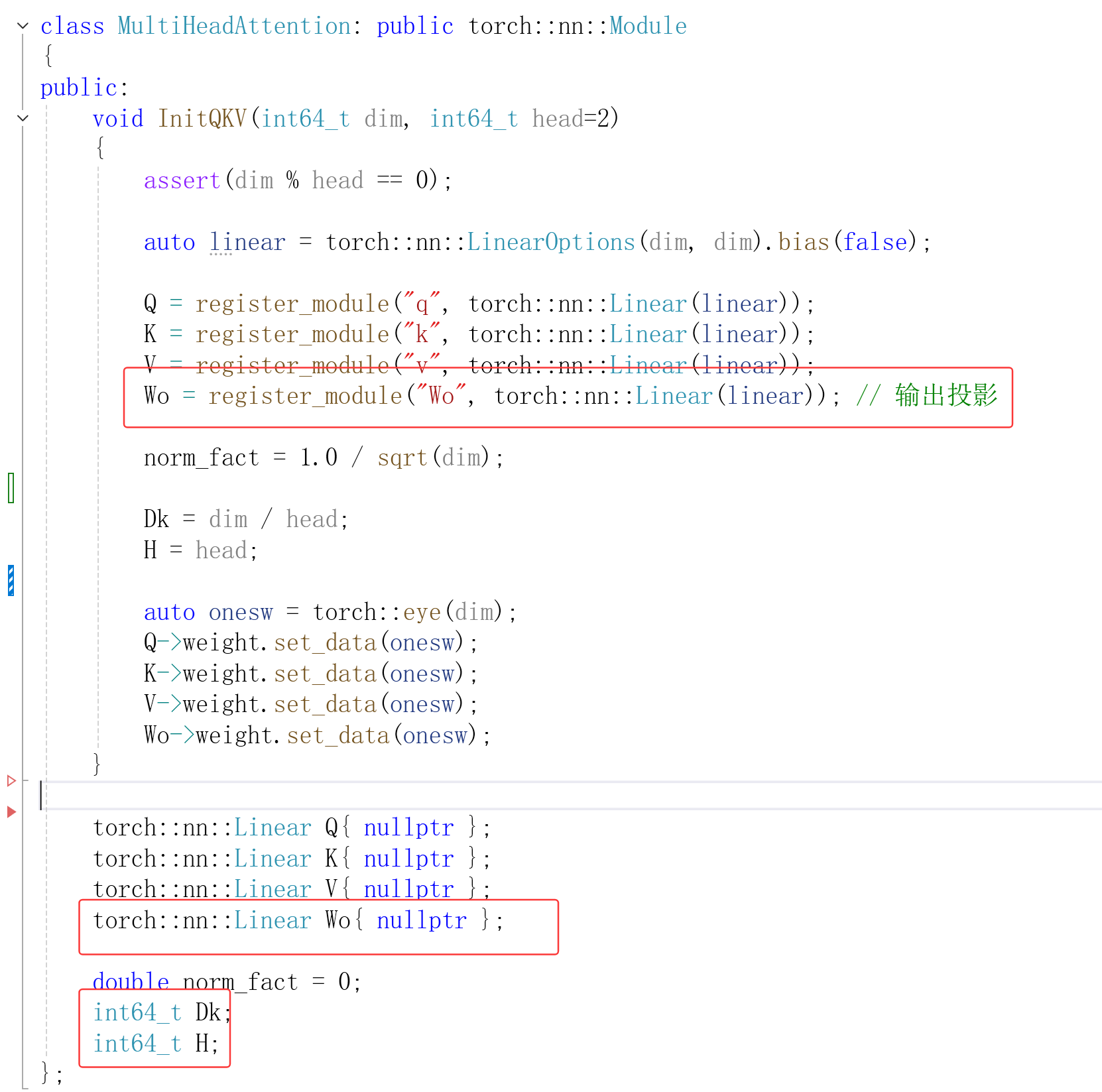
输入两维张量时,写一个函数forward
1. 输入张量x形状 [seq, dim], q、k、v 形状 [seq, dim]
2. 将q、k、v 拆分成 [H, S, Dk] , seq简写S, H:头数量, Dk = dim/ H
q = q.view({ seq,H,Dk }); //q: [seq, dim] -> [S, H, Dk]
k = k.view({ seq,H,Dk });
v = v.view({ seq,H,Dk });
q = q.permute({ 1,0,2 }); //[S, H, Dk] --->[H, S, Dk]
k = k.permute({ 1,0,2 });
v = v.permute({ 1,0,2 });3. 调 形状 [H, Dk, S]
auto kt = k.permute({ 0,2,1 }); //kt: [H, S, Dk] --> [H, Dk, S]4. 与V矩阵相乘之后 输出形状 [H, S, Dk],要转换成 [S, H, Dk]
auto out = torch::matmul(attn_score, v); // [H, S, S] * [H, S, Dk] -> out: [H, S, Dk]5. [S, H, Dk] 拼接成 [seq, dim],最后输出投影
out = out.transpose(1, 0).contiguous().view({ seq, dim }); // [H, S, Dk] --> [S, H, Dk] -> [seq, dim]
cout << "torch::matmul QK * V \n" << out.squeeze() << endl;
out = Wo->forward(out);
输入三维张量时,写一个函数forward2去实现,除了张量形状调整不同外其他都一样,实现细节只能看代码
auto forward(torch::Tensor x, int64_t head = 2, torch::Tensor mask = {})
{
x.squeeze_(); //x: [batch, seq ,dim] --> [seq, dim]
assert(x.dim() == 2);
//x: [seq, dim]
InitQKV(x.size(1), head);
auto seq = x.size(0);
auto dim = x.size(1);
auto q = Q->forward(x);
auto k = K->forward(x);
auto v = V->forward(x);
q = q.view({ seq,H,Dk }); //q: [seq, dim] -> [S, H, Dk]
k = k.view({ seq,H,Dk });
v = v.view({ seq,H,Dk });
q = q.permute({ 1,0,2 }); //[S, H, Dk] --->[H, S, Dk]
k = k.permute({ 1,0,2 });
v = v.permute({ 1,0,2 });
cout << "q k v \n" << q << endl;
auto kt = k.permute({ 0,2,1 }); //kt: [H, S, Dk] --> [H, Dk, S]
cout << "kt \n" << kt << endl;
auto attn_score = torch::matmul(q, kt); // [H, S, Dk] * [H, Dk, S]
cout << "q X kt \n" << attn_score << endl;
attn_score = attn_score * norm_fact;
cout << "scale q.X.kt \n" << attn_score << endl;
if (mask.defined())
{
attn_score += mask;
}
attn_score = torch::softmax(attn_score, -1); /// attn_score: [H, S, S]
cout << "torch::softmax q.X.kt \n" << attn_score.squeeze() << endl;
auto out = torch::matmul(attn_score, v); // [H, S, S] * [H, S, Dk] -> out: [H, S, Dk]
out = out.transpose(1, 0).contiguous().view({ seq, dim }); // [H, S, Dk] --> [S, H, Dk] -> [seq, dim]
cout << "torch::matmul QK * V \n" << out.squeeze() << endl;
out = Wo->forward(out);
return out;
}
auto forward2(torch::Tensor x, int64_t head = 2,torch::Tensor mask = {})
{
assert(x.dim() == 3);
x = x.permute({ 1,0,2 }); // x: x: [batch, seq, dim]--> [seq, batch, dim]
InitQKV(x.size(2), head);
auto seq = x.size(0);
auto batch = x.size(1);
auto dim = x.size(2);
auto q = Q->forward(x);
auto k = K->forward(x);
auto v = V->forward(x);
q = q.view({ seq,batch,H,Dk}); //q: [seq, batch, dim] -> [S, B, H, Dk]
k = k.view({ seq,batch,H,Dk });
v = v.view({ seq,batch,H,Dk });
q = q.permute({1,2,0,3}); //[S, B, H, Dk] --->[B, H, S, Dk]
k = k.permute({ 1,2,0,3 });
v = v.permute({ 1,2,0,3 });
cout << "q k v \n" << q << endl;
auto kt = k.permute({ 0,1,3,2}); //kt: [B, H, S, Dk] --> [B, H, Dk, S]
cout << "kt \n" << kt.squeeze() << endl;
auto attn_score = torch::matmul(q, kt);
cout << "q X kt \n" << attn_score << endl;
attn_score = attn_score * norm_fact;
cout << "scale q.X.kt \n" << attn_score << endl;
if (mask.defined())
{
attn_score += mask;
}
attn_score = torch::softmax(attn_score, -1); /// attn_score: [B, H, S, S]
cout << "torch::softmax q.X.kt \n" << attn_score << endl;
auto out = torch::matmul(attn_score, v); // [B, H, S, S] * [B, H, S, Dk] -> out: [B, H, S, Dk]
out = out.transpose(1, 2).contiguous().view({ seq,batch, dim }); // [B, H, S, Dk] --> [B, S, H, Dk] -> [seq,batch, dim]
cout << "torch::matmul QK * V \n" << out << endl;
out = Wo->forward(out);
return out;
}
完整代码
#include <torch/torch.h>
#include <iostream>
#include <torch/serialize.h>
#include <regex>
//#include <iostream>
#include <fstream>
using namespace std;
class FeedForwardNet : public torch::nn::Module
{
//Q = register_module("q", torch::nn::Linear(linear));
};
class SelfAttention : public torch::nn::Module
{
public:
SelfAttention()
{
}
void InitQKV(int64_t dim)
{
auto linear = torch::nn::LinearOptions(dim, dim).bias(false);
Q = register_module("q", torch::nn::Linear(linear));
K = register_module("k", torch::nn::Linear(linear));
V = register_module("v", torch::nn::Linear(linear));
norm_fact = 1.0 / sqrt(dim); // 缩放
auto onesw = torch::eye(dim); //单位矩阵
Q->weight.set_data(onesw);
K->weight.set_data(onesw);
V->weight.set_data(onesw);
}
auto forward(torch::Tensor x,torch::Tensor mask = {})
{
torch::Tensor q ;
torch::Tensor k ;
torch::Tensor v;
torch::Tensor kt;
torch::Tensor out;
auto dim = x.dim();
if (dim == 3)
{
//x: [batch, seq, dim] ---> [seq, batch, dim]
x = x.permute({1,0,2});
InitQKV(x.size(2));
}
else
{
// x: [seq, dim]
InitQKV(x.size(1));
}
/// 1.输入x 与 q k v 运算 q k v是 单位矩阵所以 q k v = x
q = Q->forward(x);
k = K->forward(x);
v = V->forward(x);
cout << "q k v \n" << q << endl;
if (dim == 3)
{
kt = k.permute({ 1,2,0 });
v = v.permute({ 1,0,2 });
}
else
{
kt = k.transpose(0, 1);// kt 是 k 的置换矩阵 kt: [dim,seq]
}
cout << "kt \n" << kt << endl;
auto attn_score = torch::matmul(q, kt); //2.
cout << "q X kt \n" << attn_score << endl;
attn_score = attn_score * norm_fact; //3. 矩阵缩放
cout << "scale q.X.kt \n" << attn_score << endl;
if (mask.defined())
{
attn_score += mask;
}
attn_score = torch::softmax(attn_score, -1);//4. Softmax 归一化指数函数
cout << "torch::softmax q.X.kt \n" << attn_score << endl;
out = torch::matmul(attn_score, v); /// 5. qKt * V
cout << "torch::matmul V \n" << out << endl;
return out;
}
torch::nn::Linear Q{ nullptr };
torch::nn::Linear K{ nullptr };
torch::nn::Linear V{ nullptr };
double norm_fact = 0 ;
};
class MultiHeadAttention: public torch::nn::Module
{
public:
void InitQKV(int64_t dim, int64_t head=2)
{
assert(dim % head == 0);
auto linear = torch::nn::LinearOptions(dim, dim).bias(false);
Q = register_module("q", torch::nn::Linear(linear));
K = register_module("k", torch::nn::Linear(linear));
V = register_module("v", torch::nn::Linear(linear));
Wo = register_module("Wo", torch::nn::Linear(linear)); // 输出投影
norm_fact = 1.0 / sqrt(dim);
Dk = dim / head;
H = head;
auto onesw = torch::eye(dim);
Q->weight.set_data(onesw);
K->weight.set_data(onesw);
V->weight.set_data(onesw);
Wo->weight.set_data(onesw);
}
auto forward(torch::Tensor x, int64_t head = 2, torch::Tensor mask = {})
{
x.squeeze_(); //x: [batch, seq ,dim] --> [seq, dim]
assert(x.dim() == 2);
//x: [seq, dim]
InitQKV(x.size(1), head);
auto seq = x.size(0);
auto dim = x.size(1);
auto q = Q->forward(x);
auto k = K->forward(x);
auto v = V->forward(x);
q = q.view({ seq,H,Dk }); //q: [seq, dim] -> [S, H, Dk]
k = k.view({ seq,H,Dk });
v = v.view({ seq,H,Dk });
q = q.permute({ 1,0,2 }); //[S, H, Dk] --->[H, S, Dk]
k = k.permute({ 1,0,2 });
v = v.permute({ 1,0,2 });
cout << "q k v \n" << q << endl;
auto kt = k.permute({ 0,2,1 }); //kt: [H, S, Dk] --> [H, Dk, S]
cout << "kt \n" << kt << endl;
auto attn_score = torch::matmul(q, kt); // [H, S, Dk] * [H, Dk, S]
cout << "q X kt \n" << attn_score << endl;
attn_score = attn_score * norm_fact;
cout << "scale q.X.kt \n" << attn_score << endl;
if (mask.defined())
{
attn_score += mask;
}
attn_score = torch::softmax(attn_score, -1); /// attn_score: [H, S, S]
cout << "torch::softmax q.X.kt \n" << attn_score.squeeze() << endl;
auto out = torch::matmul(attn_score, v); // [H, S, S] * [H, S, Dk] -> out: [H, S, Dk]
out = out.transpose(1, 0).contiguous().view({ seq, dim }); // [H, S, Dk] --> [S, H, Dk] -> [seq, dim]
cout << "torch::matmul QK * V \n" << out.squeeze() << endl;
out = Wo->forward(out);
return out;
}
auto forward2(torch::Tensor x, int64_t head = 2,torch::Tensor mask = {})
{
assert(x.dim() == 3);
x = x.permute({ 1,0,2 }); // x: x: [batch, seq, dim]--> [seq, batch, dim]
InitQKV(x.size(2), head);
auto seq = x.size(0);
auto batch = x.size(1);
auto dim = x.size(2);
auto q = Q->forward(x);
auto k = K->forward(x);
auto v = V->forward(x);
q = q.view({ seq,batch,H,Dk}); //q: [seq, batch, dim] -> [S, B, H, Dk]
k = k.view({ seq,batch,H,Dk });
v = v.view({ seq,batch,H,Dk });
q = q.permute({1,2,0,3}); //[S, B, H, Dk] --->[B, H, S, Dk]
k = k.permute({ 1,2,0,3 });
v = v.permute({ 1,2,0,3 });
cout << "q k v \n" << q << endl;
auto kt = k.permute({ 0,1,3,2}); //kt: [B, H, S, Dk] --> [B, H, Dk, S]
cout << "kt \n" << kt.squeeze() << endl;
auto attn_score = torch::matmul(q, kt);
cout << "q X kt \n" << attn_score << endl;
attn_score = attn_score * norm_fact;
cout << "scale q.X.kt \n" << attn_score << endl;
if (mask.defined())
{
attn_score += mask;
}
attn_score = torch::softmax(attn_score, -1); /// attn_score: [B, H, S, S]
cout << "torch::softmax q.X.kt \n" << attn_score << endl;
auto out = torch::matmul(attn_score, v); // [B, H, S, S] * [B, H, S, Dk] -> out: [B, H, S, Dk]
out = out.transpose(1, 2).contiguous().view({ seq,batch, dim }); // [B, H, S, Dk] --> [B, S, H, Dk] -> [seq,batch, dim]
cout << "torch::matmul QK * V \n" << out << endl;
out = Wo->forward(out);
return out;
}
torch::nn::Linear Q{ nullptr };
torch::nn::Linear K{ nullptr };
torch::nn::Linear V{ nullptr };
torch::nn::Linear Wo{ nullptr };
double norm_fact = 0;
int64_t Dk;
int64_t H;
};
void TransformerAttentionMain()
{
auto x = torch::tensor({
{{1.0, 0.0, 0.0, 0.0}, // Welcome
{2.0, 0.0, 0.0, 0.0}, // to
{3.0, 0.0, 0.0, 0.0}, // Machine
{4.0, 0.0, 0.0, 0.0}, // Learning
{0.0, 0.0, 0.0, 0.0}, // Pad
{0.0, 0.0, 0.0, 0.0} // Pad
} }, torch::kFloat);
cout << "input\n" << x << endl;
cout << "-------------SelfAttention--------------------\n" << endl;
auto x1 = x.squeeze();
auto atten= SelfAttention();
auto y = atten.forward(x1);
cout << "-------------SelfAttention--------------------\n" << endl;
cout << "\n\n-------------MultiHeadAttention--------------------\n" << endl;
auto multiAtten = MultiHeadAttention();
multiAtten.forward2(x,1);
cout << "-------------MultiHeadAttention--------------------\n" << endl;
}
感谢大家的支持,如要问题欢迎提问指正。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)