OpenCV 实现人脸识别:LBPH/Eigen/Fisher 三大算法实战详解
在人工智能飞速发展的今天,人脸识别已经成为我们生活中无处不在的技术 —— 手机解锁、刷脸支付、门禁考勤、安防监控等场景,都离不开人脸识别技术的支撑。对于 Python 开发者而言,OpenCV 库提供了开箱即用的人脸识别接口,无需深入底层算法原理,就能快速实现简易的人脸检测与识别功能。
本文将基于 OpenCV 库,手把手带你实现LBPH、EigenFace、FisherFace三种经典的人脸识别算法,从环境搭建、数据准备、代码编写到效果测试,全程实战讲解。同时解决 OpenCV 原生不支持中文标注的痛点,实现中文识别结果可视化展示。无论你是 Python 初学者,还是计算机视觉入门爱好者,都能通过本文快速掌握人脸识别的基础实现方法。
一、环境准备与核心库介绍
1.1 核心库与算法原理
- OpenCV:开源计算机视觉库,内置了三种经典的静态人脸识别算法,无需训练复杂模型,适合轻量级人脸识别场景;
- NumPy:Python 数值计算基础库,用于处理图像数据的数组转换,满足算法训练的数据格式要求;
- PIL:Python 图像处理库,弥补 OpenCV 无法直接绘制中文的缺陷,实现识别结果中文标注;
三大人脸识别算法核心区别
- LBPH(局部二值模式直方图):基于局部纹理特征,对光照、姿态变化鲁棒性强,支持任意尺寸图像,是最常用的人脸识别算法;
- EigenFace(特征脸):基于主成分分析(PCA),将人脸降维为特征向量,计算速度快,但对图像尺寸、光照要求严格;
- FisherFace(费舍尔脸):基于线性判别分析(LDA),在 EigenFace 基础上优化了分类能力,区分不同人脸的效果更优,同样要求图像尺寸统一。
二、数据集准备
人脸识别的第一步是准备训练数据,我们采用二分类人脸数据集,区分迪丽热巴和杨幂两位人物,数据集结构如下:
train_data/
├─ 0/ # 标签0:迪丽热巴
│ ├─ rb.png
│ ├─ rb1.png
│ └─ rb2.png
└─ 1/ # 标签1:杨幂
├─ ym1.png
├─ ym2.png
└─ ym3.png
数据集要求
- 所有图片均为灰度图像(人脸识别算法对灰度图处理效率更高);
- EigenFace 和 FisherFace 算法要求所有训练图像、预测图像尺寸完全一致;
- 图片中仅包含单一人脸,无过多背景干扰,保证识别准确率。
小贴士:建议提前用截图工具裁剪人脸区域,剔除多余背景,提升识别准确率。
三、算法一:LBPH 人脸识别实现
LBPH 是 OpenCV 中最灵活、最易用的人脸识别算法,无需统一图像尺寸,对环境适应性最强,适合入门首选。
3.1 完整代码实现
# 导入依赖库
import cv2
import numpy as np
# 1. 加载训练图像与标签
# 定义空列表存储训练图像
images = []
# 以灰度模式读取迪丽热巴的人脸图片(标签0)
images.append(cv2.imread('train_data/0/rb.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('train_data/0/rb1.png', cv2.IMREAD_GRAYSCALE))
# 以灰度模式读取杨幂的人脸图片(标签1)
images.append(cv2.imread('train_data/1/ym1.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('train_data/1/ym2.png', cv2.IMREAD_GRAYSCALE))
# 定义标签:与图像一一对应,0=迪丽热巴,1=杨幂
labels = [0, 0, 1, 1]
# 定义结果映射字典
dic = {0: '迪丽热巴', 1: '杨幂', -1: '无法识别'}
# 2. 加载待预测的图像
predict_img = cv2.imread('train_data/1/ym3.png', cv2.IMREAD_GRAYSCALE)
# 3. 初始化LBPH人脸识别器
# threshold:置信度阈值,超过该值则判定为无法识别
recognizer = cv2.face.LBPHFaceRecognizer_create(threshold=80)
# 4. 训练模型
# 传入训练图像列表和标签数组(需转换为numpy数组)
recognizer.train(images, np.array(labels))
# 5. 执行预测
# 返回值:预测标签、置信度
label, confidence = recognizer.predict(predict_img)
# 6. 输出结果
print('识别结果:', dic[label])
print('置信度:', confidence)
3.2 代码核心解析
- 图像读取:
cv2.IMREAD_GRAYSCALE表示以灰度模式读取图像,这是人脸识别的标准格式; - 标签定义:标签必须是整数类型,与训练图像一一对应,保证模型训练的准确性;
- LBPH 初始化:
threshold为置信度阈值,数值越小,识别越严格,超过阈值则返回 - 1(无法识别); - 模型训练:
train()方法接收图像列表和 numpy 格式的标签数组,完成模型训练; - 预测结果:
predict()回预测标签和置信度,置信度数值越小,识别结果越准确。
3.3 运行结果
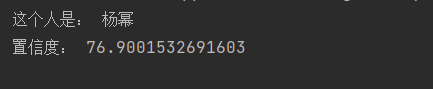
置信度 76.9001532691603 小于阈值 80,识别成功,结果准确。
四、算法二:EigenFace 人脸识别实现
EigenFace 是基于降维思想的人脸识别算法,必须保证所有图像尺寸完全一致,计算速度快,适合对性能要求高的场景。
4.1 完整代码实现
import cv2
import numpy as np
# 1. 统一图像尺寸并加载训练数据
images = []
# 读取图像并resize为统一尺寸(120,100)
a = cv2.imread('train_data/0/rb1.png', 0) # 0等价于IMREAD_GRAYSCALE
a = cv2.resize(a, (120, 100))
images.append(a)
b = cv2.imread('train_data/0/rb2.png', 0)
b = cv2.resize(b, (120, 100))
images.append(b)
c = cv2.imread('train_data/1/ym3.png', 0)
c = cv2.resize(c, (120, 100))
images.append(c)
d = cv2.imread('train_data/1/ym2.png', 0)
d = cv2.resize(d, (120, 100))
images.append(d)
# 定义标签
labels = [0, 0, 1, 1]
# 2. 加载并预处理预测图像(尺寸必须与训练图一致)
pre_image = cv2.imread('train_data/1/ym1.png', 0)
pre_image = cv2.resize(pre_image, (120, 100))
# 3. 初始化EigenFace识别器
recognizer = cv2.face.EigenFaceRecognizer_create(threshold=5000)
# 4. 训练与预测
recognizer.train(images, np.array(labels))
label, confidence = recognizer.predict(pre_image)
# 5. 结果映射与输出
dic = {0: '迪丽热巴', 1: '杨幂', -1: '无法识别'}
print('识别结果:', dic[label])
print('置信度:', confidence)
# 6. 可视化结果:在原图上标注识别结果
img = cv2.imread('train_data/1/ym1.png').copy()
# 添加英文文字(OpenCV原生不支持中文)
result_img = cv2.putText(img, 'ym', (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.9, (0, 0, 255), 2)
# 显示图像
cv2.imshow('xx', result_img)
cv2.waitKey(0) # 按下任意键关闭窗口
4.2 核心注意事项
- 尺寸统一:EigenFace 算法强制要求所有图像尺寸相同,必须使用
cv2.resize()预处理; - 阈值设置:EigenFace 的置信度数值较大,阈值通常设置为 5000 左右;
- 中文限制:OpenCV 原生
putText函数不支持中文,会显示为乱码,本文后续会解决该问题。
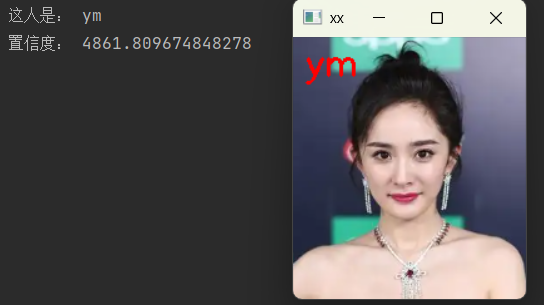
4.3 运行效果
控制台输出识别结果,弹窗显示带标注的人脸图像,直观展示识别效果。
五、算法三:FisherFace 人脸识别 + 中文标注实现
FisherFace 是 EigenFace 的优化版本,分类能力更强,同样要求图像尺寸统一。同时,我们通过 PIL 库解决OpenCV 中文标注乱码问题,实现专业的可视化效果。
5.1 中文标注核心函数
OpenCV 无法直接绘制中文,我们封装cv2AddChineseText函数,实现中文文字绘制:
from PIL import Image, ImageDraw, ImageFont
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
"""
OpenCV图像添加中文文字
:param img: OpenCV读取的图像
:param text: 中文文字内容
:param position: 文字位置(x,y)
:param textColor: 文字颜色(RGB)
:param textSize: 文字大小
:return: 带中文的OpenCV图像
"""
# 判断是否为OpenCV图像(numpy数组)
if isinstance(img, np.ndarray):
# 转换为PIL图像格式
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 创建绘图对象
draw = ImageDraw.Draw(img)
# 设置字体:宋体,支持中文
fontStyle = ImageFont.truetype('simsun.ttc', textSize, encoding='utf-8')
# 绘制中文
draw.text(position, text, textColor, font=fontStyle)
# 转换回OpenCV图像格式
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
5.2 FisherFace 完整代码
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
# 中文标注函数(同上)
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
if isinstance(img, np.ndarray):
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
fontStyle = ImageFont.truetype('simsun.ttc', textSize, encoding='utf-8')
draw.text(position, text, textColor, font=fontStyle)
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
# 封装图像加载与预处理函数
def image_preprocess(image_path, image_list):
# 读取灰度图
img = cv2.imread(image_path, 0)
# 统一尺寸:120x180
img = cv2.resize(img, (120, 180))
image_list.append(img)
# 1. 加载训练数据
images = []
image_preprocess('train_data/0/rb1.png', images)
image_preprocess('train_data/0/rb2.png', images)
image_preprocess('train_data/1/ym1.png', images)
image_preprocess('train_data/1/ym2.png', images)
labels = [0, 0, 1, 1]
# 2. 预处理预测图像
pre_image = cv2.imread('train_data/1/ym3.png', 0)
pre_image = cv2.resize(pre_image, (120, 180))
# 3. 初始化FisherFace识别器
recognizer = cv2.face.FisherFaceRecognizer_create(threshold=5000)
# 4. 训练与预测
recognizer.train(images, np.array(labels))
label, confidence = recognizer.predict(pre_image)
# 5. 结果处理
dic = {0: '迪丽热巴', 1: '杨幂', -1: '无法识别'}
print('识别结果:', dic[label])
print('置信度:', confidence)
# 6. 中文可视化
original_img = cv2.imread('train_data/1/ym3.png').copy()
# 添加中文标注
result_img = cv2AddChineseText(original_img, dic[label], (30, 10), textColor=(255, 0, 0), textSize=40)
# 显示最终效果
cv2.imshow('xx', result_img)
cv2.waitKey(0)
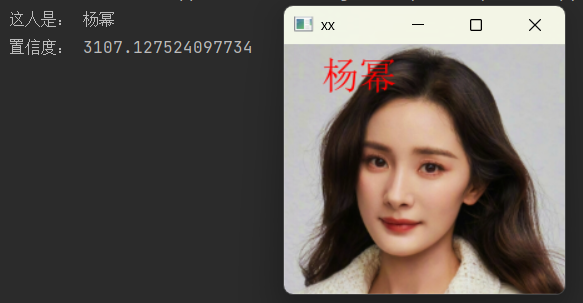
5.3 核心亮点
- 函数封装:将图像预处理封装为函数,代码更简洁、复用性更强;
- 中文标注:完美解决 OpenCV 中文乱码问题,展示专业的识别效果;
- 算法优化:FisherFace 相比 EigenFace,对相似人脸的区分能力更优,准确率更高。
六、三大算法对比与总结
6.1 算法性能对比表
| 算法 | 图像尺寸要求 | 光照适应性 | 计算速度 | 适用场景 |
|---|---|---|---|---|
| LBPH | 无要求 | 强 | 中等 | 通用场景、入门首选 |
| EigenFace | 必须统一 | 弱 | 快 | 性能优先、环境固定场景 |
| FisherFace | 必须统一 | 中等 | 中等 | 高精度分类场景 |
6.2 关键知识点总结
- 图像格式:人脸识别优先使用灰度图,减少计算量,提升效率;
- 置信度规则:三种算法的置信度数值越小,识别结果越准确;
- 阈值调整:LBPH 阈值建议 50-100,EigenFace/FisherFace 建议 5000 左右;
- 中文解决方案:通过 PIL 库转换图像格式,实现 OpenCV 中文标注;
- 数据集优化:人脸裁剪越精准、背景越干净,识别准确率越高。
七、拓展与进阶方向
本文实现的是静态人脸识别,基于本地图片完成训练与预测,在此基础上,你可以进一步拓展:
- 实时人脸识别:调用电脑摄像头,实现实时人脸检测与识别;
- 多分类识别:增加更多人物标签,实现多人脸识别;
- 人脸检测预处理:结合
cv2.CascadeClassifier实现自动人脸裁剪; - 模型保存:将训练好的模型保存为.xml 文件,无需重复训练;
- 深度学习人脸识别:基于 MTCNN、FaceNet 等深度学习模型,实现高精度识别。
结语
本文通过三段实战代码,详细讲解了 OpenCV 中 LBPH、EigenFace、FisherFace 三种人脸识别算法的实现方法,从环境搭建、数据准备到代码优化、中文可视化,覆盖了人脸识别的全流程。OpenCV 让人脸识别技术变得触手可及,即使是零基础的开发者,也能快速实现属于自己的人脸识别程序。
人脸识别是计算机视觉领域的经典应用,掌握基础算法后,你可以逐步深入深度学习领域,探索更强大的视觉技术。希望本文能为你的计算机视觉学习之路打下坚实的基础,动手实践起来,感受人工智能的魅力!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)