【世界模型】EarthCrafter: Scalable 3D Earth Generation via Dual-Sparse Latent Diffusion

标题: EarthCrafter:基于双稀疏潜在扩散的可扩展三维地球生成
原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/37663
源码链接:https://github.com/alibaba-damo-academy/earthcrafter
发表:AAAI-2026
摘要
尽管近期三维生成研究取得了显著进展,但将这类方法扩展至地理尺度(如建模数千平方公里的地球表面)仍是一项开放性挑战。本文通过数据基础设施与模型架构的双重创新解决该问题。首先,本文提出Aerial-Earth3D,即迄今为止规模最大的三维航空数据集,包含覆盖美国本土的5万条精选场景(单场景尺寸600米),总计4500万张谷歌地球多视角帧。每个场景均提供带位姿标注的多视角图像、深度图、法向量、语义分割结果与相机位姿,并经过严格质量控制以保证地形多样性。在此基础上,本文提出EarthCrafter,一款面向大规模三维地球生成的定制化框架,基于稀疏解耦潜在扩散实现。该架构将结构生成与纹理生成分离:1)双稀疏三维变分自编码器(3D-VAE)将高分辨率几何体素与纹理化二维高斯溅射(2DGS)压缩至紧凑潜在空间,大幅缓解超大地理尺度带来的高额计算负担,同时保留关键信息;2)本文提出条件感知流匹配模型,基于混合输入(语义、图像或无输入)训练,可独立灵活建模潜在几何与纹理特征。大量实验表明,EarthCrafter在超大规模生成任务中表现显著更优。该框架还支持多样化应用,从语义引导的城市布局生成到无条件地形合成,同时依托Aerial-Earth3D的丰富数据先验保证地理合理性。
项目地址:https://github.com/whiteinblue/EarthCrafter
1 引言
近年来,三维生成领域取得长足进步,研究从物体级生成(Liu等,2023;Shi等,2023a;Liu等,2024a;Xiang等,2025;Ren等,2024a;Zhao等,2025)发展至场景级合成(Ren等,2024b;Zhou等,2024;Gao*等,2024;Li等,2024;Yang等,2024;Zhang等,2025),产出了兼具照片级真实感与结构一致性的优质成果。此外,近期研究已将该能力拓展至多条件下的城市级生成(Xie等,2024,2025b;Deng等,2024;Engstler等,2025)。这些成果推动了计算机图形学、虚拟现实与高保真地理空间建模领域的新应用。
尽管取得上述进展,将三维生成扩展至广阔地理尺度仍存在关键短板——该领域需对人工建筑与自然地形进行整体建模。本文指出现有方法的两大核心局限:1)多数城市生成框架仅聚焦受限语义范围内的城市生成(Xie等,2025b;Deng等,2024;Engstler等,2025),忽略山脉、湖泊、沙漠等其他多样自然地貌。这需要覆盖多地形形态的综合性航空数据集,以及具备可扩展能力、适配通用地球生成的精心设计模型;2)由于大规模三维生成本身具有难解性,现有生成方法高度依赖各类条件,包括图像、语义、高度场、文本描述或其组合(Xie等,2024,2025a;Shang等,2024;Yang等,2024)。这类条件虽能提升生成效果,却限制了生成灵活性。与之相反,地理尺度的无条件生成常出现几何结构紊乱或纹理模糊问题,无法产出令人满意的结果。
为应对上述挑战,本文从数据构建与模型架构两方面优化,提升地理尺度生成能力。正式而言,本文提出Aerial-Earth3D,即迄今为止构建的规模最大的三维航空数据集。该数据集包含50028条精心筛选的场景,单场景覆盖范围600米×600米,数据来源覆盖美国本土,包含从谷歌地球采集的4500万张多视角帧。为以有限视角有效覆盖有效且多样的区域,本文基于数字高程模型(DEM)、开放街道图(OSM)与微软建筑数据集(MS-Building)构建的模拟三维场景,精心设计启发式相机位姿。由于谷歌地球未提供原始网格模型,本文通过InstantNGP(Müller等,2022)重建三维网格,并采用多种后处理技术提取表面平面、修正法向量、优化网格连通性。随后将这些网格体素化,作为结构生成的真值数据。此外,本文采用AIE-SEG(Xu等,2023)生成语义图作为网格属性,涵盖25个不同类别。如表1所示,Aerial-Earth3D凭借多样地形与三维标注,成为突出的大规模三维航空数据集,显著推动三维生成与重建研究发展。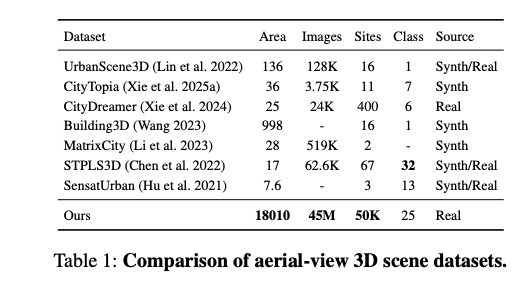

图1:EarthCrafter在多种引导条件下均能实现出色生成效果,包括(a)单视角航空语义条件与(b)单视角RGBD条件;(c)EarthCrafter具备强大的无条件生成能力,可从先验分布中采样得到合理的地理尺度三维资产;(d)EarthCrafter可基于同一语义条件生成多样化结果。
2 相关工作
2.1 三维生成模型
近年来,三维生成模型的进展备受关注。尤其随着二维生成模型的兴起(Rombach等,2022;Esser等,2024;Labs等,2025),研究者开始探索其在三维感知生成中的潜力。一类研究方向是微调二维扩散模型,以实现物体(Shi等,2023b;Wang和Shi,2023)或场景(Höllein等,2024;Wu等,2024;Gao*等,2024;Cao等,2024)的位姿条件化新视角合成。由于其输出主要为多视角二维图像,固有的视角不一致性使得将其转换为高质量三维表示仍存在挑战。
另有开创性工作通过分数蒸馏采样(SDS)(Kim等,2023;Zhu和Zhuang,2023;Wang等,2023)从二维扩散模型中提取先验,同时优化三维表示(Mildenhall等,2021;Kerbl等,2023)。然而,测试阶段的分数蒸馏采样效率不足,且常因过饱和与多面“双面神”伪影导致三维资产质量不佳。
此外,部分研究通过在深度扭曲与新视角修复中迭代拼接三维表示来创建大型三维场景(Yu等,2024b;Liang等,2024;Shriram等,2024;Yu等,2024a),但面临测试阶段数据集更新带来的高昂推理成本问题。
3 Aerial-Earth3D数据集
Aerial-Earth3D数据集通过严谨的数据构建流程开发而成。首先,从谷歌地球的“推荐景点”中采样高质量场景,在美国本土获得约150745个感兴趣点位。随后,融合开放街道图道路数据、数字高程模型地形数据与微软建筑高度数据。
接着,利用InstantNGP(Müller等,2022)重建每个场景,并通过移动立方体算法导出三维场景网格,再通过拓扑修复对这些网格进行优化。最后,通过分数聚合算法为网格赋予颜色、法向量、特征与语义属性。具体而言,采用AIE-SEG(Xu等,2023)模型进行语义预测,并利用FluxVAE(Labs等,2025)编码器导出特征,该流程如图2所示。最终,本文成功得到50028个高质量三维场景,详细信息见补充材料。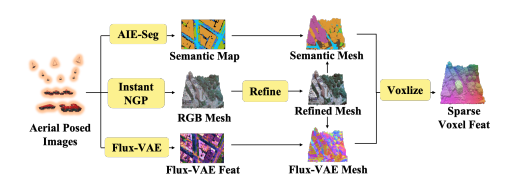
图2:Aerial-Earth3D整体数据流程。采用InstantNGP获取原始网格,通过启发式策略优化。多视角Flux-VAE特征与语义图被聚合到网格上,随后将这些带特征的网格体素化,作为纹理变分自编码器(TexVAE)的输入。
4 方法
4.1 概述
EarthCrafter的整体流程如图3©所示,包含独立的结构生成与纹理生成模块。给定随机初始化的三维噪声网格坐标 G ∈ R ( L 8 ) 3 × 3 G \in \mathbb{R}^{(\frac{L}{8})^{3} ×3} G∈R(8L)3×3,结构流匹配模型(StructFM)在可选深度或语义条件下生成结构潜在向量 S L a ∈ R ( L 8 ) 3 × c s S_{La} \in \mathbb{R}^{(\frac{L}{8})^{3} ×c_{s}} SLa∈R(8L)3×cs,其中 c s c_{s} cs 表示 S L a S_{La} SLa 的通道数。
随后,结构变分自编码器(StructVAE)解码器将 S L a S_{La} SLa 解码为高分辨率体素坐标 V c ∈ R L 3 × 3 V_{c} \in \mathbb{R}^{L^{3} ×3} Vc∈RL3×3。接着,纹理流匹配模型(TexFM)基于 V c V_{c} Vc,在可选图像与语义条件下生成纹理潜在向量 T L a ∈ R L 3 × c t T_{La} \in \mathbb{R}^{L^{3} ×c_{t}} TLa∈RL3×ct,其中 c t c_{t} ct 表示 T L a T_{La} TLa 的通道数。本文采用纹理变分自编码器(TexVAE)解码器恢复体素化二维高斯溅射 V G S ∈ R L 3 × 16 V_{GS} \in \mathbb{R}^{L^{3} ×16} VGS∈RL3×16,作为最终三维表示。
体素是三维空间中的最小体积单元,作用类似于二维空间的像素。
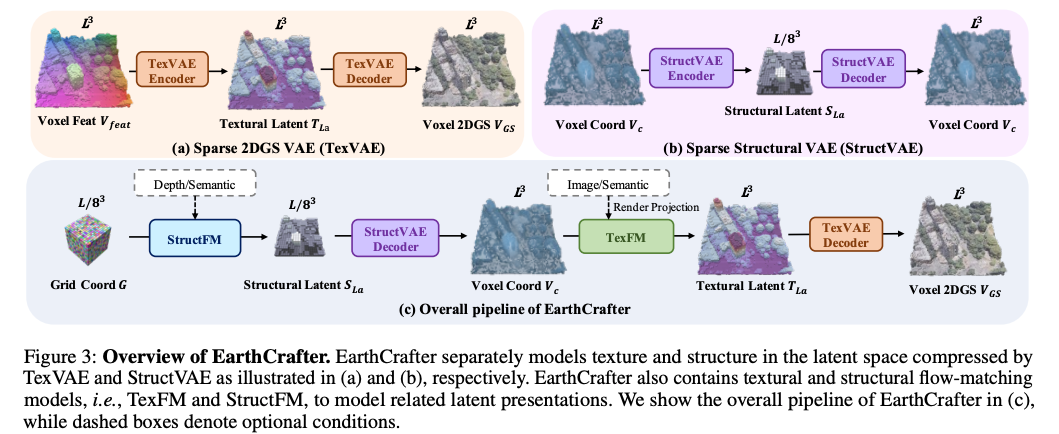
图3:EarthCrafter总览
EarthCrafter分别通过纹理变分自编码器(TexVAE)与结构变分自编码器(StructVAE)压缩潜在空间,对纹理和结构进行独立建模,二者结构分别如图(a)、(b)所示。EarthCrafter还包含纹理流匹配模型(TexFM)与结构流匹配模型(StructFM),用于建模对应的潜在表示。图©展示EarthCrafter的整体流程,其中虚线框表示可选条件。
4.2 双稀疏变分自编码器
4.2.1 结构变分自编码器(StructVAE)
与Trellis(Xiang等,2025)中受固定低分辨率体素空间限制的稠密架构不同,本文提出StructVAE,在稀疏体素建模中采用空间压缩的结构潜在空间以提升效率。如图4(a)所示,StructVAE采用编码器-解码器框架,将完整体素坐标 V c ∈ R L 3 × 3 V_{c} \in \mathbb{R}^{L^{3} ×3} Vc∈RL3×3 压缩为 S L a ∈ R ( L 8 ) 3 × c s S_{La} \in \mathbb{R}^{(\frac{L}{8})^{3} ×c_{s}} SLa∈R(8L)3×cs,尺寸缩减至原始大小的1/256,其中 c s = 32 c_{s}=32 cs=32。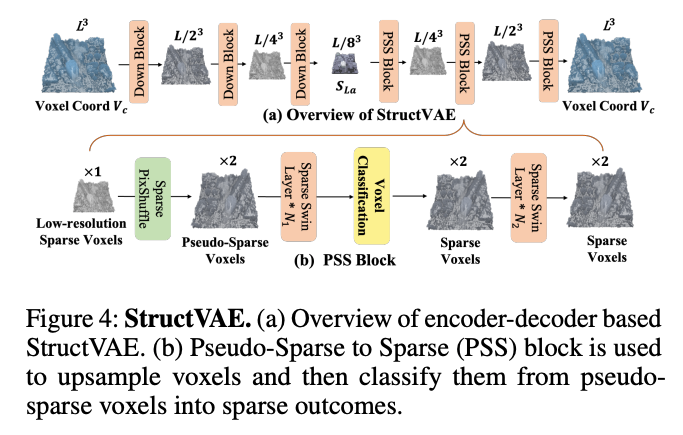
图4:结构变分自编码器(StructVAE)
(a) 基于编码器–解码器架构的StructVAE整体结构。
(b) 伪稀疏到稀疏(PSS)模块用于对体素进行上采样,随后将伪稀疏体素分类为稀疏输出结果。
本文首先将位置编码融入 V c V_{c} Vc,随后应用4层Transformer层与1层步长为2的稀疏三维卷积层(Williams等,2024)进行体素下采样。需要说明的是,稀疏体素的上采样比下采样更具挑战性。因为朴素上采样策略难以在恢复稀疏几何后保证精度,如图4©所示。因此,本文提出新颖的伪稀疏到稀疏(PSS)模块,通过稀疏像素重排与体素分类实现稀疏几何的精准上采样,细节如图4(b)所示。
具体而言,定制化像素重排层用于上采样稀疏表示,上采样后的体素称为伪稀疏体素。该定义表示部分上采样体素无效,需剔除以维持合理稀疏度下的精准几何。因此,本文提出在每个PSS模块上采样过程中加入分类模块,以恢复有效稀疏体素,如图4©所示。此外,采用稀疏Swin Transformer(Xiang等,2025)提升PSS模块的上采样学习效果,而全注意力层在学习 ( L 8 ) 3 (\frac{L}{8})^{3} (8L)3 低分辨率特征时表现更优。StructVAE遵循XCube(Ren等,2024a)的变分自编码器学习目标。创新的StructVAE架构同时实现空间压缩几何与97.1%的结构重建精度,节省后续生成的计算开销。
4.2.2 纹理变分自编码器(TexVAE)
(1) 体素化特征。遵循Trellis(Xiang等,2025),本文聚合图像特征以将外观信息注入几何体素。但TexVAE的大规模学习仍存在挑战。尽管本文已为StructVAE实现空间压缩,但在TexVAE中应用同类特征压缩会显著降低纹理恢复性能,预实验已验证该结论。此外,高维体素化特征的TexVAE学习存在输入输出难以承受的问题;例如,Trellis(Xiang等,2025)中采用DINOv2(Oquab等,2023)的1024维特征,单场景需约471MB存储空间。
因此,本文提出采用细粒度、低通道特征替代粗粒度、大通道特征用于大规模纹理变分自编码器学习。正式而言,选用为FLUX(Labs等,2025)训练的变分自编码器特征(16通道)作为特征提取器,相比DINOv2显著降低特征维度。尽管FLUX-VAE专为图像生成设计,在本文研究中展现出优异的纹理恢复重建能力。为进一步提升表示效果,本文通过最近邻缩放采用分层FLUX-VAE特征,记为 [ f 0 ; f 1 ; f 2 ] ∈ R 16 × 3 = 48 [f_{0} ; f_{1} ; f_{2}] \in \mathbb{R}^{16 ×3=48} [f0;f1;f2]∈R16×3=48,特征分别在1/1、1/2与1/4尺度拼接。
此外,融入十字形RGB像素 f r g b ∈ R 5 × 3 = 15 f_{rgb} \in \mathbb{R}^{5 ×3=15} frgb∈R5×3=15 与法向量特征 f n ∈ R 3 f_{n} \in \mathbb{R}^{3} fn∈R3 作为附加特征。最终体素化特征可表示为拼接结果:
f f e a t = [ f 0 ; f 1 ; f 2 ; f r g b ; f n ] ∈ R 66 ( 1 ) f_{feat }=\left[f_{0} ; f_{1} ; f_{2} ; f_{rgb} ; f_{n}\right] \in \mathbb{R}^{66} \quad (1) ffeat=[f0;f1;f2;frgb;fn]∈R66(1)
单场景仅占用31MB存储空间(为DINOv2的6.4%)。遵循VCD-Texture(Liu等,2024b),本文根据投影像素与体素间的距离及视角分数,通过分数聚合将体素化特征聚合为 V f e a t V_{feat} Vfeat。
(2) 模型设计与学习目标。TexVAE的网络架构遵循Trellis(Xiang等,2025),采用编码器-解码器模型,各组件均增强12层稀疏Swin Transformer层。TexVAE编码器将体素化特征 V f e a t ∈ R L 3 × 66 V_{feat} \in \mathbb{R}^{L^{3} ×66} Vfeat∈RL3×66 转换为纹理潜在向量 T L a ∈ R L 3 × c t T_{La} \in \mathbb{R}^{L^{3} ×c_{t}} TLa∈RL3×ct, c t = 8 c_{t}=8 ct=8,解码器则将潜在特征转换为二维高斯溅射表示。该表示包含偏移量 o i o_{i} oi、缩放 s i s_{i} si、不透明度 α i \alpha_{i} αi、旋转矩阵 R i R_{i} Ri 与球谐函数 c i c_{i} ci。
TexVAE的损失函数包含L1损失、LPIPS损失(Zhang等,2018)与SSIM损失,结合VGG与AlexNet的LPIPS损失以实现更优视觉质量。此外,实验发现移除TexVAE编码器会破坏特征连续性,导致二维高斯溅射结果变差。
4.3 潜在流匹配(FM)扩散模型
4.3.1 结构流匹配(StructFM)
为同时实现精准的体素分类与结构潜在特征预测,本文引入如图5所示的由粗到细框架。该框架包含两个阶段,各阶段承担截然不同的预测目标。具体而言,粗阶段由纯Transformer模块构成,专注于激活体素的分类,预测粗网格 G ^ c l a s s ∈ R ( L 8 ) 3 × 1 \hat{G}_{class} \in \mathbb{R}^{(\frac{L}{8})^{3} ×1} G^class∈R(8L)3×1。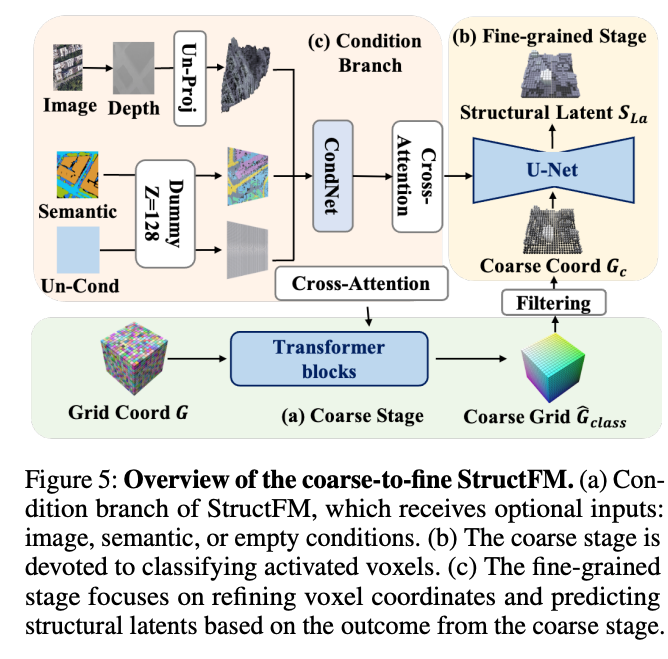
图5:由粗到细StructFM概述。(a) StructFM的条件分支,可接收图像、语义或空条件等可选输入;(b) 粗阶段专注于激活体素的分类;© 细阶段基于粗阶段输出,优化体素坐标并预测结构潜在向量。
该分类的目标可表示为二项分布 G c l a s s ∈ { − 1 , 1 } G_{class} \in \{-1,1\} Gclass∈{−1,1}。因此,粗阶段的流匹配对该分布建模为 p ( G c l a s s ∣ G , C c o n d ) p(G_{class} | G, C_{cond}) p(Gclass∣G,Ccond),其中 G ∼ N ( 0 , 1 ) G \sim N(0,1) G∼N(0,1) 表示随机初始化的噪声网格; C c o n d ∈ { C i m g , C s e g , N o n e } C_{cond} \in\{C_{img}, C_{seg}, None \} Ccond∈{Cimg,Cseg,None} 表示可选的图像条件 C i m g C_{img} Cimg、语义分割条件 C s e g C_{seg} Cseg 或无条件生成。需要注意的是,所有条件均需投影至三维空间。对于该投影操作,从图像条件估计单目深度,而语义与无条件输入则分配虚拟深度(即 z = 128 z=128 z=128)。
条件网络(CondNet)基于Swin Transformer模块构建(Liu等,2021),采用交叉注意力机制实现条件与体素特征的对齐。基于粗网格结果 G ^ c l a s s ∈ { − 1 , 1 } \hat{G}_{class} \in\{-1,1\} G^class∈{−1,1},本文设置阈值为0:大于0的数值表示有效体素,小于等于0的数值视为无效体素。
细阶段模型基于Swin注意力(Liu等,2021)的U-Net构建,以阈值过滤后的结果 G c G_{c} Gc 作为稀疏输入,进一步预测结构潜在向量 S L a ∈ R ( L 8 ) 3 × c s S_{La} \in \mathbb{R}^{(\frac{L}{8})^{3} ×c_{s}} SLa∈R(8L)3×cs,其中 c s = 32 c_{s}=32 cs=32。至关重要的是,细阶段的输出也可用于优化结构坐标。本文将无效体素的特征置零,仅保留超过50%通道满足 S L a > 0.3 S_{La}>0.3 SLa>0.3 阈值的体素。
此外,为缓解两阶段间的领域差异,本文提出体素膨胀增强策略以强化细阶段的训练。总体而言,大量实验证实StructFM的由粗到细学习方式显著提升了结构精度。
4.3.2 纹理流匹配(TexFM)
给定从StructVAE解码的体素坐标 V c ∈ R L 3 × 3 V_{c} \in \mathbb{R}^{L^{3} ×3} Vc∈RL3×3,TexFM生成通道数为 c t = 8 c_{t}=8 ct=8 的纹理潜在特征 T L a ∈ R L 3 × c t T_{La} \in \mathbb{R}^{L^{3} ×c_{t}} TLa∈RL3×ct。
为克服大规模纹理生成(单场景最高可达22万个体素)带来的计算挑战,本文通过专用U-Net架构提升TexFM模型效率。该方法融合稀疏Swin Transformer层与全注意力层,分别有效聚焦局部与全局特征学习。实验发现,Swin注意力在1/1、1/2、1/4尺度的高分辨率特征捕捉中表现优异,而全注意力为1/8尺度的低分辨率特征提供更广阔的感受野。这种互补的U-Net架构在纹理质量与学习效率间实现良好平衡。
此外,TexFM与StructFM类似,采用灵活的条件输入,包括图像与语义分割结果。TexFM的更多细节见本文补充材料。
5 实验
5.1 实现细节
本文采用AdamW优化器,学习率设为 1 × 10 − 4 1 ×10^{-4} 1×10−4,遵循多项式衰减策略。模型在32块H20 GPU上训练20万次迭代,批次大小为64。数据增强方面,对三维稀疏体素执行体素裁剪与体素翻转,同时同步变换对应相机位姿。上述两种基础增强策略应用于所有模型训练过程。
对于TexVAE、StructVAE与TexFM,采样训练体素的最大数量限制为25万。为提升StructFM的孔洞填充能力,本文基于条件体素法向量引入条件体素丢弃策略。推理阶段,分类器引导(CFG)强度与采样步数分别设为3和25。
5.2 数据准备
数据准备从5万条带特征的场景网格筛选集开始。首先提取尺寸为500米×500米的中心网格,通过滑动裁剪得到9个尺寸为200米×200米的训练网格。将这些训练网格以 L = 360 L=360 L=360 的体素数进行体素化,生成体素特征 V f e a t V_{feat} Vfeat,单个体素对应面积为 0.56 m 2 0.56 m^2 0.56m2(计算方式:200/360)。
该过程得到45万个体素特征,单个体素特征平均包含22万个个体素,是Trellis体素数量的10倍。随后,通过高度采样构建全局训练与验证数据集,得到44.7万个训练样本与3068个验证样本。此外,从纽约地区采样消融数据集,包含3000个训练样本与300个验证样本。
5.3 生成结果
5.3.1 定性对比
本节首先将本文生成结果与其他方法对比。由于本文聚焦多条件下的鸟瞰视角(BEV)场景生成,据本文所知,暂无研究采用与本文相似的设置。例如,SCube采用多张图像生成第一视角(FPV)场景,CityDreamer则依赖从二维高度图与语义图提取的强语义三维几何条件。因此,本文仅提供定性对比。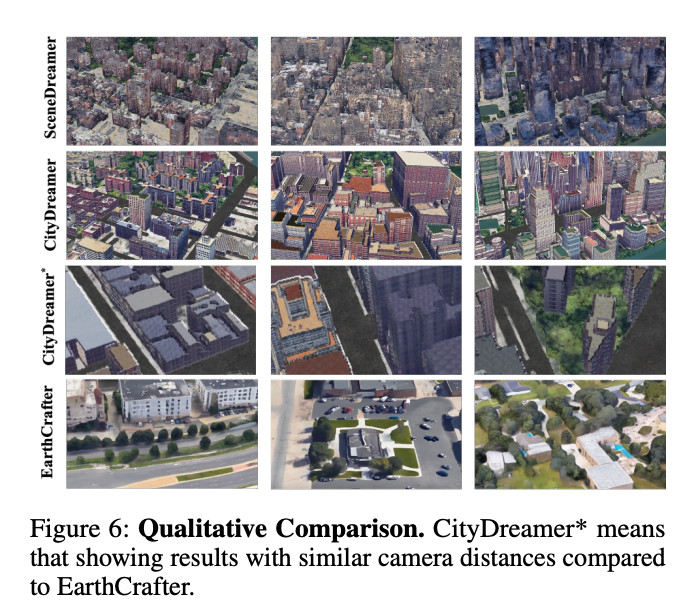
图6:定性对比。CityDreamer*表示采用与EarthCrafter相近相机距离展示的结果。
图6展示对比结果,EarthCrafter的结果基于二维语义图条件生成,未使用高度条件。通过定性对比可观察到,SceneDreamer在生成照片级真实感结果时存在显著局限,尤其在建筑元素中出现明显结构伪影与几何畸变。CityDreamer在宏观层面几何保真度有所提升,但细看仍存在纹理真实感不足、场景几何与地面物体分布缺乏多样性的问题。
相比之下,本文提出的EarthCrafter框架在多个维度表现更优,生成结果相比现有基线方法具备更强的照片级真实感与更丰富的场景多样性。此外,图1展示EarthCrafter在多种条件下的定性结果,验证其灵活的生成能力。
5.3.2 无限场景生成
受限于体素长度 L = 256 L=256 L=256,单次前向传播可生成 146 m 2 146 m^2 146m2 的场景面积。受基于掩码的修复技术启发(利用已生成结果扩展生成尺度),本文提出一种无限场景生成方法。该方法以大型语义图为条件,通过滑动窗口方式生成广阔的地球场景。
受二维高斯溅射渲染的GPU内存限制,本文生成覆盖 412 m 2 412 m^2 412m2 的大型场景,语义图尺寸为648×648。结果如图7所示,更多可视化结果见补充材料。注:大型垂直语义图从验证块的源场景网格获取,与训练块存在重叠。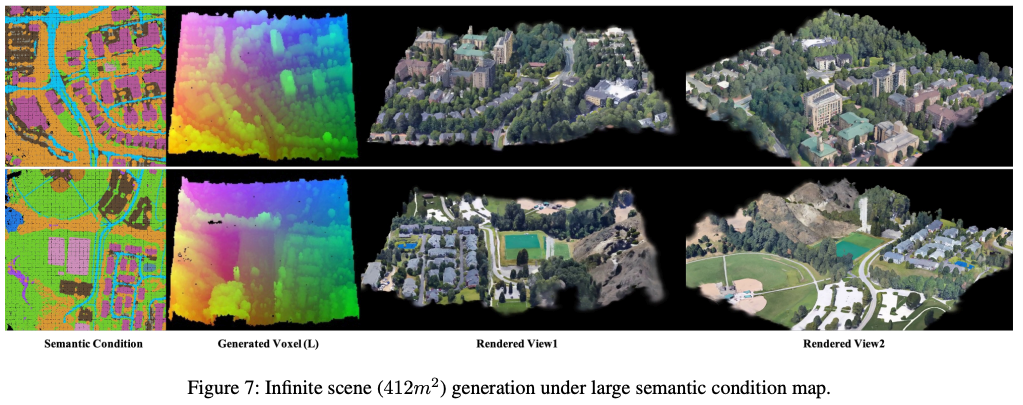
5.4 消融研究
5.4.1 纹理变分自编码器(TexVAE)
本文首先评估体素特征构建策略,实验结果总结于表2,可得出以下结论:1)对比TexA与TexB,在相同体素分辨率 L = 200 L=200 L=200 下,更多的体素特征通道可获得更优结果;2)对比TexB与TexC,精细的体素分辨率可实现显著提升;对比TexA与TexC,细粒度低通道体素特征远优于大通道粗分辨率特征;3)对比TexD、TexE与TexC,大感受野特征与局部低层特征可持续提升性能;4)TexE与TexF的结果证明,体素特征可在通道维度压缩,但不可在空间维度压缩,否则会大幅降低性能。
基于上述分析,本文选择混合特征 f f e a t f_{feat} ffeat 作为基础体素特征方案,单个 f f e a t f_{feat} ffeat 平均占用31MB缓冲区。此外,由于TexVAE无法在空间上压缩,本文将结构与纹理生成解耦,采用管状网络实现TexVAE的通道维度压缩,采用U型网络实现StructVAE的空间压缩。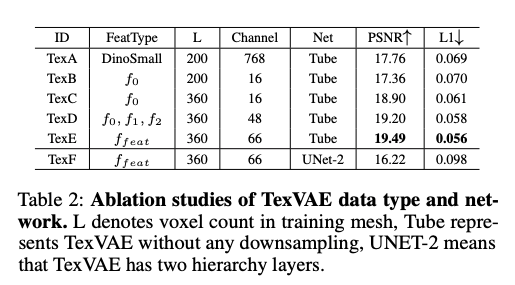
5.4.2 结构变分自编码器(StructVAE)
StructVAE的消融实验列于表3,验证所提模块的有效性。首先,像素重排(PixShuffle)大幅提升性能,证明无歧义上采样对稀疏结构的重要性。其次,每四层Swin Transformer插入一层卷积块的混合模块设计可提升性能,过多卷积块无法实现持续提升。
为捕捉全局信息,本文在最低分辨率层采用全注意力替代Swin注意力。该操作在消融数据集上观察到性能下降,但在全局训练集上表现出持续提升。本文实验认为,小数据集的几何更偏好局部特征,而大数据集更偏好全局特征。此外,本文采用相同模块通道数复现XCube方法(基于全稀疏卷积块网络),如表3所示。基于Transformer的StructVAE相比基于卷积的XCube性能更优,且训练耗时更短。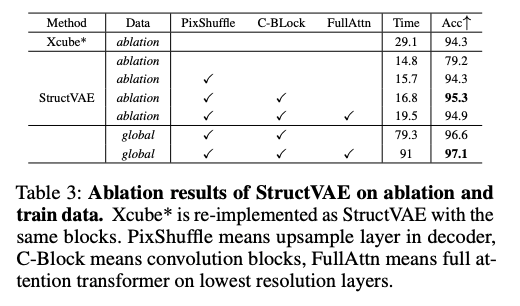
5.4.3 结构流匹配(StructFM)
为验证本文两阶段稀疏结构潜在生成的由粗到细流程的有效性,本文实现单阶段稠密结构流模型(DenseSFM),从稠密噪声潜在体中生成稀疏结构潜在向量。DenseSFM在单一模型中完成体素分类与潜在生成,采用与StructFM细阶段相同的分类方案。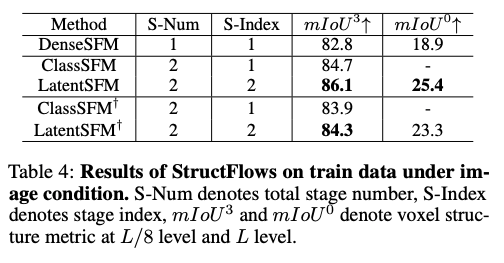
表4展示不同结构生成方法的结果。纯分类流模型ClassSFM(StructFM的第一阶段)相比DenseSFM精度更优。这表明潜在生成与体素分类在稠密模式下存在冲突,导致性能下降。然而,若将ClassSFM输出的粗稀疏体素输入LatentSFM(StructFM的第二阶段),体素分类性能持续提升。
总体而言,相比单阶段稠密模式,本文两阶段方法的分类精度显著提升(+3.3)。此外,在细粒度性能上,两阶段方法相比单阶段方法也取得可观提升。这证明了本文由粗到细两阶段方法的有效性。
6 结论
本文通过开发Aerial-Earth3D数据集与EarthCrafter框架,在地理尺度三维生成领域取得重大进展。本文提供迄今为止规模最大的三维航空数据集,为有效建模多样地形与结构奠定坚实基础。本文提出的双稀疏变分自编码器框架与创新流匹配模型,不仅提升了精细纹理与结构的生成效率,还解决了大规模计算与数据管理的核心挑战。所提由粗到细结构流匹配模型进一步保证了精准的结构表示,同时支持基于多种输入的灵活条件生成。此外,本文采用FLUX-VAE的低维特征表示体素纹理,实现更优的重建效果。严谨的实验验证了本文方法相比现有方法的有效性与优越性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)