1,DDD是什么?
引言
本文的主要内容:
-
范式
Paradigms -
模型
Models -
框架
Framework -
方法论
Methodologies -
主要活动
-
维护
Maintenance -
总结
DDD核心概念
DDD核心概念:
-
领域模型
Domain Model-
在一个具体的业务功能下,对特定业务领域知识的精确表述,包括业务中的实体
Entities、值对象Value Object、服务Services、聚合Aggregates、聚合根Aggregate Roots等概念。领域模型就是DDD的核心,主要就是用于具体业务功能的实现,专业说就是反映了业务专家的语言和决策
-
-
统一语言
Ubiquitors Language-
就是开发团队和业务专家共同使用的语言,在整个项目中保持一致,就是为了保证所有工作人员对项目的理解都是相同的,减少沟通成本,实际上可以先不关注这个东西,实际上也不是
DDD的重点之一
-
-
限界上下文
Bounded Context-
限界上下文是明确界定的系统边界,在这个边界内部有一套统一的模型和语言,不同的限界上下问有不同的模型,它们通过上下文映射来进行交互和集成
-
-
聚合
Aggregate-
聚合其实也叫聚合对象,其实他和实体对象、值对象形式上类似,但是聚合是一组相关对象的集合,它们被视为数据修改的单元。每个聚合都有一个聚合根,它是外部对象与聚合内部对象交互的唯一入口
-
-
领域服务
Domain Service-
当某些行为不属于任何实体或值对象时,这些行为可以被i当以成领域服务。领域服务通常表示领域中的一些操作或业务逻辑,主要就是用来表示这个领域中的业务逻辑
-
-
应用服务
Application Services-
是你开发的这个软件的一部分,它们协调领域对象来执行任务。它们负责应用程序的工作流程,但不包含业务规则或知识
-
-
基础设施
Infrastructure-
为领域模型提供持久化机制
和数据库映射、消息传递、应用程序的配置等技术组件,例如pojo类,和数据库的字段进行一一对应的映射关系、dao,就是mapper,定义接口,根据数据库字段来进行查询操作,和mapper.xml文件进行对应、还有一些组件的配置,例如redis的配置
-
-
领域事件
Domain Events-
领域中发生的有意义的业务事件,可以触发其他子系统的反应或流程
-
DDD这个软件设计方式涵盖了:范式、模型、框架、方法论
范式Paradigms
其实就是规则,一套规则,在开发过程中,要遵守的规则,常见的软件涉及范式包括:
-
结构化编程:强调程序结构的重要性,使用顺序、选择、循环控制结构
-
面向对象编程
OOP:基于对象的概念,将数据和处理数据的方法封装在一起 -
函数式编程:将计算机为数学函数的评估,避免状态改变和可变数据
-
事件驱动编程:以事件为中心,响应用户操作、消息或其他系统事件
多开发项目,多思考就会理解这个所谓的规则了,没有必要硬记
模型Models
其实模型也不是这么重要吧,就是对应你要开发的这个业务系统进行一个抽象的处理,就是根据功能模块来分领域设计,用于帮助对业务功能的理解
一般有:
-
UML类图:用于描述、设计和文档化软件项目 -
ER模型:用来设计数据库,描述数据的实体及之间的关系 -
状态机模型:描述业务系统中可能出现的状态、事件和在这些事件发生时的转换
框架Frameworks
在进行开发项目时使用到的一套骨架/脚手架,因为我们不可能说每次进行开发的时候都从零开始去开发一个项目,而且在企业开发中也是不会这样做的,都会提供一套标准的脚手架来进行开发,直接基于这套骨架进行后续业务功能的拓展
-
Spring Framework:一个用于Java应用程序的全面编程和配置模型。
-
Ruby on Rails:一个用于快速开发Web应用程序的Ruby框架。
-
Django:一个高级Python Web框架,鼓励快速开发和干净、实用的设计。
方法论Methodologies
就是对项目管理、开发流程、团队协作等方面
有:
-
敏捷开发:一种迭代和增量的开发方法,强调灵活性和客户合作。
-
Scrum:一种敏捷开发框架,用于管理复杂的软件和产品开发。
-
瀑布模型:一种线性顺序的开发方法,将项目分为不同阶段,每个阶段完成后才能进入下一个阶段。
DDD是软件设计的一种思想、方法,那么软件设计的主要活动包括:
-
建模
Modeling:根据你要开发的这个业务系统用模型来表示,根据不同的功能实现来进行分层划分,例如使用UML类图来描述系统架构 -
测试
Testing:每开发一个业务功能或者一个业务中的一个小功能就进行一下测试,例如单元测试、系统测试、验收测试 -
工程
Engineering:对业务系统进行需求分析、设计、实现、测试 -
开发
Development:编写代码进行开发,将需求设计转化为实际的软件产品 -
部署
Deployment:将开发好的软件部署到生产环境,可供用户使用 -
运维
Maintenance:在软件发布后进行后续的改进升级
那么接下来我们就该进入正题了
DDD是什么
是一种软件设计的手段,可以让我们合理规划出可持续迭代的工程设计
在DDD中有一套共识的工程两阶段设计手段,包括:战略设计、战术设计
战略设计:主要以应对复杂的业务需求,通过抽象、分支的过程,合理地拆分为独立的多个微服务,从而分而治之,根据对需求开发上线的时候是否每次都需要大量操作多个微服务开发和上线,来评价这个拆分是否合理。所以少数几个中等规模的单体应用,周围环绕着一个服务生态系统,这更有意义虽然说要拆分成多个微服务来进行开发,但是不要拆的很碎,显得没有关联性,否则就不是微服务了
战术设计:主要讨论如何基于面向对象编程的思维,运用领域模型来表达业务概念。通常在一些不做领域模型设计的架构,也就是通常直接映射到MVC三层架构下,Service+数据模型的开发模式,会让Service扁平、大量、平铺出非常复杂的业务逻辑代码,再加上行为对象与功能逻辑的分离,贫血模型的开发方式,让行为对象的不断交叉使用,也是让系统不断增加复杂度,并到难以维护的根因。所以这一阶段要设计每一个可以表达概念的模型,并运用实体、聚合、领域服务来承载
DDD相关的概念
什么是充血模型?
领域内都包括什么?
实体、聚合、值对象、有什么区别?
这些概念都是战术设计过程中非常重要的知识,只有弄清楚这些概念才能做好DDD的设计
充血模型
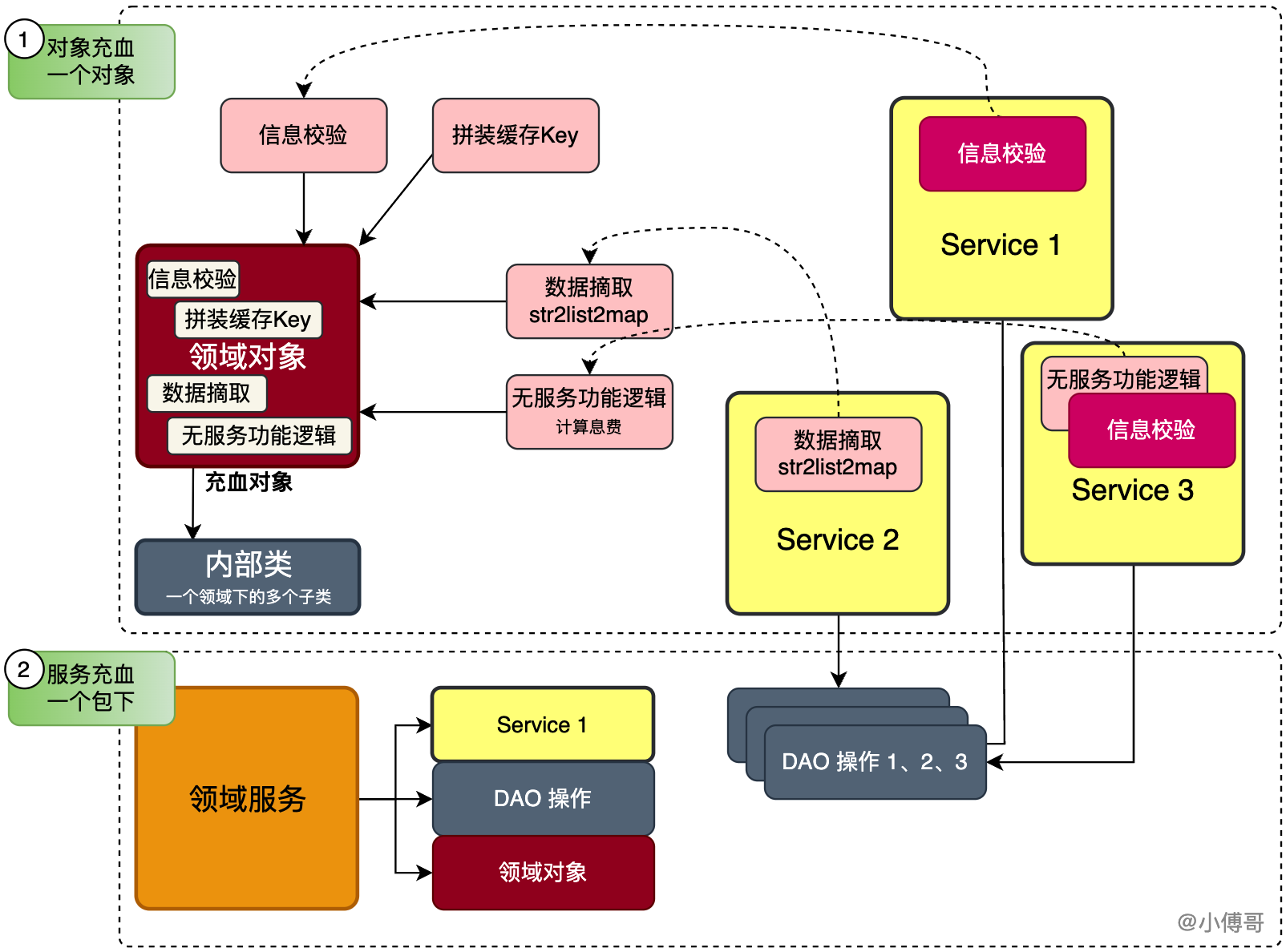
充血模型:指将对象的属性信息与行为逻辑聚合到一个类中,常用的手段有例如:在对象内提供属于当前对象的信息校验、拼装缓存Key、不含服务接口调用的逻辑处理等
在没有使用充血模型之前,用的就是
Service+数据模型,即Service要用什么方法,就在内部写上对应的方法,
图片摘取自xfg博客,如有侵权请联系,马上删除
-
这样的方式可以让我们在使用一个对象的时候,可以很方便就能拿到这个对象提供的一系列方法信息,所有使用对象的逻辑方法,都不需要自己再次处理同类逻辑
-
不要把充血模型仅限于一个类的设计和一个类内部的方法设计。充血模型还可以是整个包结构的设计,这个包里面包括了用于实现词包
Service服务所需的各类零部件,如工厂、模型、存储,也可以被看作充血模型 -
同时我们还会在一个同类的类下,提供对应的内部类,如用户实名
就是在购物的时候或者登录某些平台账号的时候进行的实名认证,包括通信类、实名卡、银行卡、四要素等,它们都被写进到一个用户类的内部子类,这样在代码编写中也会清晰地看到子类的所属信息,更容易理解代码逻辑,也便于维护迭代
领域模型
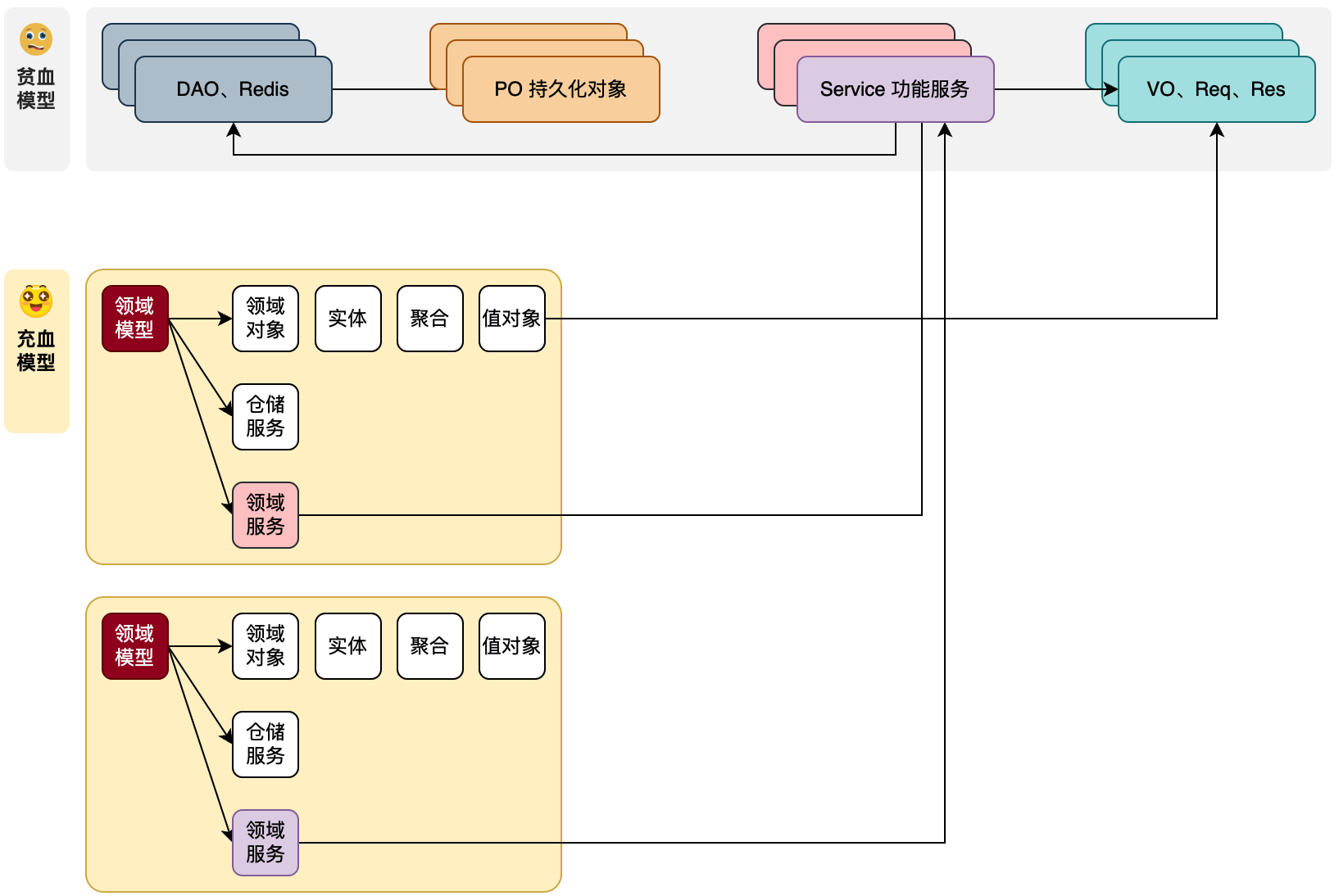
领域模型,指特定业务领域内,业务规则、策略以及业务流程的抽象和封装。在设计手段上,通过风暴模型拆分领域模块,形成界限上下文。最大的区别就是把原有的众多的Service+数据模型的方式,拆分为独立的有边界的领域模块。每个领域内创建自身所属的;领域对象(实体、聚合、值对象)、存储服务(DAO操作)、工厂、端口适配器Port(调用外部接口的手段)等
我的理解:这个领域模型就是在开发中的domain层
贫血模型或三层架构中是没有考虑这种面向对象编程的思想的,是你需要用到那个相关的属性、方法就从对应的位置进行获取,因为都提供好了,例如什么操作数据库的dao,持久化层的数据等
现在这里有几个概念,领域服务、领域对象、存储定义、事件消息、端口适配器。我们先来看看是怎么从贫血模型演变过来的,再细分讲解每个概念:
-
在原本的
Service+贫血的数据模型开发指导下,Service串联调用每一个功能模块。这些基础设施`(对象、方法、接口)是被相互调用的。这也是因为贫血模型没有进行面向对象的设计,所有的需求开发都只有详细设计 -
换到充血模型下,现在我们以一个领域功能为聚合,拆分一个领域内所需的
Service为领域服务,VO、Req、Res重新设计为领域对象,DAO、Redis等持久化操作为存储等。从上图可以看出来,一般一个业务功能就对应着一个领域模型,在这个业务模型里面有存储、模型、领域服务,就是上图所展示的都包含在内。举例:一套账户服务中的,授信认证、开户、提额降额等,每一个都是一个独立的领域,都是一个独立的领域模型,在每个独立的领域内,创建自身领域所需的各项信 -
领域模型还有一个特点,它只关注业务功能的实现,不与外部任何接口和服务直连。如:不会直接调用
DAO操作库,也不会调用缓存区操作Redis,更不会直接引入RPC连接其他微服务。而是通过仓库和端口适配器,定义调用外部数据的含有出入参对象的接口标准,让基础设施层做具体的调用实现。通过这样的方式让领域只关心业务实现,同时做好防腐
实体、聚合、值对象
原本在贫血模型下的开发,常常是不会特别在意一个方法的出入参对象的,也经常是很多个服务共用一个VO对象作为入参,只要这个对象能把我需要的属性信息带进来即可
但是在DDD的领域模型设计下,领域对象的设计是非常面向对象的,而且在整个风暴事件的四色建模过程也是在以领域对象为驱动进行的
实体、聚合、值对象三者位于每个领域下的领域对象内,服务于领域内的领域服务。这三个对象定义具体如下:
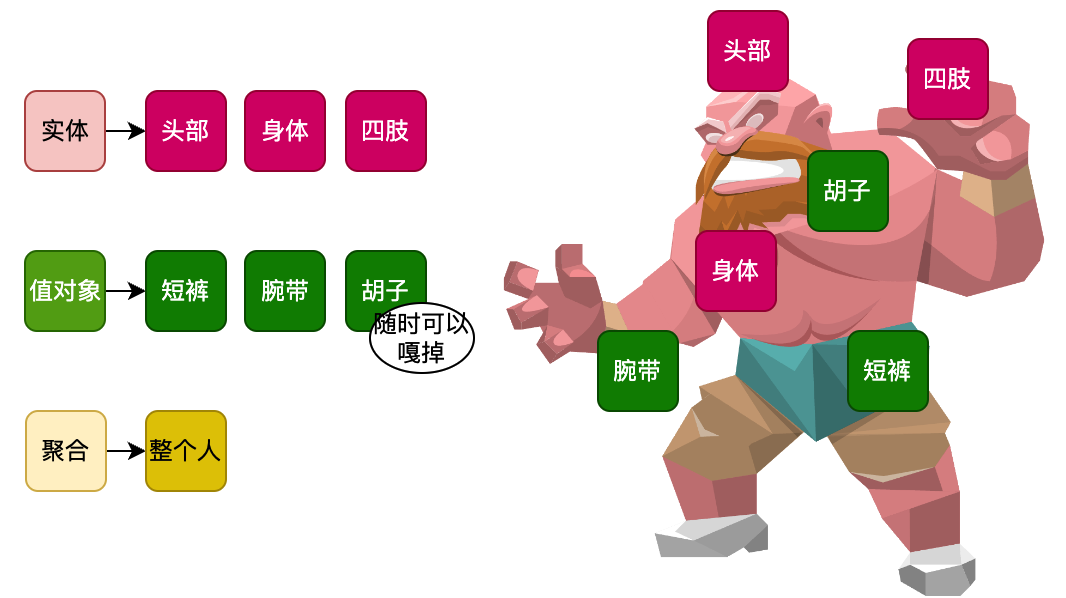
实体
是依托于持久化层数据po/pojo包下的类就是持久化数据,和数据库中的表的字段一一对应以领域功能目标为指导设计的领域对象。持久化po对象是原子类对象,不具有业务语义,是包含所有的字段数据的,而实体对象是具有业务语义且具有唯一标识的对象,跟随当前领域服务方法的全生命周期对象。如:用户po持久化对象,会涵盖用户的开户实体、授信实体、额度实体对象。也包括如商品下单时候的购物车实体对象。这个对象也通常是领域服务方法的入参对象。
-
实体 = 唯一标识 + 状态属性 + 行为动作 / 功能,是
DDD中的一个基本构建块,它代表了具有唯一标识的领域对象。实体不仅仅包含数据(状态属性),还包含了相关的行为(功能),并且它的标识在整个生命周期中保持不变 -
特征:
-
唯一标识:每一个实体之间都有一个可以进行互相区分的标识符,这个标识符可以是一个
ID、一个复合键、一个自然键,关键是能够唯一标识实体 -
领域标识:实体的唯一标识通常来源于业务领域,例如用户
ID、订单ID等,这些标识符在业务上有特定的含义,并且在系统中是唯一的 -
委派标识:实体的标识可能由
ORM(对象关系映射)框架自动生成,如数据库中自增的主键,这种标识符虽然可以唯一标识实体,但它并不直接来源于业务领域
-
-
用途:
-
表达业务概念:通过对应的实体,可以表达具体的业务概念,就是具体实现什么样的业务功能,例如用户、订单、交易、登录验证等。通过实体的属性和行为,可以描述这些业务对象的特征和能力
-
封装业务逻辑:实体不仅仅承载了数据,还封装了业务规则和业务逻辑。这些逻辑包括验证数据的有效性、执行业务规则、计算属性值等。这样做的目的是保证业务逻辑的集中和一致性
-
保持数据一致性:实体负责维护自身的状态和数据一致性。它确保自己的属性和关联关系在任何时候都是正确和完整的,从而避免数据的不一致
-
-
实现手段:
-
实现实体类:在代码中创建一个类,这个类包括实体的属性,构造函数、方法等
-
实现唯一标识:为实体类提供一个唯一标识属性,如
ID,并确保实体的生命周期中这个标识保持不变 -
封装行为:在实体类中实现业务逻辑的方法,这些方法可以操作实体的状态,并执行相关的业务规则
-
使用
ORM框架:利用ORM框架将实体映射到数据库表中,这样可以简化数据持久化的操作 -
使用领域服务:对于跨实体或跨聚合的操作,可以实现领域服务来处理这些操作,而不是在实体中直接实现
-
使用领域事件:当实体的状态发生变化时,可以发布领域事件,这样可以通知其他部分的系统进行相应的处理
-
值对象
值对象在领域服务方法的生命周期过程内是不可变对象,也没有唯一标识。它通常是配合实体对象使用的。如为实体对象提供对象属性值的描述,比如:一个公司雇员的级别值对象,一个下单的商品收货的四级地址信息对象。所以在开发值对象的时候,通常不会提供setter方法,而是提供构造函数或Builder方法来实例化对象,这个对象通常不会独立作为方法的入参对象,但可以独立作为出参对象使用
-
概念:值对象是由一组属性组成的,它们共同描述了一个领域概念。和实体
Entity不同,值对象不需要有一个唯一标识符来区分它们。值对象通常是不可变的,这意味着一旦创建了,它们的状态就不应该改变 -
特征:
-
不可变性
Immutability:值对象一旦被创建,它的状态就不应该发生变化。这有助于保证领域模型一致性和线程安全性 -
等价性
Equality:值对象的等价性不是基于身份或引用的,而是基于对象的属性值。如果两个值对象的所有属性值都相等,那么这两个对象就被二年为是等价的 -
替换性
Replaceablity:由于值对象是不可变的,任何需要修改值对象的操作都会导致创建一个新的值对象实例,而不是修改现有的实例 -
侧重于描述事务的状态:值对象通常用来描述事务的状态,而不是事务的唯一身份
-
可复用性
Reusability:值对象可以在不同的领域实体或其他值对象中重复使用
-
-
用途:
-
金额和货币,如价格、工资、费用等
-
度量和数据,如重量、长度、体积等
-
范围或区间,如日期范围、温度区间等
-
复杂的数学模型,如坐标、向量等
-
任何其他需要封装的属性集合
-
-
实现手段:
-
定义不可变类:确保类的所有属性都是私有的,并且只能通过构造函数来设置。
-
重写
equals和hashCode方法:这样可以确保值对象的等价性是基于它们的属性值,而不是对象的引用。 -
提供只读访问器:只提供获取属性值的方法,不提供修改属性值的方法。
-
使用工厂方法或构造函数创建实例:这有助于确保值对象的有效性和一致性。
-
考虑序列化支持:如果值对象需要在网络上传输或存储到数据库中,需要提供序列化和反序列化的支持。
-
聚合
当你对数据库的擦欧总需要使用多个实体时,可以创建聚合对象。一个聚合对象代表着一个数据库事务,具有事务一致性。聚合中的实体可以由聚合提供创建操作,实体也被称为聚合根对象。一个订单的聚合,会涵盖下单用户实体对象、订单实体、订单明细实体和订单收货四级地址对象。而那个作为入参的购物车实体对象,已被转换为实体对象了,聚合内事务一致性,聚合外最终一致性
-
概念:聚合是领域模型中的一个关键概念,它是一组具有内聚性的相关对象的集合,这些对象一起工作以执行某些业务规则或操作。聚合定义了一组对象的边界,这些对象可以被视为一个单一的单元进行处理
-
特征:
-
一致性边界:聚合确保其内部对象的状态变化是一致的。当对聚合内的对象进行操作时,这些操作必须保持聚合内所有对象的一致性。
-
根实体:每个聚合都有一个根实体(Aggregate Root),它是聚合的入口点。根实体拥有一个全局唯一的标识符,其他对象通过根实体与聚合交互。
-
事务边界:聚合也定义了事务的边界。在聚合内部,所有的变更操作应该是原子的,即它们要么全部成功,要么全部失败,以此来保证数据的一致性。
-
-
用途:
-
封装业务逻辑:聚合通过将相关的对象和操作封装在一起,提供了一个清晰的业务逻辑模型,有助于业务规则的实施和维护。
-
保证一致性:聚合确保内部状态的一致性,通过定义清晰的边界和规则,聚合可以在内部强制执行业务规则,从而保证数据的一致性。
-
简化复杂性:聚合通过组织相关的对象,简化了领域模型的复杂性。这有助于开发者更好地理解和扩展系统。
-
-
实现手段:
-
定义聚合根:选择合适的聚合根是实现聚合的第一步。聚合根应该是能够代表整个聚合的实体,并且拥有唯一标识。
-
限制访问路径:只能通过聚合根来修改聚合内的对象,不允许直接修改聚合内部对象的状态,以此来维护边界和一致性。
-
设计事务策略:在聚合内部实现事务一致性,确保操作要么全部完成,要么全部回滚。对于聚合之间的交互,可以采用领域事件或其他机制来实现最终一致性。
-
封装业务规则:在聚合内部实现业务规则和逻辑,确保所有的业务操作都遵循这些规则。
-
持久化:聚合根通常与数据持久化层交互,以保存聚合的状态。这通常涉及到对象-关系映射(
ORM)或其他数据映射技术。
-
仓储和适配器
在DDD设计方法中,领域层只关系领域服务的实现。最能体现这样设计的就是仓库和适配器的设计。通常在Service+数据模型的设计者,会在Service中引入Redis、RPC、配置中心等各类其他外部服务,但在DDD中,通过仓储和适配器以及基础设施层的定义,解耦了这部分内容
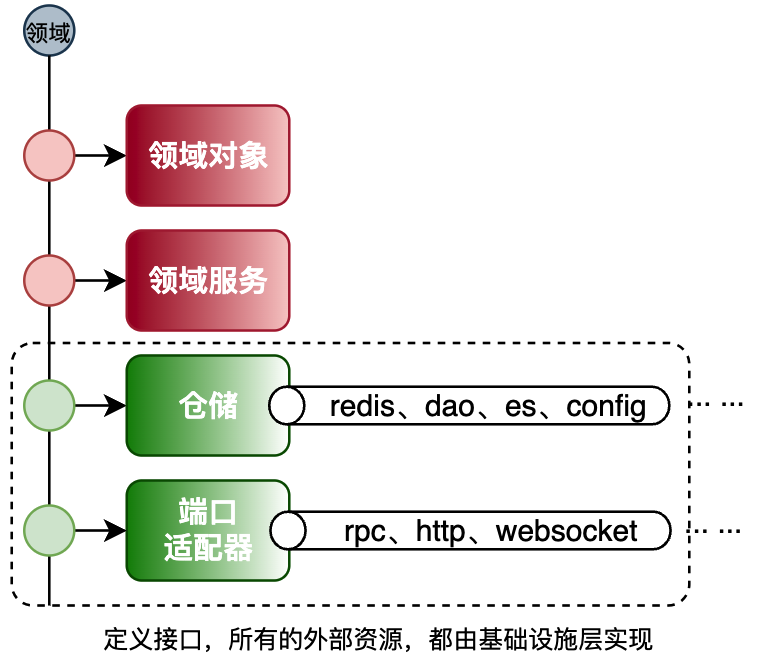
-
特征:
-
封装持久化操作:Repository负责封装所有与数据源交互的操作,如创建、读取、更新和删除(CRUD)操作。这样,领域层的代码就可以避免直接处理数据库或其他存储机制的复杂性。
-
领域对象的集合管理:Repository通常被视为领域对象的集合,提供了查询和过滤这些对象的方法,使得领域对象的获取和管理更加方便。
-
抽象接口:Repository定义了一个与持久化机制无关的接口,这使得领域层的代码可以在不同的持久化机制之间切换,而不需要修改业务逻辑。
-
用途:
-
数据访问抽象:Repository为领域层提供了一个清晰的数据访问接口,使得领域对象可以专注于业务逻辑的实现,而不是数据访问的细节。
-
领域对象的查询和管理:Repository使得对领域对象的查询和管理变得更加方便和灵活,支持复杂的查询逻辑。
-
领域逻辑与数据存储分离:通过Repository模式,领域逻辑与数据存储逻辑分离,提高了领域模型的纯粹性和可测试性。
-
优化数据访问:Repository实现可以包含数据访问的优化策略,如缓存、批处理操作等,以提高应用程序的性能。
-
实现手段:
-
定义Repository接口:在领域层定义一个或多个Repository接口,这些接口声明了所需的数据访问方法。
-
实现Repository接口:在基础设施层或数据访问层实现这些接口,具体实现可能是使用ORM(对象关系映射)框架,如MyBatis、Hibernate等,或者直接使用数据库访问API,如JDBC等。
-
依赖注入:在应用程序中使用依赖注入(DI)来将具体的Repository实现注入到需要它们的领域服务或应用服务中。这样做可以进一步解耦领域层和数据访问层,同时也便于单元测试。
-
使用规范模式(Specification Pattern):有时候,为了构建复杂的查询,可以结合使用规范模式,这是一种允许将业务规则封装为单独的业务逻辑单元的模式,这些单元可以被Repository用来构建查询。
Repository模式是DDD(领域驱动设计)中的一个核心概念,它有助于保持领域模型的聚焦和清晰,同时提供了灵活、可测试和可维护的数据访问策略。
仓储解耦的手段使用了依赖倒置的设计,所有领域需要的外部服务,不在直接引入外部的服务,而是通过定义接口的方式,让基础设施层实现领域层接口(仓储/适配器)的方式来处理。
那么也就是基础设置层负责原则对接数据库、缓存、配置中心、RPC接口、HTTP接口、MQ推送等各项资源,并承接领域服务的接口调用各项服务为领域层提供数据能力。
同时这也会体现出,领域层的实现是具有业务语义的,而到了基础设置层则没有业务语义,都是原子的方法。通过原子方法的组合为领域业务语义提供支撑。
领域编排
在 DDD 中,每一个领域都是界限上下文拆分的独立结果,而实现业务流程的功能则需要串联各个领域模块提供一整条链路的完整服务。所以也常说领域内事务一致性,领域外最终一致性。
同时这些领域模块因为是独立的,所以也可以被复用。在不同的场景功能诉求下,可以选择不同的领域模块进行组装,这个过程就像搭积木一样。
但这里有一个取舍,如果项目相对来说并不大,也没有太多的编排处理。那么可以直接让触发器层对接领域层,减少编排层后,编码会更加便捷。
触发器
在所有的模型都定义完成后,领域业务被串联了。那么接下来则是使用,而使用的方式可以包括;接口(http/rpc)、消息监听、定时任务等方式,这些方式统一被定义为触发动作。
由触发发起对编排功能的调用处理。如;定时任务做信贷的计息、开户成功消息通知返利优惠券、提供接口让外部调用授信逻辑等。这些都是触发动作。
总结
软件设计方法是一个复杂的领域,涉及多种概念和实践。范式提供了设计哲学,模型帮助我们理解和抽象系统,框架为开发提供了基础结构,方法论指导整个开发过程。软件设计的主要活动——建模、测试、工程、开发、部署和维护——是确保软件项目成功的关键步骤。每个活动都需要专业知识和技能,以及对应的工具和技术的支持。通过这些活动的协同工作,软件工程师能够交付高质量、满足用户需求的软件产品。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)