注意力变形
·
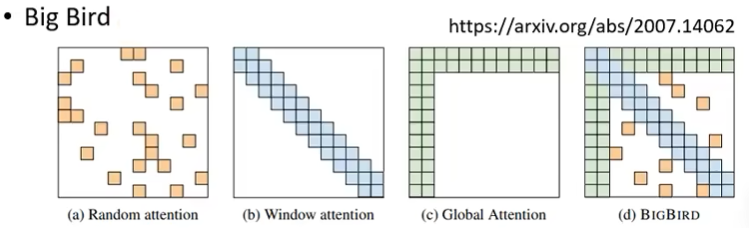
Local Attention
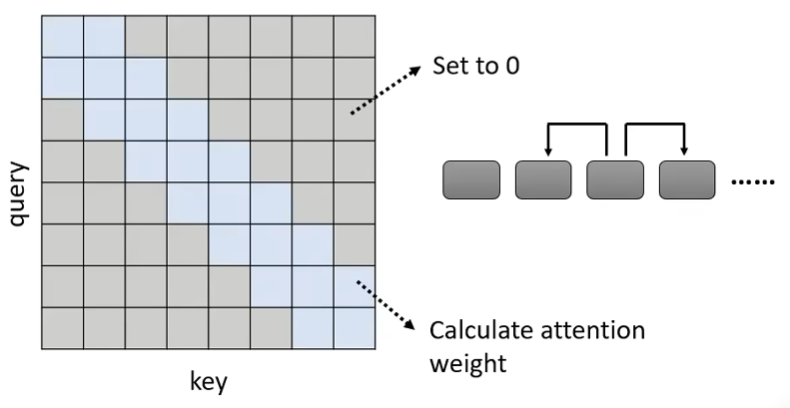
Stride Attention
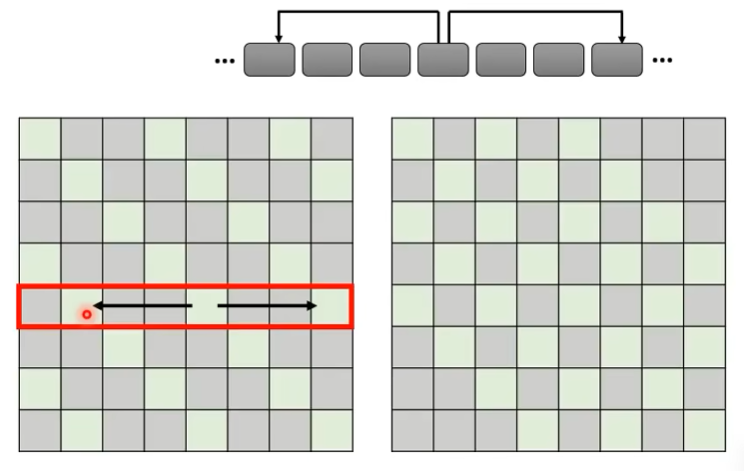
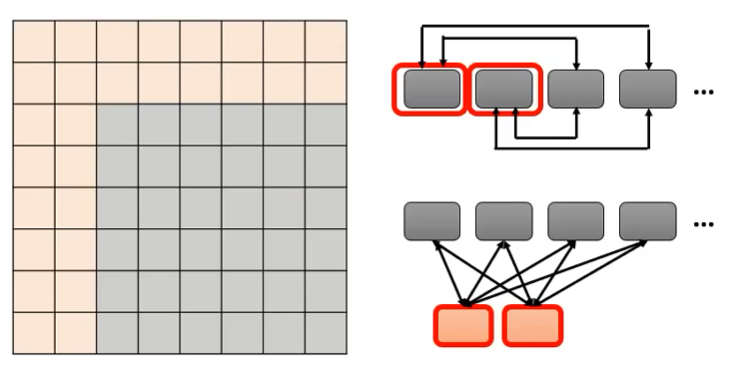
Global Attention
LongFormer
- LocalAttn+StrideAttn+GlobalAttn
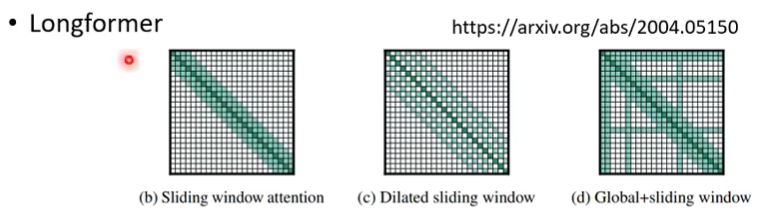
BigBird
- LocalAttn+StrideAttn+GlobalAttn+RandomAttn
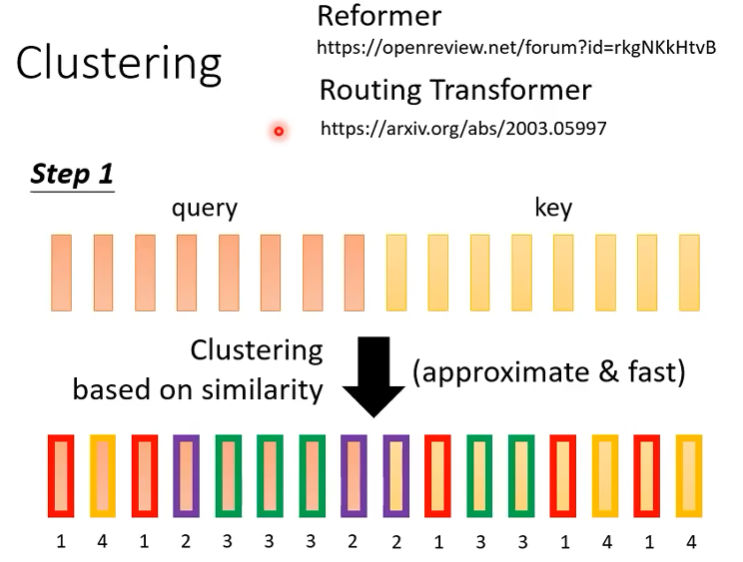
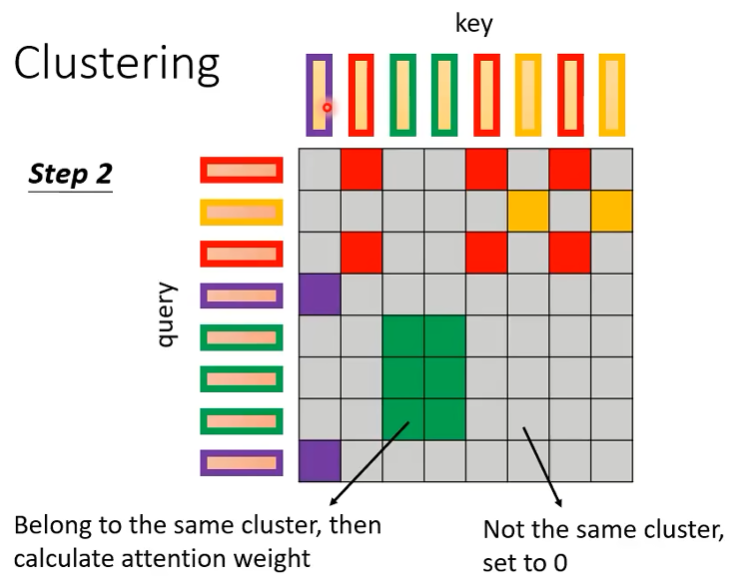
Cluster Attention
Sinkhorn Sorting Network
- 基本思想:首先对N个token预测N个分数,根据分数排序,之后应用局部注意力,就会使得相似分数的之间计算注意力。
这个机制可以分解为以下五个清晰的步骤:
步骤一:分块(Divide and Conquer)
和许多高效注意力模型一样,它不直接操作单个令牌(Token)。
- 输入:一个很长的令牌序列(长度为 N)。
- 操作:将这个长序列切分成
k个连续的、不重叠的块(Blocks)。例如,一个长度为4096的序列,可以被切成64个长度为64的块。 - 目的:
- 降低后续操作的粒度,提高计算效率。
- 保留每个块内部的局部语境信息。
步骤二:学习排序规则(The “SortNet” Brain)
这是该模型最创新的部分。模型需要学习一个“排序计划”,决定这些块应该如何重排。
- 生成块的摘要:对于每一个块,通过一个池化操作(如对块内所有令牌的嵌入向量求和或取平均)生成一个代表该块整体语义的向量。现在我们有了
k个摘要向量。 - 运行排序网络 (SortNet):这是一个小型的神经网络。它接收这
k个摘要向量,并输出一个大小为k x k的原始得分矩阵R。 - 得分矩阵
R的含义:R[i, j]的分值代表了模型认为“将原始的第i个块,移动到新序列的第j个位置”的倾向性有多强。分值越高,倾向性越强。
步骤三:可微分排序(The Sinkhorn “Magic”)
我们不能直接根据得分矩阵 R 进行“硬”排序(例如用argmax),因为这个操作不可微分,模型无法学习。因此,需要一个“软”的、可微分的替代方案。
- 输入:上一步得到的
k x k的原始得分矩阵R。 - 操作:对矩阵
R应用Sinkhorn-Knopp算法进行迭代归一化。这个过程主要包括:- 对
R取指数,确保所有值为正。 - 反复地、交替地对矩阵的行和列进行归一化(使每行/每列的和为1)。
- 对
- 输出:一个大小为
k x k的**“软”排列矩阵S**。 - 矩阵
S的特性:- 它是一个双随机矩阵(Doubly Stochastic Matrix):每行之和为1,每列之和也为1。
- 它是“软”的:矩阵内的值是0到1之间的连续浮点数,而不是离散的0和1。
- 它代表了一个加权的排序方案。
S[i, j]的值(通常接近0或1)代表了第i个原始块在构成新序列的第j个块时所占的“权重”。 - 最关键的是,整个过程是可微分的。
步骤四:执行序列重排(Execute the Sort)
现在我们有了“排序计划”(矩阵 S),可以对原始的块序列进行重排了。
- 操作:通过一次简单的矩阵乘法,将“软”排列矩阵
S与分好块的原始序列X_blocks相乘。Sorted_Blocks = S × X_blocks - 输出:一个新的、排好序的块序列。在这个新序列中,根据模型学到的规则,语义上或功能上相似的块已经被“物理地”移动到了一起,成为了邻居。
步骤五:局部注意力(Attend Locally)
这是最终收获成果的阶段。
- 输入:上一步得到的、排好序的块序列。
- 操作:在这个“整洁”的新序列上,应用一个非常高效且计算量小的局部(滑动窗口)注意力。
- 目的:由于所有相关的信息块已经被排到了一起,一个简单的局部窗口就足以捕捉到它们之间的关系。这等同于用局部的计算成本,实现了准全局的注意力效果。
Linformer
- 基本原理:压缩key的数量,只选取代表性的key与对应的value
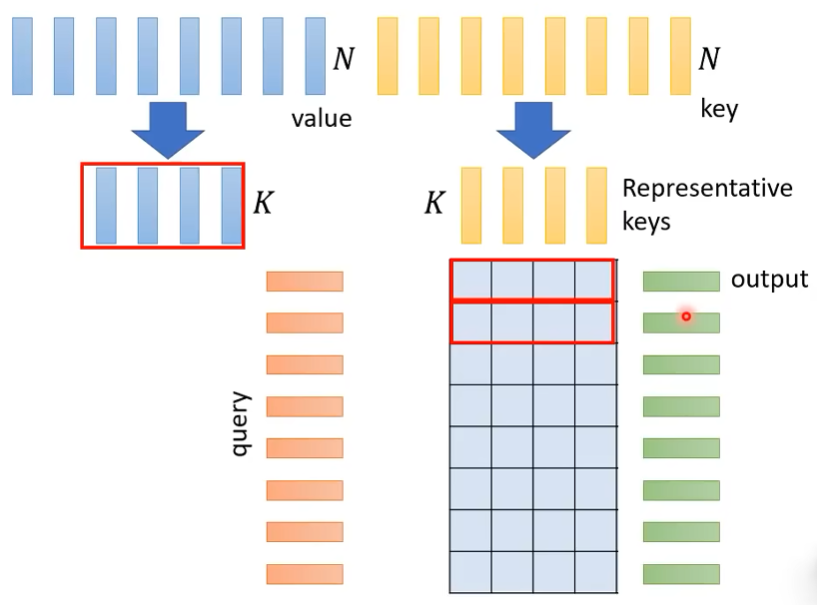
- 针对如何选出K个代表性的key,两种做法、
- Compressed Attention的做法是经过CNN,Linformer的做法是经过全连接层
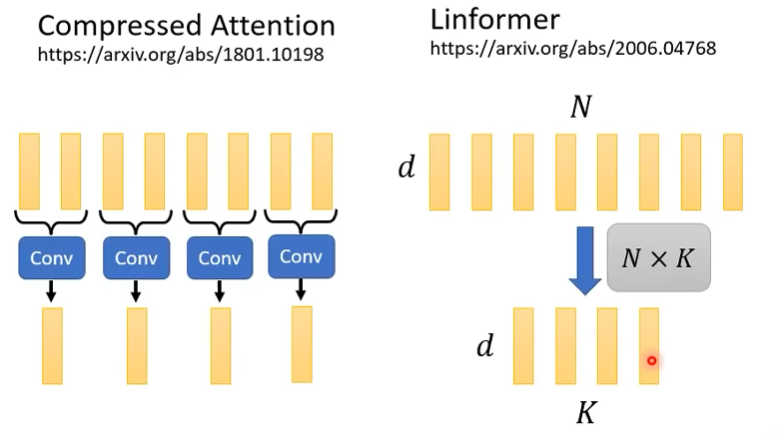
- Q:为什么不把query也压缩了呢?A:压缩query的话,输出长度也会变,在部分应用下可以压缩query
注意力新的计算方式
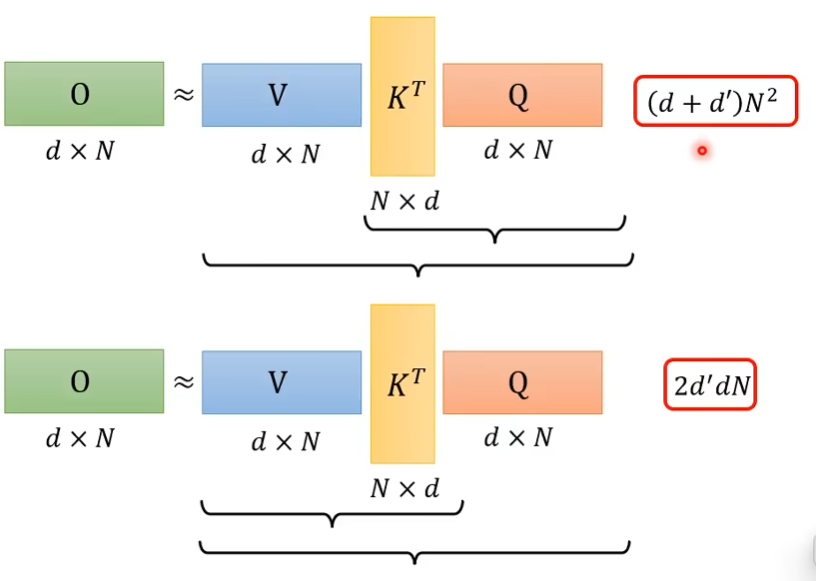
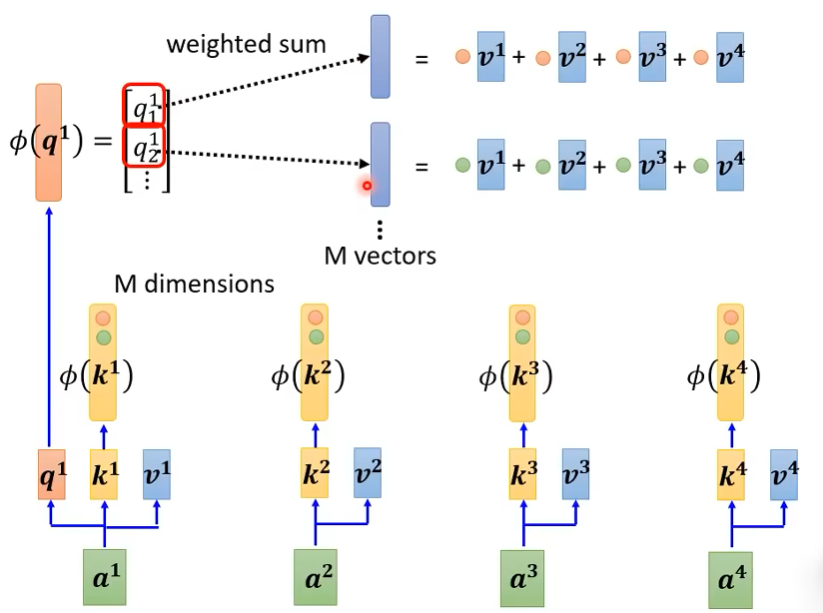
关于如何将exp(q*k)拆解,不同paper不同做法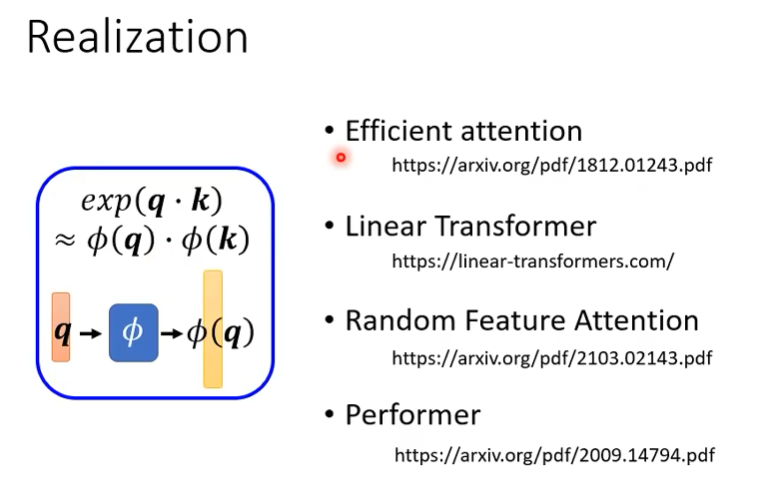
Synthesizer
- 将注意力权重矩阵作为网络的一部分,而不是经过QK点积运算


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)