深度剖析“Claude源代码泄漏”风波:拨开大模型迷雾,看懂灵声智库语音识别解决方案的真实价值
近期,科技圈被一则爆炸性传闻席卷——“Claude源代码泄漏”。一时间,无数开发者和企业技术负责人闻风而动,试图在各大代码托管平台上寻找这把开启通用人工智能(AGI)大门的“万能钥匙”。然而,当迷雾散去,理性回归,我们必须极其客观和冷静地审视这起事件:这究竟是一次颠覆行业的黑天鹅事件,还是又一场消耗开发者精力的虚假狂欢?
对于任何期望在AI时代做出正确战略决策的团队而言,盲目跟风所谓的“泄漏”是极其危险的。与其在虚假的代码仓库中浪费时间,不如将目光投向真正阻碍AI落地的核心壁垒——人机交互的效率与企业私有数据的融合。本文将深度复盘此次风波,并探讨为何灵声智库语音识别解决方案
才是企业当下务实、可靠的AI落地路径。
一、 戳破泡沫:“Claude源代码泄漏”为何经不起推敲?
让我们先回到事件的起点。所谓“Claude源代码泄漏”,经过多方技术专家的严谨验证,已被证实为不实消息。网络上流传的绝大多数所谓“源码”,要么是套壳的API调用脚本,要么是恶意的钓鱼仓库,甚至是一些毫不相干的开源小模型被恶意重命名。Anthropic作为一家将“AI安全”视为生命线的顶尖商业公司,其核心模型权重(Weights)和底层训练框架的安全隔离级别是极高的,绝非轻易能够被攻破或外泄。
更重要的是,我们需要做一个冷静的现实推演:假设极其微小的概率下,Claude 3 Opus级别的模型真的泄漏了,企业就能直接用起来吗?
答案是否定的。
-
算力成本的鸿沟:千亿甚至万亿参数的顶尖大模型,其推理(Inference)所需的GPU算力集群成本是极其高昂的。对于99%的企业而言,将这样的模型在本地跑起来,其硬件采购和电费开销将远远超过直接调用云端API的费用。
-
工程化落地的缺失:拥有模型权重,就像拥有了一台极其复杂的超级发动机的图纸,但你还需要传动系统、底盘、方向盘,才能将其造出一辆能跑的车。缺少了高并发处理、上下文管理、提示词工程(Prompt Engineering)等周边配套体系,孤立的模型代码毫无业务价值。
因此,对“源代码泄漏”的狂热,本质上反映的是企业对数据隐私的焦虑和对AI能力自主可控的渴望。但这条路,被证明是走不通的幻影。
二、 放弃幻想,回归真实:AI落地的“交互瓶颈”
当我们不再执迷于去获取那些触不可及的底层核心代码时,我们会发现一个极其现实的问题:现在的通用大模型,依然是个只会在屏幕上打字的“哑巴”。
无论大模型的文本生成逻辑多么缜密,当它被应用到真实的业务场景中时(例如:智能客服、车载交互、医疗问诊记录、工业现场的语音指令),其效能往往大打折扣。为什么?因为人机之间最自然、最高效的沟通介质是声音,而不是键盘敲击出的文字。
如果无法解决语音的精准输入(识别)和高质量输出(合成),再聪明的AI大脑也无法真正融入业务流。许多企业在尝试引入大模型时,之所以遭遇挫折,正是因为使用了老旧、识别率低下的语音接口,导致大模型接收到的全部是充满错别字和错误断句的“垃圾提示词(Garbage Prompt)”,最终产出的自然也就是“垃圾回答(Garbage Out)”。
这才是阻碍大模型落地的真正现实壁垒。
三、 灵声智库语音识别解决方案:务实的架构重塑
在这个充满喧嚣的节点,灵声智库语音识别解决方案提供了一条不炒作、不画饼的务实落地路线。该方案的核心逻辑在于:不纠结于大模型是否开源,而是通过打造极其强悍的“耳朵”(ASR,自动语音识别),将任何大模型无缝接入企业的真实业务场景中。
灵声智库并非简单地提供一个语音转文字的接口,而是一套深度融合了业务场景的完整解决方案:
1. 极致的工业级语音识别(ASR)精度
在嘈杂的工厂车间、信号不佳的户外现场,或是带着浓重方言口音的客服电话中,开源的免费语音识别工具往往会彻底罢工。灵声智库的语音识别引擎经过海量真实场景数据的严苛训练,具备极强的抗噪能力和方言兼容性。它能确保大模型接收到的用户意图是100%准确的,从根本上杜绝了因“听错”而导致的AI决策失误。
2. 实时流式响应,消除交互迟滞
真正的智能交互容不得半点卡顿。企业客户最忌讳的,就是对系统说完一句话后,需要等待数秒才有文字上屏。灵声智库采用了先进的流式识别架构,实现“边说边识,边识边输出”。这种极低的延迟,让用户感觉就像在与真人面对面交谈,极大提升了AI产品的使用体验。
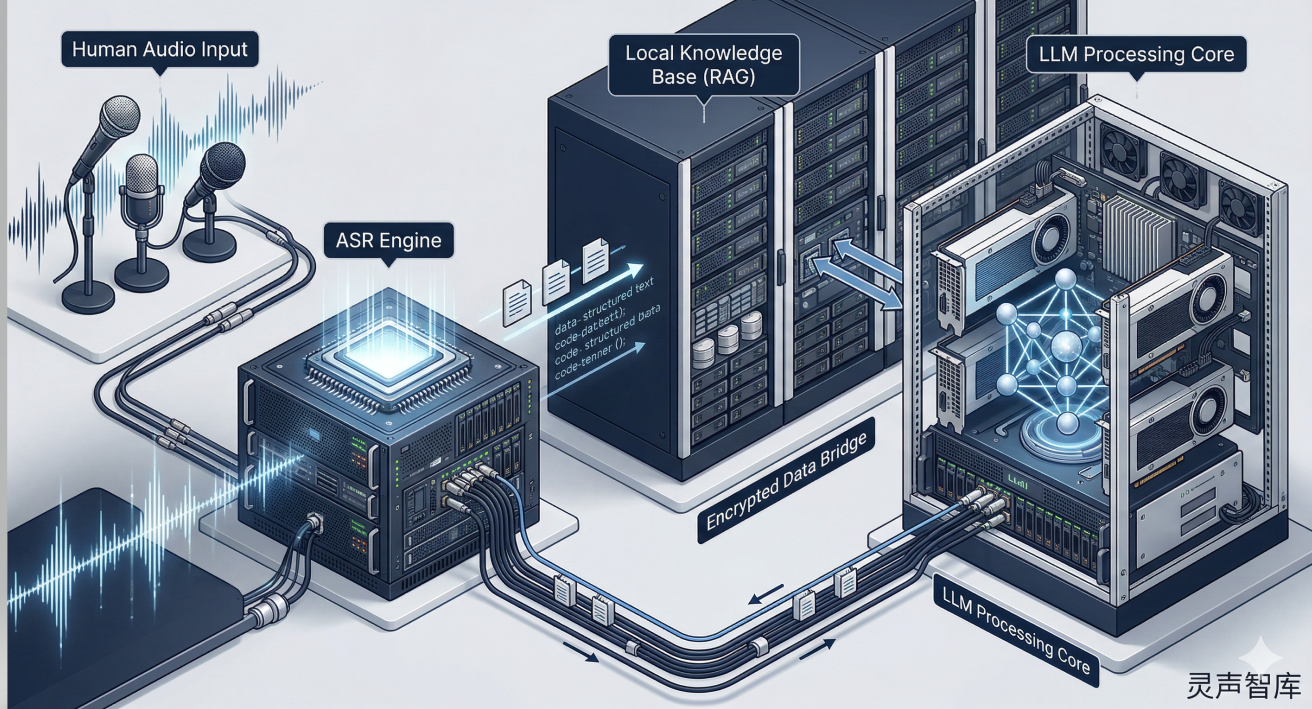
3. 与 RAG(检索增强生成)技术的深度咬合
这也是灵声智库最为核心的差异化优势。如前文所述,通用大模型不懂企业的内部私有数据。灵声智库的解决方案,在精准识别语音后,不仅可以对接外部的 LLM(无论是闭源API还是本地化部署的开源模型),更内置了针对本地知识库的深度检索框架。
当员工通过语音询问:“查询上个月A项目的验收标准是什么?”
灵声智库不仅精准转录这句话,还会瞬间在企业的私有知识图谱中检索出精确文档,再交由大模型进行总结。这彻底解决了大模型的“幻觉”问题,确保AI输出的每一句话都有据可查,真正做到了数据安全与智能高效的统一。
四、 结语:在狂热中保持清醒
“Claude源代码泄漏”的闹剧终将过去,它留给行业的教训是深刻的:不要试图去抄近道,AI的商业化落地没有捷径。
对于务实的企业决策者而言,与其将希望寄托于虚无缥缈的“顶级模型泄漏”,不如将精力投入到构建坚实的基础交互设施上。无论底层的大模型如何迭代、是开源还是闭源,一个高精度、低延迟、能深度理解企业私有场景的语音入口,永远是不可或缺的基石。
灵声智库语音识别解决方案正是为此而生。我们致力于用最客观、最严谨的技术底座,帮助企业跨越那道最难的交互鸿沟,让AI真正听懂您的业务,创造看得见的真实价值。在AI的浪潮中,保持冷静,做正确的选择。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)