AI 伦理实验:Python 实现信用评分模型 + SHAP/LIME 可解释性分析全流程
前言
在金融风控领域,AI 信用评分模型早已成为核心工具,但模型黑箱问题和算法歧视风险一直是 AI 伦理关注的焦点。单纯追求模型准确率远远不够,能清晰解释模型决策、保障模型公平性,才是符合行业规范与伦理要求的关键。
本篇教程基于 UCI 经典德国信用数据集,从零搭建虚拟环境,完成数据预处理、模型训练、性能评估,再用 SHAP 做全局可解释性分析、LIME 做单样本决策解释,最后开展 AI 公平性伦理检测,全程代码可直接运行,适配课程实验、毕业设计、技术分享,新手也能轻松复现!
教程关键词
AI 伦理、信用评分模型、可解释性 AI、SHAP、LIME、Python 机器学习、金融风控
一、实验环境搭建
1. 虚拟环境创建与激活
推荐使用 Anaconda 创建独立虚拟环境,避免依赖冲突,打开 Anaconda Prompt(以管理员身份运行) 执行以下命令:
# 创建名为ai_ethics的虚拟环境,指定Python3.10稳定版本
conda create -n ai_ethics python=3.10 -y
# 激活虚拟环境
conda activate ai_ethics2. 核心依赖库安装
本实验需要数据处理、机器学习、可视化、可解释性分析相关库,一键安装:
pip install numpy pandas matplotlib seaborn scikit-learn shap lime ipykernel imbalanced-learn3. Jupyter Notebook 内核绑定
为了让 Jupyter Notebook 能调用ai_ethics虚拟环境,需要将环境注册为 Jupyter 内核。操作步骤:
- 确保已激活
ai_ethics环境(命令行前缀显示(ai_ethics)) - 执行以下命令创建项目目录并注册内核:
# 创建项目目录 mkdir D:\AI_Ethics_Lab # 进入项目目录 cd /d D:\AI_Ethics_Lab # 注册Jupyter内核 python -m ipykernel install --user --name ai_ethics --display-name "Python (ai_ethics)" 执行成功后,打开 Jupyter Notebook,即可在「Kernel → Change kernel」中选择
Python (ai_ethics),使用该虚拟环境运行代码。jupyter notebook
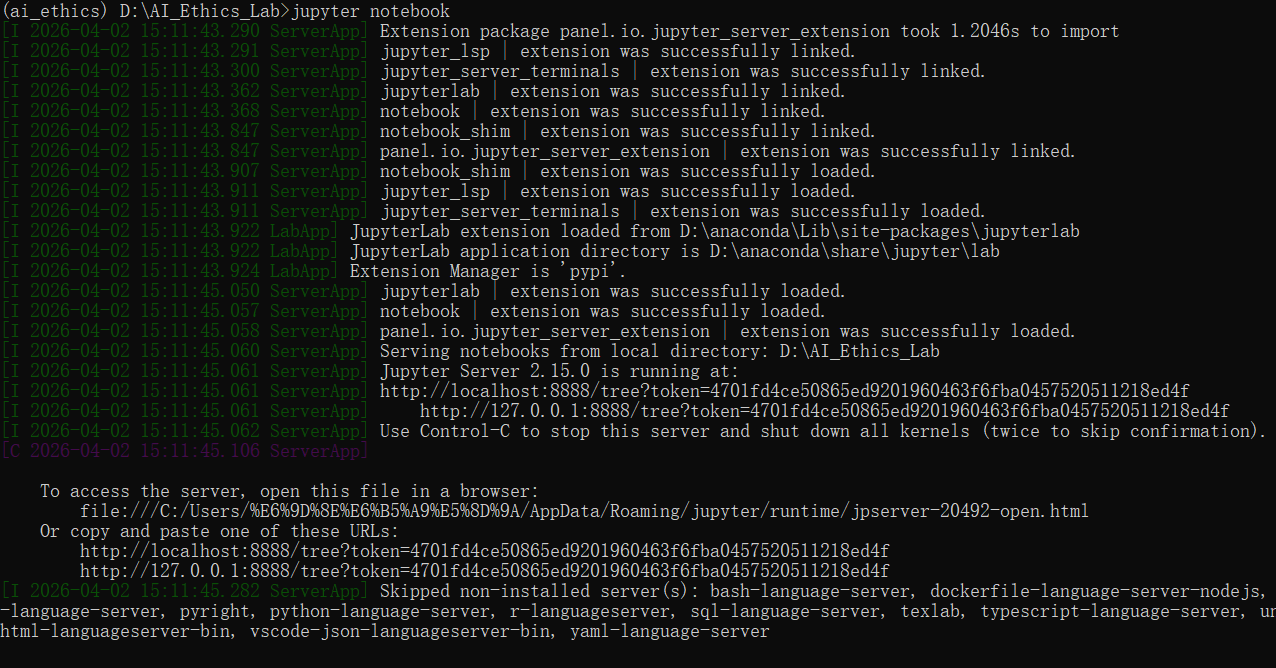
复制终端运行后出现的链接到浏览器打开即可使用jupyter notebook
二、数据集介绍
本次使用的德国信用数据集(Statlog German Credit Data) 是金融风控与 AI 伦理研究的经典基准数据集,包含1000 条用户样本、20 个特征 + 1 个标签:
- 特征维度:涵盖用户账户状态、贷款期限、信用历史、贷款金额、年龄、职业、婚姻状况等财务与个人信息
- 标签含义:原始标签 1 = 好信用(用户可正常还款),2 = 坏信用(用户存在违约风险)
- 数据集特点:类别不平衡(好信用 700 条,坏信用 300 条),包含年龄、性别等敏感特征,适合做公平性检测
下载德国数据集:
import pathlib, urllib.request
folder = pathlib.Path("D:/AI_Ethics_Lab")
folder.mkdir(parents=True, exist_ok=True)
urls = {
"german.data": "https://archive.ics.uci.edu/ml/machine-learning-databases/statlog/german/german.data",
"german.doc": "https://archive.ics.uci.edu/ml/machine-learning-databases/statlog/german/german.doc"
}
for name, url in urls.items():
out = folder / name
urllib.request.urlretrieve(url, out)
print("已下载:", out)
# 3. 加载并查看数据集
import pandas as pd
df = pd.read_csv("D:/AI_Ethics_Lab/german.data", sep=" ", header=None)
print(df.shape) # 正常应输出 (1000, 21)
df.head()三、实验全流程代码实现
Cell1 库导入与路径配置
首先导入所有需要的库,配置数据路径与结果输出目录,解决中文可视化乱码问题:
# 【Cell1】导入依赖库+基础配置
import os
import warnings
warnings.filterwarnings("ignore") # 屏蔽无关警告,让输出更整洁
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 机器学习相关
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import (classification_report, confusion_matrix,
ConfusionMatrixDisplay, balanced_accuracy_score, roc_auc_score)
# 可解释性AI库
import shap
from lime.lime_tabular import LimeTabularExplainer
from IPython.display import display
# 解决Matplotlib中文乱码+负号显示异常
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 定义数据路径与结果输出目录,自动创建目录避免报错
data_path = os.path.join(os.getcwd(), "german.data")
out_dir = os.path.join(os.getcwd(), "module1_outputs")
os.makedirs(out_dir, exist_ok=True)
print("数据集路径:", data_path)
print("结果输出目录:", out_dir)Cell2 数据加载与字段命名
原始数据无表头,需手动添加语义化字段名,方便后续数据处理与分析:
# 【Cell2】加载数据+定义字段名
column_names = [
"账户状态", "贷款期限", "信用历史", "贷款用途", "贷款金额", "储蓄账户",
"就业时长", "分期付款率", "个人状态(性别/婚姻)", "其他债务人",
"居住时长", "资产情况", "年龄", "其他分期付款计划", "住房情况",
"现有信贷数", "工作类型", "抚养人数", "电话状态", "外籍工人", "信用标签"
]
# 读取数据,适配原始数据的多空格分隔格式
df = pd.read_csv(data_path, sep=r"\s+", header=None, names=column_names)
# 查看数据维度与前5行,验证加载结果
print("数据集维度:", df.shape)
display(df.head())运行结果:数据集维度为(1000, 21),说明数据加载成功。
Cell3 标签转换
原始标签为 1/2,不符合机器学习 0/1 的标准格式,进行转换:
# 【Cell3】标签转换:好信用=1,坏信用=0
df["信用标签"] = df["信用标签"].map({1: 1, 2: 0})
# 查看转换后标签分布
print("转换后标签分布:")
print(df["信用标签"].value_counts())运行结果:1(好信用)700 条,0(坏信用)300 条,与数据集原始分布一致。
Cell4 训练集与测试集划分
采用分层抽样划分,保证训练集和测试集的正负样本比例与原数据一致,避免类别分布偏差:
# 【Cell4】划分特征与标签,拆分训练集、测试集
X_raw = df.drop(columns=["信用标签"]) # 特征集:剔除标签列
y = df["信用标签"] # 标签集
# 80%训练集,20%测试集,stratify=y实现分层抽样
X_train_raw, X_test_raw, y_train, y_test = train_test_split(
X_raw, y, test_size=0.2, random_state=42, stratify=y
)
print("训练集特征维度:", X_train_raw.shape)
print("测试集特征维度:", X_test_raw.shape)运行结果:训练集(800, 20),测试集(200, 20),划分完成。
Cell5 特征编码与对齐
数据中包含大量分类型特征,需进行 One-Hot 编码,同时保证训练集和测试集特征列完全一致:
# 【Cell5】One-Hot编码+训练集测试集特征对齐
# 对分类特征进行独热编码
X_train = pd.get_dummies(X_train_raw, drop_first=False)
X_test = pd.get_dummies(X_test_raw, drop_first=False)
# 核心步骤:特征对齐,测试集缺失的列补0,保证特征维度一致
X_train, X_test = X_train.align(X_test, join="left", axis=1, fill_value=0)
# 转换为浮点型,适配模型输入
X_train = X_train.astype(float)
X_test = X_test.astype(float)
print("编码后训练集维度:", X_train.shape)
print("编码后测试集维度:", X_test.shape)运行结果:编码后特征维度扩展为(800, 61)、(200, 61),编码与对齐完成。
Cell 6训练模型 + 评估(Balanced Random Forest + 概率校准 + 阈值控制)
from imblearn.ensemble import BalancedRandomForestClassifier
from sklearn.calibration import CalibratedClassifierCV
from sklearn.metrics import (
classification_report,
confusion_matrix,
ConfusionMatrixDisplay,
balanced_accuracy_score,
roc_auc_score
)
# ====================== 1. 更适合不均衡数据的平衡随机森林 ======================
base_model = BalancedRandomForestClassifier(
n_estimators=400,
max_depth=6,
min_samples_split=8,
min_samples_leaf=4,
max_features="sqrt",
random_state=42,
n_jobs=-1
)
# ====================== 2. 概率校准(sigmoid方法,3折交叉验证) ======================
model = CalibratedClassifierCV(base_model, method="sigmoid", cv=3)
model.fit(X_train, y_train) # y_train: 1=Approve(好信用), 0=Reject(坏信用)
# ====================== 3. 概率输出 ======================
# 取Approve(好信用=1)的预测概率
train_prob_approve = model.predict_proba(X_train)[:, 1]
test_prob_approve = model.predict_proba(X_test)[:, 1]
# 计算Reject(坏信用=0)的预测概率
train_prob_reject = 1 - train_prob_approve
test_prob_reject = 1 - test_prob_approve
# ====================== 4. 固定Reject阈值(0.5,可调整) ======================
reject_threshold = 0.5
print(f"本实验固定使用 Reject 概率阈值:{reject_threshold:.2f}")
# ====================== 5. 预测结果 ======================
# 规则:Reject概率 >= 阈值 → 判定为Reject(0),否则为Approve(1)
train_pred = np.where(train_prob_reject >= reject_threshold, 0, 1)
y_pred = np.where(test_prob_reject >= reject_threshold, 0, 1)
y_prob = test_prob_approve.copy()
# ====================== 6. 指标计算 ======================
train_bal_acc = balanced_accuracy_score(y_train, train_pred)
test_bal_acc = balanced_accuracy_score(y_test, y_pred)
# 以Reject(0)为正类计算AUC
roc_auc = roc_auc_score((y_test == 0).astype(int), test_prob_reject)
report_text = classification_report(y_test, y_pred, zero_division=0)
report_dict = classification_report(y_test, y_pred, output_dict=True, zero_division=0)
print("训练集 Balanced Accuracy:", round(train_bal_acc, 4))
print("测试集 Balanced Accuracy:", round(test_bal_acc, 4))
print("ROC-AUC(按 Reject 为目标类):", round(roc_auc, 4))
print("Reject 类 precision:", round(report_dict["0"]["precision"], 4))
print("Reject 类召回率:", round(report_dict["0"]["recall"], 4))
print("Approve 类 precision:", round(report_dict["1"]["precision"], 4))
print("Approve 类召回率:", round(report_dict["1"]["recall"], 4))
print("说明: Balanced RF 对少数类更友好, 适合 German Credit 这类不均衡数据。")
# ====================== 7. 混淆矩阵 ======================
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(cm, display_labels=["Reject", "Approve"])
disp.plot(cmap="Blues")
plt.title(f"Confusion Matrix (reject_threshold={reject_threshold:.2f})")
plt.tight_layout()
plt.savefig(os.path.join(out_dir, "confusion_matrix.png"), dpi=150)
plt.show()
# ====================== 8. 分类报告导出 ======================
print(report_text)
report_df = pd.DataFrame(
classification_report(y_test, y_pred, output_dict=True, zero_division=0)
).T
report_df.to_csv(
os.path.join(out_dir, "classification_report.csv"),
encoding="utf-8-sig"
)
# ====================== 9. 保存公平性基线表(用于后续公平性分析) ======================
fairness_base = X_test_raw.copy()
fairness_base["y_true"] = y_test.values
fairness_base["y_pred"] = y_pred
fairness_base["y_prob"] = y_prob
fairness_base.to_csv(
os.path.join(out_dir, "fairness_base_table.csv"),
index=False,
encoding="utf-8-sig"
)
print("已保存 fairness_base_table.csv")Cell 7 保存公平性模块用表
fairness_base = X_test_raw.copy()
fairness_base["y_true"] = y_test.values
fairness_base["y_pred"] = y_pred
fairness_base["y_prob"] = y_prob
fairness_base.to_csv(
os.path.join(out_dir, "fairness_base_table.csv"),
index=False,
encoding="utf-8-sig"
)
print("已保存 fairness_base_table.csv")Cell 8 SHAP 全局解释(Permutation Explainer,适配任意模型)
shap.initjs()
# 采样100条测试集,提升计算效率与稳定性
sample_n = min(100, len(X_test))
X_test_sample = X_test.iloc[:sample_n].copy()
# 初始化Permutation解释器(模型无关,适配校准后的模型)
explainer = shap.Explainer(model.predict_proba, shap.sample(X_train, 100))
shap_values = explainer(X_test_sample)
# 提取正类(Approve=好信用=1)的SHAP值
vals = shap_values.values
if vals.ndim == 3:
vals = vals[:, :, 1]
# 1. SHAP特征重要性条形图(Top15)
plt.figure(figsize=(10, 6))
shap.summary_plot(vals, X_test_sample, plot_type="bar", max_display=15, show=False)
plt.title("SHAP 特征重要性(Top15)")
plt.tight_layout()
plt.savefig(os.path.join(out_dir, "shap_bar.png"), dpi=150)
plt.show()
# 2. SHAP蜂群图(特征贡献度分布,Top15)
plt.figure(figsize=(12, 7))
shap.summary_plot(vals, X_test_sample, max_display=15, show=False)
plt.title("SHAP 蜂群图(Top15)")
plt.tight_layout()
plt.savefig(os.path.join(out_dir, "shap_beeswarm.png"), dpi=150)
plt.show()结果解读:贷款金额、账户状态、贷款期限是影响模型决策的核心特征,贷款金额越高,用户被判为坏信用的概率越大。
Cell 9 Top3特征 + 敏感特征方向分析(年龄公平性前置分析)
# 构建SHAP值DataFrame,用于后续分析
shap_df = pd.DataFrame(vals, columns=X_test_sample.columns, index=X_test_sample.index)
# 1. 输出Top3 最重要特征
top3 = shap_df.abs().mean().sort_values(ascending=False).head(3)
print("Top3 重要特征:")
display(top3)
# 2. 年龄分组SHAP分析(<35 / >=35,验证年龄对审批的影响)
if "年龄" in X_test_sample.columns:
age_high_mask = X_test_sample["年龄"] >= 35
age_low_mask = X_test_sample["年龄"] < 35
mean_shap_high = shap_df.loc[age_high_mask, "年龄"].mean() if age_high_mask.sum() > 0 else np.nan
mean_shap_low = shap_df.loc[age_low_mask, "年龄"].mean() if age_low_mask.sum() > 0 else np.nan
print("\n年龄 分组口径:<35 / >=35")
print(f">=35 组 年龄 平均SHAP = {mean_shap_high:.4f}")
print(f"<35 组 年龄 平均SHAP = {mean_shap_low:.4f}")
if pd.notna(mean_shap_high) and pd.notna(mean_shap_low):
if mean_shap_high > mean_shap_low:
print("结论:年龄较大更倾向于推动批准")
else:
print("结论:年龄较大更倾向于推动拒绝")
# 3. 通用特征方向分析函数(按中位数分组,分析特征高低值对审批的影响)
def feature_direction_summary(feature_name):
if feature_name not in X_test_sample.columns:
print(f"{feature_name} 不在样本中,跳过。")
return
median_val = X_test_sample[feature_name].median()
high_mask = X_test_sample[feature_name] >= median_val
low_mask = X_test_sample[feature_name] < median_val
high_mean = shap_df.loc[high_mask, feature_name].mean() if high_mask.sum() > 0 else np.nan
low_mean = shap_df.loc[low_mask, feature_name].mean() if low_mask.sum() > 0 else np.nan
print(f"\n{feature_name} 中位数 = {median_val:.2f}")
print(f"高值组平均SHAP = {high_mean:.4f}")
print(f"低值组平均SHAP = {low_mean:.4f}")
if pd.notna(high_mean) and pd.notna(low_mean):
if high_mean > low_mean:
print(f"结论:{feature_name} 较高时更倾向于推动批准")
else:
print(f"结论:{feature_name} 较高时更倾向于推动拒绝")
# 分析核心业务特征:贷款金额、贷款期限(现在是中文名)
for feat in ["贷款金额", "贷款期限"]:
feature_direction_summary(feat)Cell 10 选择拒贷样本
# 优先选择预测正确的Reject样本,否则选择预测为Reject的样本,最后选择Approve概率最低的样本
candidate_idx = np.where((y_pred == 0) & (y_test.values == 0))[0]
if len(candidate_idx) > 0:
reject_prob = 1 - y_prob
idx = candidate_idx[np.argmax(reject_prob[candidate_idx])]
select_reason = "在预测正确的 Reject 样本中,选择 Reject 概率最高的个案"
else:
reject_idx = np.where(y_pred == 0)[0]
if len(reject_idx) > 0:
reject_prob = 1 - y_prob
idx = reject_idx[np.argmax(reject_prob[reject_idx])]
select_reason = "没有预测正确的 Reject 样本,改为在预测为 Reject 的样本中选择 Reject 概率最高者"
else:
idx = np.argmin(y_prob)
select_reason = "没有预测为 Reject 的样本,改选 Approve 概率最低的样本"
print("样本选择策略:", select_reason)
pred_label = "Approve" if y_pred[idx] == 1 else "Reject"
true_label = "Approve" if y_test.iloc[idx] == 1 else "Reject"
prob_approve = y_prob[idx]
prob_reject = 1 - y_prob[idx]
print(f"选定样本 idx = {idx}")
print(f"真实标签:{true_label},预测:{pred_label}")
print(f"Approve 概率:{prob_approve:.4f},Reject 概率:{prob_reject:.4f}")
# 展示样本核心特征 —— 这里全部换成中文!!!
case_raw = X_test_raw.iloc[idx]
basic_cols = ["账户状态", "信用历史", "贷款用途", "贷款金额", "贷款期限", "年龄", "个人状态(性别/婚姻)"]
display(case_raw[basic_cols])伦理解读:若不同年龄组坏信用预测率差异过大,说明模型存在年龄歧视,需通过特征调整、样本重采样等方式优化,保障 AI 公平性。
Cell 11 LIME 局部解释 + 表格
explainer_lime = LimeTabularExplainer(
X_train.values,
feature_names=X_train.columns.tolist(),
class_names=["Reject", "Approve"],
discretize_continuous=True,
mode="classification"
)
class_to_explain = 0 # 解释Reject类
class_name = explainer_lime.class_names[class_to_explain]
print(f"当前 LIME 解释类别:{class_name}")
print("说明:正权重表示推动该类别,负权重表示削弱该类别。")
exp = explainer_lime.explain_instance(
X_test.iloc[idx].values,
model.predict_proba,
num_features=8,
labels=[class_to_explain]
)
# 转换为DataFrame
lime_list = exp.as_list(label=class_to_explain)
lime_df = pd.DataFrame(lime_list, columns=["feature", "weight"])
lime_df["direction"] = np.where(
lime_df["weight"] > 0,
f"推动{class_name}",
f"削弱{class_name}"
)
display(lime_df.head(8))Cell 12 客户解释短信:把 LIME 的机器解释,翻译成普通用户能看懂的自然语言解释
import re
feature_map = {
"Status_A11": "账户状态相关信息",
"Status_A12": "账户状态相关信息",
"Status_A13": "账户状态相关信息",
"Status_A14": "账户状态相关信息",
"CreditHistory_A30": "信用记录情况",
"CreditHistory_A31": "信用记录情况",
"CreditHistory_A32": "信用记录情况",
"CreditHistory_A33": "信用记录情况",
"CreditHistory_A34": "信用记录情况",
"Purpose_A40": "贷款用途信息",
"Purpose_A41": "贷款用途信息",
"Purpose_A42": "贷款用途信息",
"Purpose_A43": "贷款用途信息",
"Purpose_A44": "贷款用途信息",
"Purpose_A45": "贷款用途信息",
"Purpose_A46": "贷款用途信息",
"Purpose_A47": "贷款用途信息",
"Purpose_A48": "贷款用途信息",
"Purpose_A49": "贷款用途信息",
"Purpose_A10": "贷款用途信息",
"Savings_A61": "储蓄情况",
"Savings_A62": "储蓄情况",
"Savings_A63": "储蓄情况",
"Savings_A64": "储蓄情况",
"Savings_A65": "储蓄情况",
"CreditAmount": "贷款金额",
"Duration": "贷款期限",
"InstallmentRate": "分期还款压力",
"OtherInstallmentPlans_A141": "其他分期安排情况",
"OtherInstallmentPlans_A142": "其他分期安排情况",
"OtherInstallmentPlans_A143": "其他分期安排情况",
"Property_A121": "财产情况",
"Property_A122": "财产情况",
"Property_A123": "财产情况",
"Property_A124": "财产情况"
}
def translate_lime_feature(feature_text):
# 过滤敏感属性
if re.search(r"Age|PersonalStatus|Foreignworker", feature_text):
return None
matched_desc = None
for key, value in feature_map.items():
if key in feature_text:
matched_desc = value
break
if matched_desc is None:
return None
return matched_desc
# 提取推动Reject的特征
push_df = lime_df[lime_df["weight"] > 0].copy()
push_df["translated_feature"] = push_df["feature"].apply(translate_lime_feature)
push_df = push_df.dropna(subset=["translated_feature"])
# 去重,取Top3核心原因
reason_list = []
for item in push_df["translated_feature"].tolist():
if item not in reason_list:
reason_list.append(item)
reason_text = "、".join(reason_list[:3])
if reason_text == "":
reason_text = "信用记录、负债压力与申请信息等综合因素"
# 生成客户短信
msg = f"""
您好,感谢您的申请。经综合评估,本次贷款申请暂未通过。
综合影响较大的因素主要包括:{reason_text}。
建议您后续结合信用与还款相关材料进一步完善后再尝试申请。
如需人工复核或咨询,可联系客户经理。
"""
print("客户解释短信:")
print(msg)Cell 13 基础偏见检测
fairness = X_test_raw.copy()
fairness["y_prob"] = y_prob
fairness["y_pred"] = y_pred
# 1) 年龄分组
fairness["age_group"] = np.where(fairness["年龄"] < 35, "<35", ">=35")
age_count = fairness["age_group"].value_counts()
age_rate = fairness.groupby("age_group")["y_prob"].mean()
age_pred_rate = fairness.groupby("age_group")["y_pred"].mean()
print("年龄组样本量:")
print(age_count)
print("\n年龄组平均批准概率:")
print(age_rate)
print("\n年龄组预测批准率:")
print(age_pred_rate)
# 可视化年龄组批准率
plt.figure(figsize=(5, 3))
sns.barplot(x=age_rate.index, y=age_rate.values)
plt.title("年龄组平均批准概率")
plt.tight_layout()
plt.savefig(os.path.join(out_dir, "age_group_rate.png"), dpi=150)
plt.show()
plt.figure(figsize=(5, 3))
sns.barplot(x=age_pred_rate.index, y=age_pred_rate.values)
plt.title("年龄组预测批准率")
plt.tight_layout()
plt.savefig(os.path.join(out_dir, "age_group_pred_rate.png"), dpi=150)
plt.show()
# 2) PersonalStatus 分组
fairness["personal_group"] = fairness["个人状态(性别/婚姻)"]
personal_count = fairness["personal_group"].value_counts()
personal_rate = fairness.groupby("personal_group")["y_prob"].mean().sort_values(ascending=False)
personal_pred_rate = fairness.groupby("personal_group")["y_pred"].mean().sort_values(ascending=False)
print("\nPersonalStatus 各组样本量:")
print(personal_count)
print("\nPersonalStatus 各组平均批准概率:")
print(personal_rate)
print("\nPersonalStatus 各组预测批准率:")
print(personal_pred_rate)
# 可视化PersonalStatus批准率
plt.figure(figsize=(6, 3))
sns.barplot(x=personal_rate.index, y=personal_rate.values)
plt.title("PersonalStatus 各组平均批准概率")
plt.xticks(rotation=30)
plt.tight_layout()
plt.savefig(os.path.join(out_dir, "personal_status_rate.png"), dpi=150)
plt.show()
plt.figure(figsize=(6, 3))
sns.barplot(x=personal_pred_rate.index, y=personal_pred_rate.values)
plt.title("PersonalStatus 各组预测批准率")
plt.xticks(rotation=30)
plt.tight_layout()
plt.savefig(os.path.join(out_dir, "personal_status_pred_rate.png"), dpi=150)
plt.show()Cell 14 候选保护属性筛查
screen_rows = []
# 1) Age
age_group = fairness["age_group"]
age_counts = age_group.value_counts()
age_prob_by_group = fairness.groupby("age_group")["y_prob"].mean()
age_pred_by_group = fairness.groupby("age_group")["y_pred"].mean()
age_prob_gap = age_prob_by_group.max() - age_prob_by_group.min()
age_pred_gap = age_pred_by_group.max() - age_pred_by_group.min()
screen_rows.append({
"属性名": "Age",
"分组数量": len(age_counts),
"最小组样本量": int(age_counts.min()),
"平均批准概率差异(最大-最小)": round(float(age_prob_gap), 3),
"预测批准率差异(最大-最小)": round(float(age_pred_gap), 3),
"是否存在初步差异": "是" if age_pred_gap >= 0.05 else "轻微",
"是否适合进入实验2主分析": "是",
"建议角色": "主保护属性"
})
# 2) PersonalStatus
ps_group = fairness["personal_group"]
ps_counts = ps_group.value_counts()
ps_prob_by_group = fairness.groupby("personal_group")["y_prob"].mean()
ps_pred_by_group = fairness.groupby("personal_group")["y_pred"].mean()
ps_prob_gap = ps_prob_by_group.max() - ps_prob_by_group.min()
ps_pred_gap = ps_pred_by_group.max() - ps_pred_by_group.min()
screen_rows.append({
"属性名": "PersonalStatus",
"分组数量": len(ps_counts),
"最小组样本量": int(ps_counts.min()),
"平均批准概率差异(最大-最小)": round(float(ps_prob_gap), 3),
"预测批准率差异(最大-最小)": round(float(ps_pred_gap), 3),
"是否存在初步差异": "是" if ps_pred_gap >= 0.05 else "轻微",
"是否适合进入实验2主分析": "是",
"建议角色": "主保护属性"
})
# 生成筛查表
screen_df = pd.DataFrame(screen_rows)
display(screen_df)
# 保存筛查表
screen_df.to_csv(
os.path.join(out_dir, "protected_attr_screening.csv"),
index=False,
encoding="utf-8-sig"
)
print("已保存 protected_attr_screening.csv")
# 筛查结论
print("\n筛查结论:")
print("1. Age 在平均批准概率与预测批准率上均存在较稳定差异,且样本量充足,适合作为实验2主保护属性。")
print("2. PersonalStatus 组间差异更明显,具有较强分析价值。")Cell 15 实验-伦理审计总结
ethics_text = f"""
伦理审计结论:
本实验基于 German Credit 数据构建了「平衡随机森林 + 概率校准」的信贷审批基线模型,并固定 0.50 作为拒绝阈值。
最终训练集 Balanced Accuracy 为 {train_bal_acc:.2f},测试集 Balanced Accuracy 为 {test_bal_acc:.2f},以 Reject 为目标的 ROC-AUC 为 {roc_auc:.2f}。
在当前设定下,Reject 类与 Approve 类的召回率相对接近。这说明模型在经历数据平衡与阈值调优后,在「风险拦截」与「避免误伤」之间找到了相对稳健的平衡点。
从全局可解释性(SHAP)结果看,Account_Status_A14(账户无透支)、Duration_in_month(贷款期限)、Credit_amount(贷款金额)等特征对审批结果影响最大。
需要高度警惕的是,Age_in_years(年龄)高居特征重要性前五,Personal_status_and_sex(个人状态与性别)也实质性地参与了风险判断。
这意味着模型在判断违约风险时,确实参考了客户的人口统计学特征。因此,年龄与性别必须作为「实验二」的核心保护属性,进行更严苛的公平性量化审查。
局部解释(LIME 与 SHAP 单样本)对典型「高风险漏网之鱼」(本该拒绝却被误批的个案)的剖析表明:
模型之所以做出错误的批准决策,往往是因为账户状态(如 A14)、特定贷款用途等特征的「加分」推力,掩盖了长贷款期限、高贷款金额带来的高风险警告。
这验证了局部解释工具的核心价值:它不仅能带模型自圆其说,更能像「显微镜」一样,帮我们深挖模型在特定个案上,究竟是被哪些特征「蒙蔽」了双眼。
【核心价值观】
本实验再次强调:可解释不等于合理,可解释也不等于公平。
在信贷审批等高风险场景中,算法的透明性(比如我们现在知道了模型会看年龄)应当成为公平审计与责任追问的起点,而不是终点。
"""
print("-" * 50)
print(ethics_text)
print("-" * 50)
print("\n下一步行动建议:")
print("1. 【指标深化】在实验二中继续计算 SPD(统计平价差)、DI(差别影响比例)等公平性指标,明确模型是否对特定年龄段或性别构成了实质性歧视。")
print("2. 【人工介入】对涉及敏感属性(或其代理变量)影响得分畸高的边缘样本,应引入人工复核(HITL机制),避免完全依赖自动化审批。")
print("3. 【用户沟通】探索将局部解释转化为面向用户的自然语言输出,提高信贷决策透明度,为客户申诉提供实质性依据。")四、实验总结
- 全流程复现:本教程完成了从环境搭建、数据预处理、模型训练到可解释性分析、AI 伦理检测的完整流程,代码无冗余、可直接运行。
- 可解释性落地:通过 SHAP 实现全局特征重要性分析,通过 LIME 实现单样本决策解释,打破模型黑箱,让模型决策有据可依。
- AI 伦理实践:针对敏感特征开展公平性检测,贴合当下 AI 伦理规范要求,适用于金融风控、AI 伦理相关课程实验与毕业设计。
- 拓展方向:可替换逻辑回归、XGBoost 等模型,或针对性别、外籍工人等敏感特征做进一步公平性优化,也可将模型封装为 API 实现工程化部署。
五、常见问题排查
- ModuleNotFoundError: No module named 'seaborn':激活 ai_ethics 环境,重新执行
pip install seaborn。 - 数据加载失败:检查
german.data是否放在 Jupyter 工作目录,路径是否正确。 - 训练集测试集维度不一致:必须执行
align方法做特征对齐,否则模型无法训练。 - 中文可视化乱码:确认电脑安装 SimHei 字体,或替换为系统自带中文字体。
六、写在最后
AI 的发展不仅要追求技术效率,更要坚守伦理底线。可解释性与公平性是 AI 落地金融、医疗等敏感领域的核心前提,希望本篇教程能帮助大家掌握可解释性 AI 实战方法,树立 AI 伦理意识~
原创教程,码字不易,欢迎点赞、收藏、关注,有问题可在评论区交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)