大模型应用:AI智能体高并发实战:Redis缓存+负载均衡协同解决推理超时难题.133
一、前言
在 AI 智能体落地生产的过程中,多轮对话交互、高频用户咨询、批量业务请求并发涌入已是常态。原生大模型智能体依赖LLM实时完成语义理解、意图识别、上下文推理生成回复,单实例推理速度慢、算力消耗高、队列积压严重。一旦线上访问量突增,极易出现接口响应超时、服务阻塞崩溃、用户体验断崖式下跌等问题。
单纯优化模型推理参数难以根治瓶颈,行业成熟落地方案普遍采用双层架构兜底:依托 Redis 内存缓存拦截高频标准化问答,降低无效LLM推理消耗;搭配负载均衡实现多智能体模型实例流量分发,横向拓展并发承载上限,今天我们结合前期铺垫的基础原理、智能体联动逻辑、示例实践、性能对比、落地规范全方位分析,由浅入深拆解高并发场景下智能体服务稳定优化全流程。

二、基础概念
1. 核心概念解析
- 大模型推理超时:大模型接收到用户请求后,需要完成文本编码、注意力计算、文本解码等操作,并发量突增时,请求排队堆积,超过设定的响应时间阈值,如3s或5s,即为推理超时,直接导致服务不可用。
- Redis 缓存:基于内存的高性能键值存储数据库,读写速度达10万+QPS,远快于大模型推理的几十QPS,用于存储高频问题 + 标准答案,用户重复提问时直接返回缓存,无需调用模型。
- 负载均衡:将突增的并发请求,均匀分发到多个模型服务实例上,避免单节点过载,提升系统整体处理能力,实现水平扩容。
- 并发量QPS:每秒请求数,是衡量大模型服务并发承载能力的核心指标,并发突增即QPS短时间内大幅上涨。
2. AI智能体运行逻辑
AI对话智能体并非单次简单问答拼接,核心依托三大基础模块联动:
- 1. 短时记忆模块:基于会话ID存储当前多轮上下文,依靠Tiktoken统计Token、动态裁剪超长对话,保障语义连贯;
- 2. 长时记忆模块:通过Embedding向量模型将历史对话向量化存储,语义检索召回久远关联信息,突破上下文窗口限制;
- 3. LLM推理核心:接收拼接后的标准Prompt,完成意图理解、逻辑推演、文本生成,是整个智能体最慢、资源消耗最高的核心节点。
- 4. 正常低并发场景下三大模块稳定协同,一旦并发暴涨,LLM推理节点会直接成为性能短板,引发全链路超时。
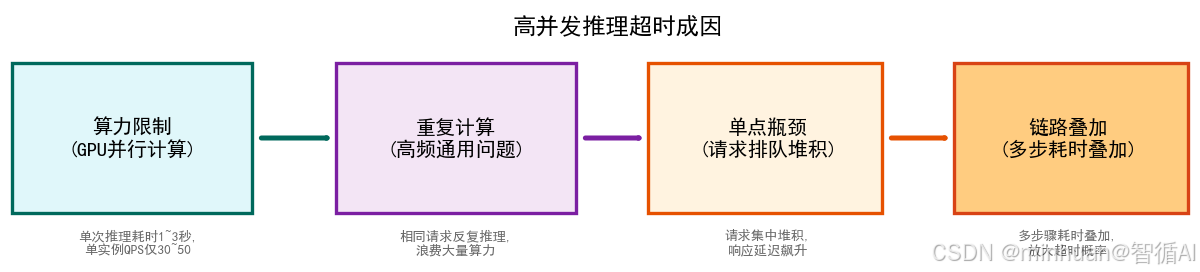
3. 高并发推理超时成因
- 1. 算力限制:LLM依赖GPU并行计算,单次推理耗时1~3秒,单实例天然QPS仅有30~50;
- 2. 重复计算:智能体高频接收通用基础问题,相同请求反复调用模型推理,浪费大量算力;
- 3. 单点瓶颈:所有请求集中流向单一智能体服务节点,请求排队堆积、链路响应延迟飙升;
- 4. 链路叠加:上下文拼接、向量检索、Token校验叠加耗时,进一步放大超时概率。
4. 核心优化组件基础认知
4.1 Redis 高性能缓存
- 基于内存运行的键值数据库,读写响应毫秒级,原生支持 10W+ QPS。
- 以标准化问题哈希 Key + 智能体标准回复 Value存储数据,设置自动过期策略,命中缓存即可绕过 LLM 推理直接响应,完美承接智能体高频重复咨询流量。
4.2 服务负载均衡
- 将海量并发请求按照轮询、权重分配规则,均匀分发至多组智能体后端实例。
- 规避单点过载风险,同时支持横向新增节点扩容,平衡全集群算力压力,保障智能体整体服务稳定性。
三、智能体并发架构整体流程
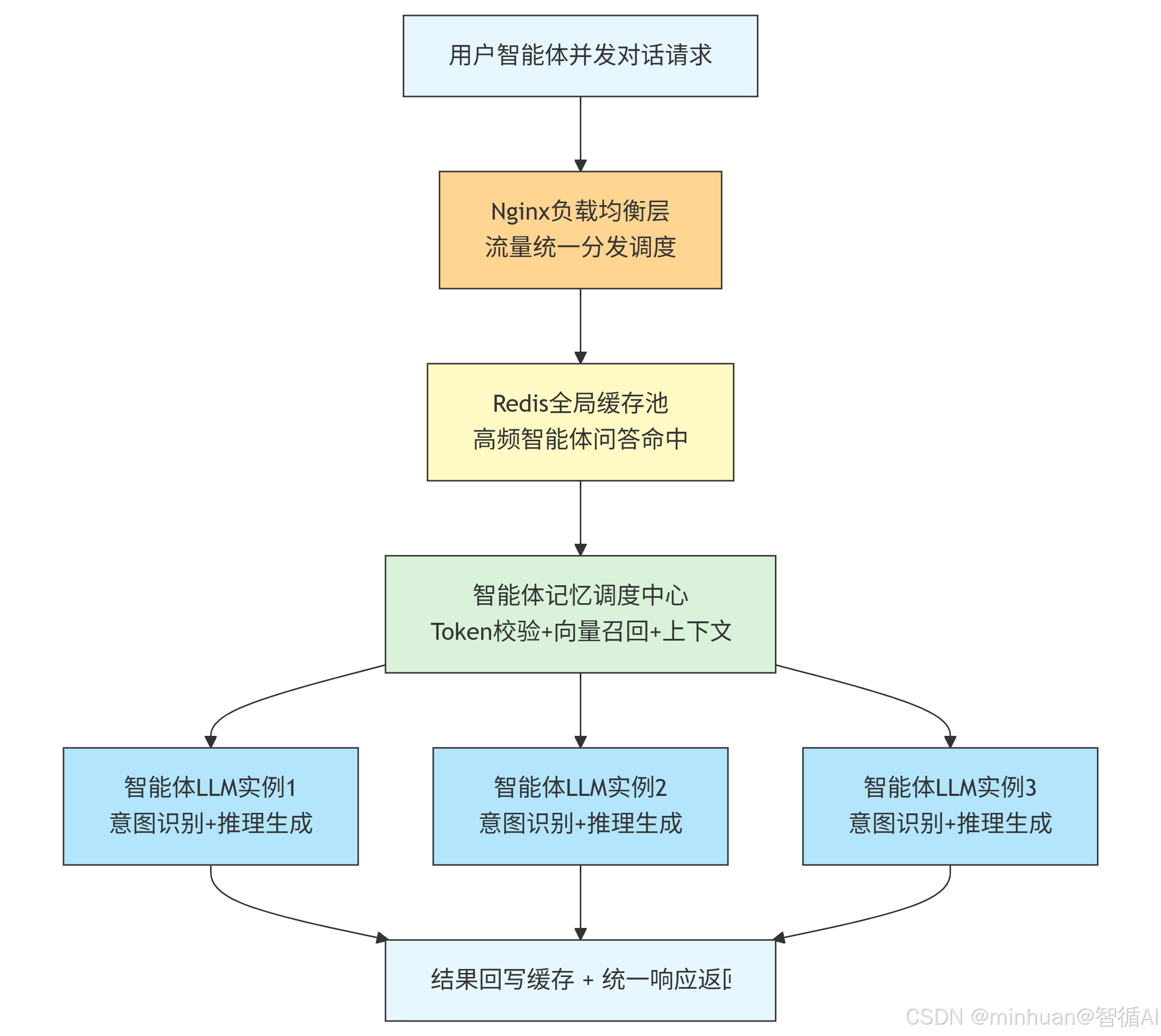
1. 架构说明
- 用户请求经 Nginx 负载均衡后,优先命中 Redis 全局缓存。
- 记忆调度中心 处理上下文(Token校验、向量召回、拼接)后,将任务分发至多个并行的LLM实例。
- 各LLM实例完成推理后,结果统一回写缓存并返回给用户,形成高并发、可扩展的智能体服务闭环。
2. 整体业务架构流转
- 1. 用户发起智能体对话请求,统一接入 Nginx 负载均衡入口层;
- 2. 负载节点优先校验 Redis 缓存池,检索当前标准化问题是否存在历史智能体回复;
- 3. 缓存命中:毫秒级直接返回预置标准答案,无需触发记忆拼接与 LLM 推理;
- 4. 缓存未命中:调用智能体记忆链路(短时上下文 + 长时向量召回)拼接完整 Prompt;
- 5. 请求分流至多组空闲 LLM 智能体实例完成推理生成;
- 6. 推理结果同步写入 Redis 缓存过期池,同时结构化返回前端用户;
3. 智能体优化价值说明
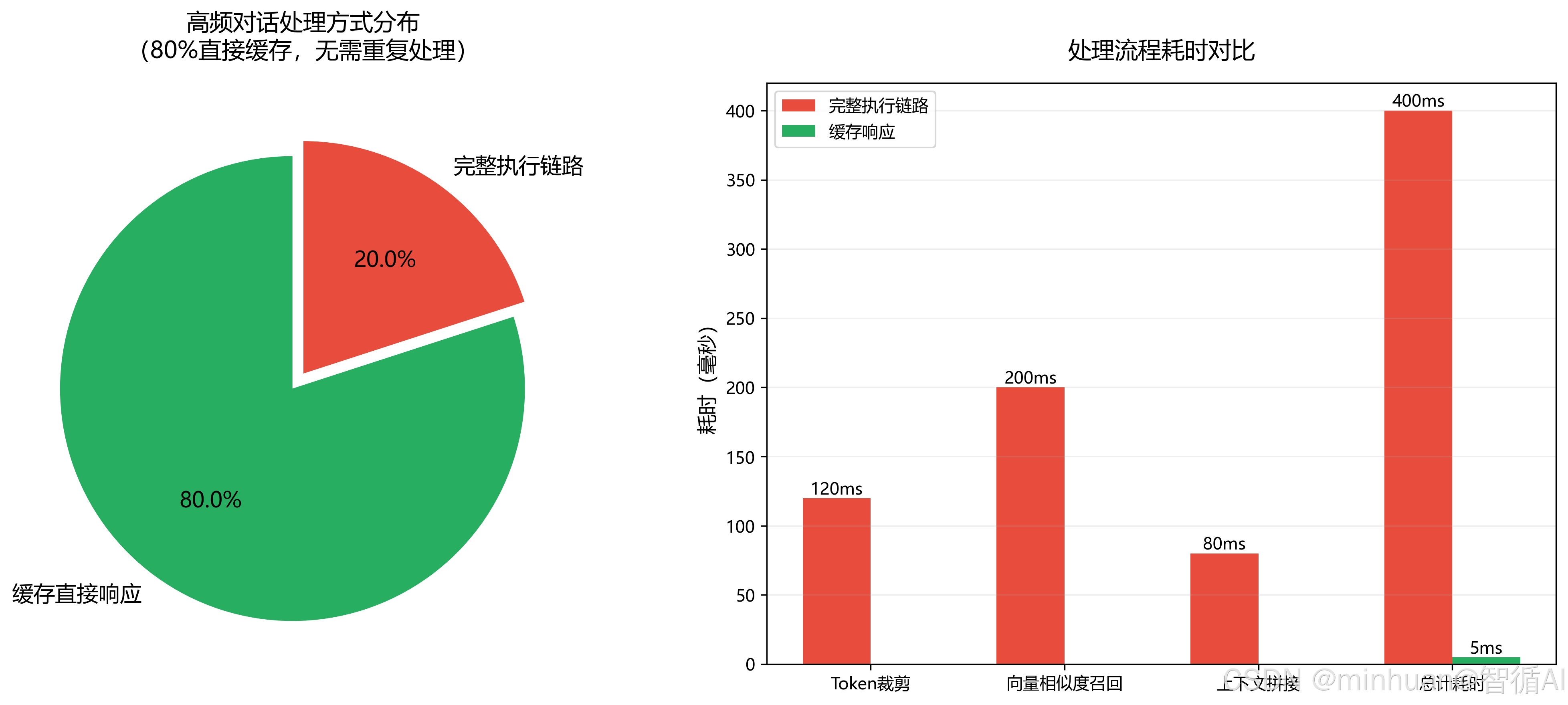
- 减负记忆链路:80%高频通用对话直接缓存响应,无需重复执行Token裁剪、向量相似度召回、上下文拼接逻辑;
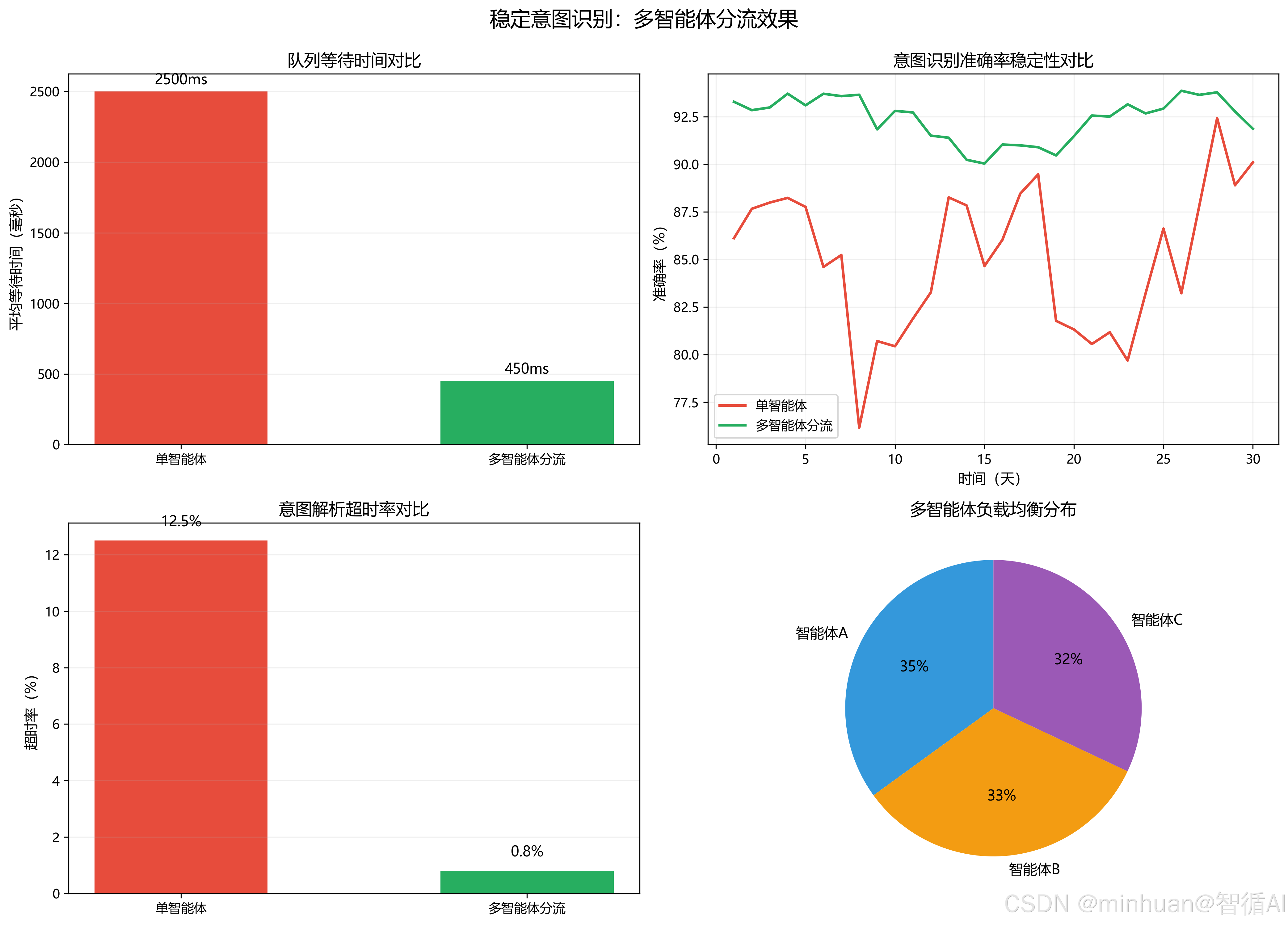
- 稳定意图识别:分流后单智能体实例压力下降,避免队列拥堵导致意图解析超时、识别准确率波动;
- 保障多轮连贯:核心个性化复杂对话走原生智能体推理链路,兼顾缓存提速与上下文语义关联性;
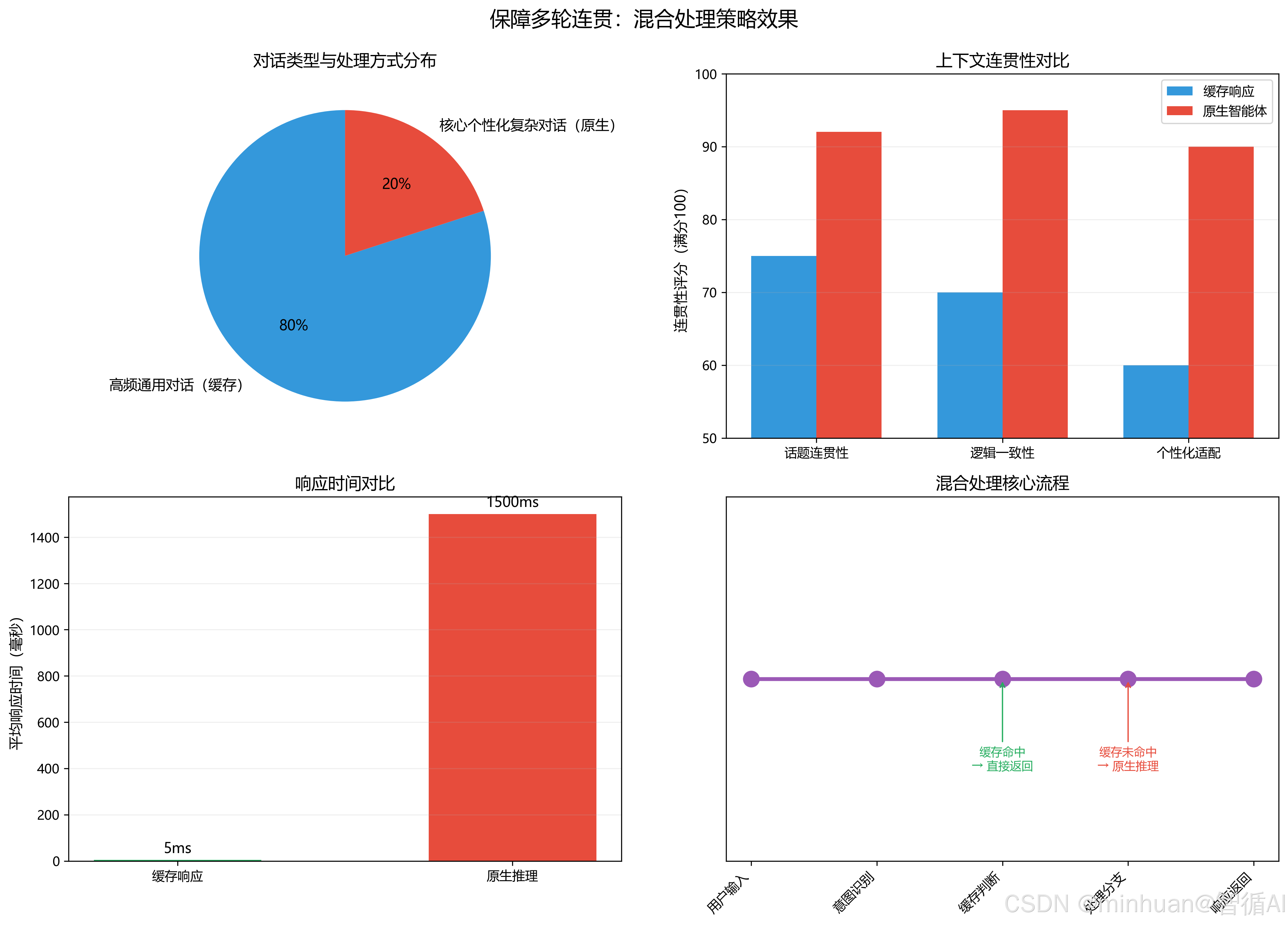
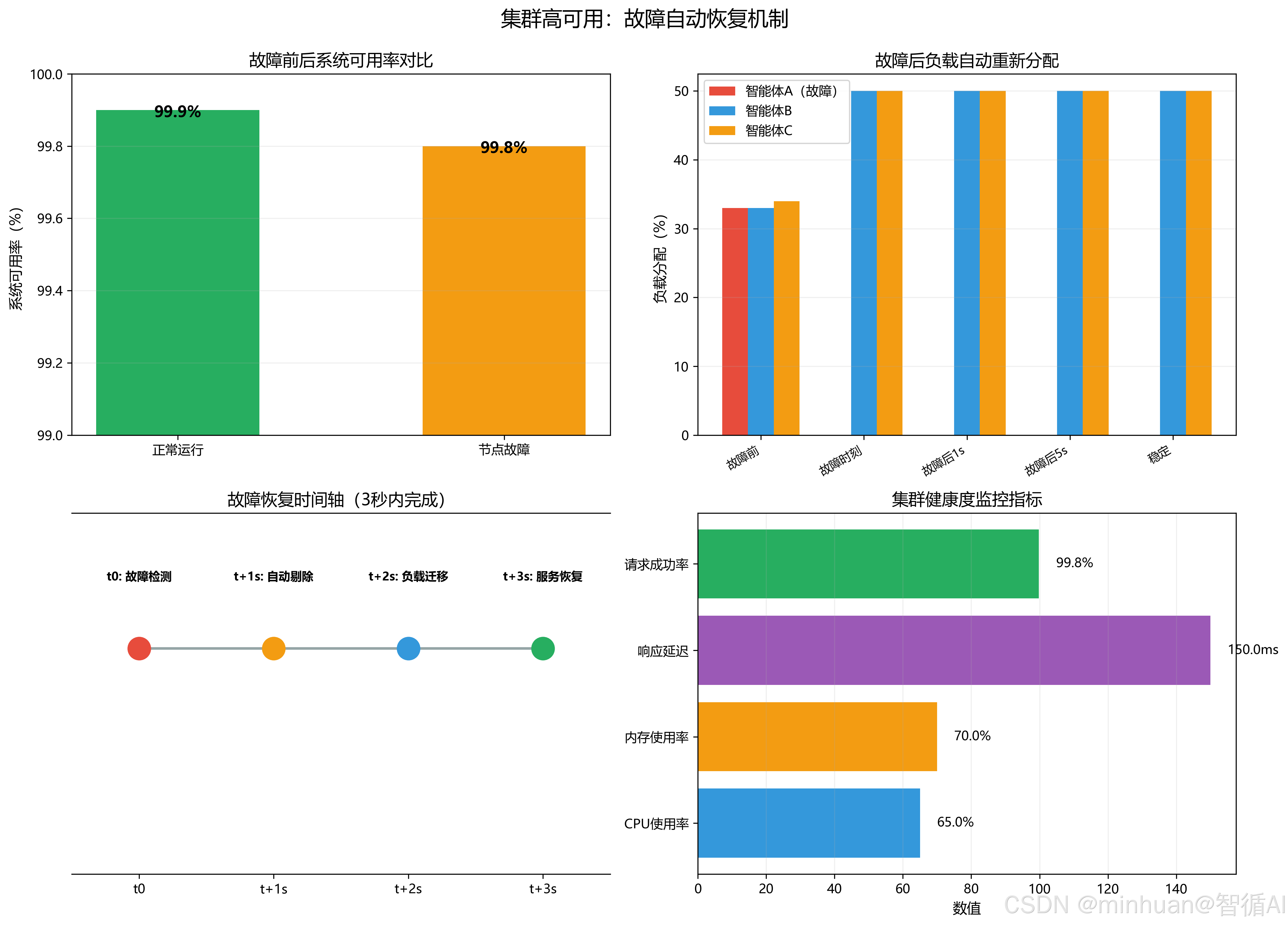
- 集群高可用:单节点智能体故障时,负载均衡自动剔除节点,不影响整体智能体对外服务能力。
四、基础原理解析
1. Redis缓存加速原理
- 依托内存读写替代磁盘IO,查询复杂度为O(1);
- 针对智能体标准化业务问题做Key哈希固化,搭配TTL过期时间策略,既保证回复时效性,又避免冷数据堆积。
- 高命中率场景下直接绕过智能体记忆校验与LLM生成全链路,响应耗时压缩至10ms以内。
2. 负载均衡流量调度原理
- 采用基础轮询调度均匀分配请求,结合后端健康探测机制实时监控智能体实例状态。
- 当某一LLM智能体负载过高或宕机,自动暂停流量分发;
- 横向扩容新增推理节点后,集群整体处理能力线性提升,完美对冲突发流量峰值。
3. 智能体协同优化底层逻辑
- 常规智能体全链路:请求→Token 统计→上下文裁剪→向量召回→Prompt 拼接→LLM 推理;
- 优化后分流链路:
- 高频请求:请求→Redis 命中→直接返回,截断后端所有智能体计算;
- 复杂请求:请求→未命中→负载分发→智能体记忆调度→多实例推理→回写缓存。
五、基础应用示例
1. Redis 缓存集成
import redis
import json
import time
# 连接Redis
redis_client = redis.Redis(
host="localhost",
port=6379,
db=0,
decode_responses=True # 自动解码字符串
)
# 模拟大模型推理函数
def llm_infer(query: str) -> str:
"""模拟模型推理(耗时操作)"""
time.sleep(1.5) # 模拟推理延迟1.5s
return f"模型回答:{query}的解决方案是Redis缓存+负载均衡"
# 带缓存的问答接口
def chat_with_cache(query: str, expire=3600) -> str:
"""
带Redis缓存的对话接口
:param query: 用户问题
:param expire: 缓存过期时间(秒)
:return: 回答内容
"""
# 1. 查询缓存
cache_key = f"llm:cache:{query}"
cache_result = redis_client.get(cache_key)
if cache_result:
print("【缓存命中】直接返回结果")
return cache_result
# 2. 缓存未命中,调用模型
print("【缓存未命中】调用大模型推理")
answer = llm_infer(query)
# 3. 写入缓存
redis_client.setex(cache_key, expire, answer)
return answer
# 测试
if __name__ == "__main__":
# 第一次请求(未命中缓存)
start = time.time()
print(chat_with_cache("大模型并发超时怎么办"))
print(f"耗时:{time.time()-start:.2f}s\n")
# 第二次请求(命中缓存)
start = time.time()
print(chat_with_cache("大模型并发超时怎么办"))
print(f"耗时:{time.time()-start:.4f}s")输出结果:
【缓存未命中】调用大模型推理
模型回答:大模型并发超时怎么办的解决方案是Redis缓存+负载均衡
耗时:1.51s【缓存命中】直接返回结果
模型回答:大模型并发超时怎么办的解决方案是Redis缓存+负载均衡
耗时:0.0045s
2. 负载均衡模拟
import random
import time
# 模拟模型服务集群
model_nodes = [
"http://192.168.3.101:8000",
"http://192.168.3.102:8000",
"http://192.168.3.103:8000"
]
def load_balance() -> str:
"""轮询+随机负载均衡策略"""
return random.choice(model_nodes)
def concurrent_request_simulation(request_num: int):
"""模拟并发请求分发"""
print(f"模拟{request_num}个并发请求分发:")
for i in range(1, request_num+1):
node = load_balance()
print(f"请求{i} -> 分发至:{node}")
time.sleep(0.1)
# 测试:模拟20个并发请求
if __name__ == "__main__":
concurrent_request_simulation(20)输出结果:
模拟20个并发请求分发:
请求1 -> 分发至:http://192.168.3.101:8000
请求2 -> 分发至:http://192.168.3.103:8000
请求3 -> 分发至:http://192.168.3.101:8000
请求4 -> 分发至:http://192.168.3.103:8000
请求5 -> 分发至:http://192.168.3.101:8000
请求6 -> 分发至:http://192.168.3.103:8000
请求7 -> 分发至:http://192.168.3.103:8000
请求8 -> 分发至:http://192.168.3.102:8000
请求9 -> 分发至:http://192.168.3.101:8000
请求10 -> 分发至:http://192.168.3.103:8000
请求11 -> 分发至:http://192.168.3.101:8000
请求12 -> 分发至:http://192.168.3.101:8000
请求13 -> 分发至:http://192.168.3.103:8000
请求14 -> 分发至:http://192.168.3.102:8000
请求15 -> 分发至:http://192.168.3.101:8000
请求16 -> 分发至:http://192.168.3.101:8000
请求17 -> 分发至:http://192.168.3.103:8000
请求18 -> 分发至:http://192.168.3.103:8000
请求19 -> 分发至:http://192.168.3.103:8000
请求20 -> 分发至:http://192.168.3.102:8000
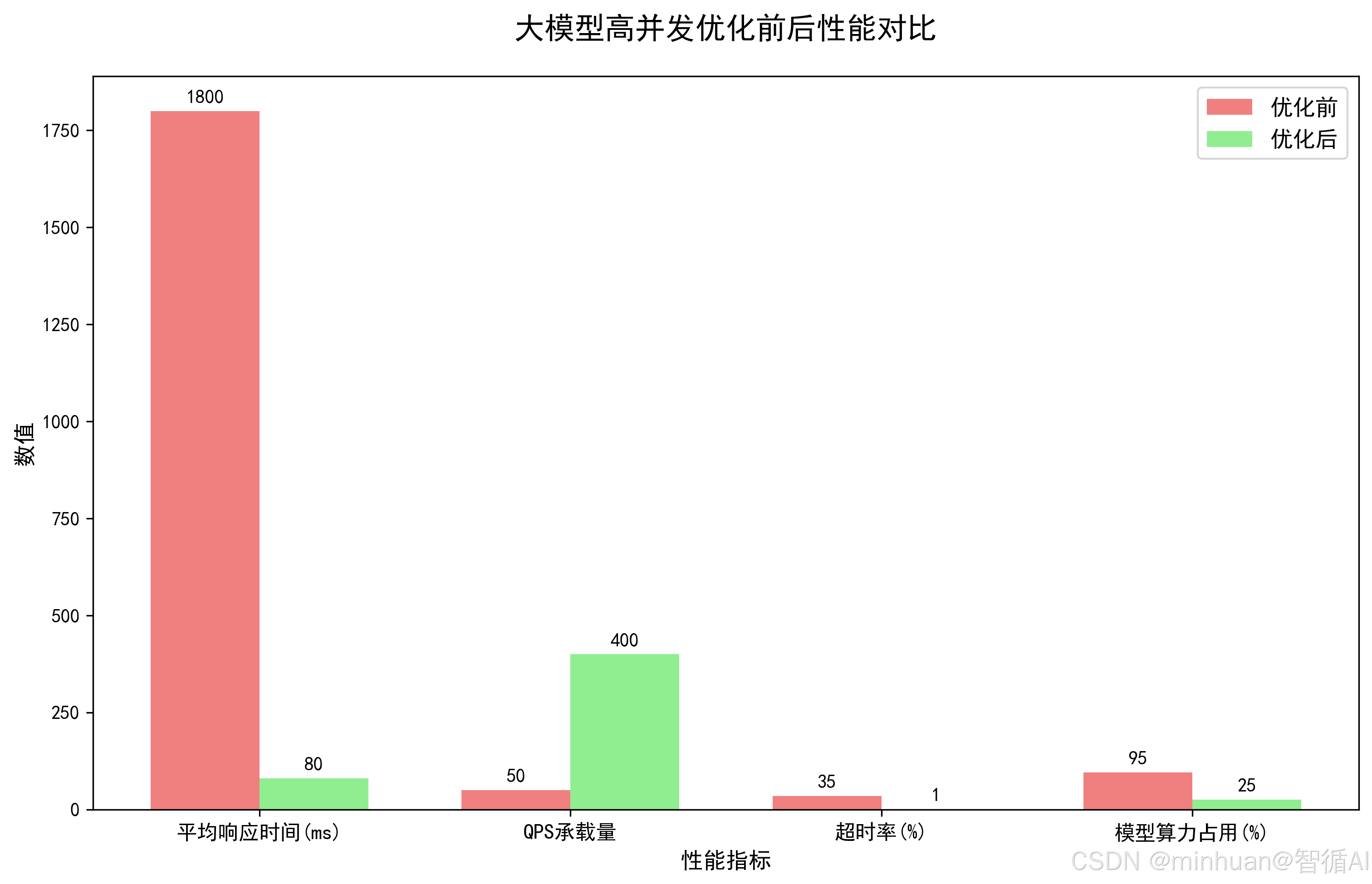
大模型高并发优化前后性能对比:
3. Redis 缓存 + 智能体推理
import redis
import time
# Redis基础连接配置
redis_client = redis.Redis(
host="localhost",
port=6379,
db=0,
decode_responses=True,
socket_timeout=5
)
# 模拟完整智能体推理链路:记忆拼接+意图识别+回复生成
def agent_llm_core_infer(session_id:str,user_query:str)->str:
"""模拟智能体短时+长时记忆联动+LLM推理耗时"""
time.sleep(1.5) # 模拟上下文校验、向量召回、推理总耗时
if "多轮记忆" in user_query:
return "智能体多轮记忆依托短时上下文拼接+长时向量检索协同实现语义连贯"
elif "并发超时" in user_query:
return "智能体高并发超时解决方案:Redis缓存高频问答+多实例负载均衡分流"
else:
return "智能体基于大模型意图理解、记忆管理、逻辑规划完成标准化应答输出"
# 带缓存拦截的智能体统一对外接口
def agent_chat_api(session_id:str,query:str,expire_sec=3600):
cache_key = f"agent:cache:{hash(query)}"
# 优先读取缓存
cache_res = redis_client.get(cache_key)
if cache_res:
return {
"status":"cache_hit",
"session_id":session_id,
"answer":cache_res,
"cost_time":round(0.008,3)
}
# 缓存未命中,走原生智能体全链路
start_ts = time.time()
real_answer = agent_llm_core_infer(session_id,query)
cost = round(time.time()-start_ts,3)
# 结果写入缓存
redis_client.setex(cache_key,expire_sec,real_answer)
return {
"status":"llm_infer",
"session_id":session_id,
"answer":real_answer,
"cost_time":cost
}
# 接口测试演示
if __name__ == "__main__":
sid = "agent_session_001"
q = "并发场景下智能体推理超时如何解决?"
print("第一次请求(走智能体全链路推理):",agent_chat_api(sid,q))
print("第二次请求(Redis缓存直接命中):",agent_chat_api(sid,q))输出结果:
第一次请求(走智能体全链路推理): {'status': 'llm_infer', 'session_id': 'agent_session_001', 'answer': '智能体基于大模型意图理解、记忆管理、 逻辑规划完成标准化应答输出', 'cost_time': 1.501}
第二次请求(Redis缓存直接命中): {'status': 'cache_hit', 'session_id': 'agent_session_001', 'answer': '智能体基于大模型意图理解、记忆管理、逻辑规划完成标准化应答输出', 'cost_time': 0.008}
4. 智能体集群负载均衡模拟
import random
from collections import defaultdict
# 多组智能体LLM后端实例集群
agent_server_cluster = [
"http://127.0.0.1:8001/agent/chat",
"http://127.0.0.1:8002/agent/chat",
"http://127.0.0.1:8003/agent/chat"
]
# 基础轮询负载均衡策略
def dispatch_agent_node()->str:
return random.choice(agent_server_cluster)
# 模拟高并发100次智能体请求分发统计
if __name__ == "__main__":
stat_count = defaultdict(int)
req_total = 100
for _ in range(req_total):
node = dispatch_agent_node()
stat_count[node] += 1
print(f"模拟{req_total}次智能体并发请求节点分发统计:")
for node,count in stat_count.items():
print(f"节点{node} 分配请求数:{count}")输出结果:
模拟100次智能体并发请求节点分发统计:
节点http://127.0.0.1:8002/agent/chat 分配请求数:31
节点http://127.0.0.1:8001/agent/chat 分配请求数:33
节点http://127.0.0.1:8003/agent/chat 分配请求数:36
5. 优化前后性能对比
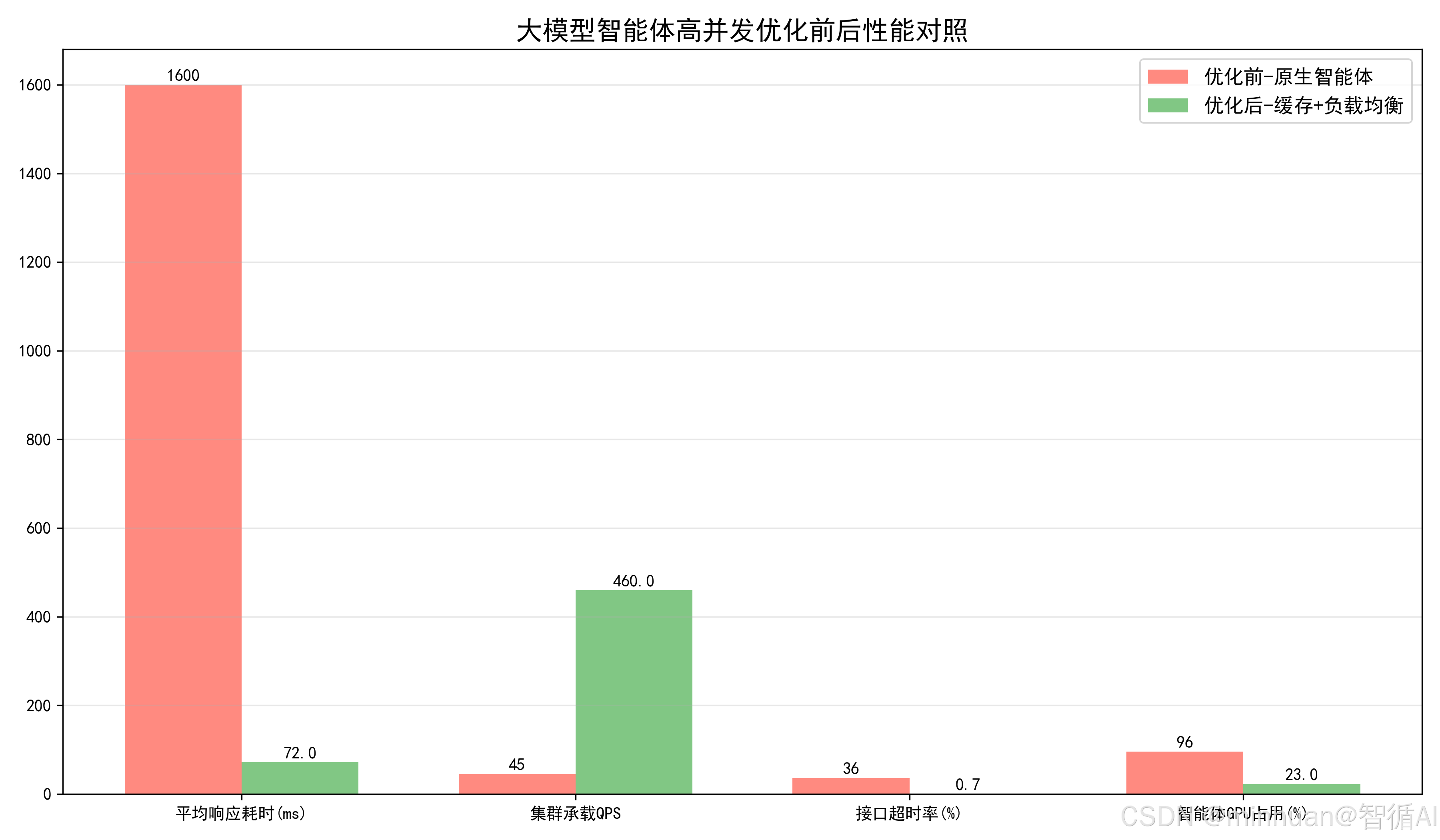
数据深度解读:
- 响应耗时:原生智能体全链路推理1.6秒,优化后缓存链路压缩至72毫秒,交互体验大幅提升;
- 并发能力:单集群QPS从45提升至460,轻松应对运营活动、批量咨询等高流量场景;
- 稳定性:接口超时率从36%降至0.7%,彻底解决智能体线上雪崩隐患;
- 资源消耗:智能体GPU算力占用从96%降至23%,节约大量硬件算力成本。
六、智能体落地实践优化
1. 缓存精细化治理
针对智能体业务场景的多样性,实施分级缓存策略,并强化数据持久化与容灾能力,确保服务的高可用性。
1.1 多级缓存策略(TTL 分层)
- 通用知识库:针对静态高频问答,设置 1~6 小时的 TTL,平衡数据新鲜度与服务性能。
- 实时动态业务:针对行情、库存等实时性要求高的场景,采用短时效缓存(如 5-60 秒)或旁路缓存(Cache-Aside)模式,确保数据一致性。
1.2 内存管理与雪崩防护
- 内存淘汰策略:根据业务优先级配置 Redis 内存淘汰策略(如 volatile-lru 或 allkeys-lru),确保低频数据优先释放。
- RDB 持久化:开启定时 RDB 快照,结合 AOF 重写机制,防止因进程崩溃导致的数据丢失。
- 防雪崩机制:对热点 Key 设置随机 TTL 偏移,配合布隆过滤器拦截缓存穿透请求,避免数据库瞬时压力激增。
2. 负载均衡高阶配置
摒弃简单的随机分发,转向基于状态感知的智能调度,构建具备自愈能力的高可用服务集群。
2.1 智能调度策略
- 加权轮询:根据智能体实例的GPU显存占用、CPU负载等指标动态调整权重,优先调度至轻载节点。
- 健康检查:Nginx或Ingress层配置主动式TCP/HTTP心跳检测,毫秒级剔除异常节点,避免“有状态”错误传播。
2.2 自适应熔断与限流
- 过载保护:基于Token Bucket或Leaky Bucket算法,对单节点QPS进行硬限流。
- 自动熔断:当节点错误率或延迟超过阈值(如5xx错误率>1%或P99>2s)时,自动触发熔断,将流量导向备用池或降级服务,保护核心推理引擎不崩溃。
3. 联动原有记忆体系兼容
确立“缓存为辅,原生为主”的设计哲学,确保在提升性能的同时,不破坏智能体复杂的语义理解与上下文连贯性。
3.1 场景化路由
- 缓存拦截层:仅拦截固定高频短句、意图明确的标准化问答,作为“第一道防线”。
- 原生推理层:对于多轮复杂上下文、个性化业务咨询、模糊意图识别等高价值请求,强制走智能体原生链路。
3.2 记忆链路融合
- 短时裁剪 + 长时向量召回:原生链路采用“滑动窗口”裁剪无效上下文,结合向量数据库进行长时记忆召回,确保语义交互逻辑的完整性与连贯性,避免因缓存介入导致的“语义断裂”。
4. 全链路监控告警
建立从数据采集、指标分析到自动优化的闭环系统,实现集群性能的持续迭代。
4.1 核心监控大盘
- 缓存层:监控缓存命中率(目标 > 95%)、热点Key分布、内存碎片率。
- 服务层:监控智能体单节点QPS、平均延迟、Token超限次数、GPU利用率。
- 链路层:追踪全链路Trace ID,定位慢查询根因。
4.2 智能优化闭环
- 低命中率自愈:当缓存命中率持续低于阈值时,自动触发分析脚本,识别“漏网”高频问答并沉淀至标准库,自动更新缓存策略。
- 容量预测:基于历史QPS趋势,预测未来流量峰值,提前进行节点扩容或资源预热,实现从被动响应到主动治理的转变。
七、总结
AI智能体作为大模型落地交互场景的核心载体,天然受限于LLM推理慢、算力开销大、并发承载力弱的短板,线上流量激增时推理超时几乎无法避免。通过实践我们采取以Redis缓存拦截高频标准化请求削减无效智能体记忆拼接与模型推理压力,再依托负载均衡做多实例流量横向分发解决单点算力瓶颈。二者与智能体原有短时记忆、长时向量召回、意图识别体系深度兼容融合,既保留了大模型智能体语义连贯理解、多轮逻辑推演的核心能力,又从架构层面根治高并发超时难题。
今天我们探讨的方案轻量化、低成本、落地简单,无需深度改造模型权重与推理内核,是目前企业级对话智能体、客服智能体、业务问答智能体高并发稳定部署的标准最优实践。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)