从 0 开始学人工智能——什么是神经网络模型,其原理是什么?
你是否曾经好奇过:那一串串冰冷的 0 和 1 组成的计算机代码,究竟是如何像人类大脑一样,学会识别照片、理解语言,甚至进行创作的呢?
科学家们从生物学中寻找灵感,试图在计算机中模拟人类大脑神经元的工作方式。
想要理解庞大的 AI 模型,我们需要从最基础的单元——神经元开始讲起。
生物神经元 (biological_neuron_scene)
要理解人工神经网络,我们首先要看看大自然的设计:生物神经元。这是人类大脑中数以百亿计的基本工作单元。尽管它的内部结构极其复杂,但我们可以将其抽象为四个关键部分。
首先是树突,它们就像是神经元的“天线”,负责接收来自其他神经元的化学或电信号。
接着是细胞体。它是神经元的控制中心,会对所有接收到的信号进行汇总和处理。
然后是轴突。一旦信号被处理完毕,它就会沿着这条细长的管道向外传递。
最后是突触。它是神经元之间交接的关口,负责将信号跨越缝隙传递给下一个神经元。
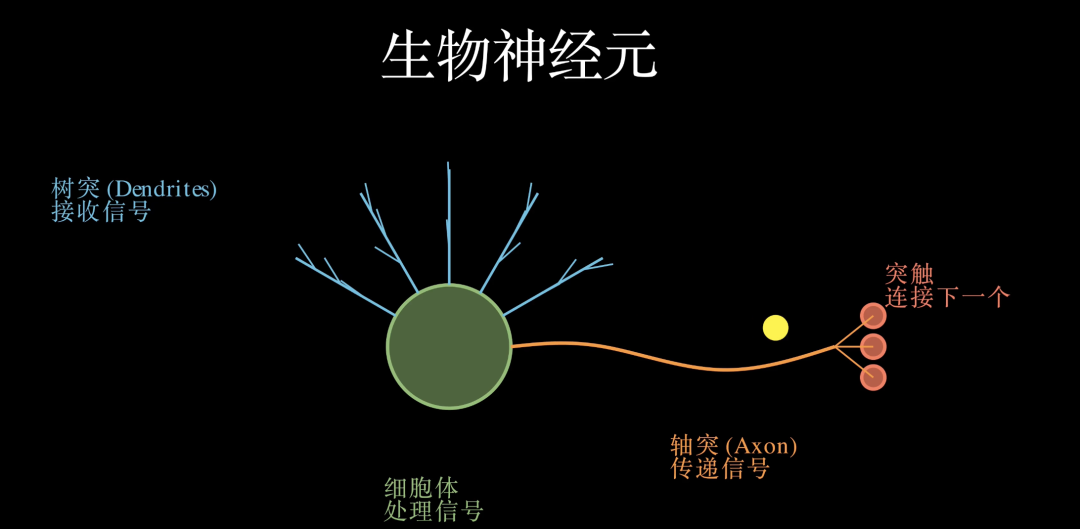
让我们观察一次完整的信号传递:信号由树突进入,经过细胞体的整合,最后通过轴突奔向下一个目标。
但并不是所有的信号都能顺利传递。这里有一个核心机制:阈值(Threshold)。只有当输入信号的强度累计超过了某个特定的阈值时,神经元才会被“点亮”并向下发送信号。这种“全或无”的工作方式,正是现代神经网络逻辑的基石。
感知机 (perceptron_scene)
现在,我们将生物神经元抽象为数学模型,这就是神经网络的鼻祖——感知机(Perceptron)。它是人类模仿大脑尝试迈出的第一步,将复杂的生物电信号简化成了纯粹的数学运算。
在这个结构中,左侧是我们的输入信号。每一个信号进入时,都会被乘上一个权重(Weight),用来代表该信号的重要性。随后,所有加权后的信号会在细胞中心进行累加,并加上一个偏置项(Bias)。这个偏置项决定了神经元被激活的难易程度。
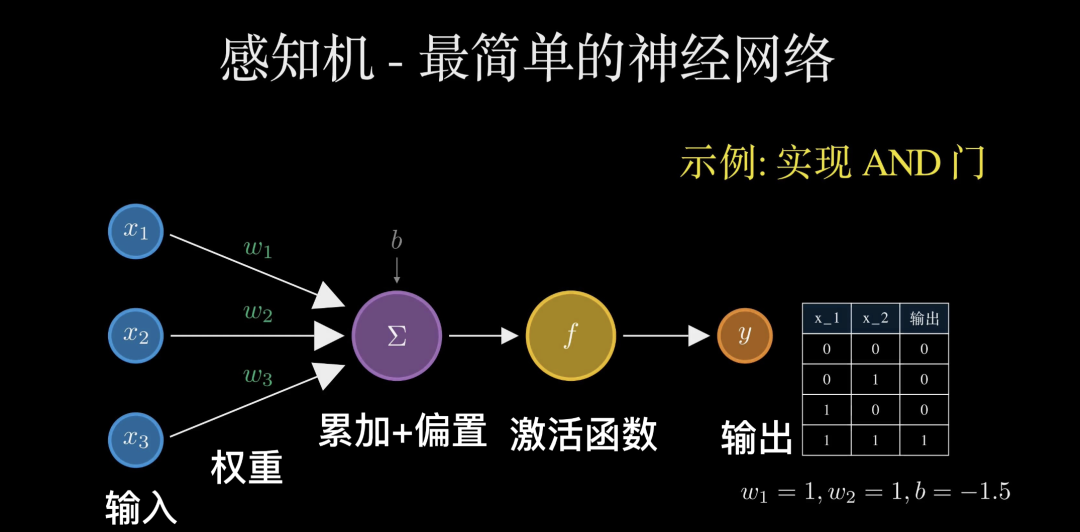
将其写成公式就是:输入与权重的点积求和,加上偏置,最后通过一个激活函数
X 是输入,w 是权重,b 是偏置,而 f 则是决定最终输出的激活函数。
为了更好理解,我们来看一个经典的逻辑运算:AND门(与门)。只有当两个输入同时为 1 时,输出才为 1。我们可以通过设定参数来实现它:令权重均为 1,偏置为 -1.5。这样,只有当
𝑥1和𝑥2 都为 1 时,总和(2)加偏置(-1.5)才大于 0,从而触发输出。感知机就这样学会了简单的逻辑判断。
感知机虽然强大,但它只能处理线性可分的问题(如 AND 门)
如果问题变得更加复杂,单层感知机还够用吗?
激活函数 (activation_functions_scene)
如果说神经元是神经网络的细胞,那么激活函数就是这些细胞的“灵魂”。
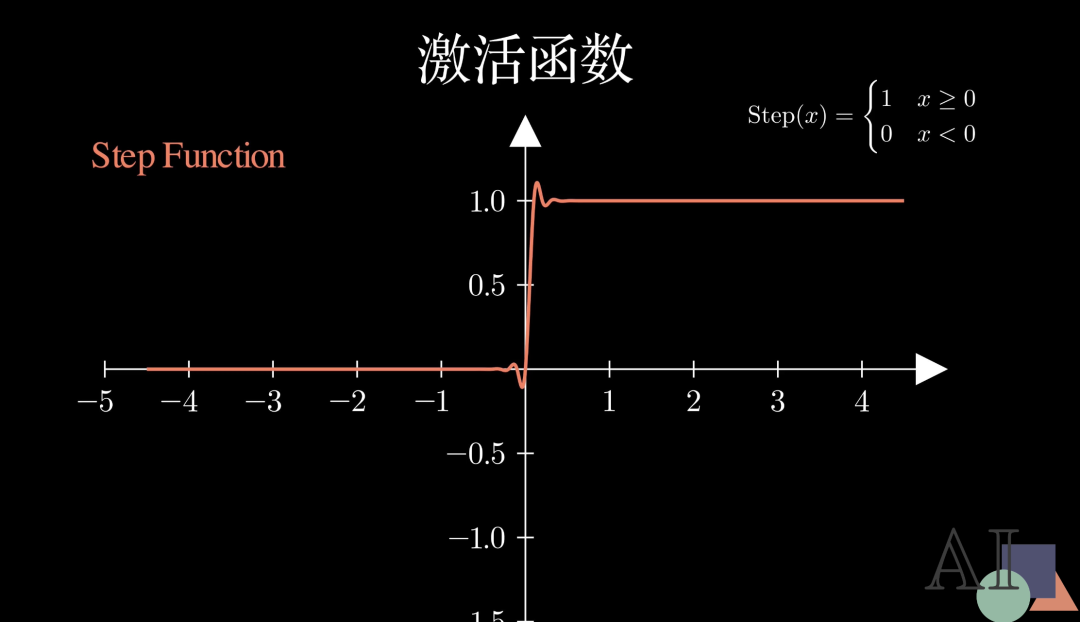
你可能会问:为什么我们不能直接输出求和的结果,非要加上一层复杂的函数变换呢?关键在于非线性(Non-linearity)。如果没有激活函数,无论你的神经网络有多少层,它在数学上都只能等同于一个简单的线性映射。只有引入了非线性,神经网络才能去拟合现实世界中各种复杂的、不规则的规律。
首先是最简单的阶跃函数(Step Function)。 它的逻辑非常果断:信号一旦超过阈值就输出 1,否则就是 0。这虽然简单,但因为不可导,在现代训练中很少使用。
接着是经典的 Sigmoid 函数。 它像一个平滑的“S”,能将任何数值压缩到 0 到 1 之间。它是神经网络早期最常用的激活函数。
随后是 Tanh 函数。 它的形状与 Sigmoid 类似,但它能输出负值,范围在 -1 到 1 之间,让数据的均值更接近 0。

最后,是目前工业界最宠爱的 ReLU。 在负区间它完全静默,在正区间它线性爆发。它的计算极其简单,却能显著加速网络的训练。
这四种函数代表了神经网络对信号处理的不同态度。有了它们,神经网络才真正具备了学习复杂逻辑的能力。
现在我们既有了神经元,又有了激活函数,是时候把它们大规模地组织起来了。
多层神经网络 (multilayer_network_scene)
单个神经元的能力是有限的,但当成千上万个神经元连接在一起时,奇迹就发生了。
这就是深度神经网络。在这个复杂的网络中,每一个节点都在处理信息,每一根连线都代表着知识的权重。典型的结构分为三部分:输入层接收原始数据;输出层给出最终结果;而中间这些神秘的隐藏层,则是模型进行抽象思考的核心地带。
那么,神经网络是如何工作的呢?这一切都始于前向传播(Forward Propagation)。数据从左侧输入,像潮水一样逐层向右涌动。每一层的神经元都会根据上一层的输出进行计算,并将激活后的信号传递给下一层。
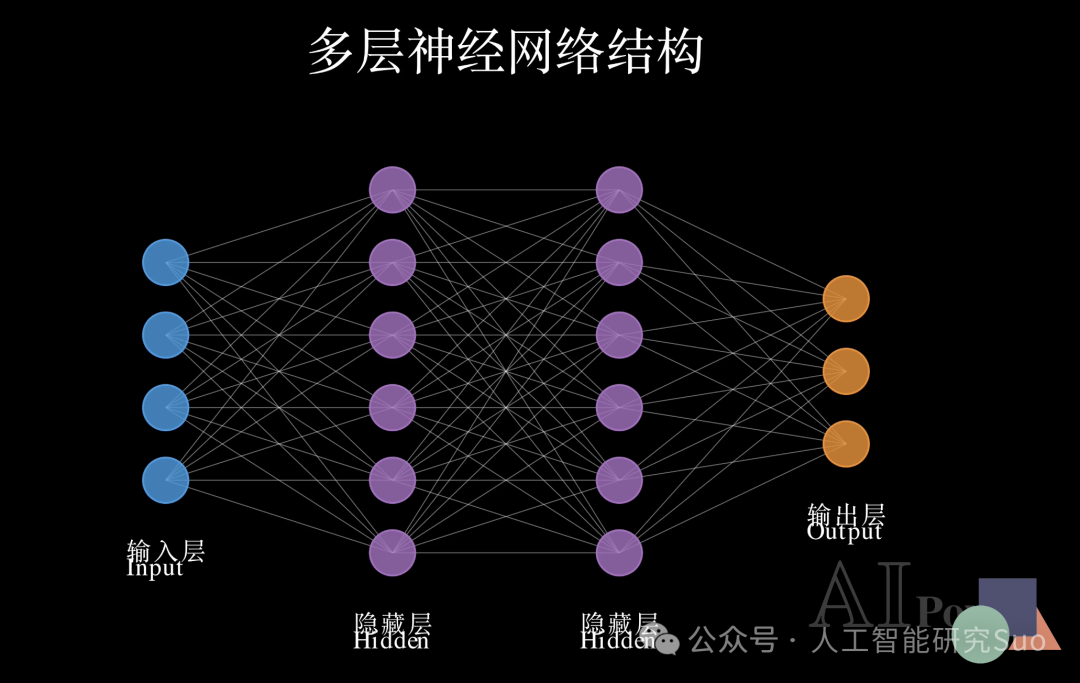
经过多层隐藏层的非线性变换,复杂的原始输入会被一步步抽象、提炼。最终,网络在输出层给出了它的“判断”。这就是神经网络模拟大脑进行推理的基本逻辑。
当然,隐藏层的层数越多,网络就越‘深’,能够理解的特征也就越复杂。
前向传播详解 (forward_propagation_scene)
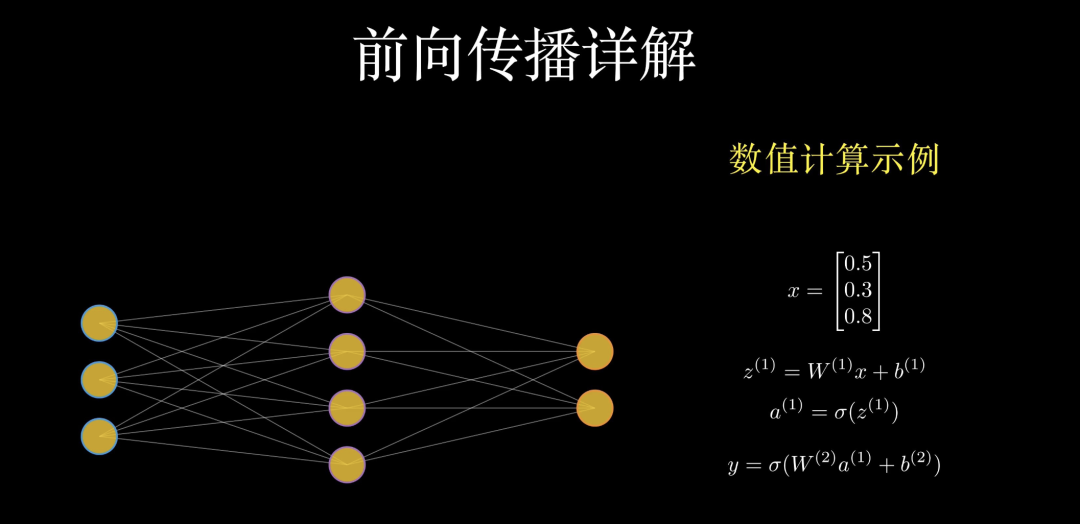
了解了整体结构后,我们来拆解数据在网络中流动的精确逻辑:前向传播。为了清晰起见,我们来看一个精简版的模型。在这里,每一层都在完成一次华丽的数学变换。
在计算机眼中,这些神经元并不是杂乱无章的点,而是整齐的矩阵。每一层的计算本质上都是一次矩阵乘法,加上偏置,再经过激活函数处理。
举个具体的数值例子:假设我们将一组由 0.5、0.3、0.8 组成的信号输入进第一层。此时,输入层的神经元被激活,它们将这些原始数据推向下一个阶段。
每一条连线上的权重会与输入相乘并汇总,得到一个中间结果𝑧。紧接着,激活函数sigma会给这个结果注入非线性的力量。隐藏层接收到了经过“深思熟虑”后的特征,并再次将它们进行加权组合,传递给最后的一层。最终,所有的信息收束在输出层。得到的结果𝑦,就是神经网络基于当前知识,对输入数据给出的预测答案。
损失函数 (loss_function_scene)
前向传播得到了预测值,但如果预测错了怎么办?这就需要引入损失函数。简单来说,损失函数就像是一个严格的“教练”,它负责精准地衡量预测值与真实标签之间的差距。

最常用的是均方误差(MSE)。 它通过计算差值的平方来放大那些严重的错误,常用于回归任务中预测连续的数值。
而在分类任务中,我们常用交叉熵(Cross-Entropy)。 它对概率分布的微小差异非常敏感。能让模型在分类时更加果断。
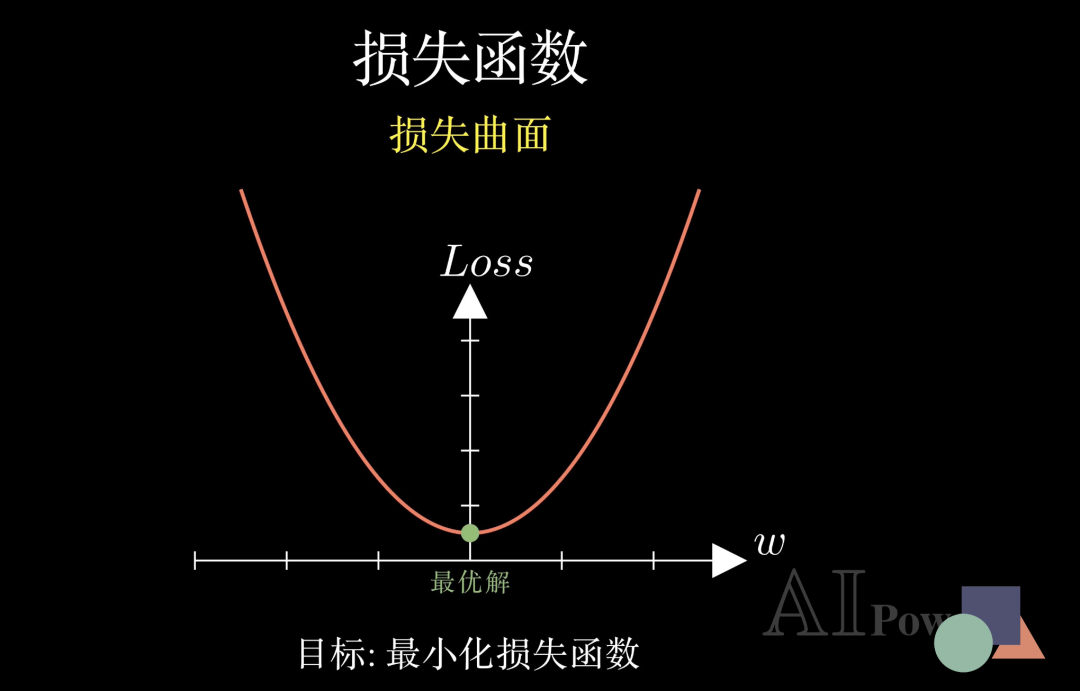
如果我们将模型的所有参数看作坐标,损失的大小看作高度,就会得到一张损失曲面。在这个曲面中,最低点就代表了损失最小、预测最准的最优解。所以,训练神经网络的核心目标,就是在这个起伏的曲面上寻找那条通往谷底的捷径:最小化损失函数。
反向传播 (backpropagation_scene)
既然知道了差距,接下来就是最关键的一步:神经网络是如何根据错误来修正自己的? 这就是著名的反向传播算法。
反向传播的核心在于数学中的链式法则(Chain Rule)。它像剥洋葱一样,将最后的总误差层层拆解,分配到每一个权重上。
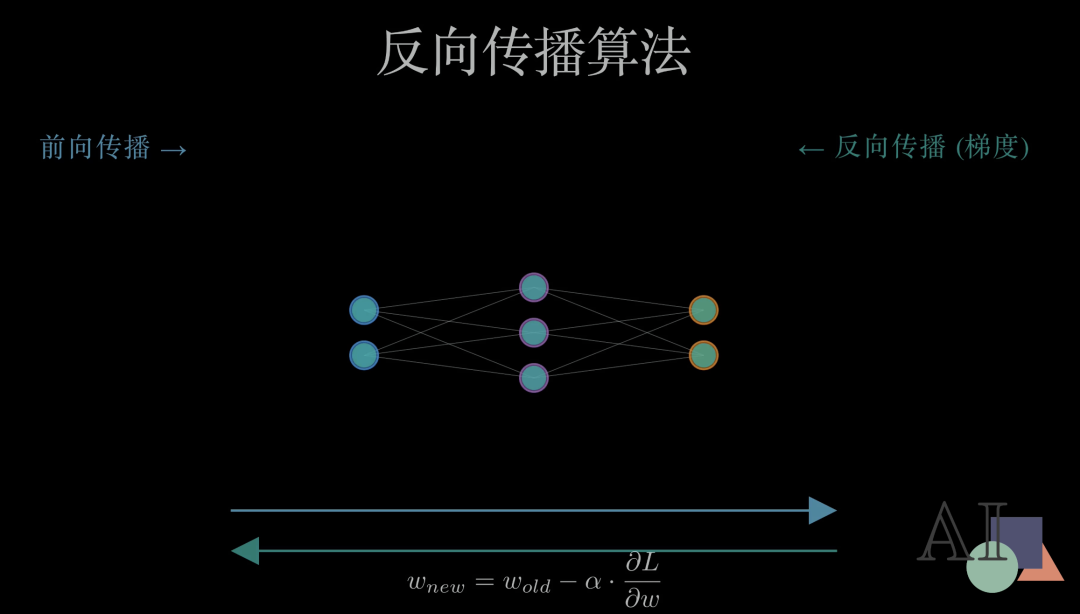
让我们回到这个三层的小型网络中。在前向传播中,数据从左向右流动产生误差。紧接着,反向传播开始了。梯度信号,也就是修正建议,从右侧的输出层出发,逆流而上。这种信号会逐层评估每一个神经元对最终误差的“贡献度”。误差越大,得到的修正信号就越强。
最后,根据计算出的梯度,网络会微调所有的权重。旧的权重减去学习率乘上梯度,就得到了进化后的新权重。每一轮这样的循环,网络都会变得更聪明一点。这就是神经网络“学习”的本质。
梯度下降 (gradient_descent_scene)
既然目标是寻找谷底,但在这片迷雾笼罩的曲面中,神经网络该如何选择下山的方向呢?
这就是神经网络中最常用的优化算法:梯度下降。
想象你正站在雾气弥漫的山顶,目标是寻找山谷的最深处。由于看不清全局,你只能感受脚下土地的倾斜度,向着最陡峭的相反方向迈出一步。这里的红色曲线就是我们的损失函数。纵轴代表误差的大小,横轴𝑤则代表权重。
每一个点上的切线斜率就是梯度。沿着梯度相反的方向移动,损失就会一点点降低。这个移动的步长取决于学习率alpha。它决定了我们是以稳健的小碎步下山,还是以大跨步飞奔。
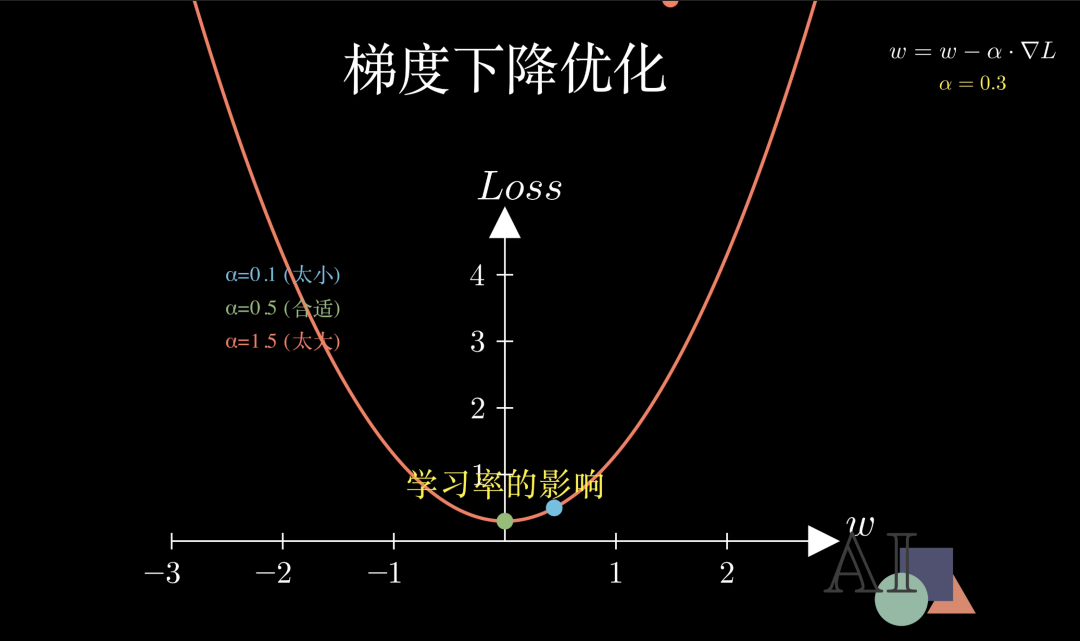
学习率的选择至关重要。看这三个不同步长的实验:蓝色的步子太小,到达终点慢得令人心急;红色的步子太大,会在山谷两端疯狂反复横跳;唯有绿色的步幅适中,既保证了速度,又能精准锁定目标。当小球停留在曲线底部时,我们就说模型已经收敛了。寻找那个“恰到好处”的学习率,是每一个深度学习算法工程师的必修课。
实际案例 (mnist_example_scene)
现在,我们已经掌握了神经网络从理论到优化的全部核心原理。接下来,让我们看一个它在现实世界大显身手的经典案例。:手写数字识别。我们使用的是著名的 MNIST 数据集。每一张图片都是一张 28乘28像素 的细微灰度图。
在计算机眼中,这张图片是一个由 784个像素点 组成的数值序列。为了识别它,我们搭建了一个多层网络:输入层拥有784个节点;中间经过两层隐藏层进行特征提取;最终,输出层有10个节点,分别代表数字 0 到 9。
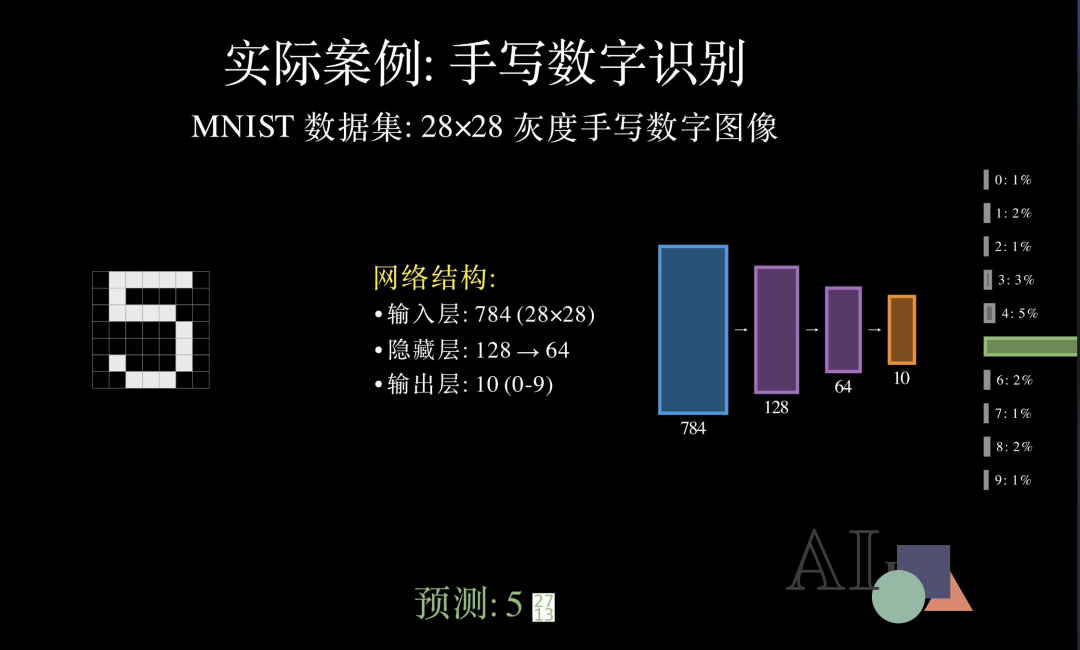
数据流过网络后,输出层会给出一组概率。在这个例子中,数字 “5” 的概率高达 82%,远超其他选项。神经网络给出了它的判断,预测结果:5。识别正确!从像素级的原始输入,到逻辑层面的分类决策,这就是神经网络处理复杂信息的全过程。
过拟合与正则化 (regularization_scene)
虽然它在训练集上表现完美,但在面对从未见过的陌生手写体时,它能保持稳定吗?
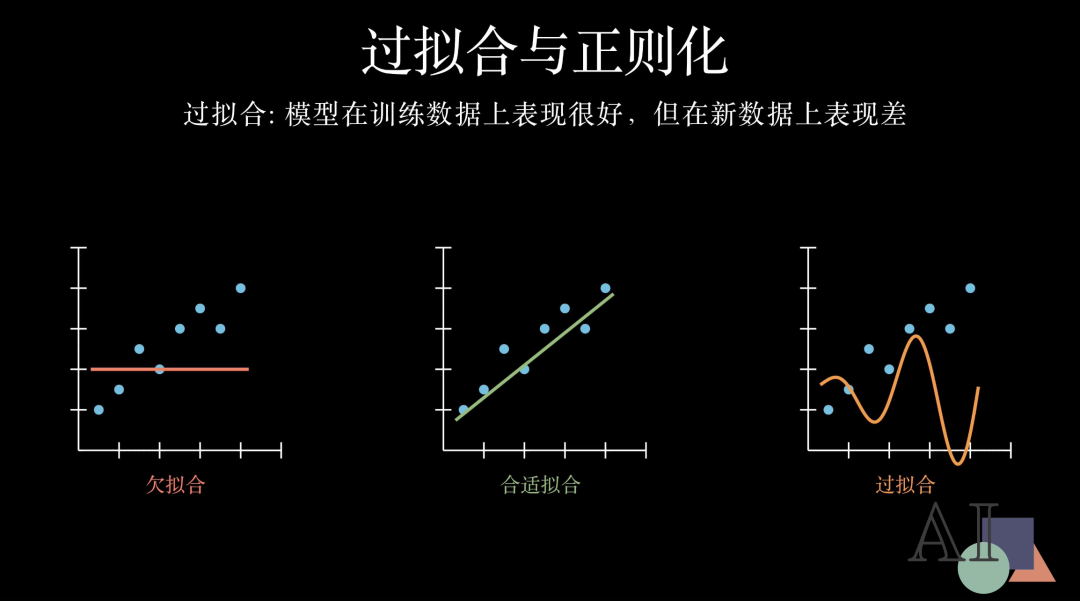
拥有了强大的拟合能力,神经网络有时也会陷入一个误区,那就是过拟合(Overfitting)。简单来说,过拟合就是模型“背”下了训练数据的所有细节,却丧失了处理新情况的通用能力。

让我们通过拟合曲线直观地感受一下:欠拟合就像是一个不努力的学生,连基础的规律都没抓到;而过拟合则是由于“想得太多”,试图穿过每一个噪点,导致曲线变得支离破碎;合适的拟合则在两者之间找到了平衡,它抓住了数据的核心本质。
为了防止模型跑偏,我们需要正则化手段。L2 正则化通过惩罚过大的权重来让模型保持低调;Dropout 强迫神经元独立生存;而早停法则在模型刚开始变得“死记硬背”时果断叫停。
总结 (summary_scene)
到这里,我们已经完整走过了神经网络的奇幻旅程。从模拟生物大脑的神经元,到数据逐层流动的前向传播;从衡量差距的损失函数,到寻找误差源头的反向传播,再到最终下山求索的梯度下降。
神经网络并没有停下脚步。从识别图像的 CNN,到理解时序的 RNN,再到如今引爆 AI 浪潮的 Transformer 架构,它们都在这些基础原理之上不断进化。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)